
Leveraging Generative Artificial Intelligence Models in Patient Education on Inferior Vena Cava Filters


Abstract
1. Introduction
2. Materials and Methods
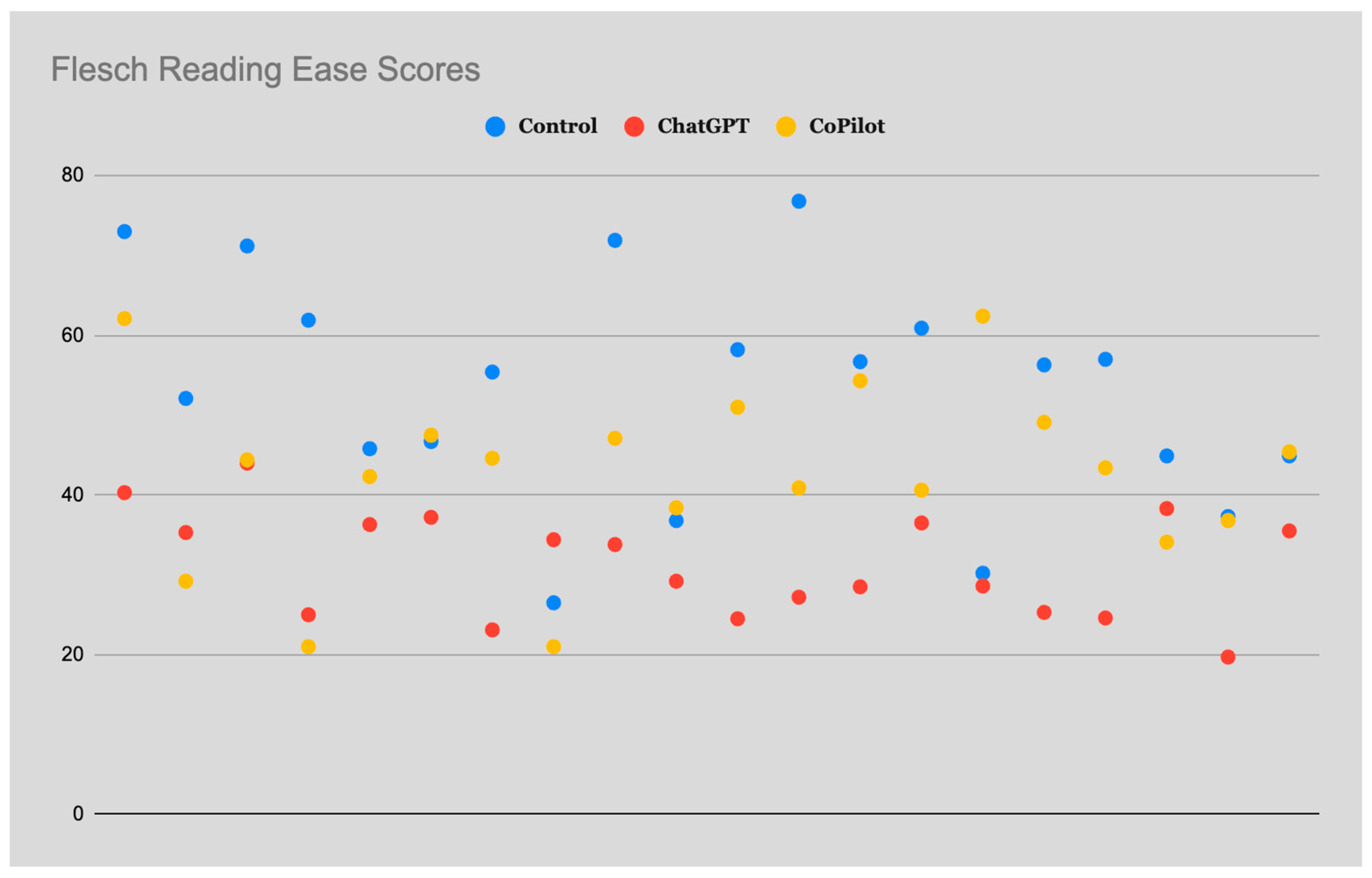
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Covello, B.; Radvany, M. Back to the Basics: Inferior Vena Cava Filters. Semin. Interv. Radiol. 2022, 39, 226–233. [Google Scholar] [CrossRef] [PubMed]
- Inferior Vena Cava Filters—PubMed. Available online: https://pubmed.ncbi.nlm.nih.gov/23787230/ (accessed on 12 December 2023).
