

Prediction of Bonding Strength of Heat-Treated Wood Based on an Improved Harris Hawk Algorithm Optimized BP Neural Network Model (IHHO-BP)
Abstract
:1. Introduction
- This paper proposes an improved Harris Hawk algorithm (IHHO) based on the Sobol sequence, Whale algorithm, and t-distribution perturbation, which mainly addresses the shortcomings of the HHO algorithm in terms of trapping in local optima and having an uneven and low-diversity initial population distribution. The main improvements include the following three aspects: firstly, the population is initialized with a Sobol sequence to make the population distribution more uniform and increase the population diversity; secondly, the Whale Optimization Algorithm is integrated to update the position of the Harris Hawk population; finally, the t-distribution is introduced to perturb the Harris Hawk optimization search results to prevent them from getting trapped in local optima solutions.
- The IHHO algorithm is used to optimize the BP neural network parameters, which enhances the performance of the BP neural network in terms of convergence and prediction accuracy.
- The model was validated by using the optimized IHHO-BP neural network for predicting the bonding strength of wood, and the outcomes were contrasted with the traditional model, which showed that the proposed model had higher prediction accuracy than the traditional model, and the model could better fulfill the requirement of prediction accuracy.
2. IHHO-BP Neural Network Prediction Model
2.1. Underlying Mechanism of the BP Neural Network
2.2. The Traditional HHO Algorithm
