

Comparison of Multiple Machine Learning Models for Estimating the Forest Growing Stock in Large-Scale Forests Using Multi-Source Data
Abstract
:1. Introduction
2. Materials and Methods
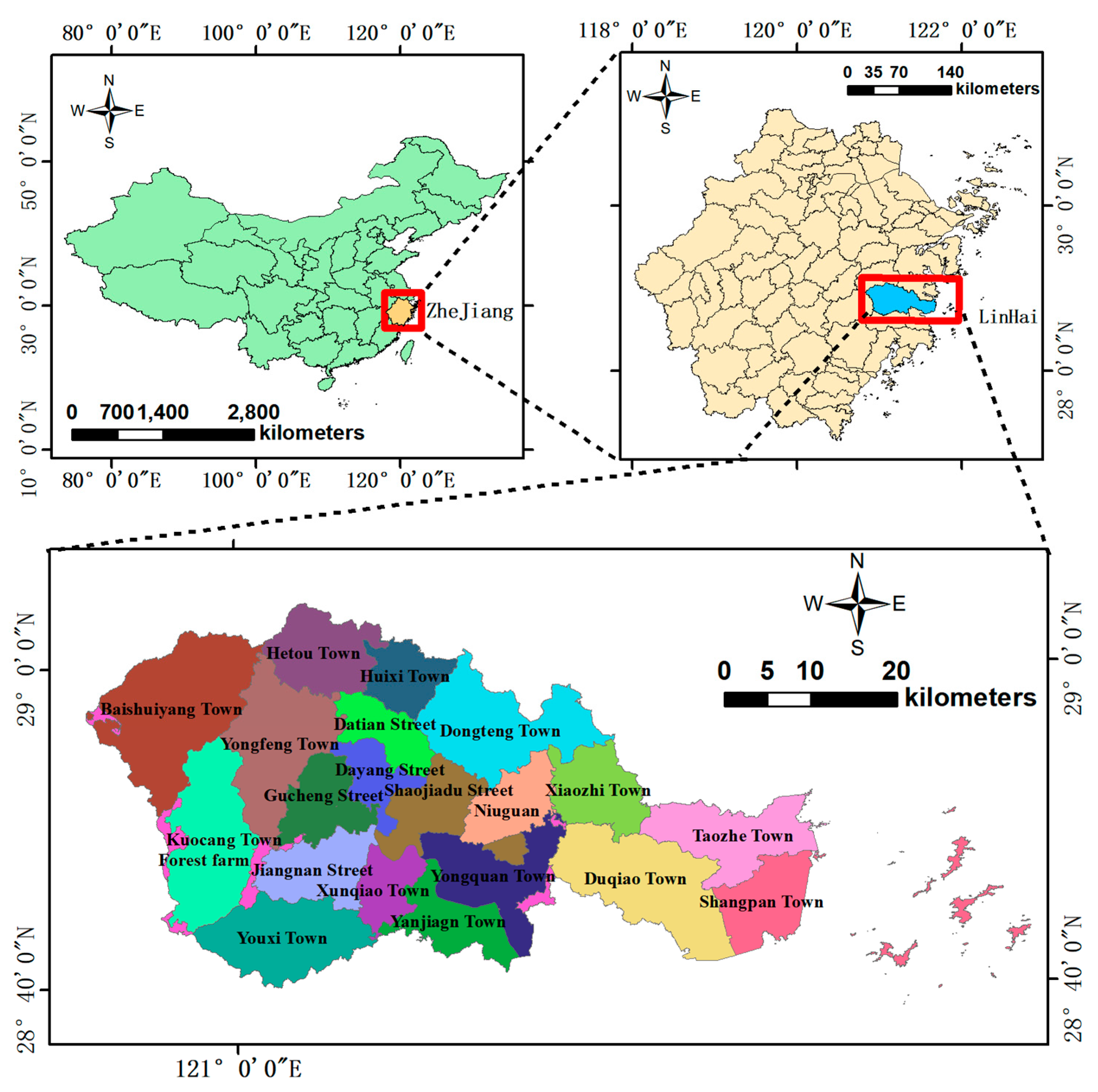
2.1. Overview of the Research Area
2.2. Research Data
2.2.1. Remote Sensing Data
2.2.2. Ground Data
2.3. Independent Variable Factor Extraction
2.3.1. The Independent Variable Factors from Optical Remote Sensing Images
2.3.2. The Independent Variable Factors from Radar Remote Sensing Images
2.3.3. The Independent Variable Factors from Ground Data
2.3.4. Data Integration
2.4. Methods
2.4.1. Gradient Boosting Decision Tree (GBDT)
2.4.2. eXtreme Gradient Boosting (XGBoost)
2.4.3. Categorical Boosting (CatBoost)
- To predict the offset: Traditional gradient enhancement depends on the sample itself for gradient calculation, and noise points will bring prediction offsets and eventually lead to overfitting. CatBoost first sorts the entire dataset several times and then removes the i-th data item for the first i-1 pieces of data, calculates the loss function and gradient, builds a residual tree, and finally adds the residual tree to the original model, which effectively avoids the prediction offset and reduces overfitting.
