Forest Fire Probability Mapping in Eastern Serbia: Logistic Regression versus Random Forest Method

 ,
, 

Abstract
:1. Introduction
2. Materials and Methods
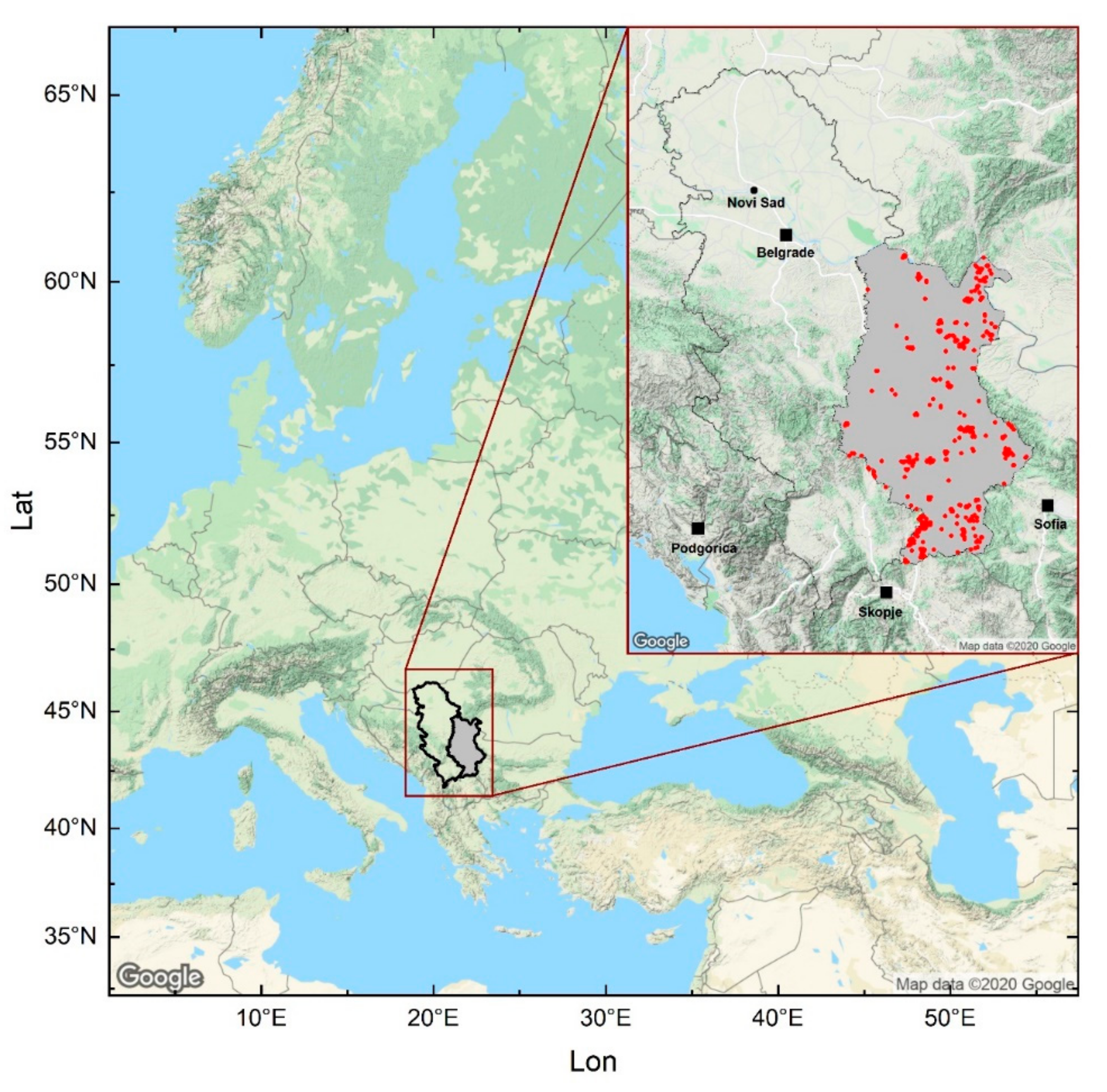
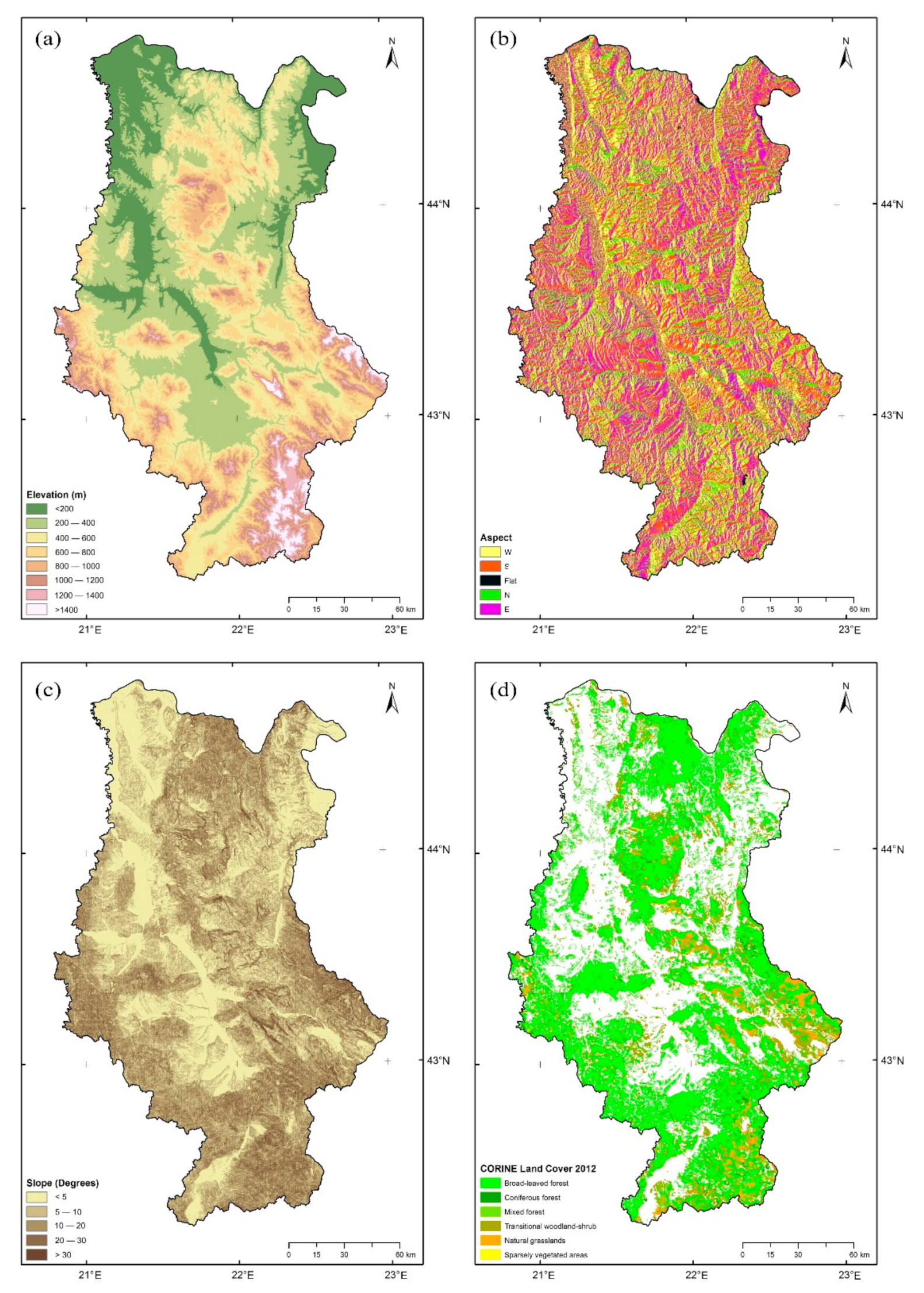
2.1. Study Area
2.2. Data Preparation
2.2.1. Dependent Variable
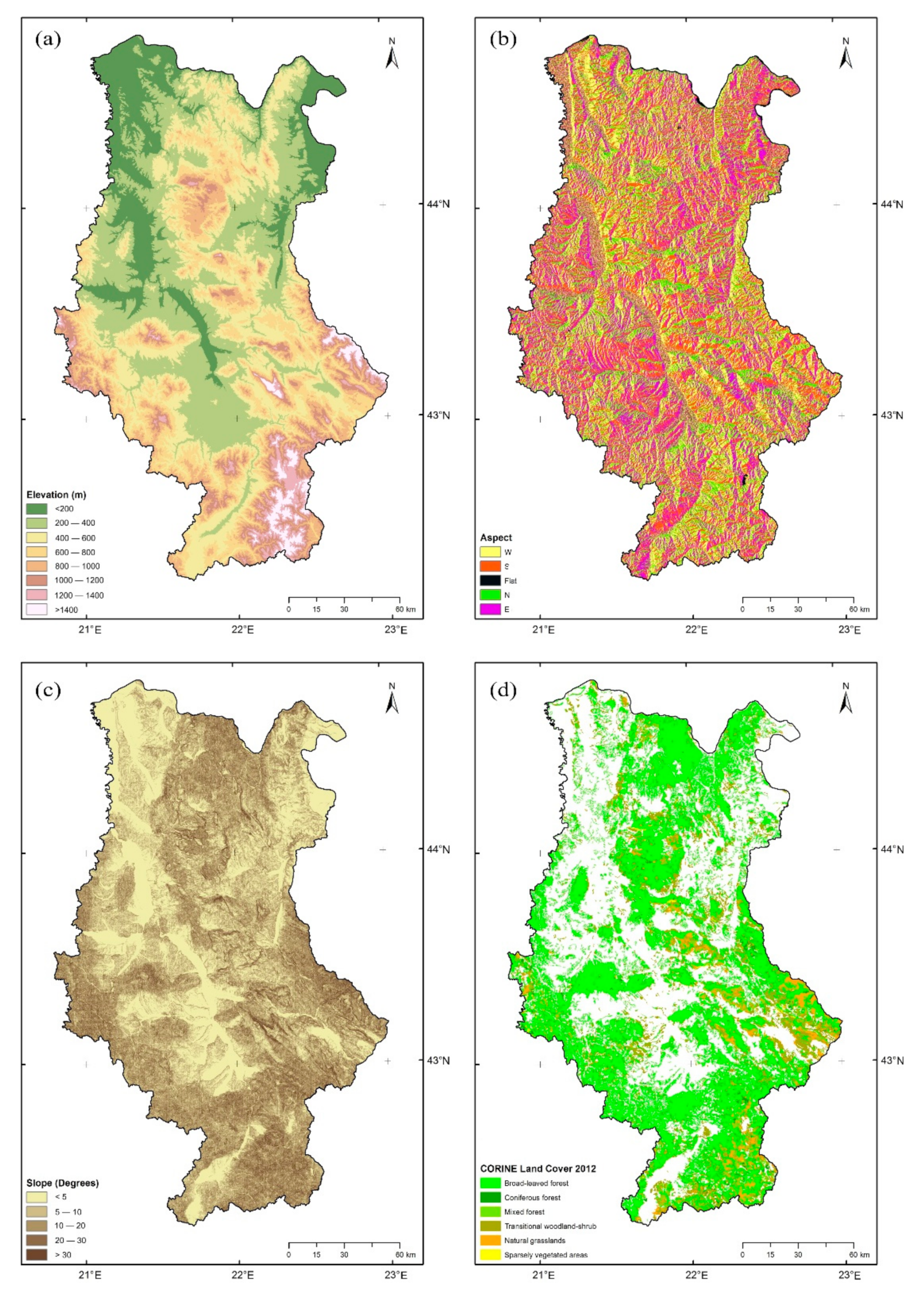
2.2.2. Independent Variables
2.2.3. Forest Fire Occurrence Frequency across Categorical Predictors
2.3. Modeling Procedures
2.3.1. LR Models
2.3.2. RF Models
2.4. Model Validation
2.5. Variable Importance Analysis
2.6. Mapping Forest Fire Occurrence Probability
3. Results
3.1. Forest Fire Occurrence Frequency
3.2. Models of Forest Fire Occurrence
3.3. Relative Importance of Variables
3.4. Spatial Modeling of Probability of Fire Occurrence
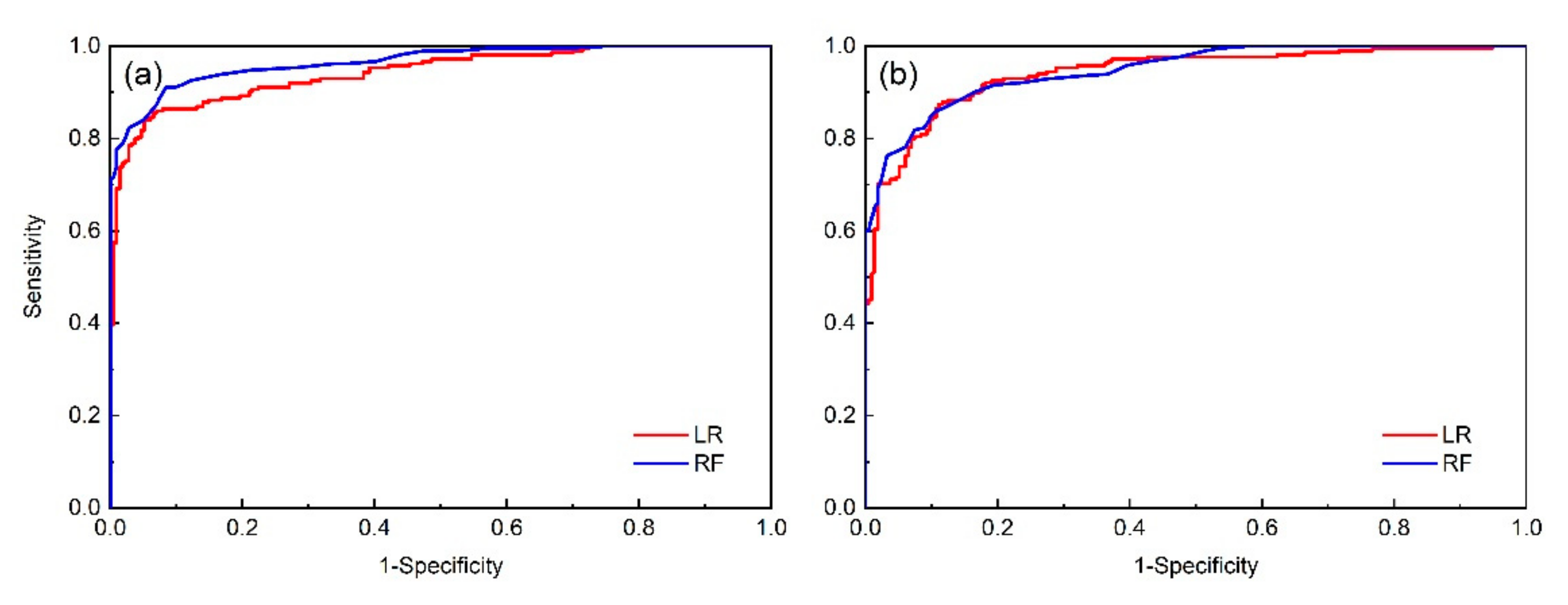
3.5. Model Validation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Doerr, S.H.; Santín, C. Global trends in wildfire and its impacts: Perceptions versus realities in a changing world. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2016, 371, 20150345. [Google Scholar] [CrossRef] [PubMed]
- Flannigan, M.D.; Krawchuk, M.A.; de Groot, W.J.; Wotton, B.M.; Gowman, L.M. Implications of changing climate for global wildland fire. Int. J. Wildl. Fire 2009, 18, 483–507. [Google Scholar] [CrossRef]
- Flannigan, M.; Cantin, A.S.; de Groot, W.J.; Wotton, M.; Newbery, A.; Gowman, L.M. Global wildland fire season severity in the 21st century. Ecol. Manag. 2013, 294, 54–61. [Google Scholar] [CrossRef]
- Moritz, M.A.; Batllori, E.; Bradstock, R.A.; Gill, A.M.; Handmer, J.; Hessburg, P.F.; Leonard, J.; McCaffrey, S.; Odion, D.C.; Schoennagel, T.; et al. Learning to coexist with wildfire. Nature 2014, 515, 58–66. [Google Scholar] [CrossRef]
- Turco, M.; Rosa-Cánovas, J.J.; Bedia, J.; Jerez, S.; Montávez, J.P.; Llasat, M.C.; Provenzale, A. Exacerbated fires in Mediterranean Europe due to anthropogenic warming projected with non-stationary climate-fire models. Nat. Commun. 2018, 9, 1–9. [Google Scholar] [CrossRef]
- Feurdean, A.; Vannière, B.; Finsinger, W.; Warren, D.; Connor, S.C.; Forrest, M.; Liakka, J.; Panait, A.; Werner, C.; Andrič, M.; et al. Fire hazard modulation by long-term dynamics in land cover and dominant forest type in eastern and central Europe. Biogeosciences 2020, 17, 1213–1230. [Google Scholar] [CrossRef] [Green Version]
- Costa, H.; de Rigo, D.; Libertà, G.; Durrant, T.; San-Miguel-Ayanz, J. European Wildfire Danger and Vulnerability in a Changing Climate: Towards Integrating Risk Dimensions; Publications Office of the European Union: Luxembourg, 2020; ISBN 978-92-76-16898-0.
- Moritz, M.A.; Parisien, M.-A.; Batllori, E.; Krawchuk, M.A.; van Dorn, J.; Ganz, D.J.; Hayhoe, K. Climate change and disruptions to global fire activity. Ecosphere 2012, 3, art49. [Google Scholar] [CrossRef]
