
Forest Fire Smoke Detection Based on Multiple Color Spaces Deep Feature Fusion


Abstract
1. Introduction
- (1)
- Compared with the smoke data selected or captured by humans in previous studies, this research utilizes a dataset of forest fire smoke derived from real-time forest fire monitoring cameras. This dataset encompasses a variety of real-world scenarios, providing a more impartial assessment of forest fire smoke detection models.
- (2)
- Our study introduces SUFN, a semantic segmentation model explicitly designed for forest fire smoke detection. SUFN builds upon the U-Net foundation and innovatively integrates features from multiple color spaces using three specialized fusion modules: multi-scale feature encoding, deep feature fusion, and multi-scale shallow feature fusion.
- (3)
- We present a novel local fusion strategy employing element-wise self-adaptive weighted addition, with an adaptive fusion weight policy devised for different local contexts and dependencies within the model. It enables the extraction of comprehensive, complementary smoke features from the diverse color spaces, significantly enhancing the model’s detection performance.
2. Materials and Methods
2.1. Dataset and Prepocessing
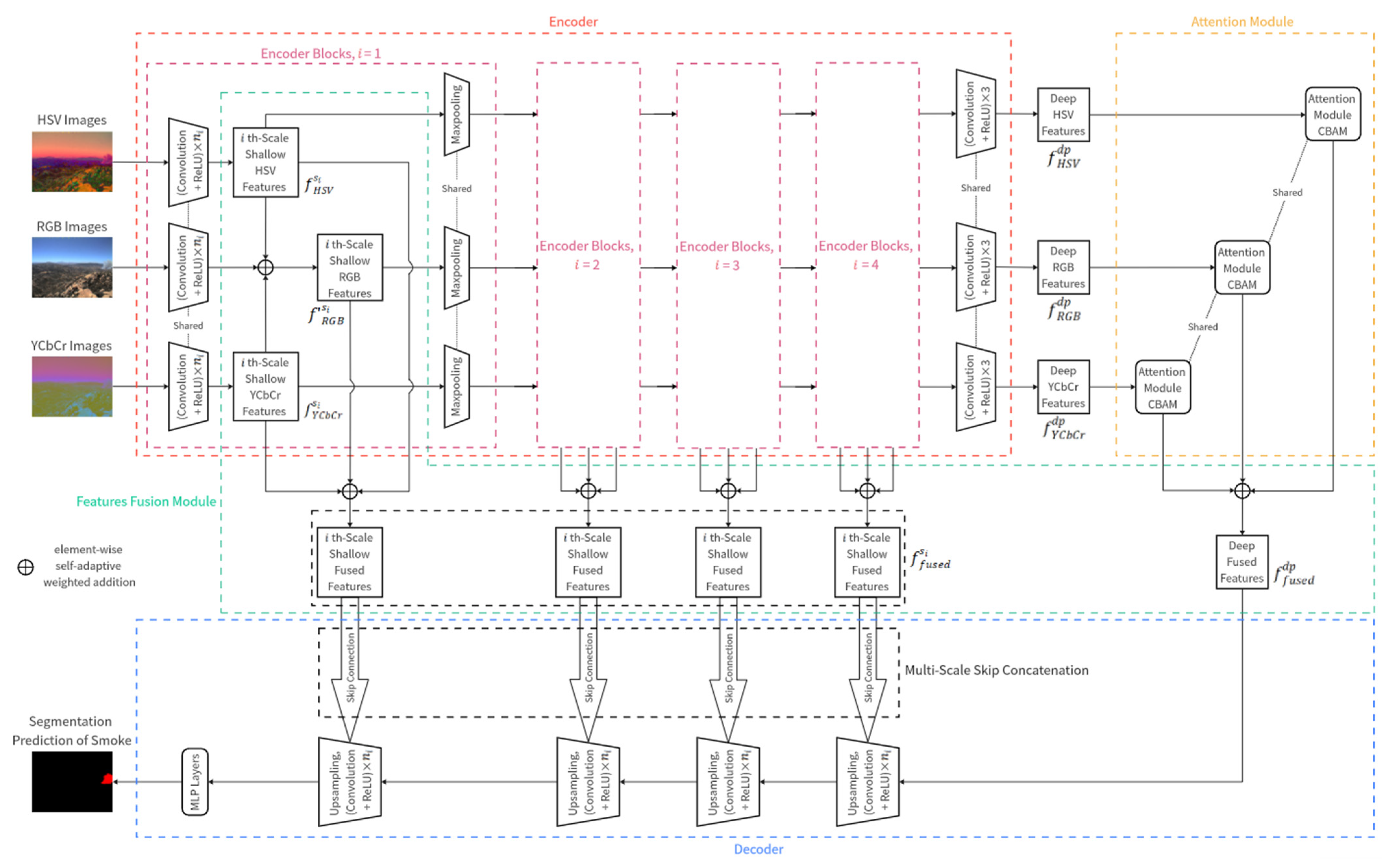
2.2. Model Architecture
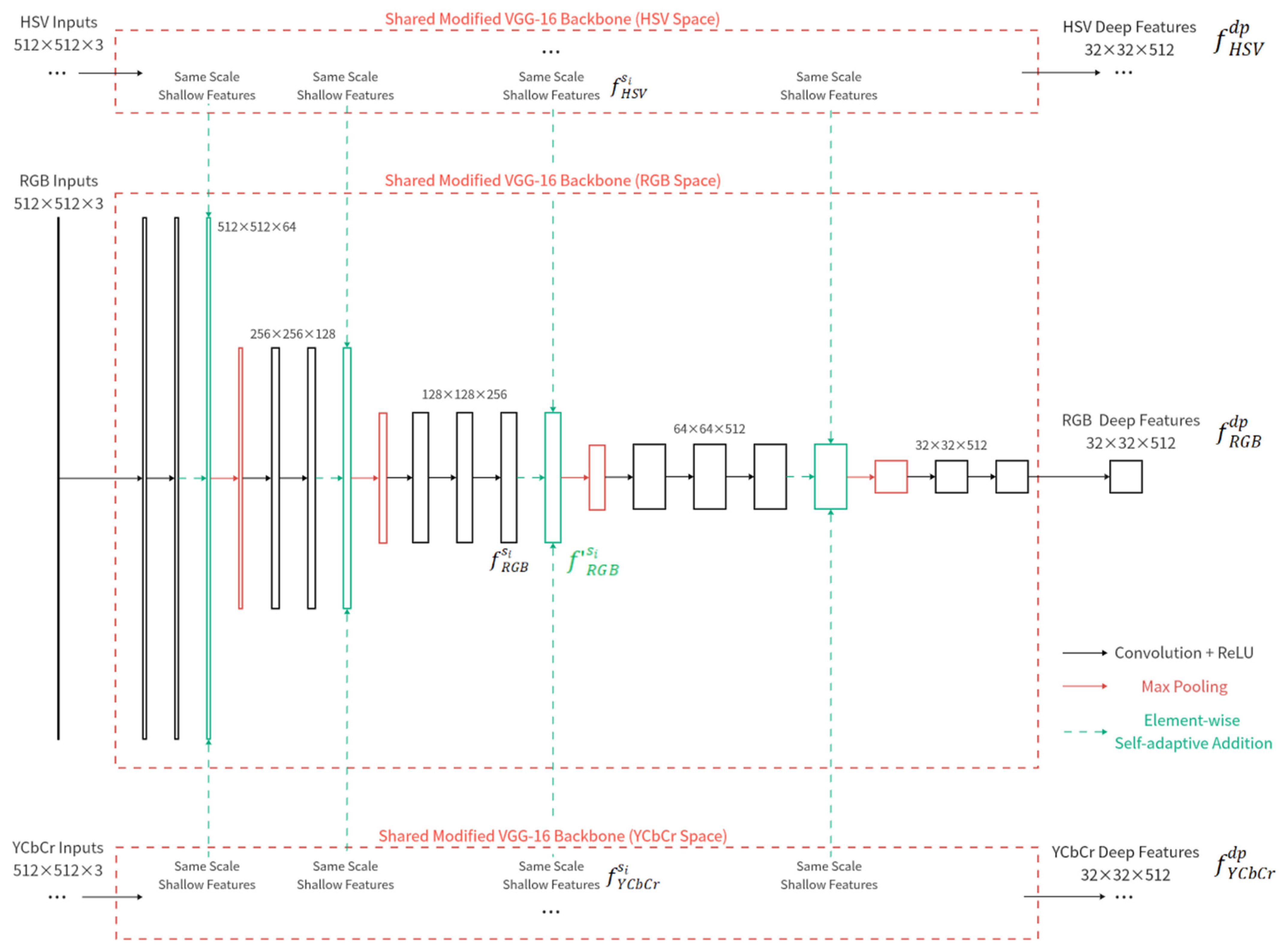
