
Prediction of Forest-Fire Occurrence in Eastern China Utilizing Deep Learning and Spatial Analysis

 , ,
, , 
Abstract
1. Introduction
2. Resources and Methods
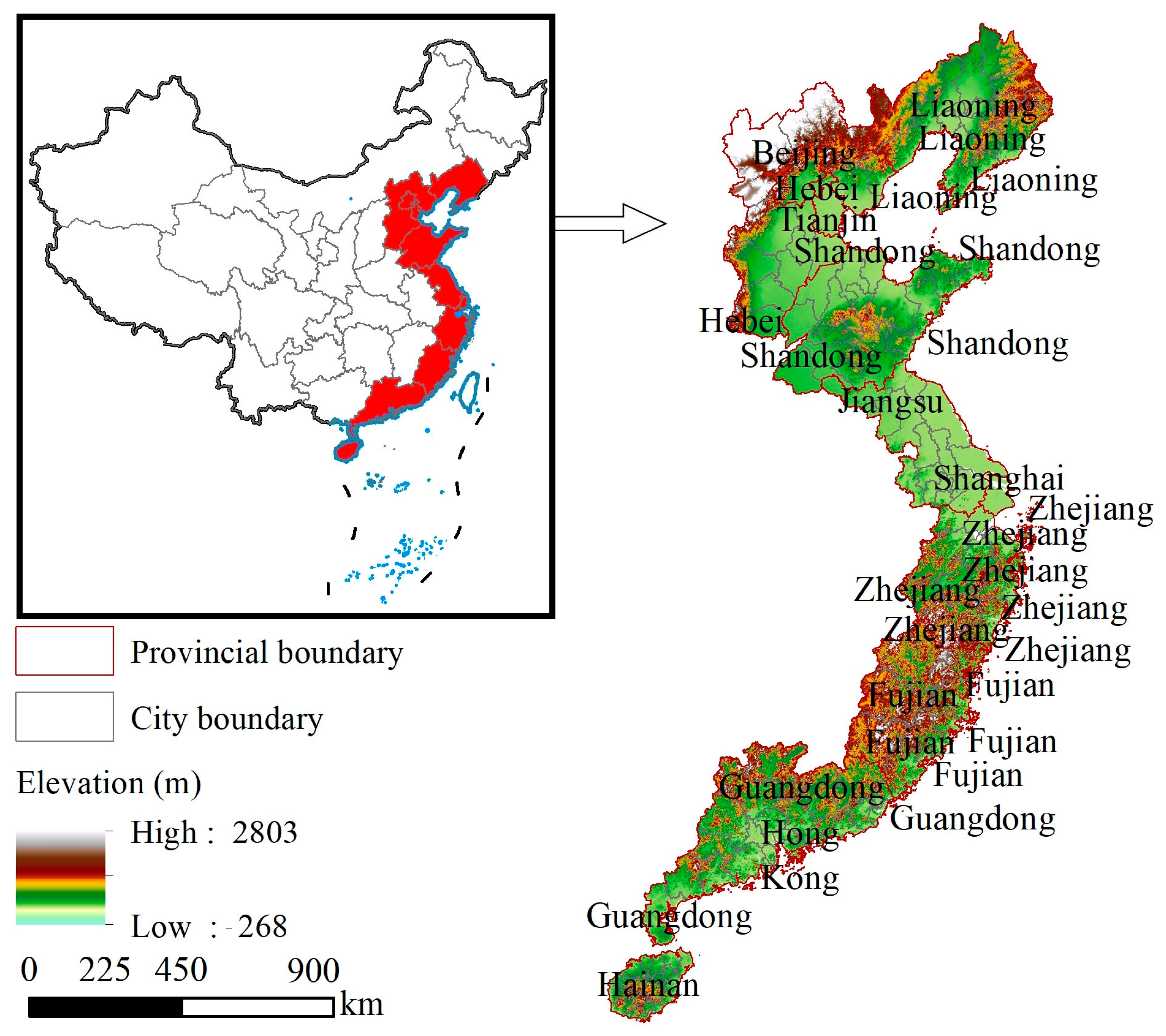
2.1. The Study Area
2.2. Data Sources

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Data | Resolution | Source | References |
|---|---|---|---|---|
| Meteorological data | Daily minimum relative hu-midity, Mean wind speed, etc. | - | https://data.cma.cn, accessed on 1 May 2020 | [37,68] |
| Economic and Social | Road Network, Public Holi-days, and Other Factors. | 1 km, 1 km, | https://www.resdc.cn, accessed on 15 May 2020 https://www.webmap.cn, accessed on 2 May 2020 | [27,28] |
| Lightning data | Lightning observation data records latitude, longitude, and timestamps. | - | - | [65,66,67] |
| Vegetation | Vegetation type | 1 km | https://www.resdc.cn, accessed on 7 May 2020 | [69] |
| Topographic | Slope/Aspect/Elevation | 1 km | https://www.resdc.cn, accessed on 20 May 2020 | [70] |
2.3. Method
2.3.1. Spatial Autocorrelation Analysis
2.3.2. Kernel Density Estimation (KDE)
2.3.3. Standard Deviation Ellipse
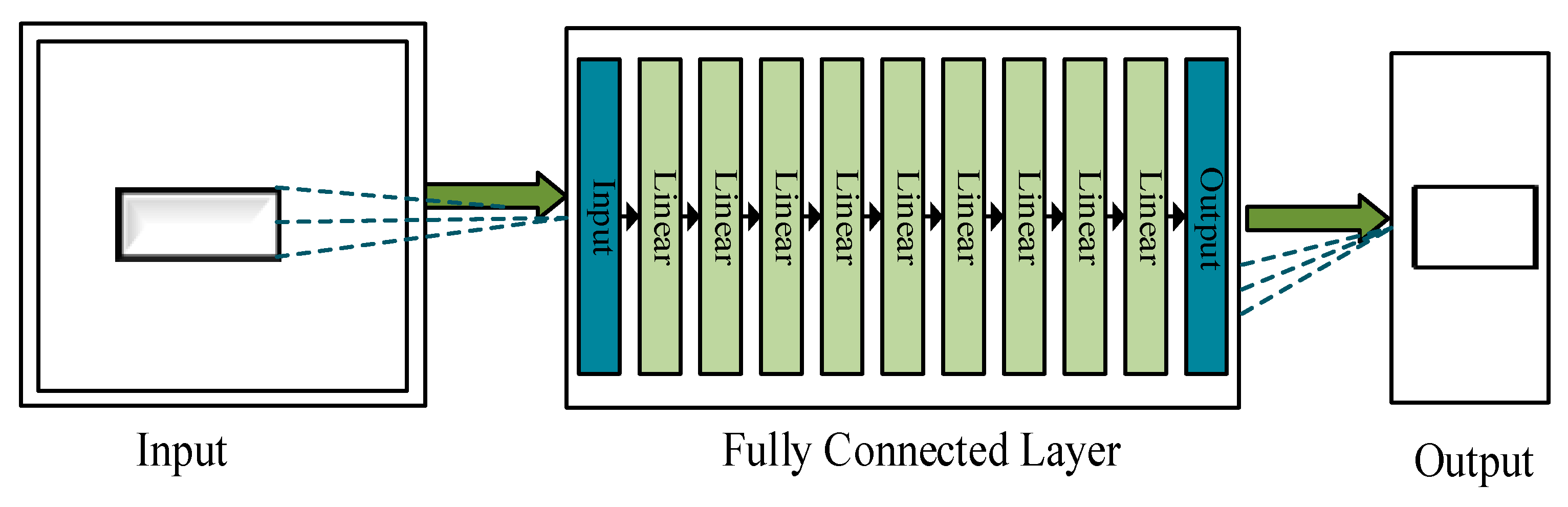
2.3.4. Deep Learning Model
2.3.5. Assessment Criteria
3. Results
3.1. Autocorrelation Analysis Findings on Forest Fire in Eastern China
3.2. Results of Kernel Density Analysis in Eastern China
3.3. Standard Deviation Ellipse Outcome Analysis
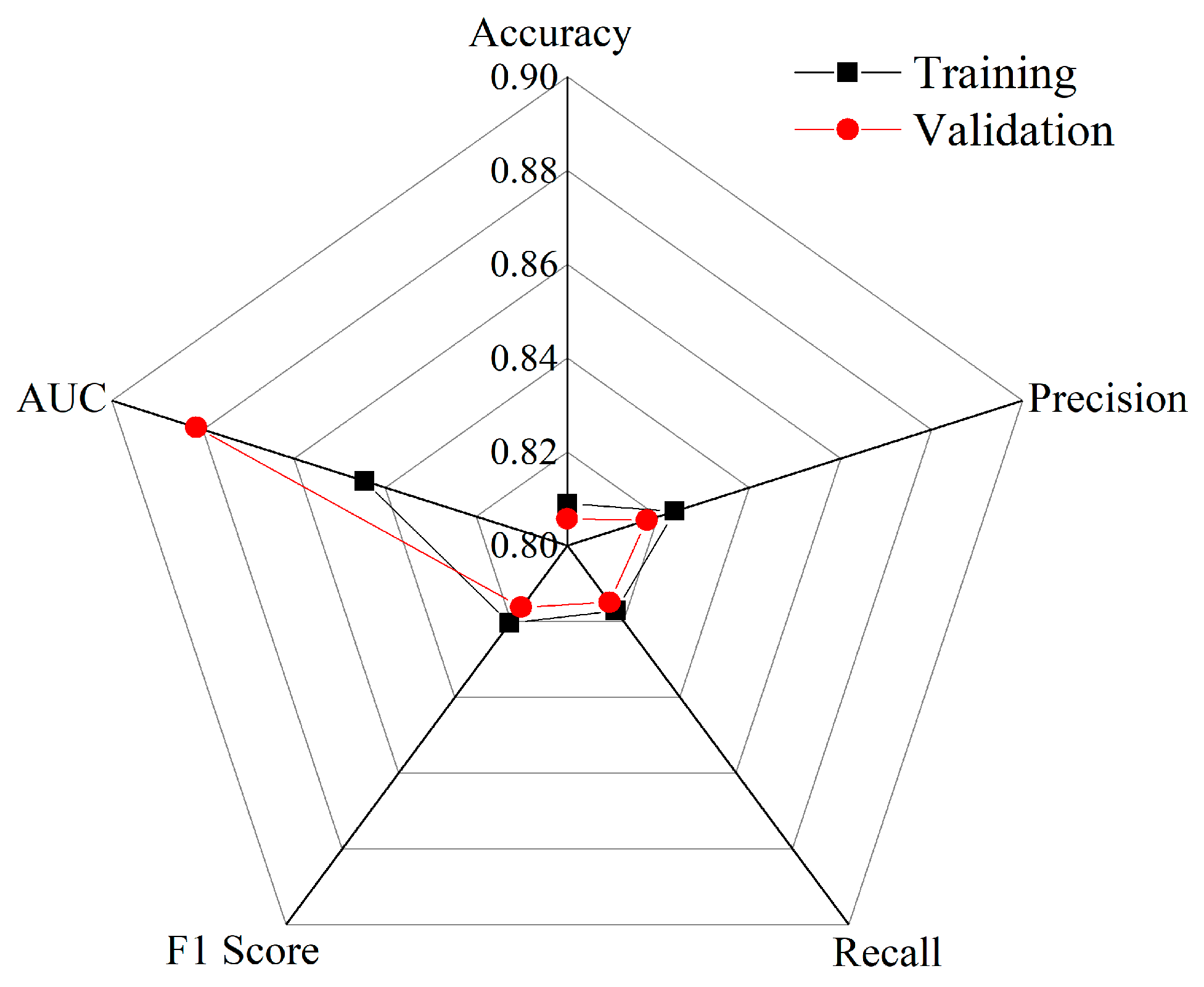
3.4. Assessment of Predictive Model
3.5. Regions for Forest-Fire Predictions
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Garrett, R.D.; Cammelli, F.; Ferreira, J.; Levy, S.A.; Valentim, J.; Vieira, I. Forests and sustainable development in the Brazilian Amazon: History, trends, and future prospects. Annu. Rev. Environ. Resour. 2021, 46, 625–652. [Google Scholar] [CrossRef]
- Hahn, W.A.; Knoke, T. Sustainable development and sustainable forestry: Analogies, differences, and the role of flexibility. Eur. J. For. Res. 2010, 129, 787–801. [Google Scholar] [CrossRef]
- Qiu, Z.; Feng, Z.; Song, Y.; Li, M.; Zhang, P. Carbon sequestration potential of forest vegetation in China from 2003 to 2050: Predicting forest vegetation growth based on climate and the environment. J. Clean. Prod. 2020, 252, 119715. [Google Scholar] [CrossRef]
- Paudel, A.; Yadav, A. Soil conservation practices in forest of Nepal. J. Clean. WAS 2021, 5, 73–77. [Google Scholar] [CrossRef]
- Goeking, S.A.; Tarboton, D.G. Forests and water yield: A synthesis of disturbance effects on streamflow and snowpack in western coniferous forests. J. For. 2020, 118, 172–192. [Google Scholar] [CrossRef]
