
Modeling the Dominant Height of Larix principis-rupprechtii in Northern China—A Study for Guandi Mountain, Shanxi Province


 ,
,
Abstract
:1. Introduction
2. Materials and Methods
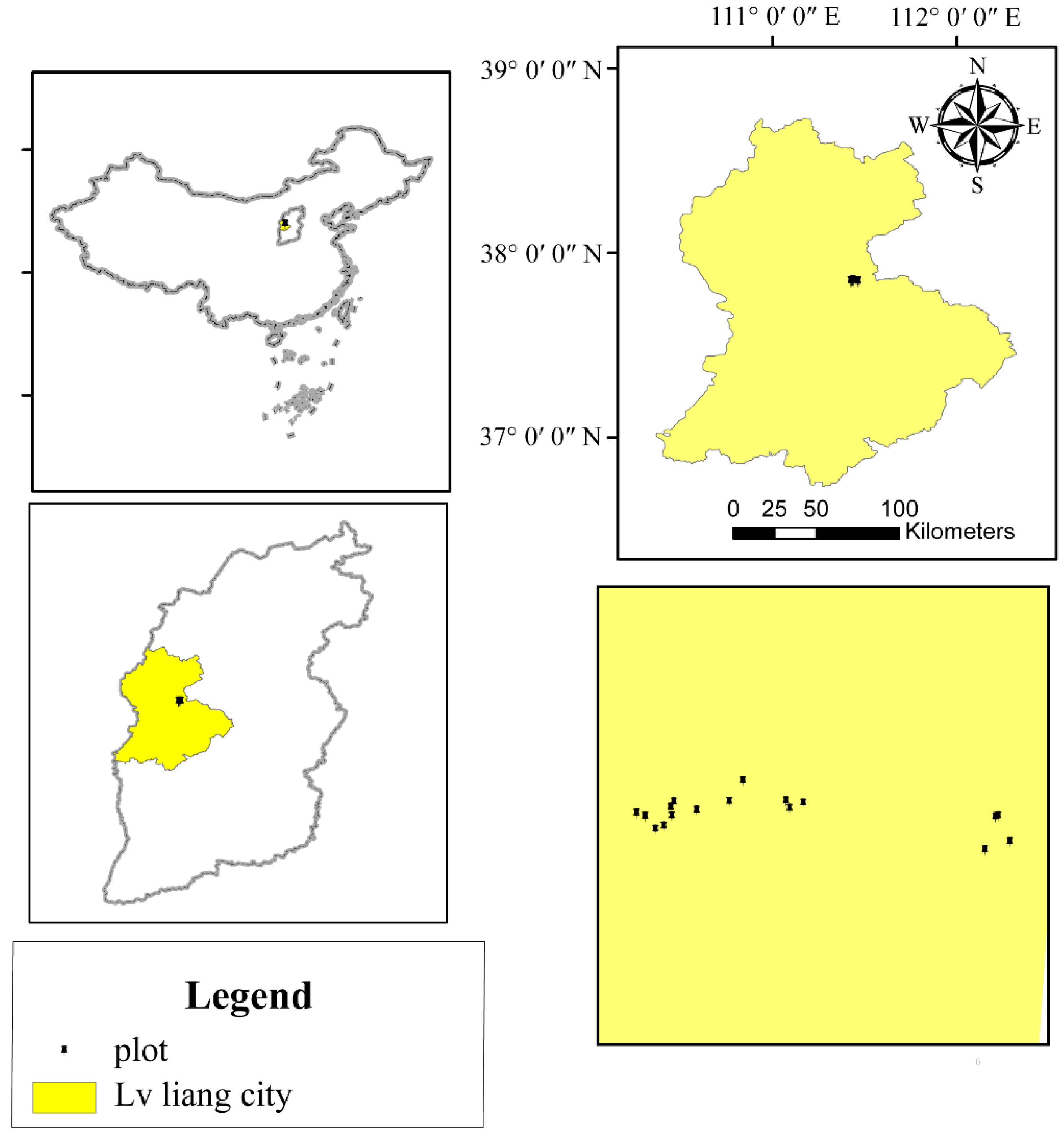
2.1. Study Areas
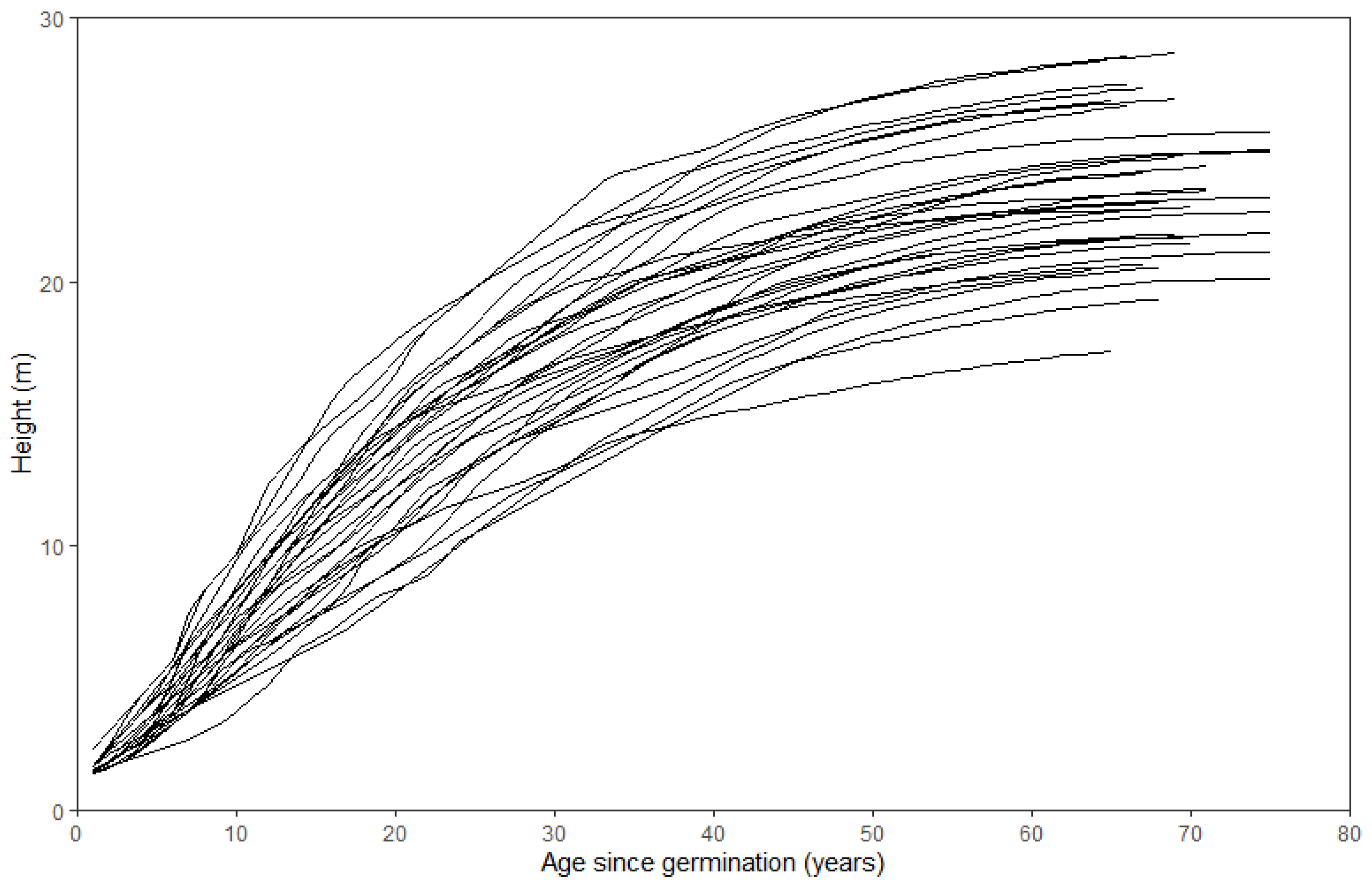
2.2. Sampling and Measurement
2.3. Stem Analysis
2.4. Base Models
2.5. Nonlinear Mixed-Effects (NLME) DH Model
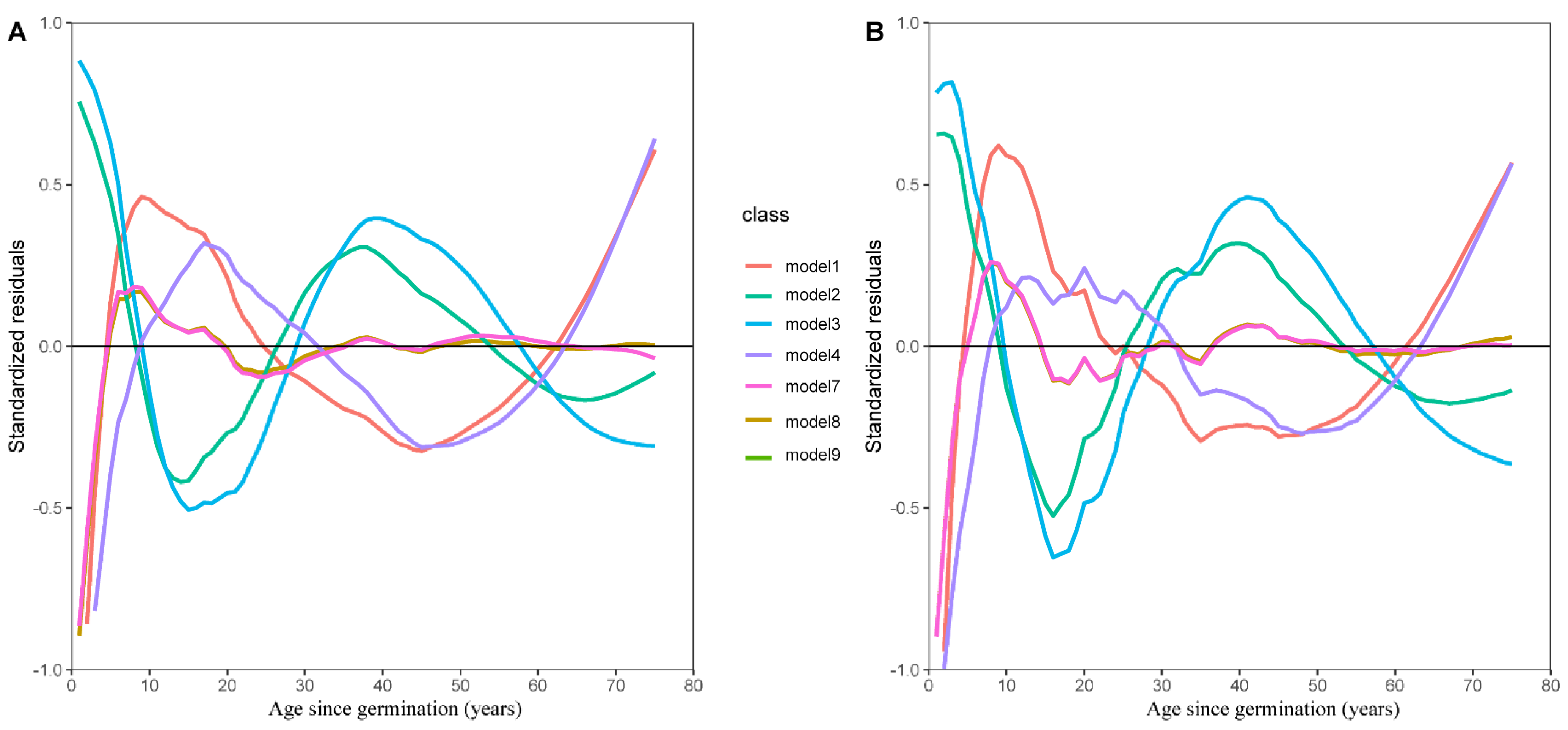
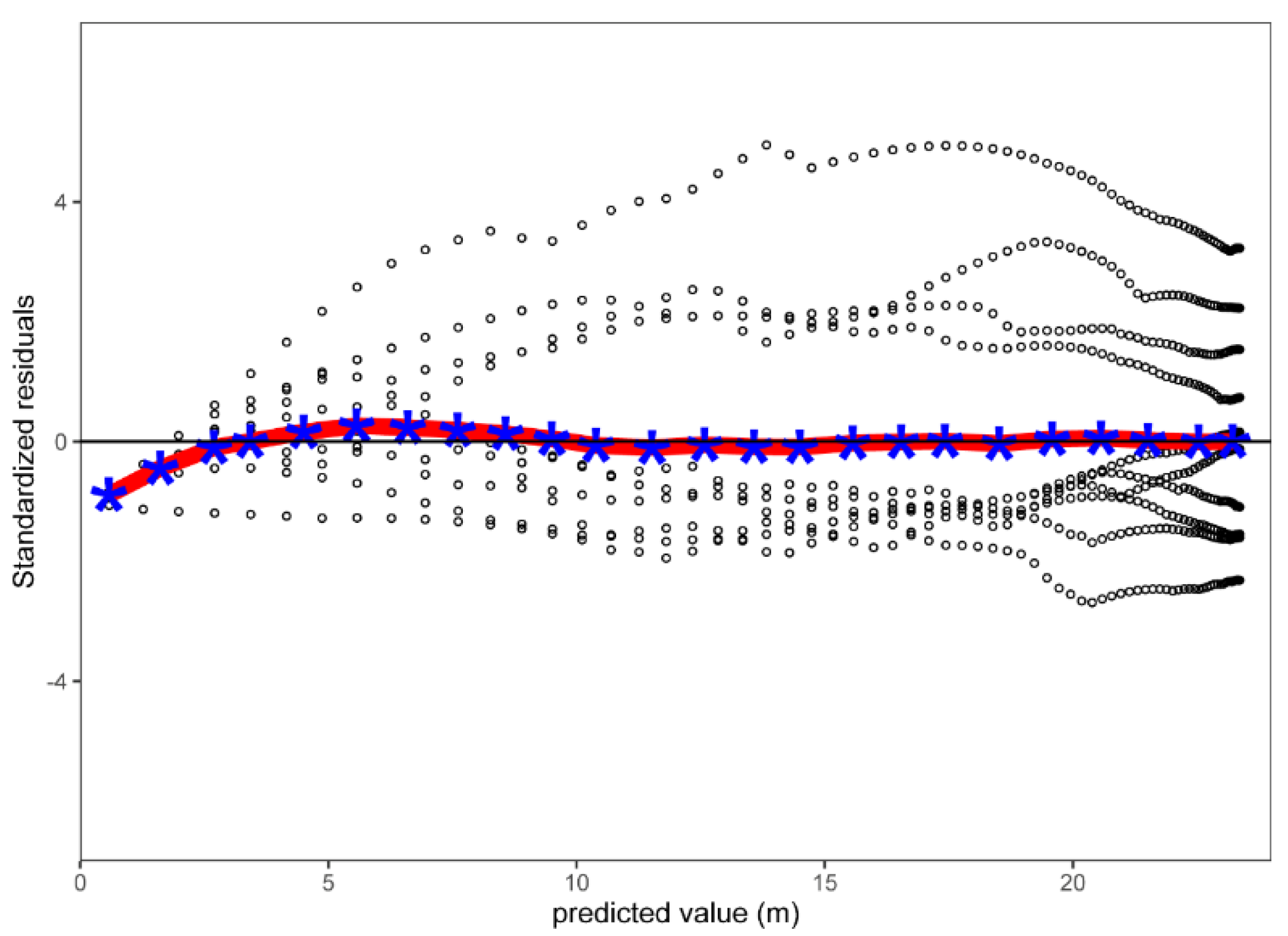
2.6. Model Evaluation
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Fu, L.; Sun, W.; Wang, G. A climate-sensitive aboveground biomass model for three larch species in northeastern and northern China. Trees 2017, 31, 557–573. [Google Scholar] [CrossRef]
- Zhou, X.; Chen, Q.; Sharma, R.P.; Wang, Y.; He, P.; Guo, J.; Lei, Y.; Fu, L. A climate sensitive mixed-effects diameter class mortality model for Prince Rupprecht larch (Larix gmelinii var. principis-rupprechtii) in northern China. For. Ecol. Manag. 2021, 491, 119091. [Google Scholar] [CrossRef]
- Zhou, X.; Fu, L.; Sharma, R.P.; He, P.; Lei, Y.; Guo, J. Generalized or general mixed-effect modelling of tree morality of Larix gmelinii subsp. principis-rupprechtii in Northern China. J. For. Res. 2021, 32, 2447–2458. [Google Scholar] [CrossRef]
