
Genetic Diversity of Grapevine Virus A in Three Australian Vineyards Using Amplicon High Throughput Sequencing (Amplicon-HTS)
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Selection
2.2. Nucleic Acid Extraction Method and RT-PCR Amplification
2.3. Amplicon Purification and Library Preparation
2.4. Amplicon Raw Reads Trimming and Filtering
2.5. Amplicon Reads Error Filtering and Clustering
2.6. Phylogenetic Group Identification of Amplicon Variants
2.7. Intra-Host Diversity Based on Lowest Pairwise Identities
2.8. Intra-Host Genetic Diversity by Median-Joining Haplotype Networks (MJNs) within a Single Sample
2.9. Intra and Inter-Host Diversity by MJNs for Overall Data
3. Results
3.1. Sequencing Reads of Amplicon-HTS
3.2. Nucleotide and Amino Acid Sequence Clustering
3.3. Intra- and Inter-Host Diversity of Amplicon Variants
3.3.1. Intra-Host Diversity: Lowest Pairwise Identities within Each Sample
3.3.2. Inter-Host Diversity: Lowest Percentage Pairwise Nucleotide Identities and Amino Acid Similarities within Each Phylogroup
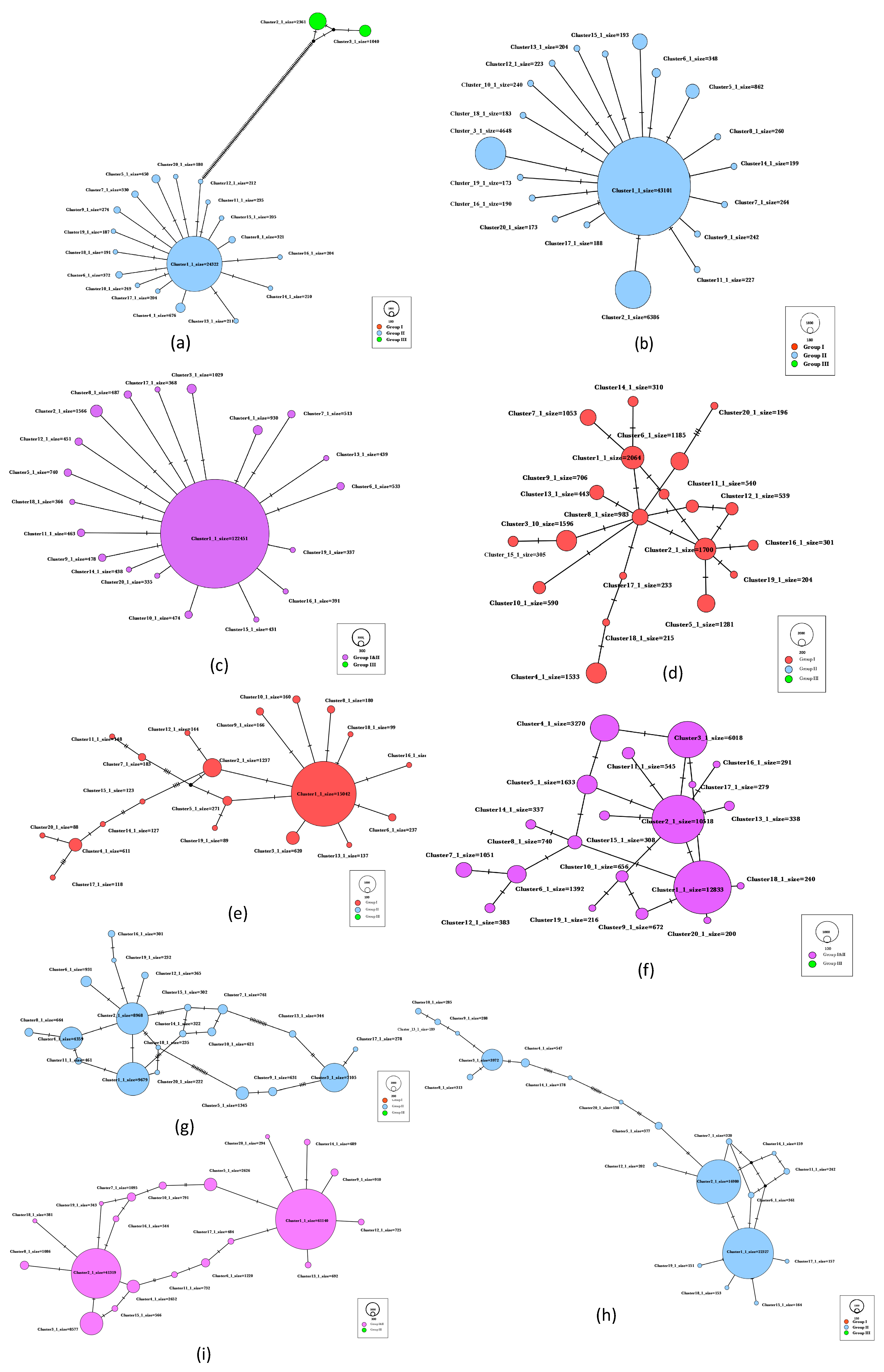
3.4. Intra- and Inter-Host Diversity Analysis by Median-Joining Haplotype Networks (MJNs)
3.4.1. MJNs of Sample WIL3, BV1 and LC1
3.4.2. Intra- and Inter-Host Diversity of MJNs by the Overall Data Set
3.4.3. Variant Groups vs. Geographical Location
4. Discussion
4.1. Challenges of GVAI Amplification by the MP Primers
4.2. Lowest Pairwise Identities
4.3. Intra-Host Diversity
4.4. Evolutionary Relationship between GVA Phylogroups
4.5. Origin of GVA Variants in Vineyards
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Corbett, M.K.; Wiid, J. Closterovirus-like particles in extracts from diseased grapevines. Phytopathol. Mediterr. 1985, 24, 91–100. [Google Scholar]
- Habili, N.; Scliefert, L. The increasing threat of grapevine virus A and its association with restricted spring growth in Australia. Aust. N. Z. Grapegrow. Winemak. 2001, 452, 22–26. [Google Scholar]
- Habili, N.; Wu, Q.; Pagay, V. Virus-associated Shiraz disease may lead Shiraz to become an endangered variety in Australia. Wine Vitic. J. 2016, 31, 47–50. [Google Scholar]
- Wu, Q.; Habili, N.; Constable, F.; Al Rwahnih, M.; Goszczynski, D.E.; Wang, Y.; Pagay, V. Virus pathogens in Australian vineyards with an emphasis on Shiraz disease. Viruses 2020, 12, 818. [Google Scholar] [CrossRef] [PubMed]
- Habili, N.; Randles, J.W. Major yield loss in Shiraz vines infected with Australian Shiraz disease associated with grapevine virus A. In Proceedings of the 17th Meeting of the International Council for the Study of Viruses and Virus-like Diseases of the Grapevine, Davis, CA, USA, 7–14 October 2012; pp. 164–165. [Google Scholar]
- Habili, N.; Randles, J.W. Descriptors for grapevine virus A-associated syndrome in Shiraz, Merlot and Ruby Cabernet in Australia, and its similarity to Shiraz disease in South Africa. Aust. N. Z. Grapegrow. Winemak. 2004, 488, 71–74. [Google Scholar]
- Adams, M.J.; Candresse, T.T.; Hammond, J.; Kreuze, J.F.; Martelli, G.P.; Namba, S.; Pearson, M.N.; Ryu, K.H.; Saldarelli, P.; Yoshikawa, N. Family -Betaflexiviridae. In Virus Taxonomy: Ninth Report of the International Committee on Taxonomy of Viruses; King, A.M.Q., Adams, M.J., Carstens, E.B., Lefkowitz, E.J., Eds.; Elsevier: Amsterdam, The Netherlands, 2012; pp. 920–941. [Google Scholar]
- Minafra, A.; Saldarelli, P.; Grieco, F.; Martelli, G.P. Nucleotide sequence of the 3’ terminal region of the RNA of two filamentous grapevine viruses. Arch. Virol. 1994, 137, 249–261. [Google Scholar] [CrossRef]