- To process the category features: The CatBoost algorithm can automatically process categorical features and combine the original category features according to the inherent relationship of the features, which enriches the feature dimensions to improve the accuracy of the prediction results. In addition, the automatic processing of category features also greatly improves efficiency.
- (1)
- To randomly arrange the categorical features to generate multiple random sequences.
- (2)
- To replace each sequence’s value with the average label value of the training dataset (shown in Formula (1)).where if xjk == xik, then [xjk = xik] = 1; otherwise, xjk = 0.
- (3)
- To convert the sequence’s value into a numerical value (shown in Formula (2)).where , P is the prior value, and a is the coefficient of the weight for the prior of P.
2.4.4. Least Absolute Shrinkage and Selection Operator (Lasso)
2.5. Model Performance Indicators
3. Results
3.1. Screening for Independent Variable Factors
3.1.1. Variable Screening for Data Schemes A and B
3.1.2. Variable Screening for Data Schemes C and D
3.2. Result Analysis
3.2.1. Analysis for Data Schemes A and B
3.2.2. Analysis for Data Schemes C and D
4. Discussion
4.1. Principal Findings
4.2. Comparison with Other Studies
4.3. Strengths and Limitations of This Study
- (1)
- A total of 34 independent variable factors are obtained, and the Lasso algorithm effectively reduces the number of independently variable factors so as to speed up the training process of the model and improve the generalization ability of the model.
- (2)
- The addition of category features significantly improves the performance of the models. This mainly depends on contributions of two aspects. One is the category features of forest population and dominant species; the addition of these category features gives more targeted estimation results according to different categories. The other is for the category features of humus thickness and aspect direction; the addition of these category features further reflects the relationship between the plant growth and the environmental factors, e.g., plants with thicker humus or on sunny slopes tend to grow better. Therefore, the model inclines to obtain a higher accuracy after adding category features.
- (3)
- It is easier to obtain the vertical structure parameters of vegetation by radar remote sensing data, which can overcome the shortcomings of optical remote sensing data to a certain extent. Thus, the combination of radar remote sensing data and optical remote sensing data can be used to estimate forest growing stock more accurately than single remote sensing data.
- (4)
- When adding the radar remote sensing data and the category features, the performance of the model improved significantly. Compared with data scheme A (without radar remote sensing data and without category features), for scheme D (with radar remote sensing data and with category features), the R2 increased by 10.76–14.71%, while MSE, MAE, and MAPE decreased by 28.44–39.22%, 10.53–20.27%, and from 24.70–27.02% to 16.20–20.28%, respectively.
- (5)
- CatBoost first sorts the entire dataset several times and then removes the i-th data item, and builds residual trees and adds them to the original model step by step, which effectively avoids the prediction offset and reduces overfitting. Furthermore, the CatBoost algorithm can automatically process categorical features and combines the original category features according to the inherent relationship of the features, which enriches the feature dimensions to improve the accuracy of the prediction results. Thus, CatBoost is the best of the three models GBDT, XGBoost, and CatBoost. When based on data scheme D, the performance indicators of the CatBoost model are R2 of 0.78, MSE of 0.62 m3/ha, MAE of 0.59 m3/ha, and MAPE of 16.20%. Moreover, the estimation accuracy is close to 85%, which has practical significance and benefit in estimating the forest growing stock.
