
Regional Forest Structure Evaluation Model Based on Remote Sensing and Field Survey Data


Abstract
1. Introduction
2. Materials and Methods
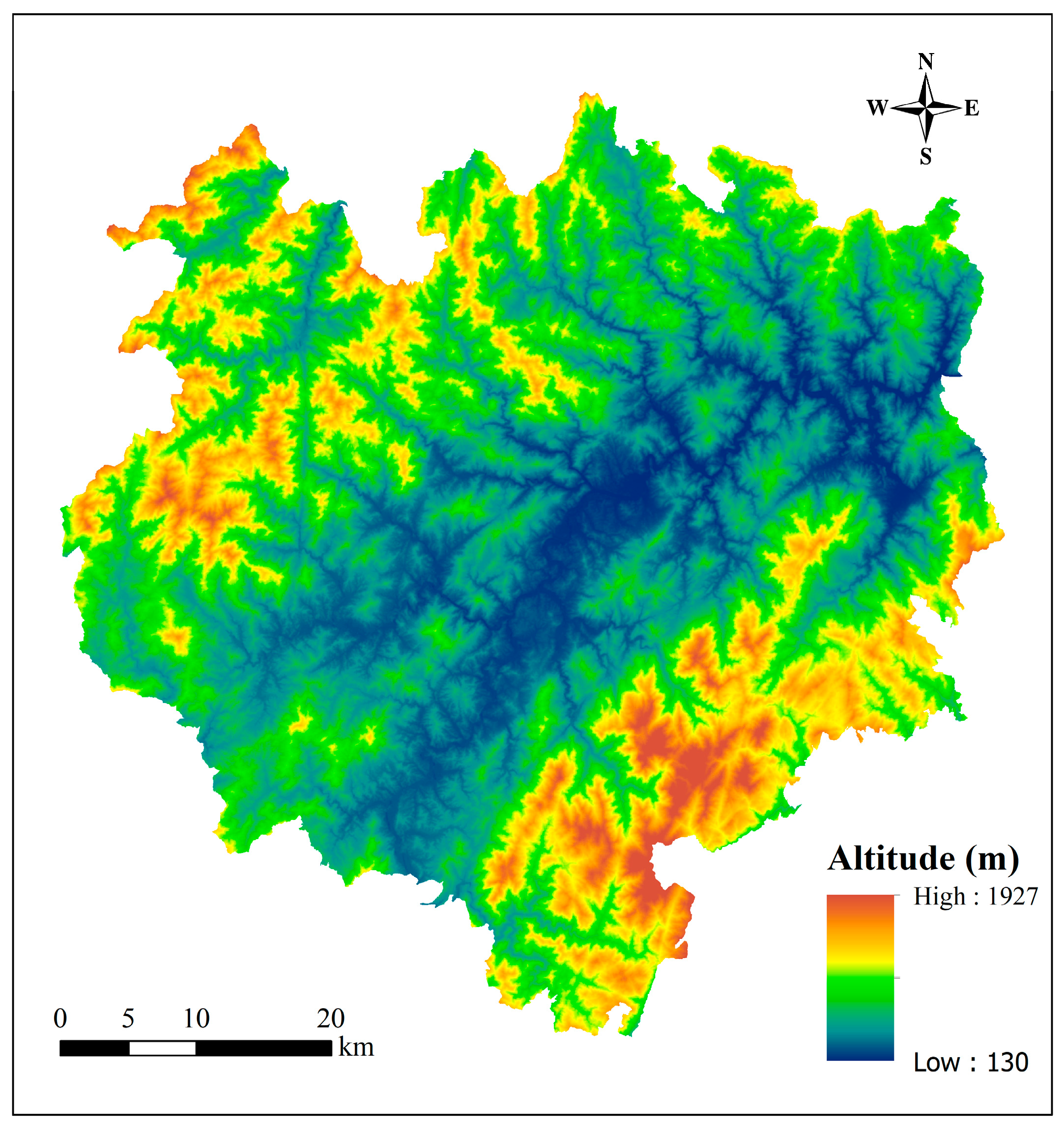
2.1. Overview of the Study Area
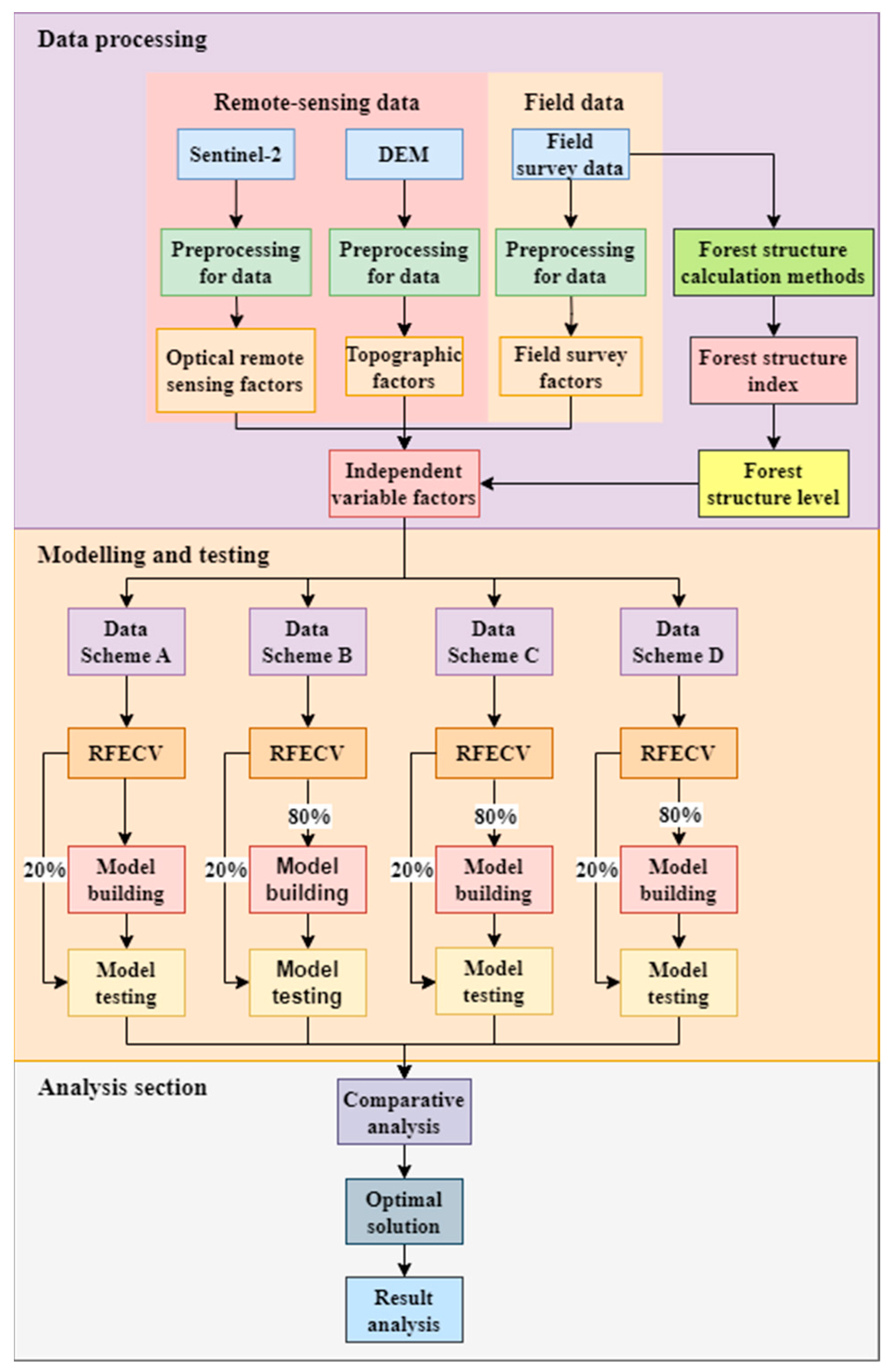
2.2. Research Framework
2.3. Data Sources and Preprocessing
2.3.1. Data Sources
2.3.2. Data Preprocessing
- (1)
- Forest resource planning and design survey data
- (2)
- DEM Image
- (3)
- Sentinel-2 remote sensing images
2.3.3. Labeling of the Data
2.4. Methods
2.4.1. Design of the Data Scheme
2.4.2. Feature Selection Methods
2.4.3. CatBoost
2.4.4. Optimal Hyperparameters
2.5. Performance Metrics
3. Results
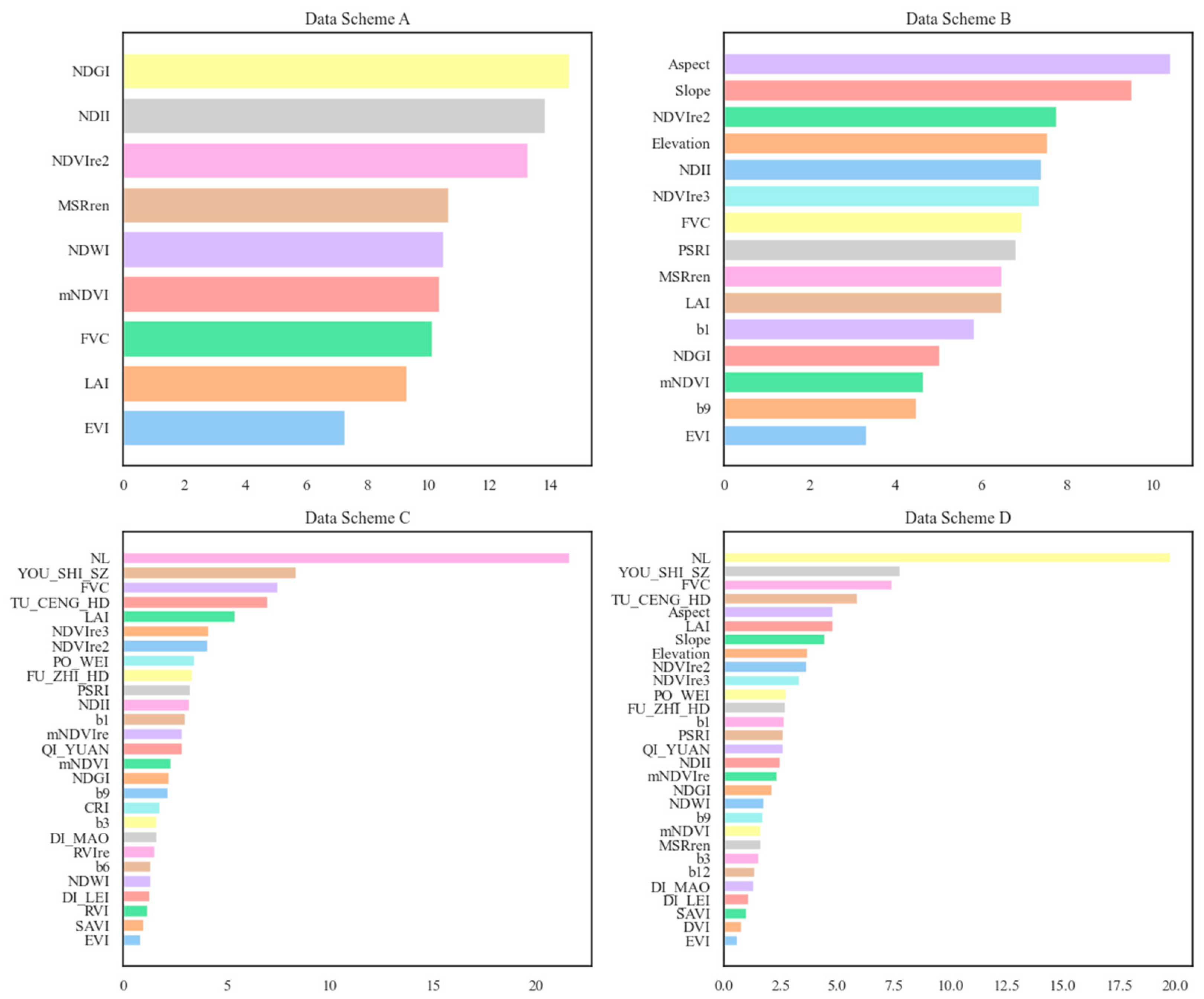
3.1. Feature Selection
3.2. Comparative Analysis of Classification Results
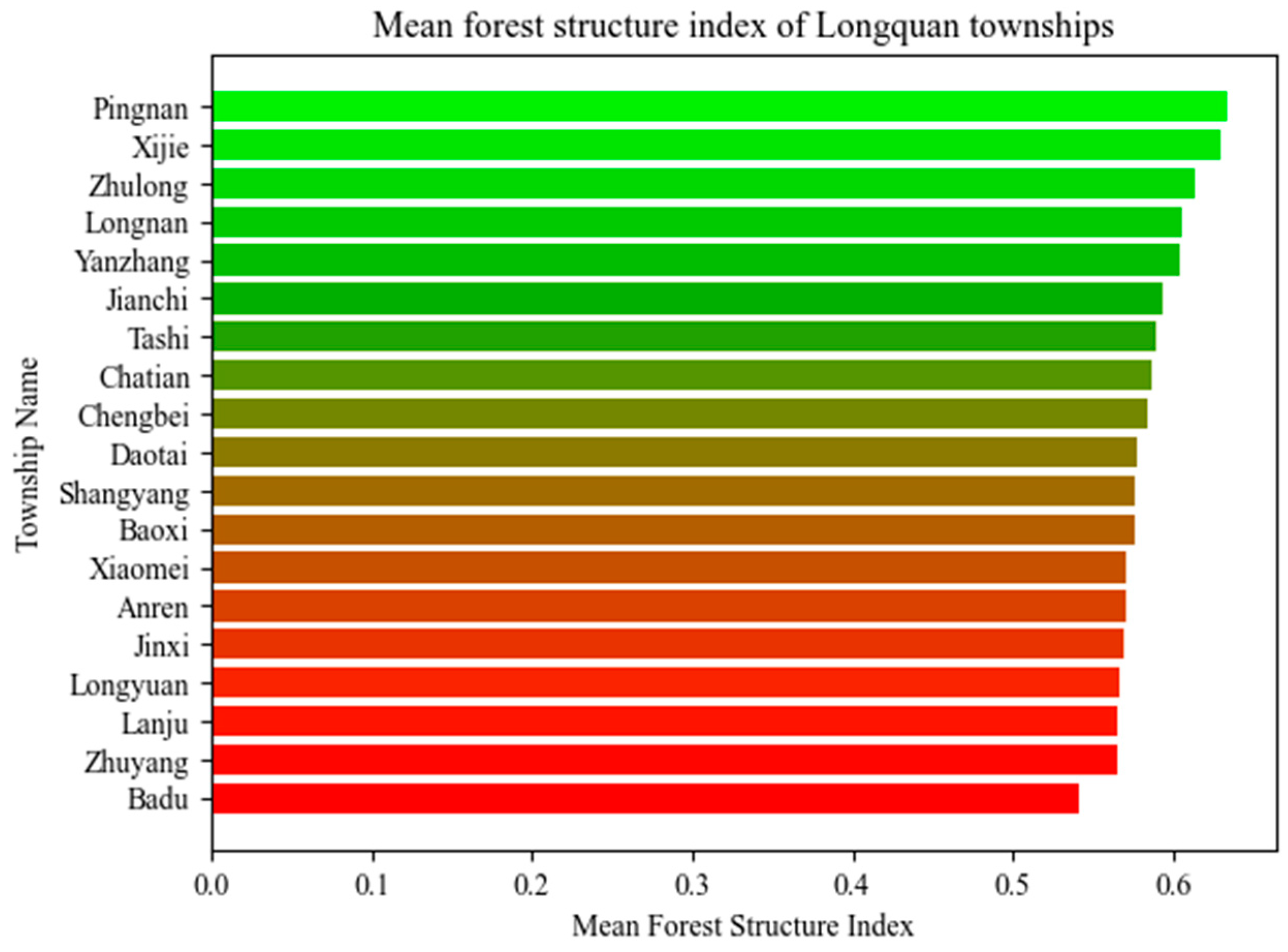