- Räisänen, J.; Hansson, U.; Ullerstig, A.; Döscher, R.; Graham, L.P.; Jones, C.; Meier, H.E.M.; Samuelsson, P.; Willén, U. European climate in the late twenty-first century: Regional simulations with two driving global models and two forcing scenarios. Clim. Dyn. 2004, 22, 13–31. [Google Scholar] [CrossRef]
- Schär, C.; Vidale, P.L.; Lüthi, D.; Frei, C.; Häberli, C.; Liniger, M.A.; Appenzeller, C. The role of increasing temperature variability in European summer heatwaves. Nature 2004, 427, 332–336. [Google Scholar] [CrossRef]
- Fronzek, S.; Carter, T.R.; Jylhä, K. Representing two centuries of past and future climate for assessing risks to biodiversity in Europe. Glob. Ecol. Biogeogr. 2012, 21, 19–35. [Google Scholar] [CrossRef]
- Thuiller, W.; Lavorel, S.; Araújo, M.B.; Sykes, M.T.; Prentice, I.C. Climate change threats to plant diversity in Europe. Proc. Natl. Acad. Sci. USA 2005, 102, 8245–8250. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brewer, S.; Cheddadi, R.; de Beaulieu, J.L.; Reille, M. The spread of deciduous Quercus throughout Europe since the last glacial period. Ecol. Manag. 2002, 156, 27–48. [Google Scholar] [CrossRef]
- Hernández, L.; Sánchez de Dios, R.; Montes, F.; Sainz-Ollero, H.; Cañellas, I. Exploring range shifts of contrasting tree species across a bioclimatic transition zone. Eur. J. Res. 2017, 136, 481–492. [Google Scholar] [CrossRef]
- Brovkina, O.; Stojanović, M.; Milanović, S.; Latypov, I.; Marković, N.; Cienciala, E. Monitoring of post-fire forest scars in Serbia based on satellite Sentinel-2 data. Geomat. Nat. Hazards Risk 2020, 11, 2315–2339. [Google Scholar] [CrossRef]
- Krawchuk, M.A.; Meigs, G.W.; Cartwright, J.M.; Coop, J.D.; Davis, R.; Holz, A.; Kolden, C.; Meddens, A.J.H. Disturbance refugia within mosaics of forest fire, drought, and insect outbreaks. Front. Ecol. Env. 2020, 18, 235–244. [Google Scholar] [CrossRef]
- San-Miguel-Ayanz, J. Methodologies for the Evaluation of Forest Fire Risk: From Long-Term (Static) to Dynamic Indices. Corso Cult. Ecol. 2002, 117, 117. [Google Scholar]
- San-Miguel-Ayanz, J.; Carlson, J.D.; Alexander, M.; Tolhurst, K.; Morgan, G.; Sneeuwjagt, R.; Dudley, M. Current Methods to Assess Fire Danger Potential; World Scientific: Singapore, 2003; pp. 21–61. [Google Scholar]
- Mohammadi, F.; Bavaghar, M.P.; Shabanian, N. Forest Fire Risk Zone Modeling Using Logistic Regression and GIS: An Iranian Case Study. Small-Scale 2014, 13, 117–125. [Google Scholar] [CrossRef]
- Agee, J.K.; Bahro, B.; Finney, M.A.; Omi, P.N.; Sapsis, D.B.; Skinner, C.N.; van Wagtendonk, J.W.; Phillip-Weatherspoon, C. The use of shaded fuelbreaks in landscape fire management. Ecol. Manag. 2000, 127, 55–66. [Google Scholar] [CrossRef]
- Agee, J.K.; Skinner, C.N. Basic principles of forest fuel reduction treatments. Ecol. Manag. 2005, 211, 83–96. [Google Scholar] [CrossRef]
- Fernandes, P.M. Fire-smart management of forest landscapes in the Mediterranean basin under global change. Landsc. Urban. Plan. 2013, 110, 175–182. [Google Scholar] [CrossRef] [Green Version]
