Abstract
Trees’ structural defects are responsible for the reduction in forest product quality and the accident of tree collapse under extreme environmental conditions. Although the manual view inspection for assessing tree health condition is reliable, it is inefficient in discriminating, locating, and quantifying the defects with various features (i.e., crack and hole). There is a general need for investigation of efficient ways to assess these defects to enhance the sustainability of trees. In this study, the deep learning algorithms of lightweight You Only Look Once (YOLO) and encoder-decoder network named DeepLabv3+ are combined in unmanned aerial vehicle (UAV) observations to evaluate trees’ structural defects. Experimentally, we found that the state-of-the-art detector YOLOv7-tiny offers real-time (i.e., 50–60 fps) and long-range sensing (i.e., 5 m) of tree defects but has limited capacity to acquire the patterns of defects at the millimeter scale. To address this limitation, we further utilized DeepLabv3+ cascaded with different network architectures of ResNet18, ResNet50, Xception, and MobileNetv2 to obtain the actual morphology of defects through close-range and pixel-wise image semantic segmentation. Moreover, the proposed hybrid scheme YOLOv7-tiny_DeepLabv3+_UAV assesses tree’s defect size with an averaged accuracy of 92.62% (±6%).
1. Introduction
Trees improve the natural environment, enrich the ecosystems, and provide the aesthetic nourishment in urban and forest areas. With age they start to senesce with the onset of decay, breakage, and windthrow sometimes caused by hurricanes, thunderstorms, microorganism decay, or animal activities [1,2]. Certain defects such as cracks and holes are often indicative of this process, which remain in a tree trunk or its branches. The defects of crack and hole reduce a tree’s structural integrity critically due to the preliminary deficiency of wood. Hence, trees’ defects pose a serious safety hazard as well as a risk of damage to public property, which calls for diagnostic techniques capable of rapid and precise assessment of these structural defects.
Among the alternative methods, the electromagnetic tomography techniques such as thermography [3] and ground penetrating radar [4] offer noninvasive imaging of tree defects. However, the collected electromagnetic responses are sometimes contaminated by extra radiation sources, mosses, and moisture [3]. In contrast to electromagnetic tomography, sonic tomography probes stress wave velocity in a cross-sectional trunk for detection of internal tree defects [5]. This technique requires instrumentation of physical-attached wired sensors around a tree trunk. However, the installation, activation, and data post-processing work are time-consuming and labor-intensive. Mounting and wiring of sensors become much more difficult, due to targeting the inaccessible part of a tree or surveying densely overgrown plants. It has also been argued that sonic tomography suffers shortage of image resolution for surface/sub-surface areas, so a union of sonic tomography and acoustic-laser technique has been proposed because the latter can supplement the sub-surface information near the tree bark [6,7]. Be that as it may, the combined method cannot address the detection of surface defects due to the required step of surface preparation. Surface defects are heightened concerns, besides internal tree decay. This is because the external cracks/holes make tree trunk more vulnerable to storms, insects, chemicals, and ultraviolet radiation. The surface defects also cause load eccentricities of a standing trunk, leading to more serious lateral deflection and local fracture. So, researchers are thinking of new vision techniques with specialization in surface defect recognition [8]. The vision-based algorithm can offer additional useful information to the existing physical tomography techniques so that the deficient tree structure can be fully represented.
Computer vision is one of the grand vision-based methods. In this field, convolutional neural networks (CNNs) were earlier applied at multiple locations of an entire image through multiple-scale sliding windows [9]. Shortly after this the region-based CNN (R-CNN) [10], fast R-CNN [11], and then faster R-CNN [12] were established as the object detectors capable of searching region proposals in accelerated procedures. Moreover, recent years have witnessed a groundbreaking object detector called You Only Look Once (YOLO) [13]. YOLO is extremely faster than faster R-CNN, since it applies an end-to-end detection pipeline to predict bounding boxes and their class probabilities in a single evaluation schema. The evolved versions of YOLO detectors, namely the YOLOv2-v7 [14,15,16,17] and some modified network architectures [18,19,20], were established to pursue the best accuracy/speed tradeoff. ResNet50-based YOLOv2 was applied to detect trees in three-dimensional (3D) images through a 360° spherical camera [21]. The detected tree information was then processed by the algorithm of “structure from motion” for measurement of structural attributes (e.g., trunk diameter). Another study reported a YOLO framework used in a UAV platform and claimed an accuracy of 89.3% for identifying dead/unhealthy trees [22]. YOLO features instant defect detection, facilitating the task through an on-the-fly/mobile camera. However, regressing the rectangular bounding boxes by YOLO often encounters a disjunction between the predicted box and the actual morphology of an object. The attributes (width, length, and diameter) of plant surface anomalies cannot be simply and accurately estimated via this model.
Semantic segmentation is another modern field of computer vision, which specializes in pixel labeling given a new or unknown image with different object categories [23]. One of the fundamental semantic segmentation algorithms is based on fractionally-strided convolution (i.e., deconvolution), also known as fully convolutional network (FCN) [24]. The output image via FCN holds the predicted classes for each pixel identical to the spatial position of input image, namely the end-to-end segmentation. However, the deep convolutional network applies many max pooling layers for down-sampling, reducing the low-level feature resolution. This would create challenges in recognizing the tree crack pattern, because the crack may have somewhat similar edges to the surrounding loosened bark. Pseudo predictions of the crack edge can also be induced by other obstructions of shadows and background debris. To enlarge the field of view, DeepLab model was developed with the aid of atrous spatial pyramid pooling (ASPP) [25]. Furthermore, DeepLabv3+ was developed to obtain sharper segmentations by fusing high- and low-level semantic information from the hierarchical convolution scheme (encoder–decoder structure) [26]. Specifically, DeepLabv3+ network structure can be reframed with deep residual models (ResNet series) [27] or depthwise separable convolutions such as Xception [28] and MobileNet [29]. Nonetheless, the semantic segmentation algorithm generally offers low inference speed for processing the image sequency (aerial video). This limits its applications in the real-time vision process.
An unaided eye would be unable to see the multiple tree defects at fast speed and the conventional mobile devices (e.g., handheld smart phone [30], camera mounted on a mobile car [31]) may be restricted in the application of targeting the inaccessible part (e.g., branch) of a tall tree. Also, the conventional video recording methods for tree monitoring are not highly automated. However, these limitations can be addressed by excellent vision-based navigation via UAV. UAV has the merits of being low-cost, high-mobility, and remote-sensing, which has been applied as an airborne platform for classification of tree species [32], recognition of diseased trees [33], and extraction of windthrown trees [34]. Considering the pros and cons of the above computer vision techniques, a hybrid deep learning scheme YOLO-tiny_DeepLabv3+_UAV is recommended in the task of trees’ defect assessment. As a real-time object detector, YOLO serves as an “artificial eye” for remote defect detection [35]. Especially, it is promising to pair UAV with lightweight YOLO (e.g., YOLO-tiny). Despite the limitation of characterizing the defects’ actual morphology, YOLO can provide image coordinates of defects and guide drone navigation closer to the targets. Second, DeepLabv3+ is deployed to cluster the defect-associated pixels for quantitative size analysis. Compared with deep-learning aided stand-off radar scheme for detecting tree defects [36], YOLO-tiny_DeepLabv3+_UAV excels at remote operation, real-time tracking, and high-mobility setup. Our developed methodology also outperforms 3D volumetric imaging by X-ray computed tomography [37] for diagnosis of living trees, considering the factors of efficiency and financial cost. Although applying deep learning methods for tree observations has been conducted before [33,38], experimental work of tree defect assessment based on deep learning is still limited in both scope and depth.
Trees’ defects are complicated, due to their textures being dependent upon the determinants of age, species, climate, and nutrition condition. Therefore, training a robust deep learning model for tree defect assessment should consider the factors of network architecture and training hyperparameter (i.e., epoch). In this study, the lightweight versions of YOLO are suggested, namely YOLO-tiny series (YOLOv2-, YOLOv3-, YOLOv4-, and YOLOv7-tiny). Although these YOLO-tiny models may sacrifice some accuracy of object detection, they should have much faster speed than the corresponding YOLO models and surpass other currently known object detectors. For a precise semantic segmentation, an appropriate backbone (feature extractor) adopted in DeepLabv3+ is crucial. Many recent articles have underlined that ResNet model can serve as a powerful and efficient backbone of DeepLabv3+ architecture to winkle out richer features from the context of an image [39]. ResNet series are learning residual functions designed to alleviate the problem of gradient dispersion and enable deepening of the network of training [27]. Compared to ResNet101 and ResNet152, ResNet50 gains more efficiency in object detection. Additionally, Xception and MobileNetv2 are the mainstream candidates of feature extractors with the concept of depthwise separable convolution [28]. Integrating these depthwise separable convolutions into DeepLabv3+ can effectively reduce the computational parameters for semantic segmentation although the accuracy remains unknown for tree defects. In addition to network architecture, the training hyperparameter of epoch affects the performance metrics of deep learning models. An epoch denotes the time to update the filter parameters for the whole process the algorithm experiences in an entire dataset of training. Usually, an increase of epoch sufficiently minimizes the loss during training but demands longer time to complete the process. This highlights the need for researching this hyperparameter when training YOLO-tiny and DeepLabv3+. Furthermore, the external environmental factor (i.e., illumination at the time of sunset) should be considered in the application. Understanding the effect of darkness on the feasibility of YOLO-tiny_DeepLabv3+_UAV in field tree inspection is of importance.
In the present study, a combination of two advanced deep learning algorithms of YOLO-tiny and DeepLabv3+ is proposed to apply in UAV for trees’ structural defect assessment. The trained YOLO-tiny models are tasked with real-time tree defect detection, while DeepLabv3+ is responsible for image segmentation of defects at pixel-wise scale. A hybrid YOLO-tiny_DeepLabv3+_UAV based system is formed. For the sake of an improved model’s adaptability to different complex scenarios of tree defects, a robust network architecture with fine-tuned training hyperparameter (i.e., epoch) is selected. For defect detection, we compare the lightweight detectors of YOLOv2-, YOLOv3-, YOLOv4-, and YOLOv7-tiny, considering the accuracy/speed performance. For semantic defect segmentation, we reframe and compare ResNet-, Xception-, and MobileNet-based DeepLabv3+ to verify the best backbone that renders higher precision without costing much inference time. To examine the practicality of the combined deep learning algorithms (YOLO-tiny and DeepLabv3+), the dynamic distance change experiment that determines the effective vision range for each model is conducted. The appropriate operational spatial distances for defect detection and for semantic defect segmentation are respectively suggested. The hybrid YOLO-tiny_DeepLabv3+_UAV scheme applied to assess trees’ defect area is evaluated. The “two-stage” procedure used in the hybrid scheme is expected to address the cost issue of traditional methods, reduce the burden on technicians in setting up devices, and accelerate the visual process of trees’ health condition.
