
Att-BEVFusion: An Object Detection Algorithm for Camera and LiDAR Fusion Under BEV Features


Abstract
1. Introduction
- (1)
- An implicit module was developed to convert camera view features into BEV features, along with a module for transforming LiDAR point cloud data into BEV features. This facilitates the alignment of camera view features with LiDAR BEV features, enhancing feature fusion.
- (2)
- An attention mechanism was added. During the construction of the BEV feature fusion module for camera and LiDAR data, a channel attention mechanism was introduced to capture important features. The issue caused by the channel attention mechanism, namely the neglect of global information in the feature map, is addressed by further designing a feature fusion-based self-attention mechanism. This helps to avoid limitations when handling long-range dependencies and the gradual loss of information during transmission.
- (3)
- We trained, validated, and tested our algorithms on the autonomous driving dataset nuScenes. Experiments show that the detection accuracy of the proposed Att-BEVFusion approach outperforms the most popular publicly available results, achieving an outstanding performance of 72.0% mAP and 74.3% NDS in the 3D object detection task, which is of great significance for enhancing the robustness and reliability of intelligent vehicle perception.
2. Related Work
2.1. Camera-Based 3D Object Detection
2.2. Three-Dimensional Object Detection Based on LiDAR
2.3. Three-Dimensional Object Detection Based on Multi-Sensor Fusion
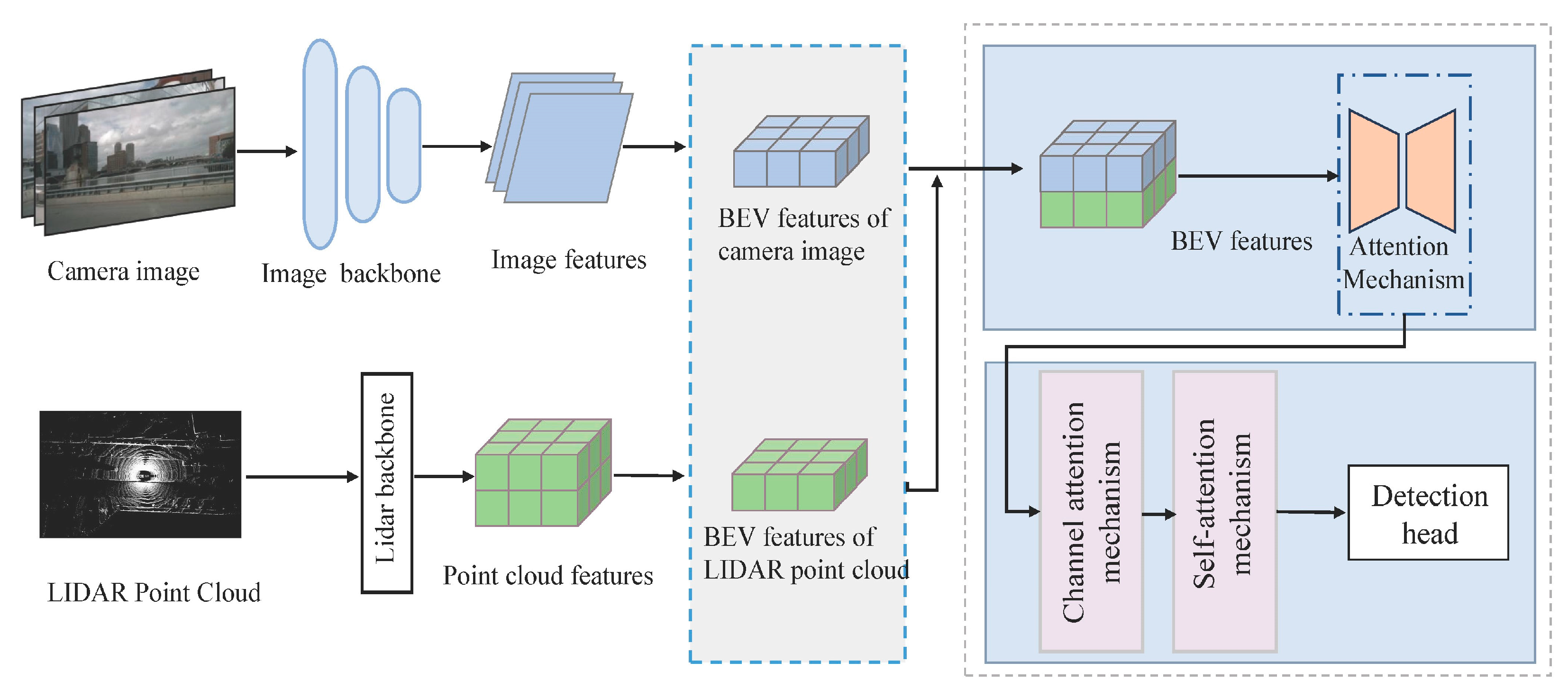
3. General Structure
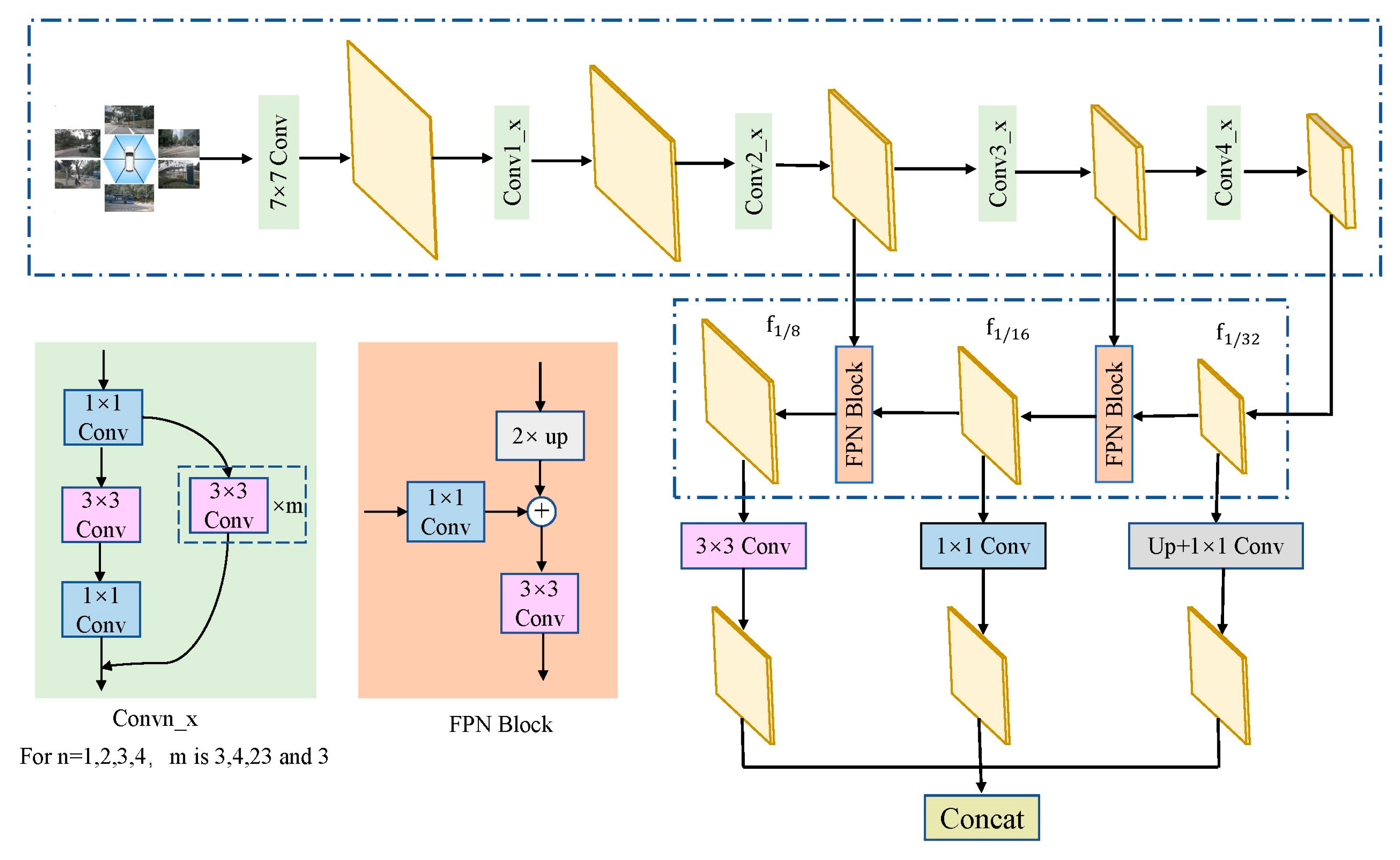
3.1. Image Feature Extraction and Construction of BEV Features
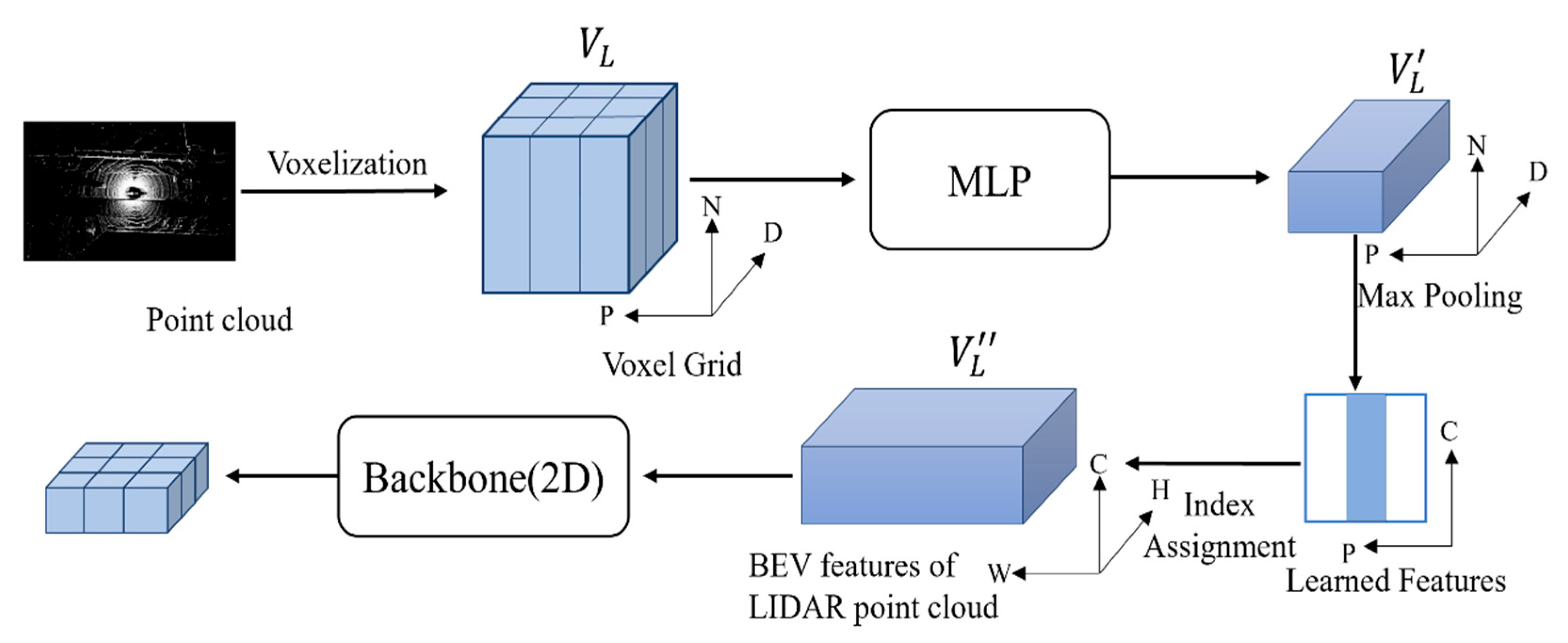
3.2. Transformation of LIDAR Features to BEV Features
3.3. BEV Feature Fusion and Object Detection
3.3.1. Channel Attention Mechanism for Camera and LiDAR BEV Feature Fusion (CAM)
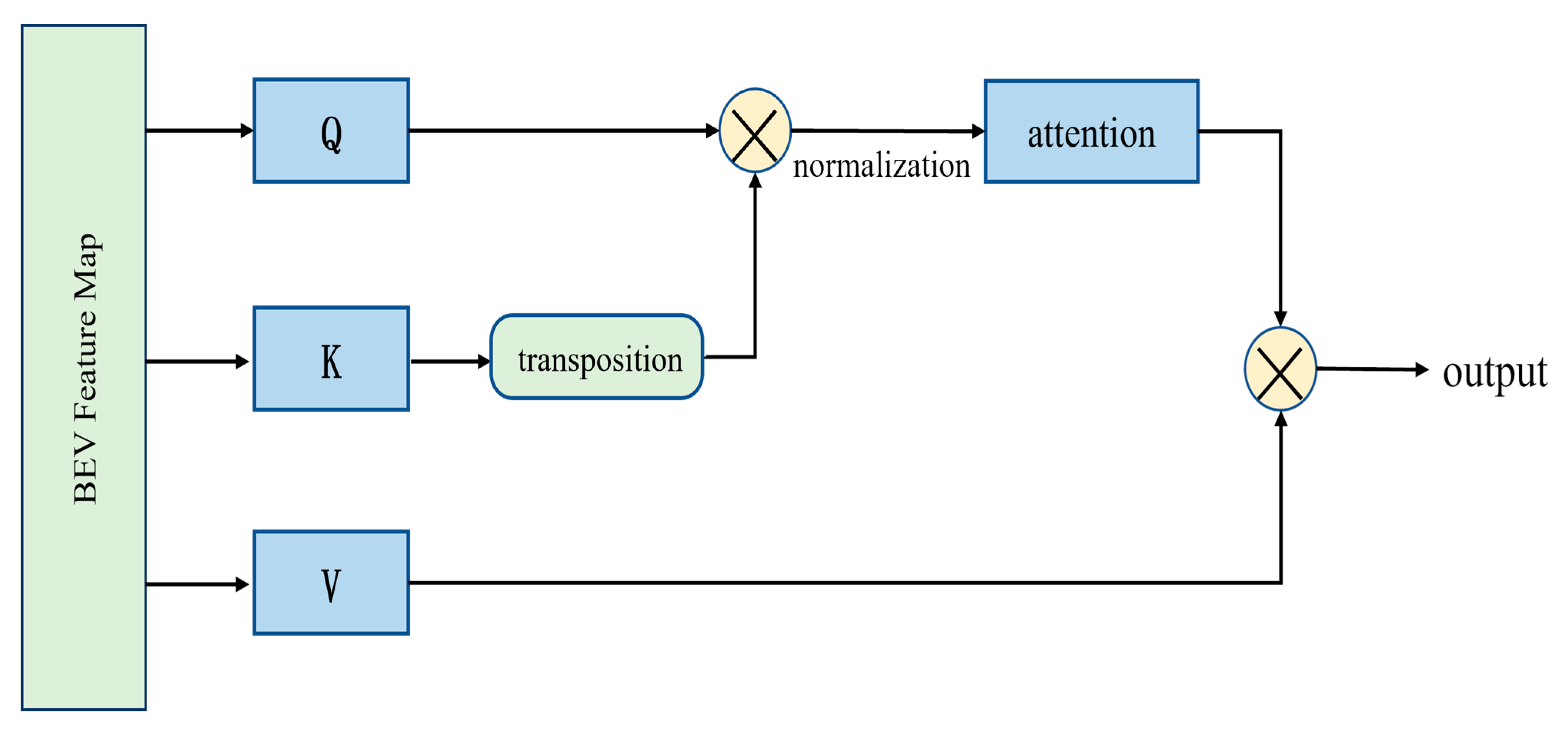
3.3.2. Self-Attention Mechanism of Feature Fusion (SAM)
3.3.3. Three-Dimensional Object Detection
3.4. Loss Function
4. Experimentation
4.1. Datasets
4.2. Evaluation Standards
4.3. Experimental Details
4.4. Test Results and Comparison
4.5. Ablation Experiments
4.5.1. Quantitative Analyses