- Minafra, A.; Saldarelli, P.; Martelli, G.P. Grapevine virus A: Nucleotide sequence, genome organization, and relationship in the Trichovirus genus. Arch. Virol. 1997, 142, 417–423. [Google Scholar] [CrossRef]
- Zhou, Z.S.; Dell’Orco, M.; Turturo, P.; Martelli, C.; Saldarelli, A.; Minafra, G.P.; Turturo, G.P. Identification of an RNA-silencing suppressor in the genome of grapevine virus A. J. Gen. Virol. 2006, 87, 2387–2395. [Google Scholar] [CrossRef]
- Galiakparov, N.; Tanne, E.; Mawassi, M.; Gafny, R.; Sela, I. ORF 5 of grapevine virus A encodes a nucleic acid-binding protein and affects pathogenesis. Virus Genes 2003, 27, 257–262. [Google Scholar] [CrossRef]
- Haviv, S.; Iddan, Y.; Goszczynski, D.E.; Mawassi, M. The ORF5 of grapevine virus A is involved in symptoms expression in Nicotiana benthamiana plants. Ann. Appl. Biol. 2012, 160, 181–190. [Google Scholar] [CrossRef]
- Goszczynski, D.E.; Du Preez, J.; Burger, J.T. Molecular divergence of grapevine virus A (GVA) variants associated with Shiraz disease in South Africa. Virus Res. 2008, 138, 105–110. [Google Scholar] [CrossRef]
- Goszczynski, D.E.; Jooste, A.E.C. Identification of divergent variants of grapevine virus A. Eur. J. Plant Pathol. 2003, 109, 397–403. [Google Scholar] [CrossRef]
- Wu, Q.; Habili, N.; Kinoti, W.M.; Tyerman, S.D.; Rinaldo, A.; Zheng, L.; Constable, F.E. A Metagenomic Investigation of the Viruses Associated with Shiraz Disease in Australia. Viruses 2023, 15, 774. [Google Scholar] [CrossRef] [PubMed]
- Simon-Loriere, E.; Holmes, E.C. Why do RNA viruses recombine? Nat. Rev. Microbiol. 2011, 9, 617–626. [Google Scholar] [CrossRef] [PubMed]
- McDonald, S.M.; Nelson, M.I.; Turner, P.E.; Patton, J.T. Reassortment in segmented RNA viruses: Mechanisms and outcomes. Nat. Rev. Microbiol. 2016, 14, 448–460. [Google Scholar] [CrossRef] [PubMed]
- García-Arenal, F.; Fraile, A.; Malpica, J.M. Variability and genetic structure of plant virus populations. Annu. Rev. Phytopathol. 2001, 39, 157. [Google Scholar] [CrossRef] [PubMed]
- Harrison, B.D. Virus variation in relation to resistance-breaking in plants. Euphytica 2002, 124, 181–192. [Google Scholar] [CrossRef]
- Domingo, E. Quasispecies and the implications for virus persistence and escape. Clin. Diagn. Virol. 1998, 10, 97–101. [Google Scholar] [CrossRef]
- Elena, S.F.; Sanjuán, R. Adaptive value of high mutation rates of RNA viruses: Separating causes from consequences. J. Virol. 2005, 79, 11555–11558. [Google Scholar] [CrossRef]
- Duffy, S. Why are RNA virus mutation rates so damn high? PLoS Biol. 2018, 16, e3000003. [Google Scholar] [CrossRef]
- Loewe, L.; Hill, W.G. The population genetics of mutations: Good, bad and indifferent. Phil. Trans. R. Soc. B 2010, 365, 1153–1167. [Google Scholar] [CrossRef] [PubMed]
- Montoya, V.; Olmstead, A.; Tang, P.; Cook, D.; Janjua, N.; Grebely, J.; Jacka, B.; Poon, A.F.Y.; Krajden, M. Deep sequencing increases hepatitis C virus phylogenetic cluster detection compared to Sanger sequencing. Infect. Genet. Evol. 2016, 43, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Liang, B.; Luo, M.; Scott-Herridge, J.; Semeniuk, C.; Mendoza, M.; Capina, R.; Sheardown, B.; Ji, H.; Kimani, J.; Ball, B.T. A comparison of parallel pyrosequencing and sanger clone-based sequencing and its impact on the characterization of the genetic diversity of HIV-1. PLoS ONE 2011, 6, e26745. [Google Scholar] [CrossRef] [PubMed]