2. Methodology
2.1. You Only Look Once (YOLO)
YOLO regards object detection as a regression problem and uses a single neural network to predict bounding boxes with label probabilities from the whole overview of an image [13]. The network splits an input image into S × S grid cells where each center of the cell generates bounding boxes and the related confidence scores. The original version of YOLO has relatively lower precision than other existing models such as VGG-16 version of Faster R-CNN, even though it achieves real-time speed of detection [13]. Many modifications including using anchor boxes, batch normalization, dimension clusters, fine-grained features, etc., have been proposed in the updated version of YOLOv2 and have shown an enhanced accuracy/speed tradeoff [14]. YOLOv3 is another advanced version which adopts Darknet-53 as the CNN feature descriptor [15]. The basic structure of Darknet-53 contains a series of repetitive and stacked blocks (i.e., 1 × 1 bottleneck layer and 3 × 3 convolutional layer at the front of residual layers), extracting more profound features than Darknet-19. Also, Darknet-53 requires fewer floating point operations and 2 × faster speed than ResNet152 [15]. In addition, YOLOv3 uses feature pyramid network (FPN) [40] that fuses feature maps at three different scales, and this strategy improves the predictions of small objects.
Based on YOLOv3, YOLOv4 was released by 2020 and had further improvements to become a state-of-the-art object detector. YOLOv4 utilizes Cross-Stage-Partial Darknet53 (CSP-Darknet53) as the feature extractor, spatial pyramid pooling (SPP) module and path aggregation network (PANet) as the neck, and YOLOv3 head [16]. CSP network separates the feature map of the base layer into two parts passing through residual blocks and concatenates the features [41]. This strategy reduces the repeated gradient flows through the network as well as the inference time and memory usage. SPP applies multiple sizes of receptive field in the process of max pooling, which enables the input of images with arbitrary aspect ratios for training [42]. The framework of PANet includes an FPN structure, a sequential path augmentation by bottom-up and top-down layers, an adaptive feature pooling module, and a fully connected fusion. These processes can fuse the bottom-up features, enriching the semantic information at the high levels and the object localization information at the low levels [43]. Apart from these methods, YOLOv4 uses Mosaic data augmentation algorithm, Mish activation, CIoU loss, etc., for additional improvements. To shorten the extensive parameters of YOLOv4, YOLOv4-tiny with simplified network architecture and fewer parameters is preferred in a mobile vehicle or UAV device. YOLOv4-tiny employs CSPDarknet53-tiny as a backbone for feature extraction and adopts FPN rather than SPP and PANet in the architecture. Besides, YOLOv4-tiny only fuses two-scale predictions, reducing the computational load. Our previous study on the detection of tiled sidewalk cracks clarified that YOLOv4-tiny renders a better accuracy and speed performance than YOLOv3 [20].
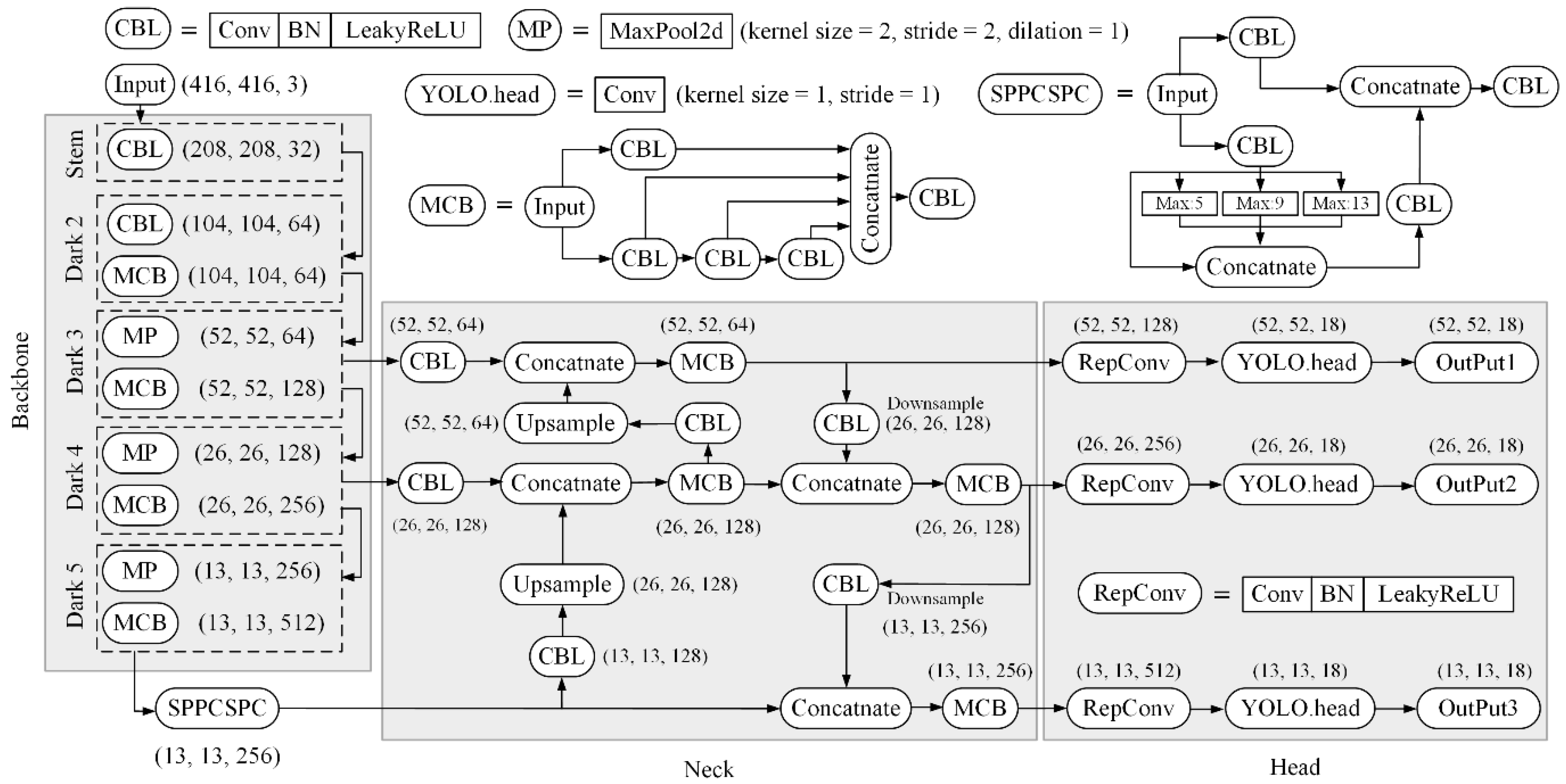
Compared to the currently known object detectors, the latest version YOLOv7 and its simplified and lightweight version YOLOv7-tiny were published in 2023 and claimed to significantly improve the detection accuracy without additional inference cost [17]. As described in Figure 1, YOLOv7-tiny is composed of the backbone for feature extraction, the neck part for feature fusion, and the head with Rep convolution and 1 × 1 convolution for prediction. The backbone in YOLOv7-tiny contains a down-sampling convolution layer followed by Dark series with CBL composite layer, MP module, and multi-contact block (MCB). CBL denotes the Cov (convolution), BN (batch normalization), and LeakyRelu activation. MP module halves both the width and length of feature map by max-pooling operation. MCB refers to an efficient long-range aggregation network that can expand, shuffle, and merge the CBL units so that the gradient path length is controlled and optimized to make the convergence of the network more effective. In this operation, the model accuracy is thereby enhanced. The neck part starts from the SPPCSPC module, namely the SPP module integrated with the CSP network, for an ensemble of richer semantic information. Technically in the SPPCSPC module, the input feature maps separate and pass through the CBL layers and the following max-pooling layers with kernel sizes of 5, 9, and 13, and concatenate together. For one aspect, the multi-branch features are integrated so that the feature information has various scales of receptive field. For another aspect, the consequent feature map is processed by 1 × 1 convolution to keep the size unchanged. In addition, the path aggregation feature pyramid network architecture is adopted for multiscale learning, which fuses the semantic characteristics with skip connections using PANet. The deep-feature map with detailed semantic information goes through the up-sampling flow and fuses with the shallow-feature map to preserve the localization information, and meanwhile the shallow-feature map along the top-down path is combined with the deep-feature map to supplement the details of the features. The use of PANet in YOLOv7-tiny benefits the detection of distant small objects due to the enhanced perceptual field. From the neck section with three paths forward, the head continues to adjust the final number of output channels by three subsequent Rep convolutions. The network structure of YOLOv7-tiny is expected to enhance small object detection in complex scenes.
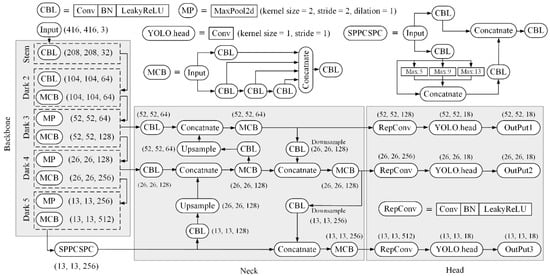
Figure 1.
Network architecture of YOLOv7-tiny.
