
Development of a Modality-Invariant Multi-Layer Perceptron to Predict Operational Events in Motor-Manual Willow Felling Operations


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.1.1. Study Location and Crop Layout
2.1.2. Tool Description, Work Organization and Relevant Process Mechanics
2.1.3. Instrumentation
2.1.4. Datasets
2.2. Data Preprocessing Workflow
2.2.1. Data Pairing, Segmentation and Labelling
2.2.2. Fusion of the Training Datasets
2.2.3. Data Normalization
2.3. Setup of the MLP
2.3.1. Software Used and General Architecture of the MLP
2.3.2. Tunning and Error Metric Used to Evaluate the Generalization Ability
2.3.3. Classification Performance Metrics
2.4. Evaluation
3. Results
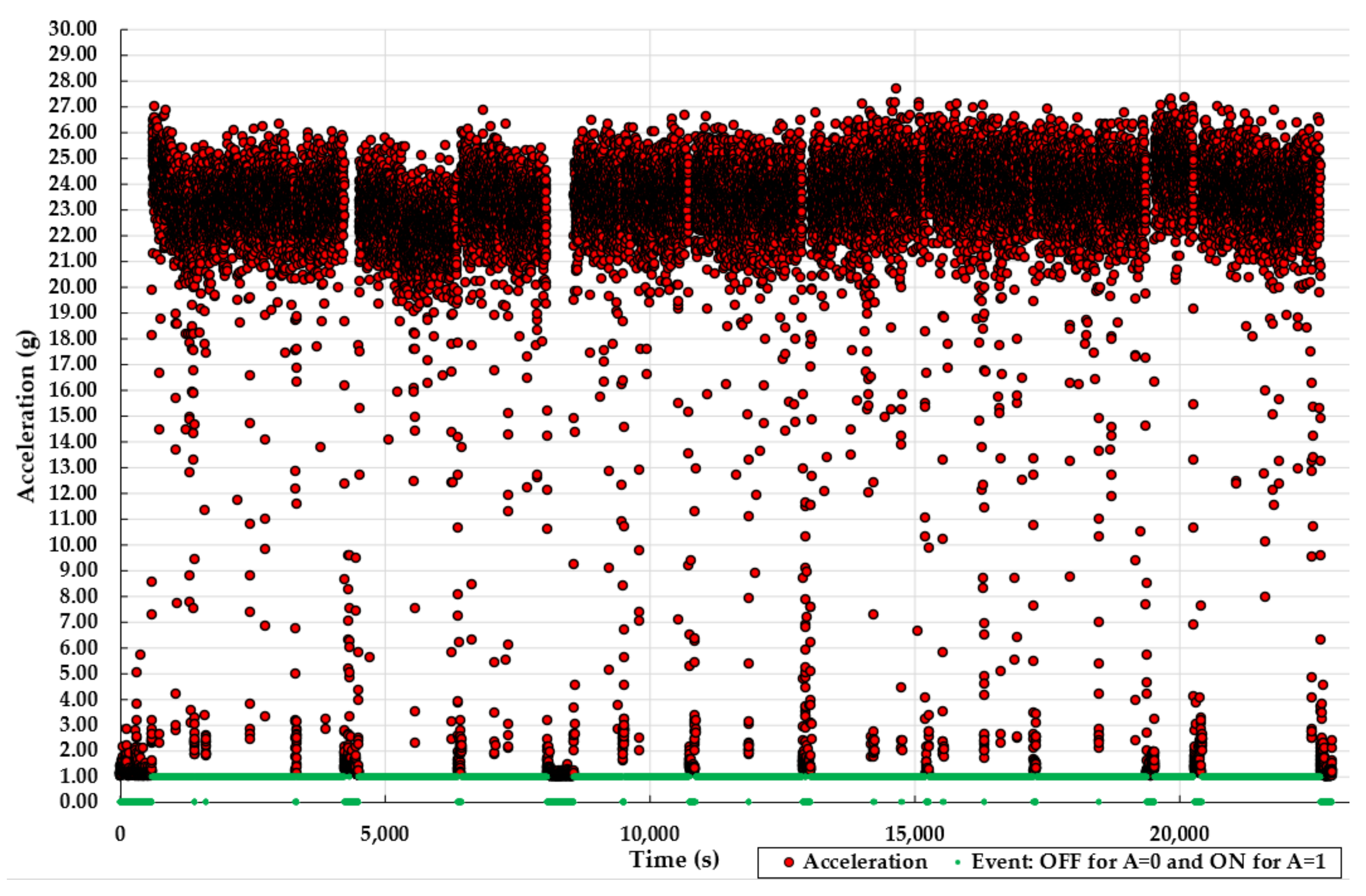
3.1. Description of the Labelled Datasets
3.2. Model Selection and Classification Performance
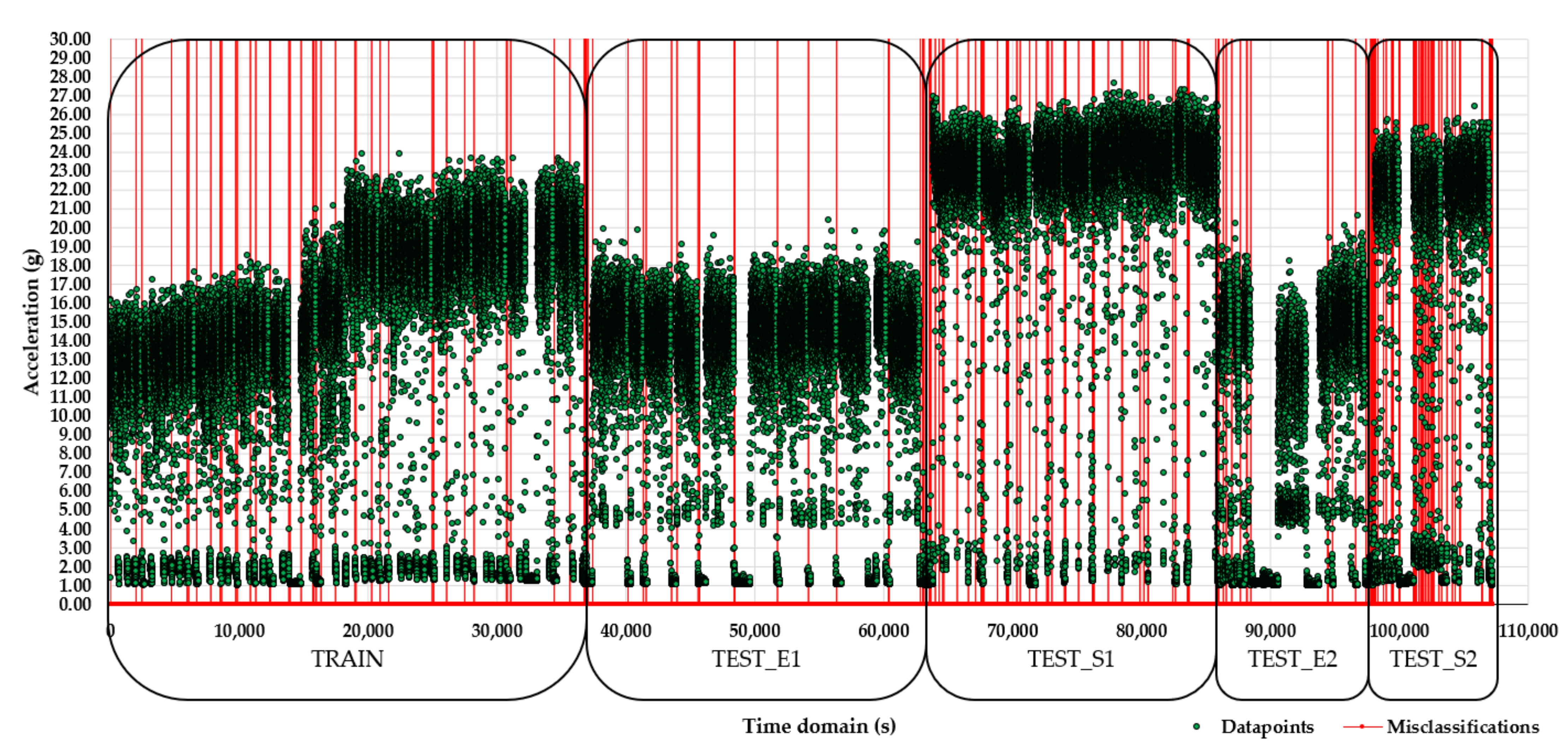
3.3. Missclassification and Probability Plots
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regularization Parameter (Training Time) | Dataset | Area under Curve (AUC) | Classification Accuracy (CA) | F1 | Precision (PREC) | Recall (REC) | Specificity (SPEC) |
|---|---|---|---|---|---|---|---|
| α = 0.0001 (261 s) a | TRAIN | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.996 | |
| TEST_S1 | 1.000 | 0.996 | 0.996 | 0.996 | 0.996 | 0.989 | |
| TEST_E2 | 0.999 | 0.994 | 0.994 | 0.994 | 0.994 | 0.995 | |
| TEST_S2 | 0.999 | 0.991 | 0.991 | 0.991 | 0.991 | 0.986 | |
| α = 0.001 (326 s) | TRAIN | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.998 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 | |
| TEST_S1 | 1.000 | 0.996 | 0.996 | 0.996 | 0.996 | 0.992 | |
| TEST_E2 | 0.999 | 0.994 | 0.994 | 0.994 | 0.994 | 0.995 | |
| TEST_S2 | 0.999 | 0.995 | 0.995 | 0.995 | 0.995 | 0.993 | |
| α = 0.01 (480 s) | TRAIN | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.998 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 | |
| TEST_S1 | 1.000 | 0.996 | 0.996 | 0.996 | 0.996 | 0.992 | |