- Tao, B.; Cao, M.; Yu, G.; Liu, J.; Wang, S.; Yan, H. Global carbon project (gcp) beijing office: A new bridge for understanding regional carbon cycles. J. Geogr. 2006, 16, 375–377. [Google Scholar]
- Fang, J.; Fei, S. Carbon cycle in the Arctic terrestrial ecosystems in relation to the global warming. Adv. Polar Sci. 1998, 9, 14–22. [Google Scholar]
- Spurr, S.H. Forest Inventory; Ronald Press Co.: New York, NY, USA, 1952. [Google Scholar]
- Hägglund, B. Evaluation of forest site productivity. For. Abstr. 1981, 42, 515–527. [Google Scholar]
- Burkhart, H.E.; Tomé, M. Modeling Forest Trees and Stands; Springer: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Hasenauer, H.; Kindermann, G.; Steinmetz, P. The tree growth model MOSES 3.0. In Sustaianble Forest Management, Growth Models for Europe; Hasenauer, H., Ed.; Springer: Berlin/Heidelberg, Germany, 2006; p. 388. [Google Scholar]
- Pretzsch, H.; Grote, R.; Reineking, B.; Rötzer, T.; Seifert, S. Models for forest eco-system management: A European perspective. Ann. Bot. 2008, 101, 1065–1087. [Google Scholar] [CrossRef]
- Socha, J.; Tymińska-Czabańska, L.; Grabska, E.; Orzeł, S. Site Index Models for Main Forest-Forming Tree Species in Poland. Forests 2020, 11, 301. [Google Scholar] [CrossRef]
- Zhang, H.Y. Study on Growth Intercept Model and Stand Dominant Height Growth Process of Pinus tabulaeformis Natural Forest in Guandi Mountain Forest Area; Shanxi Agriculture University: Jinzhong, China, 2005. [Google Scholar]