2.2. DeepLabv3+
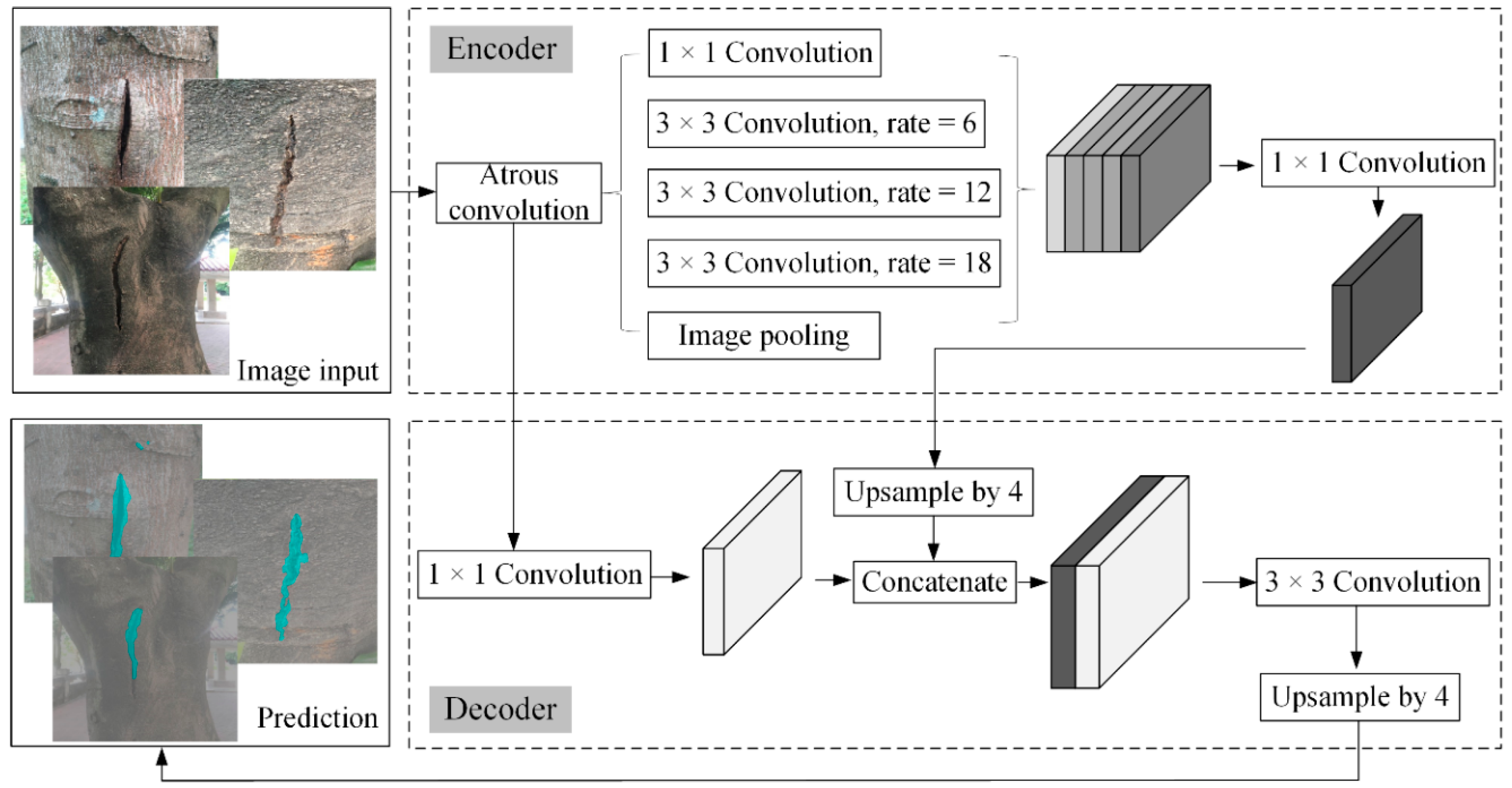
Albeit robustness of object recognition, the YOLO-based rectangular bounding box is found difficult to be matched accurately to the exact shape of the ground-truth object. In this circumstance, regarding the dimensions of this box as the size of the tree’s defect is unreasonable. As a matter of fact, this issue can be addressed by pixel-labeled semantic image segmentation technology. Semantic image segmentation has been successfully solved by fully convolutional neural (FCN) networks. Nevertheless, in a dense prediction task, the FCN networks suffer a problem regarding the spatial resolution reduction of feature maps during the max pooling at consecutive layers. To overcome this problem, some researchers from Google team pointed out DeepLab that utilizes upsampling filters to recover the feature resolution [44]. The model operates the convolution with space inside the filter, namely the atrous convolution, to expand the receptive field without increasing computational parameters. From this perspective, the researchers come up with the method of atrous spatial pyramid pooling (ASPP) which has multiple filters to encode features and to explore image context at different field of views. Furthermore, DeepLab deploys the fully connected conditional random field (CRF) as the post-processing tool to enhance the localization accuracy of object boundaries, because CRF can force labels with similar color and position to cluster in smoothed outcome. Later on, the researchers from Google extended this predecessor and proposed DeepLabv3 that gives more insights on the atrous convolution with cascaded and parallel modules [25]. DeepLabv3+, the next version to DeepLabv3, incorporated the Decoder module with skip linking to some encoder layers for better feature reuse [26]. The encoder–decoder structure not only extracts dense pixel-level features at multiple fields of view but also gains sharper object boundaries by recovering the spatial information. Technically, the workflow of DeepLabv3+ is illustrated in Figure 2. In the encoder module, the input image goes through the ASPP (atrous convolution with different dilation rates of 6, 12, and 18) and image pooling, reducing the feature maps and probing higher semantic information. Then 1 × 1 convolution is applied to the high-level features, resulting in 256 channels. In the decoder process, the high-level features are bilinearly upsampled four times, and then concatenated with the low-level features. So, both the spatial resolution and the fine features are strengthened. The concatenated features are convoluted by 3 × 3 kernels to upgrade the segmentation results and subjected to another upsampling by a factor of 4. Finally, the segmentation results are predicted.
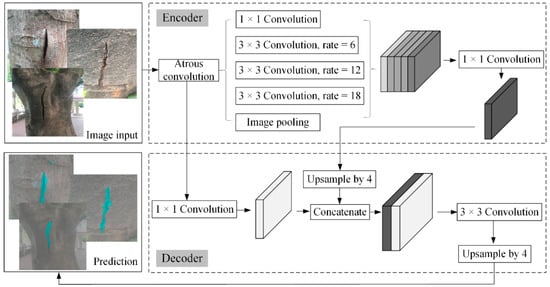
Figure 2.
Overall network architecture of DeepLabv3+ used for trees’ defect segmentation.
2.3. Training and Testing Framework
In this investigation, four lightweight YOLO models of YOLOv2-tiny, YOLOv3-tiny, YOLOv4-tiny, and YOLOv7-tiny were trained to simulate human intelligence for tracking trees’ structural defects. Meanwhile, DeepLabv3+ was trained to perform automatic high-resolution segmentation and geometric representation of the defects. Through a cell phone camera, a total of 1700 full images of trees from different urban cities of Hong Kong, Shenzhen, and Huizhou were gathered and stored as JPG format. These tree images included defects of holes and cracks and a few samples without defects, which were randomly divided into the training and testing datasets, as listed in Table 1. Since the original images with the high resolution of 3024 × 4032 were difficult to be input into the network for training, they were preprocessed and resized into 416 × 416. Hand labelling work was then conducted by the drawing of ground truth bounding boxes that truly represented the class and the position of the tree defects. As an effective way to enhance the robustness of deep learning algorithms for object detection, data augmentation was implemented in this study to expand the dataset of label-preserving images. In training YOLOv2-v4-tiny, the data augmentation was realized by random left–right flipping and change of the intensity of RGB channels. Thus, the tree defect identity remained invariant in the training dataset. Regarding YOLOv7-tiny, the process was carried out by mosaic technology which divided the original images into multiple small pieces and stitched them to form a new image with enriched position, shape, and scale. The mosaic data augmentation is considered to enhance the generalization performance of YOLOv7-tiny since real visual changes in complex scenes are involved. Afterwards, the images were input into the networks of the above YOLO-tiny models. As to the setting of training parameters, the initial learning rate was 0.001, the mini-batch size was 20, and the threshold was 0.5. More specially, the models of YOLOv2-tiny, YOLOv3-tiny, and YOLOv4-tiny were trained with varying epochs from 10 to 100. According to the current loss function convergence data and the reported investigation [45,46], YOLOv7 starts to stabilize after 100 epochs of training. Therefore, YOLOv7-tiny was trained with more epochs up to 300 in this experiment. In the process of training, the loss could be decreased by orders of magnitude after thousands of iteration times. The trained YOLO-tiny detectors were then used to test the tree images to identify tree holes as well as cracks, producing bounding boxes with the corresponding confidence scores.

Table 1.
Number of images allocated for training and testing of YOLO-tiny and DeepLabv3+.
Experimentally, we evaluated the effectiveness of all YOLO-tiny detectors in tree defect detection using quantitative measures of accuracy, precision, recall, and F1 score. As expressed in Equation (1), the accuracy is the evaluation metric that refers to the number of true predictions out of the total predictions. More specifically, it is defined by four metrics of TP (true positive, namely the number of correct detections of defect samples), TN (true negative, namely the number of non-defect images and the model has no prediction), FP (false positive, namely the number of incorrect predictions), and FN (false negative, namely the number of missed predictions). The precision, recall and their weighted harmonic mean F1 score are expressed by Equations (2)–(4). To validate the reproducibility of YOLO, each detector was trained three times, and the performance metrics were averaged.
As mentioned previously, the task of tree defect segmentation is challenging because the tree surface always contains a complexity of patterns, and the cracks/holes are not easily discriminated from the loose bark. An appropriate backbone adopted in DeepLabv3+ is crucial to encode the context information of tree defects in the images. The speed of segmentation is also greatly relevant to the selection of the feature extractor. Hence, in this study we structured and experimented DeepLabv3+ with different feature extractors: (a) ResNet18-based DeepLabv3+, (b) ResNet50-based DeepLabv3+, (c) Xception-based DeepLabv3+, and (d) MobileNetv2-based DeepLabv3+. The training and testing of DeepLabv3+ were conducted using the consistent image dataset as listed in Table 1. We cropped the input images to 416 × 416 and manually annotated the defects of holes and cracks into masks. The annotation was conducted by dragging the mouse along the edge of a target on the computer screen, which produced a mask corresponding to the ground truth. The training dataset that fused the mask with the original image was fed into the DeepLabv3+ network. The hyperparameters of initial learning rate and mini-batch size were set as 0.001 and 20, respectively. In addition, the tunable epoch ranging from 10 to 100 was researched and the optimal value was thought to be determined. During the testing progress, the new image slices were down sampled to 416 × 416. Manual annotation was also applied on the test images to create the ground truths to evaluate the network’s segmentation. The trained DeepLabv3+ network outputs the binary map showing the location and shape of the tree defects at the pixel-level scale. The performance of DeepLabv3+ was evaluated by the mean intersection over union (IoU) metric, a general standard for quantitatively assessing the accuracy of semantic segmentation, as described in Figure 3a and Equation (5):
where TP0, FP0, and FN0 refer to the true positives, false positives, and false negatives of pixels for a class. The mIoU defines the average level of the segmentation accuracy over the amount of testing images n, that is, Equation (6):
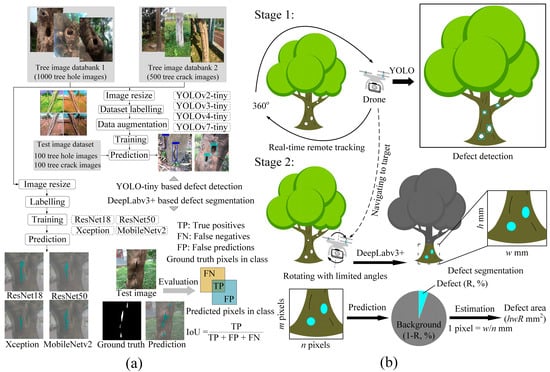
Figure 3.
Scheme of YOLO-tiny_DeepLabv3+_UAV: (a) training and testing workflow and (b) “two-stage” approach for trees’ defect assessment.
A higher mIoU indicates a higher similarity between the predicted pixels and the actual pixels, and thus a better performance of segmentation. In this investigation, the results of mIoU for ResNet18-, ResNet50-, Xception-, and MobileNetv2-based DeepLabv3+ models were compared. All our experiments were carried out on Nvidia GeForce GTX 2080 Super Max-Q (Manufacturer: NVIDIA, Santa Clara, CA, USA) with an 8 GB memory.