3.3. Results on the Forest Structure Grades in Longquan City
4. Discussion
4.1. Remote Sensing in Forest Structure Evaluation
4.2. Complementarity of Multi-Source Data
4.3. Advantages of CatBoost
4.4. Limitations of This Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mason, B.; Mencuccini, M. Managing Forests for Ecosystem Services—Can Spruce Forests Show the Way? Forestry 2014, 87, 189–191. [Google Scholar] [CrossRef]
- Staudhammer, C.L.; LeMay, V.M. Introduction and Evaluation of Possible Indices of Stand Structural Diversity. Can. J. For. Res. 2001, 31, 1105–1115. [Google Scholar] [CrossRef]
- Franklin, J.F.; Spies, T.A.; Pelt, R.V.; Carey, A.B.; Thornburgh, D.A.; Berg, D.R.; Lindenmayer, D.B.; Harmon, M.E.; Keeton, W.S.; Shaw, D.C.; et al. Disturbances and Structural Development of Natural Forest Ecosystems with Silvicultural Implications, Using Douglas-Fir Forests as an Example. For. Ecol. Manag. 2002, 155, 399–423. [Google Scholar] [CrossRef]
- Scrinzi, G.; Marzullo, L.; Galvagni, D. Development of a Neural Network Model to Update Forest Distribution Data for Managed Alpine Stands. Ecol. Model. 2007, 206, 331–346. [Google Scholar] [CrossRef]
- Liang, X.; Kukko, A.; Hyyppä, J.; Lehtomäki, M.; Pyörälä, J.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Wang, Y. In-Situ Measurements from Mobile Platforms: An Emerging Approach to Address the Old Challenges Associated with Forest Inventories. ISPRS J. Photogramm. Remote Sens. 2018, 143, 97–107. [Google Scholar] [CrossRef]
- GB/T 26424-2010; Technical Regulations for Inventory for Forest Management Planning and Design. Survey, Planning and Design Institute of the State Forestry Administration: Beijing, China, 2011; p. 56.