2.2.1. Exploration Phase
2.2.2. Transition Phase
2.2.3. Exploitation Phase
2.3. The IHHO Algorithm
2.3.1. Initializing Populations with the Sobol Sequences
2.3.2. Adding the Whale Optimization Algorithm (WOA) to Update the Position
2.3.3. The t-Distribution Perturbation
2.4. The IHHO-BP Algorithm
3. Experimental
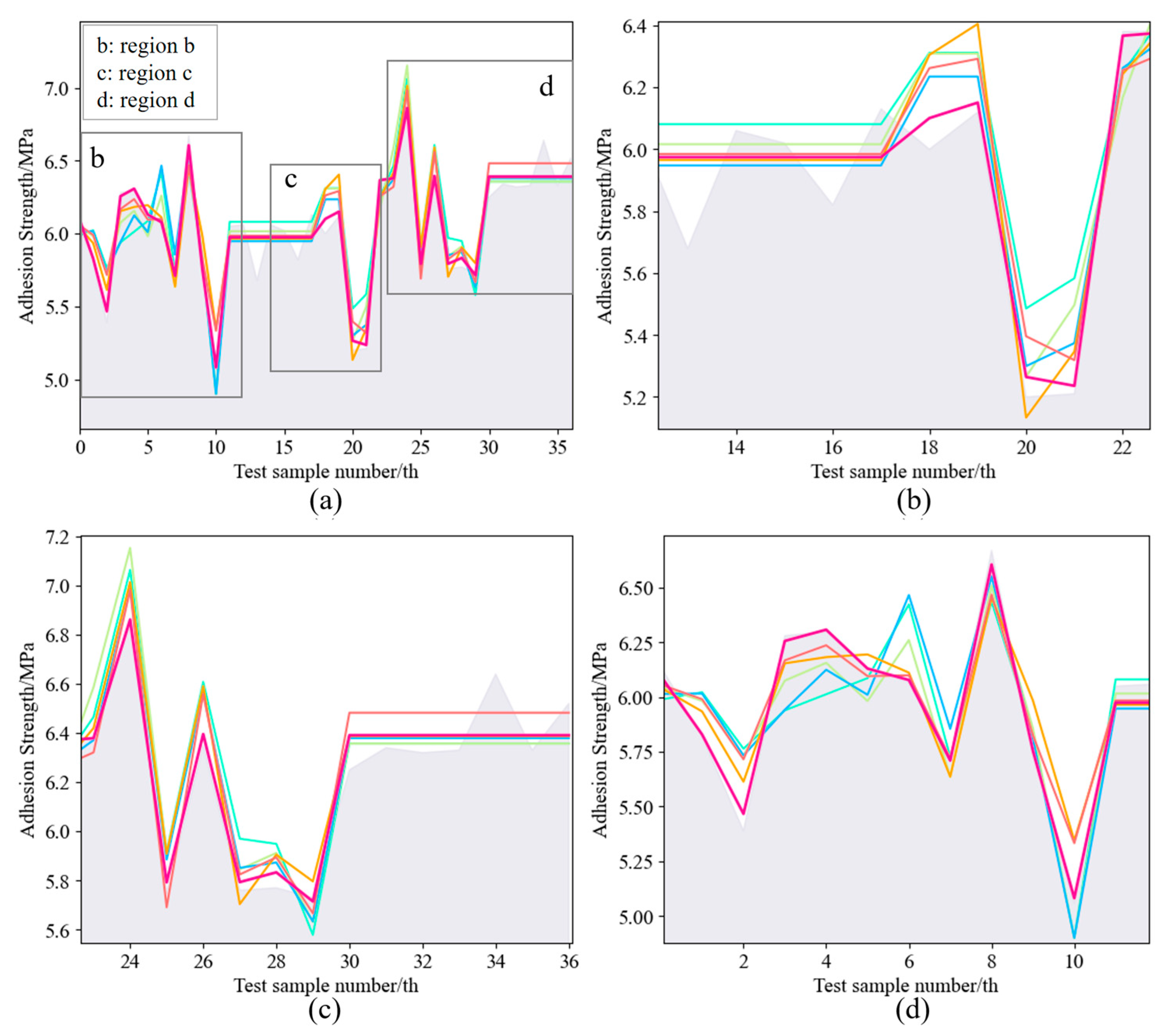
3.1. Data Preprocessing
3.2. Model Parameter Settings
3.2.1. Metaheuristic Algorithm Parameter Settings
3.2.2. Determination of the Number of Neurons and Activation Function in the Model
3.2.3. Evaluation Criteria of the Model
4. Results and Discussion
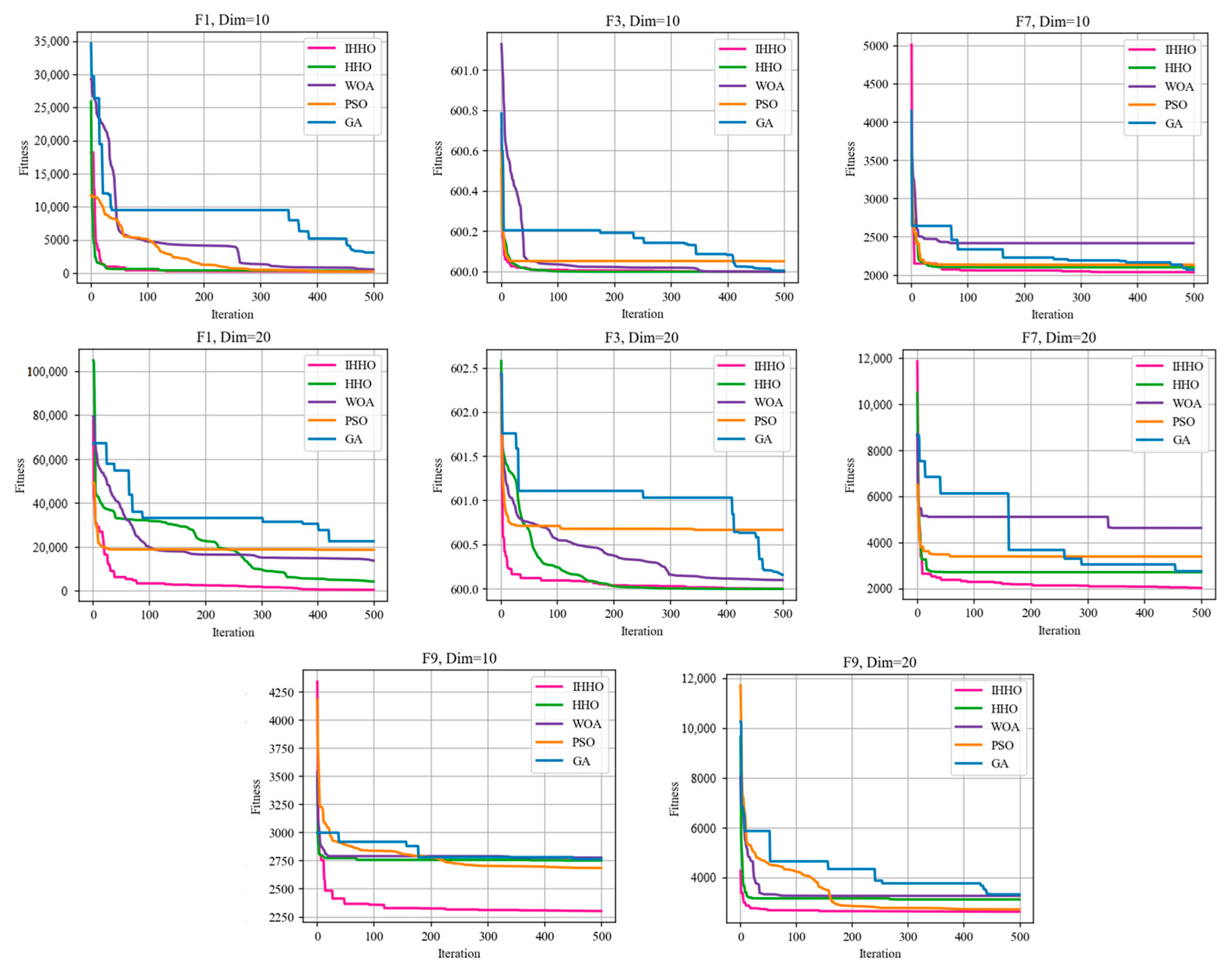
4.1. Verification of the Effectiveness of the IHHO Algorithm
4.2. Comparison Results with Other Benchmark Models
4.3. Comparison with Previous Research Results
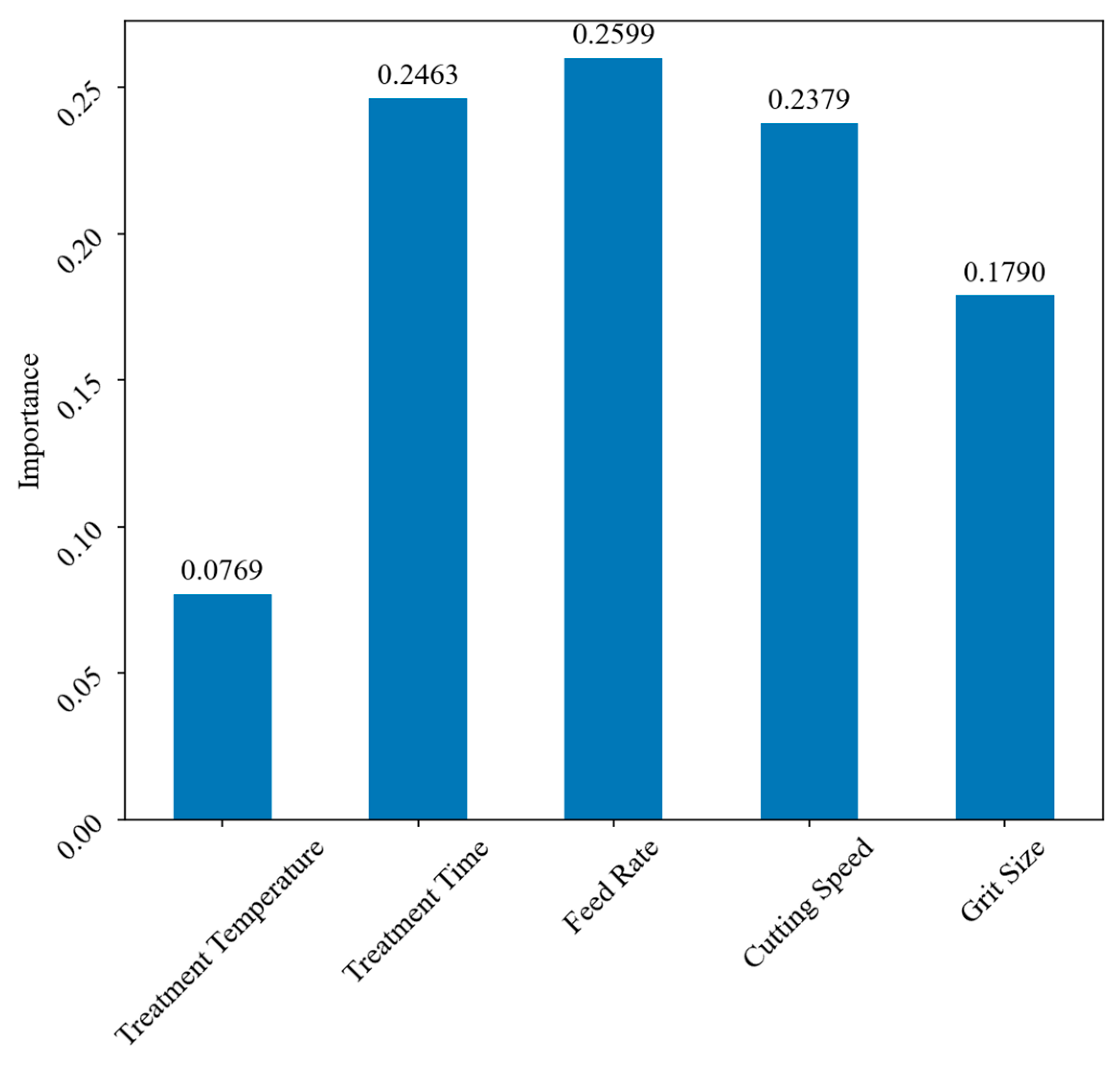
4.4. Analysis of Input Feature Importance
5. Conclusions
- The IHHO algorithm is introduced to address the issue of the traditional HHO algorithm having limited global search ability and being prone to a local optimum. First, the population is initialized by using the Sobol sequence to improve the diversity of the initialized population and the uniformity of its distribution. Second, the population position is updated by integrating the Whale Optimization Algorithm to enhance the global search ability of the algorithm. Finally, t-distribution perturbation is incorporated to achieve a balance between the global search ability and exploitation ability of the algorithm to prevent the algorithm from converging to locally optimal solutions.