- Qiu, S.Y.; Cao, Y.S.; Sun, Y.J.; Pan, L. Age-independent dominant height growth model for Chinese fir plantation. J. Nanjing For. Univ. Nat. Sci. Ed. 2019, 43, 121–127. [Google Scholar] [CrossRef]
- Perin, J.; Hébert, J.; Brostaux, Y.; Lejeune, P.; Claessens, H. Modelling the top-height growth and site index of Norway spruce in Southern Belgium. For. Ecol. Manag. 2013, 298, 62–70. [Google Scholar] [CrossRef]
- Cieszewski, C.J. Developing a well-behaved dynamic site equation using a modified Hossfeld IV function Y3 = (axm)/(c + xm−1), a simplified mixed-model and scant subalpine fir data. For. Sci. 2003, 49, 539–554. [Google Scholar]
- Weiskittel, A.R.; David, W.H.; David, E.H.; Tzeng, Y.L.; Andrew, A.B. Modeling top height growth of red alder plantations. For. Ecol. Manag. 2009, 258, 323–331. [Google Scholar] [CrossRef]
- Hu, Z.; Garcia, O. A height-growth and site-index model for interior spruce in the sub-Boreal spruce biogeoclimatic zone of British Columbia. Can. J. For. Res. 2010, 40, 1175–1183. [Google Scholar] [CrossRef]
- Sharma, M.; Amateis, R.L.; Burkhart, H.E. Top height definition and its effect on site index determination in thinned and unthinned loblolly pine plantations. For. Ecol. Manag. 2002, 168, 163–175. [Google Scholar] [CrossRef]