- Khabarov, N.; Krasovskii, A.; Obersteiner, M.; Swart, R.; Dosio, A.; San-Miguel-Ayanz, J.; Durrant, T.; Camia, A.; Migliavacca, M. Forest fires and adaptation options in Europe. Reg. Env. Chang. 2016, 16, 21–30. [Google Scholar] [CrossRef] [Green Version]
- Catry, F.X.; Rego, F.C.; Bação, F.L.; Moreira, F. Modeling and mapping wildfire ignition risk in Portugal. Int. J. Wildl. Fire 2009, 18, 921–931. [Google Scholar] [CrossRef] [Green Version]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. arXiv 2020, arXiv:2003.00646v1. [Google Scholar] [CrossRef]
- Breiman, L. Statistical modeling: The two cultures. Stat. Sci. 2001, 16, 199–215. [Google Scholar] [CrossRef]
- Malinovic-Milicevic, S.; Radovanovic, M.M.; Stanojevic, G.; Milovanovic, B. Recent changes in Serbian climate extreme indices from 1961 to 2010. Appl. Clim. 2016, 124, 1089–1098. [Google Scholar] [CrossRef]
- Luković, J.; Bajat, B.; Blagojević, D.; Kilibarda, M. Spatial pattern of recent rainfall trends in Serbia (1961–2009). Reg. Env. Chang. 2014, 14, 1789–1799. [Google Scholar] [CrossRef]
- Mimić, G.; Mihailović, D.T.; Kapor, D. Complexity analysis of the air temperature and the precipitation time series in Serbia. Appl. Clim. 2017, 127, 891–898. [Google Scholar] [CrossRef]
- Milomir, V. Forest Fire: Manual for Forest Engineers and Technicians; Level of Thesis; Faculty of Forestry University of Belgrade: Belgrade, Serbia, 1992. [Google Scholar]
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Libertà, G.; Branco, A.; de Rigo, D.; Ferrari, D.; Maianti, P.; Artes, T.; Oom, D.; et al. Forest Fires in Europe, Middle East and North Africa 2018; Publications Office of the European Union: Luxembourg, 2019; ISBN 978-92-76-12591-4.
- Schmuck, G.; San-Miguel-Ayanz, J.; Camia, A.; Durrant, T.; Boca, R.; Libertà, G.; Schulte, E. Forest fires in Europe Middle East and North Africa 2012. Sci. Tech. Res. Ser. 2013, 10–30. [Google Scholar]
- Goldstein, E. Serbia’s Potential For. Sustainable Growth And Shared Prosperity Systematic Country Diagnostic Report; World Bank: Washington, DC, USA, 2015. [Google Scholar]
- Nhongo, E.J.S.; Fontana, D.C.; Guasselli, L.A.; Bremm, C. Probabilistic modelling of wildfire occurrence based on logistic regression, Niassa Reserve, Mozambique. Geomat. Nat. Hazards Risk 2019, 10, 1772–1792. [Google Scholar] [CrossRef]
- Carmo, M.; Moreira, F.; Casimiro, P.; Vaz, P. Land use and topography influences on wildfire occurrence in northern Portugal. Landsc. Urban. Plan. 2011, 100, 169–176. [Google Scholar] [CrossRef] [Green Version]
- Konkathi, P.; Shetty, A.; Kolluru, V.; Yathish, P.; Pruthviraj, U. Static Fire Risk Index for the Forest Resources of Karnataka. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 6716–6719. [Google Scholar]