- We established the IHHO-BP model to forecast the bonding strength of heat-treated wood based on the heat treatment temperature, heat treatment time, feed speed, cutting speed, and sandpaper granularity. The proposed model was evaluated by comparing the prediction results with those of the HHO-BP, WOA-BP, PSO-BP, GA-BP, and BP models. The results showed that the IHHO-BP model had the smallest MAE, RMSE, and MAPE, and the largest R2. This indicates that the IHHO-BP model has the smallest prediction error and superior prediction accuracy, and it can better meet the accuracy requirements for predicting the bonding strength of heat-treated wood.
- The IHHO-BP model was compared with previous LR, ELM, SVR, GA-SVR, and CPA-BP prediction models. The results showed that compared with the above models, the IHHO-BP model also achieved the lowest MAE, RMSE, and MAPE, and the highest R2, once again highlighting the superior performance of the IHHO-BP model in forecasting the bonding strength of heat-treated wood.
- Through the importance analysis of five features in predicting the bonding strength of heat-treated wood using RF, it is concluded that in this study, feed rate has the greatest impact on the prediction of bonding strength, followed by treatment time, cutting speed, and grit size. Treatment temperature has the least impact on the prediction of bonding strength. This provides important reference for the study of factors affecting the bonding strength of heat-treated wood.
- However, this study has some limitations. Although we used evaluation metrics and compared multiple benchmark models to demonstrate the superiority of the proposed model in predicting the bonding strength of heat-treated wood, we lacked relevant statistical tests. While the improved IHHO algorithm has significantly enhanced optimization performance, we have not yet analyzed the computational cost brought about by the added improvement measures. In future research, we will conduct a comprehensive analysis of the model in terms of statistical tests and time complexity, compare as many new meta-heuristic algorithms as possible, and attempt to use the model to predict other mechanical properties of heat-treated wood besides bonding strength. This will enhance the applicability of the model in actual production.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Treatment Temperature/°C | Treatment Time/h | Feed Rate/m/min | Cutting Speed/m/s | Grit Size | Adhesion Strength/MPa |
|---|---|---|---|---|---|
| 190 | 2 | 16 | 4 | 100–150 | 5.54 |
| 210 | 2 | 16 | 4 | 100–150 | 5.96 |
| 190 | 2 | 16 | 6 | 100–150 | 5.94 |
| 210 | 2 | 16 | 6 | 100–150 | 5.64 |
| 190 | 2 | 20 | 4 | 100–150 | 7.26 |
| 210 | 2 | 20 | 4 | 100–150 | 6.83 |
| 190 | 2 | 20 | 6 | 100–150 | 6.17 |
| 210 | 2 | 20 | 6 | 100–150 | 5.48 |
| 190 | 4 | 16 | 4 | 100–150 | 5.02 |
| 210 | 4 | 16 | 4 | 100–150 | 5.04 |
| 190 | 4 | 16 | 6 | 100–150 | 5.93 |
| 210 | 4 | 16 | 6 | 100–150 | 6.17 |
| 190 | 4 | 20 | 4 | 100–150 | 5.86 |
| 210 | 4 | 20 | 4 | 100–150 | 6.17 |
| 190 | 4 | 20 | 6 | 100–150 | 5.99 |
| 210 | 4 | 20 | 6 | 100–150 | 6.05 |
| 180 | 3 | 18 | 5 | 100–150 | 6.45 |
| 220 | 3 | 18 | 5 | 100–150 | 6.15 |
| 200 | 3 | 18 | 3 | 100–150 | 6.34 |
| 200 | 3 | 18 | 7 | 100–150 | 6.11 |
| 200 | 3 | 14 | 5 | 100–150 | 4.95 |
| 200 | 3 | 22 | 5 | 100–150 | 6.15 |
| 200 | 1 | 18 | 5 | 100–150 | 5.71 |
| 200 | 5 | 18 | 5 | 100–150 | 5.17 |
| 200 | 3 | 18 | 5 | 100–150 | 5.75 |
| 200 | 3 | 18 | 5 | 100–150 | 5.59 |
| 200 | 3 | 18 | 5 | 100–150 | 5.94 |
| 200 | 3 | 18 | 5 | 100–150 | 6 |
| 200 | 3 | 18 | 5 | 100–150 | 6.04 |
| 200 | 3 | 18 | 5 | 100–150 | 5.96 |
| 200 | 3 | 18 | 5 | 100–150 | 6.15 |
| 190 | 2 | 16 | 4 | 100–150 | 6.18 |
| 210 | 2 | 16 | 4 | 100–150 | 5.76 |
| 190 | 2 | 16 | 6 | 100–150 | 5.68 |
| 210 | 2 | 16 | 6 | 100–150 | 5.95 |
| 190 | 2 | 20 | 4 | 100–150 | 7.56 |
| 210 | 2 | 20 | 4 | 100–150 | 7.09 |
| 190 | 2 | 20 | 6 | 100–150 | 6 |
| 210 | 2 | 20 | 6 | 100–150 | 5.78 |
| 190 | 4 | 16 | 4 | 100–150 | 4.38 |
| 210 | 4 | 16 | 4 | 100–150 | 5.14 |
| 190 | 4 | 16 | 6 | 100–150 | 6.23 |
| 210 | 4 | 16 | 6 | 100–150 | 5.79 |
| 190 | 4 | 20 | 4 | 100–150 | 6.11 |
| 210 | 4 | 20 | 4 | 100–150 | 5.95 |
| 190 | 4 | 20 | 6 | 100–150 | 5.96 |
| 210 | 4 | 20 | 6 | 100–150 | 5.82 |
| 180 | 3 | 18 | 5 | 100–150 | 6.89 |
| 220 | 3 | 18 | 5 | 100–150 | 5.84 |
| 200 | 3 | 18 | 3 | 100–150 | 5.65 |
| 200 | 3 | 18 | 7 | 100–150 | 6.04 |
| 200 | 3 | 14 | 5 | 100–150 | 5.77 |
| 200 | 3 | 22 | 5 | 100–150 | 6.48 |
| 200 | 1 | 18 | 5 | 100–150 | 5.94 |
| 200 | 5 | 18 | 5 | 100–150 | 4.56 |
| 200 | 3 | 18 | 5 | 100–150 | 5.94 |
| 200 | 3 | 18 | 5 | 100–150 | 5.56 |
| 200 | 3 | 18 | 5 | 100–150 | 5.99 |
| 200 | 3 | 18 | 5 | 100–150 | 6.08 |
| 200 | 3 | 18 | 5 | 100–150 | 6.16 |