- Molvar, C. Inferior Vena Cava Filtration in the Management of Venous Thromboembolism: Filtering the Data. Semin. Interv. Radiol. 2012, 29, 204–217. [Google Scholar] [CrossRef] [PubMed]
- Marron, R.M.; Rali, P.; Hountras, P.; Bull, T.M. Inferior Vena Cava Filters: Past, Present, and Future. Chest 2020, 158, 2579–2589. [Google Scholar] [CrossRef] [PubMed]
- Winokur, R.S.; Bassik, N.; Madoff, D.C.; Trost, D. Radiologists’ Field Guide to Permanent Inferior Vena Cava Filters. Am. J. Roentgenol. 2019, 213, 762–767. [Google Scholar] [CrossRef] [PubMed]
- Patient Education on the Internet: Opportunities and Pitfall…: Spine. Available online: https://journals.lww.com/spinejournal/abstract/2002/04010/patient_education_on_the_internet__opportunities.19.aspx (accessed on 6 April 2024).
- Internet Based Patient Education Improves Informed Consent for Elective Orthopaedic Surgery: A Randomized Controlled Trial | BMC Musculoskeletal Disorders | Full Text. Available online: https://bmcmusculoskeletdisord.biomedcentral.com/articles/10.1186/s12891-015-0466-9 (accessed on 6 April 2024).
- Wald, H.S.; Dube, C.E.; Anthony, D.C. Untangling the Web--the Impact of Internet Use on Health Care and the Physician-Patient Relationship. Patient Educ. Couns. 2007, 68, 218–224. [Google Scholar] [CrossRef] [PubMed]
- Majerczak, P.; Strzelecki, A. Trust, Media Credibility, Social Ties, and the Intention to Share towards Information Verification in an Age of Fake News. Behav. Sci. 2022, 12, 51. [Google Scholar] [CrossRef] [PubMed]
- Ko, T.K.; Yun Tan, D.J.; Hadeed, S. IVC Filter—Assessing the Readability and Quality of Patient Information on the Internet. J. Vasc. Surg. Venous Lymphat. Disord. 2024, 12, 101695. [Google Scholar] [CrossRef]
- Almagazzachi, A.; Mustafa, A.; Eighaei Sedeh, A.; Vazquez Gonzalez, A.E.; Polianovskaia, A.; Abood, M.; Abdelrahman, A.; Muyolema Arce, V.; Acob, T.; Saleem, B. Generative Artificial Intelligence in Patient Education: ChatGPT Takes on Hypertension Questions. Cureus 2024, 16, e53441. [Google Scholar] [CrossRef] [PubMed]
- Reddy, S. Generative AI in Healthcare: An Implementation Science Informed Translational Path on Application, Integration and Governance. Implement. Sci. 2024, 19, 27. [Google Scholar] [CrossRef]
- Karabacak, M.; Ozkara, B.B.; Margetis, K.; Wintermark, M.; Bisdas, S. The Advent of Generative Language Models in Medical Education. JMIR Med. Educ. 2023, 9, e48163. [Google Scholar] [CrossRef]
- Semeraro, F.; Gamberini, L.; Carmona, F.; Monsieurs, K.G. Clinical Questions on Advanced Life Support Answered by Artificial Intelligence. A Comparison between ChatGPT, Google Bard and Microsoft Copilot. Resuscitation 2024, 195, 110114. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, C.; Bhattacharya, M.; Pal, S.; Lee, S.-S. From Machine Learning to Deep Learning: Advances of the Recent Data-Driven Paradigm Shift in Medicine and Healthcare. Curr. Res. Biotechnol. 2024, 7, 100164. [Google Scholar] [CrossRef]
- Shen, T.S.; Driscoll, D.A.; Islam, W.; Bovonratwet, P.; Haas, S.B.; Su, E.P. Modern Internet Search Analytics and Total Joint Arthroplasty: What Are Patients Asking and Reading Online? J. Arthroplasty 2021, 36, 1224–1231. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.P.; Ramprasad, A.; Luu, A.; Zaidi, R.; Siddiqui, Z.; Pham, T. Health Literacy Analytics of Accessible Patient Resources in Cardiovascular Medicine: What Are Patients Wanting to Know? Kans. J. Med. 2023, 16, 309–315. [Google Scholar] [CrossRef] [PubMed]
- Sajjadi, N.B.; Shepard, S.; Ottwell, R.; Murray, K.; Chronister, J.; Hartwell, M.; Vassar, M. Examining the Public’s Most Frequently Asked Questions Regarding COVID-19 Vaccines Using Search Engine Analytics in the United States: Observational Study. JMIR Infodemiology 2021, 1, e28740. [Google Scholar] [CrossRef] [PubMed]
- Fassas, S.N.; Peterson, A.M.; Farrokhian, N.; Zonner, J.G.; Cummings, E.L.; Arambula, Z.; Chiu, A.G.; Goyal Fox, M. Sinus Surgery and Balloon Sinuplasty: What Do Patients Want to Know? Otolaryngol. Head Neck Surg. 2022, 167, 777–784. [Google Scholar] [CrossRef]
- ChatGPT. Available online: https://openai.com/chatgpt (accessed on 6 April 2024).
