1. Introduction
With the growing popularity of mobile terminals, Internet of Things (IoT), social networks, cloud computing and mobile commerce, myriad data are generated, and the era of big data is coming. The advent of big data has promoted the revolution of data-driven thinking and decision making. Governments, industry and academia have paid great attention to big data strategy, technologies and applications. More and more people worldwide have made tremendous efforts in large-scale heterogeneous data collection, organization, storage, analysis, mining and applications under the big data environment. Big data has become a hot topic of discussion. For example, Nature and Science published special issues “Big Data” in 2008 and “Dealing with Data” in 2011 respectively. In May 2011, the McKinsey global institute (MGI) released the research report “Big Data: The Next Frontier for Innovation, Competition, and Productivity” [
1]. In March 2012, U.S. President Office of Science and Technology Policy declared in public that the United States government would invest
$200 million to launch “The Big Data Research and Development Initiative” [
2]. At the same time, big data had been extensively applied into many fields, such as IoT, social networks, health care, intellisense, environment and sustainable development, and so on [
3]. For example, according to the UN Sustainable Development Goals (SDG) [
4], big data such as from satellite imagery and sensor networks make environment and development indicators increasingly measurable. Worldwide research institutions and scholars had devoted themselves to big data science research and wanted big data for sustainable development. However, more and more research outcomes have been emerging and growing rapidly [
5,
6,
7]. Moreover, the dynamic nature of a research front poses challenges for scientists, research policy makers, and many others to keep up with the rapid advances of the state of the art in science [
8]. It is still difficult for scholars to understand the current research situation and sustainable development trends of big data. Therefore, how to identify intellectual structure, to detect emerging trends and sudden changes of big data research is increasingly essential.
In recent years, with the rapidly increasing publications related to big data, some scholars have begun to aggregate relevant existing literatures, performed the bibliometric analysis, and visualized the intellectual structure, hotspots and evolution paths to provide knowledge support for other researchers in different fields based on bibliometrics [
9,
10,
11]. Bibliometrics comprehensively utilizes multi-disciplinary knowledge and methods, such as mathematics, statistics, philology, etc., to analyse the distribution regularities, the developments and research trends of a certain scientific field, and finally visualizes the research results. However, so far few quantitative depictions have been given of the intellectual structure and hotspots of big data research. A few existing surveys mainly focus on specific big data subfields and themes, such as big data and IoT applications on circular economy [
10], social networks, health care [
11], and supply chain [
12]. However, these surveys were absent in the panorama of the big data field and were not conducted on the sustainability of big data research. It is still difficult for readers to deeply understand the current intellectual structure and sustainable development directions of big data research.
In this paper, we performed a bibliometric analysis distinct from the above existing surveys in several aspects. Firstly, this study retrieved all journal articles of big data between 2002 and 2016 in the WoS database, which include Science Citation Index Expanded (SCI-EXPANDED) journals, Social Sciences Citation Index (SSCI) journals, and Arts & Humanities Citation Index (A&HCI) journals. Secondly, this study did not simply describe the traditional concentrated distribution regularities. More importantly, visualization techniques and co-word analysis were used to demonstrate visually the intellectual structures, collaboration networks, and research hotspots of big data between 2002 and 2016 from the following perspectives: publications distribution, core journals, core institutions and collaboration network, core authors and collaboration network, as well as high-frequency keywords network. It provided a vivid overall picture of big data research. This study will help would-be big data researchers know the current research situation, research gaps, what journals they should follow, what authors they should focus, how to seek co-researchers, and work out the details in big data research activities. Moreover, it will also be helpful to improve and upgrade the sustainable research and development, applications, and policy making of big data at different levels in the future. Thirdly, this study went beyond traditional citation counts. Journal co-citation analysis (JCA) and author co-citation analysis (ACA), provided by CiteSpace, were used to detect some special pioneers and journals in the big data field from the following perspectives: the most co-cited frequency, intellectual turning points, and highest citation bursts. These pioneers and journals had contributed to the sustainable development of big data research from different perspectives.
The paper is organized as follows: In
Section 2, we describe the methodology, including original data sources and research methods. In
Section 3, we demonstrate the bibliometric analysis results, and visualize the intellectual structure and hotspots of big data research. In particular, we detect the distribution characteristics, intellectual turning points, strongest citation bursts, and research hotspots. In
Section 4, we finally present the discussion and conclusions.