- Ye, T.; Wang, Y.; Guo, Z.; Li, Y. Factor contribution to fire occurrence, size, & burn probability in a subtropical coniferous forest in East China. PLoS ONE 2017, 12. [Google Scholar] [CrossRef] [Green Version]
- Jaafari, A.; Gholami, D.M.; Zenner, E.K. A Bayesian modeling of wildfire probability in the Zagros Mountains, Iran. Ecol. Inf. 2017, 39, 32–44. [Google Scholar] [CrossRef]
- Guo, F.; Su, Z.; Wang, G.; Sun, L.; Lin, F.; Liu, A. Wildfire ignition in the forests of southeast China: Identifying drivers and spatial distribution to predict wildfire likelihood. Appl. Geogr. 2016, 66, 12–21. [Google Scholar] [CrossRef]
- van Wagner, C.E.; Forest, P.; Station, E.; Ontario, C.R.; Francais, R.U.E.; Davis, H.J. Development and Structure of the Canadian Forest Fire Weather Index System; Canadian Forestry Service: Ottawa, ON, Canada, 1987. [Google Scholar]
- Oliver, M.A.; Webster, R. Kriging: A method of interpolation for geographical information systems. Int. J. Geogr. Inf. Syst. 1990, 4, 313–332. [Google Scholar] [CrossRef]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Austin, P.C. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivar. Behav. Res. 2011, 46, 399–424. [Google Scholar] [CrossRef] [Green Version]
- Rosenbaum, P.R.; Rubin, D.B. Constructing a control group using multivariate matched sampling methods that incorporate the propensity score. Am. Stat. 1985, 39, 33–38. [Google Scholar] [CrossRef]
- Rosenbaum, P.R. Observational Studies; Springer: Berlin/Heidelberg, Germany, 2002; pp. 1–17. [Google Scholar]
- Gu, X.S.; Rosenbaum, P.R. Comparison of Multivariate Matching Methods: Structures, Distances, and Algorithms. J. Comput. Graph. Stat. 1993, 2, 405–420. [Google Scholar] [CrossRef]
- Ho, D.E.; Imai, K.; King, G.; Stuart, E.A. Matching as nonparametric preprocessing for reducing model dependence in parametric causal inference. Polit. Anal. 2007, 15, 199–236. [Google Scholar] [CrossRef] [Green Version]
- Chuvieco, E.; González, I.; Verdú, F.; Aguado, I.; Yebra, M. Prediction of fire occurrence from live fuel moisture content measurements in a Mediterranean ecosystem. Int. J. Wildl. Fire 2009, 18, 430. [Google Scholar] [CrossRef]
- Vilar del Hoyo, L.; Isabel, M.P.M.; Vega, F.J.M. Logistic regression models for human-caused wildfire risk estimation: Analysing the effect of the spatial accuracy in fire occurrence data. Eur. J. Res. 2011, 130, 983–996. [Google Scholar] [CrossRef]
- Midi, H.; Sarkar, S.K.; Rana, S. Collinearity diagnostics of binary logistic regression model. J. Interdiscip. Math. 2010, 13, 253–267. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Sokal, R.; Rohlf, F. Biometry: The principles and practice of statistics in biological research. J. R. Stat. Soc. Ser. A 2012, 133. [Google Scholar] [CrossRef]
- Bisquert, M.M.; Sánchez, J.M.; Caselles, V. Fire danger estimation from MODIS Enhanced Vegetation Index data: Application to Galicia region (north-west Spain). Int. J. Wildl. Fire 2011, 20, 465–473. [Google Scholar] [CrossRef]