- Yakui, S.; Lei, W.; Changming, Z.; Hui, F.; Xin, Z.; Duan, H.; Li, T. Forest survey and spatio-temporal analysis in West Tianshan mountains supported by Google Earth Engine. Bull. Surv. Mapp. 2020, 13. [Google Scholar]
- Yakui, S.; Changming, Z.; Xinliang, X.; Xin, Z.; Qian, S. Remote sensing mapping and spatiotemporal changes of forest land in Anhui Province from 2000 to 2012. Ecol. Sci. 2020, 38, 15–21. [Google Scholar]
- Valjarević, A.; Djekić, T.; Stevanović, V.; Ivanović, R.; Jandziković, B. GIS numerical and remote sensing analyses of forest changes in the Toplica region for the period of 1953–2013. Appl. Geogr. 2018, 92, 131–139. [Google Scholar] [CrossRef]
- Agbeshie, A.A.; Abugre, S.; Atta-Darkwa, T.; Awuah, R. A review of the effects of forest fire on soil properties. J. For. Res. 2022, 33, 1419–1441. [Google Scholar] [CrossRef]
- Naderpour, M.; Rizeei, H.M.; Ramezani, F. Forest fire risk prediction: A spatial deep neural network-based framework. Remote Sens. 2021, 13, 2513. [Google Scholar] [CrossRef]
- Xiong, Q.; Luo, X.; Liang, P.; Xiao, Y.; Xiao, Q.; Sun, H.; Pan, K.; Wang, L.; Li, L.; Pang, X. Fire from policy, human interventions, or biophysical factors? Temporal–spatial patterns of forest fire in southwestern China. For. Ecol. Manag. 2020, 474, 118381. [Google Scholar] [CrossRef]
- Bhadoria, R.S.; Pandey, M.K.; Kundu, P. RVFR: Random vector forest regression model for integrated & enhanced approach in forest fires predictions. Ecol. Indic. 2021, 66, 101471. [Google Scholar]
- Preeti, T.; Kanakaraddi, S.; Beelagi, A.; Malagi, S.; Sudi, A. Forest fire prediction using machine learning techniques. In Proceedings of the 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, 25–27 June 2021; pp. 1–6. [Google Scholar]
- Sevinc, V.; Kucuk, O.; Goltas, M. A Bayesian network model for prediction and analysis of possible forest fire causes. For. Ecol. Manag. 2020, 457, 117723. [Google Scholar] [CrossRef]
- Shu, L.; Zhang, X.L.; Dai, X.A.; Tian, X.R.; Wang, M.Y. Review on Forest Fire Research (II)—Forest Fire Prediction and Forecasting. World For. Res. 2003, 16, 34–37. [Google Scholar]
- Li, Y.; Feng, Z.; Chen, S.; Zhao, Z.; Wang, F. Application of the artificial neural network and support vector machines in forest fire prediction in the guangxi autonomous region, China. Discrete Dyn. Nat. Soc. 2020, 2020, 5612650. [Google Scholar] [CrossRef]
- Li, W.; Xu, Q.; Yi, J.; Liu, J. Predictive model of spatial scale of forest fire driving factors: A case study of Yunnan Province, China. Sci. Rep. 2022, 12, 19029. [Google Scholar] [CrossRef]
- Couto, F.T.; Iakunin, M.; Salgado, R.; Pinto, P.; Viegas, T.; Pinty, J.-P. Lightning modelling for the research of forest fire ignition in Portugal. Atmos. Res. 2020, 242, 104993. [Google Scholar] [CrossRef]
