4.1. Landsat-8 Satellite Image Dataset
The evolution of satellite technology with the deep learning approach has led to a higher level of accuracy in forest mapping studies. While the Landsat-9 satellite is equipped with the best sensor specifications in the Landsat series, it is not suitable for time series studies, as it was only launched in September 2021, and lacks temporal data from previous years. In contrast, Landsat-8 is the most suitable satellite for this study, as it has the best radiometric resolution (12 bits) with sufficient temporal data over more than 10 years. The satellite imaging dataset used in this study was saved from Landsat-8 using the Google Earth Pro application. Google Earth Pro is a relatively similar application to Google Earth Engine, but it is better suited for use in this study, primarily because it is free of charge.
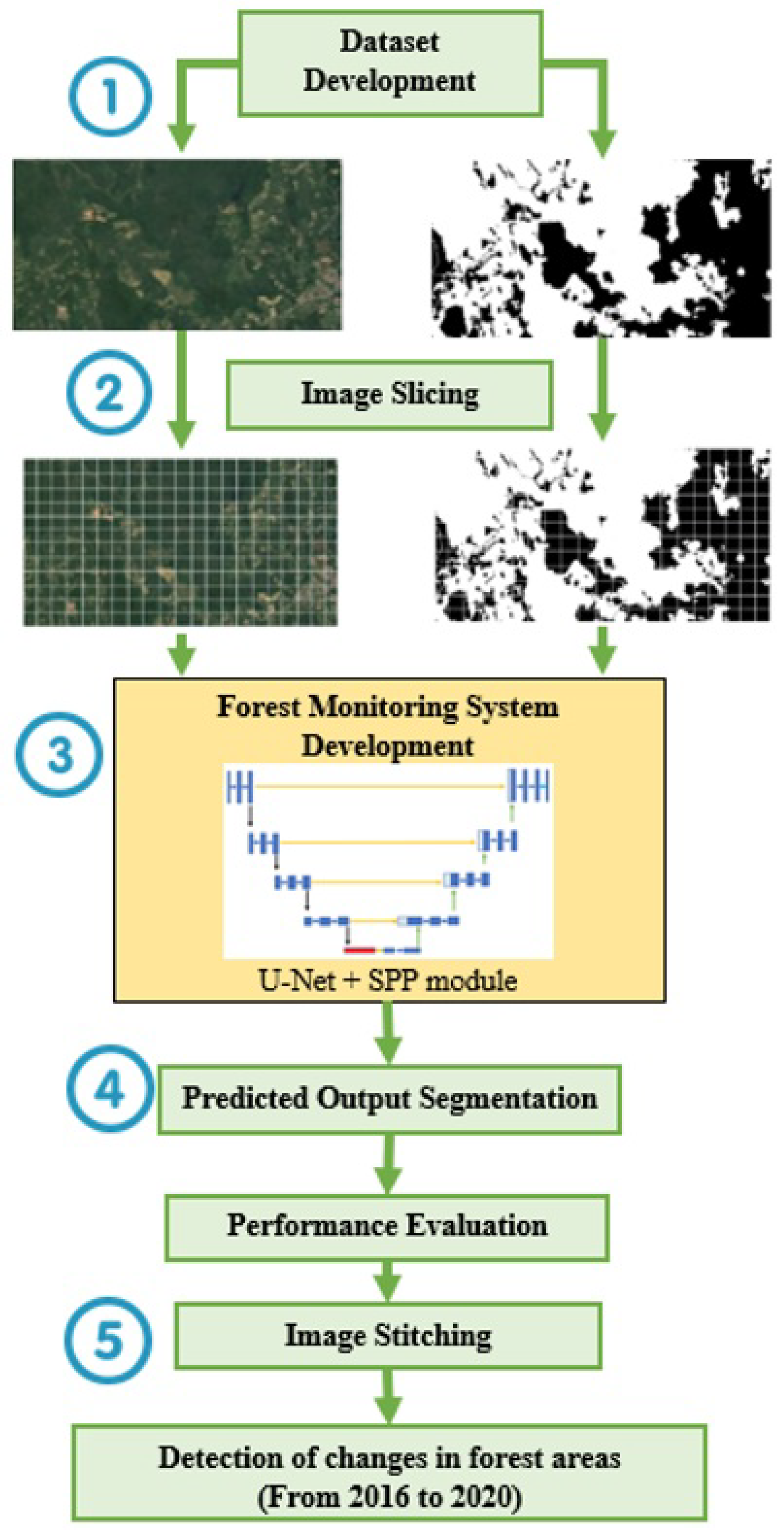
The selection of study locations is the first step in dataset development, and its quality has a direct impact on segmentation accuracy. The forest areas of South-East Asia were the best choice for this research because they offer a clear distinction between forest and non-forest areas. The dataset was extracted from the Landsat-8 satellite, whereby the size for each land parcel is pixels, with a resolution of 1.34 m per pixel. This selection was made so that the satellite images had the widest field of view without any disturbances, such as cloud cover and mosaic-like images that degrade the system’s performance. To track the changes in forest status, this study focused on developing the dataset with time series Landsat-8 satellite images taken from 2016, 2018, and 2020, and sampled at eight different locations throughout the South-East Asia region. Initially, this study focused on changes in forest status for every two years to ensure that small changes could still be clearly detected. If a one-year sampling period is chosen, the changes in the forest status are not too obvious, which is not informative for reporting purposes. Therefore, two years are chosen so that the changes in the forest status are clearly visible to support the intended applications. Please note that Landsat-8 was introduced in 2013, and so the early imaging quality is relatively low as a result of using the Google Earth Pro application. As a result, the sampling process starts from the year 2016 until 2020. For each sampling location, three land parcel samples were extracted, which resulted in a total of 24 Landsat-8 satellite images being extracted and annotated. The acquired satellite images for a particular location must also have the same angle, scale, and resolutions to ensure data consistency.
The ground truth satellite images were manually annotated using the Adobe Photoshop application. Since the performance of the system is heavily dependent on labeled data, the manual annotation of forest and non-forest areas must be performed meticulously and consistently. Thus, forest areas were annotated as the foreground with a white color RGB code of (255, 255, 255), while non-forest areas were annotated as the background with a black color RGB code of (0, 0, 0). Then, the pre-processing phase was completed by slicing the RGB images and their ground truth maps from
