Abstract
The study on the spatial distribution of forest soil nutrients is important not only as a reference for understanding the factors affecting soil variability, but also for the rational use of soil resources and the establishment of a virtuous cycle of forest ecosystems. The rapid development of remote sensing satellites provides an excellent opportunity to improve the accuracy of forest soil prediction models. This study aimed to explore the utility of the Gaofen-1 (GF-1) satellite in the forest soil mapping model in Luoding City, Yunfu City, Guangdong Province, Southeast China. We used 1000 m resolution coarse-resolution soil map to represent the overall regional soil nutrient status, 12.5 m resolution terrain-hydrology variables to reflect the detailed spatial distribution of soil nutrients, and 8 m resolution remote sensing variables to reflect the surface vegetation status to build terrain-hydrology artificial neural network (ANN) models and full variable ANNs, respectively. The prediction objects were alkali-hydro-nitrogen (AN), available phosphorus (AP), available potassium (AK), and organic matter (OM) at five soil depths (0–20, 20–40, 40–60, 60–80, and 80–100 cm). The results showed that the full-variable ANN accuracy at five soil depths was better than the terrain-hydrology ANNs, indicating that remote sensing variables reflecting vegetation status can improve the prediction of forest soil nutrients. The remote sensing variables had different effectiveness for different soil nutrients and different depths. In upper soil layers (0–20 and 20–40 cm), remote sensing variables were more useful for AN, AP, and OM, and were between 10%–14% (R2), and less effective for AK at only 8% and 6% (R2). In deep soil layers (40–60, 60–80, and 80–100 cm), the improvement of all soil nutrient models was not significant, between 3 and 6% (R2). RMSE and ROA ± 5% also decreased with the depth of soil. Remote sensing ANNs (coarse resolution soil maps + remote sensing variables) further demonstrated that the predictive power of remote sensing data decreases with soil depth. Compared to terrain-hydrological variables, remote sensing variables perform better at 0–20 cm, but the predictive power decreased rapidly with depth. In conclusion, the results of the study showed that the integration of remote sensing with coarse-resolution soil maps and terrain-hydrology variables could strongly improve upper forest soil (0–40 cm) nutrients prediction and NDVI, green band, and forest types were the best remote sensing predictors. In addition, the study area is rich in AN and OM, while AP and AK are scarce. Therefore, to improve forest health, attention should be paid to monitoring and managing AN, AP, AK, and OM levels.
1. Introduction
The spatial distribution of forest soil nutrients is directly related to the growth and health of forests and has an important influence on forest ecosystem restoration and sustainable management [1]. Forest soil nutrients are essential components of forest tree growth and development, and their availability to the forest is determined by their state in the soil [2]. Available nutrients are water-soluble and exchangeable elements in the soil. They can be directly absorbed and used by plants or quickly exchanged from soil colloid for plant use; alkali-hydro-nitrogen (AN), available phosphorus (AP) and available potassium (AK), have a significant correlation with soil fertility [3]. Total nitrogen (TN), total phosphorus (TP) and total potassium (TK) are the sum of available and unavailable nitrogen, phosphorus and potassium in the soil, respectively, and have a slight correlation with soil fertility [4]. Organic matter (OM) is all kinds of carbon-containing organic compounds in the soil, one of the primary sources of plant nutrition [5]. Thus, high-resolution maps of depth-specific soil nutrients clarifying their main controlling factors are essential for forest culture, forest management policies, regional soil degradation, and climate change study [1].
To date, various methods have been developed to produce soil nutrient maps, some of which include spatial interpolation methods [6], linear regression models [7], co-kriging [8] and regression kriging [9]. These methods require many sample points and hypotheses predetermining the relationships between soil texture and predictors [10,11]. However, when the soil nutrient prediction is performed at a large scale and in a diversified environment, sample points are scarce. Moreover, the relationship between soil nutrients and the environment variables is a nonlinear process [11]. Artificial intelligence technology is considered an appropriate and useful method to obtain a more detailed spatial distribution map of soil nutrients with auxiliary environmental variables [12,13]. Representative achievements have included McBratney et al.’s [14] use of an Artificial Neural Network (ANN) model to predict soil physical properties; regression tree and spline function were proposed to estimate 1 m deep soil organic carbon (SOC) [13]. Taghizadeh-Mehrjardi et al. [15] reported that an ANN showed the highest performance for prediction of SOC in the four standard depths compared to five other data mining techniques. Research has proven that the detailed spatial distribution of soil nutrients can be modelled with high-resolution terrain-hydrology variables at a local level [16] because water movements along terrain gradients preferentially transfer soil components such as SOM, nutrient elements, and fine soil particles [17]. The terrain is only one of the five major soil forming factors, however, and relying on it alone is not enough to perfectly model the spatial variation of soil nutrients. Therefore, the growth of precision agriculture has created an urgent need to provide more available data sources to make soil science more rigorous [18].
According to Zhao et al. [19,20] and Ding et al. [21], average soil properties are related to geological formations, parent materials and climate that could be captured by existing coarse-resolution soil maps. Coarse resolution maps are important for the production of soil maps. In addition, Ballabio et al. [22] concluded that vegetation is the most important factor affecting soil nutrients in the organism. Remote sensing data provide information about soil nutrients from direct images of bare soils [23]. However, soils are usually covered by vegetation in the forest, which obviously has impacts on the application of remote sensing data for soil mapping because remote sensors cannot directly detect soils, and remote sensing images reflect ground vegetation [24]. The reflectance of the ground vegetation varies with wavelength, and different vegetation conditions have different reflectance spectral characteristics. Vegetation indices are formed by combining the visible and near infrared bands of satellites based on the spectral characteristics of vegetation. Vegetation indices are simple, valid, and empirical measures of surface vegetation conditions [18]. Given this background, many previous DSM studies have incorporated vegetation indices and spectral reflectance from optical images into soil prediction models in areas covered by vegetation [25,26]. This approach is promising because vegetation is viewed as a crucial determinant of soil formation through its impacts on soil biophysical processes, and, in turn, is a strong indicator of the spatial variation of soil nutrients. Consequently, we gain insight into the spatial distribution of soil nutrients through quantifying the variability of remote sensing vegetation features [24]. Odebiri et al. [27] found that the critical environmental variable of soil nutrient prediction in densely forested areas is remote sensing data. Based on previous research, the remote sensing images of the Landsat series satellite are the most widely used. However, as the first high-resolution earth observation satellite in China, the Gaofen-1 (GF-1) satellite has an important strategic significance for developing remote sensing technology. The remote sensing images obtained by GF-1 have a shorter revisit period (4d) and higher spatial resolution (8 m/16 m), and it is easier to show detailed surface features and fragmentation features [28]. At present, GF-1 images are mainly used for forest detection, ground object identification and disaster monitoring. However, their application in DSM has not been explored or developed to its full potential.
An approach combining the ANN model with GF-1 remote sensing variables to predict nutrients in a forest site has not been reported. Thus, this study seeks to combine the GF-1 satellite to improve the accuracy of traditional terrain-hydrology soil models. The purpose is to find the most suitable prediction model to map five forest soil depths of AN, AP, AK, and OM. The specific research objectives were to: (1) select the combination of optimal variables for all ANN models for each depth and evaluate model performance and prediction performance outside of the area used for model development; (2) use the selected model to produce depth-specific soil element maps in the study area; and (3) evaluate the effects of the used remote sensing variables and terrain-hydrology variables on depth-specific soil elements.