2.2.1. Encoder Module
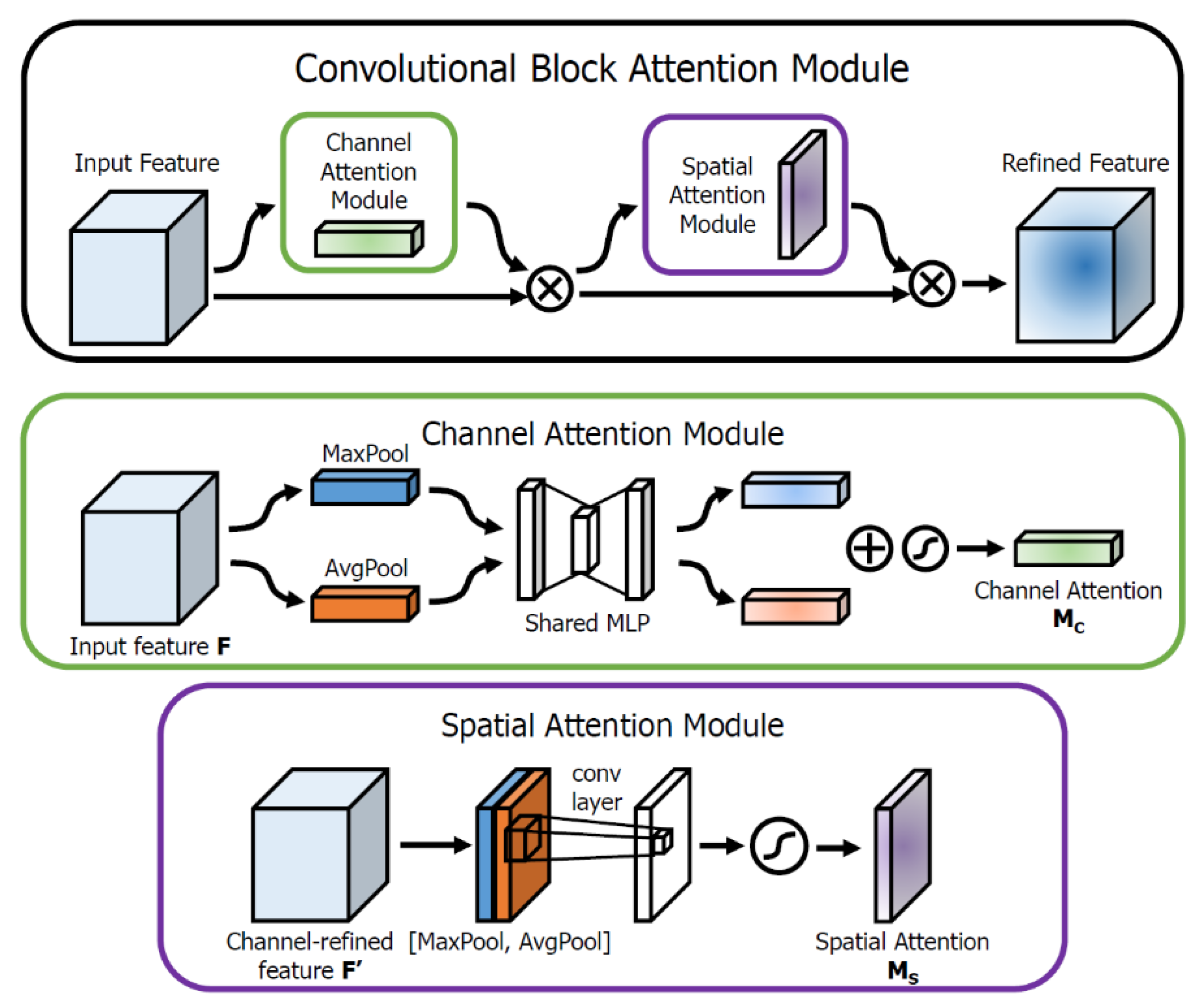
2.2.2. Attention Module
2.2.3. Feature Fusion Module
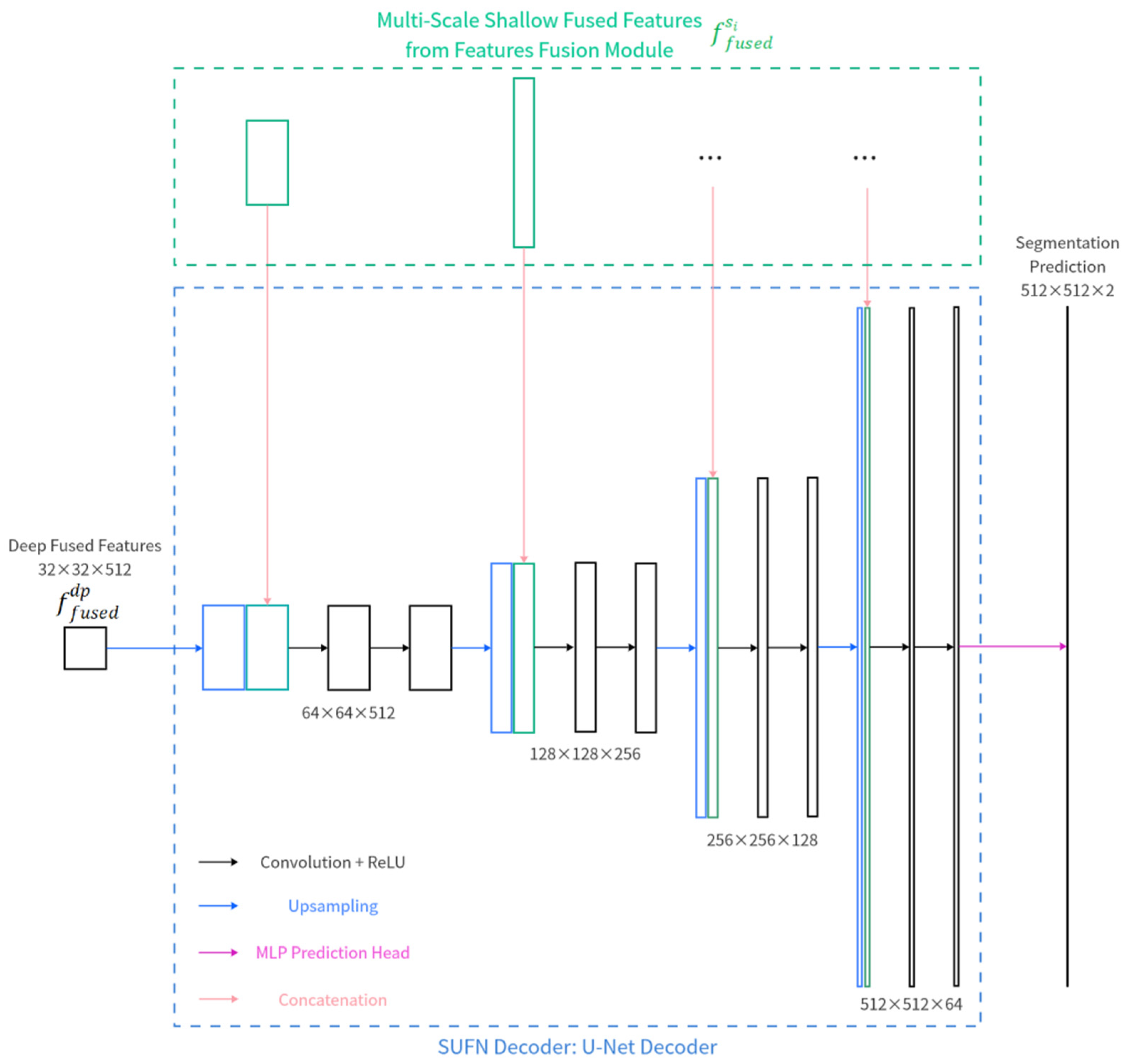
2.2.4. Decoder Module
| Algorithm 1 The Pseudo-Code of the Proposed SUFN Method |
| Input: original RGB images xRGB, smoke GT images |
| Output: The smoke segmentation prediction y |
| Initialized: the pretrained VGG16 backbone on VOC-2007 dataset θec, and the pretrained U-Net decoder θdc |
| for i in 1, 2,…, Nepoch do |
| for j in 1, 2,…, Nbatch do |
| xHSV, xYCbCr ← ColorTransformRGB→HSV (xRGB), ColorTransformRGB→YCbCr (xRGB) |
| for k in 1, 2, 3, 4 Blockec do |
| if k = 1 do |
| , , ← (xRGB), (xHSV), (xYCbCr) |