2.4. Hybrid YOLO-tiny_DeepLabv3+_UAV System
According to the merits and limitations of deep learning algorithms, we assumed that the two deep learning algorithms are combined into the UAV operation and conceived a two-stage approach that offers new opportunities in the application of assessing the tree defects in a full-field, quantitative, and convenient manner. The scheme of YOLO-tiny_DeepLabv3+_UAV consists of YOLO-tiny and DeepLabv3+ applied to an aerial video. Technically, the former algorithm is applied to detect the presence of tree defects through the video frames collected by a drone. The latter is used to segment the tree defects and predict the number of classified pixels. Overall, the lightweight configuration, high mobility, and flexible adjusting trace of UAV are fascinating in its use in managing forest trees, compared to other traditional mobile devices. For monitoring the tree populations in a forest area, the route of UAV can take place in orthogonal paths to capture images of different trees and streamline the tracking of any tree with defect. When an unhealthy tree is found, the route planning of the UAV goes to the layout of the scheme as shown in Figure 3b. The drone flies with an appropriate orbital radius (i.e., drone-to-target distance) that provides a 360° view of the targeted tree for tracking its anomalies (i.e., hole or crack defect). Hence, a complete mapping of the surface condition of an individual tree can be achieved by the rotation of scanning. In this research, the “remote track” is considered as the case of a drone orbiting at approximately 3 to 5 m away from the tree’s surface. When a defect is detected and its associated coordinate information is predicted, the second stage follows. The drone navigates closer to the surface of the trunk and captures the images with limited rotating angles. This procedure ensures that the aerial video with high spatial resolution is obtained and the frame opposite to the defect for further visual process is selected. In this stage, the recommended drone-to-target distance for DeepLabv3+ based image segmentation is suggested from the dynamic distance change experiment in the present work. Once the binary segmentation is completed, we further design the DeepLabv3+ network to estimate the ratio R (%) of pixels belonging to the defect over the whole image resolution (equal to h × w mm) of the camera. Along this way, the quantitative calculation of defect is acquired to be hwR (mm2) after calibrating the size of each pixel at the engineering scale. During the operation, the drone returns the real-time data of high-definition images to the on-ground station (CUDA® MEX and NVIDIA® GPU).
3. Results and Discussion
3.1. Performance of YOLO-Based Tree Defect Detection
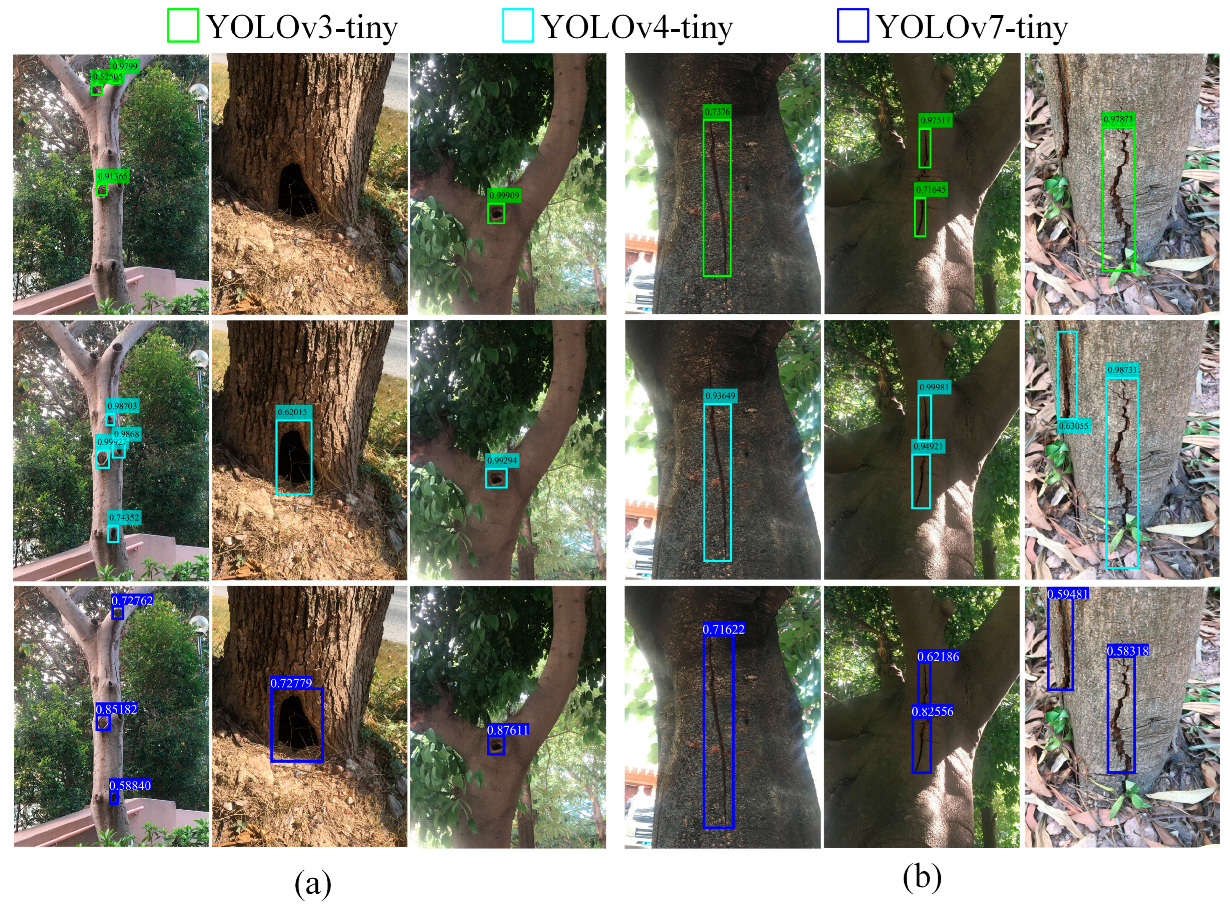
The trained YOLO-tiny detectors are used to detect the trees’ defects (hole and crack). From the illustrated testing results in Figure 4, YOLO-tiny creates a rectangular bounding box with a confidence score for each defect. The box represents the coordinate information and the dimension of the targeted object, and the confidence score reflects how confident the model is in predicting the objectiveness within the bounding box and how accurate the box is regressed. The array of bounding boxes also gives an indication of the number of multiple tree defects in the image, as the model outputs one confidence score per box. The bounding box can roughly imply the size of tree defects but is not precise enough to characterize their patterns. In general, there is a pronounced difference between the rectangular box and the real morphology of the tree defect.

Figure 4.
Tree defect detection by YOLO-tiny models: (a) tree hole and (b) tree crack.
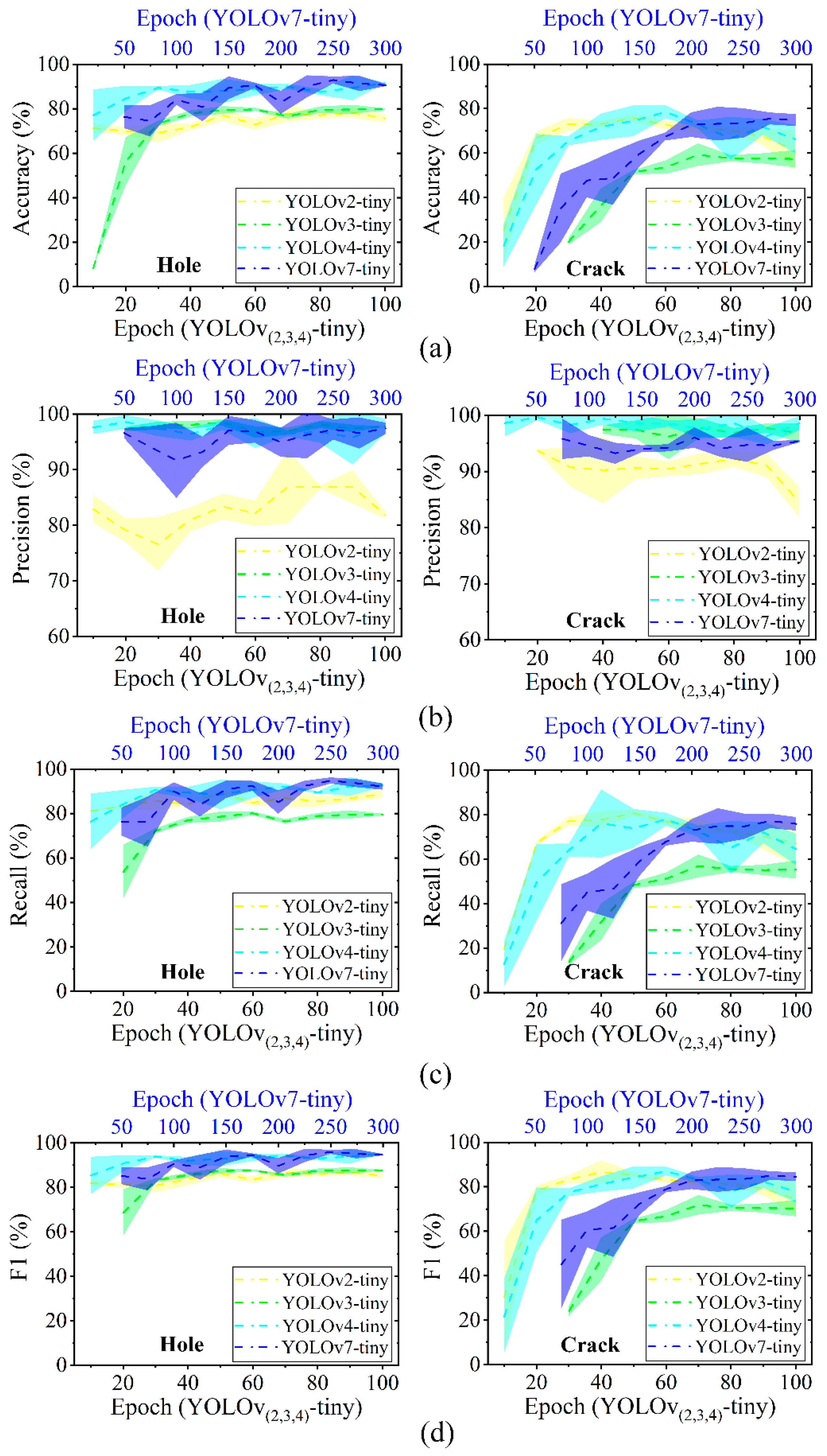
Apart from these qualitative observations, the performance metrics for different detectors of YOLOv2-tiny, YOLOv3-tiny, YOLOv4-tiny, and YOLOv7-tiny are evaluated to understand the models’ overall testing behavior in tree defect detection. In Figure 5a, the dotted line stands for the averaged accuracy and the data band represents the interval of error. The accuracy of all detectors experiences an early boost followed by a relatively stable convergence with the increase in the number of epochs. According to the accuracy–epoch curves, YOLOv2-v4-tiny should be trained at least 60 epochs to reach a plateau for a strong identification capacity. Compared to these models, YOLOv7-tiny offers higher accuracy of 92.97% for detecting a tree hole, as depicted in Figure 5a. The superior ability of this model is also confirmed by other evaluation metrics of precision, recall, and F1 score, as presented in Figure 5b–d. YOLOv2-tiny has the relatively good accuracy but showcases very poor precision, indicating that this model would generate a great number of false positive predictions. The false positive results are thought to be diminished in UAV based remote sensing because this type of prediction can suggest a wrong decision for route planning of a flying drone.