- Telele, N.F.; Kalu, A.W.; Gebre-Selassie, S.; Fekade, D.; Abdurahman, S.; Marrone, G.; Neogi, U.; Tegbaru, B.; Sönnerborg, A. Pretreatment drug resistance in a large countrywide Ethiopian HIV-1C cohort: A comparison of Sanger and high-throughput sequencing. Sci. Rep. 2018, 8, 7556. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, S.; Penaranda, G.; Gonzalez, D.; Camus, C.; Khiri, H.; Boulmé, R.; Sayada, C.; Philibert, P.; Olive, D.; Halfon, P. Comparison of ultra-deep versus Sanger sequencing detection of minority mutations on the HIV-1 drug resistance interpretations after virological failure. Aids 2014, 28, 1315–1324. [Google Scholar] [CrossRef] [PubMed]
- Arias, A.; López, P.; Sánchez, R.; Yamamura, Y.; Rivera-Amill, V. Sanger and next generation sequencing approaches to evaluate HIV-1 virus in blood compartments. Int. J. Environ. Res. Public Health 2018, 15, 1697. [Google Scholar] [CrossRef]
- Knyazev, S.; Hughes, L.; Skums, P.; Zelikovsky, A. Epidemiological data analysis of viral quasispecies in the next-generation sequencing era. Brief. Bioinform. 2021, 22, 96–108. [Google Scholar] [CrossRef]
- Harvala, H.; Wiman, Å.; Wallensten, A.; Zakikhany, K.; Englund, H.; Brytting, M. Role of sequencing the measles virus hemagglutinin gene and hypervariable region in the measles outbreak investigations in Sweden during 2013–2014. J. Infect. Dis. 2016, 213, 592–599. [Google Scholar] [CrossRef]
- Harismendy, O.; Ng, P.C.; Strausberg, R.L.; Wang, X.; Stockwell, T.B.; Beeson, K.Y.; Schork, N.J.; Murray, S.S.; Topol, E.J.; Levy, S. Evaluation of next generation sequencing platforms for population targeted sequencing studies. Genome Biol. 2009, 10, R32. [Google Scholar] [CrossRef]
- Han, S.-W.; Kim, H.-P.; Shin, J.-Y.; Jeong, E.-G.; Lee, W.-C.; Lee, K.-H.; Won, J.-K.; Kim, T.-Y.; Oh, D.-Y.; Im, S.-A. Targeted sequencing of cancer-related genes in colorectal cancer using next-generation sequencing. PLoS ONE 2013, 8, e64271. [Google Scholar] [CrossRef]
- Ding, D.; Lou, X.; Hua, D.; Yu, W.; Li, L.; Wang, J.; Gao, F.; Zhao, N.; Ren, G.; Li, L. Recurrent targeted genes of hepatitis B virus in the liver cancer genomes identified by a next-generation sequencing–based approach. PLoS Genet. 2012, 8, e1003065. [Google Scholar] [CrossRef] [PubMed]
- Guerrero-Preston, R.; Godoy-Vitorino, F.; Jedlicka, A.; Rodríguez-Hilario, A.; González, H.; Bondy, J.; Lawson, F.; Folawiyo, O.; Michailidi, C.; Dziedzic, A. 16S rRNA amplicon sequencing identifies microbiota associated with oral cancer, human papilloma virus infection and surgical treatment. Oncotarget 2016, 7, 51320. [Google Scholar] [CrossRef] [PubMed]
- Hugerth, L.W.; Andersson, A.F. Analysing microbial community composition through amplicon sequencing: From sampling to hypothesis testing. Front. Microbiol. 2017, 8, 1561. [Google Scholar] [CrossRef] [PubMed]
- Schöler, A.; Jacquiod, S.; Vestergaard, G.; Schulz, S.; Schloter, M. Analysis of soil microbial communities based on amplicon sequencing of marker genes. Biol. Fertil. Soils 2017, 53, 485–489. [Google Scholar] [CrossRef]
- Hata, A.; Kitajima, M.; Haramoto, E.; Lee, S.; Ihara, M.; Gerba, C.P.; Tanaka, H. Next-generation amplicon sequencing identifies genetically diverse human astroviruses, including recombinant strains, in environmental waters. Sci. Rep. 2018, 8, 11837. [Google Scholar] [CrossRef] [PubMed]
- Taylor, D.L.; Walters, W.A.; Lennon, N.J.; Bochicchio, J.; Krohn, A.; Caporaso, J.G.; Pennanen, T. Accurate estimation of fungal diversity and abundance through improved lineage-specific primers optimized for Illumina amplicon sequencing. Appl. Environ. Microbiol. 2016, 82, 7217–7226. [Google Scholar] [CrossRef] [PubMed]