| TEST_E2 | 0.999 | 0.994 | 0.994 | 0.994 | 0.994 | 0.995 | |
| TEST_S2 | 0.999 | 0.995 | 0.995 | 0.995 | 0.995 | 0.994 | |
| α = 0.1 (443 s) a | TRAIN | 1.000 | 0.998 | 0.998 | 0.998 | 0.998 | 0.998 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.998 | |
| TEST_S1 | 1.000 | 0.995 | 0.995 | 0.995 | 0.995 | 0.992 | |
| TEST_E2 | 0.999 | 0.994 | 0.994 | 0.994 | 0.994 | 0.995 | |
| TEST_S2 | 0.999 | 0.995 | 0.995 | 0.995 | 0.995 | 0.994 | |
| α = 1 (482 s) | TRAIN | 1.000 | 0.997 | 0.997 | 0.997 | 0.997 | 0.998 |
| TEST_E1 | 1.000 | 0.994 | 0.994 | 0.994 | 0.994 | 0.997 | |
| TEST_S1 | 1.000 | 0.994 | 0.994 | 0.995 | 0.994 | 0.994 | |
| TEST_E2 | 0.999 | 0.974 | 0.974 | 0.975 | 0.974 | 0.980 | |
| TEST_S2 | 0.999 | 0.994 | 0.994 | 0.994 | 0.994 | 0.994 | |
| α = 10 (269 s) | TRAIN | 1.000 | 0.994 | 0.994 | 0.994 | 0.994 | 0.998 |
| TEST_E1 | 1.000 | 0.990 | 0.990 | 0.991 | 0.990 | 0.996 | |
| TEST_S1 | 1.000 | 0.994 | 0.994 | 0.994 | 0.994 | 0.995 | |
| TEST_E2 | 0.999 | 0.944 | 0.944 | 0.950 | 0.944 | 0.958 | |
| TEST_S2 | 0.999 | 0.993 | 0.993 | 0.993 | 0.993 | 0.995 |
| Regularization Parameter (Training Time) | Dataset | Area under Curve (AUC) | Classification Accuracy (CA) | F1 | Precision (PREC) | Recall (REC) | Specificity (SPEC) |
|---|---|---|---|---|---|---|---|
| α = 0.0001 (261 s) a | TRAIN | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.998 | 1.000 | 0.994 | |
| TEST_S1 | 1.000 | 0.996 | 0.998 | 0.999 | 0.997 | 0.988 | |
| TEST_E2 | 0.999 | 0.994 | 0.995 | 0.997 | 0.992 | 0.996 | |
| TEST_S2 | 0.999 | 0.991 | 0.993 | 0.988 | 0.998 | 0.979 | |
| α = 0.001 (326 s) | TRAIN | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 1.000 | 0.996 | |
| TEST_S1 | 1.000 | 0.996 | 0.998 | 0.999 | 0.996 | 0.992 | |
| TEST_E2 | 0.999 | 0.994 | 0.995 | 0.998 | 0.992 | 0.998 | |
| TEST_S2 | 0.999 | 0.995 | 0.996 | 0.995 | 0.997 | 0.991 | |
| α = 0.01 (480 s) | TRAIN | 1.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 1.000 | 0.996 | |
| TEST_S1 | 1.000 | 0.996 | 0.997 | 0.999 | 0.996 | 0.992 | |