- (1)
- The texture features of remote sensing images can effectively improve the estimation accuracy to estimate forest growing stock. However, we only extracted the texture features from optical remote sensing images. If various window sizes, asynchronous lengths, and combinations from various bands are used to extract the texture features of radar remote sensing images, it would be helpful to explore the impact of texture features to improve the estimating accuracy [11].
- (2)
- The imaging date of remote sensing images used in this study is between October and November. There are some inconsistencies with the tree growth period. In the autumn and winter, some tree species are entering dormancy, which may lead to yellowing and even falling leaves. The vegetation information reflected from the remote sensing images, especially the optical remote sensing images, may not correctly reflect the sincere information of trees, which would reduce the estimation accuracy of the models. If remote sensing images with an imaging date consistent with the growth period of trees can be found in the future, the estimating accuracy may be further optimized.
- (3)
- It is necessary to verify the generality of the model through a more extensive range of the estimation of forest growing stock volume. Santoro et al. [68]’s research on global biomass estimates will provide us with a validation set.
5. Conclusions
- (1)
- The Lasso algorithm effectively reduced the number of independent variable factors and retained the main features, speeding up the training process of the model and improving the generalization ability of the model.
- (2)
- Radar remote sensing waves more easily penetrate the forest surface to obtain the vertical parameters of the forest, which makes up for the shortcomings of optical remote sensing data sources to a certain extent and could improve the estimation accuracy of forest growing stock.
- (3)
- The addition of category features led to more targeted estimation and significantly improved the performance of the models.
- (4)
- To estimate the forest growing stock, the CatBoost algorithm is the best model among the three models GBDT, XGBoost, and CatBoost. Distinguished from the common artificial classification methods which established different models according to various category characteristics, the CatBoost model is more efficient and convenient.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, D.; Chen, Q.; Wang, G. A survey of remote sensing-based aboveground biomass estimation methods in forest ecosystems. Int. J. Digit. Earth. 2014, 9, 63–105. [Google Scholar] [CrossRef]
- Scrinzi, G.; Marzullo, L.; Galvagni, D. Development of a neural network model to update forest distribution data for managed alpine stands. Ecol. Model. 2007, 206, 331–346. [Google Scholar] [CrossRef]
- Santoro, M.; Cartus, O.; Fransson, J. Estimates of forest growing stock for Sweden, Central Siberia, and Québec Using Envisat Advanced Synthetic Aperture Radar Backscatter Data. Remote Sens. 2013, 5, 4503–4532. [Google Scholar] [CrossRef]
- Tanaka, S.; Takahashi, T.; Nishizono, T. Stand Volume Estimation Using the k-NN Technique Combined with Forest Inventory Data, Satellite Image Data and Additional Feature Variables. Remote Sens. 2015, 7, 378–394. [Google Scholar] [CrossRef]
- Mohammadi, Z.; Mohammadi Limaei, S.; Lohmander, P. Estimation of a basal area growth model for individual trees in uneven-aged Caspian mixed species forests. J. For. Res. 2017, 29, 1205–1214. [Google Scholar] [CrossRef]
- Wu, D.; Ji, Y. Dynamic Estimation of Forest Volume Based on Multi-Source Data and Neural Network Model. J. Agric. Sci. 2015, 7, 18. [Google Scholar] [CrossRef]
- Maselli, F.; Chiesi, M.; Mura, M. Combination of optical and LiDAR satellite imagery with forest inventory data to improve wall-to-wall assessment of growing stock in Italy. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 377–386. [Google Scholar] [CrossRef]