pixels to subsets of
pixels, which was the input format for U-Net. The satellite image of a selected land parcel was sliced into 252 images, which resulted in 6048 smaller samples, taken from the original satellite images of 24 land parcels. The dataset was then divided into two subsets of 2268 training data and 756 testing data.
Table 4 summarizes the study locations for both annotated datasets.
To analyze the system’s capability to segment the forest area at different difficulty levels, the satellite images were further divided into two sets of data based on their difficulty level to distinguish the forest and non-forest areas, as shown in
Figure 4. The dataset with a moderate level of difficulty has a clear distinction between forest and non-forest areas, as well as fewer rivers, lakes, and vegetation areas. In contrast, the dataset with a high-difficulty level consists of satellite images with similar features between forest and non-forest areas, and with more rivers, lakes, and vegetation areas.
4.2. Performance Evaluation of the Forest Monitoring System
The performance of the forest segmentation system was measured using three metrics: average accuracy (
), Intersection over Union (
), and F1-Score (
).
is used to validate system performance by calculating the correct prediction for both classes based on the confusion metrics shown in
Table 5.
is a performance metric similar to
, but with advantages for real-world classification, especially when there is an imbalanced class distribution [
38]. Finally,
is the most commonly used metric in evaluating a segmentation model that focuses on the overlapping areas between predicated maps and ground truth maps. It represents the ratio of the area of intersection over the total area of the ground truth and predicted segmentation maps.
The first step in building an optimal base U-Net model using semantic segmentation methodology is finding the optimized set of hyperparameters. A set of experiments was conducted using different sets of hyperparameters to observe their respective training accuracy and loss, as well as to evaluate the segmentation accuracy of the trained model on the test data. The optimal hyperparameter configurations used in this study are listed in
Table 6. The selected optimizer was stochastic gradient descent (SGD). The number of epochs required for training convergence is different for each SPP module variant, and it is also dependent on the difficulty level of the dataset and the spatial relationship between features in the satellite images. Therefore, the optimum number of epochs for a certain model is determined by observing and ensuring that the training accuracy and loss converge at the end of the training process with satisfactory testing accuracy and loss.