| 200 | 3 | 18 | 5 | 100–150 | 5.64 |
| 200 | 3 | 18 | 5 | 100–150 | 6.11 |
| 190 | 2 | 16 | 4 | 100–150 | 6.04 |
| 210 | 2 | 16 | 4 | 100–150 | 5.58 |
| 190 | 2 | 16 | 6 | 100–150 | 6.05 |
| 210 | 2 | 16 | 6 | 100–150 | 5.79 |
| 190 | 2 | 20 | 4 | 100–150 | 7.09 |
| 210 | 2 | 20 | 4 | 100–150 | 6.78 |
| 190 | 2 | 20 | 6 | 100–150 | 5.79 |
| 210 | 2 | 20 | 6 | 100–150 | 5.31 |
| 190 | 4 | 16 | 4 | 100–150 | 4.97 |
| 210 | 4 | 16 | 4 | 100–150 | 5.06 |
| 190 | 4 | 16 | 6 | 100–150 | 5.84 |
| 210 | 4 | 16 | 6 | 100–150 | 6.01 |
| 190 | 4 | 16 | 4 | 100–120 | 6.67 |
| 210 | 2 | 16 | 4 | 100–120 | 6.41 |
| 190 | 2 | 16 | 6 | 100–120 | 6.05 |
| 210 | 2 | 16 | 6 | 100–120 | 5.62 |
| 190 | 2 | 20 | 4 | 100–120 | 7.01 |
| 210 | 2 | 20 | 4 | 100–120 | 6.91 |
| 190 | 2 | 20 | 6 | 100–120 | 5.17 |
| 210 | 2 | 20 | 6 | 100–120 | 4.74 |
| 190 | 4 | 16 | 4 | 100–120 | 6.33 |
| 210 | 4 | 16 | 4 | 100–120 | 5.84 |
| 190 | 4 | 16 | 6 | 100–120 | 6.76 |
| 210 | 4 | 16 | 6 | 100–120 | 6.49 |
| 190 | 4 | 20 | 4 | 100–120 | 6.24 |
| 210 | 4 | 20 | 4 | 100–120 | 6.29 |
| 190 | 4 | 20 | 6 | 100–120 | 5.57 |
| 210 | 4 | 20 | 6 | 100–120 | 5.26 |
| 180 | 3 | 18 | 5 | 100–120 | 6.62 |
| 220 | 3 | 18 | 5 | 100–120 | 6.29 |
| 200 | 3 | 18 | 3 | 100–120 | 7.1 |
| 200 | 3 | 18 | 7 | 100–120 | 5.44 |
| 200 | 3 | 14 | 5 | 100–120 | 6.45 |
| 200 | 3 | 22 | 5 | 100–120 | 5.97 |
| 200 | 1 | 18 | 5 | 100–120 | 5.64 |
| 200 | 5 | 18 | 5 | 100–120 | 5.44 |
| 200 | 3 | 18 | 5 | 100–120 | 6.45 |
| 200 | 3 | 18 | 5 | 100–120 | 6.22 |
| 200 | 3 | 18 | 5 | 100–120 | 5.97 |
| 200 | 3 | 18 | 5 | 100–120 | 6.37 |
| 200 | 3 | 18 | 5 | 100–120 | 6.25 |
| 200 | 3 | 18 | 5 | 100–120 | 6.7 |
| 200 | 3 | 18 | 5 | 100–120 | 6.33 |
| 190 | 2 | 16 | 4 | 100–120 | 6.81 |
| 210 | 2 | 16 | 4 | 100–120 | 6.85 |
| 190 | 2 | 16 | 6 | 100–120 | 6.83 |
| 210 | 2 | 16 | 6 | 100–120 | 6.36 |
| 190 | 2 | 20 | 4 | 100–120 | 7.08 |
| 210 | 2 | 20 | 4 | 100–120 | 7.1 |
| 190 | 2 | 20 | 6 | 100–120 | 5.43 |
| 210 | 2 | 20 | 6 | 100–120 | 4.95 |
| 190 | 4 | 16 | 4 | 100–120 | 6.15 |
| 210 | 4 | 16 | 4 | 100–120 | 5.93 |
| 190 | 4 | 16 | 6 | 100–120 | 6.74 |
| 210 | 4 | 16 | 6 | 100–120 | 6.63 |
| 190 | 4 | 20 | 4 | 100–120 | 6.67 |
| 210 | 4 | 20 | 4 | 100–120 | 6.42 |
| 190 | 4 | 20 | 6 | 100–120 | 5.48 |
| 210 | 4 | 20 | 6 | 100–120 | 4.94 |
| 180 | 3 | 18 | 5 | 100–120 | 6.52 |
| 220 | 3 | 18 | 5 | 100–120 | 6.22 |
| 200 | 3 | 18 | 3 | 100–120 | 7.26 |
| 200 | 3 | 18 | 7 | 100–120 | 5.8 |
| 200 | 3 | 14 | 5 | 100–120 | 6.84 |
| 200 | 3 | 22 | 5 | 100–120 | 5.84 |
| 200 | 1 | 18 | 5 | 100–120 | 5.96 |
| 200 | 5 | 18 | 5 | 100–120 | 5.48 |
| 200 | 3 | 18 | 5 | 100–120 | 5.95 |
| 200 | 3 | 18 | 5 | 100–120 | 6.42 |
| 200 | 3 | 18 | 5 | 100–120 | 6.41 |
| 200 | 3 | 18 | 5 | 100–120 | 6.64 |
| 200 | 3 | 18 | 5 | 100–120 | 6.55 |
| 200 | 3 | 18 | 5 | 100–120 | 6.34 |
| 200 | 3 | 18 | 5 | 100–120 | 6.36 |
| 190 | 2 | 16 | 4 | 100–120 | 6.89 |
| 210 | 2 | 16 | 4 | 100–120 | 6.76 |
| 190 | 2 | 16 | 6 | 100–120 | 6.31 |
| 210 | 2 | 16 | 6 | 100–120 | 6.12 |
| 190 | 2 | 20 | 4 | 100–120 | 7.73 |
| 210 | 2 | 20 | 4 | 100–120 | 7.06 |
| 190 | 2 | 20 | 6 | 100–120 | 5.74 |
| 210 | 2 | 20 | 6 | 100–120 | 4.95 |
| 190 | 4 | 16 | 4 | 100–120 | 5.63 |
| 210 | 4 | 16 | 4 | 100–120 | 5.93 |
| 190 | 4 | 16 | 6 | 100–120 | 6.81 |
| 210 | 4 | 16 | 6 | 100–120 | 6.7 |
| 190 | 4 | 20 | 4 | 100–120 | 5.86 |
| 210 | 4 | 20 | 4 | 100–150 | 6.14 |
| 190 | 4 | 20 | 6 | 100–150 | 5.82 |
| 210 | 4 | 20 | 6 | 100–150 | 5.39 |
| 210 | 3 | 18 | 5 | 100–150 | 6.28 |
| 190 | 3 | 18 | 5 | 100–150 | 6.3 |
| 210 | 3 | 18 | 3 | 100–150 | 6.13 |
| 180 | 3 | 18 | 7 | 100–150 | 6.07 |
| 220 | 3 | 14 | 5 | 100–150 | 5.71 |
| 200 | 3 | 22 | 5 | 100–150 | 6.67 |
| 200 | 1 | 18 | 5 | 100–150 | 5.74 |
| 200 | 5 | 18 | 5 | 100–150 | 5.06 |
| 200 | 3 | 18 | 5 | 100–150 | 6.05 |
| 200 | 3 | 18 | 5 | 100–150 | 6.06 |
| 200 | 3 | 18 | 5 | 100–150 | 5.68 |
| 200 | 3 | 18 | 5 | 100–150 | 6.06 |
| 200 | 3 | 18 | 5 | 100–150 | 6.02 |
| 200 | 3 | 18 | 5 | 100–150 | 5.82 |
| 200 | 3 | 18 | 5 | 100–150 | 6.13 |
| 200 | 4 | 20 | 4 | 100–120 | 6 |
| 200 | 4 | 20 | 4 | 100–120 | 6.12 |
| 200 | 4 | 20 | 6 | 100–120 | 5.2 |
| 190 | 4 | 20 | 6 | 100–120 | 5.21 |
| 210 | 3 | 18 | 5 | 100–120 | 6.38 |
| 190 | 3 | 18 | 5 | 100–120 | 6.38 |
| 210 | 3 | 18 | 3 | 100–120 | 6.85 |
| 180 | 3 | 18 | 7 | 100–120 | 5.75 |
| 220 | 3 | 14 | 5 | 100–120 | 6.35 |
| 200 | 3 | 22 | 5 | 100–120 | 5.76 |
| 200 | 1 | 18 | 5 | 100–120 | 5.77 |
| 200 | 5 | 18 | 5 | 100–120 | 5.73 |
| 200 | 3 | 18 | 5 | 100–120 | 6.25 |
| 200 | 3 | 18 | 5 | 100–120 | 6.34 |
| 200 | 3 | 18 | 5 | 100–120 | 6.32 |
| 200 | 3 | 18 | 5 | 100–120 | 6.33 |
| 200 | 3 | 18 | 5 | 100–120 | 6.64 |
| 200 | 3 | 18 | 5 | 100–120 | 6.33 |
| 200 | 3 | 18 | 5 | 100–120 | 6.52 |