| else do |
| , , ← (Maxpool()), (Maxpool()), (Maxpool()) |
| end if |
| ← Norm() |
| ← Norm() |
| end for |
| , , ← (Maxpool()), (Maxpool()), (Maxpool()) |
| , , ← CBAM(), CBAM(), CBAM() |
| ← Norm() |
| ← (Cat(Upsample(), )) |
| for m in 3, 2, 1 do |
| ← (Cat(Upsample(), )) |
| end for |
| y ← FC () |
| L ← CE (y, ) |
| Using gradient descent with Adam for loss backward |
| Update θec, θdc, , , , , and |
| end for |
| end for |
3. Results and Analyses
3.1. Evaluation Protocol
3.2. Experimental and Training Settings
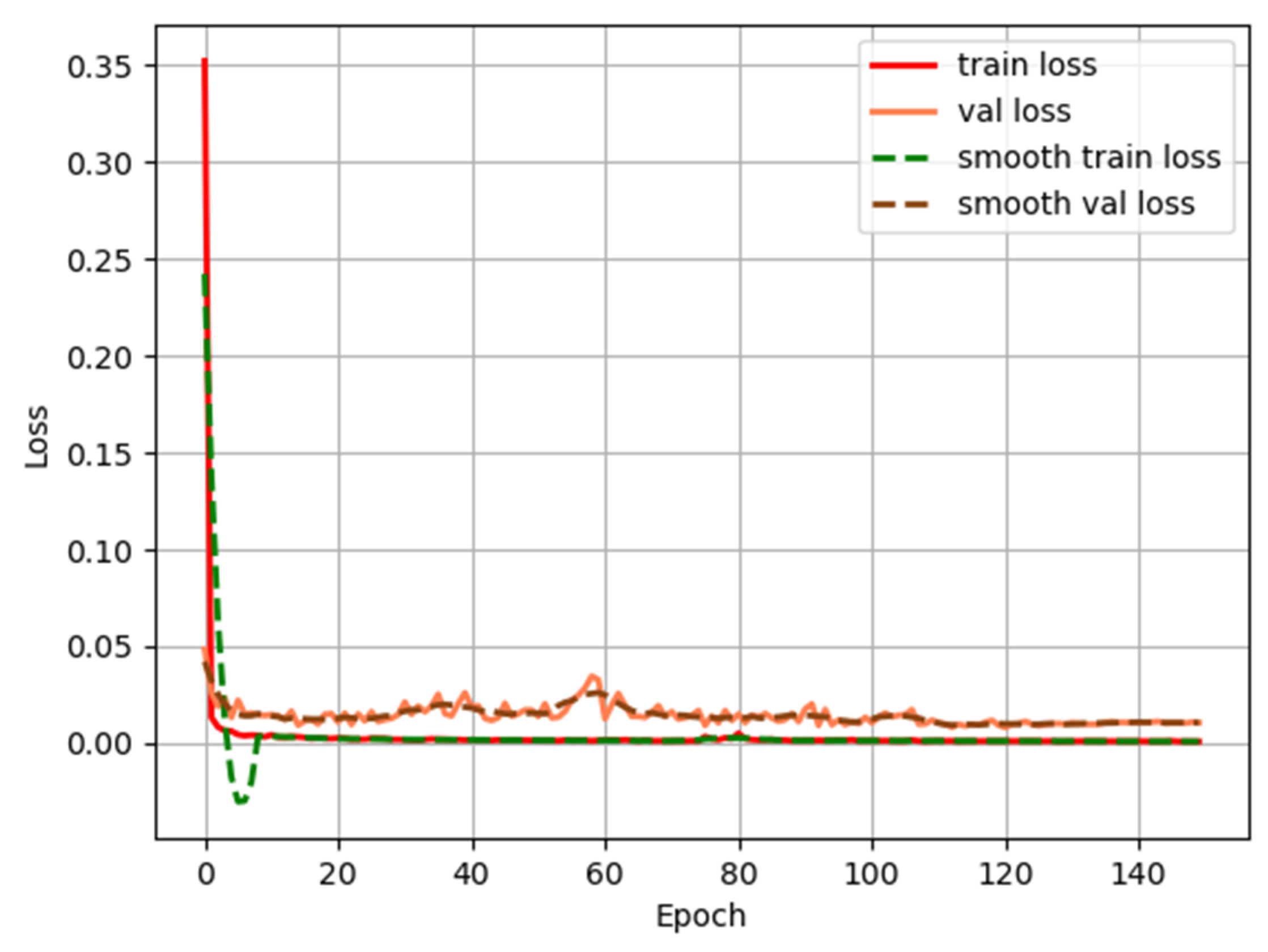
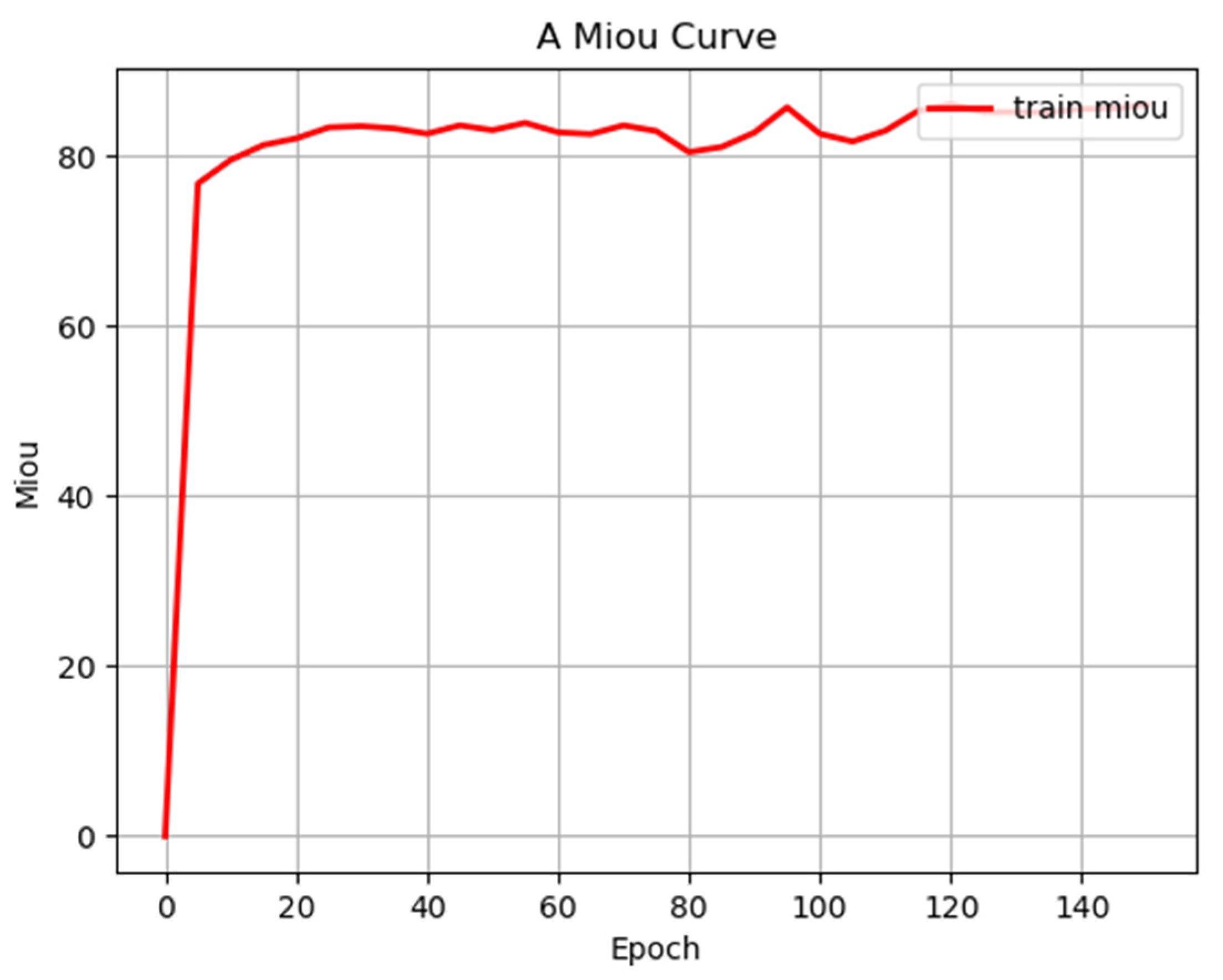
3.3. Results
3.4. Self-Adaptive Weighted Fusion Strategies and Coefficients
3.5. Results for Different Smoke Type and the Visualization Performance
4. Discussion
- (1)
- The volume of data samples used for training and testing are relatively small due to the lack of smoke annotation, especially for the IS smoke samples, which would lead to a decrease in the model accuracy, robustness, and reliability in real application.
- (2)
- The CBAM attention mechanism and the way it was introduced into the proposed model may not be the optimal one. More attention mechanisms are needed to be taken into consideration, and how to incorporate them more properly into the baseline model requires further attempts.