Table 7 shows the performance of the proposed forest segmentation system at moderate and high levels of difficulty with and without the SPP module for both datasets. The forest segmentation system developed by the dataset with a moderate level of difficulty has an
,
, and
of 88.23%, 78.80%, and 87.02%, respectively. It can also be seen that the base U-Net performance is improved by all SPP variants, especially for the system embedded with SPP comprising four parallel paths with pooling kernel sizes of
,
,
, and
. This optimal SPP module successfully produces the highest
,
, and
of 90.81%, 83.17%, and 90.72%, respectively, with a performance improvement of 2.92%, 5.55%, and 4.25%, respectively. The optimal SPP module is made up of four pooling layers, which effectively preserves the spatial information of various scales, resulting in more robust segmentation mapping. The forest segmentation system produces the best performance with an SPP module comprising four parallel paths, followed by SPP modules with three and two parallel branches. Meanwhile, the experimental results also show that a combination of smaller pooling kernel sizes is able to detect smaller features in satellite images, hence allowing the more efficacious segmentation of multi-scale forest areas. This is the reason why the system integrated with an SPP module with two parallel branches has the highest performance with pooling kernel sizes of
and
, followed by
and
, and finally
and
. Coincidentally, the patterns are similar for the SPP module with three parallel paths. It is observable that the forest segmentation system would be more sensitive to small changes in forest areas by using a combination of smaller SPP module pooling kernel sizes.
The forest segmentation system developed using a dataset of high-level difficulty on the base U-Net architecture has an , , and of 84.54%, 70.84%, and 76.92%, respectively. It performs worse than the system developed by the dataset with a moderate level of difficulty. In this case, all SPP module variants enhanced the system’s performance, with the exception of the SPP module composed of two parallel paths with pooling kernel sizes of and pixels. This variant only achieved an of 83.90%, which is 0.75% lower than the system developed using the base U-Net model. This is likely caused by the large kernel sizes used in both pooling layers that neglect the smaller features in the feature maps and result in less accurate segmentation maps of forest and non-forest areas and lower the accuracy performance. As the drop in accuracy performance is very small, with observable improvements for the and , this SPP module is still considered the one that can enhance system performance in multi-scale segmentation problems.
Similar to the system developed with a moderate difficulty dataset, the optimal SPP module variant developed for a high-difficulty dataset comprises four parallel paths with pooling kernel sizes of , , , and pixels. The performance of the forest segmentation system optimized by this variant of the SPP module produces the highest , , and of 86.71%, 75.59%, and 82.88%, respectively, with a performance improvement of 2.57%, 6.71%, and 7.75%, respectively. However, the performance of the forest segmentation system with two and three parallel paths is significantly different from the system developed with a moderate difficulty dataset. The SPP module with two parallel paths is better suited to the forest segmentation system for a set of high-difficulty datasets because it produces better performance for , , and compared to the SPP module with three parallel paths.
Further experiments were also conducted to compare the performance of the proposed multi-scale model with the other deep semantic segmentation models. The tests were carried out using a high-difficulty dataset to test the performance limit of the tested models. There are four deep semantic segmentation models that were tested with the optimized individual set up, which are FCN [
39], TernausNet [
40], SegNet [
29], and U-Net [
37].
Table 8 shows the performance comparison between the models. FCN and TernausNet return the worst performance with
,
, and
of 38.39%, 19.19%, and 55.48%, respectively. Interestingly, both of these models use VGG network [
41] as their encoder to extract the respective features of forest and non-forest areas. This encoder design that comprises 13 layers of CNN with ReLU activation function is not suitable for the forest segmentation task. Besides that, both SegNet and U-Net have performed relatively well compared to the FCN and TernausNet. SegNet returns the third best performance values of 84.54%, 70.84%, and 76.92% for
,
, and
, respectively, while U-Net returns the second best performance values of 84.54%, 70.84%, and 76.92% for
,
, and
, respectively. Furthermore, both SegNet and U-Net utilize a symmetric network architecture between their encoder and decoder. However, the best deep semantic segmentation model is the proposed method with the best performance values across all metrics. The proposed method also adopts symmetric design architecture because the SPP module is added at the bottleneck layer.