| Number of Hidden Layer Neurons | Activate Functions | Average Score | First-Fold Score | Second-Fold Score | Third-Fold Score | Fourth-Fold Score | Fifth-Fold Score |
|---|---|---|---|---|---|---|---|
| 4 | tansig-purelin | 0.1844 | 0.2045 | 0.1610 | 0.2226 | 0.1640 | 0.1696 |
| tansig-sigmod | 0.1946 | 0.2274 | 0.2162 | 0.1225 | 0.2068 | 0.2003 | |
| sigmod-purelin | 0.1326 | 0.1332 | 0.1238 | 0.1446 | 0.1359 | 0.1254 | |
| sigmod-sigmod | 0.1619 | 0.1343 | 0.1233 | 0.2270 | 0.1324 | 0.1923 | |
| relu-purelin | 0.1562 | 0.1817 | 0.1352 | 0.1301 | 0.1824 | 0.1515 | |
| relu-sigmod | 0.1755 | 0.1910 | 0.2116 | 0.1466 | 0.1717 | 0.1564 | |
| 5 | tansig-purelin | 0.0691 | 0.0557 | 0.0785 | 0.0692 | 0.0768 | 0.0656 |
| tansig-sigmod | 0.0786 | 0.0618 | 0.0833 | 0.0824 | 0.0829 | 0.0828 | |
| sigmod-purelin | 0.0742 | 0.0635 | 0.0839 | 0.0807 | 0.0695 | 0.0733 | |
| sigmod-sigmod | 0.0732 | 0.0794 | 0.0544 | 0.0876 | 0.0643 | 0.0805 | |
| relu-purelin | 0.0738 | 0.0802 | 0.0590 | 0.0634 | 0.0781 | 0.0885 | |
| relu-sigmod | 0.0731 | 0.0629 | 0.0852 | 0.0790 | 0.0730 | 0.0654 | |
| 6 | tansig-purelin | 0.0464 | 0.0483 | 0.0533 | 0.0419 | 0.0444 | 0.0441 |
| tansig-sigmod | 0.0475 | 0.0409 | 0.0473 | 0.0505 | 0.0574 | 0.0412 | |
| sigmod-purelin | 0.0534 | 0.0495 | 0.0431 | 0.0564 | 0.0589 | 0.0593 | |
| sigmod-sigmod | 0.0513 | 0.0566 | 0.0458 | 0.0579 | 0.0518 | 0.0444 | |
| relu-purelin | 0.0459 | 0.0449 | 0.0429 | 0.0416 | 0.0542 | 0.0461 | |
| relu-sigmod | 0.0518 | 0.0574 | 0.0598 | 0.0501 | 0.0412 | 0.0507 | |
| 7 | tansig-purelin | 0.0426 | 0.0371 | 0.0583 | 0.0352 | 0.0463 | 0.0361 |
| tansig-sigmod | 0.0499 | 0.0439 | 0.0405 | 0.0497 | 0.0581 | 0.0573 | |
| sigmod-purelin | 0.0442 | 0.0424 | 0.0471 | 0.0381 | 0.0389 | 0.0547 | |
| sigmod-sigmod | 0.0468 | 0.0580 | 0.0442 | 0.0333 | 0.0415 | 0.0568 | |
| relu-purelin | 0.0523 | 0.0588 | 0.0583 | 0.0489 | 0.0366 | 0.0587 | |
| relu-sigmod | 0.0509 | 0.0419 | 0.0414 | 0.0580 | 0.0576 | 0.0556 | |
| 8 | tansig-purelin | 0.0453 | 0.0510 | 0.0416 | 0.0469 | 0.0385 | 0.0484 |
| tansig-sigmod | 0.0468 | 0.0495 | 0.0536 | 0.0359 | 0.0541 | 0.0410 | |
| sigmod-purelin | 0.0450 | 0.0348 | 0.0517 | 0.0353 | 0.0444 | 0.0588 | |
| sigmod-sigmod | 0.0451 | 0.0404 | 0.0574 | 0.0416 | 0.0308 | 0.0550 | |
| relu-purelin | 0.0392 | 0.0355 | 0.0310 | 0.0473 | 0.0431 | 0.0390 | |
| relu-sigmod | 0.0465 | 0.0562 | 0.0336 | 0.0500 | 0.0531 | 0.0396 | |
| 9 | tansig-purelin | 0.0244 | 0.0191 | 0.0350 | 0.0325 | 0.0175 | 0.0177 |
| tansig-sigmod | 0.0253 | 0.0273 | 0.0306 | 0.0247 | 0.0239 | 0.0202 | |
| sigmod-purelin | 0.0275 | 0.0250 | 0.0266 | 0.0188 | 0.0311 | 0.0359 | |
| sigmod-sigmod | 0.0264 | 0.0339 | 0.0301 | 0.0212 | 0.0214 | 0.0251 | |
| relu-purelin | 0.0251 | 0.0257 | 0.0197 | 0.0344 | 0.0271 | 0.0184 | |
| relu-sigmod | 0.0272 | 0.0312 | 0.0245 | 0.0328 | 0.0288 | 0.0185 | |
| 10 | tansig-purelin | 0.0282 | 0.0299 | 0.0296 | 0.0228 | 0.0299 | 0.0285 |
| tansig-sigmod | 0.0363 | 0.0327 | 0.0323 | 0.0362 | 0.0386 | 0.0418 | |
| sigmod-purelin | 0.0347 | 0.0431 | 0.0267 | 0.0457 | 0.0201 | 0.0377 | |
| sigmod-sigmod | 0.0313 | 0.0204 | 0.0447 | 0.0288 | 0.0407 | 0.0221 | |
| relu-purelin | 0.0395 | 0.0346 | 0.0270 | 0.0472 | 0.0408 | 0.0479 | |
| relu-sigmod | 0.0313 | 0.0427 | 0.0270 | 0.0270 | 0.0358 | 0.0242 | |
| 11 | tansig-purelin | 0.0382 | 0.0480 | 0.0366 | 0.0377 | 0.0282 | 0.0405 |
| tansig-sigmod | 0.0381 | 0.0437 | 0.0324 | 0.0362 | 0.0320 | 0.0460 | |
| sigmod-purelin | 0.0379 | 0.0357 | 0.0314 | 0.0390 | 0.0430 | 0.0405 | |
| sigmod-sigmod | 0.0341 | 0.0424 | 0.0316 | 0.0353 | 0.0245 | 0.0364 | |
| relu-purelin | 0.0309 | 0.0256 | 0.0325 | 0.0285 | 0.0422 | 0.0258 | |
| relu-sigmod | 0.0320 | 0.0344 | 0.0309 | 0.0257 | 0.0264 | 0.0423 | |
| 12 | tansig-purelin | 0.0289 | 0.0252 | 0.0236 | 0.0299 | 0.0358 | 0.0300 |
| tansig-sigmod | 0.0331 | 0.0317 | 0.0365 | 0.0410 | 0.0316 | 0.0246 | |
| sigmod-purelin | 0.0384 | 0.0327 | 0.0476 | 0.0437 | 0.0434 | 0.0245 | |
| sigmod-sigmod | 0.0318 | 0.0259 | 0.0331 | 0.0328 | 0.0288 | 0.0384 | |
| relu-purelin | 0.0317 | 0.0306 | 0.0255 | 0.0450 | 0.0353 | 0.0222 | |
| relu-sigmod | 0.0347 | 0.0277 | 0.0313 | 0.0407 | 0.0408 | 0.0331 | |
| 13 | tansig-purelin | 0.0305 | 0.0402 | 0.0243 | 0.0280 | 0.0236 | 0.0361 |
| tansig-sigmod | 0.0357 | 0.0403 | 0.0381 | 0.0303 | 0.0251 | 0.0445 | |
| sigmod-purelin | 0.0309 | 0.0335 | 0.0229 | 0.0273 | 0.0298 | 0.0412 | |
| sigmod-sigmod | 0.0382 | 0.0413 | 0.0311 | 0.0365 | 0.0478 | 0.0342 | |
| relu-purelin | 0.0384 | 0.0368 | 0.0336 | 0.0469 | 0.0435 | 0.0309 | |
| relu-sigmod | 0.0328 | 0.0278 | 0.0474 | 0.0256 | 0.0389 | 0.0241 |
References
- Esteves, B.; Ferreira, H.; Viana, H.; Ferreira, J.; Domingos, I.; Cruz-Lopes, L.; Jones, D.; Nunes, L. Termite Resistance, Chemical and Mechanical Characterization of Paulownia tomentosa Wood before and after Heat Treatment. Forests 2021, 12, 1114. [Google Scholar] [CrossRef]