- (3)
- Only three color spaces are involved for multiple color spaces feature fusion, which limits the research refinement. More distinct color spaces and combinations could be considered and the appropriate number of multiple inputs for multiple color spaces needs further study.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, Y.; Tang, Q.; Wu, X.; Lu, X. EFFNet: Enhanced Feature Foreground Network for Video Smoke Source Prediction and Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1820–1833. [Google Scholar] [CrossRef]
- Zhu, G.; Chen, Z.; Liu, C.; Rong, X.; He, W. 3D video semantic segmentation for wildfire smoke. Mach. Vis. Appl. 2020, 31, 50. [Google Scholar] [CrossRef]
- Lu, N. Dark convolutional neural network for forest smoke detection and localization based on single image. Soft Comput. 2022, 26, 8647–8659. [Google Scholar] [CrossRef]
- Dewangan, A.; Pande, Y.; Braun, H.-W.; Vernon, F.; Perez, I.; Altintas, I.; Cottrell, G.W.; Nguyen, M.H. FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection. Remote Sens. 2022, 14, 1007. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Localization in Video Surveillance Applications. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Singh, P.K.; Sharma, A. An insight to forest fire detection techniques using wireless sensor networks. In Proceedings of the 2017 4th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 21–23 September 2017; pp. 647–653. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A Review on Early Forest Fire Detection Systems Using Optical Remote Sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Jin, C.; Wang, T.; Alhusaini, N.; Zhao, S.; Liu, H.; Xu, K.; Zhang, J. Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire 2023, 6, 315. [Google Scholar] [CrossRef]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.W.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Abid, F. A Survey of Machine Learning Algorithms Based Forest Fires Prediction and Detection Systems. Fire Technol. 2021, 57, 559–590. [Google Scholar] [CrossRef]
- Szpakowski, D.M.; Jensen, J.L.R. A Review of the Applications of Remote Sensing in Fire Ecology. Remote Sens. 2019, 11, 2638. [Google Scholar] [CrossRef]
- Khan, F.; Xu, Z.; Sun, J.; Khan, F.M.; Ahmed, A.; Zhao, Y. Recent Advances in Sensors for Fire Detection. Sensors 2022, 22, 3310. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Taberkit, A.M.; Kechida, A. A review on early wildfire detection from unmanned aerial vehicles using deep learning-based computer vision algorithms. Signal Process. 2022, 190, 108309. [Google Scholar] [CrossRef]
- Mao, J.; Zheng, C.; Yin, J.; Tian, Y.; Cui, W. Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation. Sensors 2021, 21, 7785. [Google Scholar] [CrossRef]
- Memane, S.E.; Kulkarni, V.S. A Review on Flame and Smoke Detection Techniques in Videos. Int. J. Adv. Res. Electr. Electron. Instrum. Energy 2015, 4, 855–859. [Google Scholar]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video Flame and Smoke Based Fire Detection Algorithms: A Literature Review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Garg, S.; Verma, A.A. Review Survey on Smoke Detection. Imp. J. Interdiscip. Res. 2016, 2, 935–939. [Google Scholar]
- Chaturvedi, S.; Khanna, P.; Ojha, A. A survey on vision-based outdoor smoke detection techniques for environmental safety. ISPRS J. Photogramm. Remote Sens. 2022, 185, 158–187. [Google Scholar] [CrossRef]
- Altun, M.; Celenk, M. Smoke Detection in Video Surveillance Using Optical Flow and Green’ s Theorem. In Proceedings of the IPCV 2013: International Conference on Image Processing, Computer Vision, and Pattern Recognition, Las Vegas, NV, USA, 22–25 July 2013. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Govil, K.; Welch, M.L.; Ball, J.T.; Pennypacker, C.R. Preliminary Results from a Wildfire Detection System Using Deep Learning on Remote Camera Images. Remote Sens. 2020, 12, 166. [Google Scholar] [CrossRef]
- Zhang, Z.; Jin, Q.; Wang, L.; Liu, Z. Video-based Fire Smoke Detection Using Temporal-spatial Saliency Features. Procedia Comput. Sci. 2022, 198, 493–498. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, S.; Wang, H.; Li, J.; Liu, H. Unified Smoke and Fire Detection in An Evolutionary Framework with Self-Supervised Progressive Data Augment. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 574–581. [Google Scholar]
- Fernandes, A.M.; Utkin, A.B.; Chaves, P. Automatic Early Detection of Wildfire Smoke with Visible Light Cameras Using Deep Learning and Visual Explanation. IEEE Access 2022, 10, 12814–12828. [Google Scholar] [CrossRef]
- Bhamra, J.K.; Ramaprasad, S.A.; Baldota, S.; Luna, S.; Zen, E.; Ramachandra, R.; Kim, H.; Schmidt, C.; Arends, C.; Block, J.; et al. Multimodal Wildland Fire Smoke Detection. Remote Sens. 2023, 15, 2790. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.; Gong, J. Deep Convolutional Network with Pixel-Aware Attention for Smoke Recognition. Fire Technol. 2022, 58, 1839–1862. [Google Scholar] [CrossRef]