- De Filippis, F.; Laiola, M.; Blaiotta, G.; Ercolini, D. Different amplicon targets for sequencing-based studies of fungal diversity. Appl. Environ. Microbiol. 2017, 83, e00905-17. [Google Scholar] [CrossRef]
- Ranjan, R.; Rani, A.; Metwally, A.; McGee, H.S.; Perkins, D.L. Analysis of the microbiome: Advantages of whole genome shotgun versus 16S amplicon sequencing. Biochem. Biophys. Res. Commun. 2016, 469, 967–977. [Google Scholar] [CrossRef]
- Kuczynski, J.; Lauber, C.L.; Walters, W.A.; Parfrey, L.W.; Clemente, J.C.; Gevers, D.; Knight, R. Experimental and analytical tools for studying the human microbiome. Nat. Rev. Genet. 2012, 13, 47–58. [Google Scholar] [CrossRef]
- Sabrià, A.; Pintó, R.M.; Bosch, A.; Quer, J.; Garcia-Cehic, D.; Gregori, J.; Dominguez, A.; Carol, M.; Sala-Farré, M.-R.; Guix, S. Characterization of intra-and inter-host norovirus P2 genetic variability in linked individuals by amplicon sequencing. PLoS ONE 2018, 13, e0201850. [Google Scholar] [CrossRef]
- Piry, S.; Wipf-Scheibel, C.; Martin, J.-F.; Galan, M.; Berthier, K. High throughput amplicon sequencing to assess within-and between-host genetic diversity in plant viruses. bioRxiv 2017, 168773. [Google Scholar] [CrossRef]
- Kinoti, W.M.; Constable, F.E.; Nancarrow, N.; Plummer, K.M.; Rodoni, B. Generic amplicon deep sequencing to determine Ilarvirus species diversity in Australian Prunus. Front. Microbiol. 2017, 8, 1219. [Google Scholar] [CrossRef] [PubMed]
- Kinoti, W.M.; Constable, F.E.; Nancarrow, N.; Plummer, K.M.; Rodoni, B. Analysis of intra-host genetic diversity of Prunus necrotic ringspot virus (PNRSV) using amplicon next generation sequencing. PLoS ONE 2017, 12, e0179284. [Google Scholar] [CrossRef] [PubMed]
- Kinoti, W.M.; Constable, F.E.; Nancarrow, N.; Plummer, K.M.; Rodoni, B. The incidence and genetic diversity of apple mosaic virus (ApMV) and prune dwarf virus (PDV) in Prunus species in Australia. Viruses 2018, 10, 136. [Google Scholar] [CrossRef] [PubMed]
- Maina, S.; Zheng, L.; Rodoni, B.C. Targeted genome sequencing (TG-Seq) approaches to detect plant viruses. Viruses 2021, 13, 583. [Google Scholar] [CrossRef] [PubMed]
- Bandelt, H.-J.; Forster, P.; Röhl, A. Median-joining networks for inferring intraspecific phylogenies. Mol. Biol. Evol. 1999, 16, 37–48. [Google Scholar] [CrossRef] [PubMed]
- Ramachandran, S.; Campo, D.S.; Dimitrova, Z.E.; Xia, G.-l.; Purdy, M.A.; Khudyakov, Y.E. Temporal variations in the hepatitis C virus intrahost population during chronic infection. J. Virol. 2011, 85, 6369–6380. [Google Scholar] [CrossRef]
- Lee, D.-H.; Torchetti, M.K.; Killian, M.L.; Berhane, Y.; Swayne, D.E. Highly pathogenic avian influenza A (H7N9) virus, Tennessee, USA, March 2017. Emerg. Infect. Dis. 2017, 23, 1860–1863. [Google Scholar] [CrossRef]
- Beerens, N.; Heutink, R.; Bergervoet, S.A.; Harders, F.; Bossers, A.; Koch, G. Multiple reassorted viruses as cause of highly pathogenic avian influenza A (H5N8) virus epidemic, the Netherlands, 2016. Emerg. Infect. Dis. 2017, 23, 1974–1981. [Google Scholar] [CrossRef]
- Lundström, J.O.; Hesson, J.C.; Schäfer, M.L.; Östman, Ö.; Semmler, T.; Bekaert, M.; Weidmann, M.; Lundkvist, Å.; Pfeffer, M. Sindbis virus polyarthritis outbreak signalled by virus prevalence in the mosquito vectors. PLoS Negl. Trop. Dis. 2019, 13, e0007702. [Google Scholar] [CrossRef]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar] [PubMed]
