
Multistage Sampling and Optimization for Forest Volume Inventory Based on Spatial Autocorrelation Analysis



Abstract
:1. Introduction
2. Research Area and Data Sources
2.1. Research Area
2.2. Data Sources
3. Methods
3.1. Forest Volume Calculation
3.2. Spatial Autocorrelation Analysis
3.2.1. Global Spatial Autocorrelation
3.2.2. Incremental Spatial Autocorrelation
3.2.3. Local Spatial Autocorrelation
3.3. Sampling Design
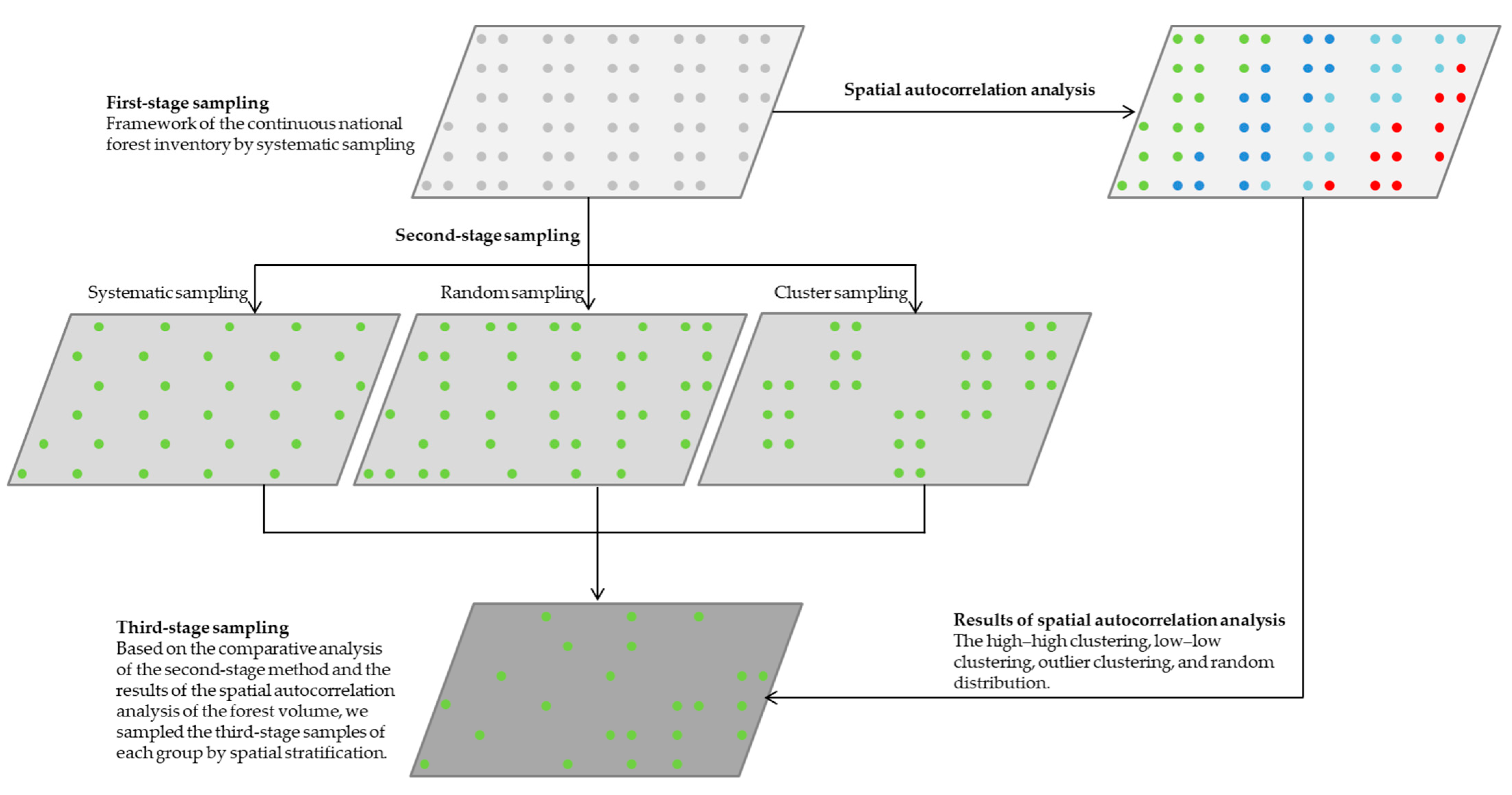
3.3.1. The Multistage Sampling Frame
3.3.2. Second-Stage Sampling Methods
3.3.3. Third-Stage Spatial Sampling
3.4. Method of Estimation
3.5. Sampling Efficiency Analysis
4. Results
4.1. Results of the Spatial Autocorrelation Analysis
4.2. Estimation Results of the Forest Volume
4.2.1. Second-Stage Sampling
- Systematic sampling
- Random sampling
- Cluster sampling
4.2.2. Spatial Stratified Sampling in the Third Stage
4.3. Sampling Efficiency Analysis
4.3.1. Sampling Ratio
4.3.2. Sampling Accuracy
4.3.3. Workload and Costs
5. Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hou, Z.; Domke, G.M.; Russell, M.B.; Coulston, J.W.; Nelson, M.; Xu, Q.; McRoberts, R.E. Updating annual state- and county-level forest inventory estimates with data assimilation and FIA data. For. Ecol. Manag. 2020, 483, 118777. [Google Scholar] [CrossRef]
- Zeng, W.; Xia, R. Discussion on methodology for generating annual estimates in national forest inventory. For. Resour. Manag. 2021, 2, 29–35. [Google Scholar]
- Wu, H.; Xu, H. A review of the application of sampling techniques in forest biomass inventory. J. Southwest For. Univ. (Nat. Sci.) 2021, 41, 183–188. [Google Scholar]
- FIA. Forest Inventory and Analysis National Program. 2019. Available online: https://www.fa.fs.fed.us/tools-data/default.asp (accessed on 30 June 2021).
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program—National Sampling Design and Estimation Procedures; U.S. Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2005; pp. 1–73. [Google Scholar]
- Hetzer, J.; Huth, A.; Wiegand, T.; Dobner, H.J.; Fischer, R. An analysis of forest biomass sampling strategies across scales. Biogeoences 2020, 17, 1673–1683. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, M.J.; Lewis, S.L.; Hubau, W. Field methods for sampling tree height for tropical forest biomass estimation. Methods Ecol. Evol. 2018, 9, 1179–1189. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Feng, Z.; Lu, J.; Liu, J. Estimation of Forest Biomass in Beijing (China) Using Multisource Remote Sensing and Forest Inventory Data. Forests 2020, 11, 163. [Google Scholar] [CrossRef] [Green Version]
