1. Introduction
Unevenly-aged forests are characterized by heterogeneous structures that make ecosystems more stable from both ecological and static viewpoints, as well as more resistant to any damaging agents and destructive factors in the environment. These forests, at the same time, are considered to better fulfill the requirements for multipurpose forest use and the provision of ecosystem services than forests under even-aged rotation forest management (RFM) [
1]. Therefore, the importance of unevenly-aged forest management (also known as continuous cover forestry (CCF)) is expected to increase in the future as an alternative to the prevailing RFM.
The concept of close-to-nature forestry developed in Germany from “Naturgemässe Wirtschaftwald”, following “Dauerwald” defined by Möller [
2], can be considered a specific CCF system based on the maximal utilization of natural processes to achieve management goals. As summarized by Bauhus et al. [
3], close-to-nature forestry is characterized by accepting the species composition adopted at the site, avoiding uncovered areas due to harvest, enhancing forest stability, utilizing natural processes, focusing on the development of individual trees, and forming mixed, unevenly-aged, rich-structured stands. Given the complexity (spatial, age, species heterogeneity) of close-to-nature forests, however, there are some problems related to the lack of adequate inventory and planning tools; this lacking has been the main reason for the limited use of these tools and, in some extreme cases, even the rejection of selective logging in some countries. Therefore, enhanced inventory methods are still needed to obtain spatially explicit information for these kinds of forest ecosystems.
Advanced methods of remote sensing provide an alternative approach to traditional forest inventory and there is potential to meet these monitoring needs, including over heterogeneous forests. Airborne laser scanning (ALS, also called airborne LiDAR) data and aerial images especially provide opportunities to replace or combine terrestrial inventory methods with time-saving and cost-efficient remote sensing solutions. A comprehensive overview of possible remote sensing techniques applicable for resource assessment and monitoring of continuous cover forests was published by Gadow et al. [
4]. In this overview, some examples for estimation of stand canopy closure and mapping of forest structure by airborne LiDAR, aerial images or high-resolution satellite data were provided. Recent studies, however, indicate particular problems with the remote-based identification of understory trees, obtaining individual tree attributes from different canopy layers, as well as with species-specific estimations, in more complex stand structures (e.g., [
5,
6]). One way to overcome these problems is a combination of ALS and image data. However, there are still many research gaps in relation to inventory of close-to-nature forests, and new extensive studies are, therefore, required.
Regardless of forest structure, there are two general approaches to ALS-based forest inventory. The first is the area-based approach (ABA), which uses the statistical correlation between field-measured variables and the metrics of ALS data (e.g., [
7,
8,
9]). The second is individual tree detection (ITD), which is based on the detection of single trees and the extraction or estimation of their attributes (e.g., [
10,
11,
12]). Both ABA and ITD methods have advantages and disadvantages. ABA-based techniques usually provide predictions with small systematic errors. However, the attributes of only the main tree species can be predicted with high accuracy and mainly in heterogeneous stands, whereas the accuracy of the minority species is reduced due to inaccurate species-specific estimations [
13]. Several studies related to ABA, therefore, combined information from ALS data with digital aerial images, or applied the nonparametric k-MSN method to more precisely predict species-specific forest variables [
14]. On the other hand, ITD-based techniques are suitable for developing species-specific models that can lead to more accurate stand-level estimations, particularly for mixed stands [
15]. However, tree-based results are often underestimated due to problems in detecting suppressed and understory trees, especially in stands with a complex forest structure. To overcome this problem, semi-ITD approaches (e.g., [
16]) and several techniques for modeling understory trees based on regression estimators (e.g., [
17]), probability models (e.g., [
18]), and the theoretical distribution or location of small trees (e.g., [
19]), as well as the use of a Bayesian inversion framework (e.g., [
20]) have been proposed.
Most studies based on ITD, which is the approach used in the present study, have used a canopy height model (CHM) as input for the extraction or derivation of forest inventory attributes (e.g., [
21]). These grid-based techniques decrease the size of the datasets, computational time, and the demands on hardware, but they also reduce information regarding the understory. On the other hand, point-based techniques are still computationally demanding. Therefore, techniques that combine some type of digital model and part of point cloud data were developed. There are methods that retrieve points associated with crown segments, which are extracted from the CHM (e.g., [
22]), as well as methods that use 3D single-tree modelling and point clouds, which are normalized by using digital terrain model (DTM) (e.g., [
23]). These methods, particularly the voxel-based models, represent an efficient trade-off between grid- and point-based techniques. However, external processing of point cloud data is still required [
24], or a less demanding method is more suitable for the forestry industry.