4. Discussion and Conclusions
In this study, we extracted the bibliometric data of 4927 effective journal articles listed in the WoS between 2002 and 2016, visualized the intellectual structure and hotspots of big data research from the bibliometric perspective, and presented the results in terms of publications distribution, journals distribution and co-citation network, institutions distribution and collaboration network, authors distribution, collaboration network and co-citation network, and keywords co-word network. The main findings of this study are as follows:
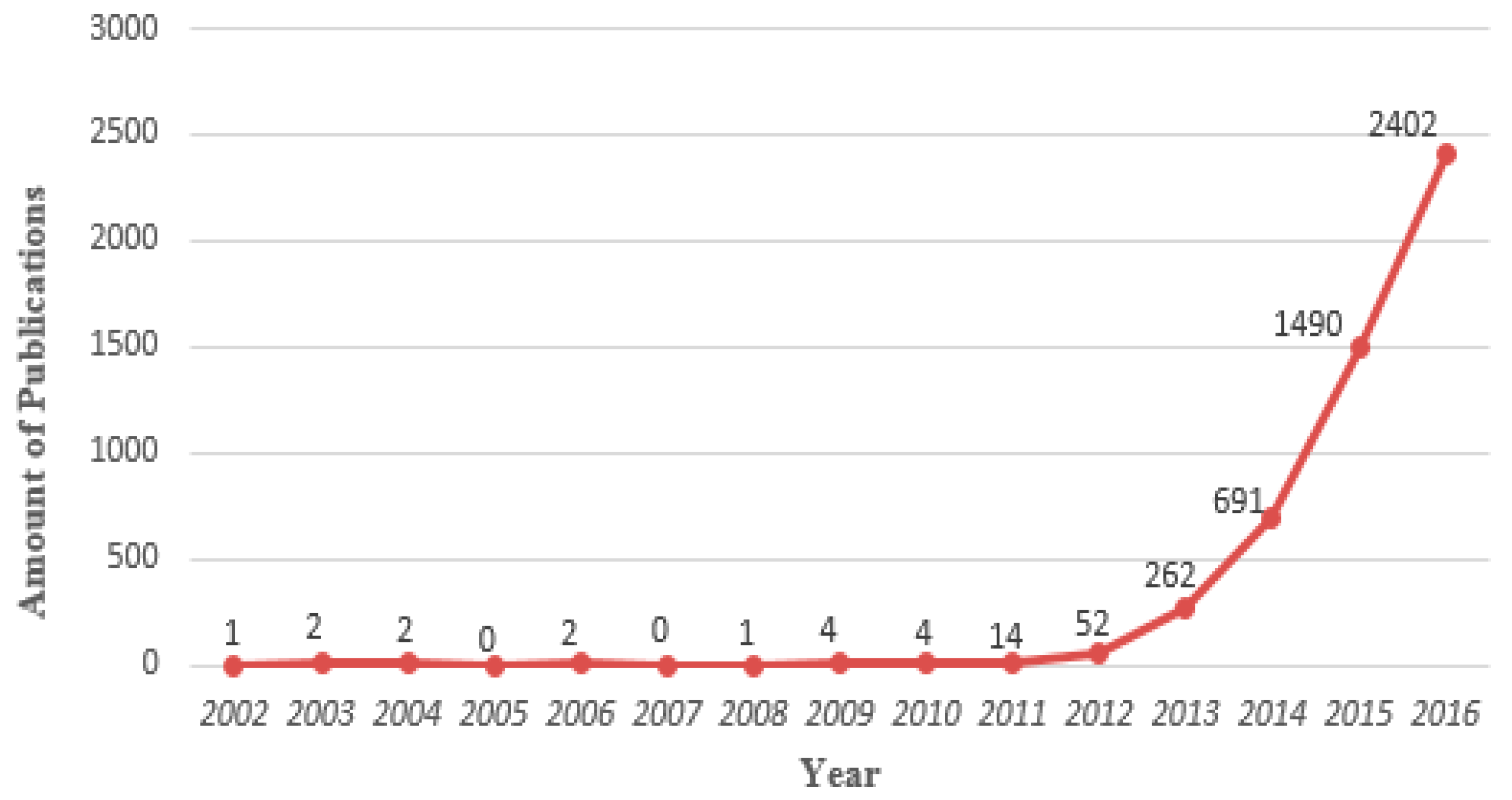
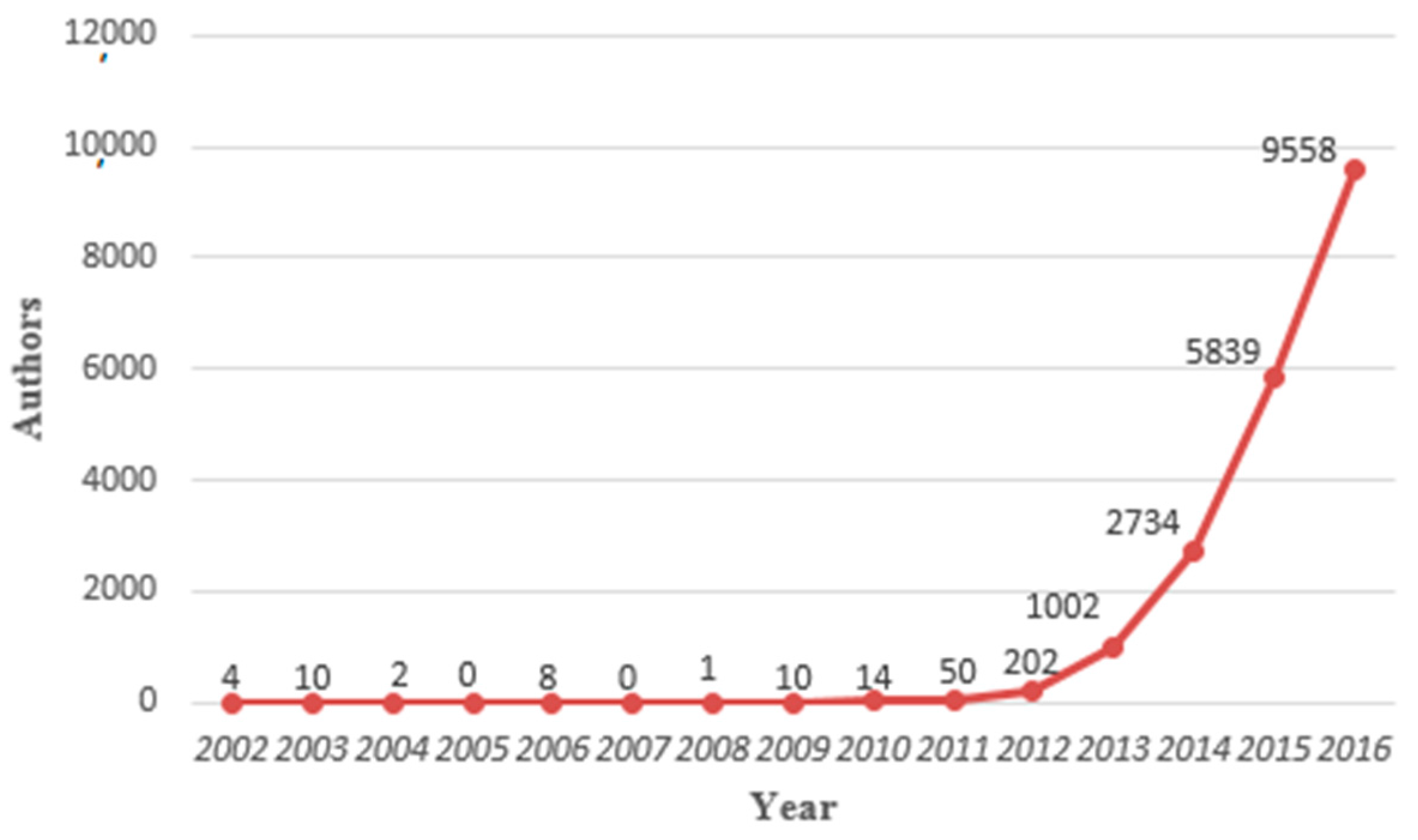