| TEST_E2 | 0.999 | 0.994 | 0.995 | 0.998 | 0.992 | 0.998 | |
| TEST_S2 | 0.999 | 0.995 | 0.996 | 0.995 | 0.996 | 0.992 | |
| α = 0.1 (443 s) a | TRAIN | 1.000 | 0.998 | 0.999 | 0.999 | 0.998 | 0.997 |
| TEST_E1 | 1.000 | 0.999 | 0.999 | 0.999 | 1.000 | 0.997 | |
| TEST_S1 | 1.000 | 0.995 | 0.997 | 0.999 | 0.996 | 0.992 | |
| TEST_E2 | 0.999 | 0.994 | 0.995 | 0.999 | 0.991 | 0.998 | |
| TEST_S2 | 0.999 | 0.995 | 0.996 | 0.996 | 0.996 | 0.994 | |
| α = 1 (482 s) | TRAIN | 1.000 | 0.997 | 0.998 | 1.000 | 0.996 | 0.999 |
| TEST_E1 | 1.000 | 0.994 | 0.996 | 1.000 | 0.993 | 0.998 | |
| TEST_S1 | 1.000 | 0.994 | 0.997 | 0.999 | 0.994 | 0.994 | |
| TEST_E2 | 0.999 | 0.974 | 0.997 | 0.999 | 0.956 | 0.999 | |
| TEST_S2 | 0.999 | 0.994 | 0.995 | 0.997 | 0.993 | 0.995 | |
| α = 10 (269 s) | TRAIN | 1.000 | 0.994 | 0.996 | 1.000 | 0.993 | 0.999 |
| TEST_E1 | 1.000 | 0.990 | 0.994 | 1.000 | 0.988 | 0.999 | |
| TEST_S1 | 1.000 | 0.994 | 0.997 | 0.999 | 0.994 | 0.996 | |
| TEST_E2 | 0.999 | 0.944 | 0.948 | 0.999 | 0.903 | 0.999 | |
| TEST_S2 | 0.999 | 0.993 | 0.995 | 0.998 | 0.992 | 0.996 |
| Regularization Parameter (Training Time) | Dataset | Area under Curve (AUC) | Classification Accuracy (CA) | F1 | Precision (PREC) | Recall (REC) | Specificity (SPEC) |
|---|---|---|---|---|---|---|---|
| α = 0.0001 (261 s) a | TRAIN | 1.000 | 0.999 | 0.998 | 0.998 | 0.997 | 0.999 |
| TEST_E1 | 1.000 | 0.999 | 0.997 | 1.000 | 0.994 | 1.000 | |
| TEST_S1 | 1.000 | 0.996 | 0.982 | 0.976 | 0.988 | 0.997 | |
| TEST_E2 | 0.999 | 0.994 | 0.993 | 0.989 | 0.996 | 0.992 | |
| TEST_S2 | 0.999 | 0.991 | 0.988 | 0.997 | 0.979 | 0.998 | |
| α = 0.001 (326 s) | TRAIN | 1.000 | 0.999 | 0.997 | 0.997 | 0.997 | 0.999 |
| TEST_E1 | 1.000 | 0.999 | 0.998 | 1.000 | 0.996 | 1.000 | |
| TEST_S1 | 1.000 | 0.996 | 0.980 | 0.970 | 0.992 | 0.996 | |
| TEST_E2 | 0.999 | 0.994 | 0.993 | 0.989 | 0.998 | 0.992 | |
| TEST_S2 | 0.999 | 0.995 | 0.993 | 0.995 | 0.991 | 0.997 | |
| α = 0.01 (480 s) | TRAIN | 1.000 | 0.999 | 0.998 | 0.998 | 0.997 | 0.999 |