- Jirouš-Rajković, V.; Miklečić, J. Heat-Treated Wood as a Substrate for Coatings, Weathering of Heat-Treated Wood, and Coating Performance on Heat-Treated Wood. Adv. Mater. Sci. Eng. 2019, 2019, 8621486. [Google Scholar] [CrossRef]
- Jirouš-Rajković, V.; Miklečić, J. Enhancing Weathering Resistance of Wood-A Review. Polymers 2021, 13, 1980. [Google Scholar] [CrossRef]
- Davis, K.; Leavengood, S.; Morrell, J. Effects of Climate on Exterior Wood Coating Performance: A Comparison of Three Industrial Coatings in a Warm-Summer Mediterranean and a Semi-Arid Climate in Oregon, USA. Coatings 2022, 12, 85. [Google Scholar] [CrossRef]
- Söğütlü, C.; Nzokou, P.; Koc, I.; Tutgun, R.; Döngel, N. The effects of surface roughness on varnish adhesion strength of wood materials. J. Coat. Technol. Res. 2016, 13, 863–870. [Google Scholar] [CrossRef]
- Gurleyen, L.; Ayata, U.; Esteves, B.; Gurleyen, T.; Cakicier, N. Effects of Thermal Modification of Oak Wood Upon Selected Properties of Coating Systems. Bioresources 2019, 14, 1838–1849. [Google Scholar] [CrossRef]
- Herrera, R.; Muszyńska, M.; Krystofiak, T.; Labidi, J. Comparative evaluation of different thermally modified wood samples finishing with UV-curable and waterborne coatings. Appl. Surf. Sci. 2015, 357, 1444–1453. [Google Scholar] [CrossRef]
- Hazir, E.; Koc, K.H.; Baray, S.A.; Esnaf, S. Improvement of adhesion strength for wood-based material coating process using design of experiment methodology. Eur. J. Wood Wood Prod. 2020, 78, 301–312. [Google Scholar] [CrossRef]
- Dilik, T.; Erdinler, S.; HazJr, E.; Koç, H.; Hiziroglu, S. Adhesion Strength of Wood Based Composites Coated with Cellulosic and Polyurethane Paints. Adv. Mater. Sci. Eng. 2015, 2015, 745675. [Google Scholar] [CrossRef]
- Moghadamzadeh, H.; Rahimi, H.; Asadollahzadeh, M.; Hemmati, A.R. Surface treatment of wood polymer composites for adhesive bonding. Int. J. Adhes. Adhes. 2011, 31, 816–821. [Google Scholar] [CrossRef]
- Wang, B.Z.; Nong, S.N.; Pan, L.C.; You, G.L.; Li, Z.H.; Sun, J.P.; Shi, S.H. Machine learning-based non-destructive testing model for high precision and stable evaluation of mechanical properties in bamboo-wood composites. Eur. J. Wood Wood Prod. 2024, 82, 621–633. [Google Scholar] [CrossRef]
- Rahimi, S.; Avramidis, S. Predicting moisture content in kiln dried timbers using machine learning. Eur. J. Wood Wood Prod. 2022, 80, 681–692. [Google Scholar] [CrossRef]
- Guan, X.M.; Li, W.F.; Huang, Q.L.; Huang, J.Y. Intelligent color matching model for wood dyeing using Genetic Algorithm and Extreme learning machine. J. Intell. Fuzzy Syst. 2022, 42, 4907–4917. [Google Scholar] [CrossRef]
- Chen, S.; Wang, J.P.; Liu, Y.X.; Chen, Z.J.; Lei, Y.F.; Yan, L. The relationship between color and mechanical properties of heat-treated wood predicted based on support vector machines model. Holzforschung 2023, 76, 994–1002. [Google Scholar] [CrossRef]
- Ergün, H.; Ergün, M.E. Modeling Xanthan Gum Foam’s Material Properties Using Machine Learning Methods. Polymers 2024, 16, 740. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.O.; Dai, Y.W.; Wu, Q.B. A Novel Regularization Paradigm for the Extreme Learning Machine. Neural Process. Lett. 2023, 55, 7009–7033. [Google Scholar] [CrossRef]
- Roy, A.; Chakraborty, S. Support vector machine in structural reliability analysis: A review. Reliab. Eng. Syst. Saf. 2023, 233, 109126. [Google Scholar] [CrossRef]
- Wang, Q.H.; Wang, W.; He, Y.; Li, M. Prediction of Physical and Mechanical Properties of Heat-Treated Wood Based on the Improved Beluga Whale Optimisation Back Propagation (IBWO-BP) Neural Network. Forests 2024, 15, 687. [Google Scholar] [CrossRef]
- Zhang, R.Z.; Zhu, Y.J. Predicting the Mechanical Properties of Heat-Treated Woods Using Optimization-Algorithm-Based BPNN. Forests 2023, 14, 935. [Google Scholar] [CrossRef]
- Chai, H.J.; Chen, X.M.; Cai, Y.C.; Zhao, J.Y. Artificial Neural Network Modeling for Predicting Wood Moisture Content in High Frequency Vacuum Drying Process. Forests 2019, 10, 16. [Google Scholar] [CrossRef]
- Nguyen, T.H.V.; Nguyen, T.T.; Ji, X.D.; Guo, M.H. Predicting Color Change in Wood During Heat Treatment Using an Artificial Neural Network Model. Bioresources 2018, 13, 6250–6264. [Google Scholar] [CrossRef]
- Bao, X.; Ying, J.H.; Cheng, F.; Zhang, J.; Luo, B.; Li, L.; Liu, H.G. Research on neural network model of surface roughness in belt sanding process for Pinus koraiensis. Measurement 2018, 115, 11–18. [Google Scholar] [CrossRef]
- Wang, S.X.; Zhang, N.; Wu, L.; Wang, Y.M. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Li, N.; Wang, W. Prediction of Mechanical Properties of Thermally Modified Wood Based on TSSA-BP Model. Forests 2022, 13, 160. [Google Scholar] [CrossRef]