- Martínez, J.; Vega-Garcia, C.; Chuvieco, E. Human-caused wildfire risk rating for prevention planning in Spain. J. Environ. Manag. 2009, 90, 1241–1252. [Google Scholar] [CrossRef] [PubMed]
- Bisquert, M.; Caselles, E.; Snchez, J.M.; Caselles, V. Application of artificial neural networks and logistic regression to the prediction of forest fire danger in Galicia using MODIS data. Int. J. Wildl. Fire 2012, 21, 1025–1029. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Guo, F.; Wang, G.; Su, Z.; Liang, H.; Wang, W.; Lin, F.; Liu, A. What drives forest fire in Fujian, China? Evidence from logistic regression and Random Forests. Int. J. Wildl. Fire 2016, 25, 505–519. [Google Scholar] [CrossRef]
- Chen, M.-M.; Chen, M.-C. Modeling Road Accident Severity with Comparisons of Logistic Regression, Decision Tree and Random Forest. Information 2020, 11, 270. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An Empirical Comparison of Supervised Learning Algorithms. In Proceedings of the ACM International Conference Proceeding Series; ACM Press: New York, NY, USA, 2006; Volume 148, pp. 161–168. [Google Scholar]
- Couronné, R.; Probst, P.; Boulesteix, A.L. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Kaitlin, K.; Smith, T.; Sadler, B. Random Forest vs. Logistic Regression: Binary Classification for Heterogeneous Datasets. SMU Data Sci. Rev. 2018, 1, 9. [Google Scholar]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013; ISBN 9781118548387. [Google Scholar]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28. [Google Scholar] [CrossRef] [Green Version]
- López-Ratón, M.; Rodríguez-Álvarez, M.X.; Suárez, C.C.; Sampedro, F.G. OptimalCutpoints: An R Package for Selecting Optimal Cutpoints in Diagnostic Tests. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Goksuluk, D.; Korkmaz, S.; Zararsiz, G.; Karaagaoglu, A.E. EasyROC: An. interactive web-tool for roc curve analysis using r language environment. R J. 2016, 8, 2. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Fernández, J.; Chuvieco, E.; Koutsias, N. Modelling long-term fire occurrence factors in Spain by accounting for local variations with geographically weighted regression. Nat. Hazards Earth Syst. Sci. 2013, 13, 311–327. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984; ISBN 0412048418. [Google Scholar]
- Nembrini, S.; König, I.R.; Wright, M.N. The revival of the Gini importance? Bioinformatics 2018, 34, 3711–3718. [Google Scholar] [CrossRef] [Green Version]
- Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a new ensemble model based on SVM and random forest in forest fire susceptibility assessment and its mapping in Serbia’s Tara National Park. Forests 2019, 10. [Google Scholar] [CrossRef] [Green Version]
- Ramón González, J.; Palahí, M.; Trasobares, A.; Pukkala, T. A fire probability model for forest stands in Catalonia (north-east Spain). Ann. Sci. 2006, 63, 169–176. [Google Scholar] [CrossRef]