- Mihaescu, R.; Levy, D.; Pachter, L. Why neighbor-joining works. Algorithmica 2009, 54, 1–24. [Google Scholar] [CrossRef]
- Minafra, A.; Hadidi, A. Sensitive detection of grapevine virus A, B, or leafroll-associated III from viruliferous mealybugs and infected tissue by cDNA amplification. J. Virol. Methods 1994, 47, 175–187. [Google Scholar] [CrossRef] [PubMed]
- Goszczynski, D.E.; Jooste, A.E.C. Identification of grapevines infected with divergent variants of grapevine virus A using variant-specific RT-PCR. J. Virol. Methods 2003, 112, 157–164. [Google Scholar] [CrossRef] [PubMed]
- Nassuth, A.; Pollari, E.; Helmeczy, K.; Stewart, S.; Kofalvi, S.A. Improved RNA extraction and one-tube RT-PCR assay for simultaneous detection of control plant RNA plus several viruses in plant extracts. J. Virol. Methods 2000, 90, 37–49. [Google Scholar] [CrossRef] [PubMed]
- Schubert, M.; Lindgreen, S.; Orlando, L. AdapterRemoval v2: Rapid adapter trimming, identification, and read merging. BMC Res. Notes 2016, 9, 88. [Google Scholar] [CrossRef] [PubMed]
- Bushnell, B. BBMap: A Fast, Accurate, Splice-Aware Aligner; LBNL Report LBNL-7065E; Lawrence Berkeley National Lab (LBNL): Berkeley, CA, USA, 2014. [Google Scholar]
- Altschul, S.F.; Madden, T.L.; Schäffer, A.A.; Zhang, J.; Zhang, Z.; Miller, W.; Lipman, D.J. Gapped BLAST and PSI-BLAST: A new generation of protein database search programs. Nucleic Acids Res. 1997, 25, 3389–3402. [Google Scholar] [CrossRef]
- Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet. J. 2011, 17, 10–12. [Google Scholar] [CrossRef]
- Shen, W.; Le, S.; Li, Y.; Hu, F. SeqKit: A cross-platform and ultrafast toolkit for FASTA/Q file manipulation. PLoS ONE 2016, 11, e0163962. [Google Scholar] [CrossRef]
- Edgar, R.C. MUSCLE: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32, 1792–1797. [Google Scholar] [CrossRef]
- Edgar, R.C. Search and clustering orders of magnitude faster than BLAST. Bioinformatics 2010, 26, 2460–2461. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef] [PubMed]
- Muhire, B.M.; Varsani, A.; Martin, D.P. SDT: A virus classification tool based on pairwise sequence alignment and identity calculation. PLoS ONE 2014, 9, e108277. [Google Scholar] [CrossRef] [PubMed]
- Jridi, C.; Martin, J.-F.; Marie-Jeanne, V.; Labonne, G.; Blanc, S. Distinct viral populations differentiate and evolve independently in a single perennial host plant. J. Virol. 2006, 80, 2349–2357. [Google Scholar] [CrossRef] [PubMed]
- Tamukong, Y.B.; Collum, T.D.; Stone, A.L.; Kappagantu, M.; Sherman, D.J.; Rogers, E.E.; Dardick, C.; Culver, J.N. Dynamic changes impact the plum pox virus population structure during leaf and bud development. Virology 2020, 548, 192–199. [Google Scholar] [CrossRef] [PubMed]
- Kearney, C.M.; Thomson, M.J.; Roland, K.E. Genome evolution of tobacco mosaic virus populations during long-term passaging in a diverse range of hosts. Arch. Virol. 1999, 144, 1513–1526. [Google Scholar] [CrossRef]
- Arthur, K.; Collins, N.C.; Randles, J.W. Mutation rate in Velvet tobacco mottle virus varies between genomic region and virus variant but is not influenced by obligatory mirid transmission. Virus Genes 2012, 45, 575–580. [Google Scholar] [CrossRef]
- Little, A.; Fazeli, C.F.; Rezaian, M.A. Hypervariable genes in grapevine leafroll associated virus 1. Virus Res. 2001, 80, 109–116. [Google Scholar] [CrossRef]
- Lasken, R.S.; Stockwell, T.B. Mechanism of chimera formation during the Multiple Displacement Amplification reaction. BMC Biotechnol. 2007, 7, 19. [Google Scholar] [CrossRef]