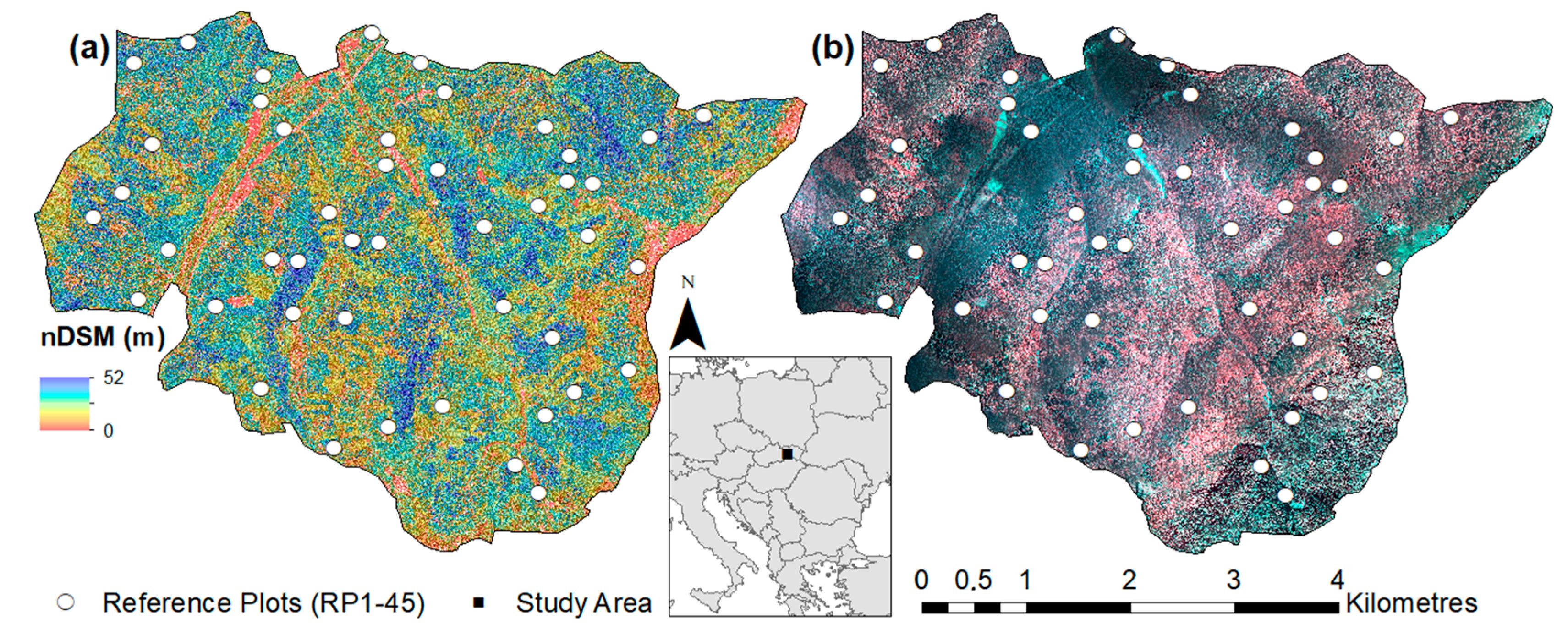
The presented fully point-based technique was developed to compensate for the abovementioned drawbacks [
25]. First of all, the algorithm uses the complete information contained in the raw point cloud, while the computationally-demanding operations are optimized by tiling and thinning procedures. Thus, although external processing or generation of some type of digital model is not required, computational time is comparable with grid-based techniques and, at the same time, information from the understory is not neglected. Specifically, the initial procedures optimize the number of points via tiling and thinning operations. Subsequently, treetop detection, tree crown delineation, and tree height estimation are performed using the reduced, tiled, and normalized point cloud in the original three-dimensional data structure. The next step requires external inputs, such as the raster layer representing tree species and the allometric model for tree diameter derivation. Finally, based on the detected attributes and external inputs, the algorithm automatically evaluates all tree and stand characteristics. The presented algorithm was integrated into reFLex (remote forestland explorer) software, which was developed by the National Forest Center (Zvolen, Slovakia) for its easy-to-use application by the forestry industry.
The purpose of this study was to assess the possibilities and limitations of the individual tree-detection approach applied by the point-based technique within inventory of close-to-nature forest based on a combination of discrete airborne LiDAR data and multispectral aerial images. There, using all information from point cloud and aerial images should improve the results of the inventory in heterogeneous forests. The main forestry tree and stand characteristics, such as the number, species, height, diameter, and volume, were evaluated separately.
3. Results and Discussion
3.1. Accuracy of Individual Tree Detection
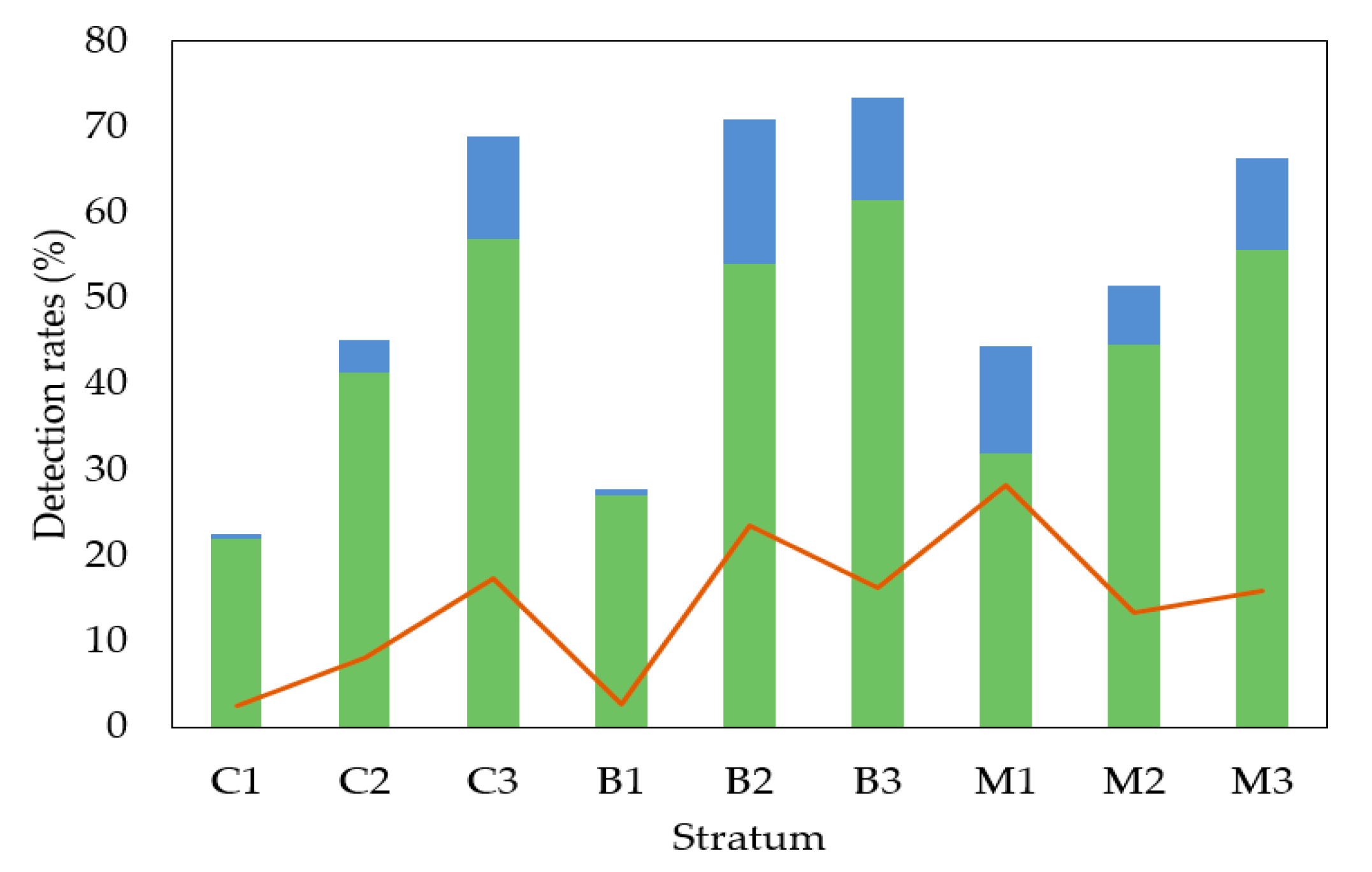
Detection rates for each stratum are shown in
Figure 3, and the matching rate for each stratum as well as for each class of tree social status is shown in