4.3. Training Performance: Accuracy and Loss
Training
describes how well the system performs in achieving correct segmentation for both forest and non-forest areas on training data, while training loss refers to the segmentation error of the corresponding model, which is also used as a variable to update the weights during the learning process.
Figure 5a illustrates the training accuracy and loss of a forest segmentation system developed using the moderate difficulty dataset without an SPP module. The training process converged after 80 epochs, despite there being several spikes in the loss graph at certain epochs. The spikes in loss values are normal because they are used to update the new weights by the optimizer. Thus, training accuracy drops for every single epoch that experiences a surge of loss and then increases during subsequent learning epochs after the new weights are updated with a high loss value.
The addition of the optimal SPP module to the base U-Net architecture resulted in a higher training loss compared to the system without the SPP module, which converged faster after 50 epochs, as shown in
Figure 5b. The training loss for this model reached 35.2393, which is 34.8725 higher than the base system without the SPP module (0.3368). This is most likely due to the batch normalization layers, which increased the number of untrainable parameters and contributed to an increase in the training loss. This small increment is still tolerable because the batch normalization layer is important in normalizing the input to speed up the training process.
As shown in
Figure 6a,b, using a high-difficulty dataset with and without an SPP module, the training accuracy and loss of the forest monitoring system converge successfully after 70 and 80 epochs, respectively. If we scrutinize the results, the training accuracy for the system without the SPP module increases very slowly after the loss spike at the ninth epoch. This is because the learning rate used for the training process is very small, only 0.0001 to ensure that the learning update can be carried out at an optimal level. Despite the fact that the training loss is higher in the system with SPP due to the batch normalization layers, the training accuracy is still successfully increased by 1.7%. Therefore, the embedded multi-scale module has managed to improve the performance of the forest segmentation algorithm, which is a very important low-level function in a forest monitoring system. The usage of a multi-scale module can be extended to any problem that encounters the issue of varying sizes of input. For example, in eye disease screening applications [
42], the multi-scale capability has further improved the detection rate of the disease by better analyzing affected signals. Besides that, a multi-scale approach has also been implemented for agriculture applications that allow the system to detect leaf diseases of various sizes [
43]. Hence, a multi-scale module can be optimally embedded into a base segmentation network in order to improve the model’s capability to extract features of various scales.
4.4. Qualitative Discussion on the Segmentation Output
The impact of SPP module integration into the base U-Net model was also studied by comparing qualitatively the predicted output images to the ground truth maps.
Figure 7 depicts several samples of raw satellite images, ground truth maps, and predicted output maps produced by the proposed forest segmentation system, with and without the SPP module, tested on a moderate-difficulty dataset. Generally, the base system without the integration of the SPP module has vague and unclear segmentation maps between forest and non-forest areas. This weakness is more obvious along the segmentation lines near the boundaries of both areas, which is the main cause of low segmentation accuracy. On the other hand, the output maps from the system with an optimal SPP module had successfully mitigated this weakness. The maps show more precise segmentation lines along the boundaries of both classes with minimal unwanted interference of white and black dots. In conclusion, the proposed forest segmentation system with an embedded SPP module is found to be more capable of detecting and segmenting forest and non-forest areas of varying scales.
Figure 8 illustrates the predicted segmentation output at locations D and H from 2016 to 2020. The changes in forest status were detected by observing the changes in white and black areas on the maps, which refer to the forest and non-forest areas, respectively.
Figure 8a depicts the segmentation map of the satellite image at location D, taken from 2016, 2018, and 2020. The circled area in the upper right corner of the respective satellite image clearly shows the forest areas have shrunk from 2016 to 2020. In 2016, there were more forest areas than non-forest areas, as shown by the presence of more white pixels compared to black pixels. Later on, this area was exploited in 2018, and the proposed system has successfully recognized the reduction in forest areas as depicted by an increment in black-colored pixels. In 2020, it was detected that this particular area contained a larger proportion of forest areas again, mainly caused by the COVID-19 pandemic that halted deforestation activities.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}