- Vallette, F.; Mege, E.; Reiss, A.; Adesnik, M. Construction of mutant and chimeric genes using the polymerase chain reaction. Nucleic Acids Res. 1989, 17, 723–733. [Google Scholar] [CrossRef]
- Drake, J.W.; Holland, J.J. Mutation rates among RNA viruses. Proc. Natl. Acad. Sci. USA 1999, 96, 13910–13913. [Google Scholar] [CrossRef]
- da Silva, W.; Kutnjak, D.; Xu, Y.; Xu, Y.; Giovannoni, J.; Elena, S.F.; Gray, S. Transmission modes affect the population structure of potato virus Y in potato. PLoS Pathog. 2020, 16, e1008608. [Google Scholar] [CrossRef] [PubMed]
- Mochizuki, T.; Ohara, R.; Roossinck, M.J. Large-scale synonymous substitutions in cucumber mosaic virus RNA 3 facilitate amino acid mutations in the coat protein. J. Virol. 2018, 92, e01007-18. [Google Scholar] [CrossRef] [PubMed]
- Lauring, A.S.; Acevedo, A.; Cooper, S.B.; Andino, R. Codon usage determines the mutational robustness, evolutionary capacity, and virulence of an RNA virus. Cell Host Microbe 2012, 12, 623–632. [Google Scholar] [CrossRef] [PubMed]
- Mueller, S.; Papamichail, D.; Coleman, J.R.; Skiena, S.; Wimmer, E. Reduction of the rate of poliovirus protein synthesis through large-scale codon deoptimization causes attenuation of viral virulence by lowering specific infectivity. J. Virol. 2006, 80, 9687–9696. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Shan, K.j.; Zan, F.; Tang, X.; Qian, Z.; Lu, J. Optimization and Deoptimization of Codons in SARS-CoV-2 and Related Implications for Vaccine Development. Adv. Sci. 2023, 10, 2205445. [Google Scholar] [CrossRef] [PubMed]
- Chare, E.R.; Holmes, E.C. Selection pressures in the capsid genes of plant RNA viruses reflect mode of transmission. J. Gen. Virol. 2004, 85, 3149–3157. [Google Scholar] [CrossRef]
- Butković, A.; González, R. A brief view of factors that affect plant virus evolution. Front. Virol. 2022, 2, 994057. [Google Scholar] [CrossRef]
- Garcia, D.; Garcia, S.; Voinnet, O. Nonsense-mediated decay serves as a general viral restriction mechanism in plants. Cell Host Microbe 2014, 16, 391–402. [Google Scholar] [CrossRef]
- Nyikó, T.; Kerenyi, F.; Szabadkai, L.; Benkovics, A.H.; Major, P.; Sonkoly, B.; Merai, Z.; Barta, E.; Niemiec, E.; Kufel, J. Plant nonsense-mediated mRNA decay is controlled by different autoregulatory circuits and can be induced by an EJC-like complex. Nucleic Acids Res. 2013, 41, 6715–6728. [Google Scholar] [CrossRef]
- Yang, G.; Qiu, B.S.; Liu, X.G.; Li, Y.; Wang, X.F. Nonsense mutations of replicase and movement protein genes contribute to the attenuation of an avirulent tomato mosaic virus. Virus Res. 2002, 87, 119–128. [Google Scholar] [CrossRef] [PubMed]
- Pereira, F. SARS-CoV-2 variants combining spike mutations and the absence of ORF8 may be more transmissible and require close monitoring. Biochem. Biophys. Res. Commun. 2021, 550, 8–14. [Google Scholar] [CrossRef] [PubMed]
- Lefeuvre, P.; Martin, D.P.; Elena, S.F.; Shepherd, D.N.; Roumagnac, P.; Varsani, A. Evolution and ecology of plant viruses. Nat. Rev. Microbiol. 2019, 17, 632–644. [Google Scholar] [CrossRef] [PubMed]
- Mauck, K.E. Variation in virus effects on host plant phenotypes and insect vector behavior: What can it teach us about virus evolution? Curr. Opin. Virol. 2016, 21, 114–123. [Google Scholar] [CrossRef] [PubMed]
- McCrone, J.T.; Lauring, A.S. Genetic bottlenecks in intraspecies virus transmission. Curr. Opin. Virol. 2018, 28, 20–25. [Google Scholar] [CrossRef] [PubMed]