| TEST_E1 | 1.000 | 0.999 | 0.998 | 0.999 | 0.996 | 1.000 | |
| TEST_S1 | 1.000 | 0.996 | 0.980 | 0.968 | 0.992 | 0.996 | |
| TEST_E2 | 0.999 | 0.994 | 0.993 | 0.989 | 0.998 | 0.992 | |
| TEST_S2 | 0.999 | 0.995 | 0.993 | 0.994 | 0.992 | 0.996 | |
| α = 0.1 (443 s) a | TRAIN | 1.000 | 0.998 | 0.996 | 0.995 | 0.997 | 0.998 |
| TEST_E1 | 1.000 | 0.999 | 0.998 | 0.999 | 0.997 | 1.000 | |
| TEST_S1 | 1.000 | 0.995 | 0.979 | 0.965 | 0.992 | 0.996 | |
| TEST_E2 | 0.999 | 0.994 | 0.993 | 0.988 | 0.998 | 0.991 | |
| TEST_S2 | 0.999 | 0.995 | 0.993 | 0.993 | 0.994 | 0.996 | |
| α = 1 (482 s) | TRAIN | 1.000 | 0.997 | 0.994 | 0.989 | 0.999 | 0.996 |
| TEST_E1 | 1.000 | 0.994 | 0.987 | 0.976 | 0.998 | 0.993 | |
| TEST_S1 | 1.000 | 0.994 | 0.974 | 0.955 | 0.994 | 0.994 | |
| TEST_E2 | 0.999 | 0.974 | 0.970 | 0.944 | 0.999 | 0.956 | |
| TEST_S2 | 0.999 | 0.994 | 0.992 | 0.988 | 0.995 | 0.993 | |
| α = 10 (269 s) | TRAIN | 1.000 | 0.994 | 0.988 | 0.977 | 0.999 | 0.993 |
| TEST_E1 | 1.000 | 0.990 | 0.979 | 0.960 | 0.999 | 0.988 | |
| TEST_S1 | 1.000 | 0.994 | 0.974 | 0.953 | 0.996 | 0.994 | |
| TEST_E2 | 0.999 | 0.944 | 0.938 | 0.884 | 0.999 | 0.903 | |
| TEST_S2 | 0.999 | 0.993 | 0.991 | 0.986 | 0.996 | 0.992 |
References
- Dickmann, D.I. Silviculture and biology of short-rotation woody crops in temperate regions: Then and now. Biomass Bioenerg. 2006, 30, 696–705. [Google Scholar] [CrossRef]
- Kuzovkina, Y.A.; Volk, T.A. The characterization of willow (Salix L.) varieties for use in ecological engineering applications: Co-ordination of structure, function and autecology. Ecol. Eng. 2009, 35, 1178–1189. [Google Scholar] [CrossRef]
- Berhongaray, G.; El Kasmioui, O.; Ceulemans, R. Comparative analysis of harvesting machines on operational high-density short rotation woody crop (SRWC) culture: One-process versus two-process harvest operation. Biomass Bioenerg. 2013, 58, 333–342. [Google Scholar] [CrossRef] [Green Version]
- Schweier, J.; Becker, G. Harvesting of short rotation coppice—Harvesting trials with a cut and storage system in Germany. Silva Fenn. 2012, 46, 287–299. [Google Scholar] [CrossRef] [Green Version]