4.5.2. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Zhou, C.; Shang, G.; Wang, X.; Li, Z.; Xu, C.; Hu, K. SLAM overview: From single sensor to heterogeneous fusion. Remote Sens. 2022, 14, 6033. [Google Scholar] [CrossRef]
- Li, H.; Sima, C.; Dai, J.; Wang, W.; Lu, L.; Wang, H.; Zeng, J.; Li, Z.; Yang, J.; Deng, H. Delving into the devils of bird’s-eye-view perception: A review, evaluation and recipe. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2151–2170. [Google Scholar] [CrossRef] [PubMed]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. Pointaugmenting: Cross-modal augmentation for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11794–11803. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10386–10393. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Fast-CLOCs: Fast camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 187–196. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Zhou, Q.; Yu, C. Point rcnn: An angle-free framework for rotated object detection. Remote Sens. 2022, 14, 2605. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Huang, J.; Huang, G. Bevpoolv2: A cutting-edge implementation of bevdet toward deployment. arXiv 2022, arXiv:2211.17111. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Li, M.; Zhang, Y.; Ma, X.; Qu, Y.; Fu, Y. BEV-DG: Cross-Modal Learning under Bird’s-Eye View for Domain Generalization of 3D Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11632–11642. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Shi, P.; Liu, Z.; Dong, X.; Yang, A. CL-fusionBEV: 3D object detection method with camera-LiDAR fusion in Bird’s Eye View. Complex Intell. Syst. 2024, 10, 7681–7696. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ma, Y.; Wang, T.; Bai, X.; Yang, H.; Hou, Y.; Wang, Y.; Qiao, Y.; Yang, R.; Manocha, D.; Zhu, X. Vision-centric bev perception: A survey. arXiv 2022, arXiv:2208.02797. [Google Scholar] [CrossRef] [PubMed]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV; Springer: Cham, Switzerland, 2020; pp. 194–210. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; pp. 1477–1485. [Google Scholar]
- Shi, G.; Li, R.; Ma, C. Pillarnet: Real-time and high-performance pillar-based 3d object detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 35–52. [Google Scholar]
- Shi, P.; Dong, X.; Yang, A. Research Progress on Bev Perception Algorithms for Autonomous Driving: A Review. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4790559 (accessed on 21 October 2024).