- Mallinis, G.; Petrila, M.; Mitsopoulos, I.; Lorenţ, A.; Neagu, Ş.; Apostol, B.; Gancz, V.; Popa, I.; Goldammer, J.G. Geospatial Patterns and Drivers of Forest Fire Occurrence in Romania. Appl. Spat. Anal. Policy 2019, 12, 773–795. [Google Scholar] [CrossRef]
- Šturm, T.; Podobnikar, T. A probability model for long-term forest fire occurrence in the Karst forest management area of Slovenia. Int. J. Wildl. Fire 2017, 26, 399. [Google Scholar] [CrossRef]
- Pourhoseingholi, M.A.; Baghestani, A.R.; Vahedi, M. How to control confounding effects by statistical analysis. Gastroenterol. Hepatol. Bed Bench 2012, 5, 79–83. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Greene, T. A Weighting Analogue to Pair Matching in Propensity Score Analysis. Int. J. Biostat. 2013, 9, 215–234. [Google Scholar] [CrossRef]
- Deb, S.; Austin, P.C.; Tu, J.V.; Ko, D.T.; Mazer, C.D.; Kiss, A.; Fremes, S.E. A Review of Propensity-Score Methods and Their Use in Cardiovascular Research. Can. J. Cardiol. 2016, 32, 259–265. [Google Scholar] [CrossRef]
- Yan, H.; Karmur, B.S.; Kulkarni, A.V. Comparing Effects of Treatment: Controlling for Confounding. Clin. Neurosurg. 2020, 86, 325–331. [Google Scholar] [CrossRef] [Green Version]
- Hudson, P.; Botzen, W.J.W.; Kreibich, H.; Bubeck, P.H.; Aerts, J.C.J. Evaluating the effectiveness of flood damage mitigation measures by the application of propensity score matching. Nat. Hazards Earth Syst. Sci. 2014, 14, 1731–1747. [Google Scholar] [CrossRef] [Green Version]
- Heyerdahl, E.K.; Brubaker, L.B.; Agee, J.K. Spatial controls of historical fire regimes: A multiscale example from the interior west, USA. Ecology 2001, 82, 660–678. [Google Scholar] [CrossRef]
- Rogeau, M.P.; Armstrong, G.W. Quantifying the effect of elevation and aspect on fire return intervals in the Canadian Rocky Mountains. Ecol. Manag. 2017, 384, 248–261. [Google Scholar] [CrossRef]
- Schwartz, M.W.; Butt, N.; Dolanc, C.R.; Holguin, A.; Moritz, M.A.; North, M.P.; Safford, H.D.; Stephenson, N.L.; Thorne, J.H.; van Mantgem, P.J. Increasing elevation of fire in the Sierra Nevada and implications for forest change. Ecosphere 2015, 6, art121. [Google Scholar] [CrossRef]
- Everett, R.L.; Schellhaas, R.; Keenum, D.; Spurbeck, D.; Ohlson, P. Fire history in the ponderosa pine/Douglas-fir forests on the east slope of the Washington Cascades. Ecol. Manag. 2000, 129, 207–225. [Google Scholar] [CrossRef]
- Castro, R.; Chuvieco, E. Modeling forest fire danger from geographic information systems. Geocarto Int. 1998, 13, 15–23. [Google Scholar] [CrossRef]
- Curt, T.; Fréjaville, T.; Lahaye, S. Modelling the spatial patterns of ignition causes and fire regime features in southern France: Implications for fire prevention policy. Int. J. Wildl. Fire 2016, 25, 785–796. [Google Scholar] [CrossRef] [Green Version]