- Zhou, C. Some thoughts on China national forest inventory and its annual statistic data. For. Resour. Manag. 2013, 2, 1–5. [Google Scholar]
- McRoberts, R.E. Imputation and model-based updating techniques for annual forest inventories. For. Sci. 2001, 47, 322–330. [Google Scholar]
- Edgar, C.B.; Westfall, J.A.; Klockow, P.A. Interpreting effects of multiple, large-scale disturbances using national forest inventory data: A case study of standing dead trees in east Texas, USA. For. Ecol. Manag. 2019, 437, 27–40. [Google Scholar] [CrossRef]
- Shu, Q.; Tang, S. The status and trend of international forest resources monitoring. World For. Res. 2005, 18, 33–37. [Google Scholar]
- Poudel, K.P.; Temesgen, H.; Gray, A.N. Evaluation of sampling strategies to estimate crown biomass. For. Ecosyst. 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Good, N.M.; Paterson, M.; Mengersen, B.K. Estimating tree component biomass using variable probability sampling methods. J. Agric. Biol. Environ. Stat. 2001, 6, 258–267. [Google Scholar] [CrossRef]
- Ozcelik, R.; Eraslan, T. Two-stage sampling to estimate individual tree biomass. Turk. J. Agric. For. 2011, 36, 389–398. [Google Scholar]
- Rejou, M.M.; Tanguy, A.; Piponiot, C. BIOMASS: An R package for estimating above-ground biomass and its uncertainty in tropical forests. Methods Ecol. Evol. 2017, 8, 1163–1167. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X. A review on muti-purpose forest environment monitoring in Germany, Austria and France. J. Beijing For. Univ. 1997, 3, 80–85. [Google Scholar]
- Liu, H.; Chen, Y.; Ju, H.; Lei, Y. Inspiration of forest resources monitoring in USA for integrated forest resources monitoring system in China. World For. Res. 2012, 25, 64–68. [Google Scholar]
- Bagaram, M.B.; Tóth, S.F. Multistage Sample Average Approximation for Harvest Scheduling under Climate Uncertainty. Forests 2020, 11, 1230. [Google Scholar] [CrossRef]
- Haining, R.P. Spatial Data Analysis: Theory and Practice; Cambridge University: Cambridge, UK, 2003. [Google Scholar]
- Anselin, L. Local indicators of spatial association-LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Trangmar, B.B.; Di, H.J.; Kemp, R.A. Use of Geostatistics in Designing Sampling Strategies for Soil Survey. Soil Sci. 1989, 53, 1163–1167. [Google Scholar]