Table 3. We found matching rates within the interval of 22–62% and a relatively low error of commission that varied between 3% and 28%. The average matching rates for the dominant, co-dominant, intermediate, and suppressed trees were 82%, 65%, 33%, and 22%, respectively.
The best matching rates were achieved within the older forest stands and forest stands where broadleaved trees dominated (tree species composition had no significant impact on accuracy). The results grouped by the social position of trees, however, clearly demonstrate that the decrease in overall matching rates was related to poor detection achieved within understory trees. The differences in matching rates between strata representing an equal development stage (C1 vs. M1, C1 vs. B1, M1 vs. B1, etc.) were not significant, and the effect of tree species composition was marginal in these cases (α = 0.05).
The detection rates in our study are consistent with the results of international research where overall detection fluctuated by approximately 70 ± 25%; these findings are related mainly to the extraction method and the quality of the point clouds [
24,
28,
29]. The structure of the forest stand was also an important parameter, as the dense crown canopy caused most points to be concentrated within the overstory trees. For example, in broadleaved stands, Sačkov et al. [
30] detected 66%, 48%, 18%, and 5%; Duncanson et al. [
31] detected 70%, 58%, 35%, 21%; and Ferraz et al. [
32] detected 99%, 93%, 66%, 15% of the dominant, co-dominant, intermediate, and suppressed trees, respectively. In the case of coniferous stands, the overall accuracy often exceeded levels of 90% [
33]. For example, Solberg et al. [
34] detected 93% of dominant, 63% of co-dominant, 38% of intermediate, and 19% of suppressed trees within these stands.
3.2. Accuracy of Tree Height Detection
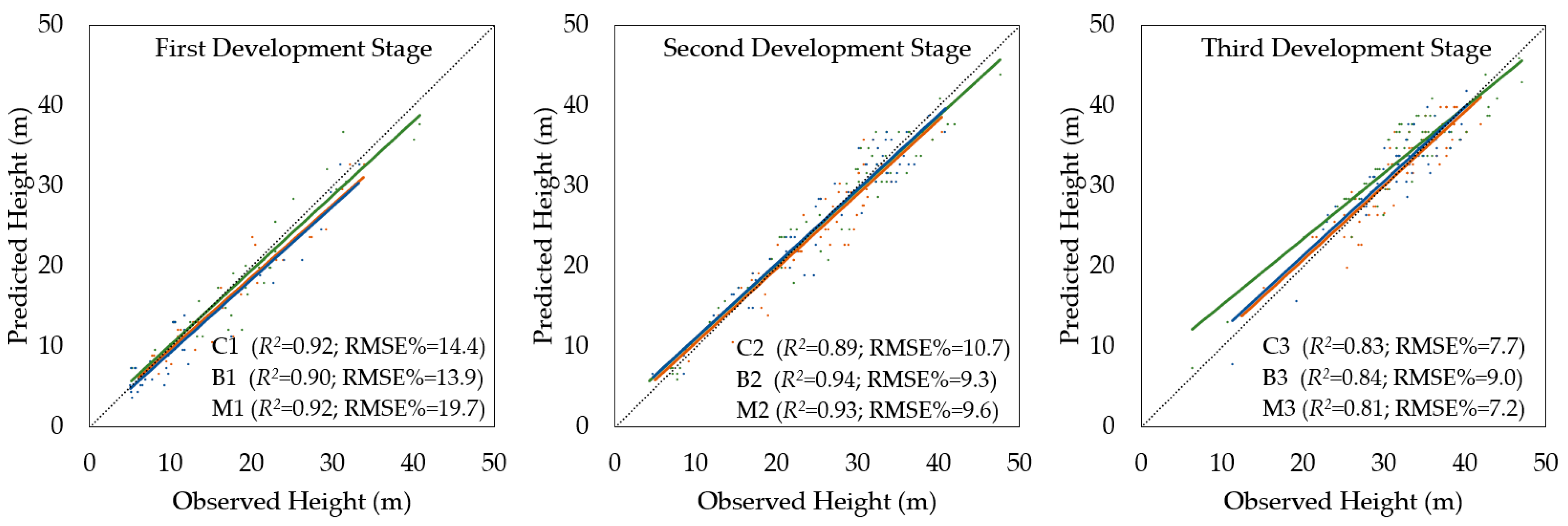
The accuracy assessment of tree height detection based on the ALS data confirmed systematic errors (α = 0.05). Therefore, all results were corrected with respect to a bias value for different tree height intervals. The results of the accuracy assessment for tree height detection after correction for different tree height intervals are shown in
Table 4 and for each stratum in
Figure 4.
