In order to reconcile the frequency-based with the syntax-based approaches, we propose a novel feature extraction method based on an extended HITS algorithm which is called MHITS. This method mainly consists of two steps: feature-sentiment pairs extraction and feature ranking. In the first step, the dependency relations between features and sentiment words are selected after dependency syntax analysis on partly customer reviews. Subsequently, they are used to extract candidate features-sentiment pairs of the entire corpus by using known dependency relation. In the second step, MHITS will calculate the authority values of candidate feature to find out the actual feature.
3.1. Analysis of Dependency Syntax
Dependency grammar is used to describe the relation between words in sentence. There are many types of dependency relations in a sentence such as “attribute”, “adjunct”, “head”, “subject-verb”, “adverbial” and so on. This paper uses LTP (HIT-SCIR, LTP [Language Technology Platform],
http://www.ltp-cloud.com/) to automatically do POS tagging and analyse dependency relation of sentences. The LTP tool divides the dependency relation into 15 types, respectively “ATT”, “RAD”, “VOB”, etc. Taking sentence “the appearance of the mobile phone is very good-looking” as an example, it can be observed that there are five kinds of dependency relations, which are “ATT (attribute)”, “RAD (adjunct)”, “HED (head)”, “SBV (subject-verb)”, and “ADV (adverbial)” respectively. Among them, the relationship between “mobile phone” and the word “appearance” is an attribute relation “ATT”; “appearance” and “good-looking” are a subject-verb relation “SBV”; “mobile phone” and “of” are an adjunct relation “RAD”; “very” and “good-looking” are an adverbial relation “ADV”, and the entire sentence and “good-looking” constitute a head relation “HED”. However, only part of these dependency relations is helpful for identifying product features and sentiment words. In this research, candidate product features and its corresponding sentiment words are identified by LTP. Specifically, through the dependency relation analysis of the sentence, we find that the relation between feature and sentiment is mainly subject-predicate relation, namely the “SBV” relation. However, the “ATT” relation is also considered to improve the recall rate of features. They are used in previous feature extraction studies [
35,
39]. So, we manually select two types of dependency relation, “SBV” and “ATT”.
“SBV” relation represents the subject-verb relation of words in a sentence. Two specific “SBV” models are as follows.
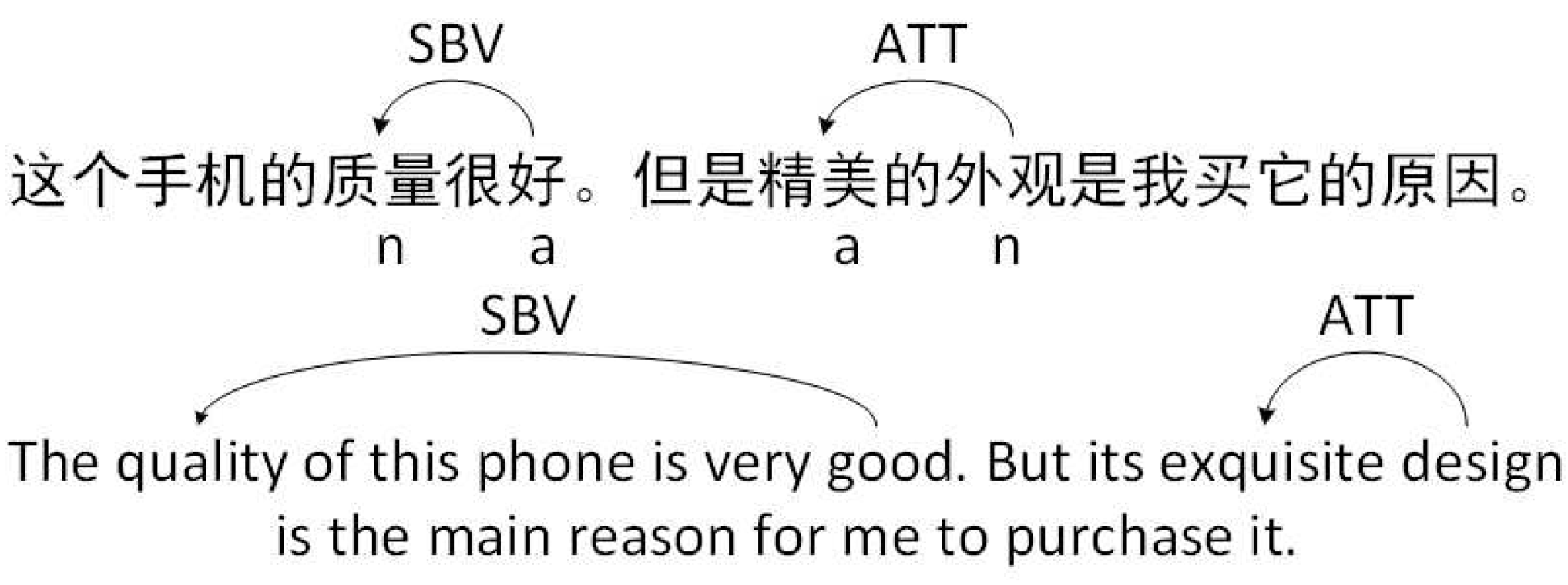
Adj+Noun: This pattern represents a word pair that meets the “SBV” relation, in which the subject must be a noun and the predicate is an adjective. As shown in
Figure 1, “quality” is a noun and “good” is an adjective. Moreover, “quality” is modified by “good”. It can be found in this sentence that “quality” is a product feature and “good” is an opinion word on it. Therefore, “Adj+Noun” means that noun is modified by a single adjective.