- Bontemps, J.J.D.; Bouriaud, O. Predictive approaches to forest site productivity: Recent trends, challenges and future perspectives. Forestry 2013, 87, 109–128. [Google Scholar] [CrossRef]
- Sharma, R.P.; Brunner, A.; Eid, T.; Øyen, B.H. Modelling dominant height growth from national forest inventory individual tree data with short time series and large age errors. For. Ecol. Manag. 2011, 262, 2162–2175. [Google Scholar] [CrossRef]
- Pinheiro, J.C.; Bates, D.M. Mixed-Effects Models in S and S-PLUS; Springer: New York, NY, USA, 2000. [Google Scholar]
- Calama, R.; Montero, G. Interregional nonlinear height-diameter model with random coefficients for stone pine in Spain. Can. J. For. Res. 2004, 34, 150–163. [Google Scholar] [CrossRef]
- West, P.W.; Ratkowsky, D.A.; Davis, A.W. Problems of hypothesis testing of regressions with multiple measurements from individual sampling units. For. Ecol. Manag. 1984, 7, 207–224. [Google Scholar] [CrossRef]
- Sharma, R.P.; Fu, L.; Zhang, H.; Pang, L.; Wang, G. A generalized nonlinear mixed-effects height to crown base model for mongolian oak in northeast china. For. Ecol. Manag. 2016, 384, 34–43. [Google Scholar]
- Sharma, R.P.; Breidenbach, J. Modeling height-diameter relationships for Norway spruce, Scots pine, and downy birch using Norwegian national forest inventory data. For. Sci. Technol. 2015, 11, 44–53. [Google Scholar] [CrossRef]