- Wang, G.; Tian, B.; Zhang, Y.; Chen, L.; Cao, D.; Wu, J. Multi-view adaptive fusion network for 3D object detection. arXiv 2020, arXiv:2011.00652. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Shin, K.; Kwon, Y.P.; Tomizuka, M. Roarnet: A robust 3d object detection based on region approximation refinement. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2510–2515. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Honolulu, HI, USA, 21–26 July 2017, pp. 2117–2125.
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- MMDetection3D Contributors. OpenMMLab’s Next-Generation Platform for General 3D Object Detection. 2020. Available online: https://openmmlab.medium.com/mmdetection3d-the-next-generation-3d-object-detection-platform-8a17d9292d3c (accessed on 21 October 2024).
- Imambi, S.; Prakash, K.B.; Kanagachidambaresan, G. PyTorch. In Programming with TensorFlow: Solution for Edge Computing Applications; Springer: Cham, Switzerland, 2021; pp. 87–104. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Qiao, Y.; Dai, J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 1–18. [Google Scholar]
- Yang, L.; Yu, K.; Tang, T.; Li, J.; Yuan, K.; Wang, L.; Zhang, X.; Chen, P. Bevheight: A robust framework for vision-based roadside 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21611–21620. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Han, J.; Sun, A. DeepRouting: A deep neural network approach for ticket routing in expert network. In Proceedings of the 2020 IEEE International Conference on Services Computing (SCC), Beijing, China, 7–11 November 2020; pp. 386–393. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1090–1099. [Google Scholar]
- Xu, S.; Zhou, D.; Fang, J.; Yin, J.; Bin, Z.; Zhang, L. Fusionpainting: Multimodal fusion with adaptive attention for 3d object detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3047–3054. [Google Scholar]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. Bevfusion: A simple and robust lidar-camera fusion framework. Adv. Neural Inf. Process. Syst. 2022, 35, 10421–10434. [Google Scholar]
- Cai, H.; Zhang, Z.; Zhou, Z.; Li, Z.; Ding, W.; Zhao, J. BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird’s-Eye-View via Cross-Modality Guidance and Temporal Aggregation. arXiv 2023, arXiv:2303.17099. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVII; Springer: Cham, Switzerland, 2020; pp. 720–736. [Google Scholar]
- Yang, Z.; Chen, J.; Miao, Z.; Li, W.; Zhu, X.; Zhang, L. Deepinteraction: 3d object detection via modality interaction. Adv. Neural Inf. Process. Syst. 2022, 35, 1992–2005. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Modality | mAP | NDS | Latency (ms) | Car | Truck | C.V. | Bus | Trailer | Barrier | Motor. | Bicycle | Ped. | T.C. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BEVDet [15] | C | 42.4 | 47.6 | - | 64.3 | 35.0 | 16.2 | 35.8 | 35.4 | 61.4 | 44.8 | 29.6 | 41.1 | 60.1 |