- El Kasmioui, O.; Ceulemans, R. Financial analysis of the cultivation of short rotation woody crops for bioenergy in Belgium: Barriers and opportunities. Bioenerg. Res. 2013, 6, 336–350. [Google Scholar] [CrossRef]
- Buchholz, T.; Volk, T.A. Improving the profitability of willow crops—Identifying opportunities with a crop budget model. Bioenerg. Res. 2011, 4, 85–95. [Google Scholar] [CrossRef]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Chiriloiu, D.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D.; Marcu, M.V. Physical strain, exposure to noise and postural assessment in motor-manual felling of willow short rotation coppice: Results of a preliminary study. Croat. J. Eng. 2019, 40, 377–388. [Google Scholar] [CrossRef]
- Schweier, J.; Becker, G. Motor manual harvest of short rotation coppice in South-West Germany. Allg. Forst-und Jagdztg. 2012, 183, 159–167. [Google Scholar]
- Talagai, N.; Borz, S.A.; Ignea, G. Performance of brush cutters in felling operations of willow short rotation coppice. Bioresources 2017, 12, 3560–3569. [Google Scholar] [CrossRef]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D. Automating data collection in motor-manual time and motion studies implemented in a willow short rotation coppice. Bioresources 2018, 13, 3236–3249. [Google Scholar] [CrossRef]
- Vanbeveren, S.P.P.; Schweier, J.; Berhongaray, G.; Ceulemans, R. Operational short rotation woody crops plantations: Manual or mechanized harvesting? Biomass Bioenerg. 2015, 72, 8–18. [Google Scholar] [CrossRef]
- Acuna, M.; Bigot, M.; Guerra, S.; Hartsough, B.; Kanzian, C.; Kärhä, K.; Lindroos, O.; Magagnotti, N.; Roux, S.; Spinelli, R.; et al. Good Practice Guidelines for Biomass Production Studies; Magagnotti, N., Spinelli, R., Eds.; CNR IVALSA: Sesto Fiorentino, Italy, 2012; Available online: http://www.forestenergy.org/pages/cost-action-fp0902/good-practice-guidelines/ (accessed on 15 April 2018).