- Janssen, T.A.J.; Jones, M.W.; Finney, D.; van der Werf, G.R.; van Wees, D.; Xu, W.; Veraverbeke, S. Extratropical forests increasingly at risk due to lightning fires. Nat. Geosci. 2023, 16, 1136–1144. [Google Scholar] [CrossRef]
- Ivanov, V.A.; Ponomarev, E.I.; Ivanova, G.A.; Mal’kanova, A.V. Lightning and Forest Fires under Modern Climatic Conditions of Central Siberia. Russ. Meteorol. Hydrol. 2023, 48, 630–638. [Google Scholar] [CrossRef]
- Soler, A.; Pineda, N.; San Segundo, H.; Bech, J.; Montanyà, J. Characterisation of thunderstorms that caused lightning-ignited wildfires. Int. J. Wildland Fire 2021, 30, 954–970. [Google Scholar] [CrossRef]
- Aftergood, O.S.R.; Flannigan, M.D. Identifying and analyzing spatial and temporal patterns of lightning-ignited wildfires in Western Canada from 1981 to 2018. Can. J. For. Res. 2022, 52, 1399–1411. [Google Scholar] [CrossRef]
- Müller, M.M.; Vacik, H. Characteristics of lightnings igniting forest fires in Austria. Agric. For. Meteorol. 2017, 240–241, 26–34. [Google Scholar] [CrossRef]
- Smith, J.A.; Baker, M.B.; Weinman, J.A. Do forest fires affect lightning? Q. J. R. Meteorolog. Soc. 2006, 129, 2651–2670. [Google Scholar] [CrossRef]
- Jiao, Q.; Fan, M.; Tao, J.; Wang, W.; Liu, D.; Wang, P. Forest Fire Patterns and Lightning-Caused Forest Fire Detection in Heilongjiang Province of China Using Satellite Data. Fire 2023, 6, 166. [Google Scholar] [CrossRef]
- Schumacher, V.; Setzer, A.; Saba, M.M.F.; Naccarato, K.P.; Mattos, E.; Justino, F. Characteristics of lightning-caused wildfires in central Brazil in relation to cloud-ground and dry lightning. Agric. For. Meteorol. 2022, 312, 108723. [Google Scholar] [CrossRef]
- Shao, Y.; Wang, Z.; Feng, Z.; Sun, L.; Yang, X.; Zheng, J.; Ma, T. Assessment of China’s forest fire occurrence with deep learning, geographic information and multisource data. J. For. Res. 2023, 34, 963–976. [Google Scholar] [CrossRef]
- Shao, Y.; Fan, G.; Feng, Z.; Sun, L.; Yang, X.; Ma, T.; Li, X.; Fu, H.; Wang, A. Prediction of forest fire occurrence in China under climate change scenarios. J. For. Res. 2023, 34, 1217–1228. [Google Scholar] [CrossRef]
- Nikolić, G.; Vujović, F.; Golijanin, J.; Šiljeg, A.; Valjarević, A. Modelling of Wildfire Susceptibility in Different Climate Zones in Montenegro Using GIS-MCDA. Atmosphere 2023, 14, 929. [Google Scholar] [CrossRef]
- Baranovskiy, N. Deterministic-Probabilistic Approach to Predict Lightning-Caused Forest Fires in Mounting Areas. Forecasting 2021, 3, 695–715. [Google Scholar] [CrossRef]