2. Materials and Methods
2.1. Study Area
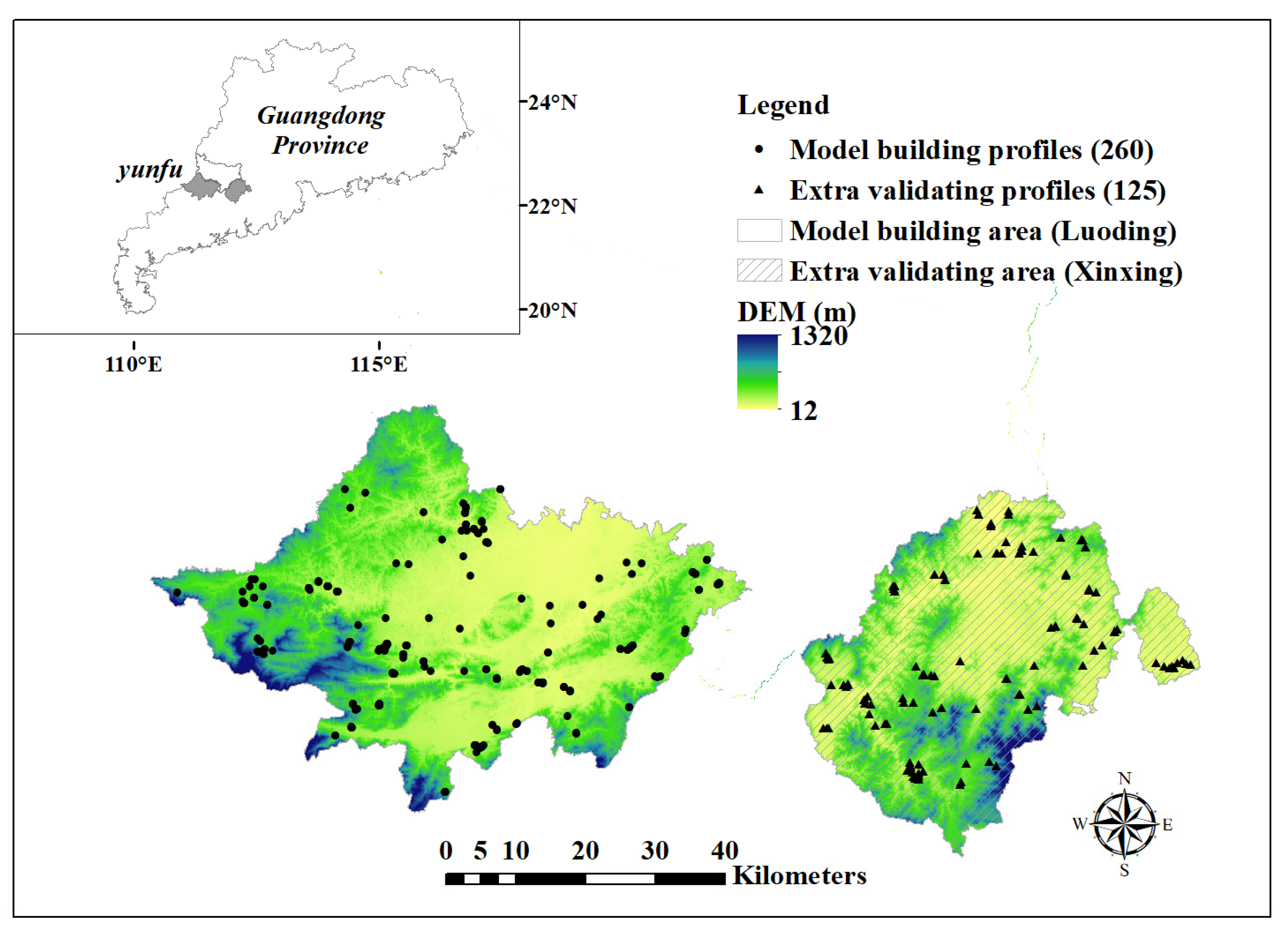
The model building area (22°25′–22°57′ N, 111°03′–111°52′ E) was Luoding City, which is located in the southwestern Yunfu City, Guangdong Province, China, with 1426.9 km² of its total 2327.5 km² area forested. The extra validation area was Xinxing County (22°22′–22°5′ N, 111°57′–112°31′ E), which is located in the southeastern Yunfu City, with 1008.4 km² of its total 1521.7 km² area forested, see Figure 1. The two study areas are in the subtropical monsoon zone, with high temperature and ample precipitation in the same period (May–October), which is conducive to plant growth [21]. The two areas are mountainous regions with elevations ranging from 12 to 1320 m. In both study areas, tropical monsoon forest types are dominated by natural secondary evergreen broad leaved forests, coniferous forests, and mixed forests. The main coniferous species are Pinus massoniana, Eucalyptu ssp. and Cunninghamia lanceolate, and the main broad leaved tree species include Chenopodium album, Liquidambar formosana, and Cinnamomum camphora (Guangdong Forestry Survey and Planning Institute, Guangzhou, China, 2014). As economic forests occupy larger and larger areas, human management activities on forests are intensifying, affecting the structure and fertility of forest soils. As a result of local climate, terrain, and vegetation type, the two study areas comprised Typic Kanhapludults (Lateritic Red Earths) and Typic Hapludults (Red Earths). Udults is the common soil type in tropics and subtropics of China, and it is rich in iron and aluminum as a result of desilication. In nature, the content of N, P, K and OM are low because of the strong physical and chemical weathering of soil minerals, the rapid decomposition of OM and the massive leaching of nutrients in the field [20]. Based on this, high-resolution three-dimensional models are effective to analyze and predict the spatial distribution of forest soil nutrients.
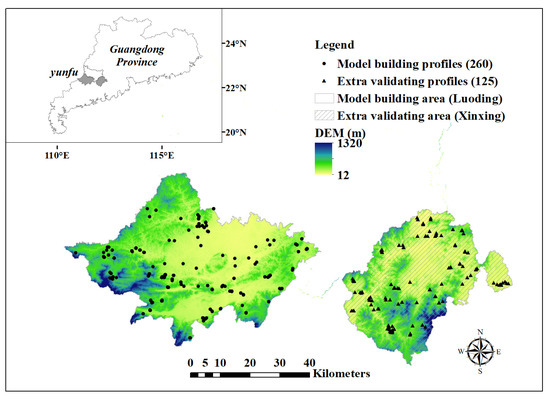
Figure 1.
DEM and soil profile distribution in model building and extra validating areas.
2.2. Data Sources
In this study, the coarse-resolution soil nutrient maps at 1000 m resolution represented the overall state of forest soil nutrients, the 12.5 m resolution digital elevation model (DEM)-derived terrain-hydrology variables represented the detailed forest soil nutrients change caused by terrain-hydrology conditions, and the 8 m resolution GF-1 satellite-derived band reflectance and vegetation indices represented the detailed forest soil nutrient variation caused by vegetation (see Table 1). All variable maps from various sources were interpolated into 10 m resolution raster format using the conventional inverse distance weighted approach. The pixel values of the raster layers (environmental variables) that corresponded to the coordinates of sampling points were extracted to build the model.

Table 1.
Input variables for Model A, Model B, and Model C.
2.2.1. Coarse-Resolution Soil Map and Soil Sampling
A coarse-resolution soil nutrient map roughly reflects the spatial distribution of soil nutrients in large-scale areas. In this study, a 0–20 cm coarse-resolution soil nutrient map (http://www.soilinfo.cn/map/index.aspx (accessed on 27 October 2018)) was used, and the basic necessary input variables, including coarse resolution alkali hydro nitrogen (CAN), coarse resolution available phosphorus (CAP), coarse resolution available potassium map (CAK), and coarse resolution organic matter map (COM), were obtained from the Institute of Soil Research, Chinese Academy of Sciences with a scale of 1:1,000,000. Soil vector maps (1:1,000,000 scale) were converted into 1000 m resolution raster maps in ArcGIS 10.2, and then resampled to 10-m resolution. In this study, a coarse resolution soil map represents the soil nutrient average value in the field. The soil nutrient content provided by the coarse-resolution soil nutrient map is the basis for model construction, and both terrain-hydrology and remote sensing variables are used to respond to more details.
The soil profiles (n = 385) for building (260) and validating (125) were collected by the 2015 Forest Soil Survey Project of Guangdong Academy of Forestry Sciences, taking soil type, terrain-hydrology conditions, and vegetation characteristics into consideration. Two sample schemes, including thematic distribution and random distribution, were used to set the sample points. Based on these conditions, the soil samples were small in number but were representative soil points for the area. The distribution of the sample points is shown in Figure 1. The latitude and longitude of all soil points were located by a hand-held GPS (global positioning system) receiver, and the positioning accuracy was 5 m. A 1 m deep soil pit was dug at each sample site. If the profile had no record before 1 m depth, the soil profile was excavated to the parent material horizon. Each soil profile was divided into five depth intervals: 0–20 cm (D1), 20–40 cm (D2), 40–60 cm (D3), 60–80 cm (D4), and 80–100 cm (D5). Sampling stratification was based on the coarse-resolution soil nutrient maps to obtain enough samples within every class of soil elements. Each soil sample was air-dried, ground, passed through 2 mm sieves, and stored in glass bottles for further analysis. The NaOH alkali solution expansion method and NaHCO3 extraction molybdenum blue colorimetric method were used to determine AN concentrations and AP concentrations, respectively. A NH4OAC extraction-flame photometric method was used to measure AK content and a dichromic acid oxidation–external heating method to estimate OM [17,29].
2.2.2. Terrain-Hydrology Variables
Moore, I.D. et al. [30] summarized the significance and physical meaning of various terrain attributes to landscape processes. Building on their work, many authors have used terrain attributes derived from DEM as explanatory variables in predictive soil models [31]. Terrain affects water movement, which involves the transportation and deposition of sediment. In the model building area, nine terrain hydrology variables, including slope, aspect, topographical position index (TPI), potential solar radiation (PSR), depth to water (DTW), sediment delivery ratio (SDR), flow length (FL), flow direction (FD), and soil terrain factor (STF), were derived from DEM images. Detailed information is shown in Table 1. The DEM was obtained from Cartosat-1 (IRS P5) with a 12.5 m resolution of Guangdong Academy of Forestry Sciences and was resampled to 10 m raster using ArcGIS 10.2 software. The spatial analyst extension tools and developed forest hydrology tools of ArcGIS were used to generate terrain and hydrology variables [32]. Terrain-hydrology variables affect the accumulation of forest soil nutrients in the region.