- Fischer, M.M.; Scholten, H.J.; Unwin, D. Spatial Analytical Perspectives on GIS; Taylor & Francis: London, UK, 1996. [Google Scholar]
- Marcel, R.R.; Henrique, F.S.; Jose, M.M.; Jose, R.S.S.; John, P.M.; Aliny, A.R. Geostatistics Applied to Growth Estimates in Continuous Forest Inventories. For. Sci. 2017, 63, 29–38. [Google Scholar]
- Zhao, J.; Zhao, L.; Chen, E.; Li, Z.; Xu, K.; Ding, X. An Improved Generalized Hierarchical Estimation Framework with Geostatistics for Mapping Forest Parameters and Its Uncertainty: A Case Study of Forest Canopy Height. Remote Sens. 2022, 14, 568. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, J.; Cao, Z. A review of geo-spatial sampling theory. Acta Geogr. Sin. 2009, 64, 368–380. [Google Scholar]
- Fu, W.; Fu, Z.; Ge, H.; Ji, B.; Jiang, P.; Li, Y.; Wu, J.; Zhao, K. Spatial Variation of Biomass Carbon Density in a Subtropical Region of Southeastern China. Forests 2015, 6, 1966–1981. [Google Scholar] [CrossRef] [Green Version]
- Thompson, S.K. Adaptive Cluster Sampling: Designs with Primary and Secondary Units. Biometrics 1991, 47, 1103–1115. [Google Scholar] [CrossRef]
- Gilbert, B.; Lowell, K. Forest attributes and spatial autocorrelation and interpolation: Effects of alternative sampling schemata in the boreal forest. Landsc. Urban Plan. 1997, 37, 235–244. [Google Scholar] [CrossRef]
- Holmberg, H.; Lundevaller, E.H. A test for robust detection of residual spatial autocorrelation with application to mortality rates in Sweden. Spat. Stat. 2015, 14, 365–381. [Google Scholar] [CrossRef]
- Xu, Y.; Li, M.; Hao, S. GIS-based sampling method of urban forest biomass. For. Resour. Manag. 2018, 5, 123–127. [Google Scholar]
- Zhong, G. Impacts of spatial correlation and variability on the spatial sampling efficiency for crop acreage estimation. Master’s Thesis, Chinese Academy of Agricultural Sciences, Beijing, China, 2019. [Google Scholar]
- National Forestry and Grassland Administration. China Forest Resources Report (2014–2018); China Forestry Publishing House: Beijing, China, 2019; pp. 218–221. [Google Scholar]
- Wu, H.; Xu, H. Carbon sequestration rate and dynamic analysis of main arbor forest types in Sichuan Province, China. For. Resour. Manag. 2021, 5, 47–55. [Google Scholar]
- GB/T 38590—2020; Technical Regulations for Continuous Forest Inventory. Chinese National Technical Committee for the Standardization of Forest Resources. Standards Press of China: Beijing, China, 2020.