- Roossinck, M.J. Symbiosis versus competition in plant virus evolution. Nat. Rev. Microbiol. 2005, 3, 917–924. [Google Scholar] [CrossRef] [PubMed]
- Callaway, E. Beyond Omicron: What’s next for COVID’s viral evolution. Nature 2021, 600, 204–207. [Google Scholar] [CrossRef]
- Rosciglione, B.; Castellano, M.A.; Martelli, G.P.; Savino, V.; Cannizzaro, G. Mealybug transmission of grapevine virus A. Vitis 1983, 22, 331–347. [Google Scholar]
- Hommay, G.; Komar, V.; Lemaire, O.; Herrbach, E. Grapevine virus A transmission by larvae of Parthenolecanium corni. Eur. J. Plant Pathol. 2008, 121, 185–188. [Google Scholar] [CrossRef]
- Bertin, S.; Cavalieri, V.; Gribaudo, I.; Sacco, D.; Marzachì, C.; Bosco, D. Transmission of grapevine virus A and grapevine leafroll-associated virus 1 and 3 by Heliococcus bohemicus (Hemiptera: Pseudococcidae) nymphs from plants with mixed infection. J. Econ. Entomol. 2016, 109, 1504–1511. [Google Scholar] [CrossRef]
- Tsai, C.-W.; Chau, J.; Fernandez, L.; Bosco, D.; Daane, K.; Almeida, R. Transmission of grapevine leafroll-associated virus 3 by the vine mealybug (Planococcus ficus). Phytopathology 2008, 98, 1093–1098. [Google Scholar] [CrossRef] [PubMed]
- Le Maguet, J.; Beuve, M.; Herrbach, E.; Lemaire, O. Transmission of six ampeloviruses and two vitiviruses to grapevine by Phenacoccus aceris. Phytopathology 2012, 102, 717–723. [Google Scholar] [CrossRef] [PubMed]
- Petersen, C.L.; Charles, J.G. Transmission of grapevine leafroll-associated closteroviruses by Pseudococcus longispinus and P. calceolariae. Plant Pathol. 1997, 46, 509–515. [Google Scholar] [CrossRef]
- Barrass, I.C.; Jerie, P.; Ward, S.A. Aerial dispersal of first-and second-instar longtailed mealybug, Pseudococcus longispinus (Targioni Tozzetti)(Pseudococcidae: Hemiptera). Aust. J. Exp. Agric. 1994, 34, 1205–1208. [Google Scholar] [CrossRef]
- Grasswitz, T.R.; James, D.G. Movement of grape mealybug, Pseudococcus maritimus, on and between host plants. Entomol. Exp. Appl. 2008, 129, 268–275. [Google Scholar] [CrossRef]
- Charleston, K.; Addison, S.; Miles, M.; Maas, S. The Solenopsis mealybug outbreak in Emerald. Aust. Cottongrower 2010, 31, 18–22. [Google Scholar]
- Forrester, N.L.; Guerbois, M.; Seymour, R.L.; Spratt, H.; Weaver, S.C. Vector-borne transmission imposes a severe bottleneck on an RNA virus population. PLoS Pathog. 2012, 8, e1002897. [Google Scholar] [CrossRef]
- Moury, B.; Fabre, F.; Senoussi, R. Estimation of the number of virus particles transmitted by an insect vector. Proc. Natl. Acad. Sci. USA 2007, 104, 17891–17896. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Gene 1 | MP | CP | RB |
|---|---|---|---|
| Total raw reads | 6,466,112 | 8,784,286 | 7,568,478 |
| Quality trimmed reads | 2,805,669 | 3,877,170 | 3,399,212 |
| Size trimmed reads | 2,188,151 | 2,080,245 | 3,153,286 |
| Primer trimmed reads | 2,128,784 | 2,015,120 | 2,814,646 |
| Proportion of trimmed reads in total raw reads (%) | 64.44 | 46.08 | 73.36 |
| Total nucleotide (nt) variants | 12,983 | 13,103 | 10,052 |
| Unique nt variants 2 | 10,454 | 10,899 | 6366 |
| Proportion of unique nt variants in total variants (%) | 80.52 | 83.18 | 63.33 |
| Total amino acid (aa) variants | 6593 | 5389 | 6192 |
| Unique aa variants | 4402 | 2250 | 1900 |
| Proportion of unique aa variants in total variants (%) | 66.77 | 41.75 | 30.68 |
| Lowest Identity a | MP b | CP b | RB b | |||
|---|---|---|---|---|---|---|
| % nt Identity a | % aa Similarity a | % nt Identity | % aa Similarity | % nt Identity | % aa Similarity | |