- Wang, Q.; Hu, J.; Reiter, J.P. Dirichlet Process Mixture Models for Modeling and Generating Synthetic Versions of Nested Categorical Data. Bayesian Anal. 2018, 13, 183–200. [Google Scholar]
- Zhang, L. Polymorphic Site Index Cure Model and Variable Growth Intercept Model for Larix principis-rupperechtii Stand in Guandi Mountain Forest Zones; Shanxi Agriculture University: Jinzhong, China, 2016. [Google Scholar]
- Carmean, W.H. Site Index Curves for Upland Oaks in the Central States. For. Sci. 1972, 18, 109–120. [Google Scholar]
- Debouche, C. Application de la Régression Non Linéaire à L’étude et à la Comparaison de Courbes de Croissance Longitudinales—These; Faculté des Sciences Agronomiques, Gembloux: Gembloux, Belgium, 1977; p. 304. [Google Scholar]
- Chen, H.; Klinka, K.; Kabzems, R.D. Height growth and site index models for trembling aspen (Populus tremuloides Michx.) in northern British Columbia. For. Ecol. Manag. 1998, 102, 157–165. [Google Scholar] [CrossRef]
- Lappi, J.; Bailey, R.L. A height predication model with random stand and tree parameters—An alternative to traditional site index methods. For. Sci. 1988, 34, 907–927. [Google Scholar]
- Dulat, P.; Tran-Ha, M. Modelles de Croissance en Hauteur Dominante: Pour le Hetre (Fagus sylvatica L.), le Sapin Pectine (Abies alba Miller), le Pin Sylvestre (Pinus sylvestris L.) dans le Massif de L’aigoual; Office National des Forets, Section Technique: Paris, France, 1986; p. 34.