- Björheden, R.; Apel, K.; Shiba, M.; Thompson, M. IUFRO Forest Work Study Nomenclature; Swedish University of Agricultural Science, Department of Operational Efficiency: Grapenberg, Sweden, 1995. [Google Scholar]
- Borz, S.A. Evaluarea Eficienţei Echipamentelor şi Sistemelor Tehnice în Operaţii Forestiere; Lux Libris Publishing House: Braşov, Romania, 2008. [Google Scholar]
- Keefe, R.F.; Zimbelman, E.G.; Wempe, A.M. Use of smartphone sensors to quantify the productive cycle elements of hand fallers on industrial cable logging operations. Int. J. Eng. 2019, 30, 132–143. [Google Scholar] [CrossRef]
- Cheţa, M.; Marcu, M.V.; Borz, S.A. Effect of training parameters on the ability of artificial neural networks to learn: A simulation on accelerometer data for task recognition in motor-manual felling and processing. Bull. Transilv. Univ. Bras. Ser. Wood Ind. Agric. Food Eng. 2020, 131, 19–36. [Google Scholar] [CrossRef]
- Cheţa, M.; Marcu, M.V.; Iordache, E.; Borz, S.A. Testing the capability of low-cost tools and artificial intelligence techniques to automatically detect operations done by a small-sized manually driven bandsaw. Forests 2020, 11, 739. [Google Scholar] [CrossRef]
- Borz, S.A.; Păun, M. Integrating offline object tracking, signal processing and artificial intelligence to classify relevant events in sawmilling operations. Forests 2020, 11, 1333. [Google Scholar] [CrossRef]
- Talagai, N.; Borz, S.A. Concepte de automatizare a activităţii de colectare a datelor cu aplicabilitate în monitorizarea performanţei productive în operaţii de gestionare a culturilor de salcie rotaţie scurtă. Rev. Pădurilor 2016, 131, 78–94. [Google Scholar]
- Talagai, N.; Marcu, M.V.; Zimbalatti, G.; Proto, A.R.; Borz, S.A. Productivity in partly mechanized planting operations of willow short rotation coppice. Biomass Bioenerg. 2020, 138, 105–609. [Google Scholar] [CrossRef]
- Borz, S.A.; Niţa, M.D.; Talagai, N.; Scriba, C.; Grigolato, S.; Proto, A.R. Performance of small-scale technology in planting and cutback operations of short-rotation willow crops. Trans. ASABE 2019, 62, 167–176. [Google Scholar] [CrossRef]
- User Guide of the Husqvarna 545 Series (In Romanian). Available online: https://www.husqvarna.com/ro/products/motounelte-motocoase/545rx/966015901/ (accessed on 16 February 2021).
- Talagai, N.; Cheţa, M.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D.; Borz, S.A. Predicting time consumption of chipping tasks in a willow short rotation coppice from GPS and acceleration data. In Proceedings of the Biennial International Symposium “Forest and Sustainable Development”, Braşov, Romania, 25–27 October 2018; Borz, S.A., Curtu, A.L., Muşat, E.C., Eds.; Transilvania University Press: Braşov, Romania, 2019; pp. 1–12. [Google Scholar]
- Boja, N.; Borz, S.A. Energy inputs in motor-manual release cutting of broadleaved forests: Results of twelve options. Energies 2020, 13, 4597. [Google Scholar] [CrossRef]
- Ignea, G.; Ghaffaryian, M.R.; Borz, S.A. Impact of operational factors on fossil energy inputs in motor-manual tree felling and processing operations: Results of two case studies. Ann. Res. 2017, 60, 161–172. [Google Scholar] [CrossRef] [Green Version]
- Technical Specifications of the Extech® VB300 3-Axis G-force USB Datalogger. Available online: http://www.extech.com/products/VB300 (accessed on 17 February 2021).
- Technical specifications of the Extech® 407760 USB Sound Level Datalogger. Available online: http://www.extech.com/products/407760 (accessed on 17 February 2021).
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges and opportunities. J. ACM 2018, 37, 111. [Google Scholar]
- Van Hees, V.T.; Gorzelniak, L.; Dean Leon, E.C.; Eder, M.; Pias, M.; Taherian, S.; Ekelund, U.; Renström, F.; Franks, P.W.; Horsch, A.; et al. Separating movement and gravity components in acceleration signal and implications for the assessment of human daily physical activity. PLoS ONE 2013, 8, e61691. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ha, S.; Yun, J.-M.; Chi, S. Multi-modal convolutional neural networks for activity recognition. In Proceedings of the 2015 IEEE Conference on Systems, Man and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 3017–3022. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Burlington, MA, USA, 2006. [Google Scholar]
- Demsar, J.; Curk, T.; Erjavec, A.; Gorup, C.; Hocevar, T.; Milutinovic, M.; Mozina, M.; Polajnar, M.; Toplak, M.; Staric, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- Goodfellow, J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: https://www.deeplearningbook.org/ (accessed on 17 February 2021).