- Meng, Y.; Cao, B.; Dong, C.; Dong, X. Mount Taishan Forest Ecosystem Health Assessment Based on Forest Inventory Data. Forests 2019, 10, 657. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Y.; Zhang, X.; Li, M.; Liu, C.; Li, W.; Fu, M.; Qin, S.; Fan, Q.; Luo, H.; et al. Comparison of Variable Extraction Methods Using Surface Field Data and Its Key Influencing Factors: A Case Study on Aboveground Biomass of Pinus Densata Forest Using the Original Bands and Vegetation Indices of Landsat 8. Ecol. Indic. 2023, 157, 111307. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree Species Classification with Random Forest Using Very High Spatial Resolution 8-Band WorldView-2 Satellite Data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef]
- Zhu, L.; Zhou, S. Research on automatic estimation method of forest canopy based on spatial data cloud platform and machine learning. For. Constr. 2018, 31–34. [Google Scholar]
- Periasamy, S.; Ravi, K.P. A Novel Approach to Quantify Soil Salinity by Simulating the Dielectric Loss of SAR in Three-Dimensional Density Space. Remote Sens. Environ. 2020, 251, 112059. [Google Scholar] [CrossRef]
- Feng, Q.; Zhou, L.; Chen, E.; Liang, X.; Zhao, L.; Zhou, Y. The Performance of Airborne C-Band PolInSAR Data on Forest Growth Stage Types Classification. Remote Sens. 2017, 9, 955. [Google Scholar] [CrossRef]
- TAN, P.; ZHU, J.; FU, H.; LIN, H. Inversion of Forest Height Based on ALOS-2 PARSAR-2 Multi-Baseline Polarimetric SAR Interferometry Data. J. Radars 2020, 9, 569–577. [Google Scholar]
- Zhang, Y.; Li, M. A New Method for Monitoring Start of Season (SOS) of Forest Based on Multisource Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102556. [Google Scholar] [CrossRef]
- Roffey, M.; Wang, J. Evaluation of Features Derived from High-Resolution Multispectral Imagery and LiDAR Data for Object-Based Support Vector Machine Classification of Tree Species. Can. J. Remote Sens. 2020, 46, 473–488. [Google Scholar] [CrossRef]
- Kumar, P.; Krishna, A.P. InSAR-Based Tree Height Estimation of Hilly Forest Using Multitemporal Radarsat-1 and Sentinel-1 SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5147–5152. [Google Scholar] [CrossRef]
- Ahmed, O.S.; Franklin, S.E.; Wulder, M.A.; White, J.C. Characterizing Stand-Level Forest Canopy Cover and Height Using Landsat Time Series, Samples of Airborne LiDAR, and the Random Forest Algorithm. ISPRS J. Photogramm. Remote Sens. 2015, 101, 89–101. [Google Scholar] [CrossRef]
- Panagiotidis, D.; Abdollahnejad, A.; Slavík, M. 3D Point Cloud Fusion from UAV and TLS to Assess Temperate Managed Forest Structures. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102917. [Google Scholar] [CrossRef]
- Ette, J.S.; Ritter, T.; Vospernik, S. Insights in Forest Structural Diversity Indicators with Machine Learning: What Is Indicated? Biodivers. Conserv. 2023, 32, 1019–1046. [Google Scholar] [CrossRef]
- Fang, N.; Yao, L.; Wu, D.; Zheng, X.; Luo, S. Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning. Forests 2023, 14, 1630. [Google Scholar] [CrossRef]
- Gebauer, A.; Brito Gómez, V.M.; Ließ, M. Optimisation in Machine Learning: An Application to Topsoil Organic Stocks Prediction in a Dry Forest Ecosystem. Geoderma 2019, 354, 113846. [Google Scholar] [CrossRef]
- Huang, X. Research and Development of Feature Dimensionality Reduction. Comput. Sci. 2018, 45, 16-21+53. [Google Scholar]
- Jeon, H.; Oh, S. Hybrid-Recursive Feature Elimination for Efficient Feature Selection. Appl. Sci. 2020, 10, 3211. [Google Scholar] [CrossRef]
- Shen, Z.; Miao, J.; Wang, J.; Zhao, D.; Tang, A.; Zhen, J. Evaluating Feature Selection Methods and Machine Learning Algorithms for Mapping Mangrove Forests Using Optical and Synthetic Aperture Radar Data. Remote Sens. 2023, 15, 5621. [Google Scholar] [CrossRef]
- T/CSF 002-2021; Monitoring Indicator System and Technological Specification of Forest Ecological Quality. Ecology and Nature Conservation Institute, Chinese Academy of Forestry: Beijing, China, 2021; pp. 5–14.