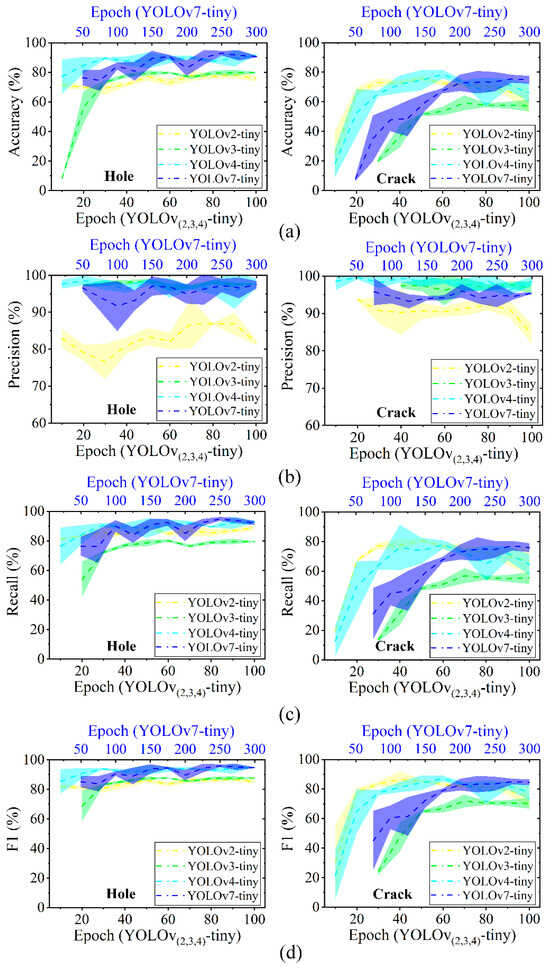
Figure 5.
Performance metrics of detecting tree hole and crack by YOLO-tiny: (a) accuracy, (b) precision, (c) recall, and (d) F1 score. A specific color is assigned to each YOLO-tiny model (i.e., light yellow for YOLOv2-tiny, light green for YOLOv3-tiny, light blue for YOLOv4-tiny, and dark blue for YOLOv7-tiny). The dotted line refers to the averaged value, within its colored band (i.e., error interval).
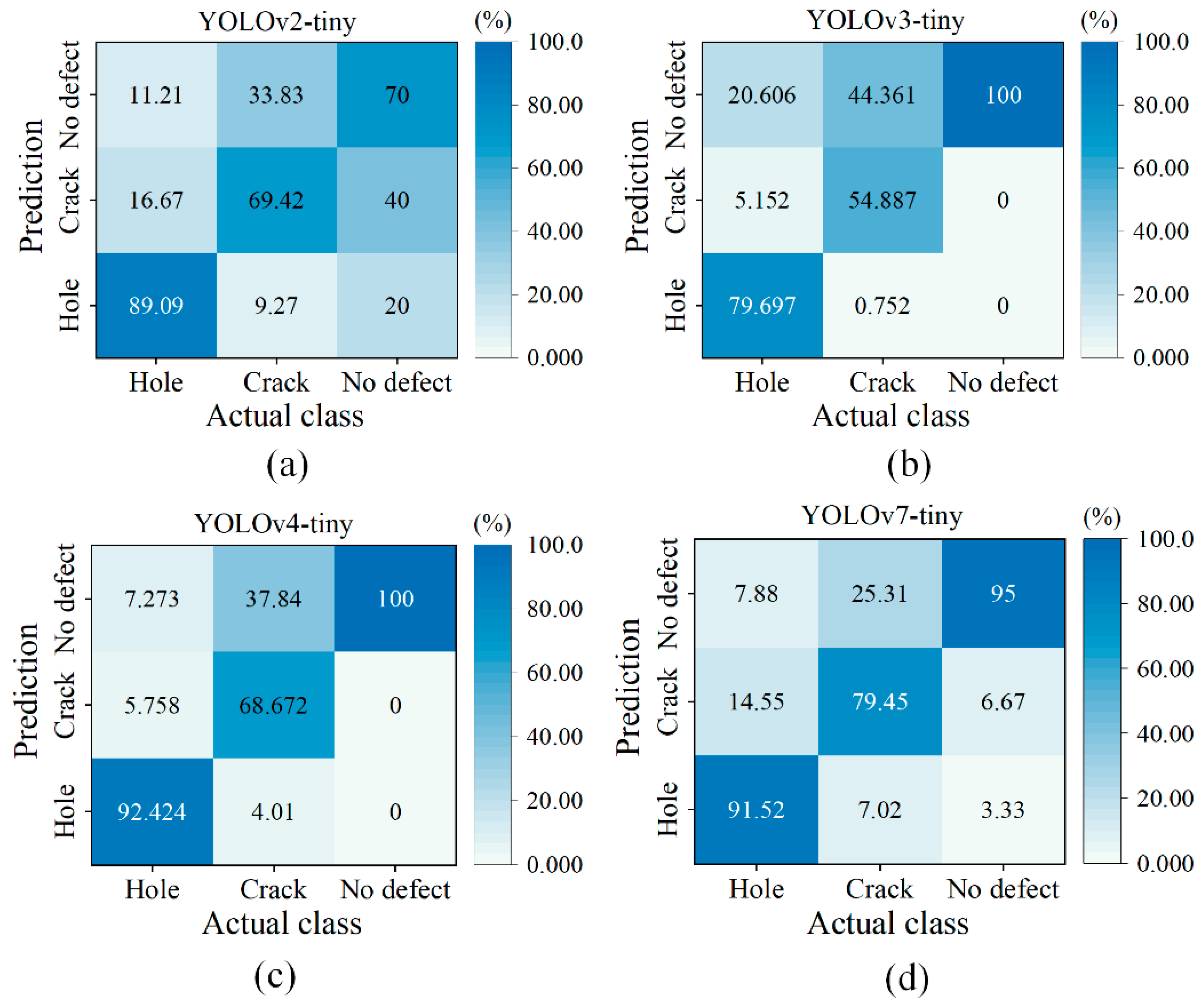
All YOLO-tiny models show relatively poor results of detecting tree crack. As exhibited in Figure 5a, YOLOv4-tiny and YOLOv7-tiny only provide accuracies of 78.52% and 75.54% for tree crack detection, respectively. This is attributed to the complicated natural phenomenon of tree crack morphology that is always influenced by tree species, surface roughness, etc. To further examine whether the category of tree defect is more easily confused in the network, the confusion matrix between the provided actual class and the predicted results is analyzed and displayed in Figure 6. In the list of data classes, the actual tree holes are likely to be identified as tree cracks, and vice versa. In some cases, the overall shape of tree hole with a large aspect ratio appears like tree crack. YOLOv3-, YOLOv4-, and YOLOv7-tiny have better ability to differentiate the classes between tree hole and crack. Nevertheless, over 25% of tree cracks are mistakenly recognized as “non-defect” categories for all YOLO-tiny models. To reduce the misidentification rate, an increase in the training dataset of tree cracks is suggested so that YOLO experiences more iterations in the training cycle. Upgrading the factor of data augmentation is also recommended to artificially enrich the training dataset relevant to the tree cracks.
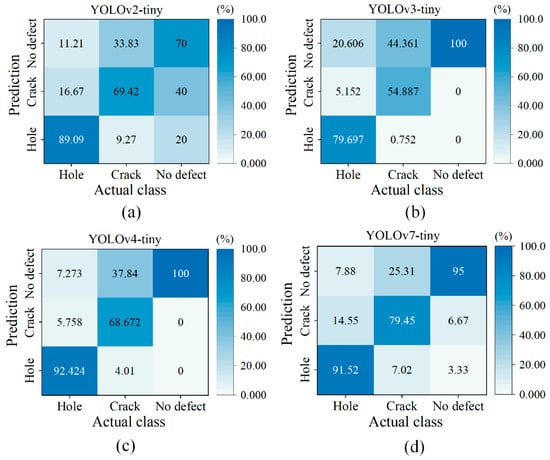
Figure 6.
Confusion matrix of data classes between tree hole and tree crack: (a) YOLOv2-tiny, (b) YOLOv3-tiny, (c) YOLOv4-tiny, and (d) YOLOv7-tiny. The percentage denotes the ratio of the number of predicted objects to the number of original samples.
3.2. DeepLabv3+ Based Tree Defect Segmentation
DeepLabv3+ is trained to perform semantic segmentation and capture the geometrical information of tree defects with various patterns of hole and crack. Different base networks of ResNet18, ResNet50, Xception, and MobileNetv2 are used to construct the network architecture of DeepLabv3+. The performance of semantic segmentation on a subset of our collected testing dataset (Table 1) is evaluated. The models divide the test image into the parts of background (covered by light grey mask) and foreground (covered by light blue mask). Obviously in Figure 7, DeepLabv3+ predicts the pixels belonging to different types of defects. For example, the pixels more in line with the crack pattern are assigned to a class label of tree crack. Among the models, ResNet18-, Xception-, and MobileNetv2-based DeepLabv3+ seem to produce more fracture and discontinuity between the predicted mask and the actual defect. Although introducing the Xception- or MobileNetv2-based backbone network can lessen the model calculation parameters for an increased inference speed, we can find plenty of incorrect segmentation results. In contrast, ResNet50-based DeepLabv3+ generates smoother and more continuous masks and makes high-precision match to the exact outline of the defects. Qualitatively, ResNet50 outperforms Xception and MobileNetv2 in the efficacy of tree defect segmentation.

Figure 7.
Segmentation of tree hole and tree crack by DeepLabv3+ models. The segmented images consist of the foreground of defect and the background. The defect is masked by the light blue color, while the background is represented by the light grey color with transparency.
In this study, the effect of the internal training parameter of the epoch on the semantic segmentation of tree defects is also investigated. Figure 8 demonstrates the segmentation results for tree hole and crack from ResNet50-based DeepLabv3+ with varying number of epochs of 10, 50, and 100. It can be seen from the figure that training ResNet50-based DeepLabv3+ by 10 epochs does not yield a satisfactory foreground as the true defect. When the epoch is increased, it is found that the model turns out a refined mask along the target boundary. Hence, tuning an appropriate epoch is important in the case of using this computer vision technique to quantify the size of tree defect.