COO+SBV: “COO” represents an parallel relation of words in a sentence. “COO+SBV” pattern represents the fact that there are multiple adjective modifiers of a noun to form multiple “SBV” relations, and these “SBV” relations constitute “COO” relations. For sentence “this screen is clear and large”, “screen” is the feature word and “large” and “clear” are opinion words. After parsing, it can find that “large” and “clear” depend on “screen”. That is, “screen” and “clear”, “large” are all “SBV” relation, and the relationship between these two “SBV” relations is “COO”. In other words, “COO+SBV” means that both “large” and “clear” modifies “screen”.
“ATT” relation represents an attribute relationship in a sentence. Three specific “ATT” models are as follows.
Noun+Adj: This pattern represents a word pair that satisfies the “ATT” relation, in which attributive is an adjective and the attributive modifier is a noun. In the example of
Figure 1, “exquisite” is not only an adjective but also an attributive of “design”.
ATT+COO: This pattern represents two nouns are modified by the same adjective. For example, in sentence “Reasons I bought it is its clear picture quality and sound quality”, it can be found that the adjective “clear” modifies both two features of “picture quality” and “sound quality”.
COO+ATT: This pattern means that multiple adjectives modify one noun in an “ATT” relation. For example, in sentence “I love this large and clear screen”, both words “large” and “clear” are not only adjectives but also attributes of the “screen”.
3.3. The MHITS Algorithm
HITS is a link analysis algorithm which was proposed by Kleinberg in 1999 to evaluate the importance of web pages [
40]. The main idea of the HITS algorithm is that the number of web pages referenced and the number of it links are used to calculate its authority and hub value respectively [
41]. Specifically, HITS algorithm can be described as follows. Firstly, it collects
k highest ranked pages that are assumed to be highly correlated with a broad search query
q in search engine. This set
R with
k pages is called root set. Then, other nodes that point to nodes of
R will constantly become nodes of
R. Finally,
R becomes a base set
S when there is not any more node point to node in it. The (directed) link graph of
S is denoted by
, in which
V is the set of nodes and
E is the set of directed edges. HITS works on
G and assigns to each node an authority score and a hub score. The authority score estimates the value of the content of the page, and the hub score estimates the value of its links to other pages. The relationship of them is represented as follows:
where
is the authority score of the node
i , and
is the hub score of node
i.
From Equation (
1), it can be found that the node authority is the sum of the hub score of all nodes which it links to, and the hub score of a node is the sum of the authority score of nodes which it points to. The node with larger authority score is called authority node, and the node with larger hub score is called hub node. If a node is linked by many hub nodes, it will have a high authority score. Similarly, if a node is connected by many authority nodes, it will have a high hub score. Thus, authority nodes and hub nodes have a mutual reinforcement relationship [
15].
However, the original HITS algorithm has apparent shortcomings when it was employed in search engines. It completely excludes text and content of the web page. Due to this algorithm treats all hyperlinks identical and lack semantic analysis, it is prone to the phenomenon of “Topic-Drift” which will result in mismatch of query results and consumer requirements [
16]. Thus, in order to take into account the text and subject of web pages, Jon Kleinberg and David Gibson [
16] introduced a weight to the original HITS algorithm. The idea is assigning a positive numerical weight
to each edge from node
p to node
q. This weight measures the authority on the topic, which is the number of matching terminology of topic description in two web pages.