- Ercanli, I.; Kahriman, A.; Yavuz, H. Dynamic base-age invariant site index models based on generalized algebraic difference approach for mixed Scots pine (Pinus sylvestris L.) and Oriental beech (Fagus orientalis Lipsky) stands. Turk. J. Agric. For. 2014, 38, 134–147. [Google Scholar] [CrossRef]
- Seki, M.; Sakici, O.E. Dominant height growth and dynamic site index models for Crimean pine in the Kastamonu-Taşköprü region of Turkey. Can. J. For. Res. 2017, 47, 1441–1449. [Google Scholar] [CrossRef]
- Fang, Z.; Bailey, R.L. Nonlinear mixed effects modeling for slash pine dominant height growth following intensive silvicultural treatments. For. Sci. 2001, 47, 287–300. [Google Scholar]
- Fu, L.; Sun, H.; Sharma, R.P.; Lei, Y.; Zhang, H.; Tang, S. Nonlinear mixed-effects crown width models for individual trees of Chinese fir (Cunninghamia lanceolata) in south-central China. For. Eco. Manag. 2013, 302, 210–220. [Google Scholar] [CrossRef]
- Li, C.M. Application of Mixed Effects Models in Forest Growth Models. Chin. Acad. For. 2009, 45, 131–138. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: http://wwwR-projectorg/ (accessed on 1 March 2022).
- Rathgeber, C.; Blanc, L.; Ripert, C.; Vennetier, M. Modelling height growth of Aleppo pine (Pinus halepensis Mill.) in the French Mediterranean region. Ecol. Mediterr. 2004, 30, 205–218. [Google Scholar] [CrossRef]
- Duplat, P.; Tran-Ha, M. Modélisation de la croissance en hauteur dominante du chêne sessile (Quercus petraea Liebl) en France. Variabilité inter-régionale et effet de la période récente (1959–1993). Ann. For. Sci. 1997, 54, 611–634. [Google Scholar] [CrossRef]
- Raulier, F.; Lambert, M.C.; Pothier, D.; Ung, C.H. Impact of dominant tree dynamics on site index curves. For. Ecol. Manag. 2003, 184, 65–78. [Google Scholar] [CrossRef]
- Seymour, R.S.; Fajvan, M.A. Influence of prior growth suppression and soil on red spruce site index. North. J. Appl. For. 2001, 18, 55–62. [Google Scholar] [CrossRef] [Green Version]

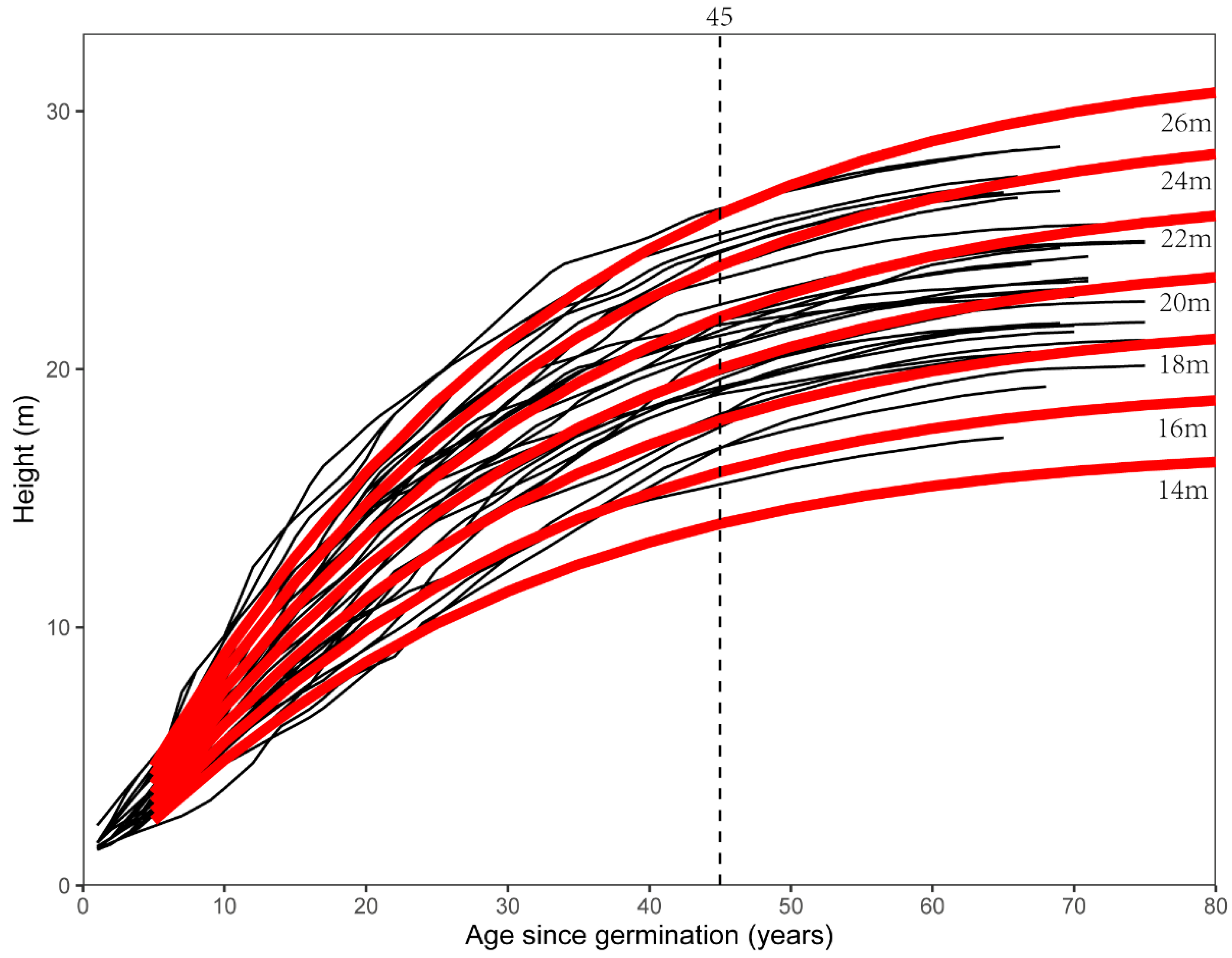

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Site Type | Number of Dominant Trees | Stand Age | Number of Plots | Slope (°) |