- Raiyani, K.; Gonçalves, T.; Rato, L.; Salgueiro, P.; Marques Da Silva, J.R. Sentinel-2 Image Scene Classification: A Comparison between Sen2Cor and a Machine Learning Approach. Remote Sens. 2021, 13, 300. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS. NASA Spec. Publ. 1973, 351, 309. [Google Scholar]
- Jordan, C.F. Derivation of Leaf-Area Index from Quality of Light on the Forest Floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Hardisky, M.A. The Influence of Soil Salinity, Growth Form, and Leaf Moisture on-the Spectral Radiance of Spartina alterniflora Canopies. Photogramm. Eng. Remote Sens. 1983, 49, 77–83. [Google Scholar]
- Yang, W.; Kobayashi, H.; Wang, C.; Shen, M.; Chen, J.; Matsushita, B.; Tang, Y.; Kim, Y.; Bret-Harte, M.S.; Zona, D.; et al. A Semi-Analytical Snow-Free Vegetation Index for Improving Estimation of Plant Phenology in Tundra and Grassland Ecosystems. Remote Sens. Environ. 2019, 228, 31–44. [Google Scholar] [CrossRef]
- Huete, A.R.; Liu, H.Q.; Batchily, K.; van Leeuwen, W. A Comparison of Vegetation Indices over a Global Set of TM Images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Richardson, A.J.; Wiegand, C.L. Distinguishing Vegetation from Soil Background Information. Photogramm. Eng. Remote Sens. 1977, 43, 1541–1552. [Google Scholar]
- Huete, A.R. A Soil-Adjusted Vegetation Index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Lopez-Alvarez, B.; Urbano-Peña, M.A.; Moran-Ramírez, J.; Ramos-Leal, J.A.; Tuxpan-Vargas, J. Estimation of the Environment Component of the Water Poverty Index via Remote Sensing in Semi-Arid Zones. Hydrol. Sci. J. 2020, 65, 2647–2657. [Google Scholar] [CrossRef]
- Liu, L.; Pang, Y.; Ren, H.; Li, Z. Predict Tree Species Diversity from GF-2 Satellite Data in a Subtropical Forest of China. Sci. Silvae Sin. 2019, 55, 61–74. [Google Scholar]
- Sims, D.; Gamon, J. Relationships Between Leaf Pigment Content and Spectral Reflectance Across a Wide Range of Species, Leaf Structures and Developmental Stages. Remote Sens. Environ. 2002, 81, 337–354. [Google Scholar] [CrossRef]
- Zong, Y.; Li, Y.; Liu, H. A Study of Coastal Wetland Vegetation Classification Based on Object⁃oriented Random Forest Method. J. Nanjing Norm. Univ. (Eng. Technol. Ed.) 2021, 47–55. [Google Scholar]
- Cao, L. Estimation of Forest Stock Volume in Yanqing District Based on Sentinel-2 Images; Beijing Forestry University: Beijing, China, 2019. [Google Scholar]
- Gitelson, A.A.; Merzlyak, M.N. Remote Estimation of Chlorophyll Content in Higher Plant Leaves. Int. J. Remote Sens. 1997, 18, 2691–2697. [Google Scholar] [CrossRef]
- Zhang, X.; Hou, X.; Wang, M.; Wang, L.; Liu, F. Study on Relationship Between Photosynthetic Rate and Hyperspectral Indexes of Wheat Under Stripe Rust Stress. Spectrosc. Spectr. Anal. 2022, 42, 940–946. [Google Scholar]
- Wang, X. Research on Forest Dynamic Change Detection Method Based on Sentinel-2; Huazhong Agricultural University: Wuhan, China, 2020. [Google Scholar]
- De Luca, G.; MN Silva, J.; Di Fazio, S.; Modica, G. Integrated Use of Sentinel-1 and Sentinel-2 Data and Open-Source Machine Learning Algorithms for Land Cover Mapping in a Mediterranean Region. Eur. J. Remote Sens. 2022, 55, 52–70. [Google Scholar] [CrossRef]
- Wang, B.; Wang, W.; Zhou, C.; Fang, Y.; Zheng, Y. Feature Selection and Classification of Heart Sound Based on EMD Adaptive Reconstruction. Space Med. Med. Eng. 2020, 33, 533–541. [Google Scholar] [CrossRef]
- Lu, P.; Zhuo, Z.; Zhang, W.; Tang, J.; Wang, Y.; Zhou, H.; Huang, X.; Sun, T.; Lu, J. A Hybrid Feature Selection Combining Wavelet Transform for Quantitative Analysis of Heat Value of Coal Using Laser-Induced Breakdown Spectroscopy. Appl. Phys. B 2021, 127, 19. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Z.; Zheng, J. CatBoost: A New Approach for Estimating Daily Reference Crop Evapotranspiration in Arid and Semi-Arid Regions of Northern China. J. Hydrol. 2020, 588, 125087. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost Method for Prediction of Reference Evapotranspiration in Humid Regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Jiang, Q.; Yang, X.; Yang, C.; Zhao, Z. Object-Oriented Land Use Classification Based on CatBoost Algorithm. J. Jilin Univ. (Inf. Sci. Ed.) 2020, 38, 185–191. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. Adv. Neural Inf. Process. Syst. 2019, 31, 1–11. [Google Scholar]