| BEVFormer [37] | C | 48.1 | 56.9 | - | 67.7 | 39.2 | 22.9 | 35.7 | 39.6 | 62.5 | 47.9 | 40.7 | 54.4 | 70.3 |
| BEVHeight [38] | C | 53.2 | 61.0 | - | 68.6 | 44.8 | 27.4 | 42.8 | 48.5 | 69.8 | 54.2 | 45.9 | 57.7 | 72.6 |
| CenterPoint [39] | L | 60.3 | 67.3 | 80.7 | 85.2 | 53.5 | 20.0 | 63.6 | 56.6 | 71.1 | 59.5 | 30.7 | 84.6 | 78.4 |
| Deeproute [40] | L | 60.6 | 68.1 | - | 82.9 | 51.5 | 25.1 | 59.5 | 47.6 | 65.2 | 68.6 | 44.3 | 84.4 | 76.4 |
| TransFusion-L [41] | L | 65.5 | 70.2 | - | 86.3 | 56.7 | 28.1 | 66.2 | 58.7 | 78.0 | 68.4 | 44.2 | 86.2 | 82.0 |
| 3D-CVF [45] | L + C | 52.7 | 62.4 | - | 83.3 | 45.1 | 15.7 | 48.6 | 49.5 | 65.7 | 51.2 | 30.6 | 74.1 | 62.9 |
| FusionPainting [42] | L + C | 68.1 | 72.0 | - | 87.1 | 60.8 | 30.0 | 68.5 | 61.7 | 71.8 | 74.7 | 53.5 | 88.3 | 85.0 |
| TransFusion [41] | L + C | 68.9 | 71.5 | 156.6 | 87.5 | 59.9 | 33.0 | 68.1 | 60.9 | 78.1 | 73.5 | 52.9 | 88.4 | 86.7 |
| BEVFusion [43] | L + C | 70.2 | 72.3 | - | 88.6 | 60.1 | 39.3 | 69.8 | 63.8 | 80.0 | 74.1 | 51.0 | 89.2 | 86.5 |
| DeepInteraction [46] | L + C | 70.8 | 73.7 | - | 87.7 | 60.4 | 37.9 | 70.6 | 63.8 | 80.4 | 75.4 | 54.5 | 91.7 | 87.2 |
| BEVFusion [19] | L + C | 71.3 | 73.4 | 119.2 | 88.3 | 70.0 | 34.3 | 69.1 | 62.1 | 78.5 | 72.1 | 52.0 | 89.2 | 86.7 |
| BEVFusion4D [44] | L + C | 71.9 | 73.7 | - | 88.8 | 64.0 | 38.0 | 72.8 | 65.0 | 79.8 | 77.0 | 56.4 | 90.4 | 87.1 |
| Ours | L + C | 72.0 | 74.3 | 141.3 | 88.9 | 64.8 | 30.2 | 73.5 | 64.2 | 80.0 | 78.9 | 60.0 | 91.8 | 87.7 |
| Baseline | CBT | CAM | SAM | mAP | NDS | Car | Bicycle | Ped. | |
|---|---|---|---|---|---|---|---|---|---|
| a | √ | -- | -- | -- | 58.4 | 66.5 | 84.0 | 54.3 | 83.1 |
| b | √ | √ | -- | -- | 59.2 | 68.2 | 85.2 | 55.6 | 83.6 |
| c | √ | √ | √ | -- | 61.3 | 69.6 | 86.6 | 56.2 | 84.1 |
| d | √ | √ | √ | √ | 62.3 | 70.1 | 87.2 | 58.6 | 85.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, P.; Zhou, M.; Dong, X.; Yang, A. Att-BEVFusion: An Object Detection Algorithm for Camera and LiDAR Fusion Under BEV Features. World Electr. Veh. J. 2024, 15, 539. https://doi.org/10.3390/wevj15110539
Shi P, Zhou M, Dong X, Yang A. Att-BEVFusion: An Object Detection Algorithm for Camera and LiDAR Fusion Under BEV Features. World Electric Vehicle Journal. 2024; 15(11):539. https://doi.org/10.3390/wevj15110539
Chicago/Turabian StyleShi, Peicheng, Mengru Zhou, Xinlong Dong, and Aixi Yang. 2024. "Att-BEVFusion: An Object Detection Algorithm for Camera and LiDAR Fusion Under BEV Features" World Electric Vehicle Journal 15, no. 11: 539. https://doi.org/10.3390/wevj15110539
APA StyleShi, P., Zhou, M., Dong, X., & Yang, A. (2024). Att-BEVFusion: An Object Detection Algorithm for Camera and LiDAR Fusion Under BEV Features. World Electric Vehicle Journal, 15(11), 539. https://doi.org/10.3390/wevj15110539