- Baranovskiy, N.V. Predicting Forest Fire Numbers Using Deterministic-Probabilistic Approach. In Predicting, Monitoring, and Assessing Forest Fire Dangers and Risks; Advances in Environmental Engineering and Green Technologies; IGI Global: Hershey, PA, USA, 2020; pp. 89–100. [Google Scholar]
- Baranovskiy, N.V.; Vyatkina, V.A.; Chernyshov, A.M. Deterministic–Probabilistic Prediction of Forest Fires from Lightning Activity Taking into Account Aerosol Emissions. Atmosphere 2022, 14, 29. [Google Scholar] [CrossRef]
- Baranovskiy, N.V.; Kirienko, V.A. Forest Fuel Drying, Pyrolysis and Ignition Processes during Forest Fire: A Review. Processes 2022, 10, 89. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Dinh Du, T.; Yen, H.P.H.; Phong, T.V.; Nguyen, D.H.; Le, H.V.; Mafi-Gholami, D.; et al. Performance Evaluation of Machine Learning Methods for Forest Fire Modeling and Prediction. Symmetry 2020, 12, 1022. [Google Scholar] [CrossRef]
- Galván, L.; Magaña, V. Forest fires in Mexico: An approach to estimate fire probabilities. Int. J. Wildland Fire 2020, 29, 753–763. [Google Scholar] [CrossRef]
- Preisler, H.K.; Ager, A.A. Forest-Fire Models. Encycl. Environmetrics 2012, 3, 2181–2185. [Google Scholar]
- Shokouhi, M.; Asadi Oskouei, E.; Sadeghi, H.; Rahnama, M. Calibration and evaluation of the Forest Fire Weather Index (FWI) in the Hamoun wetland area. J. Nat. Environ. Hazards 2024, 13, 45–60. [Google Scholar]
- Trucchia, A.; D’Andrea, M.; Baghino, F.; Fiorucci, P.; Ferraris, L.; Negro, D.; Gollini, A.; Severino, M. PROPAGATOR: An operational cellular-automata based wildfire simulator. Fire 2020, 3, 26. [Google Scholar] [CrossRef]
- Lopes, A.; Cruz, M.G.; Viegas, D. FireStation—An integrated software system for the numerical simulation of fire spread on complex topography. Environ. Modell. Softw. 2002, 17, 269–285. [Google Scholar] [CrossRef]
- Fujioka, F.M.; Weise, D.R.; Chen, S.-C.; Kim, S.H.; Kafatos, M.C. Reaction intensity partitioning: A new perspective of the National Fire Danger Rating System Energy Release Component. Int. J. Wildland Fire 2021, 30, 351–364. [Google Scholar] [CrossRef]
- Keane, R.E.; Rollins, M.; Zhu, Z.-L. Using simulated historical time series to prioritize fuel treatments on landscapes across the United States: The LANDFIRE prototype project. Ecol. Modell. 2007, 204, 485–502. [Google Scholar] [CrossRef]
- Jin, T.; Hu, X.; Liu, B.; Xi, C.; He, K.; Cao, X.; Luo, G.; Han, M.; Ma, G.; Yang, Y. Susceptibility prediction of post-fire debris flows in Xichang, China, using a logistic regression model from a spatiotemporal perspective. Remote Sens. 2022, 14, 1306. [Google Scholar] [CrossRef]