- Hussain, S.; Raza, A.; Abdo, H.G.; Mubeen, M.; Tariq, A.; Nasim, W.; Majeed, M.; Almohamad, H.; Al Dughairi, A.A. Relation of Land Surface Temperature with Different Vegetation Indices Using Multi-Temporal Remote Sensing Data in Sahiwal Region, Pakistan. Geosci. Lett. 2023, 10, 33. [Google Scholar] [CrossRef]
- Xu, J.; Tang, Y.; Xu, J.; Chen, J.; Bai, K.; Shu, S.; Yu, B.; Wu, J.; Huang, Y. Evaluation of Vegetation Indexes and Green-Up Date Extraction Methods on the Tibetan Plateau. Remote Sens. 2022, 14, 3160. [Google Scholar] [CrossRef]
- Bagheri, N. Application of Aerial Remote Sensing Technology for Detection of Fire Blight Infected Pear Trees. Comput. Electron. Agric. 2020, 168, 105147. [Google Scholar] [CrossRef]
- Pérez-Romero, J.; Navarro-Cerrillo, R.M.; Palacios-Rodriguez, G.; Acosta, C.; Mesas-Carrascosa, F.J. Improvement of Remote Sensing-Based Assessment of Defoliation of Pinus Spp. Caused by Thaumetopoea Pityocampa Denis and Schiffermüller and Related Environmental Drivers in Southeastern Spain. Remote Sens. 2019, 11, 1736. [Google Scholar] [CrossRef]
- Lin, H.; Liu, X.; Han, Z.; Cui, H.; Dian, Y. Identification of Tree Species in Forest Communities at Different Altitudes Based on Multi-Source Aerial Remote Sensing Data. Appl. Sci. 2023, 13, 4911. [Google Scholar] [CrossRef]
- Spracklen, B.; Spracklen, D.V. Synergistic Use of Sentinel-1 and Sentinel-2 to Map Natural Forest and Acacia Plantation and Stand Ages in North-Central Vietnam. Remote Sens. 2021, 13, 185. [Google Scholar] [CrossRef]
- Fang, G.; Xu, H.; Yang, S.-I.; Lou, X.; Fang, L. Synergistic Use of Sentinel-1, Sentinel-2, and Landsat 8 in Predicting Forest Variables. Ecol. Indic. 2023, 151, 110296. [Google Scholar] [CrossRef]
- Ahmadi, K.; Kalantar, B.; Saeidi, V.; Harandi, E.K.G.; Janizadeh, S.; Ueda, N. Comparison of Machine Learning Methods for Mapping the Stand Characteristics of Temperate Forests Using Multi-Spectral Sentinel-2 Data. Remote Sens. 2020, 12, 3019. [Google Scholar] [CrossRef]
- He, W.; Zhu, J.; Lopez-Sanchez, J.M.; Gómez, C.; Fu, H.; Xie, Q. Forest Height Inversion by Combining Single-Baseline TanDEM-X InSAR Data with External DTM Data. Remote Sens. 2023, 15, 5517. [Google Scholar] [CrossRef]
- Xia, Y.; Pang, Y.; Liu, L.; Chen, B.; Dong, B.; Huang, Q. Forest Height Growth Monitoring of Cunninghamia lanceolata Plantation Using Multi-Temporal Aerial Photography with the Support of High Accuracy DEM. Sci. Silvae Sin. 2019, 55, 108–121. [Google Scholar]
- Shen, J.; Lei, X.; Li, Y.; Lan, Y. Prediction mean height for Larix olgensis plantation based on Bayesian-regularization BP neural network. J. Nanjing For. Univ. 2018, 42, 147–154. [Google Scholar]
- Rajarajan, K.; Verma, S.; Sahu, S.; Radhakrishna, A.; Kumar, N.; Priyadarshini, E.; Handa, A.; Arunachalam, A. Differential Gene Expression Analysis Reveals the Fast-Growth Mechanisms in Melia Dubia at Different Stand Ages. Mol. Biol. Rep. 2023, 50, 10671–10675. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for Big Data: An Interdisciplinary Review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef] [PubMed]
- Cao, L.; He, X.; Chen, S.; Fang, L. Assessing Forest Quality through Forest Growth Potential, an Index Based on Improved CatBoost Machine Learning. Sustainability 2023, 15, 8888. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, J.; Liang, S.; Li, X.; Li, M. An Evaluation of Eight Machine Learning Regression Algorithms for Forest Aboveground Biomass Estimation from Multiple Satellite Data Products. Remote Sens. 2020, 12, 4015. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | Division Standard |
|---|---|
| Excellent (4) | Prominent dominant tree species, multiple associated tree species |
| Good (3) | Dominant tree species, few associated tree species |
| Fair (2) | One dominant tree species, one associated tree species |