- Copilot. Available online: https://copilot.microsoft.com/ (accessed on 6 April 2024).
- Daraz, L.; Morrow, A.S.; Ponce, O.J.; Farah, W.; Katabi, A.; Majzoub, A.; Seisa, M.O.; Benkhadra, R.; Alsawas, M.; Larry, P.; et al. Readability of Online Health Information: A Meta-Narrative Systematic Review. Am. J. Med. Qual. Off. J. Am. Coll. Med. Qual. 2018, 33, 487–492. [Google Scholar] [CrossRef] [PubMed]
- Eltorai, A.E.M.; Naqvi, S.S.; Ghanian, S.; Eberson, C.P.; Weiss, A.-P.C.; Born, C.T.; Daniels, A.H. Readability of Invasive Procedure Consent Forms. Clin. Transl. Sci. 2015, 8, 830–833. [Google Scholar] [CrossRef] [PubMed]
- Kher, A.; Johnson, S.; Griffith, R. Readability Assessment of Online Patient Education Material on Congestive Heart Failure. Adv. Prev. Med. 2017, 2017, 9780317. [Google Scholar] [CrossRef]
- Lucy, A.T.; Rakestraw, S.L.; Stringer, C.; Chu, D.; Grams, J.; Stahl, R.; Mustian, M.N. Readability of Patient Education Materials for Bariatric Surgery. Surg. Endosc. 2023, 37, 6519–6525. [Google Scholar] [CrossRef]
- Szabó, P.; Bíró, É.; Kósa, K. Readability and Comprehension of Printed Patient Education Materials. Front. Public Health 2021, 9, 725840. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.P.; Qureshi, F.M.; Borthwick, K.G.; Singh, S.; Menon, S.; Barthel, B. Comprehension Profile of Patient Education Materials in Endocrine Care. Kans. J. Med. 2022, 15, 247–252. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, N.; Baird, G.L.; Garg, M. Examining the Reading Level of Internet Medical Information for Common Internal Medicine Diagnoses. Am. J. Med. 2016, 129, 637–639. [Google Scholar] [CrossRef] [PubMed]
- Phan, A.; Jubril, A.; Menga, E.; Mesfin, A. Readability of the Most Commonly Accessed Online Patient Education Materials Pertaining to Surgical Treatments of the Spine. World Neurosurg. 2021, 152, e583–e588. [Google Scholar] [CrossRef]
- Allen-Meares, P.; Lowry, B.; Estrella, M.L.; Mansuri, S. Health Literacy Barriers in the Health Care System: Barriers and Opportunities for the Profession. Health Soc. Work 2020, 45, 62–64. [Google Scholar] [CrossRef]
- Miller, T.A. Health Literacy and Adherence to Medical Treatment in Chronic and Acute Illness: A Meta-Analysis. Patient Educ. Couns. 2016, 99, 1079–1086. [Google Scholar] [CrossRef] [PubMed]
- Shahid, R.; Shoker, M.; Chu, L.M.; Frehlick, R.; Ward, H.; Pahwa, P. Impact of Low Health Literacy on Patients’ Health Outcomes: A Multicenter Cohort Study. BMC Health Serv. Res. 2022, 22, 1148. [Google Scholar] [CrossRef] [PubMed]
- Cascella, M.; Semeraro, F.; Montomoli, J.; Bellini, V.; Piazza, O.; Bignami, E. The Breakthrough of Large Language Models Release for Medical Applications: 1-Year Timeline and Perspectives. J. Med. Syst. 2024, 48, 22. [Google Scholar] [CrossRef]
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.-N.; Laleh, N.G.; Löffler, C.M.L.; Schwarzkopf, S.-C.; Unger, M.; Veldhuizen, G.P.; et al. The Future Landscape of Large Language Models in Medicine. Commun. Med. 2023, 3, 141. [Google Scholar] [CrossRef]