- Chirici, G.; Barbati, A.; Corona, P. Non-parametric and parametric methods using satellite images for estimating growing stock volume in alpine and Mediterranean forest ecosystems. Remote Sens. Environ. 2008, 112, 2686–2700. [Google Scholar] [CrossRef]
- Tomppo, E.; Halme, M. Using coarse scale forest variables as ancillary information and weighting of variables in k-NN estimation: A genetic algorithm approach. Remote Sens Environ. 2004, 92, 1–20. [Google Scholar] [CrossRef]
- Boisvenue, C.; Smiley, B.P.; White, J.C. Integration of Landsat time series and field plots for forest productivity estimates in decision support models. For. Ecol. Manag. 2016, 376, 284–297. [Google Scholar] [CrossRef]
- Wang, K.N.; Lv, J.; Li, C.G. Inversion of Growing Stock Volume Using Satellite Image Multiscale Texture Feature. J. Cent. South Univ. 2017, 37, 84–89. (In Chinese) [Google Scholar]
- Hao, L.; Liu, H.; Chen, Y.F. Remote Sensing Estimation of forest growing stock Based on Spectral and Texture Information. J. Mt. Sci. 2017, 35, 246–254. (In Chinese) [Google Scholar]
- Chrysafis, I.; Mallinis, G.; Siachalou, S. Assessing the relationships between growing stock volume and Sentinel-2 imagery in a Mediterranean forest ecosystem. Remote Sens. Lett. 2017, 8, 508–517. [Google Scholar] [CrossRef]
- Sothe, C.; Almeida, C.; Liesenberg, V. Evaluating Sentinel-2 and Landsat-8 Data to Map Successional Forest Stages in a Subtropical Forest in Southern Brazil. Remote Sens. 2017, 9, 838. [Google Scholar] [CrossRef]
- Mura, M.; Bottalico, F.; Giannetti, F. Exploiting the capabilities of the Sentinel-2 multi spectral instrument for predicting growing stock volume in forest ecosystems. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 126–134. [Google Scholar] [CrossRef]
- Wang, Z.M.; Yue, C.Y.; Liu, Q. Study on Model of Forest Volume Estimation Based on Optical and Microwave Remote Sensing Data. Southwest China J. Agric. Sci. 2018, 31, 1722–1726. (In Chinese) [Google Scholar]
- Chowdhury, T.A.; Thiel, C.; Schmullius, C. Growing stock volume estimation from L-band ALOS PALSAR polarimetric coherence in Siberian forest. Remote Sens. Environ. 2014, 155, 129–144. [Google Scholar] [CrossRef]
- Thiel, C.; Schmullius, C. The potential of ALOS PALSAR backscatter and InSAR coherence for forest growing stock estimation in Central Siberia. Remote Sens. Environ. 2016, 173, 258–273. [Google Scholar] [CrossRef]
- Yang, M.S.; Xu, T.S.; Niu, X.H. Estimation of Pinus Kesiya var. Langbianensis Forest Stock Volume Based on Sentinel-1A SAR Image. J. West China For. Sci. 2019, 48, 52–58. (In Chinese) [Google Scholar]
- Laurin, G.V.; Balling, J.; Corona, P. Above-ground biomass prediction by Sentinel-1 multitemporal data in central Italy with integration of ALOS2 and Sentinel-2 data. J. Appl. Remote Sens. 2018, 12, 016008. [Google Scholar] [CrossRef]
- Ningthoujam, R.; Balzter, H.; Tansey, K.; Morrison, K.; Johnson, S.; Gerard, F.; George, C.; Malhi, Y.; Burbidge, G.; Doody, S.; et al. Airborne S-Band SAR for Forest Biophysical Retrieval in Temperate Mixed Forests of the UK. Remote Sens. 2016, 8, 609. [Google Scholar] [CrossRef]
- Du, J.; Shi, J.; Sun, R. The development of HJ SAR soil moisture retrieval algorithm. Int. J. Remote Sens. 2010, 31, 3691–3705. [Google Scholar] [CrossRef]
- Bird, R.; Whittaker, P.; Stern, B.; Angli, N.; Cohen, M.; Guida, R. NovaSAR-S a low cost approach to sar applications, synthetic aperture radar. In Proceedings of the IEEE 2013 Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Tsukuba, Japan, 23–27 September 2013; pp. 84–87. [Google Scholar]
- Jet Propulsion Laboratory (JPL). Mission to Earth: NASA-ISRO Synthetic Aperture Radar. Available online: http://www.Jpl.Nasa.Gov/missions/nasa-isro-synthetic-aperture-radar-nisar/ (accessed on 15 December 2015).