| Poor (1) | No dominant tree species or single species |
| Grade | Division Standard |
|---|---|
| Excellent (4) | Has a complete structure, with a tree layer, shrub layer, herbaceous layer, and ground cover layer, etc. |
| Good (3) | Has a relatively complete structure, with a tree layer and another two lower vegetation layers |
| Fair (2) | Has a structure with a tree layer and one other lower vegetation layer |
| Poor (1) | Simple structure with only one tree layer |
| Grade | Height (cm) | ||
|---|---|---|---|
| ≤30 | 30~49 | ≥50 | |
| Excellent (4) | ≥5000 | ≥3000 | ≥2500 |
| Good (3) | 4000~4999 | 2000~2999 | 1500~2499 |
| Fair (2) | 3000~3999 | 1000~1999 | 500~1499 |
| Poor (1) | <3000 | <1000 | <500 |
| Category | Assignment Criteria and Grades | |||
|---|---|---|---|---|
| Excellent (4) | Good (3) | Fair (2) | Poor (1) | |
| Tree species composition | Criteria and Ranking of Evaluation Indicators for Tree Species Composition (Table 1) | |||
| Tree age group structure | Mature forest | Near-mature forest | Middle-aged forest | Overmature forest or immature forest |
| Forest layer and community structure | Evaluation indicators, value standards, and levels for forest layer and community structure (Table 2) | |||
| Mean diameter at breast height (cm) | ≥29.0 | 17.0~28.9 | 5.0~16.9 | <5.0 |
| Mean tree height (cm) | ≥16.0 | 10.0~15.9 | 4.0~9.9 | <4.0 |
| Diameter class distribution (cm) | ≥38 | 26~36 | 14~24 | 6~12 |
| Fractional vegetation cover | ≥70% | 40%~69% | 20%~39% | <20% |
| Leaf area index | ≥5.0 | 3.0~5.0 | 2.0~2.9 | <2.0 |
| Canopy density | ≥0.7 | 0.5~0.69 | 0.3~0.49 | 0.2~0.29 |
| Natural regeneration level | Evaluation criteria and levels for natural regeneration (Table 3) | |||
| No. | Indicator Name | Explanation |
|---|---|---|
| 1 | DI_LEI | Land type |
| 2 | DI_MAO | Landforms |
| 3 | PO_WEI | Slope position |
| 4 | TU_RANG_MC | Soil type |
| 5 | TU_RANG_ZD | Soil texture |
| 6 | TU_CENG_HD | Soil depth |
| 7 | FU_ZHI_HD | Humus layer thickness |
| 8 | LIN_ZHONG | Tree species |
| 9 | QI_YUAN | Origin |
| 10 | YOU_SHI_SZ | Dominant tree species |
| 11 | NL | Average tree age |
| Band | Name | Wavelength (nm) | Resolution (m) |
|---|---|---|---|
| B1 | Aerosol | 442.7 | 60 |
| B2 | Blue | 492.4 | 10 |
| B3 | Green | 559.8 | 10 |
| B4 | Red | 664.5 | 10 |
| B5 | Red Edge 1 | 704.1 | 20 |
| B6 | Red Edge 2 | 740.5 | 20 |
| B7 | Red Edge 3 | 782.8 | 20 |
| B8 | NIR | 832.8 | 10 |
| B8a | Narrow NIR | 864.7 | 20 |
| B9 | Water vapor | 945.1 | 60 |
| B11 | SWIR 1 | 1613.7 | 20 |
| B12 | SWIR 2 | 2202.4 | 20 |
| No. | Vegetation Index | Formula | References |
|---|---|---|---|
| 1 | Normalized Difference Vegetation Index (NDVI) | [27] | |
| 2 | Ratio Vegetation Index (RVI) | [28] | |
| 3 | Normalized Difference Infrared Index (NDII) | [29] | |
| 4 | Normalized Difference Green Index (NDGI) | [30] | |
| 5 | Enhanced Vegetation Index (EVI) | [31] | |
| 6 | Difference Vegetation Index (DVI) | [32] | |
| 7 | Soil-Adjusted Vegetation Index (SAVI) | [33] | |
| 8 | Chlorophyll Index (CI green) | [34] | |
| 9 | Carotenoid Reflectance Index (CRI) | [35] | |
| 10 | Modified Normalized Difference Vegetation Index (mNDVI) | [36] |
| No. | Red-Edge Vegetation Index | Formula | References |
|---|---|---|---|
| 1 | Modified Red-Edge Normalized Difference Vegetation Index (mNDVIre) | [36] | |
| 2 | Normalized Difference Water Index (NDWI) | [37] | |
| 3 | Red-Edge Ratio Vegetation Index (RVIre) | [38] | |
| 4 | Red Edge 1 Normalized Difference Index (NDVIre1) | [39] | |
| 5 | Red Edge 2 Normalized Difference Index (NDVIre2) | [39] | |
| 6 | Red Edge 3 Normalized Difference Vegetation Index (NDVIre3) | [39] | |
| 7 | Plant Senescence Reflectance Index (PSRI) | [40] | |
| 8 | Modified Simple Ratio Red Edge 2 Vegetation Index (MSRren) | [41] | |
| 9 | Red Edge 1 Normalized Difference Index (NDre1) | [41] | |
| 10 | Red Edge 2 Normalized Difference Index (NDre2) | [41] |
| Evaluation Indicator | Original Weight | Normalized Weight |
|---|---|---|
| Tree species composition | 0.0412 | 0.1282 |
| Tree age group structure | 0.0363 | 0.1129 |