- Graff, C.A.; Coffield, S.R.; Chen, Y.; Foufoula-Georgiou, E.; Randerson, J.T.; Smyth, P. Forecasting daily wildfire activity using poisson regression. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4837–4851. [Google Scholar] [CrossRef]
- Bugallo, M.; Esteban, M.D.; Marey-Pérez, M.F.; Morales, D. Wildfire prediction using zero-inflated negative binomial mixed models: Application to Spain. J. Environ. Manag. 2023, 328, 116788. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Lupascu, M.; Meel, K.S. Predicting forest fire using remote sensing data and machine learning. Proc. AAAI Conf. Artif. Intell. 2021, 35, 14983–14990. [Google Scholar] [CrossRef]
- Pang, Y.; Li, Y.; Feng, Z.; Feng, Z.; Zhao, Z.; Chen, S.; Zhang, H. Forest fire occurrence prediction in China based on machine learning methods. Remote Sens. 2022, 14, 5546. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.-X.; Xu, C. Applying genetic algorithms to set the optimal combination of forest fire related variables and model forest fire susceptibility based on data mining models. The case of Dayu County, China. Remote Sens. Environ. 2018, 630, 1044–1056. [Google Scholar] [CrossRef]
- Mohajane, M.; Costache, R.; Karimi, F.; Pham, Q.B.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of remote sensing and machine learning algorithms for forest fire mapping in a Mediterranean area. Ecol. Indic. 2021, 129, 107869. [Google Scholar] [CrossRef]
- Li, E.; Fei, Y. Prediction of forest fires based on least squares support vector machine. Hans J. Data Min 2016, 6, 15–27. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G. Efficient forest fire occurrence prediction for developing countries using two weather parameters. Eng. Appl. Artif. Intell. 2011, 24, 888–894. [Google Scholar] [CrossRef]
- Ma, T.; Wang, G.; Guo, R.; Chen, L.; Ma, J. Forest fire susceptibility assessment under small sample scenario: A semi-supervised learning approach using transductive support vector machine. J. Environ. Manag. 2024, 359, 120966. [Google Scholar] [CrossRef]
- Veysi, R.; Fattahi, B.; Khosrobeigi, S. Predicting and preparing a risk map of rangeland fires using random forest algorithms and support vector machine (Case study: Arak rangelands). Rangeland 2022, 16, 413–426. [Google Scholar]
- Tan, C.; Feng, Z. Mapping forest fire risk zones using machine learning algorithms in Hunan province, China. Sustainability 2023, 15, 6292. [Google Scholar] [CrossRef]
- Li, Y.; Li, G.; Wang, K.; Wang, Z.; Chen, Y. Forest fire risk prediction based on stacking ensemble learning for yunnan Province of China. Fire 2023, 7, 13. [Google Scholar] [CrossRef]