2.2.3. Remote Sensing Variables
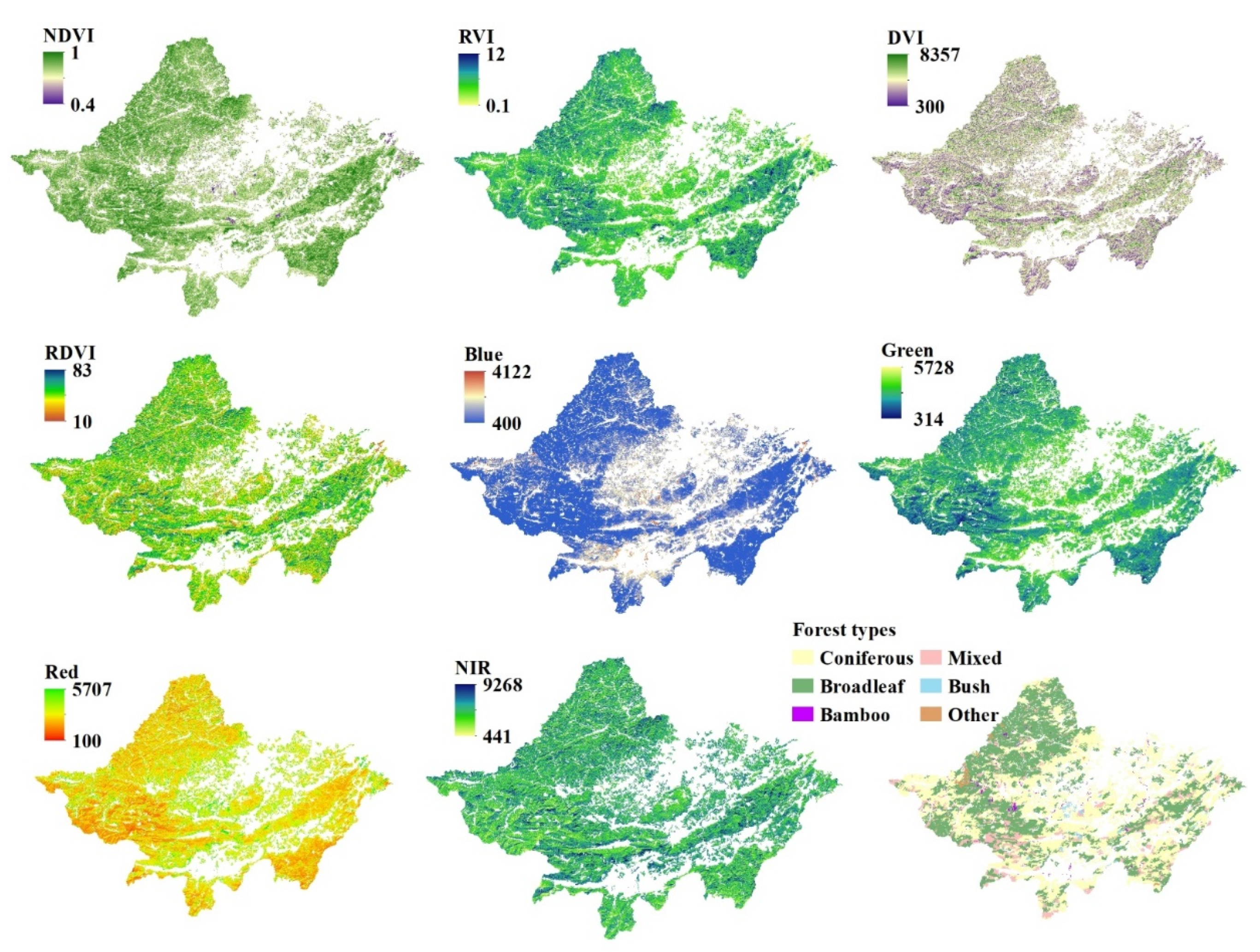
In nature, vegetation litter is the main source of forest soil nutrients. Vegetation density and vegetation type determine the amount of litter, and the root condition of vegetation affects its ability to absorb soil nutrients. Remote sensing images provide direct land vegetation information. Therefore, the close relationship between vegetation variables and soil nutrients allows remote sensing variables that reflect the condition of vegetation to be applied to forest DSM work [33]. The clearest 8 m resolution GF-1 multi-spectral remote sensing images covering the model building area were downloaded from the geospatial data cloud website (http://www.gscloud.cn (accessed on 9 May 2016)). Firstly, remote sensing images were pre-processed by ENVI 5.3 software, including radiometric calibration, atmospheric correction, geometric correction, mosaic, cropping, and resampling to the 10 m resolution. In this study, the remote sensing variables included four bands of GF-1, including the blue band (B), green band (G), red band (R), and near infrared band (NIR). These bands were selected because they represented the growth and biomass of vegetation. We also used the band math function of ENVI 5.3 to extract four plant indices: NDVI (normalized difference vegetation index), DVI (difference vegetation index), RVI (ratio vegetation index), and RDVI (renormalized difference vegetation index). Some information on remote sensing variables is shown in Table 1. Vegetation indices are effective indicators for detecting vegetation growth status, vegetation cover, and eliminating some radiation errors. In remote sensing science, NDVI is widely used in forest growth monitoring and yield prediction [34] and is an uncertain graphical sign that can be employed to outline the greenness, relative density, and healthiness of vegetation [35]. DVI is very sensitive to the change in soil background, and it increases rapidly with an increase in vegetation [36]. RVI can better reflect the difference in vegetation coverage and growth status, which is especially suitable for vegetation monitoring with vigorous growth and high coverage [37]. RDVI is commonly used to investigate plants at the growth stage and the greenness present in the vegetation [38].
The hierarchical classification method was used to classify forest types from the processed 8 m resolution images in the eCognition 9.0 software to improve the accuracy of forest classification. The mixed forest, coniferous forest, and broad-leaved forest were automatically classified according to the spectral characteristics, geometric characteristics, texture characteristics, and vegetation indexes of the segmented objects. Samples of 900 forest types were taken from the forest class vector map of Luoding City provided by the Guangdong Academy of Forestry Sciences and randomly divided into two parts, in which 600 samples were used for classification training, and 300 samples were used for accuracy verification. The “Feature Space Optimization” module of eCognition was used to select the features with the best separation. The first step was to distinguish between the vegetation area and the non-vegetation area. Next, we determined the forest land and the cultivated land in the vegetation areas. Finally, we divided the forest land into conifers, broad-leaved forests, and mixed forests. The “Error Matrix based on Sample” in eCognition was used for classification accuracy evaluation. The overall accuracy was 0.81 and KIA (Kappa coefficient) was 0.77. The overall accuracy and KIA reflect the classification accuracy of the whole map. Broad leaved forest, coniferous forest, and mixed forest were the main forest types in the area, but bamboo and other kinds of vegetation were too small for automatic classification. Therefore, these plants were distinguished according to the forest class vector map [39]. Finally, resampling the forest type image to the 10 × 10 m resolution corresponded to other variable raster maps. The forest types and other eight remote sensing variables obtained from GF-1 are shown in Figure 2.
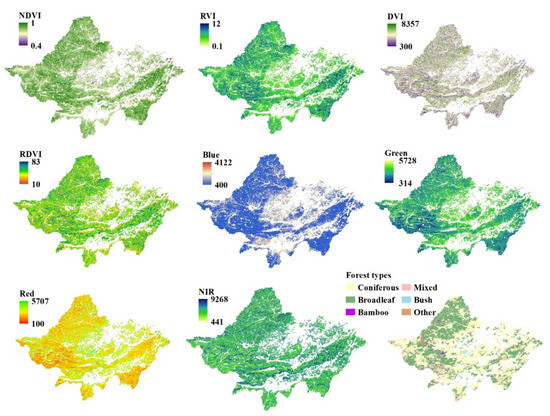
Figure 2.
Nine remote sensing variable images derived from GF-1.
2.3. Artificial Neural Network Model
We applied the ANN model, a machine learning algorithm developed by Zhao et al. [17,40,41], to predict the spatial distribution at 1 m depth of AN, AP, AK, and OM by MATLAB 2016 software. The most common ANN type is a multi-layer perceptron with three layers: input layer, output layer, and hidden layer. The input layer contained in-dependent variables used to make a model prediction (the coarse-resolution nutrient maps, the DEM-generated terrain-hydrology variables, and GF-1-generated remote sensing variables). The output layer contained the prediction dependent variable (the measured data of AN, AP, AK, and OM). The input layer and the output layer were connected by a hidden layer whose number of neurons determined the complexity of the ANN model: too many hidden neurons will cause over-fitting, and too few hidden neurons will lead to poor fit. All links between the input and hidden layers form the input weight matrix, and all links between the hidden and output layers form the output weight matrix [42]. The ANN model was trained using a back-propagation technique that adjusted the weight and bias values along a negative gradient descent, using the Levenberg Marquardt algorithm [43] to minimize the mean squared error (MSE) between the network output (predicted value) and the target value (measured value). When MSE is less than 0.01, the training stops. A 10-fold cross-validation was used to evaluate and train the ANNs; the entire model building area data set (260 soil profiles) was divided into 10 equal subsets. The data from 9 subsets were used as calibration data to build the model, and the remaining subsets were used as data for validation. This process was repeated 10 times until all subsets were used as the validation set. Meanwhile, an early stopping method was used to avoid “over-fitting”, which uses a training set (80% of the calibration data) to calculate the gradient, update the network weights, and estimate the bias. The testing dataset (20% of the calibration data) was used to monitor the training process to prevent overfitting. If the training MSE decreases but the test MSE increases, the training of the ANN model was stopped assuming that the most appropriate model coefficients had been obtained. According to previous studies [40,41], the number of hidden layer neurons changed from 5 to 40. Finally, 35 neurons in the hidden layer were the best structure in this study.