- Nazir, A.; Wang, Z. A Comprehensive Survey of ChatGPT: Advancements, Applications, Prospects, and Challenges. Meta-Radiol. 2023, 1, 100022. [Google Scholar] [CrossRef]
- Tan, T.F.; Thirunavukarasu, A.J.; Campbell, J.P.; Keane, P.A.; Pasquale, L.R.; Abramoff, M.D.; Kalpathy-Cramer, J.; Lum, F.; Kim, J.E.; Baxter, S.L.; et al. Generative Artificial Intelligence Through ChatGPT and Other Large Language Models in Ophthalmology. Ophthalmol. Sci. 2023, 3, 100394. [Google Scholar] [CrossRef] [PubMed]
- Digital Patient Education on Xanthelasma Palpebrarum: A Content Analysis—PMC. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10605081/ (accessed on 12 December 2023).

{kind=link}
| Questions |
|---|
| What is the filter for the inferior vena cava? |
| What happens if IVC filter gets clogged? |
| Who should get an IVC filter? |
| When is it too late to remove IVC filter? |
| What are symptoms of IVC filter problems? |
| Can you still have a stroke with an IVC filter? |
| Can an IVC filter stay in permanently? |
| Can you still get a clot with an IVC filter? |
| What is the success rate of IVC filter? |
| Do you need blood thinner after IVC filter? |
| What to expect after IVC filter placement? |
| How do you fix a clogged IVC filter? |
| Should I have my IVC filter removed? |
| Can IVC filter cause pulmonary embolism? |
| How long does an IVC filter procedure take? |
| Why would someone need an IVC filter? |
| Is IVC filter removal a major surgery? |
| What happens if an IVC filter cannot be removed? |
| What is the most common IVC filter complication? |
| Readability | Formula |
|---|---|
| Flesch Reading Ease | 206.835 − 1.015 (word count/sentence count) − 84.6 (syllable count/word count) |
| Flesch Kincaid | 0.39 (word count/sentence count) + 11.8(syllable count/word count) − 15.59 |
| Gunning Fog | 0.4 [(words/sentences) + 100 (total number of words with ≥3 syllables/words)] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, S.P.; Jamal, A.; Qureshi, F.; Zaidi, R.; Qureshi, F. Leveraging Generative Artificial Intelligence Models in Patient Education on Inferior Vena Cava Filters. Clin. Pract. 2024, 14, 1507-1514. https://doi.org/10.3390/clinpract14040121
Singh SP, Jamal A, Qureshi F, Zaidi R, Qureshi F. Leveraging Generative Artificial Intelligence Models in Patient Education on Inferior Vena Cava Filters. Clinics and Practice. 2024; 14(4):1507-1514. https://doi.org/10.3390/clinpract14040121
Chicago/Turabian StyleSingh, Som P., Aleena Jamal, Farah Qureshi, Rohma Zaidi, and Fawad Qureshi. 2024. "Leveraging Generative Artificial Intelligence Models in Patient Education on Inferior Vena Cava Filters" Clinics and Practice 14, no. 4: 1507-1514. https://doi.org/10.3390/clinpract14040121
APA StyleSingh, S. P., Jamal, A., Qureshi, F., Zaidi, R., & Qureshi, F. (2024). Leveraging Generative Artificial Intelligence Models in Patient Education on Inferior Vena Cava Filters. Clinics and Practice, 14(4), 1507-1514. https://doi.org/10.3390/clinpract14040121