- Ramalingam, R. An Innovative Investigation on Predicting Forest Fire Using Machine Learning Approach. In AI and IoT for Proactive Disaster Management; Advances in Computational Intelligence and Robotics; IGI Global: Hershey, PA, USA, 2024; pp. 61–77. [Google Scholar]
- Merabet, M.; Kourtiche, A. Embedded ANN-Based Forest Fire Prediction Case Study of Algeria. Int. J. Distrib. Artif. Intell. 2022, 14, 1–18. [Google Scholar] [CrossRef]
- Safi, Y.; Bouroumi, A. Prediction of forest fires using artificial neural networks. Appl. Math. Sci. 2013, 7, 271–286. [Google Scholar] [CrossRef]
- Abid, F. A survey of machine learning algorithms based forest fires prediction and detection systems. Fire Technol. 2021, 57, 559–590. [Google Scholar] [CrossRef]
- Saha, S.; Bera, B.; Shit, P.K.; Bhattacharjee, S.; Sengupta, N. Prediction of forest fire susceptibility applying machine and deep learning algorithms for conservation priorities of forest resources. Remote Sens. Appl. Soc. Environ. 2023, 29, 100917. [Google Scholar] [CrossRef]
- Yandouzi, M.; Grari, M.; Idrissi, I.; Moussaoui, O.; Azizi, M.; Ghoumid, K.; Elmiad, A.K. Review on forest fires detection and prediction using deep learning and drones. J. Theor. Appl. Inf. Technol. 2022, 100, 4565–4576. [Google Scholar]
- Ghali, R.; Akhloufi, M.A. Deep learning approaches for wildland fires using satellite remote sensing data: Detection, mapping, and prediction. Fire 2023, 6, 192. [Google Scholar] [CrossRef]
- Yang, S.; Huang, Q.; Yu, M. Advancements in remote sensing for active fire detection: A review of datasets and methods. Remote Sens. Environ. 2024, 943, 173273. [Google Scholar] [CrossRef]
- Schiks, T.J.; Wotton, B.M.; Martell, D.L. Remote Sensing Active Fire Detection Tools Support Growth Reconstruction for Large Boreal Wildfires. Fire 2024, 7, 26. [Google Scholar] [CrossRef]
- Albar, I.; Jaya, I.N.S.; Saharjo, B.H.; Kuncahyo, B.; Vadrevu, K.P. Spatio-temporal analysis of land and forest fires in Indonesia using MODIS active fire dataset. In Land-Atmospheric Research Applications in South and Southeast Asia; Springer: Berlin/Heidelberg, Germany, 2018; pp. 105–127. [Google Scholar]
- Kaplan, J.O.; Lau, K.H.-K. The WGLC global gridded lightning climatology and time series. Earth Syst. Sci. Data 2021, 13, 3219–3237. [Google Scholar] [CrossRef]
- Kaplan, J.O.; Lau, K.H.-K. World Wide Lightning Location Network (WWLLN) Global Lightning Climatology (WGLC) and time series, 2022 update. Earth Syst. Sci. Data 2022, 14, 5665–5670. [Google Scholar] [CrossRef]
- Kaplan, J.; Lau, K. The WWLLN Global Lightning Climatology and Timeseries (WGLC), v2022. 0.0, Zenodo [Data Set]. 2022. Available online: https://zenodo.org/records/6007052 (accessed on 20 September 2024).