Figure 8.
Effect of epoch on the tree defect segmentation by ResNet50-based DeepLabv3+.
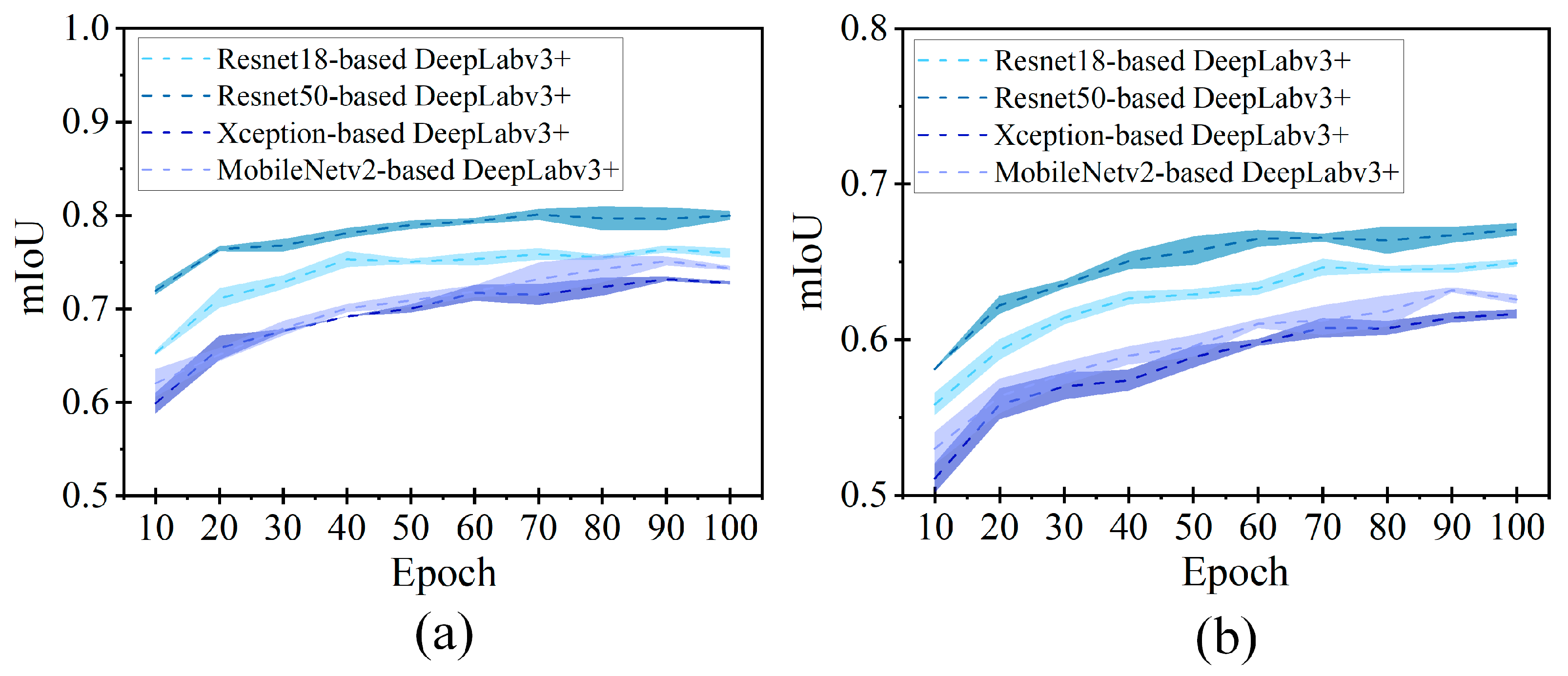
To illustrate this parameter, we plot the mIoU with the increasing epochs from 10 to 100 in Figure 9. The dot line indicates the averaged mIoU, while the error band is shown to indicate the degree of deviation. By observing the graphs, most of the DeepLabv3+ models present the mIoU in the range of 0.5 and 0.8. Increasing the epoch can effectively lead to an upsurge of mIoU. Herein, we recorded the maximum values of mIoU for different DeepLabv3+ models from the figures and listed them in Table 2. For a total of 100 epochs, ResNet50-based DeepLabv3+ offers the highest precision, achieving the mIoU of 0.8 for tree hole and 0.67 for tree crack. The defect segmentation results favor ResNet network over other models of Xception and MobileNetv2 as the feature extractor in DeepLabv3+. The superiority of ResNet50 compared to other backbone networks for extracting enriched feature representations was also proved by the researchers who detected the wheat impurity rate [47].
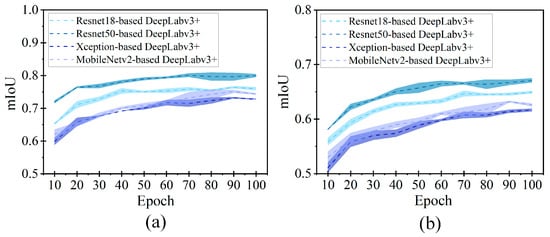
Figure 9.
mIoU versus epoch in the semantic segmentation of tree defects by DeepLabv3+: (a) tree hole and (b) tree crack. A specific color is assigned to each DeepLabv3+ model (i.e., light blue for ResNet18-based DeepLabv3+, dark blue for ResNet50-based DeepLabv3+, light purple for MobileNetv2-based DeepLabv3+, and dark purple for Xception-based DeepLabv3+). The dotted line means the averaged mIOU, within its colored band (i.e., error interval).
Table 2.
mIoU for segmentation of tree defects by different DeepLabv3+ models.
3.3. Environmental Uncertainty
The use of deep learning algorithms in the UAV exploration and object inspection tasks should consider the environmental uncertainties that may cause low visibility of the features in the recorded video frames [48,49]. The semantic information in an image can be significantly varied by the environmental light condition such as darkness. In the present investigation, we collected the photos of tree hole at normal and evening time, selected a subset of test images under three different levels of darkness, and then examined the adaptability of the YOLOv7-tiny and DeepLabv3+ models. As displayed in Figure 10, YOLOv7-tiny identifies the presence and location of tree hole correctly and its performance of defect detection does not seem to be influenced under lower illumination. The robustness of YOLOv7-tiny manifests its feasibility not only to lengthen the daily period of tree inspection but also to assist in the infrared technique for night test. However, the performance of the DeepLabv3+ model declines significantly in the dark condition, which is reflected by the predicted mask and the tested mIOU values. Compared to ResNet18-, Xception-, and MobileNetv2-based DeepLabv3+, ResNet50-based DeepLabv3+ has better adaptability to this environmental uncertainty. To remedy the darkness-induced faults, this article lists as follows a few possible practical solutions: (a) an increase of training dataset; (b) an advanced data augmentation technique; (c) an increase of epoch in the training process; and (d) an enhanced image feature with the aid of infrared tomography.

Figure 10.
Effect of environmental darkness on the performance of tree defect detection by YOLO-tiny and DeepLabv3+: (a) YOLOv7-tiny, (b) ResNet18-based DeepLabv3+, (c) ResNet50-based DeepLabv3+, (d) Xception-based DeepLabv3+, and (e) MobileNetv2-based DeepLabv3+.
3.4. YOLO-tiny_ DeepLabv3+_UAV System for Tree Defect Evaluation
YOLO-tiny excels at real-time speed and remote sensing. However, YOLO-tiny produces disjunction between the rectangular box and the real morphology of a tree defect, generally causing the mistakes of pattern recognition and wrong estimation of defect size. Compared to YOLO-tiny, DeepLabv3+ has the disadvantages of slow inference speed and limited sensing distance but this algorithm can perform pixel-labeled semantic image segmentation. It is therefore of great significance to combine these two deep learning methods for assessment of dense trees in urban areas, owing to their complementary advantages in visual understanding. The combined algorithms are then applied to UAV imaging to construct the YOLO-tiny_DeepLabv3+_UAV system, aiming to simulate the human intelligence that can automatedly discover the foreground in the image according to the type of defect it belongs to (e.g., hole and crack), characterize the object’s shape, and further measure the size of defects. To testify this system, we carried out a dynamic distance change experiment. The distance between the tree’s object and the UAV camera varied from 0.5 to 5 m. It is interesting to observe from Figure 11 that the capacity of detecting the tree hole by YOLOv4-tiny and YOLOv7-tiny does not apparently decline over distance. YOLO-tiny has the robustness to detect the small hole of a tree even when the distance reaches 5 m. In actuality, it is exceedingly difficult for the naked eye to perceive a small object at remote distance [50]. Compared to the detection of tree hole, the ability of detecting the tree crack depends much more on the working distance. YOLO-tiny fails to classify the object when the drone is flown 1 m away from the field. From a remote UAV imaging, the tree crack appears to have narrower spatial resolution and the features become vague. Regarding the DeepLabv3+ algorithm, the increasing distance (>0.5 m) seriously lowers the performance of image segmentation either for tree hole or for tree crack. DeepLabv3+ is not suited as an individual model to be applied for remote sensing via UAV, which necessitates the integration with YOLO for enhanced performance of tree defect assessment. Based on this observation, we suggest suitable target-to-drone distances in YOLO-tiny_DeepLabv3+_UAV operation: (a) remote distance of 0.5–5 m for detection of tree hole and 0.5–1 m for detection of tree crack using YOLO-tiny and (b) close-range distance of 0.5–2 m for segmentation of tree hole and around 0.5 m for segmentation of tree crack using DeepLabv3+.

Figure 11.
Tree defect detection in a dynamic distance change experiment. YOLO-tiny successfully detects the presence of tree hole in varying distance from 0.5 to 5 m and tree crack from 0.5 to 1 m. DeepLabv3+ is effective to segment tree hole at the drone-to-target of 0.5–2 m and tree crack at around 0.5 m.
The inference time of the deep learning algorithms in the tasks of object detection and semantic segmentation affects the efficiency of tree health assessment in the UAV platform. On the basis of the computer with NVIDIA GeForce RTX 2080 Super Max-Q (8GB), the elapsed time of processing aerial video frames under YOLO models (i.e., YOLOv2-, YOLOv3-, YOLOv4-, and YOLOv7-tiny) and DeepLab models (i.e., ResNet18-, ResNet50-, Xception-, and MobileNetv2-based DeepLabv3+) was recorded. The frame rates were then determined and are listed in Table 3. The speed indicates that all YOLO-tiny detectors achieve real-time processing of video as they can reach over 30 frames per second (fps). YOLOv2-tiny ranks as the fastest model for detecting both tree hole and tree crack, due to the relatively simple architecture of the network. YOLOv7-tiny also shows a high speed of 54.03 fps for tree hole and 58.18 fps for tree crack. Compared to YOLO-tiny, DeepLabv3+ offers a much lower speed in the range of 3.12–5.58 fps for processing the image sequency. The algorithm fails to reach the real-time inference speed for segmentation. Among these models, Xception- or MobileNetv2-based DeepLabv3+ gains faster tree defect segmentation. However, this improvement is not significant and these two DeepLabv3+ models make more erroneous predictions. By considering the accuracy/speed tradeoff, we suggest the use of YOLOv7-tiny and ResNet50-based DeepLabv3+ in aerial video for imaging of tree defects.