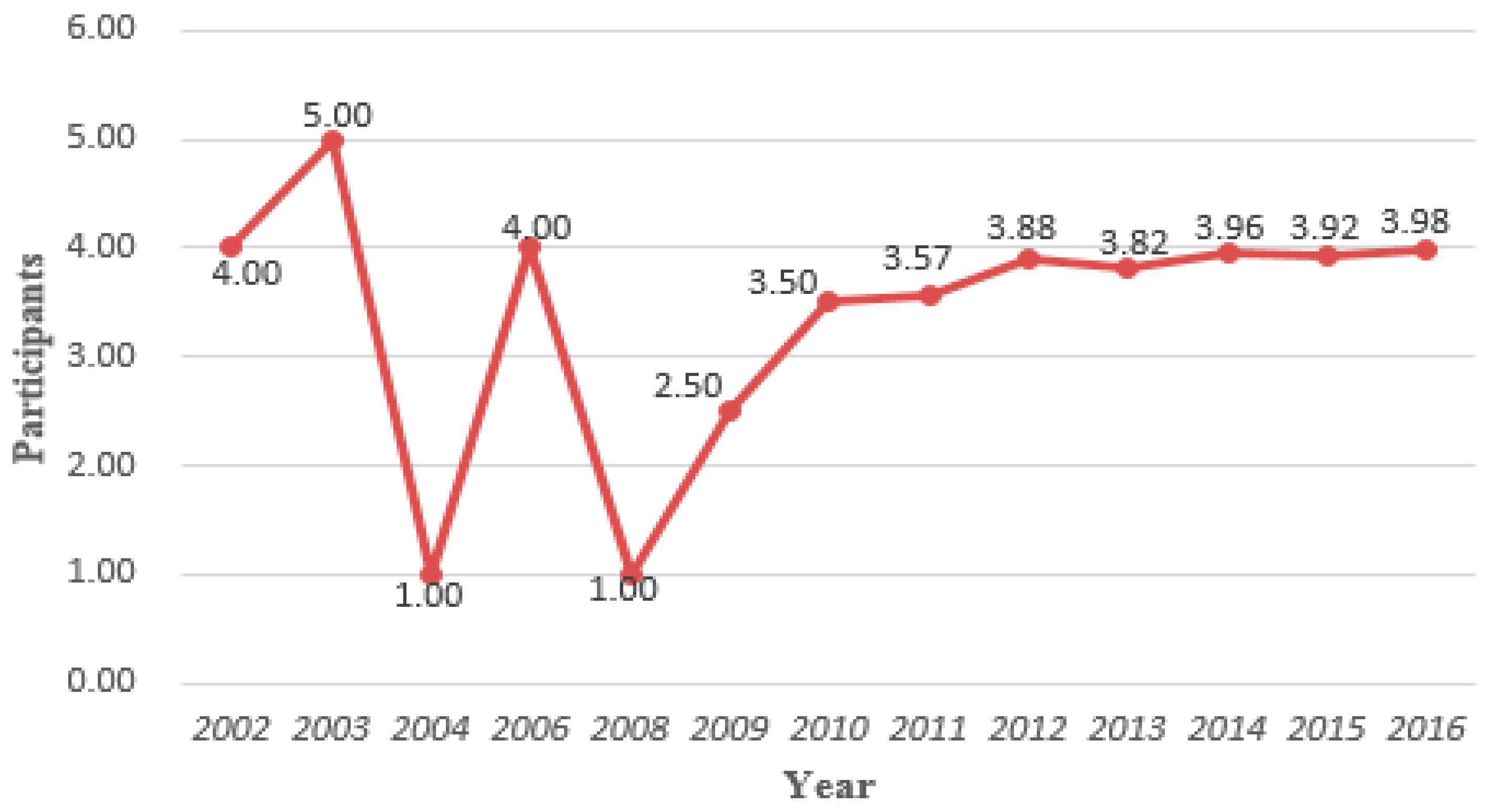
According to publications distribution, we found the annual growth trend of big data research outcomes and authors, as well as the changes of co-author numbers in each article. The research outcomes in the embryonic stage (2002–2009) were very few, but an exponential growth spurt was generated from 2010 to 2016. In addition, the growth trend of annual authors is similar to the annual publications distribution. Moreover, we found that the average number of participants per article in the big data field were between three and four authors.
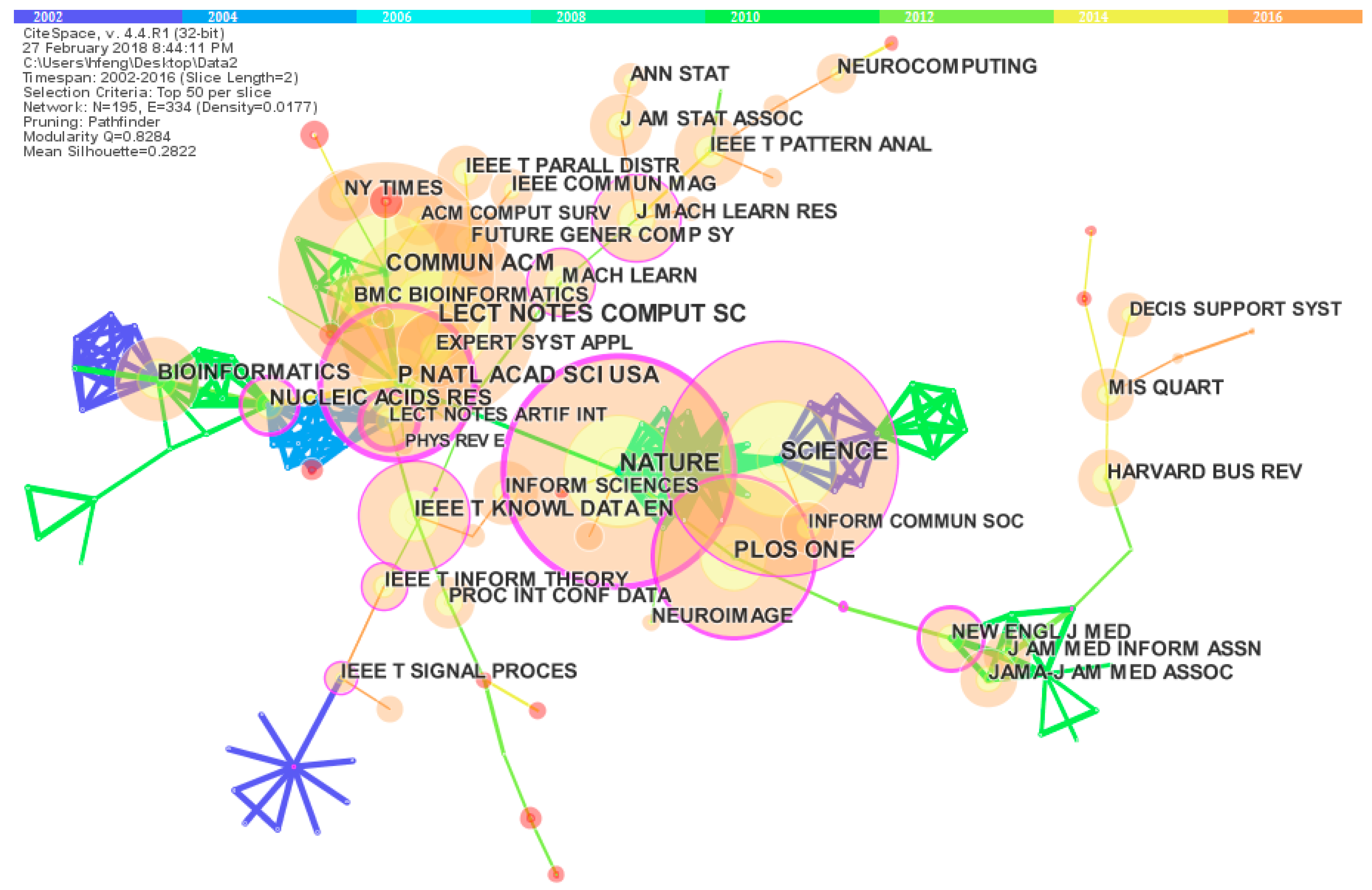