- Ma, W.; Wang, W.; Cao, Y. Mechanical Properties of Wood Prediction Based on the NAGGWO-BP Neural Network. Forests 2022, 13, 1870. [Google Scholar] [CrossRef]
- Wan, Z.H.; Yang, H.; Xu, J.P.; Mu, H.B.; Qi, D.W. BACNN: Multi-scale feature fusion-based bilinear attention convolutional neural network for wood NIR classification. J. For. Res. 2024, 35, 4. [Google Scholar] [CrossRef]
- Rajwar, K.; Deep, K.; Das, S. An exhaustive review of the metaheuristic algorithms for search and optimization: Taxonomy, applications, and open challenges. Artif. Intell. Rev. 2023, 56, 13187–13257. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.D.; Wang, S.H.; Ji, G.L. A Comprehensive Survey on Particle Swarm Optimization Algorithm and Its Applications. Math. Probl. Eng. 2015, 2015, 931256. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Braik, M.; Hammouri, A.; Atwan, J.; Al-Betar, M.A.A.; Awadallah, M.A. White Shark Optimizer: A novel bio-inspired meta-heuristic algorithm for global optimization problems. Knowl. Based Syst. 2022, 243, 108457. [Google Scholar] [CrossRef]
- Al-Betar, M.A.; Awadallah, M.A.; Braik, M.S.; Makhadmeh, S.; Doush, I.A. Elk herd optimizer: A novel nature-inspired metaheuristic algorithm. Artif. Intell. Rev. 2024, 57, 48. [Google Scholar] [CrossRef]
- Karimi-Mamaghan, M.; Mohammadi, M.; Meyer, P.; Karimi-Mamaghan, A.M.; Talbi, E. Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: A state-of-the-art. Eur. J. Oper. Res. 2022, 296, 393–422. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Abu Doush, I.; Al-Betar, M.A.; Malik, S.B. Chapter 19—Metaheuristics for optimizing weights in neural networks. Compr. Metaheuristics 2023, 2023, 359–377. [Google Scholar] [CrossRef]
- Abu Doush, I.; Awadallah, M.A.; Al-Betar, M.A.; Alomari, O.A.; Makhadmeh, S.N.; Abasi, A.K.; Alyasseri, Z.A.A. Archive-based coronavirus herd immunity algorithm for optimizing weights in neural networks. Neural Comput. Appl. 2023, 35, 15923–15941. [Google Scholar] [CrossRef] [PubMed]
- Al-Betar, M.A.; Awadallah, M.A.; Abu Doush, I.; Alomari, O.A.; Abasi, A.K.; Makhadmeh, S.N.; Alyasseri, Z.A.A. Boosting the training of neural networks through hybrid metaheuristics. Clust. Comput. J. Netw. Softw. Tools Appl. 2023, 26, 1821–1843. [Google Scholar] [CrossRef]
- Li, J.C.; Li, N.; Li, J.Z.; Wang, W.; Wang, H.L. Prediction of Thermally Modified Wood Color Change after Artificial Weathering Based on IPSO-SVM Model. Forests 2023, 14, 948. [Google Scholar] [CrossRef]
- Alabool, H.M.; Alarabiat, D.; Abualigah, L.; Heidari, A.A. Harris hawks optimization: A comprehensive review of recent variants and applications. Neural Comput. Appl. 2021, 33, 8939–8980. [Google Scholar] [CrossRef]
- Ma, N.; Yin, H.X.; Wang, K. Prediction of the Remaining Useful Life of Supercapacitors at Different Temperatures Based on Improved Long Short-Term Memory. Energies 2023, 16, 5240. [Google Scholar] [CrossRef]
- Moayedi, H.; Osouli, A.; Nguyen, H.; Rashid, A.S.A. A novel Harris hawks’ optimization and k-fold cross-validation predicting slope stability. Eng. Comput. 2021, 37, 369–379. [Google Scholar] [CrossRef]
- Zheng, Y.X.; Jin, H.W.; Jiang, C.Y.; Moradi, Z.; Khadimallah, M.A.; Moayedi, H. Analyzing behavior of circular concrete-filled steel tube column using improved fuzzy models. Steel Compos. Struct. 2022, 43, 625–637. [Google Scholar] [CrossRef]
- Fan, Q.; Chen, Z.J.; Xia, Z.H. A novel quasi-reflected Harris hawks optimization algorithm for global optimization problems. Soft Comput. 2020, 24, 14825–14843. [Google Scholar] [CrossRef]
- Zhong, C.T.; Li, G. Comprehensive learning Harris hawks-equilibrium optimization with terminal replacement mechanism for constrained optimization problems. Expert Syst. Wiith Appl. 2022, 192, 116432. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H.L. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Wu, Q. A self-adaptive embedded chaotic particle swarm optimization for parameters selection of Wv-SVM. Expert Syst. Appl. 2011, 38, 184–192. [Google Scholar] [CrossRef]
- Arora, S.; Anand, P. Chaotic grasshopper optimization algorithm for global optimization. Neural Comput. Appl. 2019, 31, 4385–4405. [Google Scholar] [CrossRef]
- Khamsawang, S.; Jiriwibhakorn, S. DSPSO–TSA for economic dispatch problem with nonsmooth and noncontinuous cost functions. Energy Convers. Manag. 2010, 51, 365–375. [Google Scholar] [CrossRef]
- Kaveh, A.; Rahmani, P.; Eslamlou, A.D. An efficient hybrid approach based on Harris Hawks optimization and imperialist competitive algorithm for structural optimization. Eng. Comput. 2022, 38, 1555–1583. [Google Scholar] [CrossRef]