- Jet Propulsion Laboratory (JPL). Overview. Available online: https://nisar.jpl.nasa.gov/mission/get-to-know-sar/overview/ (accessed on 4 September 2022).
- Torbick, N.; Ledoux, L.; Salas, W. Regional Mapping of Plantation Extent Using Multisensor Imagery. Remote Sens. 2016, 8, 236. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, L. Estimating Forest Aboveground Biomass by Combining Optical and SAR Data: A Case Study in Genhe, Inner Mongolia, China. Sensors 2016, 16, 834. [Google Scholar] [CrossRef] [Green Version]
- Zhao, P.; Lu, D.; Wang, G. Forest aboveground biomass estimation in Zhejiang Province using the integration of Landsat TM and ALOS PALSAR data. Int. J. Appl. Earth Obs. Geoinf. 2016, 53, 1–15. [Google Scholar] [CrossRef]
- Fedrigo, M.; Meir, P.; Sheil, D. Fusing radar and optical remote sensing for biomass prediction in mountainous tropical forests. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium, IGARSS, Melbourne, Australia, 21–26 July 2013. [Google Scholar]
- Vafaei, S.; Soosani, J.; Adeli, K. Improving Accuracy Estimation of Forest Aboveground Biomass Based on Incorporation of ALOS-2 PALSAR-2 and Sentinel-2A Imagery and Machine Learning: A Case Study of the Hyrcanian Forest Area (Iran). Remote Sens. 2018, 10, 172. [Google Scholar] [CrossRef]
- Chirici, G.; Giannetti, F.; Mcroberts, R.E. Wall-to-wall spatial prediction of growing stock volume based on Italian National Forest Inventory plots and remotely sensed data. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101959. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M.; Li, G. Land use/cover classification in the Brazilian Amazon using satellite images. Pesqui. Agropecu. Bras. 2012, 47. [Google Scholar] [CrossRef]
- Drusch, M.; Bello, U.D.; Carlier, S. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Puliti, S.; Saarela, S.; Gobakken, T. Combining UAV and Sentinel-2 auxiliary data for forest growing stock estimation through hierarchical model-based inference. Remote Sens. Environ. 2018, 204, 485–497. [Google Scholar] [CrossRef]
- Zharko, V.O.; Bartalev, S.A.; Sidorenkov, V.M. Forest growing stock estimation using optical remote sensing over snow-covered ground: A case study for Sentinel-2 data and the Russian Southern Taiga region. Remote Sens. Lett. 2020, 11, 677–686. [Google Scholar] [CrossRef]
- Macintyre, P.; Niekerk, A.; Mucina, L. Efficacy of multi-season Sentinel-2 imagery for compositional vegetation classification. Int. J. Appl. Earth Obs. Geoinf. 2020, 85, 101980. [Google Scholar] [CrossRef]
- Grabska, E.; Hostert, P.; Pflugmacher, D. Forest Stand Species Mapping Using the Sentinel-2 Time Series. Remote Sens. 2019, 11, 1197. [Google Scholar] [CrossRef]
- Reis, M.S.; Dutra, L.V.; Sant’Anna, S.J.S. Multi-source change detection with PALSAR data in the Southern of Pará state in the Brazilian Amazon. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101945. [Google Scholar] [CrossRef]
- Rumora, L.; Miler, M.; Medak, D. Impact of Various Atmospheric Corrections on Sentinel-2 Land Cover Classification Accuracy Using Machine Learning Classifiers. ISPRS Int. J. Geo-Inf. 2020, 9, 277. [Google Scholar] [CrossRef]
- Were, K.; Bui, D.T.; Dick, Ø.B.; Singh, B.R. A comparative assessment of support vector regression, artificial neural networks, and random forests for predicting and mapping soil organic carbon stocks across an Afromontane landscape. Ecol. Indic. 2015, 52, 394–403. [Google Scholar] [CrossRef]