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Varying Regularization in Multi-Layer Perceptrons. Available online: https://scikit-learn.org/stable/auto_examples/neural_networks/plot_mlp_alpha.html#sphx-glr-auto-examples-neural-networks-plot-mlp-alpha-py (accessed on 17 February 2021).
- Understanding Binary Cross-Entropy/Log-Loss: A Visual Explanation. By Daniel Godoy. Available online: https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a (accessed on 17 February 2021).
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Wescoat, E.; Krugh, M.; Henderson, A.; Goodnough, J.; Mears, L. Vibration analysis using unsupervised learning. Procedia Manuf. 2019, 34, 876–884. [Google Scholar] [CrossRef]
- McDonald, T.P.; Fulton, J.P. Automated time study of skidders using global positioning system data. Comput. Electron. Agric. 2005, 48, 19–37. [Google Scholar] [CrossRef] [Green Version]
- Strandgard, M.; Mitchell, R. Automated time study of forwarders using GPS and a vibration sensor. Croat. J. Eng. 2015, 36, 175–184. [Google Scholar]
- Contreras, M.; Freitas, R.; Ribeiro, L.; Stringer, J.; Clark, C. Multi-camera surveillance systems for time and motion studies of timber harvesting equipment. Comput. Electron. Agric. 2015, 135, 208–215. [Google Scholar] [CrossRef]
- McDonald, T.P.; Fulton, J.P.; Darr, M.J.; Gallagher, T.V. Evaluation of a system to spatially monitor hand planting of pine seedlings. Comput. Electron. Agric. 2008, 64, 173–182. [Google Scholar] [CrossRef]
- Borz, S.A.; Marcu, M.V.; Cataldo, M.F. Evaluation of a HSM 208F 14tone HVT-R2 forwarder prototype under conditions of steep-terrain low-access forests. Croat. J. For. Eng. [CrossRef]
- Marogel-Popa, T.; Cheţa, M.; Marcu, M.V.; Duţă, I.; Ioraș, F.; Borz, S.A. Manual cultivation operations in poplar stands: A characterization of job difficulty and risks of health impairment. Int. J. Env. Res. Public Health 2019, 16, 1911. [Google Scholar] [CrossRef] [Green Version]
- Cheţa, M.; Marcu, M.V.; Borz, S.A. Workload, exposure to noise, and risk of musculoskeletal disorders: A case study of motor-manual tree felling and processing in poplar clear cuts. Forests 2018, 9, 300. [Google Scholar] [CrossRef] [Green Version]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial of human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Karsoliya, S. Approximating number of hidden layer neurons in multiple hidden layer BPNN architecture. Int. J. Eng. Technol. 2012, 3, 714–717. [Google Scholar]
- Panchal, F.S.; Panchal, M. Review on methods of selecting number of hidden nodes in Artificial Neural Network. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 455–464. [Google Scholar]
- Keefe, R.F.; Wempe, A.M.; Becker, R.M.; Zimbelman, E.G.; Nagler, E.S.; Gilbert, S.L.; Caudill, C.C. Positioning methods and the use of location and activity data in forests. Forests 2019, 10, 458. [Google Scholar] [CrossRef] [Green Version]
- Borz, S.A. Turning a winch skidder into a self-data collection machine. Bull. Transilv. Univ. Bras. Ser. Wood Ind. Agric. Food Eng. 2016, 9, 1–6. [Google Scholar]
- Spinelli, R.; Laina-Relano, R.; Magagnotti, N.; Tolosana, E. Determining observer effect and method effects on the accuracy of elemental time studies in forest operations. Balt. For. 2013, 19, 301–306. [Google Scholar]