Screening and Assessing ANN Models
In this study, 260 soil samples of each soil depth were used to build, train, and evaluate the ANN model in the model building area (Luoding City). Xinxing County, which had 125 sample profiles, served as an independent verification area outside the ANN model building area to test the generalization ability of the selected ANN model. Three indexes were adopted to compare the performance of the ANN model accuracy, including root mean square error (RMSE), coefficient of determination (R2), and relative overall accuracy (ROA ± 5%). According to the three model evaluation indexes, the best model appears when the model precision is not obviously improved after other variables are added. Therefore, the best model should have a relatively higher R2 and ROA ± 5% and lower RMSE. The specific formulas were as follows:
where is the predicted value; is the measured value; is number of sample points; is the average value of the model’s predicted values; T is the accuracy threshold (e.g., 5 for 5% in this study) determined based on target to fit the model.
3. Results
3.1. Exploratory Data Analysis
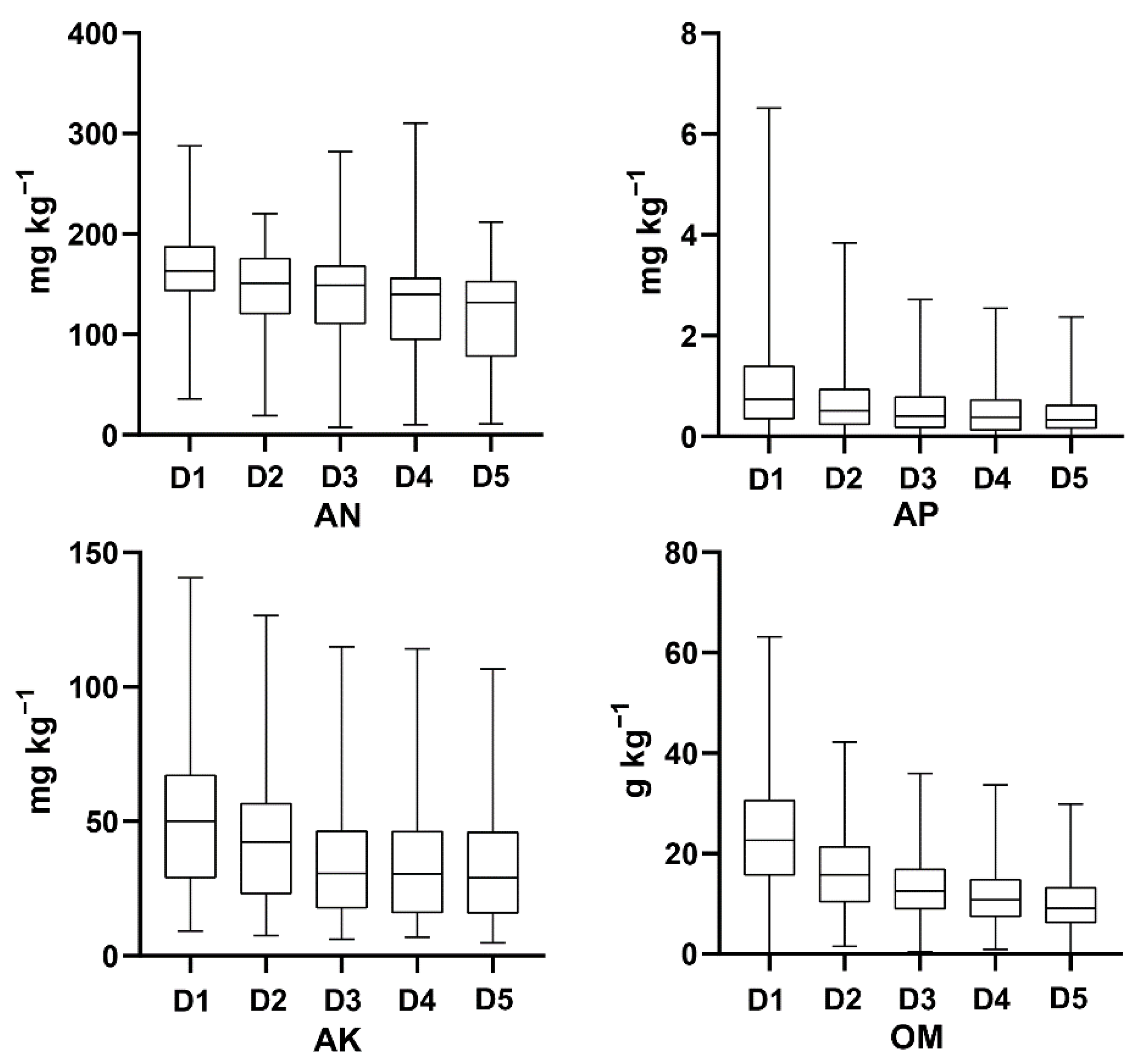
In total, the measured soil nutrient data from 260 soil profiles in Luoding City and 125 soil profiles in Xinxing County were used in this study. The statistical results of AN, AP, AK, and OM are shown in Figure 3. The boxplot was drawn using GraphPad Prism 8.0 software. AN content varied from 7.44 to 310.07 mg kg−1 with the most significant variation at D4 from 10.33 to 310.07 mg kg−1. AP content was from 0.01 to 6.52 mg kg−1, AK content was from 4.80 to 140.62 mg kg−1, and OM content was from 0 to 63.20 g kg−1; these three nutrient elements had the most significant variation at D1. The mean of the four soil nutrients showed a general decreasing trend in variation from D1–D5. AK and OM means at D3, D4, and D5 were about two times lower than D1, but AN and AP means at each depth did not significantly change. Using ArcGIS software to analyze the spatial autocorrelation of the samples, the results show that the Moran index (I) approaches 0, showing weak autocorrelation.
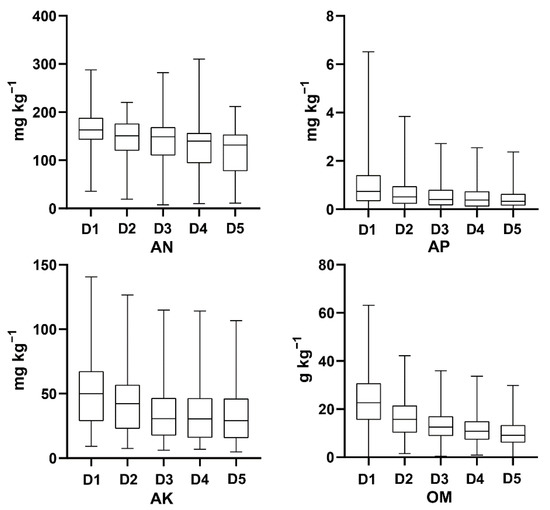
Figure 3.
Descriptive statistics of available nutrients (mg kg−1) and organic matter (g kg−1). D1: 0–20 cm; D2: 20–40 cm; D3: 40–60 cm; D4: 60–80 cm; D5: 80–100 cm. AN: alkali-hydro-nitrogen; AP: available phosphorus; AK: available potassium; OM: organic matter.
3.2. Optimal Variables Combination of Each Soil Depths
The accuracy results of the Model A are shown in Table 2. For each depth, based on coarse-resolution data, model prediction performance was significantly improved by increasing terrain-hydrology variables. Still, this improvement was not sustainable when the additional variable exceeded a certain degree. Taking AN as an example, the accuracy of the Model A in D1 was significantly improved by gradually adding the terrain-hydrology variable from one to six, decreasing the RMSE values from 1536.42 to 863.56, 823.64, 580.53, 528.38 and 495.68 mg kg−1, increasing the R2 values from 0.23 to 0.55, 0.58, 0.71, 0.74 and 0.76%, and increasing the ROA ± 5% values from 55 to 59, 66, 70, 71, and 74%, respectively. However, when further adding the seventh, eighth, and ninth terrain variables, RMSE values increased from 593.21 to 638.11 and 748.31 mg kg−1, R2 values decreased from 72 to 69 and 67%, and ROA ± 5% values decreased from 72 to 69 and 68%, respectively. This was not a surprise because the additional variables were based on their order of importance to soil nutrients. The added variables were less important to the soil nutrients. Therefore, the optimal variables combined for the D1 layer of AN were SDR, Slope, Aspect, DTW, TPI, and FD. On the other hand, the additional input variables may have introduced more uncertainty because of their own precision and accuracy, thus limiting the model’s prediction performance. Based on this selection scheme, the optimal Model A, Model B, and Model C of all soil layers were generated by this screening method. The slope and aspect appear in all selected optimal Model A in Table 2, indicating that slope and aspect had a huge impact on the distribution of soil nutrients. Table 3 and Table 4 show the prediction accuracies for the Model B and Model C fore four soil nutrient contents, respectively. Model B had better predictive performance than the Model A. In Table 3, the NDVI, G, and forest have the highest occurrence frequency, indicating that they had the greatest influence on soil nutrients among the nine remote sensing variables.
Table 2.
Optimal variable combination and accuracies of the terrain hydrology ANN model (Model A) of soil nutrients.
Table 3.
Optimal variable combination and accuracies of full variables ANN model (Model B) of soil nutrients.