- Dos Reis, A.A.; Carvalho, M.C.; Mello, J.M. Spatial prediction of basal area and volume in Eucalyptus stands using Landsat TM data: An assessment of prediction methods. N. Z. J. For. Sci. 2018, 48, 1. [Google Scholar] [CrossRef]
- Esteban, J.; Mcroberts, R.; Fernández-Landa, A. Estimating Forest Volume and Biomass and Their Changes Using Random Forests and Remotely Sensed Data. Remote Sens. 2019, 11, 1944. [Google Scholar] [CrossRef]
- Zhou, R.Y.; Wu, D.S.; Fang, L.M. A Levenberg-Marquardt Backpropagation Neural Network for Predicting Forest Growing Stock Based on the Least-Squares Equation Fitting Parameters. Forests 2018, 9, 757. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Yu, D.; Liu, Z.; Su, C. Copy number variation in plasma as a tool for lung cancer prediction using Extreme Gradient Boosting (XGBoost) classifier. Thorac. Cancer 2020, 11, 95–102. [Google Scholar] [CrossRef] [PubMed]
- Liang, W.; Luo, S.; Zhao, G. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics 2020, 8, 765. [Google Scholar] [CrossRef]
- Liu, T.; Jiang, T.; Ang, L.I.; Guo, L. Remote sensing estimation of forest stock volume based on neural network and different site quality. J. Shandong Univ. Sci. Technol. Sci. 2019, 38, 25–35. (In Chinese) [Google Scholar] [CrossRef]
- Wang, Z.; Xu., T.S.; Yue, C.R. Application of Dummy Variable in the Research of Pinus densata Stock Volume Inversion Model. For. Resour. Manag. 2017, 75–81. (In Chinese) [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of Leaf-Area Index from Quality of Light on the Forest Floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Goel, N.S.; Qin, W. Influences of canopy architecture on relationships between various vegetation indices and LAI and Fpar: A computer simulation. Remote Sens. Rev. 1994, 10, 309–347. [Google Scholar] [CrossRef]
- Rouse, J.W., Jr.; Hass, R.H. Monitoring Vegetation Systems in the Great Plains with ERTS; Texas A&M University: College Station, TX, USA, 1974; Volume 20, pp. 309–313. [Google Scholar]
- Sims, D.A.; Gamon, J.A. Relationships between leaf pigment content and spectral reflectance across a wide range of species, leaf structures and developmental stages. Remote Sens. Environ. 2002, 81, 337–354. [Google Scholar] [CrossRef]
- Hardisky, M.S.; Klemas, V. The influence of soil salinity, growth form, and leaf moisture on the spectral radiance of Spartina Alterniflora canopies. Photogramm. Eng. Remote Sens. 1983, 49, 77–84. [Google Scholar]
- Yang, W.; Kobayashi, H.; Wang, C.; Shen, M.G.; Chen, J.; Matsushita, B.; Tang, Y.H.; Kim, Y.W.; Bret-Harte, S.; Zona, D.; et al. A semi-analytical snow-free vegetation index for improving estimation of plant phenology in tundra and grassland ecosystems. Remote Sens. Environ. 2019, 228, 31–44. [Google Scholar] [CrossRef]
- Huete, A.R.; Liu, H.Q.; Batchily, K.; YanLeeuwen, W. A comparison of vegetation indices global set of TM images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Richardson, A.J.; Wiegand, C.L. Distinguishing vegetation from soil background information. Photogramm. Eng. Remote Sens. 1977, 43, 1541–1552. [Google Scholar]