We found that tree heights detected and corrected based on the ALS data and bias value provided an output with differences that were not statistically significant relative to the ground data (α = 0.05). Based on the whole-sample size, the remote-based approach underestimated tree height by 0.3 ± 13%, the RMSE% was ±9.7%, and the relationship between the height of the measured and detected trees was very high (R2 = 0.89).
Even in this case, a higher accuracy of tree height detection was achieved within the older forest stands, and poor accuracy of heights detected within understory trees caused a decrease in overall precision. On the other hand, differences in the accuracy of tree height detection between the strata representing equal development stages were not significant only for a few pairs of strata. A notable exception was the coniferous and broadleaved stratum in the third development stage (C3 vs. B3), where the difference was significant (α = 0.05). Thus, in older forest stands, the dominance of any group of tree species had an important influence on the accuracy of tree height detection.
Our results confirmed the general statement that tree height is mostly underestimated, but also the most accurate forest inventory attribute within direct estimations based on the ALS data. First, this is an important point because tree height mensuration from the ground is often difficult due to treetops being hidden by the branches of other trees. Second, tree height is useful for the derivation of other forest inventory attributes. In this context, Sibona et al. [
35] presented a detailed study where remote-based tree heights and field-based tree heights of a hundred felled trees throughout a coniferous forest were compared using point clouds with a density of 1 pt/m
2, 5 pt/m
2, and 10 pt/m
2. The mean absolute difference ranged from 0.95 to 1.13 m in this study. Similar studies by Brandtberg et al. [
36] and Gaveau and Hill [
37] that involved deciduous forests have been conducted, where tree heights evaluated based on the ALS data from leaf-off conditions reached an overall standard error of 1.1 m. These authors underestimated shrub canopy height by 0.91 m and main canopy height by 1.27 m. Chávez and Tullis [
38] evaluated tree height using ALS data and spectral predictors over full-canopy oak-hickory forests and reported an average error of 1.67–2.99 m, a RMSE of 2.2 m, and a correlation coefficient of 0.42–0.51.
3.3. Accuracy of Tree Species Classification
The overall accuracy of tree species classification for both groups of coniferous and broadleaved trees was relatively low. Classification within overstory trees reached OA at 65.0%. Approximately 83% of all coniferous trees and 33% of all broadleaved trees were correctly identified by the classification (producer’s accuracy (PA)) (
Table 5).
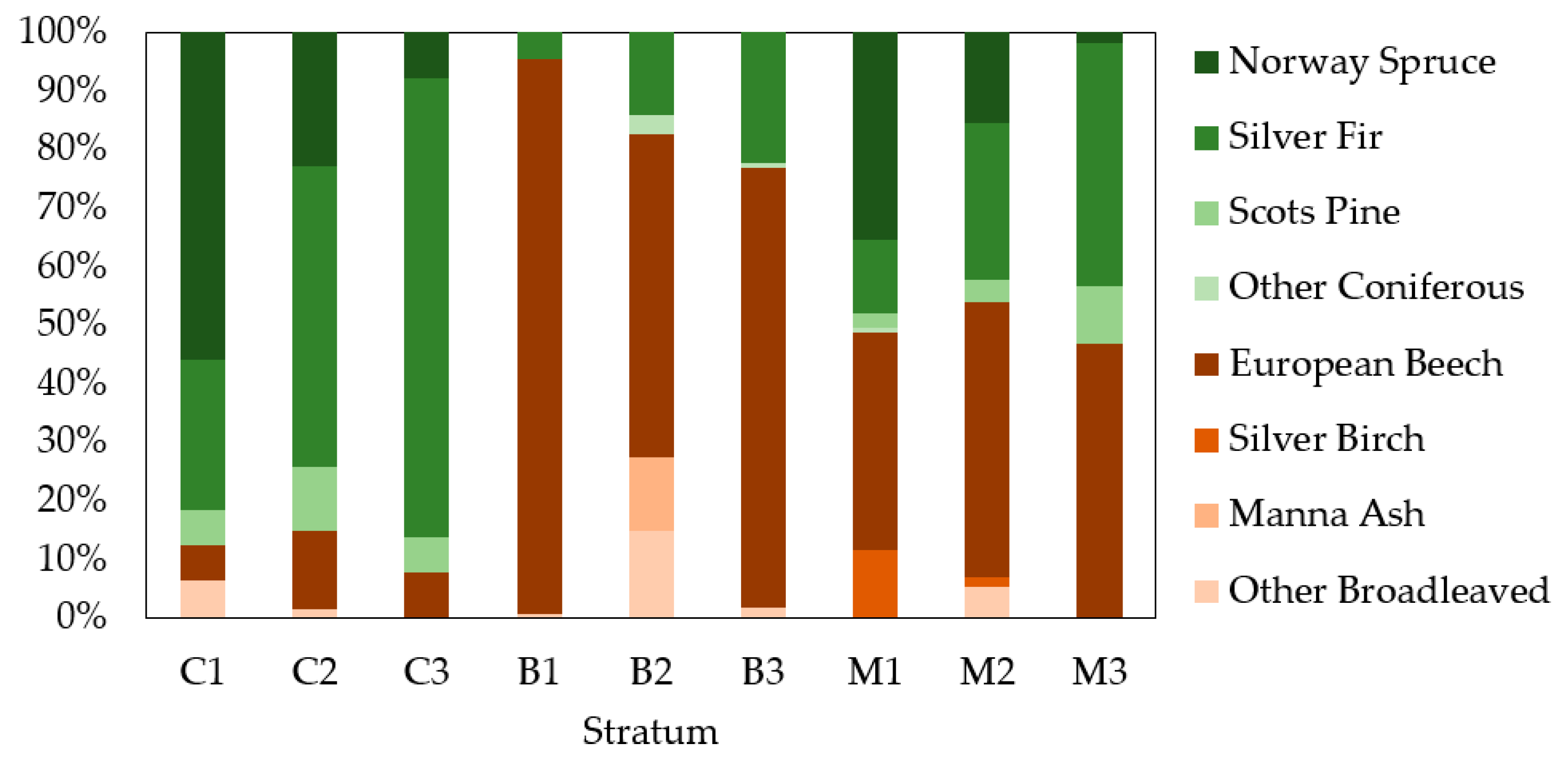
From a stratification perspective, the overall accuracy for strata dominated by broadleaved trees (B1–3) was only 39.9%, while the accuracy results of strata representing coniferous (C1–3) and mixed (M1–3) stands were greater than 63%.