The current core journal with the most publications was PLoS One, followed by IEEE Access and Big Data. However, the top five co-citation journals, which contributed to the sustainable intellectual base formation of big data, were Nature, Science, Lecture Notes in Computer Science, PLoS One, and Communications of the ACM. Among them, Nature had the highest betweenness centrality. Moreover, the most categories of top 10 co-citation journals were multidisciplinary sciences and computer science, which is closely related to the nature of big data science.
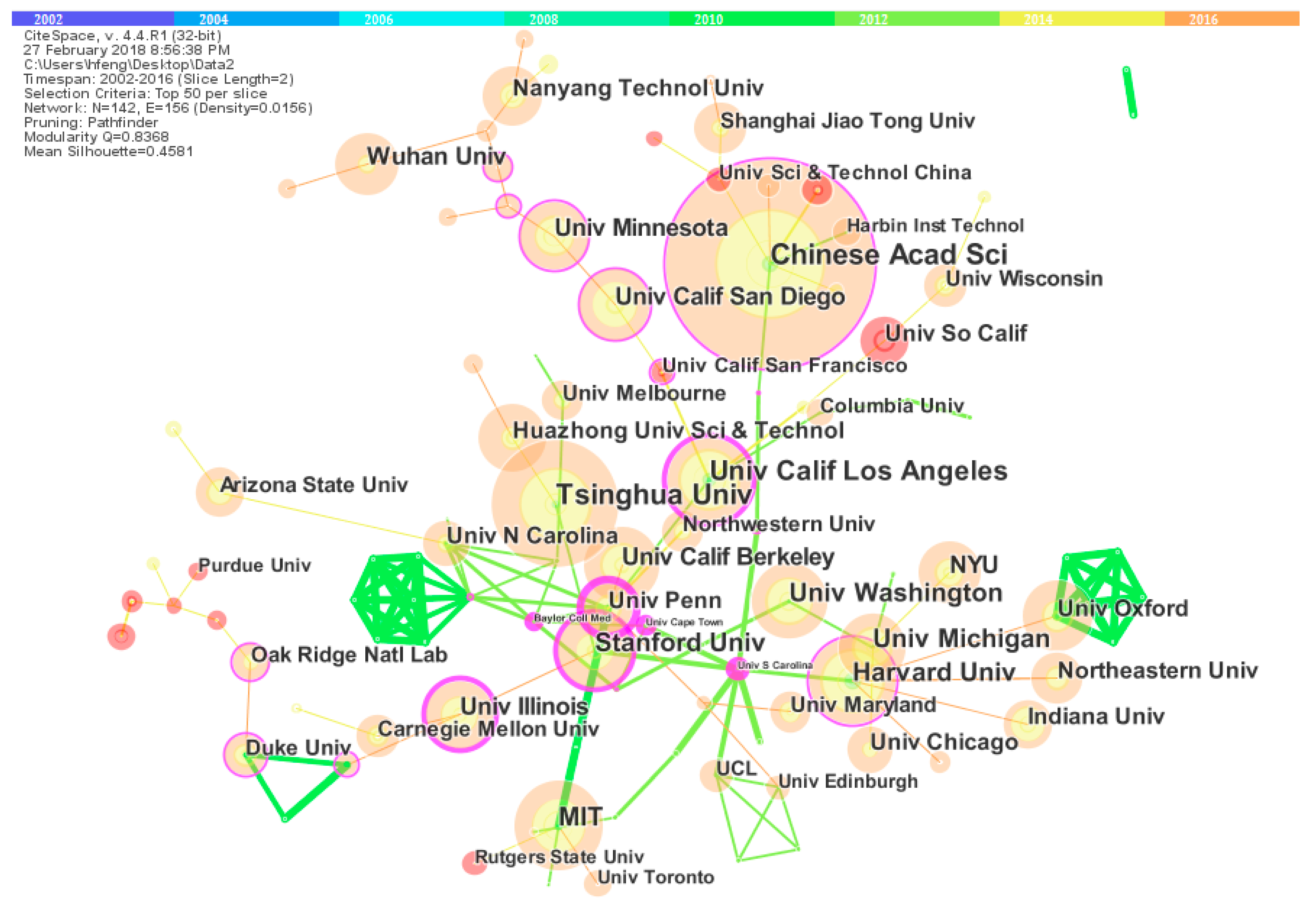
There was a wider scientific research collaboration among institutions in big data research. The top three core institutions in terms of publications were Chinese Academy of Science, Tsinghua University, and University of California, Los Angeles. However, the institutions with most publications had lower betweenness centrality scores, signifying that these institutions still were scattered and did not get general consent. Hence, the current research relationships among the institutions were rather weak and diffuse in the big data research field. With sustainable development and prosperity of big data research, the research collaboration relationships will be strengthened and increasingly firm.