|---|---|---|---|---|
| Sunny slope, thick soil, and middle-elevation area | 7 | 57–75 | 2 | 6 |
| Sunny slope with medium or thick soil in the middle-elevation area | 9 | 67–75 | 4 | 7 |
| Shady slope, thick soil, and middle-elevation area | 8 | 59–73 | 3 | 9 |
| Shady slope with medium or thick soil in the middle-elevation area | 9 | 55–75 | 4 | 8 |
| Sunny slope, thick soil, and high-elevation area | 14 | 64–75 | 5 | 6 |
| Sunny slope with medium or thick soil in the high-elevation area | 11 | 68–75 | 4 | 8 |
| Shady slope, thick soil, and middle- and high-elevation areas | 9 | 57–75 | 4 | 7 |
| Shady slope with medium or thick soil in the high-elevation area | 8 | 62–72 | 3 | 8 |
| Name | Formulation | Designation | Source |
|---|---|---|---|
| Mitscherlich | (1) | [29] | |
| Gompertz | (2) | ||
| Modified Gaussian | (3) | ||
| Log-logistic | (4) | ||
| Chapman–Richards anamorphic | (5) | [30] | |
| Bailey and Clutter | (6) | [31] | |
| Duplat and Tran-Ha I | (7) | [32] | |
| Duplat and Tran-Ha II | (8) |
| Base Model Forms | Parameters Related to Site and Solution for Theoretical Variable X | Dynamic GADA Formulation | Designation | Source |
|---|---|---|---|---|
| (9) | [20] |
| Model | a | b | c | d |
|---|---|---|---|---|
| 1 | 0.6846 (0.1551 ***) | 26.1782 (0.2053 ***) | 28.1981 (0.5923 ***) | |
| 2 | 13.3189 (0.1334 ***) | 23.6106 (0.1093 ***) | 14.3975 (0.2295 ***) | |
| 3 | −10.2367 (0.3447 ***) | 23.0135 (0.0927 ***) | −34.3262 (0.4830 ***) | |
| 4 | 23.7925 (0.6569 ***) | 29.5419 (0.4642 ***) | 1.3459 (0.0293 ***) | |
| 5 | - | - | - | |
| 6 | −6.9349 (0.2548 **) | 3.7427 (0.0374 ***) | 0.5956 (0.0229 ***) | |
| 7 | 55.2780 (17.0909 *) | −0.2938 (0.1438 ***) | 63.8875 (22.9816 ***) | 1.0400 (0.0332 ***) |
| 8 | 259.4453 (236.4819) | −48.9553 (47.9220) | 104.5320 (71.9311) | 1.2811 (0.01528) *** |
| 9 | −1.6187 (0.0494 ***) | 0.0234 (0.0003 ***) |
| Model | Model Fitting Data | Model Validation Data | |||||
|---|---|---|---|---|---|---|---|
| MD | RMSE | TRE | R2 | MD | RMSE | TRE | |