Table 3.
Speed of YOLO and DeepLabv3+ for processing the video frames of tree defects (unit: fps).
The present study demonstrated the use of YOLOv7-tiny_DeepLabv3+_UAV system in the measurement of tree hole size in the real scene (Jinshan Lake Park, Huizhou, China). The tree planting density in this testing area was 18 trees out of 625 m2, i.e., estimating to be 288 trees/ha. To inspect more dense trees, the proposed scheme is preferred over the traditional vehicle car and handheld smart phone, owing to its flexibility of adjusting flight angle and altitude. However, some issues should be noted. Before the test, our investigations suggested UAV to fly at an altitude ≥ 0.5 m to avoid air turbulence or hitting other plants like bushes on the ground. It is also worth noting that setting the altitude of the drone flight for scanning a tree trunk is dependent on the drone-to-target distance and the scan cover of the drone’s camera. To recognize this relationship, we calibrated the scan cover of the camera at different drone-to-target distances. According to the specifications of the drone in Table 4, a suitable drone-to-target distance and a flying altitude can be suggested for a specific height of tree trunk under inspection. For long-range sensing of tree defects, UAV has a larger view of field and thus a small change in altitude may have little influence on detection. However, for close-range segmentation, the UAV is located at the drone-to-target distance of 0.5 m. In this circumstance, the scanned texture information could be affected by varying altitudes during the drone flight. Averaging the results of tree defect size from the continuous shooting mode of the camera may be useful to enhance the adaptability of this methodology.
Table 4.
Specifications of drone used in YOLOv7-tiny_DeepLabv3+_UAV for tree defect assessment.
In this field test, the flying altitude of the drone was set at around 0.82 m. When the drone navigates, YOLOv7-tiny was used to identify the defect in aerial videos after resizing, as described in Figure 12a,b. A video clip as a supplementary material to show the real-time and remote sensing of the tree defects by YOLOv7-tiny is available for this work (please refer to Supplementary Materials: Video S1: Video sample_YOLOv7tiny). After spotting the tree hole, the drone position was adjusted and controlled at a distance 1.5 m away from the trunk. At this close-range sensing, the scan area of the drone’s camera is 710 mm × 1340 mm, as listed in Table 4. Then, the DeepLabv3+ models were superimposed to segment the tree hole prior to defect quantification.
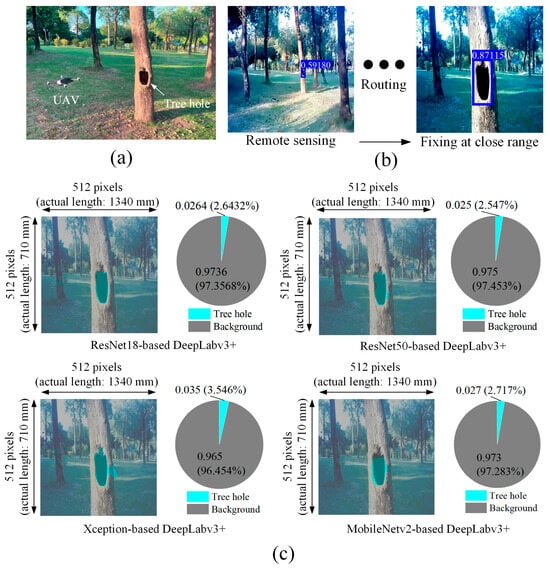
Figure 12.
Practical application of tree defect characterization by YOLOv7-tiny_DeepLabv3+_UAV system: (a) photograph of flying quadcopter drone over the study area, (b) remote sensing of tree defect by YOLOv7-tiny, and (c) close-range assessment of tree defect by DeepLabv3+.
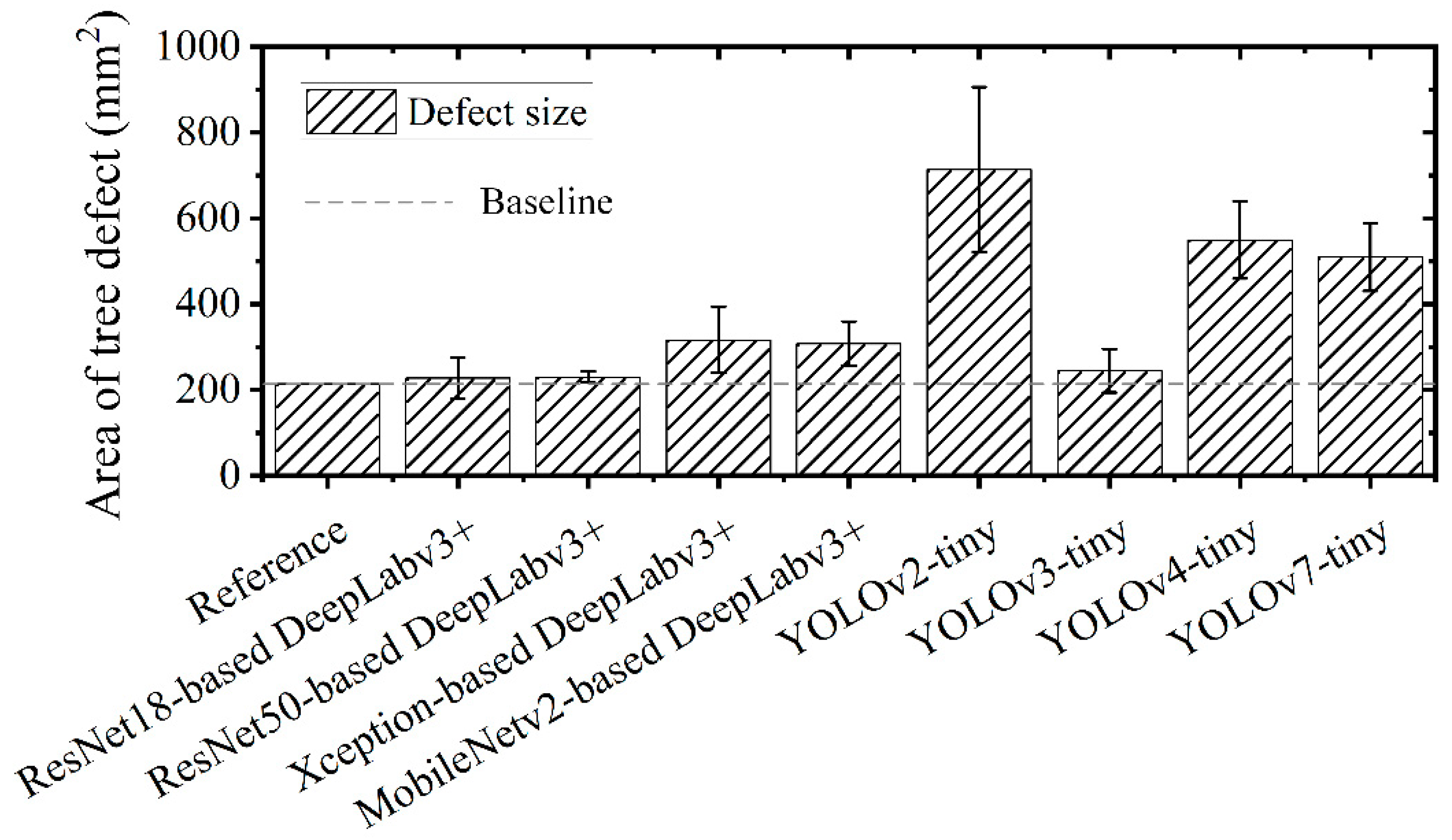
To validate that DeepLabv3+ is more suited for the close-range characterization of the real morphology of tree defects, we compared the pattern recognition between YOLO-tiny and DeepLabv3+. The results in Figure 13 demonstrate the merits and superiority of pixel-level semantic segmentation for the characterization. Figure 12c shows the segmented appearance of a tree hole and its predicted ratio from DeepLabv3+ with ResNet18, ResNet50, Xception, or MobileNetv2. Accordingly, the defect sizes estimated by these four DeepLabv3+ algorithms are then displayed and compared to those predicted results from YOLO-tiny detectors, as shown in Figure 14 and Table 5. In addition, we manually measured the size by a ruler and made it the reference data for validation. The tree hole is deemed as a symmetric ellipse and its area is determined by the major and the minor diameters. From the in-situ field measurement results, it was found that most YOLO-tiny models have large errors of tree size estimation. In contrast, DeepLabv3+ performs much better and ResNet50-based DeepLabv3+ offers the highest accuracy of 92.62% (± 6%) for estimating tree defect size. This further confirms the reliability of DeepLabv3+ applied to defect quantification.

Figure 13.
Comparison of pattern recognition of a tree’s defect by YOLO-tiny and DeepLabv3+.
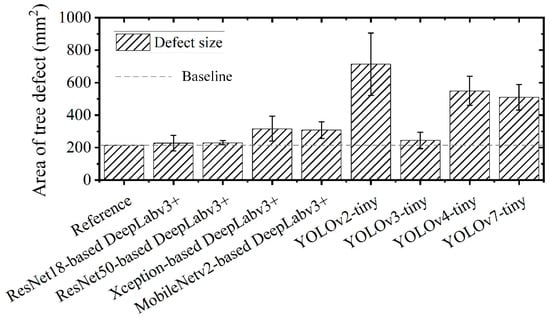
Figure 14.
Comparison of defect quantification by different deep learning models.
Table 5.
Size estimation of defect in trees by YOLO-tiny_DeepLabv3+_UAV system.
3.5. Future Research Directions
The present research investigated the performance of tree defect assessment by two deep learning models of YOLO-tiny and DeepLabv3+ and proposes their combined use in UAV operations. The results suggest a “two-stage” approach for the hybrid scheme which utilizes the YOLO-tiny model for long-range sensing of tree defects and the DeepLabv3+ model for close-range quantification of the defect size. However, UAV on-board flight control is manually taken in the present work; in other words, the hybrid YOLOv7-tiny_DeepLabv3+_UAV system is not fully automated in the application. Future research should consider the autonomous driving of UAV through CNN based route planning. Attention mechanism models are also desired to be integrated in YOLO to upgrade the image coordinates of the defect’s location [51], which can promote smart drone navigation.
Another issue is about the image dataset of tree crack. Although YOLO-tiny and DeepLabv3+ achieve good accuracy in predicting the type of tree hole, both algorithms have relatively poor performance of tree crack assessment. This phenomenon is partly attributed to the insufficient training image dataset. Future training work for crack detection should be enhanced by boosting the imagery dataset available from different urban cities, plant fields, and forest areas. Alternatively, using multiple data augmentation (e.g., brightness enhancement and reduction, adding Gaussian noise, etc.) [52] on the training image dataset to enhance the generalization of network architecture is highly recommended.