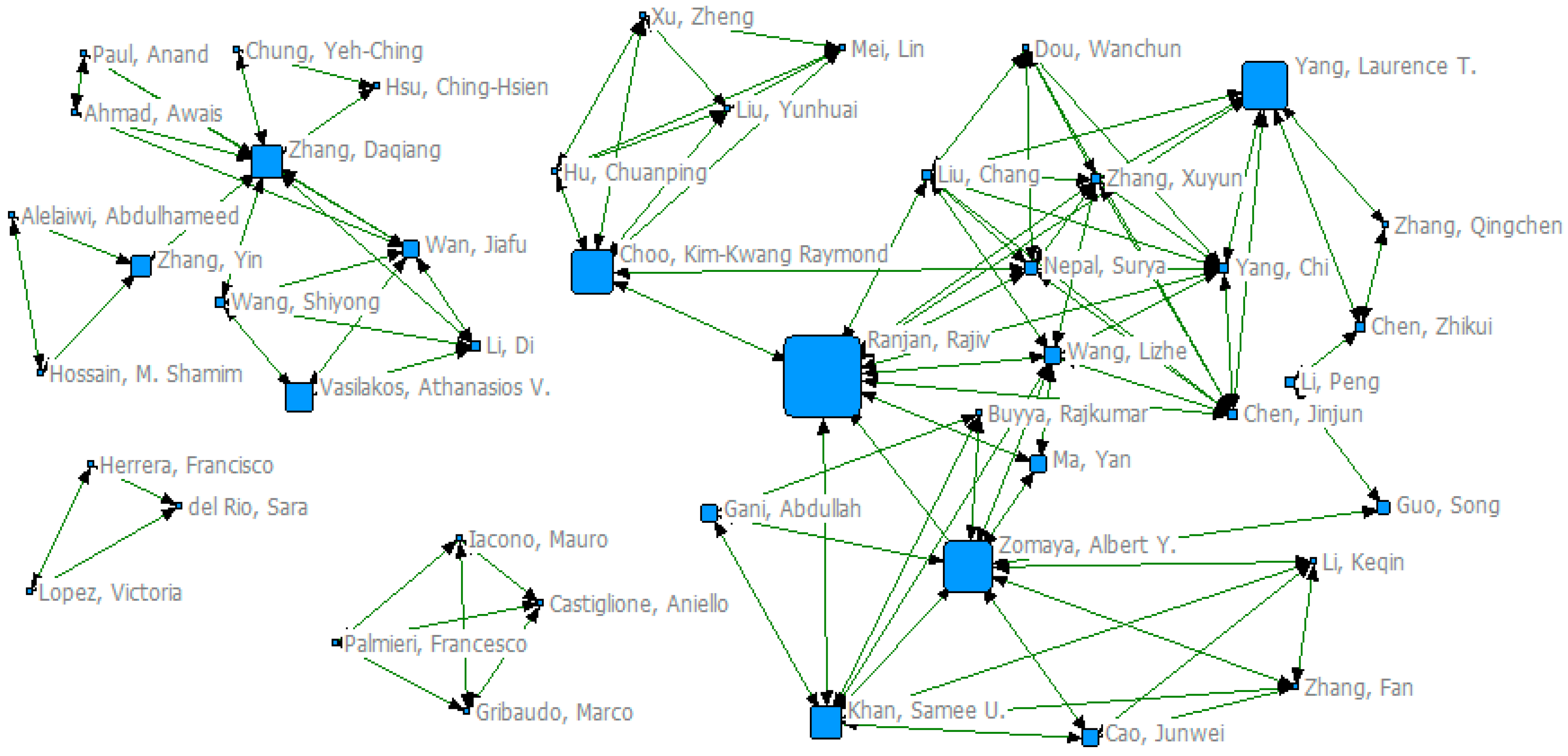
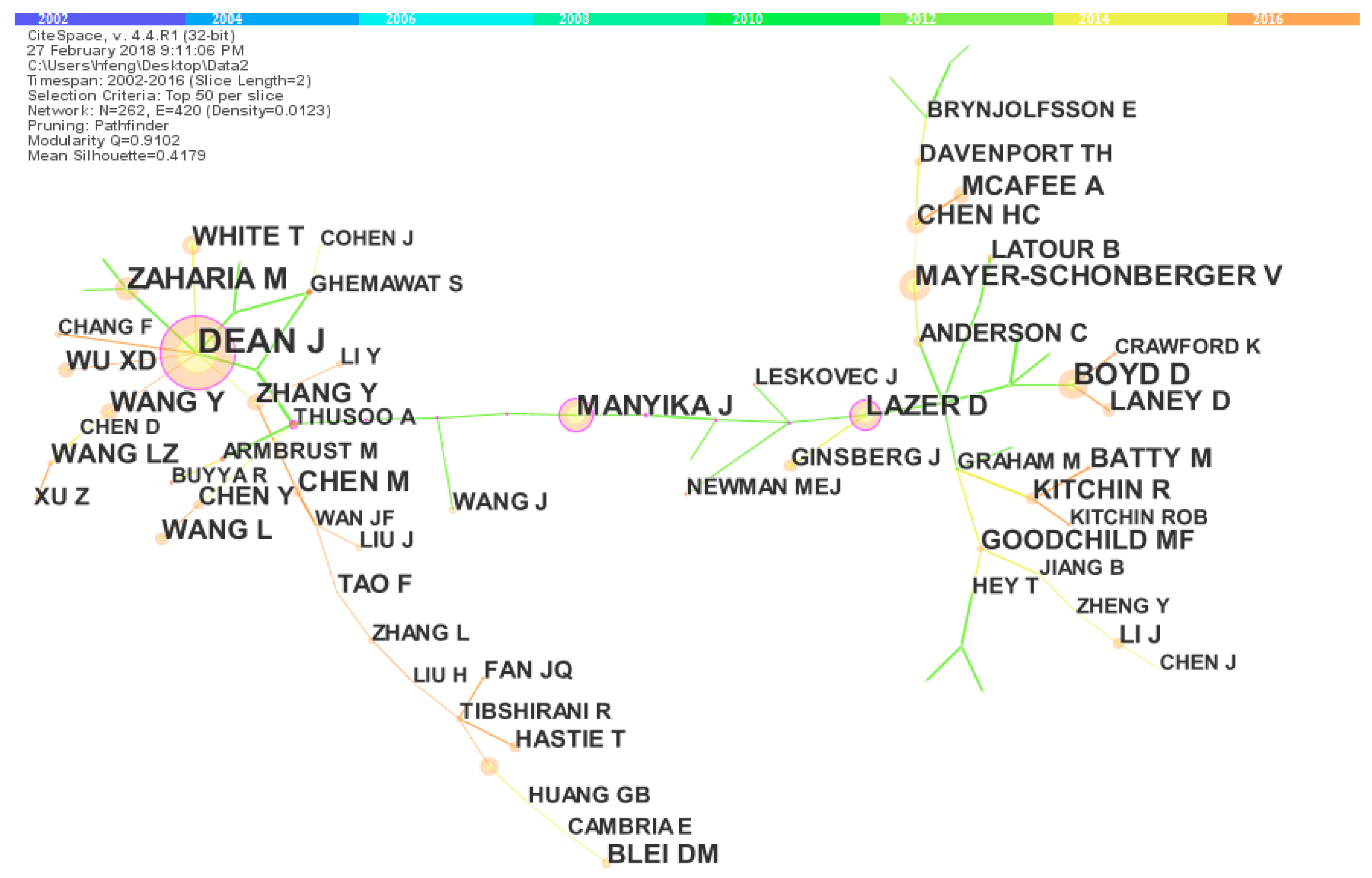
According to the core authors identification, compared with USA and China, Australia had a current greater research strength in big data research. However, according to authors co-citation analysis, the top 10 most co-cited authors mainly came from USA and China. Moreover, some special authors with most co-citation frequency, high betweenness centrality and strong citation bursts were also identified, such as the most co-citation authors, pivotal scholars or intellectual turning pointers, and the strongest citation burst authors. These authors had contributed to the sustainable development of big data from different perspectives, and have a profound impact on the big data field. More attention should be paid to their work.