- Zumbrunnen, T.; Pezzatti, G.B.; Menéndez, P.; Bugmann, H.; Bürgi, M.; Conedera, M. Weather and human impacts on forest fires: 100 years of fire history in two climatic regions of Switzerland. Ecol. Manag. 2011, 261, 2188–2199. [Google Scholar] [CrossRef]
- Petrić, J.; Maričić, T.; Basarić, J. The population conundrums and some implications for urban development in Serbia. Spatium 2012, 314, 7–14. [Google Scholar] [CrossRef]
- Fried, J.S.; Gilless, J.K.; Riley, W.J.; Moody, T.J.; Simon de Blas, C.; Hayhoe, K.; Moritz, M.; Stephens, S.; Torn, M. Predicting the effect of climate change on wildfire behavior and initial attack success. Clim. Chang. 2008, 87, 251–264. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.; He, H.S.; Hu, Y.; Bu, R.; Li, X. Historic and current fire regimes in the Great Xing’an Mountains, northeastern China: Implications for long-term forest management. Ecol. Manag. 2008, 254, 445–453. [Google Scholar] [CrossRef]
- Sadori, L.; Masi, A.; Ricotta, C. Climate-driven past fires in central Sicily. Plant Biosyst. Int. J. Deal. All Asp. Plant Biol. 2015, 149, 166–173. [Google Scholar] [CrossRef]
- Kalabokidis, K.; Palaiologou, P.; Gerasopoulos, E.; Giannakopoulos, C.; Kostopoulou, E.; Zerefos, C. Effect of Climate Change Projections on Forest Fire Behavior and Values-at-Risk in Southwestern Greece. Forests 2015, 6, 2214–2240. [Google Scholar] [CrossRef] [Green Version]
- Varela, V.; Vlachogiannis, D.; Sfetsos, A.; Karozis, S.; Politi, N.; Giroud, F. Projection of Forest Fire Danger due to Climate Change in the French Mediterranean Region. Sustainability 2019, 11, 4284. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Du, T.D.; Hai-Yen, H.P.; van Phong, T.; Nguyen, D.H.; van Le, H.; Mafi-Gholami, D.; et al. Performance evaluation of machine learning methods for forest fire modeling and prediction. Symmetry 2020, 12, 1022. [Google Scholar] [CrossRef]
- Xanthopoulos, G.; Calfapietra, C.; Fernandes, P. Fire Hazard and Flammability of European Forest Types. In Post-Fire Management and Restoration of Southern European Forests; Moreira, F., Arianoutsou, M., Corona, P., de las Heras, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 24, pp. 79–92. ISBN 978-94-007-2207-1. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Code | Units | Source | VIF |
|---|---|---|---|---|
| Vegetation | ||||
| Broad-leaved forest | BF | m2 | CORINE 2012 | 4.121 |
| Coniferous forest | CF | m2 | 1.160 | |
| Mixed forest | MF | m2 | 1.224 | |
| Natural grasslands | NG | m2 | 2.114 | |
| Transitional woodland-shrub | TWS | m2 | 2.482 | |
| Sparsely vegetated area | SVA | m2 | 1.066 | |
| 1 Total forested area | TFA | m2 | ||
| Anthropogenic | ||||
| Distance to Municipality | DisM | m | OpenStreetMap | 1.576 |
| Distance to Road | DisRo | m | 1.117 | |
| Distance to Rail | DisRa | m | 1.224 | |
| Population Density | PopD | N/km2 | CIESIN | 1.147 |
| Distance to Arable Land | DisAL | m | CORINE 2012 | 1.012 |