- Hasan, S.B.; Rahman, S.; Khaliluzzaman, M.; Ahmed, S. Smoke Detection from Different Environmental Conditions Using Faster R-CNN Approach Based on Deep Neural Network. In Cyber Security and Computer Science: Second EAI International Conference, ICONCS 2020, Dhaka, Bangladesh, 15–16 February 2020, Proceedings 2; Springer International Publishing: Cham, Switzerland, 2020; pp. 705–717. [Google Scholar]
- Guede-Fernández, F.; Martins, L.; de Almeida, R.V.; Gamboa, H.; Vieira, P. A Deep Learning Based Object Identification System for Forest Fire Detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using MVMNet. Knowl. Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Li, J.; Zhou, G.; Chen, A.; Wang, Y.; Jiang, J.; Hu, Y.; Lu, C. Adaptive linear feature-reuse network for rapid forest fire smoke detection model. Ecol. Inform. 2022, 68, 101584. [Google Scholar] [CrossRef]
- Choi, M.; Kim, C.; Oh, H. A video-based SlowFastMTB model for detection of small amounts of smoke from incipient forest fires. J. Comput. Des. Eng. 2022, 9, 793–804. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Chen, G.; Cheng, R.; Lin, X.; Jiao, W.; Bai, D.; Lin, H. LMDFS: A Lightweight Model for Detecting Forest Fire Smoke in UAV Images Based on YOLOv7. Remote Sens. 2023, 15, 3790. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A Gated Recurrent Network with Dual Classification Assistance for Smoke Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 4409–4422. [Google Scholar] [CrossRef]
- Perrolas, G.; Niknejad, M.; Ribeiro, R.; Bernardino, A. Scalable Fire and Smoke Segmentation from Aerial Images Using Convolutional Neural Networks and Quad-Tree Search. Sensors 2022, 22, 1701. [Google Scholar] [CrossRef]
- Khan, S.; Muhammad, K.; Hussain, T.; Del Ser, J.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H.C. DeepSmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Ding, Z.; Zhao, Y.; Li, A.; Zheng, Z. Spatial–Temporal Attention Two-Stream Convolution Neural Network for Smoke Region Detection. Fire 2021, 4, 66. [Google Scholar] [CrossRef]
- Muksimova, S.; Mardieva, S.; Cho, Y.-I. Deep Encoder–Decoder Network-Based Wildfire Segmentation Using Drone Images in Real-Time. Remote Sens. 2022, 14, 6302. [Google Scholar] [CrossRef]
- Martins, L.; Guede-Fernández, F.; Valente de Almeida, R.; Gamboa, H.; Vieira, P. Real-Time Integration of Segmentation Techniques for Reduction of False Positive Rates in Fire Plume Detection Systems during Forest Fires. Remote Sens. 2022, 14, 2701. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, C.; Yin, J.; Tian, Y.; Cui, W. A Semantic Segmentation Method for Early Forest Fire Smoke Based on Concentration Weighting. Electronics 2021, 10, 2675. [Google Scholar] [CrossRef]
- Deng, J.; Bei, S.; Shaojing, S.; Zhen, Z. Feature Fusion Methods in Deep-Learning Generic Object Detection: A Survey. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11 December 2020; pp. 431–437. [Google Scholar]
- Tang, L.; Zhang, H.; Xu, H.; Ma, J. Deep Learning-Based Image Fusion: A Survey. J. Image Graph. 2023, 28, 3–36. [Google Scholar]
- Liu, Y.; Zheng, C.; Liu, X.; Tian, Y.; Zhang, J.; Cui, W. Forest Fire Monitoring Method Based on UAV Visual and Infrared Image Fusion. Remote Sens. 2023, 15, 3173. [Google Scholar] [CrossRef]
- Zhao, J.; Zhou, Y.; Shi, B.; Yang, J.; Zhang, D.; Yao, R. Multi-Stage Fusion and Multi-Source Attention Network for Multi-Modal Remote Sensing Image Segmentation. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–20. [Google Scholar] [CrossRef]
- Chen, X.; Hopkins, B.; Wang, H.; O’neill, L.; Afghah, F.; Razi, A.; Fulé, P.; Coen, J.; Rowell, E.; Watts, A. Wildland Fire Detection and Monitoring Using a Drone-Collected RGB/IR Image Dataset. IEEE Access 2022, 10, 121301–121317. [Google Scholar] [CrossRef]
- Daoud, Z.; Ben Hamida, A.; Ben Amar, C. FireClassNet: A deep convolutional neural network approach for PJF fire images classification. Neural Comput. Appl. 2023, 35, 19069–19085. [Google Scholar] [CrossRef]
- Haridasan, S.; Rattani, A.; Demissie, Z.; Dutta, A. Multispectral Deep Learning Models for Wildfire Detection. In Proceedings of the International Workshop on Data-driven Resilience Research, Leipzig, Germany, 6 July 2022. [Google Scholar]
- Xing, D.; Zhongming, Y.; Lin, W.; Jinlan, L. Smoke Image Segmentation Based on Color Model. J. Innov. Sustain. 2015, 6, 130–138. [Google Scholar] [CrossRef]
- Prema, C.E.; Vinsley, S.S.; Suresh, S. Multi Feature Analysis of Smoke in YUV Color Space for Early Forest Fire Detection. Fire Technol. 2016, 52, 1319–1342. [Google Scholar] [CrossRef]