- Cao, L. Estimation of Forest Stock Volume in Yuqing District Based on Sentinel-2 Image. Master’s Thesis, Beijing Forestry University, Beijing, China, 2019. (In Chinese). [Google Scholar]
- Gitelson, A.A.; Merzlyak, M.N. Remote estimation of chlorophyll content in higher plant leaves. Int. J. Remote Sens. 1997, 18, 2691–2697. [Google Scholar] [CrossRef]
- Cao, L.; Peng, D.L.; Wang, X.J. Estimation of Forest Stock Volume with Spectral and Textural Information from the Sentinel-2A. J. Northeast For. Univ. 2018, 46, 54–58. (In Chinese) [Google Scholar]
- Liu, M.Y.; Wang, X.L.; Feng, Z.K. Estimation of Laotudingzi Nature Reserve Forest Volume Based on Principal Component Analysis. J. Cent. South Univ. 2017, 37, 80–83. (In Chinese) [Google Scholar]
- Mauya, E.W.; Koskinen, J.; Tegel, K. Modelling and Predicting the Growing Stock Volume in Small-Scale Plantation Forests of Tanzania Using Multi-Sensor Image Synergy. Forests 2019, 10, 279. [Google Scholar] [CrossRef]
- Zhou, J.; Zhou, Z.; Zhao, Q. Evaluation of Different Algorithms for Estimating the Growing Stock Volume of Pinus massoniana Plantations Using Spectral and Spatial Information from a SPOT6 Image. Forests 2020, 11, 540. [Google Scholar] [CrossRef]
- Huang, Y.L.; Wu, D.S.; Fang, L.M. Forest stock volume estimation based on XGboost method of stepwise regression. J. Cent. South Univ. For. Technol. 2020, 40, 72–80. (In Chinese) [Google Scholar]
- Santoro, M.; Cartus, O.; Carvalhais, N.; Rozendaal, D.M.A.; Avitabile, V.; Araza, A.; de Bruin, S.; Herold, M.; Quegan, S.; Rodríguez-Veiga, P.; et al. The Global Forest Above-Ground Biomass Pool for 2010 Estimated from High-Resolution Satellite Observations. Earth Syst. Sci. Data 2021, 13, 3927–3950. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Remote Sensing Images | Satellite | Date of Acquisition | Product Level |
|---|---|---|---|
| Optical remote sensing | Sentiniel-2B, Sentinel-2A | 27 November 2017, 3 scenes October 2017, 1 scene | L1C |
| Radar remote sensing | Sentinel-1A | 13 October 2017, 2 scenes | IW GRD |
| No. | Vegetation Index | Formula | Reference |
|---|---|---|---|
| 1 | Soil Adjusted Vegetation Index (SAVI) | SAVI = ((NIR − R)/(NIR + R + L)) × 1.5 | [52] |
| 2 | Ratio Vegetation Index (RVI) | RVI = NIR/R | [53] |
| 3 | Nonlinear Index (NLI) | NLI = ((NIR × NIR) − R)/((NIR × NIR) + R) | [54] |
| 4 | Normalized Difference Vegetation Index (NDVI) | NDVI = (NIR − R)/(NIR + R) | [55] |
| 5 | Modified Normalized Difference Vegetation Index (mNDVI) | mNDVI = (NIR − R)/(NIR + R − 2 × B) | [56] |
| 6 | Normalized Difference Infrared Index (NDII) | NDII = (NIR − SWIR1)/(NIR + SWIR1) | [57] |
| 7 | Normalized Difference Green Index (NDGI) | NDGI = (G − R)/(G + R) | [58] |
| 8 | Enhanced Vegetation Index (EVI) | EVI = 2.5 × (NIR − R)/(NIR + 6 × R − 7.5 × B + 1) | [59] |
| 9 | Difference Vegetation Index (DVI) | DVI = NIR − R | [60] |
| 10 | RedEdge Ratio Vegetation Index (RVIre) | RVIre = NIR/Re | [61] |
| 11 | RedEdge1 Normalized Difference Vegetation Index (NDVIre1) | NDVIre1 = (NIR − Re1)/(NIR + Re1) | [62] |
| 12 | RedEdge2 Normalized Difference Vegetation Index (NDVIre2) | NDVIre2 = (NIR − Re2)/(NIR + Re2) | [62] |
| 13 | Modified RedEdge Normalized Difference Vegetation Index (mNDVIre) | mNDVIre = (NIR − Re1)/(NIR + Re1-2 × B) | [56] |
| 14 | RedEdge Nonlinear index(NLIre) | NLIre = ((NIR × NIR) − Re1)/((NIR × NIR) + Re1) | [61] |