| Distance to Agricultural Land | DisAgL | m | 1.619 | |
| Topographic | ||||
| Distance to Water | DisW | m | OpenStreetMap | 1.804 |
| Slope Degree Classes * | SD.C | DEM | 1.606 | |
| Aspect Classes * | A.C4 | 2.132 | ||
| 2 Elevation Classes* | E.C2 | 1.009 | ||
| Climatic | ||||
| Drought code | DC | RHMS | 1.365 |
| LR | RF | ||
|---|---|---|---|
| Variable | Wald | Variable | Gini Impurity |
| Drought Code | 44.968 *** | Drought Code | 1 |
| Distance to Rail | 36.085 *** | Distance to Municipality | 0.697 |
| Distance to Agricultural Land | 19.407 *** | Distance to Water | 0.688 |
| Distance to Water | 18.851 *** | Distance to Rail | 0.658 |
| Natural Grasslands | 17.136 *** | Distance to Arable Land | 0.544 |
| Transitional Woodland-Shrub | 13.054 *** | Broad-Leaved Forest | 0.503 |
| Distance to Arable Land | 7.080 ** | Distance to Agricultural Land | 0.461 |
| Broad-Leaved Forest | 4.182 * | Transitional Woodland-Shrub | 0.365 |
| Population Density | 3.944 * | Natural Grasslands | 0.324 |
| Distance to Municipality | 3.694 ns | Population Density | 0.283 |
| Slope Degree Classes | 3.226 ns | Distance to Road | 0.272 |
| Distance to Road | 1.914 ns | Slope Degree Classes | 0.204 |
| Aspect Classes | 1.868 ns | Aspect Classes | 0.185 |
| Mixed Forest | 1.313 ns | Coniferous Forest | 0.093 |
| Coniferous Forest | 0.034 ns | Mixed Forest | 0.085 |
| Model | Cutoff | Predicted | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training | Validation | |||||||||
| 0 | 1 | % Correct | 0 | 1 | % Correct | |||||
| LR | 0.483 | Observed | 0 | 186 | 28 | 86.9 | 0 | 187 | 28 | 87.0 |
| 1 | 29 | 185 | 86.4 | 1 | 29 | 186 | 86.5 | |||
| Overall % | 86.7 | 86.7 | ||||||||
| RF | 0.460 | Observed | 0 | 196 | 18 | 91.6 | 0 | 192 | 23 | 89.3 |
| 1 | 19 | 195 | 91.1 | 1 | 30 | 185 | 86.0 | |||
| Overall % | 91.4 | 87.7 | ||||||||
| Forest Fire Probability Percentile | Forest Fire Probability Class | LR | RF |
|---|---|---|---|
| 0–20 | Very low | 4.7 | 8.4 |
| 20–40 | Low | 18.6 | 15.3 |
| 40–60 | Moderate | 22.8 | 17.7 |
| 60–80 | High | 21.4 | 22.3 |
| 80–100 | Very high | 32.6 | 36.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milanović, S.; Marković, N.; Pamučar, D.; Gigović, L.; Kostić, P.; Milanović, S.D. Forest Fire Probability Mapping in Eastern Serbia: Logistic Regression versus Random Forest Method. Forests 2021, 12, 5. https://doi.org/10.3390/f12010005
Milanović S, Marković N, Pamučar D, Gigović L, Kostić P, Milanović SD. Forest Fire Probability Mapping in Eastern Serbia: Logistic Regression versus Random Forest Method. Forests. 2021; 12(1):5. https://doi.org/10.3390/f12010005
Chicago/Turabian StyleMilanović, Slobodan, Nenad Marković, Dragan Pamučar, Ljubomir Gigović, Pavle Kostić, and Sladjan D. Milanović. 2021. "Forest Fire Probability Mapping in Eastern Serbia: Logistic Regression versus Random Forest Method" Forests 12, no. 1: 5. https://doi.org/10.3390/f12010005