| Stand and community structure | 0.0331 | 0.1030 |
| Mean diameter at breast height | 0.0122 | 0.0380 |
| Mean tree height | 0.0094 | 0.0292 |
| Diameter class distribution | 0.0205 | 0.0638 |
| Natural regeneration level | 0.0285 | 0.0886 |
| Fractional vegetation cover | 0.0555 | 0.1726 |
| Leaf area index | 0.0373 | 0.1160 |
| Canopy density | 0.0475 | 0.1477 |
| Code | Forest Structure Level | Forest Structure Index |
|---|---|---|
| 1 | Good | [0.75, 1] |
| 2 | Moderate | [0.5, 0.75) |
| 3 | Poor | [0.25, 0.5) |
| Data Combination Scheme | Data Source |
|---|---|
| A | Sentinel-2 |
| B | Sentinel-2, DEMs |
| C | Sentinel-2, forest resource planning and design survey data |
| D | Sentinel-2, DEMs, forest resource planning and design survey data |
| Model | Optimal Hyperparameters |
|---|---|
| KNN | n_neighbors = 6, weights = ‘distance’, algorithm = ‘brute’ |
| SVM | C = 4.4226, gamma = 0.0867 |
| RF | n_estimators = 696, min_samples_split = 4 |
| CatBoost | n_estimators = 676, learning_rate = 0.1195, depth = 10 |
| Factors | A | B | C | D | Factors | A | B | C | D |
|---|---|---|---|---|---|---|---|---|---|
| b1 | √ | √ | √ | NDII | √ | √ | √ | √ | |
| b3 | √ | √ | mNDVI | √ | √ | √ | √ | ||
| b6 | √ | RVIre | √ | ||||||
| b9 | √ | √ | √ | LAI | √ | √ | √ | √ | |
| b12 | √ | FVC | √ | √ | √ | √ | |||
| CRI | √ | Elevation | - | √ | - | √ | |||
| MSRren | √ | √ | √ | Aspect | - | √ | - | √ | |
| PSRI | √ | √ | √ | Slope | - | √ | - | √ | |
| NDVIre2 | √ | √ | √ | √ | DI_LEI | - | - | √ | √ |
| NDVIre3 | √ | √ | √ | DI_MAO | - | - | √ | √ | |
| RVI | √ | PO_WEI | - | - | √ | √ | |||
| NDWI | √ | √ | √ | TU_CENG_HD | - | - | √ | √ | |
| mNDVIre | √ | √ | FU_ZHI_HD | - | - | √ | √ | ||
| SAVI | √ | √ | QI_YUAN | - | - | √ | √ | ||
| DVI | √ | YOU_SHI_SZ | - | - | √ | √ | |||
| EVI | √ | √ | √ | √ | NL | - | - | √ | √ |
| NDGI | √ | √ | √ | √ |
| Program | Overall Accuracy Rate | Category Accuracy Rate | Recall | Kappa | ||
|---|---|---|---|---|---|---|
| Good | Moderate | Poor | ||||
| KNN-A | 75.33% | 50.43% | 79.36% | 47.99% | 48.27% | 0.2538 |
| KNN-B | 75.23% | 48.99% | 79.78% | 49.17% | 49.69% | 0.2701 |
| KNN-C | 82.24% | 67.08% | 85.39% | 69.96% | 65.14% | 0.5108 |
| KNN-D | 81.87% | 65.85% | 84.91% | 70.57% | 63.86% | 0.4954 |
| SVM-A | 76.41% | 66.01% | 76.85% | 63.11% | 38.96% | 0.1208 |
| SVM-B | 77.26% | 69.06% | 77.90% | 64.17% | 42.61% | 0.1918 |
| SVM-C | 84.54% | 74.82% | 86.86% | 74.12% | 69.00% | 0.5751 |
| SVM-D | 84.48% | 75.62% | 86.90% | 72.81% | 69.09% | 0.5749 |
| RF-A | 77.58% | 66.20% | 79.26% | 56.01% | 47.42% | 0.2664 |
| RF-B | 77.81% | 67.78% | 79.22% | 58.23% | 47.19% | 0.2659 |
| RF-C | 86.20% | 76.48% | 87.84% | 81.34% | 71.52% | 0.6203 |
| RF-D | 86.33% | 77.79% | 87.72% | 82.08% | 71.24% | 0.6209 |
| CatBoost-A | 77.41% | 62.10% | 79.91% | 54.55% | 49.71% | 0.2936 |
| CatBoost-B | 77.51% | 60.47% | 79.96% | 57.23% | 49.79% | 0.2959 |
| CatBoost-C | 87.75% | 77.52% | 89.91% | 81.53% | 76.52% | 0.6756 |
| CatBoost-D | 88.07% | 78.19% | 90.04% | 82.82% | 76.86% | 0.6833 |
| Level | Longquan City | |
|---|---|---|
| Sub-Compartment Quantity | Percentage | |
| Good | 6273 | 11.18% |
| Moderate | 43,070 | 76.77% |
| Poor | 6757 | 12.05% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Wen, Q.; Wu, D.; Huang, H.; Zheng, X. Regional Forest Structure Evaluation Model Based on Remote Sensing and Field Survey Data. Forests 2024, 15, 533. https://doi.org/10.3390/f15030533
Lin S, Wen Q, Wu D, Huang H, Zheng X. Regional Forest Structure Evaluation Model Based on Remote Sensing and Field Survey Data. Forests. 2024; 15(3):533. https://doi.org/10.3390/f15030533
Chicago/Turabian StyleLin, Shangqin, Qingqing Wen, Dasheng Wu, Huajian Huang, and Xinyu Zheng. 2024. "Regional Forest Structure Evaluation Model Based on Remote Sensing and Field Survey Data" Forests 15, no. 3: 533. https://doi.org/10.3390/f15030533
APA StyleLin, S., Wen, Q., Wu, D., Huang, H., & Zheng, X. (2024). Regional Forest Structure Evaluation Model Based on Remote Sensing and Field Survey Data. Forests, 15(3), 533. https://doi.org/10.3390/f15030533