| 1 | 0.0001 | 2.4587 | 1.9925 | 0.8790 | −0.0733 | 1.6564 | 0.8276 |
| 2 | −0.0161 | 2.4482 | 1.9753 | 0.8800 | −0.0896 | 1.6418 | 0.8130 |
| 3 | −0.0179 | 2.4573 | 1.9903 | 0.8791 | −0.0918 | 1.6625 | 0.8337 |
| 4 | 0.0416 | 2.4570 | 1.9898 | 0.8791 | −0.0328 | 1.6460 | 0.8172 |
| 5 | - | - | - | - | - | - | - |
| 6 | 0.0626 | 2.4905 | 2.0456 | 0.8758 | −0.0101 | 1.6982 | 0.8703 |
| 7 | 0.0131 | 2.4386 | 1.9595 | 0.8809 | −0.0595 | 1.6262 | 0.7975 |
| 8 | 0.0158 | 2.4391 | 1.9603 | 0.8809 | −0.0576 | 1.6260 | 0.7973 |
| 9 | −0.0467 | 2.6324 | 2.2908 | 0.8613 | −0.0598 | 1.9340 | 1.1490 |
| Model | Parameter Estimates | Random Effects | Fit Statistics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | c | d | R2 | RMSE | TRE | LL | ||
| Model 7 | 22.1398 | 0.0348 | 23.4600 | 1.1566 | 1.5682 | 0.9060 | 2.1667 | 1.5403 | −8963.653 |
| Model 8 | 17.7929 | 1.6331 | 23.4646 | 1.0941 | 1.5785 | 0.9060 | 2.1669 | 1.5406 | −8964.046 |
| Variance Functions | NLME Model 7 | |
|---|---|---|
| AIC | LL | |
| Equation (15) | 17766.92 | −8876.46 |
| Equation (16) | 17500.2 | −8743.10 |
| Equation (17) | 17502.19 | −8743.097 |
| Equation (15) + AR(1) | 17705.89 | −8844.944 |
| Equation (16) + AR(1) | 17466.55 | −8725.273 |
| Equation (17) + AR(1) | 17468.55 | −8725.273 |
| AR(1) | 17873.81 | −8929.906 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhou, X.; Guo, J.; Sharma, R.P.; Zhang, L.; Zhou, H. Modeling the Dominant Height of Larix principis-rupprechtii in Northern China—A Study for Guandi Mountain, Shanxi Province. Forests 2022, 13, 1592. https://doi.org/10.3390/f13101592
Zhang Y, Zhou X, Guo J, Sharma RP, Zhang L, Zhou H. Modeling the Dominant Height of Larix principis-rupprechtii in Northern China—A Study for Guandi Mountain, Shanxi Province. Forests. 2022; 13(10):1592. https://doi.org/10.3390/f13101592
Chicago/Turabian StyleZhang, Yunxiang, Xiao Zhou, Jinping Guo, Ram P. Sharma, Lei Zhang, and Huoyan Zhou. 2022. "Modeling the Dominant Height of Larix principis-rupprechtii in Northern China—A Study for Guandi Mountain, Shanxi Province" Forests 13, no. 10: 1592. https://doi.org/10.3390/f13101592