Table 4.
The optimal accuracies of remote sensing ANN model (Model C) of soil nutrients.
This study mainly compared the performance of the Model A and Model B that are shown in Table 2 and Table 3. The full-variable ANNs (Model B) presented the best prediction performance, exhibited the lowest RMSE, the highest R2 and ROA ± 5%. This was expected because when the terrain-hydrology ANNs (Model A) accepts more helpful information, the prediction accuracy will naturally improve. Moreover, compared with the Model A, the Model B showed that the improved scales of surface soil depths (D1 and D2) were more significant than deep soil depths (D3, D4, and D5). In the Model B, the R² of AN at D1 and D2 layers increased 13 and 12%, while the D3, D4, and D5 layers only increased 6, 5, and 5%, respectively. The R² of AP for D1 and D2 increased 13 and 12%, but D3, D4, and D5 only increased 5, 5, and 6%, respectively. The R² of AK for D1 and D2 increased 8 and 6%, and D3, D4, and D5 increased 4, 5, and 5%, respectively. The R² of OM for D1 and D2 increased 14 and 10%, and D3, D4, and D5 only increased 5, 4, and 3%, respectively. For the other two accuracy evaluation indexes, RMSE and ROA ± 5% also showed a similar trend. This revealed that remote sensing variables were limited in improving the accuracies of AN, AP, AK, and OM. In addition, remote sensing variables had different performances for different soil nutrients and different depths. The more effective for AN, AP, and OM at 0–40 cm were between 10–14% (R2), the less helpful for AK at 0–40 cm were only 8 and 6% (R2), and the improvement of all deep soil layers (40–100 cm) was not significant. The results of remote sensing ANNs (Model C) further support this conclusion that the model prediction accuracies decrease rapidly with depth and have poor predictive power for AK.
3.3. Performance of ANN Model Outside of the Model-Building Area
In an attempt to truly test the capability of generalization, the optimal models for D1-D5 built with the 260 soil profiles from Luoding (model building area) were used to estimate AN, AP, AK, and OM content in Xinxing (the extra validating area). The accuracies of the extra validating area (125 soil profiles) are shown in Table 5. The five soil layers of each soil nutrient index’s prediction ability decreased in the extra validation area. Compared with the building accuracy, the RMSE of extra validation accuracy rose by 65.77–105.08 mg kg−1 for AN, 0.08–0.15 mg kg−1 for AP, 35.50–57.50 mg kg−1 for AK, and 1.02–4.35 g kg−1 for OM; the R2 decreased by 25–34% for AN, 27–39% for AP, 32–44% for AK, and 23–42% for OM; and the ROA ± 5% declined by 26–40% for AN, 20–39% for AP, 24–44% for AK, and 24–38% for OM. The prediction ability declined to a certain extent, indicating that the early stopping technology played a limited role in preventing the over-fitting of the model training data set. However, the three evaluation indexes still showed a good prediction capability, close to or better than that of others [13,44,45]. The complexity of the network architecture was adequate because the extra validation showed that the model’s ability developed to generalize predictions. The optimal ANN model screened from the model building area can be applied in similar areas.
Table 5.
Evaluation of model performances calculated from the extra validation area.
3.4. Spatial Prediction of Soil Nutrients
Our model results showed that the Model B performs best, so it was selected to predict the spatial distribution of topsoil (D1) AN, AP, AK, and OM contents with a resolution of 10 × 10 m grid (Figure 4). Table 6 also summarizes the prediction mean and standard deviation for AN, AP, AK, and OM contents at different soil depths. Mean values of soil nutrients decreased with the depth of soil. The average values for AN content varied from 133.91 to 159.93 mg·kg−1 with soil depths, AP content ranged from 0.53 to 0.96 mg·kg−1, AK content changed from 37.78 to 49.94 mg·kg−1, and OM content ranged from 10.05 to 23.17 g·kg−1. The average content of each soil layer showed little difference, indicating that the soil nutrient surface aggregation was not significant in the model building area. Moreover, as a whole, the standard deviation of the predicted value was lower than that of the measured value, indicating that the predicted result was more stable. For a real analysis of the stability of predictions, we calculate the standard errors (SE) for the 10 maps produced by the 10 best ANN models obtained from the 10-fold cross-validation. The low prediction SE map of D1 for AN in Figure 4e further demonstrates the good performance of the constructed ANN. Figure 4f–i, show a partial enlargement of Figure 4a–d, showing detailed information and covering the boundary of the coarse-resolution maps. The boundaries of coarse-resolution maps were faintly visible in the generated maps, indicating that the coarse-resolution maps had a small impact on the generated map.
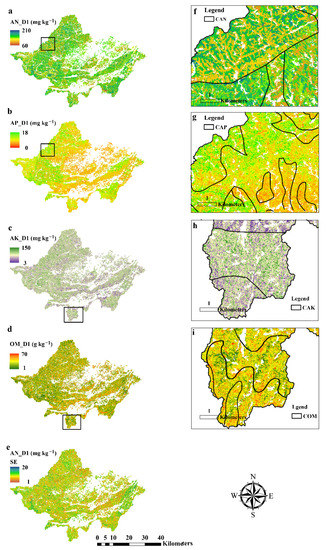
Figure 4.
The spatial distribution of the D1 layer of AN (a), AP (b), AK (c), and OM (d). (e) is the standard error map of the D1 layer of AN. (f–i) represent a highlighted area in (a–d), respectively, showing detailed information and covering the boundary of the coarse-resolution maps.
Table 6.
Statistics of the predicted values for each soil layer.
4. Discussion
4.1. Assessment of Prediction Models
Soil nutrients affect the healthy growth of trees and the stability of ecosystems and are an important indicator for evaluating soil quality. The integration of remote sensing variables in forest soil nutrient prediction is the trend in this field. In this study, when nine GF-1 derived remote sensing variables were added to the terrain-hydrology ANNs, there was a good improvement in the model prediction accuracy, which was consistent with the reports of Wang et al. [46] and Zhou et al. [26]. They believed that the total variable model was more successful than the terrain-hydrology model in predicting soil properties.
We conclude that these variables had good performance in mapping soil nutrient content, the nonlinear modality of responses, and the complex interaction between input variables. Compared with similar studies, our model has superior predictive performance. Wang et al. [18] found that the RF model, combined with all variables (including topography, climate, and remote sensing images), had the best prediction performance (R2 = 0.71) for soil nitrogen. Odebiri et al. [27] used Landsat 8 to predict SOC and the ANN model accuracy was 0.77 (R2) in commercial forests. Most of the studies used Landsat series satellite images with 30 m resolution to produce soil maps [31,42,47,48]. We used 8 m resolution remote sensing images to produce higher resolution forest soil nutrient maps. Highly accurate spatial distribution models of forest soil nutrients facilitate forestry management decisions.
By comparing Table 2 and Table 3, we found that the scale of uplift was more significant in the topsoil (0–40 cm) and lower in the deep soil (40–100 cm). This was consistent with the results of Kempen et al. [49], Minasny et al. [12], and Liu et al. [50], who all reported that the performance of three-dimensional mapping methods decreased with depth. The results of remote sensing ANNs (model C) further demonstrated that the prediction accuracies of remote sensing variables decreased rapidly with soil depth. This may be due to the reduced mapping ability of auxiliary environmental variables. Most of the ancillary data used could not effectively capture the soil nutrient variation in these layers (40–100 cm). Their uncertainty increased with depth, increasing the model’s prediction uncertainty in deep soil depths. In the deep soil layers (D3, D4, and D5), the remote sensing variables made little difference in the prediction of AK, AN, AP, and OM. In the surface soil layers (D1 and D2), there was a poor prediction performance for AK, and the model accuracy only improved by 8 and 6% (R2), respectively. It may be that the selected remote sensing variables were less sensitive to AK. However, the prediction accuracies of terrain-hydrology (Model A) had no significant difference at different soil depths, which is consistent with the findings of Zhao et al. and Ding et al. [17,21]. The predictive power of DEM-derived terrain-hydrology data is similar for different soil layers.