- Li, X.N.; Wu, H.; Yang, Q.; Tan, S.; Xue, P.; Yang, X.H. A multistrategy hybrid adaptive whale optimization algorithm. J. Comput. Des. Eng. 2022, 9, 1952–1973. [Google Scholar] [CrossRef]
- Zabell, S.L. On Student’s 1908 Article “The Probable Error of a Mean”. J. Am. Stat. Assoc. 2008, 103, 1–7. [Google Scholar] [CrossRef]
- Li, J.H.; Lei, Y.S.; Yang, S.H. Mid-long term load forecasting model based on support vector machine optimized by improved sparrow search algorithm. Energy Rep. 2022, 8, 491–497. [Google Scholar] [CrossRef]
- Hazir, E.; Ozcan, T.; Koç, K.H. Prediction of Adhesion Strength Using Extreme Learning Machine and Support Vector Regression Optimized with Genetic Algorithm. Arab. J. Sci. Eng. 2020, 45, 6985–7004. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Chen, Y. Carnivorous Plant Algorithm and BP to Predict Optimum Bonding Strength of Heat-T reated Woods. Forests 2023, 14, 51. [Google Scholar] [CrossRef]







| Algorithm | Parameter | Setting |
|---|---|---|
| GA | 0.8 | |
| 0.05 | ||
| PSO | and | 2 |
| Inertia weight | Linearly decreased from 0.9 to 0.1 | |
| WOA | Gradually Reduced from 2 to 0 | |
| HHO | escape energy factor | Linearly decreased from 1 to −1 |
| IHHO | escape energy factor | Linearly decreased from 1 to −1 |
| The dimension of the Sobol sequence | 64 | |
| Probability of t-distribution perturbation | 0.5 |
| Function | Formula | Dim | Search Range | Best Value |
|---|---|---|---|---|
| F1 | 10/20 | [−100, 100] | 300 | |
| F3 | 10/20 | [−100, 100] | 600 | |
| F7 | 10/20 | [−100, 100] | 2000 | |
| F9 | 10/20 | [−100, 100] | 2300 |
| Function | Dim | Indicator | IHHO | HHO | WOA | PSO | GA |
|---|---|---|---|---|---|---|---|
| F1 | 10 | Best | 300.3694 | 301.6383 | 313.8464 | 311.0403 | 322.0550 |
| Average | 335.9410 | 403.9251 | 431.5243 | 439.9808 | 504.5946 | ||
| STD | 21.3837 | 64.2540 | 78.1941 | 91.7957 | 107.2404 | ||
| 20 | Best | 328.1572 | 652.4272 | 991.6811 | 1829.4519 | 2726.1598 | |
| Average | 1231.8510 | 2657.4552 | 8038.1607 | 8256.8382 | 11,244.2925 | ||
| STD | 1141.5671 | 1313.5080 | 4567.1136 | 5003.6406 | 5699.8139 | ||
| F3 | 10 | Best | 600.0000 | 600.0003 | 600.0009 | 600.0010 | 600.0161 |
| Average | 600.0026 | 600.0078 | 600.0296 | 600.0423 | 600.1232 | ||
| STD | 0.0056 | 0.0105 | 0.0258 | 0.0294 | 0.0699 | ||
| 20 | Best | 600.0001 | 600.0004 | 600.0886 | 600.0955 | 600.3625 | |
| Average | 600.0028 | 600.0307 | 600.3321 | 600.3737 | 600.6267 | ||
| STD | 0.0017 | 0.0177 | 0.1464 | 0.1830 | 0.2012 | ||
| F7 | 10 | Best | 2038.7114 | 2052.2212 | 2059.4569 | 2073.7016 | 2051.6123 |
| Average | 2096.6045 | 2120.9077 | 2192.6254 | 2328.8584 | 2459.1100 | ||
| STD | 39.1627 | 46.1024 | 98.9004 | 174.5463 | 296.0627 | ||
| 20 | Best | 2047.6545 | 2090.5460 | 2894.7576 | 2684.4154 | 2889.1896 | |
| Average | 2153.6233 | 2968.4444 | 3500.9027 | 3985.8512 | 4607.1419 | ||
| STD | 60.3008 | 483.1014 | 407.6184 | 744.7080 | 978.4388 | ||
| F9 | 10 | Best | 2301.1321 | 2327.4268 | 2331.9077 | 2357.1124 | 2340.4099 |
| Average | 2529.3670 | 2667.2676 | 2740.4971 | 2812.9339 | 2754.3577 | ||
| STD | 159.0777 | 171.9700 | 234.9014 | 250.3330 | 285.7676 | ||
| 20 | Best | 2382.9228 | 2499.3693 | 2749.4379 | 2938.4243 | 3029.0854 | |
| Average | 2720.9958 | 2735.8546 | 3016.1995 | 3265.8828 | 3346.1276 | ||
| STD | 178.5477 | 186.5087 | 204.1760 | 207.5216 | 215.7812 |
| Model | MAE/MPa | RMSE/MPa | MAPE/% | R2 |
|---|---|---|---|---|
| BP | 0.1709 | 0.2076 | 2.8811 | 0.7363 |
| GA-BP | 0.1488 | 0.1757 | 2.4852 | 0.8112 |
| PSO-BP | 0.1459 | 0.1691 | 2.4414 | 0.8250 |
| WOA-BP | 0.1370 | 0.1581 | 2.2926 | 0.8470 |
| HHO-BP | 0.1316 | 0.1534 | 2.2123 | 0.8559 |
| IHHO-BP | 0.0643 | 0.0915 | 1.0635 | 0.9488 |
| Model | MAE/MPa | RMSE/MPa | MAPE/% | R2 |
|---|---|---|---|---|
| LR | 0.2791 | 0.3535 | 4.7352 | 0.2548 |
| ELM | 0.2061 | 0.2672 | 3.3059 | 0.5958 |
| SVR | 0.1770 | 0.2047 | 2.7098 | 0.7340 |
| GA-SVR | 0.1439 | 0.1718 | 2.5143 | 0.8117 |
| CPA-BP | 0.1216 | 0.1326 | 2.0442 | 0.8927 |
| IHHO-BP | 0.0643 | 0.0915 | 1.0635 | 0.9488 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Wang, W.; Cao, Y.; Wang, Q.; Li, M. Prediction of Bonding Strength of Heat-Treated Wood Based on an Improved Harris Hawk Algorithm Optimized BP Neural Network Model (IHHO-BP). Forests 2024, 15, 1365. https://doi.org/10.3390/f15081365
He Y, Wang W, Cao Y, Wang Q, Li M. Prediction of Bonding Strength of Heat-Treated Wood Based on an Improved Harris Hawk Algorithm Optimized BP Neural Network Model (IHHO-BP). Forests. 2024; 15(8):1365. https://doi.org/10.3390/f15081365
Chicago/Turabian StyleHe, Yan, Wei Wang, Ying Cao, Qinghai Wang, and Meng Li. 2024. "Prediction of Bonding Strength of Heat-Treated Wood Based on an Improved Harris Hawk Algorithm Optimized BP Neural Network Model (IHHO-BP)" Forests 15, no. 8: 1365. https://doi.org/10.3390/f15081365