In this paper, we introduce Pointwise mutual information into HITS algorithm to identify actual features. Before illustrating how mutual information can be applied to HITS, let us first give a brief introduction to mutual information. Mutual information (MI) is a measure of the information overlap between two random variables [
42]. The MI between random variables
X and
Y is defined as:
where
and
are marginal probabilities of
X and
Y respectively, and
is joint probability. MI is also taken as the expected or average value of pointwise mutual information which is used to measure the correlation between two individual events
[
43].
However,
PMI is sensitive to low frequency, which will result in relatively high score for low frequency events. It is more accurately described as a lack of sensitivity to high frequency [
43]. Therefore, we use the normalized
PMI called
which is used by Bouma [
43] in collocation extraction to avoid this bias. The normalized PMI is defined as:
Normalized PMI has less biased towards low frequency collocations. So it has a moderate but positive effect on the effectiveness in measure the co-occurrence frequency of words [
43].
Normalized PMI reflects tightness between two variables. The higher the normalized PMI value is, the higher the correlation between X and Y is. In other words, if the co-occurrence frequency of a feature-sentiment pair is very high, the relation between feature and its sentiment of this word pair is tight. Therefore, the pair with high normalized PMI is more likely to express the consumer’s attention to this product feature with corresponding sentiment.
People often use nouns to denote product features and use adjectives to express their sentiments toward specific product features [
44]. In the context of feature extraction, a noun or noun phrase is more likely to be a feature if it is modified by quite a few adjectives [
17]. Similarly, an adjective is more likely to be a sentiment word if it is the modifier of many product features. In this paper, we treat candidate feature and sentiment word as different kinds of nodes in a network, which is called authority node and hub node respectively. Modifying relations between candidate features and sentiment words is taken as edges of the network. Based on the above analysis, we define such a network as a directed bipartite feature-sentiment relation network.
The MHITS algorithm measures the importance of network nodes based on the link structure of a network and co-occurrence relation between nodes. In this directed bipartite feature-sentiment network, the authority value of a candidate feature (authority node) can be calculated by the sum of hub value of candidate sentiment words (hub node) that link to it. If a candidate feature is modified by many candidate sentiment words with high hub value, this feature will have a high authority value. On the other hand, the hub value of a candidate sentiment word can be calculated by the sum of authority value of candidate features that link to it. If a candidate sentiment word modifies many feature words with high authority values, it will have a high hub value. Finally, the edge weight is calculated by the between authority nodes and hub nodes. If the value of a feature-sentiment word pair is high, the edge of corresponding network has a high weight. Thus, if the hub or authority value of a node is high, this node is more likely to be an actual sentiment or feature.
Assuming that
N represents the set of dependency word pairs;
F represents the set of candidate feature in
W;
S is the set of candidate sentiment in
N. Nodes in this directed bipartite feature-sentiment network are divided into two categories, namely authority node and hub node. Authority node is comprised of candidate feature words, and hub node is composed of candidate sentiment words. If an authority node
and a hub node
are a pair of candidate feature and sentiment word, an edge
of the network is directed by
towards
. The weight of edge
is measured by the normalized pointwise mutual information between
and
.
Figure 2 is an example of this network.
Considering that a candidate feature is more likely to be an actual feature if it is modified by more hub adjectives. We define the authority value
of an authority node
as:
where
is the value of the authority node;
T is the set of hub nodes linked to
;
F is the set of authority nodes in the network;
S is the set of hub nodes in the network;
is the weight of the edge from hub node
to authority node
;
is the weight of the edge from
to
as follows:
where
is the value of feature-sentiment word pairs, which is the pointwise mutual information of a hub node
and an authority node
. Thus, it can also be represented by the weight of edge of
pointing to
.
The more candidate features modified by an adjective are, the more likely this adjective is an actual sentiment word. We define the hub value of node
as:
where
U is the set of authority nodes linked to
.
The MHITS algorithm can be described as follows:
Initial step: let the value of authority node in the network be ; i = 1, 2, ..., n. The value of the hub node be ; j = 1, 2, ..., m. The edge is the co-occurrence frequency of the pair of feature-sentiment words represented by nodes.
Iterative process: The following three operations are carried out at step :
- -
Authority value adjustment rule: the value of each authority node is adjusted to the sum of the edge weights of the hub nodes.
- -
Hub value adjustment rule: the value of each hub node is adjusted to the sum of the edge weights of the authority nodes.
- -
The weights of edge adjustment rule:
This problem is addressed by using a power iteration method. The MHITS algorithm computes iteratively until it converges. Finally, the value of node and edge tends to be stable in the network.



{kind=link}
{kind=link}