4.2. Effect of Remote Sensing Data on Predicting Soil Nutrients
Given the close relationship between soil and vegetation conditions, many studies have used remote sensing variables that reflect vegetation conditions as auxiliary variables to predict soil nutrients Vegetation is the main source of soil nutrients, as it controls the amounts of AN, AP, AK, and OM entering the soil [51]. Its effects on soil biophysical processes and, in turn, the distribution of plant communities, are affected by soil nutrients [22,26]. Different vegetation statuses have different reflection capabilities in the visible light range. They have been recorded by the sensor forming different spectral curves, showing different DN values in remote sensing images. Analyzing and interpreting of vegetation conditions recorded on remote sensing images can reflect soil nutrients in a certain sense. Kim and Grunwald [52] demonstrated that remote sensing variables closely related to vegetation could represent the spatial variability and quantity of SOC. The results from model C showed that the remote sensing variables performances close to or better than the terrain-hydrology variables in the topsoil layer (D1). Judging from the optimal Model B in Table 3, the most critical remote sensing band for predicting soil nutrients was the G band in Table 3. Yang et al. [48] believed that the G band was an influential variable to characterize vegetation density and biomass, so it was an important predictor of soil nutrients [53]. To measure absorption characteristics, some scholars focus on vegetation indices that are more beneficial than individual bands because they minimize the effects of interfering external factors such as sun, viewpoint, and lighting conditions. The use of vegetation indices can help us to understand some plant conditions, including vegetation land cover, biomass, crop production, and plant health [47]. In Table 3, NDVI showed the most robust predictive ability in predicting AN and AK. Based on AN (D1) in the Model A, by adding only NDVI the RMSE was reduced 48.01 mg kg−1, R² and ROA ± 5% increased 3 and 10%, respectively. The finding indicated that NDVI could significantly improve the accuracy of AN in topsoil (D1). That was consistent with previous studies. Dematte et al. [54] believed that NDVI plays a vital role in describing soil nitrogen index spatial patterns. In this study, forest types were the most important predictor for OM. The primary source of soil nutrients is vegetation litter. The denser the vegetation, the more litter there is [55]. However, the characteristics of plant litter are also important reasons. The decomposition rate of coniferous species leaf litter is slow, which leads to low nutrient content, but the leaf litter of broad-leaved trees decomposes easily, so the nutrient content is higher [56]. Furthermore, some deciduous broad-leaved forests have seasonal defoliation, leading to increased nutrient content in the soil. In Guangdong Province, Liu et al. [57] found a significant relationship between forest species and OM content, which is consistent with this study that forest type is the most important predictor of OM. Different forest types have different litter properties and climatic conditions, which in turn lead to spatial differences in soil nutrients. Based on our current study results, G, NDVI, and forest types were the best remote sensing predictors in soil mapping. These indicators were most sensitive to alteration in vegetation cover, vegetation pigment contents, and leaf water. They have been successfully used to evaluate vegetation cover status, predict soil nutrients and soil salinity, etc. [58,59]. Therefore, spectral reflection and vegetation indices can be introduced as indirect indicators to understand the status of soil nutrients.
4.3. Effect of Terrain-Hydrology Data on Predicting Soil Nutrients
Pouladi et al. [60] believed that when the sampling points were dense enough, there was no need to introduce other environmental variables into the model. Our research showed that terrain variables played a key role in predicting soil nutrients, and terrain variables alone could explain soil nutrients 66–79% (R2) spatial distribution, as seen in Table 3. Moreover, from the perspective of the improved scale of the Model B, the remote sensing variables had a better prediction effect at the topsoil (D1 and D2) than deep soil depths (D3, D4, and D5) and model C also showed that remote sensing variables performed poorly in deep soil. Therefore, terrain variables are necessary to predict the spatial distribution of deep soil nutrients, especially in forest areas with large undulating terrain. According to Mosleh et al. [61], terrain attributes are very useful auxiliary variables to predict soil properties in the areas where other soil-forming factors are almost homogeneous. As one of the five soil-forming factors, topography can affect water temperature conditions and the distribution of soil-forming materials. According to the optimal combination of variables screened by the Model A, the representative topographic and hydrological variable for predicting AN content was SDR, which directly explained 55% (ROA ± 5%) of the total variation. SDR reflected sediment transport efficiency in the watershed, where the sediment is severely washed and the AN content is low. PSR, the total amount of solar radiation, was the most important terrain variable for AP accumulation. It mainly affected the growth of vegetation and then affected the source and decomposition rate of soil nutrients. The slope was a strong determinant of AK and OM content. The larger the slope, the weaker the human influence, which provided a favorable environment for AK and OM aggregation. These terrain-hydrology variables determined the distribution of light, heat, and water, affecting the distribution of land vegetation types and the migration and transformation of soil nutrients [62]. Studies have also proved the importance of terrain variables. Li et al. [63] explored the role of Sentinel series satellites in predicting soil nutrients and believed that terrain-hydrology variables were irreplaceable.
4.4. Spatial Distribution of Soil Properties
Regarding the vertical distribution of AN, AP, AK, and OM, with the increase of soil depth their content decreased gradually, which is consistent with the research results of Deng et al. [64] on the subtropical Guangxi mountainous red soil region. The main reason is that the vegetation litter, soil animals and microorganisms are mainly in the surface layer of the soil, and the surface soil ventilation, moisture, and heat conditions are better than the deep soil, which increases the accumulation of AN, AP, AK, and SOM in the surface layer. Regarding the horizontal pattern, the spatial distribution of the four soil nutrients were similar to some remote sensing raster maps (e.g., NDVI map, Green map, and forest type map). The higher soil nutrient content corresponded to higher NDVI and green values, mainly in the broad-leaved forest area and mixed forest. In a way, high-resolution remote sensing data reflect detailed vegetation conditions, which in turn influence soil nutrient accumulation [65]. The accumulation of soil nutrients is mainly affected by higher plant litter, soil animals, and microorganisms. The litter of broad-leaved forest decomposes more easily than that of the coniferous forest. In addition, Pinus massoniana, Cunninghamia lanceolata and Eucalyptus spp. are the main coniferous forest species in Luoding City, which are more affected by human forestry activities and are not conducive to the accumulation of soil nutrients. From the prediction results, the overall forest soil in Luoding is very rich in AN, deficient in AK and OM, and extremely deficient in AP. This may be the result of forestry managers focusing on applying nitrogen fertilizer and not applying enough organic fertilizer. In addition, the study area is a typical mountainous area with steep slopes and much rainfall. Soil nutrients are easily lost due to rainfall scouring and transport, which is not conducive to accumulation [20]. Phosphate and potassium existing in soil were affected by the soil organic matter, so we suggest increasing the quantities of phosphate and potassium and applying organic fertilizer. However, because of the diverse spatial distribution of soil nutrients, the fertilization patterns for different types of forests should be adapted to local conditions. Moreover, variations in soil nutrients should be caught in time to improve the efficiency of fertilization. Soil nutrients are the main factor affecting forestry productivity, so we recommend that the rate of fertilization should be observed in subsequent forest management.
4.5. Uncertainty and Insufficiency in Current Research
In this study, despite the success with remote sensing variables, some aspects are worthy of special attention. First, there might be sampling and experimental errors in data collection and laboratory analysis. Second, affected by the terrain and clouds, high altitude areas often produced shadows in the image segmentation process that led to large reflectivity errors in satellite image data [66]. Moreover, the variation in land surface characteristics over time and the acquisition time of remote sensing variables also affected the accuracy. Thirdly, we used only nine variables, including four wavebands, four vegetation indices and forest types, and may have omitted better remote sensing variables for modelling work. In the future we should include more vegetation variables that can reflect vegetation growth conditions and soil background. Relevant research has shown that the texture features of images can effectively improve the image classification effect and the model’s accuracy [67,68]. Therefore, more remote sensing variables, such as texture features of multi-spectral bands and panchromatic bands, and more variables such as terrain and climate, should be introduced to test and analyze their applicability in subsequent studies. Furthermore, future testing and analysis models can be undertaken with new remote sensing data sources, classification methods, and modelling methods, etc., to improve the estimation system model, providing strong support for subsequent soil nutrient estimation.
5. Conclusions
Study results showed that full variables ANNs (Model B) are best overall at predicting soil nutrients in this region. The GF-1 remote sensing satellite can be applied to soil mapping. However, spatial prediction performed better for the topsoil layers (0–40 cm) than deep layers (40–100 cm), which showed that the subsoil prediction needs to be improved using other more effective variables. The remote sensing factors had different performances for different soil nutrients at 0–40 cm—more useful for AN, AP, and OM, and less helpful for AK. Herein, NDVI, G, and forest type were the most useful auxiliary remote sensing data to map soil nutrients. Overall, fine-resolution GF-1 remote sensing images are useful for many soil and environmental scientists and land managers in China. Therefore, it is worth exploring the use of more GF-1 remote sensing satellite data for soil mapping to promote the further development of forestry and agriculture.
Author Contributions
Conceptualisation, Z.Z. and Y.L.; methodology, Y.L. and Z.Z.; software, Z.Z. and Y.L.; validation, Y.L., S.W. and D.S.; formal analysis, Q.Y., Z.Z. and Y.L.; investigation, Z.Z., X.D. and D.S.; resources, X.D.; data curation, X.D. and Z.Z.; writing—original draft preparation, Y.L.; writing—review and editing, Y.L., Z.Z. and S.W.; visualisation, Q.Y.; supervision, Z.Z.; project administration, X.D.; funding acquisition, Q.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by funding from the Guangxi Natural Science Foundation of China (Grant No. 2018GXNSFAA050135 and 2018GXNSFBA138035), and Guangdong Forestry Science and Technology Plan of China (Grant No. 2019−07).
Data Availability Statement
Not applicable.