- Pundir, A.S.; Raman, B. Deep Belief Network for Smoke Detection. Fire Technol. 2017, 53, 1943–1960. [Google Scholar] [CrossRef]
- CVAT. Available online: http://www.cvat.ai (accessed on 4 March 2024).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Datetime of the Fire | Location of the Fire | Smoke Type | #Images | Total |
|---|---|---|---|---|---|
| Training | 11:19 on 20 May 2017 | Lyons Peak South | NCS | 38 | 281 |
| 14:19 on 13 August 2019 | L. A. Co. F. D Helibase 69 Bravo East | NCS | 34 | ||
| 11:30 on 6 July 2018 | Mt. San Miguel North | NSI | 24 | ||
| 13:31 on 27 July 2018 | Mt. Woodson North | NSI | 29 | ||
| 15:03 on 29 May 2019 | Otay Mountain North | NSI | 23 | ||
| 13:03 on 16 July 2019 | Mesa Grande North | NSI | 21 | ||
| 18:34 on 6 August 2020 | Otay Mountain North | NSI | 24 | ||
| 10:56 on 29 August 2020 | Cuyamaca Peak South | NSI | 24 | ||
| 14:25 on 5 September 2020 | Los Pinos West | NSI | 23 | ||
| 09:43 on 26 July 2018 | Sky Oaks North | IS | 24 | ||
| 13:34 on 16 December 2020 | Lyons Peak West | IS | 17 | ||
| Testing | 14:56 on 24 September 2019 | Lyons Peak North | NCS | 29 | 71 |
| 14:29 on 5 September 2020 | Mt. San Miguel East | NSI | 22 | ||
| 11:55 on 25 July 2018 | High Point North | IS | 20 |
| Models | Spaces | ||||||
|---|---|---|---|---|---|---|---|
| RGB | HSV | YCbCr | RGB HSV | RGB YCbCr | HSV YCbCr | RGB HSV YCbCr | |
| DeepLabv3+ Based Basic Fusion Model | 68.03 | 66.89 | 65.14 | 70.86 | 67.99 | 68.41 | 73.44 |
| PSPNet Based Basic Fusion Model | 74.60 | 71.91 | 70.32 | 74.36 | 72.52 | 73.78 | 77.53 |
| U-Net Based Basic Fusion Model | 83.12 | 79.33 | 78.46 | 82.61 | 78.08 | 82.19 | 82.14 |
| U-Net Based Fusion Model w. CBAM | 83.54 | 79.32 | 79.47 | 82.29 | 79.86 | 83.05 | 84.05 |
| U-Net Based Fusion Model w. CBAM & Self-Adaptive Weights | —— | —— | —— | 84.44 | 81.44 | 85.88 | 85.04 |
| SUFN w/o CBAM nor Self-Adaptive Weights | 83.12 | 79.33 | 78.46 | 84.89 | 82.83 | —— | 84.57 |
| SUFN w/o Self-Adaptive Weights | 83.54 | 79.32 | 79.47 | 85.21 | 83.73 | —— | 84.63 |
| SUFN | —— | —— | —— | 85.44 | 84.86 | —— | 86.14 |
| Models | FPR (%) | FNR (%) |
|---|---|---|
| DeepLabv3+ Based Basic Fusion Model (RGB & HSV & YCbCr) | 14.85 | 15.33 |
| PSPNet Based Basic Fusion Model (RGB & HSV & YCbCr) | 12.27 | 11.12 |
| U-Net Baseline Model | 8.10 | 10.06 |
| U-Net Based Fusion Model w. CBAM & Self-Adaptive Weights (HSV & YCbCr) | 7.28 | 7.65 |
| SUFN (RGB & HSV & YCbCr) | 4.93 | 6.13 |
| Models & Fusion Hyper-Parameters Type | Spaces | ||||||
|---|---|---|---|---|---|---|---|
| RGB | HSV | YCbCr | RGB HSV | RGB YCbCr | HSV YCbCr | RGB HSV YCbCr | |
| U-Net Based Basic Fusion Model | 83.12 | 79.33 | 78.46 | 82.61 | 78.08 | 82.19 | 82.14 |
| U-Net Based Fusion Model w. CBAM | 83.54 | 79.32 | 79.47 | 82.29 | 79.86 | 83.05 | 84.05 |
| U-Net Based Fusion Model w. CBAM & Self-Adaptive Weights (A) | —— | —— | —— | 83.47 | 80.93 | 84.16 | 82.74 |
| U-Net Based Fusion Model w. CBAM & Self-Adaptive Weights (B) | —— | —— | —— | 84.44 | 81.44 | 85.88 | 85.04 |
| U-Net Based Fusion Model w. CBAM & Self-Adaptive Weights (C) | —— | —— | —— | 81.79 | 78.90 | 84.56 | 83.33 |
| SUFN w/o CBAM nor Self-Adaptive Weights | 83.12 | 79.33 | 78.46 | 84.89 | 82.83 | —— | 84.57 |
| SUFN w/o Self-Adaptive Weights | 83.54 | 79.32 | 79.47 | 85.21 | 83.73 | —— | 84.63 |
| SUFN (D) | —— | —— | —— | 84.81 | 84.00 | —— | 85.22 |
| SUFN (E) | —— | —— | —— | 85.44 | 84.86 | —— | 86.14 |
| SUFN (F) | —— | —— | —— | 85.30 | 83.29 | —— | 83.32 |
| Models | Features Fusion Phases | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Features Encoding Fusion | Deep Features Fusion | Shallow Features Fusion | |||||||
| RGB | HSV | YCbCr | RGB | HSV | YCbCr | RGB | HSV | YCbCr | |
| U-Net Based Fusion Model w. CBAM & Self-Adaptive Weights (B) | —— | —— | —— | —— | 0.491 | 0.509 | —— | 0.437 | 0.563 |
| SUFN (E) | 0.592 | 0.170 | 0.238 | 0.584 | 0.197 | 0.219 | 0.543 | 0.142 | 0.315 |
| Model | Testing Smoke Type | ||
|---|---|---|---|
| NCS | NSI | IS | |
| SUFN(E) in RGB & HSV & YCbCr Spaces | 90.31 | 85.79 | 80.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Z.; Tian, Y.; Zheng, C.; Zhao, F. Forest Fire Smoke Detection Based on Multiple Color Spaces Deep Feature Fusion. Forests 2024, 15, 689. https://doi.org/10.3390/f15040689
Han Z, Tian Y, Zheng C, Zhao F. Forest Fire Smoke Detection Based on Multiple Color Spaces Deep Feature Fusion. Forests. 2024; 15(4):689. https://doi.org/10.3390/f15040689
Chicago/Turabian StyleHan, Ziqi, Ye Tian, Change Zheng, and Fengjun Zhao. 2024. "Forest Fire Smoke Detection Based on Multiple Color Spaces Deep Feature Fusion" Forests 15, no. 4: 689. https://doi.org/10.3390/f15040689
APA StyleHan, Z., Tian, Y., Zheng, C., & Zhao, F. (2024). Forest Fire Smoke Detection Based on Multiple Color Spaces Deep Feature Fusion. Forests, 15(4), 689. https://doi.org/10.3390/f15040689