- Alisjahbana, A.S.; Busch, J.M. Forestry, forest fires, and climate change in Indonesia. Bull. Indones. Econ. Stud. 2017, 53, 111–136. [Google Scholar] [CrossRef]
- Lindenmayer, D.; MacGregor, C.; Welsh, A.; Donnelly, C.; Crane, M.; Michael, D.; Montague-Drake, R.; Cunningham, R.; Brown, D.; Fortescue, M. Contrasting mammal responses to vegetation type and fire. Wildl. Res. 2008, 35, 395–408. [Google Scholar] [CrossRef]
- Ciesielski, M.; Balazy, R.; Borkowski, B.; Szczesny, W.; Zasada, M.; Kaczmarowski, J.; Kwiatkowski, M.; Szczygiel, R.; Milanovic, S. Contribution of anthropogenic, vegetation, and topographic features to forest fire occurrence in Poland. iForest Biogeosci. For. 2022, 15, 307. [Google Scholar] [CrossRef]
- Griffith, D.A. What is spatial autocorrelation? Reflections on the past 25 years of spatial statistics. L’Espace Géogr. 1991, 21, 265–280. [Google Scholar]
- Li, L.; Tang, H.; Lei, J.; Song, X. Spatial autocorrelation in land use type and ecosystem service value in Hainan Tropical Rain Forest National Park. Ecol. Indic. 2022, 137, 108727. [Google Scholar] [CrossRef]
- Ren, H.; Shang, Y.; Zhang, S. Measuring the spatiotemporal variations of vegetation net primary productivity in Inner Mongolia using spatial autocorrelation. Ecol. Indic. 2020, 112, 106108. [Google Scholar] [CrossRef]
- Lemmerz, T.; Herlé, S.; Blankenbach, J. Geostatistics on Real-Time Geodata Streams—High-Frequent Dynamic Autocorrelation with an Extended Spatiotemporal Moran’s I Index. ISPRS Int. J. Geo-Inf. 2023, 12, 350. [Google Scholar] [CrossRef]
- Chen, Y. An analytical process of spatial autocorrelation functions based on Moran’s index. PLoS ONE 2021, 16, e0249589. [Google Scholar] [CrossRef]
- Moran, P.A. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef]
- Zambom, A.Z.; Dias, R. A review of kernel density estimation with applications to econometrics. Int. Econom. Rev. 2013, 5, 20–42. [Google Scholar]
- Chen, Y.-C. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 2017, 1, 161–187. [Google Scholar] [CrossRef]
- Kuter, N.; Yenilmez, F.; Kuter, S. Forest fire risk mapping by kernel density estimation. Croat. J. For. Eng. 2011, 32, 599–610. [Google Scholar]
- Zhao, Y.; Wu, Q.; Wei, P.; Zhao, H.; Zhang, X.; Pang, C. Explore the mitigation mechanism of urban thermal environment by integrating geographic detector and standard deviation ellipse (SDE). Remote Sens. 2022, 14, 3411. [Google Scholar] [CrossRef]
- Huang, J.; Song, L.; Yu, M.; Zhang, C.; Li, S.; Li, Z.; Geng, J.; Zhang, C. Quantitative spatial analysis of thermal infrared radiation temperature fields by the standard deviational ellipse method for the uniaxial loading of sandstone. Infrared Phys. Technol. 2022, 123, 104150. [Google Scholar] [CrossRef]
- Polajžer, B.; Brezovnik, R.; Ritonja, J. Evaluation of load frequency control performance based on standard deviational ellipses. IEEE Trans. Power Syst. 2016, 32, 2296–2304. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhao, Z.; Zhang, P. A new method for identifying industrial clustering using the standard deviational ellipse. Sci. Rep. 2023, 13, 578. [Google Scholar] [CrossRef]
- Fjellström, C.; Nyström, K. Deep learning, stochastic gradient descent and diffusion maps. J. Comput. Math. Data Sci. 2022, 4, 100054. [Google Scholar] [CrossRef]
- Haji, S.H.; Abdulazeez, A.M. Comparison of optimization techniques based on gradient descent algorithm: A review. PalArch’s J. Archaeol. Egypt/Egyptol. 2021, 18, 2715–2743. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef]