It is evident that the decrease in overall accuracy is related mainly to the classification of broadleaved trees. The broadleaved group was misclassified as a coniferous group, especially in broadleaved strata. High spectral variability occurred in these parts of the area, which was most likely caused by tree health and bidirectional reflectance. Similarly, greater levels of geometric distortion were achieved in that area, probably caused by difficult terrain conditions (differences in elevation). Other more objective causes could have been the social position of trees (broadleaved are mainly within the understory) and shadowed parts of the research area. Therefore, broadleaved trees from the understory were not visible in the remote sensing data or were shadowed, which influenced the spectral values of the respective pixels. Dominant trees may not have been sufficiently illuminated by the sun, and the acquired spectral values of different tree species may also not have been as substantial within the overstory. There, geometric accuracy of ortophoto images partially influenced the results of classification, as well. In this context, the selection of optimal conditions for data acquisition (e.g., weather, season), sensor settings (e.g., FOV, image overlapping), radiometric correction of data, and using a true-ortophoto images or advanced methods for fusion of ALS-image data, resents ways to improve tree species classification accuracy in the future. The use of multiple observations of the same area or aerial and satellite images at different phenological stages would definitely help separate coniferous and deciduous trees, as well.
Information on tree species composition is extremely beneficial, as this information directly describes some qualitative forest characteristics, including structural diversity and habitat quality, and represents an independent variable for estimating many quantitative forest inventory attributes (e.g., tree diameter, tree volume). However, the classification of tree species composition using remote sensing data has proven to be a difficult task. Most studies have estimated tree species using multispectral or hyperspectral aerial imagery by pixel- or object-oriented classification, as described by Ballanti et al. [
39]. Methods based on a combination of aerial images and some derivatives from ALS data (e.g., digital models, intensity raster) are also available (as described by Manzanera et al. [
40] and Sedliak et al. [
41]). Finally, several authors have investigated the potential of discrete or waveform airborne LiDAR data for these purposes, as well as experimentally with spectral airborne LiDAR. There have been a few studies where different forest inventory attributes or variables describing the point cloud were extracted directly from ALS data, such as crown density, crown shape, crown surface texture, echo width, the standard deviation of echo amplitude, the total number of echoes per pulse and received energy from individual peaks, e.g., [
42]. Relevant studies focused on using RS data for tree species composition have reported an overall accuracy in the range of 33–95%.