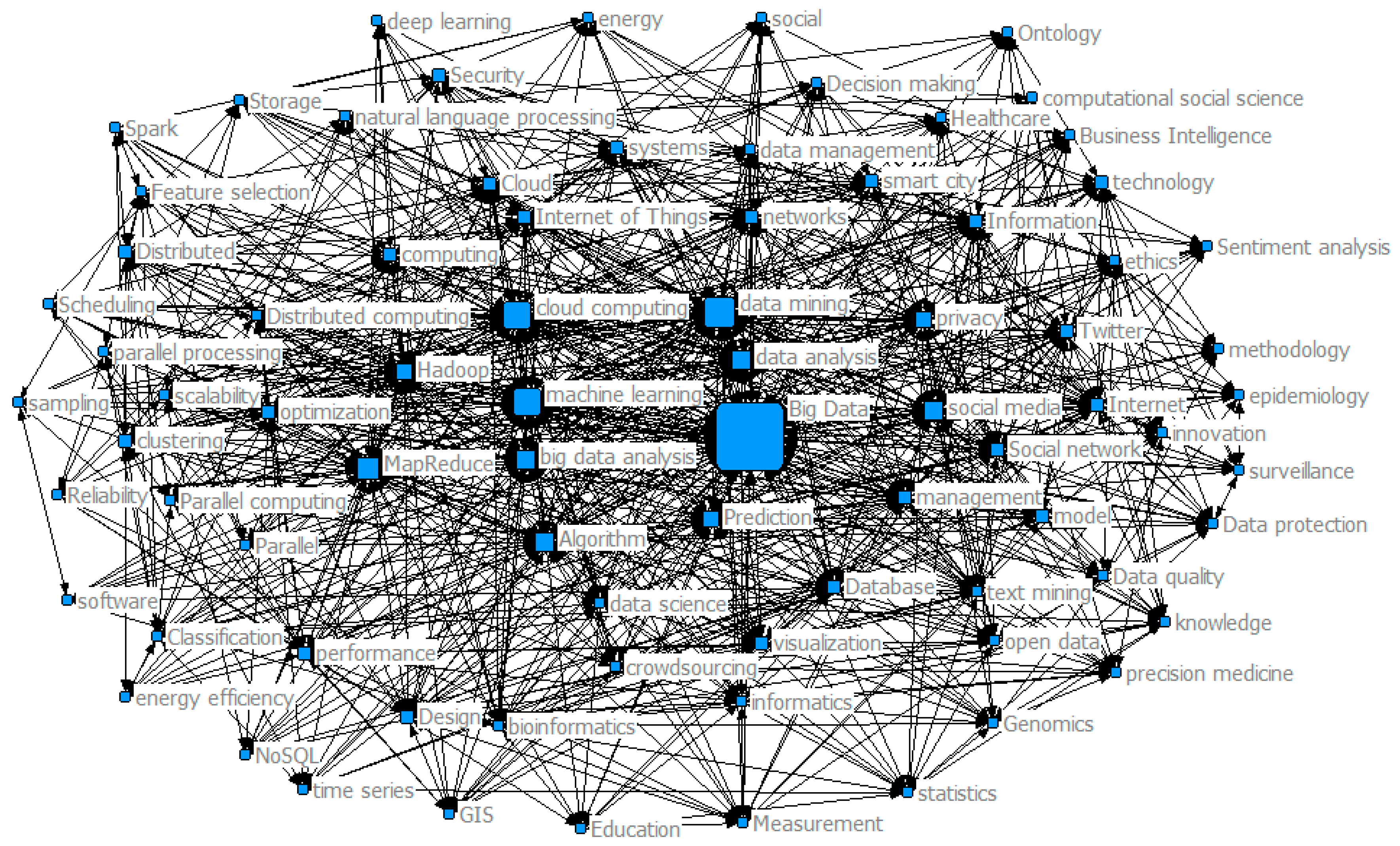
Keywords co-word analysis detected the current research hotspots and emerging topics, including not only the well-known research hotspots like data mining, cloud computing, machine learning, MapReduce, Hadoop, social media, and visualization, but also some emerging research topics, such as data science (data privacy, data management, data protection, and data quality, etc.), deep learning, and so on. Moreover, algorithm, model, performance and optimization are also gradually entering researchers’ considerations. In addition, keywords co-word analysis also detected the current emerging and sustainable development applications areas of big data, such as social network, smart city, bioinformatics, crowdsourcing, ethics, Genomics, GIS, Healthcare, Education, epidemiology, precision medicine, and energy.
As an emerging hot topic, big data has changed the lives of human beings, and driven some changes in thinking, decision making, and research paradigms. Moreover, big data itself contains important strategic resources for social trends, market changes, scientific and technological development and national security. Many colleges and universities have opened big data disciplines and courses. However, as a new emerging cross-discipline, the sustainable development of big data still faces many very complicated and difficult challenges, such as the heterogeneity and incompleteness of data, the efficiency of big data processing, big data security and privacy protection, high energy consumption, and so on. On the one hand, these challenges indicate some sustainable development directions of future big data research. On the other hand, these challenges are also unprecedented opportunities of big data sustainable development. With the increasing improvement of physical infrastructure constructions and policy making at national and institutional levels, and the further breakthroughs of information technologies (computer networks, distributed systems, cloud computing, data storage, machine learning, and so on), these above issues will be gradually solved. A bright future of big data science is coming.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}