- Alakus, T.B.; Turkoglu, I. Comparison of deep learning approaches to predict COVID-19 infection. Chaos Solitons Fractals 2020, 140, 110120. [Google Scholar] [CrossRef] [PubMed]
- Gale, M.G.; Cary, G.J.; Van Dijk, A.I.; Yebra, M. Forest fire fuel through the lens of remote sensing: Review of approaches, challenges and future directions in the remote sensing of biotic determinants of fire behaviour. Remote Sens. Environ. 2021, 255, 112282. [Google Scholar] [CrossRef]
- Kalantar, B.; Ueda, N.; Idrees, M.O.; Janizadeh, S.; Ahmadi, K.; Shabani, F. Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data. Remote Sens. 2020, 12, 3682. [Google Scholar] [CrossRef]
- Nuthammachot, N.; Stratoulias, D. Multi-criteria decision analysis for forest fire risk assessment by coupling AHP and GIS: Method and case study. Environ. Dev. Sustain. 2021, 23, 17443–17458. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, Y.; Wang, G.; Zheng, C.; Zhao, F. A Forest Fire Prediction Method for Lightning Stroke Based on Remote Sensing Data. Forests 2024, 15, 647. [Google Scholar] [CrossRef]
- Wang, R.; Zorzetto, E.; Malyshev, S.; Shevliakova, E. Characterizing lightning-ignited wildfire occurrences at sub-grid scales in orography-aware NOAA/GFDL land model LM4. 2. In Proceedings of the EGU General Assembly 2024, Vienna, Austria, 14–19 April 2024. [Google Scholar]
- Taori, A.; Suryavanshi, A.; Goenka, R.; Venkatesh, D.; Rao, G.S. Inter-comparison of World Wide Lightning Location Network (WWLLN) and Lightning Detection Sensor Network (LDSN) data over India. J. Atmos. Sol. Terr. Phys. 2024, 261, 106286. [Google Scholar] [CrossRef]
- Coughlan, R.; Di Giuseppe, F.; Vitolo, C.; Barnard, C.; Lopez, P.; Drusch, M. Using machine learning to predict fire-ignition occurrences from lightning forecasts. Meteorol. Appl. 2021, 28, e1973. [Google Scholar] [CrossRef]








| Year | XStdDist (km) | YStdDist (km) | Rotation | Oblateness |
|---|---|---|---|---|
| 2001 | 252.2531 | 647.6313 | 29.4644 | 0.389501041 |
| 2004 | 472.2580 | 181.5792 | 47.4166 | 2.600836827 |
| 2005 | 265.1277 | 647.9294 | 36.6400 | 0.409192231 |
| 2012 | 326.6989 | 921.9091 | 19.7177 | 0.35437217 |
| 2014 | 271.2652 | 940.0433 | 23.3805 | 0.288566668 |
| 2015 | 270.2658 | 957.6216 | 25.6633 | 0.28222607 |
| 2019 | 327.2204 | 1364.0125 | 21.3958 | 0.239895437 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Huang, D.; Chen, C.; Liu, Y.; Wang, J.; Shao, Y.; Wang, A.; Li, X. Prediction of Forest-Fire Occurrence in Eastern China Utilizing Deep Learning and Spatial Analysis. Forests 2024, 15, 1672. https://doi.org/10.3390/f15091672
Li J, Huang D, Chen C, Liu Y, Wang J, Shao Y, Wang A, Li X. Prediction of Forest-Fire Occurrence in Eastern China Utilizing Deep Learning and Spatial Analysis. Forests. 2024; 15(9):1672. https://doi.org/10.3390/f15091672
Chicago/Turabian StyleLi, Jing, Duan Huang, Chuxiang Chen, Yu Liu, Jinwang Wang, Yakui Shao, Aiai Wang, and Xusheng Li. 2024. "Prediction of Forest-Fire Occurrence in Eastern China Utilizing Deep Learning and Spatial Analysis" Forests 15, no. 9: 1672. https://doi.org/10.3390/f15091672
APA StyleLi, J., Huang, D., Chen, C., Liu, Y., Wang, J., Shao, Y., Wang, A., & Li, X. (2024). Prediction of Forest-Fire Occurrence in Eastern China Utilizing Deep Learning and Spatial Analysis. Forests, 15(9), 1672. https://doi.org/10.3390/f15091672