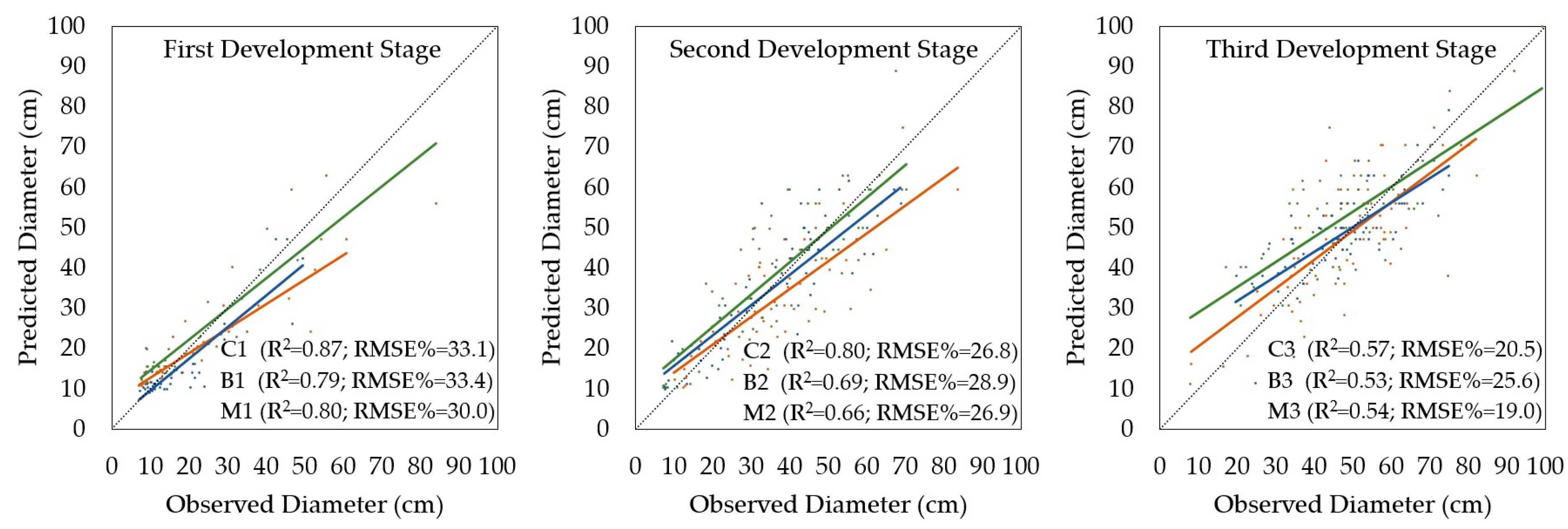
3.4. Accuracy of Tree Diameter Derivation
Tree diameters obtained using the regression model were systematically underestimated in the case of tree height intervals of 21–30 m (α = 0.05). Therefore, the results were corrected with respect to a bias value only for this tree height interval. The results of the accuracy assessment for the tree diameter derivation after correction (tree height interval of 21–30 m) for different tree height intervals are shown in
Table 6 and for each stratum in
Figure 5.
We found that the derived and corrected tree diameters based on the ALS data and bias value provided an output with differences that were not statistically significant relative to the ground data (α = 0.05). Based on the entire sample size, the remote-based approach overestimated the tree diameter by 1.1 ± 31%, the RMSE% was ±25.7%, and the relationship between the diameters of the measured and detected trees was very strong (R2 = 0.79).
Regarding the structure of the model, in which tree height is an important parameter, used to predict the tree diameter, the results concerning the best and worst accuracies of diameter derivation were similar as in the case of tree height. However, the significant effect of tree species composition at equal development stages on the accuracy of tree diameter derivation was also confirmed between coniferous and broadleaved strata in the second and third development stages (C2 vs. B2, C3 vs. B3), as well as between broadleaved and mixture strata at the first development stage (B1 vs. M1), where there was a significant difference (α = 0.05). Thus, in the middle and older forest stands, the dominance of any group of tree species had an important influence on the accuracy of tree diameter derivation. In addition, younger broadleaved stands were different from young mixed forest stands with respect to the tree diameter derivation by the proposed model.
The derivation of tree diameters based on the ALS data was undertaken indirectly by model that uses a well-known relationship between tree diameter and tree height. However, as LiDAR metrics are also used on other tree variables, such as crown area, crown height, and crown volume, which were extracted based on the tree detection approach. Furthermore, Prieditis et al. [
43] proposed models extended by information on soil type and the age of forest stands. Subsequently, many models have been built on multilinear regressions, least square boosting decision trees, random forests, and ε-support vector regressions. Broad research efforts predicting tree diameters using ALS data by different parametric or nonparametric approaches have achieved an overall RMSE% accuracy that fluctuates from 15% to 23% [
44].
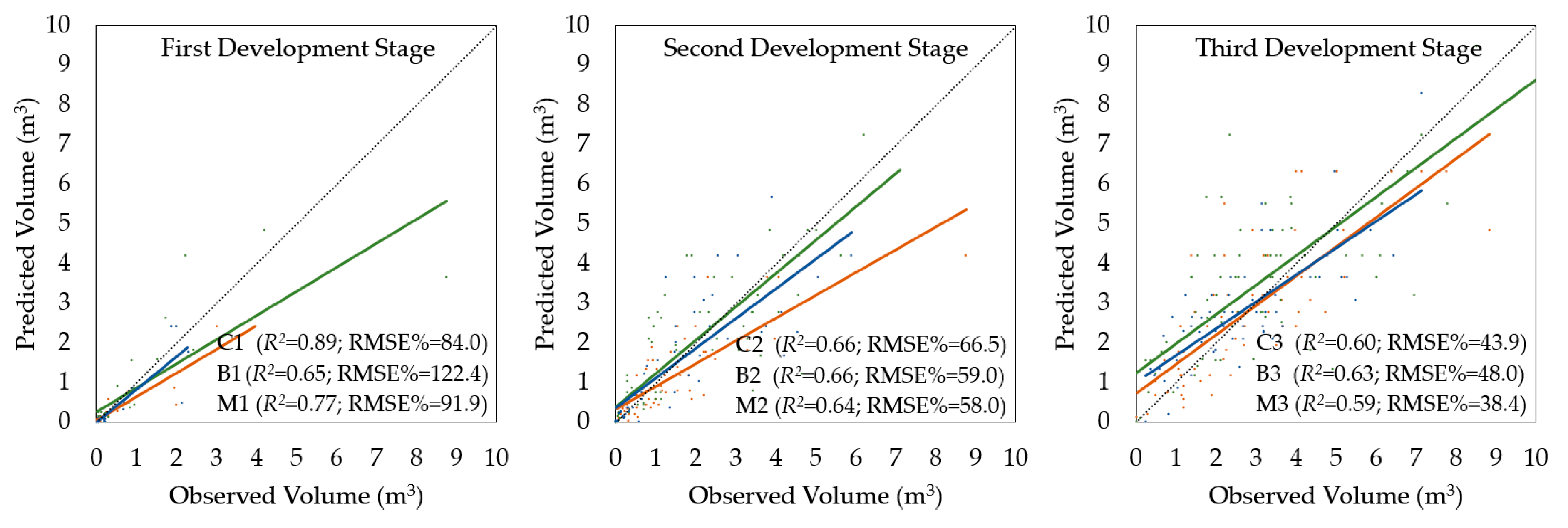
3.5. Accuracy of Tree Volume Calculation
In the case of tree volume, the bias value was not confirmed (α = 0.05); therefore, the results of the calculations were not corrected. The results of the accuracy assessment for the tree volume calculation for different tree height intervals are shown in
Table 7 and for each stratum in
Figure 6.