Acknowledgments
The authors are grateful for the special founding from Guangxi Hundred-Talent Program to Zhengyong Zhao and Qi Yang. The authors also appreciate the remote sensing editorial office, and the anonymous referees for their valuable suggestions and questions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Grinand, C.; Maire, G.L.; Vieilledent, G.; Razakamanarivo, H.; Razafimbelo, T.; Bernoux, M. Estimating Temporal Changes in Soil Carbon Stocks at Ecoregional Scale in Madagascar Using Remote-Sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 54, 1–14. [Google Scholar] [CrossRef]
- Tian, L.; Zhao, L.; Wu, X.; Hu, G.; Fang, H.; Zhao, Y.; Sheng, Y.; Chen, J.; Wu, J.; Li, W.; et al. Variations in Soil Nutrient Availability across Tibetan Grassland from the 1980s to 2010s. Geoderma 2019, 338, 197–205. [Google Scholar] [CrossRef]
- Yang, W.; Zhong, Z.; Tang, J.; Heng, W. Study on temporal and spatial characteristics of available soil nitrogen, phosphorus, and potassium among the forest ecosystem of Mt Jinyun. Acta Ecol. Sin. 2001, 21, 1285–1289. (In Chinese) [Google Scholar]
- Heuck, C.; Weig, A.; Spohn, M. Soil Microbial Biomass C:N:P Stoichiometry and Microbial Use of Organic Phosphorus. Soil Biol. Biochem. 2015, 85, 119–129. [Google Scholar] [CrossRef]
- Kindler, R.; Miltner, A.; Richnow, H.; Kastner, M. Fate of Gram-Negative Bacterial Biomass in Soil—Mineralization and Contribution to SOM. Soil Biol. Biochem. 2006, 38, 2860–2870. [Google Scholar] [CrossRef]
- Schloeder, C.A.; Zimmerman, N.E.; Jacobs, M.J. Comparison of Methods for Interpolating Soil Properties Using Limited Data. Soil Sci. Soc. Am. J. 2001, 65, 470–479. [Google Scholar] [CrossRef]
- Martin, M.P.; Wattenbach, M.; Smith, P.; Meersmans, J.; Jolivet, C.; Boulonne, L.; Arrouays, D. Spatial Distribution of Soil Organic Carbon Stocks in France. Biogeosciences 2011, 8, 1053–1065. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Wu, J.; Luo, Y.; Zhang, L.; DeGloria, S.D. Spatial Prediction of Soil Organic Matter Content Using Cokriging with Remotely Sensed Data. Soil Sci. Soc. Am. J. 2009, 73, 1202–1208. [Google Scholar] [CrossRef]
- Yigini, Y.; Panagos, P. Assessment of Soil Organic Carbon Stocks under Future Climate and Land Cover Changes in Europe. Sci. Total. Environ. 2016, 557–558, 838–850. [Google Scholar] [CrossRef]
- Behrens, T.; Scholten, T. Digital Soil Mapping in Germany—A Review. J. Plant Nutr. Soil Sci. 2007, 170, 181. [Google Scholar] [CrossRef]
- McBratney, A.B.; Odeh, I.O.A.; Bishop, T.F.A.; Dunbar, M.S.; Shatar, T.M. An Overview of Pedometric Techniques for Use in Soil Survey. Geoderma 2000, 97, 293–327. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Malone, B.P.; Wheeler, I. Digital Mapping of Soil Carbon. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2013; Volume 118, pp. 1–47. ISBN 978-0-12-405942-9. [Google Scholar]
- Mulder, V.L.; Lacoste, M.; Richer-de-Forges, A.C.; Martin, M.P.; Arrouays, D. National versus Global Modelling the 3D Distribution of Soil Organic Carbon in Mainland France. Geoderma 2016, 263, 16–34. [Google Scholar] [CrossRef]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On Digital Soil Mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Kerry, R. Digital Mapping of Soil Organic Carbon at Multiple Depths Using Different Data Mining Techniques in Baneh Region, Iran. Geoderma 2016, 266, 98–110. [Google Scholar] [CrossRef]
- Zhao, Z.; Chow, T.L.; Yang, Q.; Rees, H.W.; Benoy, G.; Xing, Z.; Meng, F.-R. Model Prediction of Soil Drainage Classes Based on Digital Elevation Model Parameters and Soil Attributes from Coarse Resolution Soil Maps. Can. J. Soil. Sci. 2008, 88, 787–799. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, Q.; Sun, D.; Ding, X.; Meng, F. Extended Model Prediction of High-Resolution Soil Organic Matter over a Large Area Using Limited Number of Field Samples. Comput. Electron. Agric. 2020, 169, 105172. [Google Scholar] [CrossRef]
- Wang, S.; Jin, X.; Adhikari, K.; Li, W.; Yu, M.; Bian, Z.; Wang, Q. Mapping Total Soil Nitrogen from a Site in Northeastern China. Catena 2018, 166, 134–146. [Google Scholar] [CrossRef]
- Zhao, Z.; Ashraf, M.I.; Meng, F.-R. Model Prediction of Soil Drainage Classes over a Large Area Using a Limited Number of Field Samples: A Case Study in the Province of Nova Scotia, Canada. Can. J. Soil. Sci. 2013, 93, 73–83. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, Q.; Ding, X.; Xing, Z. Impacts of Coarse-Resolution Soil Maps and High-Resolution Digital-Elevation-Model-Generated Attributes on Modelling Forest Soil Zinc and Copper. Can. J. Soil. Sci. 2021, 101, 261–276. [Google Scholar] [CrossRef]
- Ding, X.; Zhao, Z.; Yang, Q.; Chen, L.; Tian, Q.; Li, X.; Meng, F.-R. Model Prediction of Depth-Specific Soil Texture Distributions with Artificial Neural Network: A Case Study in Yunfu, a Typical Area of Udults Zone, South China. Comput. Electron. Agric. 2020, 169, 105217. [Google Scholar] [CrossRef]
- Ballabio, C.; Fava, F.; Rosenmund, A. A Plant Ecology Approach to Digital Soil Mapping, Improving the Prediction of Soil Organic Carbon Content in Alpine Grasslands. Geoderma 2012, 187–188, 102–116. [Google Scholar] [CrossRef]
- Ben-Dor, E.; Taylor, R.G.; Hill, J.; Demattê, J.A.M.; Whiting, M.L.; Chabrillat, S.; Sommer, S. Imaging Spectrometry for Soil Applications. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2008; Volume 97, pp. 321–392. ISBN 978-0-12-374352-7. [Google Scholar]
- Yang, R.-M.; Guo, W.-W.; Zheng, J.-B. Soil Prediction for Coastal Wetlands Following Spartina Alterniflora Invasion Using Sentinel-1 Imagery and Structural Equation Modeling. Catena 2019, 173, 465–470. [Google Scholar] [CrossRef]
- Mulder, V.L.; de Bruin, S.; Schaepman, M.E.; Mayr, T.R. The Use of Remote Sensing in Soil and Terrain Mapping—A Review. Geoderma 2011, 162, 1–19. [Google Scholar] [CrossRef]
- Zhou, T.; Geng, Y.; Chen, J.; Liu, M.; Haase, D.; Lausch, A. Mapping Soil Organic Carbon Content Using Multi-Source Remote Sensing Variables in the Heihe River Basin in China. Ecol. Indic. 2020, 114, 106288. [Google Scholar] [CrossRef]
- Odebiri, O.; Mutanga, O.; Odindi, J.; Peerbhay, K.; Dovey, S. Predicting Soil Organic Carbon Stocks under Commercial Forest Plantations in KwaZulu-Natal Province, South Africa Using Remotely Sensed Data. GIScience Remote. Sens. 2020, 57, 450–463. [Google Scholar] [CrossRef]
- Yang, D.; Yan, S.; Yang, Y.; Tian, M. Soil Moisture Retrieval Based on Multi-temporal GF-1 Images. Sci. Technol. Eng. 2021, 21, 4540–4549. (In Chinese) [Google Scholar]
- Li, X.; Ding, X.; Ceng, S.; Zhang, C.; Yang, H. Forest Soil Survey of Yunfu, Guangdong Province; China Forestry Publishing House: Beijing, China, 2018; pp. 112–124. (In Chinese) [Google Scholar]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital Terrain Modelling: A Review of Hydrological, Geomorphological, and Biological Applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Scull, P.; Franklin, J.; Chadwick, O.A.; McArthur, D. Predictive Soil Mapping: A Review. Prog. Phys. Geogr. Earth Environ. 2003, 27, 171–197. [Google Scholar] [CrossRef] [Green Version]
- Meng, F.R.; Castonguay, M.; Ogilvie, J.; Murphy, P.N.C.; Arp, P.A. Developing a GIS-Based flow-channel and wet areas mapping framework for precision forestry planning. In Proceedings of the IUFRO Precision Forestry Symposium, Stellenbosch, South Africa, 5–10 March 2006. [Google Scholar]
- Yang, R.; Rossiter, D.G.; Liu, F.; Lu, Y.; Yang, F.; Yang, F.; Zhao, Y.; Li, D.; Zhang, G. Predictive Mapping of Topsoil Organic Carbon in an Alpine Environment Aided by Landsat TM. PLoS ONE 2015, 10, e0139042. [Google Scholar] [CrossRef] [PubMed]