- Picchio, R.; Proto, A.R.; Civitarese, V.; Di Marzio, N.; Latterini, F. Recent contributions of some fields of the electronics in development of forest operations technologies. Electronics 2019, 8, 1465. [Google Scholar] [CrossRef] [Green Version]






| Location | Dataset a | Size b [s] | Date of Collection | Coordinates |
|---|---|---|---|---|
| Poian 1 | TRAIN_E | 18,377 | 04/11/2017 | 46°04.373′ N–26°10.924′ E |
| TRAIN_S | 18,377 | 04/11/2017 | 46°04.373′ N–26°10.924′ E | |
| Poian 2 | TEST_E1 | 26,493 | 02/27/2017 | 46°04.354′ N–26°10.904′ E |
| TEST_S1 | 22,885 | 02/27/2017 | 46°04.354′ N–26°10.904′ E | |
| Belani | TEST_E2 | 11,859 | 03/02/2017 | 46°03.362′ N–26°11.208′ E |
| TEST_S2 | 9285 | 03/02/2017 | 46°03.362′ N–26°11.208′ E | |
| TOTAL | - | 107,276 | - | - |
| Location | Dataset a | Size b [s] | Class Size [s] | Class Share [%] | ||
|---|---|---|---|---|---|---|
| ON | OFF | ON | OFF | |||
| Poian 1 | TRAIN_E | 18,377 | 13,980 | 4487 | 76.07 | 23.93 |
| TRAIN_S | 18,377 | 13,980 | 4487 | 76.07 | 23.93 | |
| TRAIN | 36,754 | 27,960 | 8794 | 76.07 | 23.93 | |
| Poian 2 | TEST_E1 | 26,493 | 20,579 | 5914 | 77.68 | 22.32 |
| TEST_S1 | 22,885 | 20,404 | 2481 | 89.16 | 10.84 | |
| Belani | TEST_E2 | 11,859 | 6806 | 5053 | 57.39 | 42.61 |
| TEST_S2 | 9285 | 5886 | 3399 | 63.39 | 36.61 | |
| TOTAL | - | 107,276 c | 81,635 c | 25,641 c | - | - |
| Class | TRAIN | TEST_E1 | TEST_S1 | TEST_E2 | TEST_S2 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| α = 0.0001 | α = 0.1 | α = 0.0001 | α = 0.1 | α = 0.0001 | α = 0.1 | α = 0.0001 | α = 0.1 | α = 0.0001 | α = 0.1 | |
| ON | 0.999 | 0.998 | 0.999 | 0.999 | 0.996 | 0.995 | 0.994 | 0.994 | 0.991 | 0.995 |
| OFF | 0.999 | 0.998 | 0.999 | 0.999 | 0.996 | 0.995 | 0.994 | 0.994 | 0.991 | 0.995 |
| OVERALL | 0.999 | 0.998 | 0.999 | 0.999 | 0.996 | 0.995 | 0.994 | 0.994 | 0.991 | 0.995 |
| Regularization Term | Dataset a | Size b [s] | Correctly Classified | Misclassified as | ||||
|---|---|---|---|---|---|---|---|---|
| False Positives | False Negatives | |||||||
| N | Share (%) | N | Share (%) | N | Share (%) | |||
| α = 0.0001 | TRAIN | 36,754 | 36,711 | 99.88 | 28 | 0.08 | 15 | 0.04 |
| TEST_E1 | 26,493 | 26,465 | 99.89 | 2 | 0.01 | 26 | 0.10 | |
| TEST_S1 | 22,885 | 22,795 | 99.61 | 40 | 0.18 | 50 | 0.22 | |
| TEST_E2 | 11,859 | 11,788 | 99.40 | 15 | 0.13 | 56 | 0.47 | |
| TEST_S2 | 9285 | 9202 | 99.11 | 73 | 0.78 | 10 | 0.11 | |
| TOTAL | 107,276 | - | - | - | - | - | - | |
| α = 0.1 | TRAIN | 36,754 | 36,686 | 99.82 | 23 | 0.06 | 45 | 0.12 |
| TEST_E1 | 26,493 | 26,469 | 99.90 | 12 | 0.05 | 12 | 0.05 | |
| TEST_S1 | 22,885 | 22,787 | 99.57 | 21 | 0.09 | 77 | 0.34 | |
| TEST_E2 | 11,859 | 11,784 | 99.37 | 8 | 0.07 | 67 | 0.56 | |
| TEST_S2 | 9285 | 9237 | 99.48 | 26 | 0.28 | 22 | 0.24 | |
| TOTAL | 107,276 | - | - | - | - | - | - | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borz, S.A. Development of a Modality-Invariant Multi-Layer Perceptron to Predict Operational Events in Motor-Manual Willow Felling Operations. Forests 2021, 12, 406. https://doi.org/10.3390/f12040406
Borz SA. Development of a Modality-Invariant Multi-Layer Perceptron to Predict Operational Events in Motor-Manual Willow Felling Operations. Forests. 2021; 12(4):406. https://doi.org/10.3390/f12040406
Chicago/Turabian StyleBorz, Stelian Alexandru. 2021. "Development of a Modality-Invariant Multi-Layer Perceptron to Predict Operational Events in Motor-Manual Willow Felling Operations" Forests 12, no. 4: 406. https://doi.org/10.3390/f12040406