Apart from the present hybrid deep learning algorithm, a unified technology composed of YOLOv7-tiny_DeepLabv3+_UAV, acoustic-laser technique [53,54,55,56], and sonic tomography is anticipated [6]. The integration aims to establish the 3D visual structure of surface, sub-surface and internal core defects in trees, as inspired by the latest review from the perspective of artificial-intelligence-led Industry 4.0 [57]. Specifically, the YOLOv7-tiny_DeepLabv3+_UAV modulus acquires the pixel-labeled morphology of tree surface decay and transforms it into slices of classified pixels at the cross-sectional plane. The predicted information is expected to be coupled with the interior contour plot produced by acoustic-laser technique and sonic tomography. The obtained pixels categorized from these three techniques can be fused together, generating a full-scale and high-resolution map of deterioration distribution in trees.
4. Conclusions
The present study, for the first time, proposes the combined use of deep learning algorithms of YOLO-tiny and DeepLabv3+ for assessing the categories, locations, patterns, and areas of tree defects. A prototype of YOLO-tiny_DeepLabv3+_UAV system operated through “two-stage” procedures is proposed, which involves the YOLO-tiny detectors trained to perform long-range defect detection and the DeepLabv3+ models for close-range pixel-wise semantic image segmentation of defects in UAV imaging. According to the present investigation, YOLOv7-tiny outperforms all other YOLO-tiny models and is recommended to be applied in real-time and remote sensing of tree defects. The encoder–decoder network of ResNet50-based DeepLabv3+ performs better segmentation of tree defects and has stronger adaptability to the environmental uncertainty related to darkness, compared to Xception- and MobileNetv2-based DeepLabv3+ models. Due to the relatively low speed of DeepLabv3+, this model is coupled with YOLO-tiny to enhance the practicality of defect assessment. The “two-stage” approach implemented in YOLO-tiny_DeepLabv3+_UAV makes an automated measurement of tree defect size and demonstrates an accuracy of 92.62% (±6%). The knowledge derived from this research contributes to a comprehensive understanding of machine learning applications in forest sustainability.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/f15081374/s1, Video S1: Video sample_YOLOv7tiny.
Author Contributions
Conceptualization, methodology, writing—original draft preparation, writing—review and editing, visualization, and project administration, Q.Q. and D.L.; software, formal analysis, investigation, resources, and data curation, Q.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data is contained within the article or Supplementary Material.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cook, E.R. A Time Series Analysis Approach to Tree Ring Standardization. Ph.D. Thesis, University of Arizona, Tucson, AZ, USA, 1985. [Google Scholar]
- Roach, D.A. Evolutionary senescence in plants. Genetica 1993, 91, 53–64. [Google Scholar] [CrossRef]
- Vidal, D.; Pitarma, R. Infrared thermography applied to tree health assessment: A Review. Agriculture 2019, 9, 156. [Google Scholar] [CrossRef]
- Xue, F.; Zhang, X.; Wang, Z.; Wen, J.; Guan, C.; Han, H.; Zhao, J.; Ying, N. Analysis of imaging internal defects in living trees on irregular contours of tree trunks using ground-penetrating radar. Forests 2021, 12, 1012. [Google Scholar] [CrossRef]
- Gilbert, G.S.; Ballesteros, J.O.; Barrios-Rodriguez, C.A.; Bonadies, E.F.; Cedeño-Sánchez, M.L.; Fossatti-Caballero, N.J. Use of sonic tomography to detect and quantify wood decay in living trees. Appl. Plant Sci. 2016, 4, 1600060. [Google Scholar] [CrossRef] [PubMed]
- Qin, R.; Qiu, Q.; Lam, J.H.; Tang, A.M.; Leung, M.W.; Lau, D. Health assessment of tree trunk by using acoustic-laser technique and sonic tomography. Wood Sci. Technol. 2018, 52, 1113–1132. [Google Scholar] [CrossRef]
- Qiu, Q.; Qin, R.; Lam, J.H.M.; Tang, A.M.C.; Leung, M.W.K.; Lau, D. An innovative tomographic technique integrated with acoustic-laser approach for detecting defects in tree trunk. Comput. Electron. Agric. 2019, 156, 129–137. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Defect detection in FRP-bonded structural system via phase-based motion magnification technique. Struct. Control Health Monit. 2018, 25, e2259. [Google Scholar] [CrossRef]
- Sermanet, P.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y.; Eigen, D. OverFeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Yang, R.; Hu, Y.; Yao, Y.; Gao, M.; Liu, R. Fruit target detection based on BCo-YOLOv5 model. Mob. Inf. Syst. 2022, 8457173. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Real-time detection of cracks in tiled sidewalks using YOLO-based method applied to unmanned aerial vehicle (UAV) images. Autom. Constr. 2023, 147, 104745. [Google Scholar] [CrossRef]
- Itakura, K.; Hosoi, F. Automatic tree detection from three-dimensional images reconstructed from 360° spherical camera using YOLO v2. Remote Sens. 2020, 12, 988. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Q.; Jiang, P.; Zheng, Y.; Yuan, L.; Yuan, P. LDS-YOLO: A lightweight small object detection method for dead trees from shelter forest. Comput. Electron. Agric. 2022, 198, 107035. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. Comput. Vis. Pattern Recognit. 2017. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schrof, F.; Adam, H. Encoder-Decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the Computer Vision–ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. Comput. Vis. Pattern Recognit. 2017. [Google Scholar] [CrossRef]
- Ahamed, A.; Foye, J.; Poudel, S.; Trieschman, E.; Fike, J. Measuring Tree Diameter with Photogrammetry Using Mobile Phone Cameras. Forests 2023, 14, 2027. [Google Scholar] [CrossRef]
- Roberts, J.; Koeser, A.; Abd-Elrahman, A.; Wilkinson, B.; Hansen, G.; ShawnLandry; Perez, A. Mobile Terrestrial Photogrammetry for Street Tree Mapping and Measurements. Forests 2019, 10, 701. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Zhou, C.; Yin, L.; Feng, X. Urban forest monitoring based on multiple features at the single tree scale by UAV. Urban For. Urban Green. 2021, 58, 126958. [Google Scholar] [CrossRef]
- Hu, G.; Yin, C.; Wan, M.; Zhang, Y.; Fang, Y. Recognition of diseased Pinus trees in UAV images using deep learning and AdaBoost classifier. Biosyst. Eng. 2020, 194, 138–151. [Google Scholar] [CrossRef]
- Duan, F.; Wan, Y.; Deng, L. A Novel Approach for Coarse-to-Fine Windthrown Tree Extraction Based on Unmanned Aerial Vehicle Images. Remote Sens. 2017, 9, 306. [Google Scholar] [CrossRef]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Qian, J.; Lee, Y.H.; Cheng, K.; Dai, Q.; Yusof, M.L.M.; Lee, D.; Yucel, A.C. A Deep Learning-Augmented Stand-off Radar Scheme for Rapidly Detecting Tree Defects. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5106915. [Google Scholar] [CrossRef]
- Krähenbühl, A.; Kerautret, B.; Debled-Rennesson, I.; Mothe, F.; Longuetaud, F. Knot segmentation in 3D CT images of wet wood. Pattern Recognit. 2014, 47, 3852–3869. [Google Scholar] [CrossRef]
- Xie, Q.; Li, D.; Yu, Z.; Zhou, J.; Wang, J. Detecting Trees in Street Images via Deep Learning with Attention Module. IEEE Trans. Instrum. Meas. 2020, 69, 5395–5406. [Google Scholar] [CrossRef]
- Czajkowska, J.; Badura, P.; Korzekwa, S.; Płatkowska-Szczerek, A. Automated segmentation of epidermis in high-frequency ultrasound of pathological skin using a cascade of DeepLab v3+ networks and fuzzy connectedness. Comput. Med. Imaging Graph. 2022, 95, 102023. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. arXiv 2014, arXiv:1406.4729. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, A.P.S.; Christanto, H.J. Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model. Big Data Cogn. Comput. 2023, 7, 53. [Google Scholar] [CrossRef]
- Feng, G.; Yang, Q.; Tang, C.; Liu, Y.; Wu, X.; Wu, W. Mask-Wearing Detection in Complex Environments Based on Improved YOLOv7. Appl. Sci. 2024, 14, 3606. [Google Scholar] [CrossRef]
- Chen, M.; Jin, C.; Ni, Y.; Xu, J.; Yang, T. Online detection system for wheat machine harvesting impurity rate based on DeepLabV3+. Sensors 2022, 22, 7627. [Google Scholar] [CrossRef] [PubMed]
- Sandino, J.; Maire, F.; Caccetta, P.; Sanderson, C.; Gonzalez, F. Drone-Based Autonomous Motion Planning System for Outdoor Environments under Object Detection Uncertainty. Remote Sens. 2021, 13, 4481. [Google Scholar] [CrossRef]
- Yang, K.; Tang, X.; Li, J.; Wang, H.; Zhong, G.; Chen, J.; Cao, D. Uncertainties in Onboard Algorithms for Autonomous Vehicles: Challenges, Mitigation, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8963–8987. [Google Scholar] [CrossRef]
- Chen, S.-Y.; Lin, C.; Tai, C.-H.; Chuang, S.-J. Adaptive Window-Based Constrained Energy Minimization for Detection of Newly Grown Tree Leaves. Remote Sens. 2018, 10, 96. [Google Scholar] [CrossRef]
- Lv, L.; Li, X.; Mao, F.; Zhou, L.; Xuan, J.; Zhao, Y.; Yu, J.; Song, M.; Huang, L.; Du, H. A deep learning network for individual tree segmentation in UAV images with a coupled CSPNet and attention mechanism. Remote Sens. 2023, 15, 4420. [Google Scholar] [CrossRef]
- Wu, D.; Jiang, S.; Zhao, E.; Liu, Y.; Zhu, H.; Wang, W.; Wang, R. Detection of Camellia oleifera Fruit in Complex Scenes by Using YOLOv7 and Data Augmentation. Appl. Sci. 2022, 12, 11318. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Defect detection of FRP-bonded civil structures under vehicle-induced airborne noise. Mech. Syst. Signal Process. 2021, 146, 106992. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Measurement of structural vibration by using optic-electronic sensor. Measurement 2018, 117, 435–443. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. The sensitivity of acoustic-laser technique for detecting the defects in CFRP-bonded concrete systems. J. Nondestruct. Eval. 2016, 35, 1–10. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. A novel approach for near-surface defect detection in FRP-bonded concrete systems using laser reflection and acoustic-laser techniques. Constr. Build. Mater. 2017, 141, 553–564. [Google Scholar] [CrossRef]
- Wang, X.Q.; Chen, P.; Chow, C.L.; Lau, D. Artificial-intelligence-led revolution of construction materials: From molecules to Industry 4.0. Matter 2023, 6, 1831–1859. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).