- Goward, S.N.; Markham, B.; Dye, D.G.; Dulaney, W.; Yang, J. Normalized Difference Vegetation Index Measurements from the Advanced Very High Resolution Radiometer. Remote Sens. Environ. 1991, 35, 257–277. [Google Scholar] [CrossRef]
- Powell, S.L.; Cohen, W.B.; Healey, S.P.; Kennedy, R.E.; Moisen, G.G.; Pierce, K.B.; Ohmann, J.L. Quantification of Live Aboveground Forest Biomass Dynamics with Landsat Time-Series and Field Inventory Data: A Comparison of Empirical Modeling Approaches. Remote Sens. Environ. 2010, 114, 1053–1068. [Google Scholar] [CrossRef]
- Major, D.J.; Baret, F.; Guyot, G. A Ratio Vegetation Index Adjusted for Soil Brightness. Int. J. Remote Sens. 1990, 11, 727–740. [Google Scholar] [CrossRef]
- McGillem, C.; Svedlow, M. Short Papers Optimum Filter for Minimization of Image Registration Error Variance. IEEE Trans. Geosci. Electron. 1977, 15, 257–259. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1353691. [Google Scholar] [CrossRef] [Green Version]
- Sun, Q. Study on Classification Method of Main Forest Types in Badaling Forest Farm Based on GF-2. Master Thesis, Beijing Forestry University, Beijing, China, 2017. (In Chinese). [Google Scholar]
- Zhao, Z.; Chow, T.L.; Rees, H.W.; Yang, Q.; Xing, Z.; Meng, F.-R. Predict Soil Texture Distributions Using an Artificial Neural Network Model. Comput. Electron. Agric. 2009, 65, 36–48. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, Q.; Benoy, G.; Chow, T.L.; Xing, Z.; Rees, H.W.; Meng, F.-R. Using Artificial Neural Network Models to Produce Soil Organic Carbon Content Distribution Maps across Landscapes. Can. J. Soil. Sci. 2010, 90, 75–87. [Google Scholar] [CrossRef]
- Schillaci, C.; Lombardo, L.; Saia, S.; Fantappiè, M.; Märker, M.; Acutis, M. Modelling the Topsoil Carbon Stock of Agricultural Lands with the Stochastic Gradient Treeboost in a Semi-Arid Mediterranean Region. Geoderma 2017, 286, 35–45. [Google Scholar] [CrossRef]
- Sigillito, V.G.; Hutton, L.V. Case Study II: Radar Signal Processing. In Neural Network PC Tools; Elsevier: Amsterdam, The Netherlands, 1990; pp. 235–250. ISBN 978-0-12-228640-7. [Google Scholar]
- Vaysse, K.; Lagacherie, P. Evaluating Digital Soil Mapping Approaches for Mapping GlobalSoilMap Soil Properties from Legacy Data in Languedoc-Roussillon (France). Geoderma Reg. 2015, 4, 20–30. [Google Scholar] [CrossRef]
- Akpa, S.I.C.; Odeh, I.O.A.; Bishop, T.F.A.; Hartemink, A.E. Digital Mapping of Soil Particle-Size Fractions for Nigeria. Soil Sci. Soc. Am. J. 2014, 78, 1953–1966. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Gao, J.; Zhuang, Q.; Lu, Y.; Gu, H.; Jin, X. Multispectral Remote Sensing Data Are Effective and Robust in Mapping Regional Forest Soil Organic Carbon Stocks in a Northeast Forest Region in China. Remote Sens. 2020, 12, 393. [Google Scholar] [CrossRef] [Green Version]
- Mahmoudabadi, E.; Karimi, A.; Haghnia, G.H.; Sepehr, A. Digital Soil Mapping Using Remote Sensing Indices, Terrain Attributes, and Vegetation Features in the Rangelands of Northeastern Iran. Environ. Monit. Assess. 2017, 189, 500. [Google Scholar] [CrossRef]
- Yang, R.-M.; Zhang, G.-L.; Liu, F.; Lu, Y.-Y.; Yang, F.; Yang, F.; Yang, M.; Zhao, Y.-G.; Li, D.-C. Comparison of Boosted Regression Tree and Random Forest Models for Mapping Topsoil Organic Carbon Concentration in an Alpine Ecosystem. Ecol. Indic. 2016, 60, 870–878. [Google Scholar] [CrossRef]
- Kempen, B.; Brus, D.J.; Stoorvogel, J.J. Three-Dimensional Mapping of Soil Organic Matter Content Using Soil Type–Specific Depth Functions. Geoderma 2011, 162, 107–123. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Zhang, G.-L.; Sun, Y.-J.; Zhao, Y.-G.; Li, D.-C. Mapping the Three-Dimensional Distribution of Soil Organic Matter across a Subtropical Hilly Landscape. Soil Sci. Soc. Am. J. 2013, 77, 1241–1253. [Google Scholar] [CrossRef]
- Nyssen, J.; Temesgen, H.; Lemenih, M.; Zenebe, A.; Haregeweyn, N.; Haile, M. Spatial and Temporal Variation of Soil Organic Carbon Stocks in a Lake Retreat Area of the Ethiopian Rift Valley. Geoderma 2008, 146, 261–268. [Google Scholar] [CrossRef]
- Kim, J.; Grunwald, S. Assessment of Carbon Stocks in the Topsoil Using Random Forest and Remote Sensing Images. J. Environ. Qual. 2016, 45, 1910–1918. [Google Scholar] [CrossRef]
- Yimer, F.; Ledin, S.; Abdelkadir, A. Soil Organic Carbon and Total Nitrogen Stocks as Affected by Topographic Aspect and Vegetation in the Bale Mountains, Ethiopia. Geoderma 2006, 135, 335–344. [Google Scholar] [CrossRef]
- Demattê, J.A.M.; Sayão, V.M.; Rizzo, R.; Fongaro, C.T. Soil Class and Attribute Dynamics and Their Relationship with Natural Vegetation Based on Satellite Remote Sensing. Geoderma 2017, 302, 39–51. [Google Scholar] [CrossRef]
- Mirzaee, S.; Ghorbani-Dashtaki, S.; Mohammadi, J.; Asadi, H.; Asadzadeh, F. Spatial Variability of Soil Organic Matter Using Remote Sensing Data. Catena 2016, 145, 118–127. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, Q.; Yang, Z.; Yu, N.; Jin, X. Temporal and Spatial Changes of Soil Organic Carbon Stocks in the Forest Area of Northeastern China. Forests 2019, 10, 1023. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Li, H.; Cao, L.; Zhang, Y. Analysis on the heterogeneity of forest soil nutrients in Guangdong Province of southern China. J. Beijing For. Univ. 2021, 43, 90–101. [Google Scholar]
- Rivero, R.G.; Grunwald, S.; Binford, M.W.; Osborne, T.Z. Integrating Spectral Indices into Prediction Models of Soil Phosphorus in a Subtropical Wetland. Remote Sens. Environ. 2009, 113, 2389–2402. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Minasny, B.; Sarmadian, F.; Malone, B.P. Digital Mapping of Soil Salinity in Ardakan Region, Central Iran. Geoderma 2014, 213, 15–28. [Google Scholar] [CrossRef]
- Pouladi, N.; Møller, A.B.; Tabatabai, S.; Greve, M.H. Mapping Soil Organic Matter Contents at Field Level with Cubist, Random Forest and Kriging. Geoderma 2019, 342, 85–92. [Google Scholar] [CrossRef]
- Mosleh, Z.; Salehi, M.H.; Jafari, A.; Borujeni, I.E.; Mehnatkesh, A. The Effectiveness of Digital Soil Mapping to Predict Soil Properties over Low-Relief Areas. Environ. Monit. Assess. 2016, 188, 195. [Google Scholar] [CrossRef]
- Adhikari, K.; Hartemink, A.E.; Minasny, B.; Bou Kheir, R.; Greve, M.B.; Greve, M.H. Digital Mapping of Soil Organic Carbon Contents and Stocks in Denmark. PLoS ONE 2014, 9, e105519. [Google Scholar] [CrossRef]
- Li, X.; Ding, J.; Liu, J.; Ge, X.; Zhang, J. Digital Mapping of Soil Organic Carbon Using Sentinel Series Data: A Case Study of the Ebinur Lake Watershed in Xinjiang. Remote Sens. 2021, 13, 769. [Google Scholar] [CrossRef]
- Deng, X.; Cao, J.; Song, X.; Tang, J.; Chen, F. Vertical Distribution Characteristics of Three Forest Types’ Soil Properties on Mao’er Mountain Biosphere Reserve. Ecol. Sci. 2014, 33, 1129–1134. (In Chinese) [Google Scholar] [CrossRef]
- Wang, B.; Waters, C.; Orgill, S.; Gray, J.; Cowie, A.; Clark, A.; Liu, D.L. High Resolution Mapping of Soil Organic Carbon Stocks Using Remote Sensing Variables in the Semi-Arid Rangelands of Eastern Australia. Sci. Total Environ. 2018, 630, 367–378. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, Q.; Jin, X.; Yang, Z.; Liu, H. Predicting Soil Organic Carbon and Soil Nitrogen Stocks in Topsoil of Forest Ecosystems in Northeastern China Using Remote Sensing Data. Remote Sens. 2020, 12, 1115. [Google Scholar] [CrossRef] [Green Version]
- Eckert, S. Improved Forest Biomass and Carbon Estimations Using Texture Measures from WorldView-2 Satellite Data. Remote Sens. 2012, 4, 810–829. [Google Scholar] [CrossRef] [Green Version]
- Meng, J.; Li, S.; Wang, W.; Liu, Q.; Xie, S.; Ma, W. Estimation of Forest Structural Diversity Using the Spectral and Textural Information Derived from SPOT-5 Satellite Images. Remote Sens. 2016, 8, 125. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).