- Wang, J.; Haining, R.; Cao, Z. Sample Surveying to Estimate the Mean of a Heterogeneous Surface: Reducing the Error Variance Through Zoning. Int. J. Geogr. Inf. Sci. 2010, 24, 523–543. [Google Scholar] [CrossRef]
- Dai, W. Spatial Variation Characteristics of Carbon Density and Storage in Forest Ecosystems in Zhejiang Province. Master’s Thesis, Zhejiang A&F University, Zhejiang, China, 2018. [Google Scholar]
- Shi, J.; Lei, Y.; Zhao, T. Progress in sampling technology and methodology in forest inventory. For. Res. 2009, 22, 101–108. [Google Scholar]
- Luo, X. Theoretical and Applied Research on Related Sampling Techniques of Comprehensive Forest Resources Monitoring. Doctoral Dissertation, Beijing Forestry University, Beijing, China, 2010. [Google Scholar]
- Li, Y.; Chen, Z.; Lei, J.; Chen, X.; Yang, Q.; Wu, T. Study on spatial balance sampling of forest resources survey in Haikou. For. Resour. Manag. 2019, 2, 47–53. [Google Scholar]
- Annika, K.; Matti, M. Forestry Inventory Methodology and Applications; Springer: Dordrecht, The Netherlands, 2006; pp. 248–249. [Google Scholar]
- Poso, S.; Wang, G.; Tuominen, S. Weighted Alternative Estimates when Using Multi-Source Auxiliary Data for Forest Inventory. Silva Fenn. 1999, 33, 41–50. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Pattern | Statistics(m3/ha) | Plot Groupings | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | ||||||||||||
| 2002 | 2007 | 2012 | 2002 | 2007 | 2012 | 2002 | 2007 | 2012 | 2002 | 2007 | 2012 | 2002 | 2007 | 2012 | ||
| High–high | Number | 160 | 158 | 150 | 159 | 154 | 149 | 173 | 178 | 166 | 160 | 155 | 149 | 160 | 163 | 156 |
| Mean | 254.38 | 258.37 | 274.82 | 260.53 | 271.19 | 280.61 | 282.80 | 290.47 | 306.77 | 273.35 | 283.33 | 294.02 | 273.41 | 282.31 | 296.41 | |
| S.D. | 138.53 | 142.22 | 147.31 | 165.97 | 170.26 | 176.72 | 191.74 | 194.35 | 189.78 | 162.77 | 160.67 | 151.71 | 181.18 | 182.09 | 186.63 | |
| CV | 0.54 | 0.55 | 0.54 | 0.64 | 0.63 | 0.63 | 0.68 | 0.67 | 0.62 | 0.60 | 0.57 | 0.52 | 0.66 | 0.64 | 0.63 | |
| Low–low | Number | 175 | 156 | 165 | 176 | 183 | 172 | 172 | 167 | 177 | 156 | 153 | 142 | 159 | 159 | 158 |
| Mean | 5.12 | 6.32 | 7.27 | 5.30 | 6.57 | 7.08 | 5.05 | 6.10 | 6.69 | 5.47 | 7.13 | 7.97 | 5.07 | 5.82 | 7.60 | |
| S.D. | 4.44 | 5.00 | 5.64 | 3.91 | 4.93 | 5.81 | 3.96 | 5.14 | 5.83 | 4.29 | 6.04 | 6.77 | 4.11 | 4.74 | 5.91 | |
| CV | 0.87 | 0.79 | 0.77 | 0.74 | 0.75 | 0.82 | 0.78 | 0.84 | 0.87 | 0.78 | 0.85 | 0.85 | 0.81 | 0.82 | 0.78 | |
| Outlier | Number | 30 | 35 | 41 | 24 | 31 | 34 | 28 | 26 | 35 | 35 | 32 | 29 | 32 | 35 | 38 |
| Mean | 61.65 | 52.50 | 51.37 | 67.72 | 44.94 | 56.42 | 30.07 | 49.02 | 73.02 | 30.97 | 29.76 | 62.78 | 34.41 | 43.04 | 57.56 | |
| S.D. | 191.57 | 75.07 | 59.92 | 154.86 | 67.08 | 76.12 | 47.99 | 57.42 | 77.22 | 59.43 | 56.62 | 69.31 | 60.08 | 66.31 | 80.32 | |
| CV | 3.11 | 1.43 | 1.17 | 2.29 | 1.49 | 1.35 | 1.60 | 1.17 | 1.06 | 1.92 | 1.90 | 1.10 | 1.75 | 1.54 | 1.40 | |
| Random | Number | 377 | 385 | 384 | 374 | 389 | 395 | 398 | 409 | 401 | 321 | 340 | 355 | 397 | 405 | 401 |
| Mean | 54.13 | 58.35 | 66.71 | 53.94 | 62.02 | 68.08 | 52.94 | 57.25 | 67.20 | 54.98 | 62.74 | 68.09 | 47.35 | 53.22 | 58.34 | |
| S.D. | 59.69 | 56.84 | 60.90 | 66.17 | 69.14 | 63.46 | 53.31 | 52.28 | 59.15 | 69.49 | 69.73 | 70.34 | 46.69 | 47.90 | 47.96 | |