Based on the entire sample size, the remote-based approach overestimated tree diameters by 1.9 ± 91%, the RMSE% was ±56.1%, and the relationship between the diameters of the measured and detected trees was very strong (R2 = 0.87).
As expected, the volume equations did not affect the overall interpretation of the results. The oldest forest stands achieved a higher accuracy of tree volume calculation, and the lack of precision increased mainly for understory trees; however, the stem volume of understory trees represented only a small ratio of the overall growing stock. Similar to the previous results, differences in the accuracy of tree volume calculations between strata representing equal development stages were not significant, and the effect of tree species composition in these cases was marginal (α = 0.05).
Tree volume, which is also known as stem volume, represents the final quantitative attribute of forest inventory at the tree level. Since our study was related to the ITD approach, we used an allometric model for tree volume calculation based on tree height and diameter. However, several studies have also used combinations of tree and stand variables. For example, Naesset [
45] used percentiles of laser pulse heights and canopy density in a mature forest area and reported a correlation coefficient that ranged from 0.83 to 0.86. The model by Tesfamichael et al. [
46] combined LiDAR-derived height variables (stems per hectare as well as stand age), and the level of association between the estimated and observed volume in eucalyptus plantations was relatively high (
R2 = 0.82–0.94). Furthermore, several models for volume estimation related to the ABA approach have also been reported. In these cases, the forest biophysical variables were regressed against the ALS metrics, and the statistical relationships could be approximated by linear models (e.g., [
47]), nonparametric approaches, such as nearest neighbor imputations (e.g., [
48]), linear mixed effects models with random stand-level intercepts (e.g., [
49]), and Bayesian methods (e.g., [
50]). The overall accuracy of both the ITD and ABA approaches within the tree volume calculation based on the ALS data varied from less than 20% to more than 40%, and the mean error was often negative.
3.6. Accuracy at the Plot Level
The proposed remote-based approach evaluated the mean height at 26.0 m by averaging the detected tree heights, the mean diameter at 37.6 cm by averaging the derived tree diameters, and the volume at 955.4 m3 by adding the calculated tree volumes. The smallest differences with the ground data reached values of 0.4%, 17.9%, and −21.4% for the mean height, mean diameter, and growing stock, respectively.
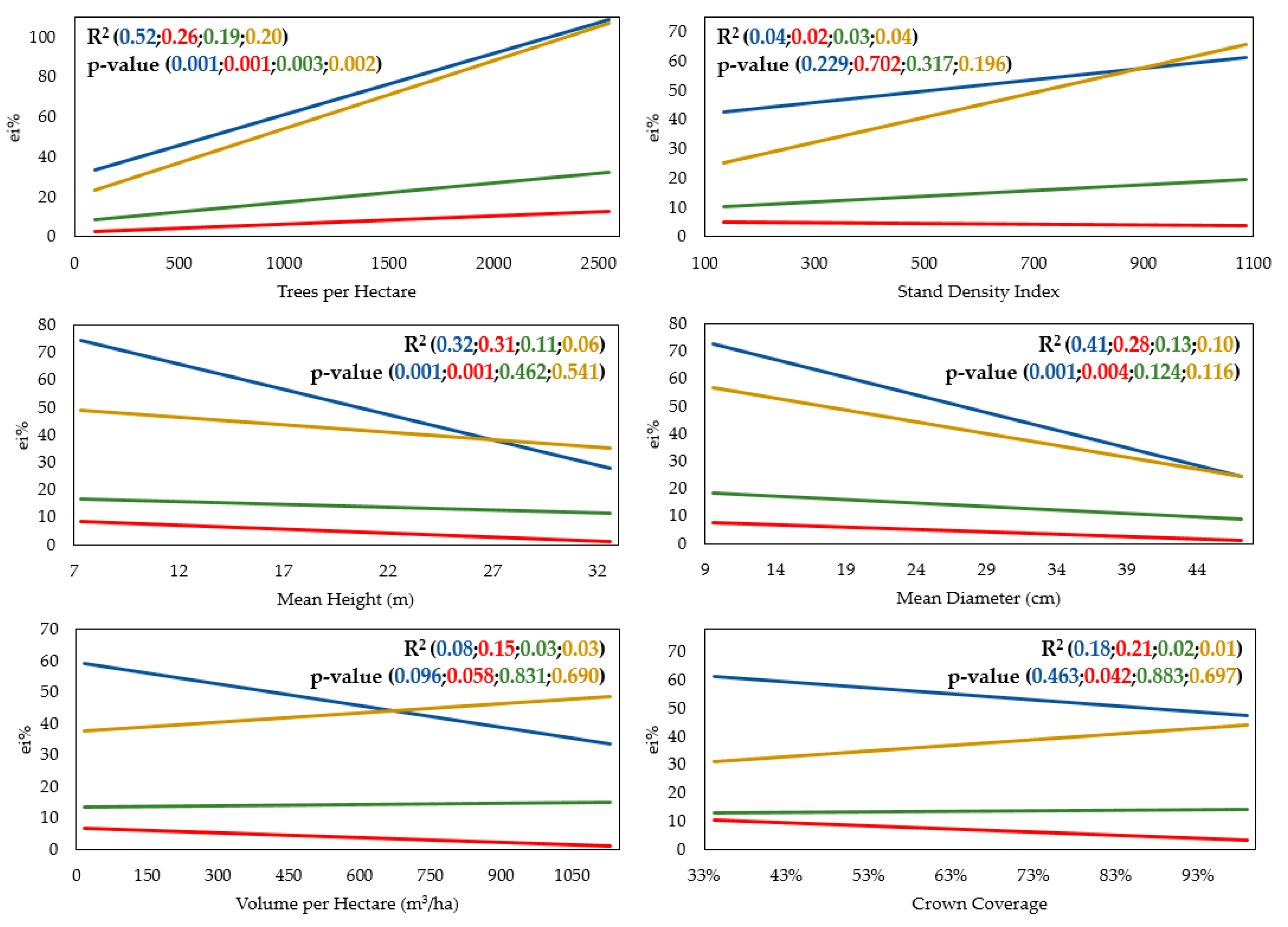
We then investigated the effect of selected stand parameters (i.e., trees per hectare, stand density index, mean height, mean diameter, crown coverage, volume per hectare) on the performance of remote-based inventory techniques used in this study (
Figure 7).
None of the remotely-sensed attributes showed special sensitivity to selected stand parameters, but the accuracy of the used approach was found to be mostly related to the number of trees per hectare. In this case, the effect on all remotely-sensed attributes was significant. The significant effect was further confirmed between the parameters representing the mean basal area (quadratic mean height and diameter) and tree detection, as well as the remotely-sensed mean height. Significant effects were similarly observed between the crown coverage and remotely sensed mean height. Other parameters did not have a significant effect on the accuracy of the used approach (α = 0.05).