| No. | Factor Name | Explanation | Source of Data | Types of Factors |
|---|---|---|---|---|
| 1–14 | Refer to Table 2 | Vegetation indexes from optical remote sensing images | Independent Variable Factors | |
| 15 | Mean | Mean | Texture features from optical remote sensing images | |
| 16 | Variance | Variance | ||
| 17 | Homogeneity | Homogeneity | ||
| 18 | Contrast | Contrast | ||
| 19 | Dissimilarity | Dissimilarity | ||
| 20 | Entropy | Entropy | ||
| 21 | Angular second moment | Angular second moment | ||
| 22 | Correlation | Correlation | ||
| 23 | VV | VV polarization | Radar remote sensing images | |
| 24 | VH | VH polarization | ||
| 25 | VV/VH | Polarization coefficient ratio | ||
| 26 | VV-VH | Polarization coefficient difference | ||
| 27 | ELEVATION | Altitude | Digital elevation model | |
| 28 | SLOPE | Slope | ||
| 29 | ASPECT | Aspect angle | ||
| 30 | PO_WEI | Slope position | Inventory data for forest management planning and design | |
| 31 | TU_CENG_HD | Soil thickness | ||
| 32 | ZB_FGD | Vegetation coverage | ||
| 33 | NL | Tree age | ||
| 34 | YU_BI_DU | Canopy density | ||
| 35 | QUN_LUO | Forest population | Inventory data for forest management planning and design | Category features |
| 36 | YOU_SHI_SZ | Dominant species | ||
| 37 | FU_ZHI_HD | Humus thickness | ||
| 38 | PO_XIANG | Aspect direction | ||
| Data Scheme | Data Source | Category Features |
|---|---|---|
| A | Sentinel-2, DEM, Inventory data for forest management planning and design | Did not add |
| B | Added | |
| C | Sentinel-2, Sentiniel-1, DEM, Inventory data for forest management planning and design | Did not add |
| D | Added |
| Data Scheme | A | B | C | D | |
|---|---|---|---|---|---|
| GBDT | R2 | 0.65 | 0.71 | 0.63 | 0.72 |
| MSE | 1.09 | 0.90 | 1.05 | 0.78 | |
| MAE (m3/ha) | 0.76 | 0.69 | 0.78 | 0.68 | |
| MAPE (%) | 27.02 | 24.64 | 23.71 | 20.28 | |
| RMSE | 1.04 | 0.95 | 1.02 | 0.88 | |
| RMSEr (%) | 25.90 | 23.53 | 25.42 | 21.91 | |
| XGBoost | R2 | 0.66 | 0.73 | 0.63 | 0.75 |
| MSE | 1.06 | 0.86 | 1.03 | 0.71 | |
| MAE(m3/ha) | 0.74 | 0.66 | 0.76 | 0.62 | |
| MAPE (%) | 25.93 | 22.99 | 22.83 | 18.28 | |
| RMSE | 1.03 | 0.93 | 1.01 | 0.84 | |
| RMSEr (%) | 25.54 | 23.00 | 25.17 | 20.90 | |
| CatBoost | R2 | 0.68 | 0.76 | 0.65 | 0.78 |
| MSE | 1.02 | 0.75 | 1.04 | 0.62 | |
| MAE (m3/ha) | 0.74 | 0.62 | 0.77 | 0.59 | |
| MAPE (%) | 24.70 | 21.03 | 21.63 | 16.20 | |
| RMSE | 1.01 | 0.87 | 1.02 | 0.79 | |
| RMSEr (%) | 25.05 | 21.48 | 25.29 | 19.53 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.; Wu, D.; Fang, L.; Zheng, X. Comparison of Multiple Machine Learning Models for Estimating the Forest Growing Stock in Large-Scale Forests Using Multi-Source Data. Forests 2022, 13, 1471. https://doi.org/10.3390/f13091471
Huang H, Wu D, Fang L, Zheng X. Comparison of Multiple Machine Learning Models for Estimating the Forest Growing Stock in Large-Scale Forests Using Multi-Source Data. Forests. 2022; 13(9):1471. https://doi.org/10.3390/f13091471
Chicago/Turabian StyleHuang, Huajian, Dasheng Wu, Luming Fang, and Xinyu Zheng. 2022. "Comparison of Multiple Machine Learning Models for Estimating the Forest Growing Stock in Large-Scale Forests Using Multi-Source Data" Forests 13, no. 9: 1471. https://doi.org/10.3390/f13091471