| GVAI variants | 95.60% 1 | 95.04% 1 | 92.59% 1 | 86.42% 1 | 90.40% 3 | 86.36% 3 |
| GVAII variants | 88.74% | 90.08% | 86.42% | 87.04% | See GVAI | |
| GVAIII variants | N/A | 88.07% 2 | 88.89% 2 | N/A | ||
| Gene 1 | Sample ID | No. of Reads | % Nucleotide (nt) Identity to LC1-1 3 | % nt Identity to LC1-2 3 |
|---|---|---|---|---|
| CP | LC1_CP_Cluster1 # | 9679 | 96.09% | 100.00% # |
| LC1_CP_Cluster2 # | 8968 | 96.30% | 99.79% # | |
| LC1_CP_Cluster3 * | 7105 | 100.00% * | 96.09% | |
| LC1_CP_Cluster4 # | 4359 | 96.09% | 99.59% # | |
| LC1_CP_Cluster5 | 1345 | 98.97% | 97.12% | |
| MP | LC1_MP_Cluster1 * | 22,327 | 100.00% * | 93.96% |
| LC1_MP_Cluster2 * | 16,980 | 99.73% * | 94.23% | |
| LC1_MP_Cluster3 # | 3972 | 93.96% | 100.00% # | |
| LC1_MP_Cluster4 # | 547 | 94.51% | 99.45% # | |
| LC1_MP_Cluster5 * | 377 | 99.18% * | 94.78% | |
| RB | LC1_RB_Cluster1 * | 61,140 | 100.00% * | N/A 2 |
| LC1_RB_Cluster2 | 41,319 | 96.97% | N/A | |
| LC1_RB_Cluster3 | 8577 | 96.46% | N/A | |
| LC1_RB_Cluster4 | 2652 | 97.47% | N/A | |
| LC1_RB_Cluster5 * | 2626 | 99.49% * | N/A |
| Variant Group ID 1 | CP 2 | MP 2 | RB 2 | ||||
|---|---|---|---|---|---|---|---|
| Sample ID | Lowest % Nucleotide (nt) Identity within the Variant Group | Sample ID | Lowest % nt Identity within the Variant Group | Sample ID | Lowest % nt Identity within the Variant Group | ||
| Multiple-Sample Variant Groups | VG1 | LC8, 9, 14 | 95.68 | LC8, 9, 14 | 97.53 | LC8, 9, 14 | 95.96 |
| VG2 | LC8, 14 | 98.77 | LC8, 14 | 97.8 | N/A 3 | N/A | |
| VG3 | LC5, 13 | 98.97 | LC5, 13 | 97.53 | N/A | N/A | |
| VG4 | LC1,2; WIL1 | 98.56 | LC1,2; WIL1 | 96.98 | LC1,2; WIL1 | 95.96 | |
| VG5 | WIL2, 3 | 97.33 | N/A | N/A | N/A | N/A | |
| VG6 | LC3, 4, 11, 12 | 94.65 | LC3, 4, 11, 12 | 96.98 | N/A | N/A | |
| VG7 | LC6, 7 | 98.97 | LC6, 7 | 99.45 | LC6, 7 | 97.98 | |
| VG8 | WIL5, 6 | 99.59 | WIL5, 6 | 98.9 | WIL5, 6 | 98.48 | |
| VG9 | LC1; WIL1a | 99.38 | LC1; WIL1a | 98.63 | N/A | N/A | |
| VG10 | LC3, 12 | 98.56 | N/A | N/A | N/A | N/A | |
| VG11 | N/A | N/A | WIL2, 3; LC2 | 98.08 | N/A | N/A | |
| VG12 | N/A | N/A | LC10, 12 | 94.78 | N/A | N/A | |
| VG13 | LC1; WIL1b | 99.38 | N/A | N/A | N/A | N/A | |
| VG14 * | N/A | N/A | N/A | N/A | LC3,4,5,11,12,13; WIL1,2,7,8 * | 97.47 | |
| Single-Sample Variant Group | VG15 | LC3 | 99.38 | N/A | N/A | LC3 | 97.47 |
| VG16 | LC15 | 99.38 | LC15 | 99.45 | LC15 | 98.99 | |
| VG17 | LC10 | 99.59 | N/A | N/A | LC10 | 98.99 | |
| VG18 | WIL4 | 99.59 | WIL4 | 98.9 | WIL4 | 98.99 | |
| VG19 | WIL7 | 98.97 | WIL7 | 99.18 | N/A | N/A | |
| VG20 | WIL8 | 98.97 | WIL8 | 99.18 | N/A | N/A | |
| VG21 | N/A | N/A | N/A | N/A | WIL3 | 98.99 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Kinoti, W.M.; Habili, N.; Tyerman, S.D.; Rinaldo, A.; Constable, F.E. Genetic Diversity of Grapevine Virus A in Three Australian Vineyards Using Amplicon High Throughput Sequencing (Amplicon-HTS). Viruses 2024, 16, 42. https://doi.org/10.3390/v16010042
Wu Q, Kinoti WM, Habili N, Tyerman SD, Rinaldo A, Constable FE. Genetic Diversity of Grapevine Virus A in Three Australian Vineyards Using Amplicon High Throughput Sequencing (Amplicon-HTS). Viruses. 2024; 16(1):42. https://doi.org/10.3390/v16010042
Chicago/Turabian StyleWu, Qi, Wycliff M. Kinoti, Nuredin Habili, Stephen D. Tyerman, Amy Rinaldo, and Fiona E. Constable. 2024. "Genetic Diversity of Grapevine Virus A in Three Australian Vineyards Using Amplicon High Throughput Sequencing (Amplicon-HTS)" Viruses 16, no. 1: 42. https://doi.org/10.3390/v16010042