Regardless of statistical significance, the relationship between the forest structure and performance of the used approach was clear. The accuracy of tree detection decreased with increasing tree numbers per hectare and stand density index; however, this accuracy increased, as all other stand parameters increased. The accuracy of the remotely-sensed mean height decreased with increasing tree numbers per hectare, but increased as all other stand parameters increased. The accuracy of the remotely-sensed mean diameter, as well as the volume, decreased with increasing tree numbers per hectare, stand density index, volume per hectare, and crown coverage, as well as decreasing mean height and mean diameter.
Forest stands are defined as a group of trees occupying a specific area, and stand parameters, such as mean height, mean diameter, and growing stock, provide basal quantitative information about the structure of forest stands. In this sense, this information relates directly to silvicultural or environmental decisions and plays a key role in the management of natural resources. Unlike our proposed method, most studies related to the ITD-based approach have used a canopy height model as input for the extraction or derivation of stand characteristics. Point-based techniques are used less often, as these techniques often require time-consuming calculations. For example, using the same algorithm used in our study but based on lightweight aerial scanner data, Sačkov et al. [
30] achieved accuracies over a multilayered broadleaved forest within ranges of 4–17%, 22–40%, and 40–45% for stand height, stand diameter, and growing stock, respectively. Woods et al. [
51] provided similar results to our study using low-density ALS data over natural hardwoods and conifers and reported accuracies within ranges of 6–12%, 11–20%, and 22–23% for stand height, stand diameter, and growing stock, respectively.
4. Conclusions
The main objective of this study was to assess the usability and accuracy of an inventory for multistory mixed forests under close-to-nature management based on a combination of discrete airborne LiDAR data and multispectral aerial images using an individual tree-detection approach.
The results showed that this approach could be used for the remote-based estimation of various tree and stand inventory variables, including the number of trees, tree species, tree height, tree diameter, and tree volume. With respect to other studies, our findings indicated that airborne LiDAR data are suitable mainly for the detection of overstory trees and the estimation of the heights of those trees. The algorithm achieved less success regarding tree detection of understory trees, tree diameter derivation, and tree volume calculation. The main weakness of our proposed workflow was the aerial image-based classification of tree species composition. Although only groups of coniferous and broadleaved trees were classified, the obtained overall accuracy was insufficient. We argue, however, that the problem lies mainly in the quality of available images. Thus, the thorough preparation of flight missions and precise post-processing should ensure better results of tree species classification in the future. Multiple observations of the same area or the use of aerial or satellite images at different phenological stages would also definitely help separate coniferous and deciduous trees. Additionally, using true-ortophoto images or advanced methods for fusion of ALS data and ortophoto images, such as back-projecting [
52], is a promising solution with a higher level of objectivity. Despite the shortcomings of this approach, the results were still positive at the stand level for practical use within forestry. There is the major benefit that the accuracy of the total growing stock calculated based on the remotely-sensed data was close to ±20% of the limit defined for the volume calculation in several European countries.
In this context, future research should be concerned with building more precise models for stem diameter derivation, and trying enhanced methods for the fusion of airborne laser scanning and imaging data. Subsequently, additional testing of our approach within a praxis of forest inventories under different ecosystems and data quality is needed.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}