| CV | 1.10 | 0.97 | 0.91 | 1.23 | 1.11 | 0.93 | 1.01 | 0.91 | 0.88 | 1.26 | 1.11 | 1.03 | 0.99 | 0.90 | 0.82 | |
| Year | Grouping by Systematic Sampling in the Second Stage a | O-Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | |||||||
| E-Value | p | E-Value | p | E-Value | p | E-Value | p | E-Value | p | ||
| 2007 | 16.53 | 94.09% | 16.54 | 94.09% | 16.25 | 93.98% | 15.94 | 93.88% | 16.14 | 93.54% | 16.16 |
| 2012 | 17.09 | 94.13% | 17.17 | 94.13% | 17.43 | 94.18% | 16.48 | 94.15% | 17.32 | 94.13% | 17.01 |
| 2017 | 18.13 | 94.12% | 18.69 | 94.14% | 19.24 | 94.13% | 19.07 | 94.37% | 19.12 | 94.24% | 18.78 |
| Year | Grouping by Random Sampling in the Second Stage a | O-Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | |||||||
| E-Value | p | E-Value | p | E-Value | p | E-Value | p | E-Value | p | ||
| 2007 | 15.72 | 93.61% | 16.20 | 93.89% | 16.55 | 94.10% | 16.15 | 93.97% | 16.51 | 94.04% | 16.16 |
| 2012 | 17.10 | 94.19% | 17.00 | 94.05% | 17.41 | 94.16% | 17.03 | 94.16% | 16.95 | 94.14% | 17.01 |
| 2017 | 18.97 | 94.42% | 18.79 | 94.10% | 18.88 | 94.01% | 18.84 | 94.28% | 18.69 | 94.19% | 18.78 |
| Year | Grouping by Cluster Sampling in the Second Stage a | O-Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | |||||||
| E-Value | p | E-Value | p | E-Value | p | E-Value | p | E-Value | p | ||
| 2007 | 15.85 | 93.79% | 16.55 | 93.74% | 16.19 | 94.08% | 16.32 | 93.89% | 16.32 | 94.00% | 16.16 |
| 2012 | 16.76 | 94.22% | 17.50 | 94.18% | 16.69 | 93.96% | 17.02 | 94.11% | 17.49 | 94.28% | 17.01 |
| 2017 | 18.80 | 94.33% | 18.15 | 93.83% | 19.10 | 94.15% | 19.06 | 94.28% | 18.89 | 94.46% | 18.78 |
| Year | Grouping by Spatial Stratified Sampling in Third Stage a | O-Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | |||||||
| E-Value | p | E-Value | p | E-Value | p | E-Value | p | E-Value | p | ||
| 2007 | 15.52 | 91.78% | 16.62 | 93.43% | 16.24 | 93.52% | 16.24 | 93.04% | 16.72 | 93.31% | 16.16 |
| 2012 | 17.18 | 93.25% | 16.79 | 92.97% | 16.92 | 92.96% | 17.14 | 93.45% | 17.45 | 93.57% | 17.01 |
| 2017 | 19.28 | 93.54% | 18.30 | 92.33% | 18.40 | 92.65% | 18.83 | 93.35% | 18.35 | 92.57% | 18.78 |
| Stage | Sampling Methods | Evaluation Indicator | |
|---|---|---|---|
| R | RD% | ||
| Second Stage | Systematic sampling | 0.95 | −0.52 |
| Random sampling | 0.98 | −0.39 | |
| Cluster sampling | 0.96 | −0.36 | |
| Third Stage | Spatial stratified sampling | 0.94 | −0.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Xu, H.; Tian, X.; Zhang, W.; Lu, C. Multistage Sampling and Optimization for Forest Volume Inventory Based on Spatial Autocorrelation Analysis. Forests 2023, 14, 250. https://doi.org/10.3390/f14020250
Wu H, Xu H, Tian X, Zhang W, Lu C. Multistage Sampling and Optimization for Forest Volume Inventory Based on Spatial Autocorrelation Analysis. Forests. 2023; 14(2):250. https://doi.org/10.3390/f14020250
Chicago/Turabian StyleWu, Heng, Hui Xu, Xianglin Tian, Wangfei Zhang, and Chi Lu. 2023. "Multistage Sampling and Optimization for Forest Volume Inventory Based on Spatial Autocorrelation Analysis" Forests 14, no. 2: 250. https://doi.org/10.3390/f14020250
APA StyleWu, H., Xu, H., Tian, X., Zhang, W., & Lu, C. (2023). Multistage Sampling and Optimization for Forest Volume Inventory Based on Spatial Autocorrelation Analysis. Forests, 14(2), 250. https://doi.org/10.3390/f14020250