1. Introduction
1.1. Social Problems and Challenging Issues for Identifying Ongoing Social Problems
Facing social problems as the challenges of the well-being and sustainability, e.g., high suicide rate and air pollution with fine dust in South Korea, research and development (R&D) projects have been promoted in addition to political and administrative measures not only to solve social problems, and but also to improve the quality of people’s lives by solving social problems. Subsequently, technologies for solving social problems have attracted increased attention and driven the expansion of social entrepreneurship around the world. Thus, both the public and private sectors have started to place more emphasis than before on the technologies that are related to social problems [
1,
2,
3]. Moreover, technological knowledge shares, e.g., patent documents and open research articles, have been more easily accessible currently than ever before, and this provides opportunities for solving social problems based on technologies rather than government policies. Therefore, it is necessary to facilitate the exploration of technological knowledge shares for solving social problems, and we should focus on identifying the ongoing social problems because it is a starting point for linking social problems to state-of-the-art technologies as solutions.
At the same time, with the emergence of Web 2.0 and social media, the amount of unstructured, textual data on the Internet has grown tremendously, especially at the micro level, which involves human behaviors, such as tweets of an individual person, the textual expression in blog posts over a period time, and furthermore the sensed activities by digital sensors in the so-called Internet of Things [
4]. This abundance of publicly available textual data creates new opportunities for both qualitative and quantitative researchers in various areas that are related to data and information sciences. In particular, the big data that are available on the Internet provide opportunities for identifying social problems. A large amount of event-related textual data, e.g., online news articles and web forum posts, contain data and information that are useful for taking an overview of ongoing social problems, e.g., the types of ongoing social problems and their progress. In this respect, several information technologies can be applied, from information retrieval (IR) to text mining.
However, the previous works have not paid attention to social-problem-specific perspectives of big data, so it is currently unclear how information technologies can be used to identify and manage the ongoing social problems from big data. In detail, the following challenging issues need to be resolved:
First, various social problems are in process simultaneously, and they occur in multiple streams of events. Therefore, it is a nontrivial task to determine the landscape of ongoing social problems from a large amount of the event-related textual data, e.g., online news articles and web forum posts. Particularly when individual persons are unfamiliar with the ongoing social problems, it is difficult for them to identify the ongoing social problems from such big data [
5]. Therefore, it is necessary to identify the ongoing social problems and their key terms, which can represent the ongoing social problems, in an automatic way.
Second, most people use nouns as key terms to get data and information about ongoing social problems because they are relevant to topics, whereas the other types of key terms such as verbs, adjectives, and adverbs are more relevant to sentiments than topics [
6,
7,
8]. In addition, for the same reason, it is harder for people to come up with and figure out key noun terms that are related to social problems than the other types of key terms. It means key noun terms are crucial for successfully getting data and information about the ongoing social problems. Hence, we need to focus on key noun terms for finding out social-problem-related data and information.
Third, some of the key noun terms can be more useful for figuring out the topics of ongoing social problems from big data because they play roles in categorizing those social-problem-related topics (SPRTs) into their corresponding social problems. For example, let us assume that two SPRTs were detected, and each SPRT was represented by five key noun terms, namely topic1 = {Suwon, Suicide, Student, Female, Police} and topic2 = {Daegu, Suicide, Student, Male, Violence}. Then, the key noun terms, such as Suicide, Student, Female/Male, and Violence, can be social-problem-specific key noun terms (hereinafter, SocialTERMs). Particularly, Suicide indicates that the two SPRTs can be grouped into the same type of social problems. In contrast, the city names, namely Suwon and Daegu, are event-specific key noun terms (hereinafter, EventTERMs), which specify that the two SPRTs occurred at different locations. Thus, the different roles of such key noun terms in labeling the identified SPRTs need to be considered.
Lastly, there have been no previous works on identifying the SocialTERMs from a large number of online news articles in an automatic way. Consequently, manual annotation after reading a large amount of textual data is unavoidable for now in extracting the SocialTERMs for the detected SPRTs. However, it requires significant human efforts, and it is labor-intensive, expensive, time-consuming, and often error-prone. In addition, to reflect the importance of key noun terms in the textual data at different levels, e.g., the document level and the detected topic level, several weighting schemes have been used in previous works, e.g.,
tf,
idf, and
tfidf [
9]. However, it is unknown whether those weighting schemes can reflect the different roles of key noun terms in representing social problems over time.
1.2. Key Term Identification in the Previous Text Mining Applications
With the emergence of Web 2.0 and social media, the amount of unstructured data, most of which are textual and publicly available on the Internet, has increased massively, especially the amount of data on individual entities such as persons and companies. This big data creates new opportunities for both qualitative and quantitative researchers of data and information sciences. Thus, big data is essential not only for scientific research on social systems but also for businesses and individuals [
10], and it is important to develop a method that helps people obtain the relevant data quickly and accurately from big data and analyze it. To resolve it, text mining has been employed, with a focus on analyzing the statistical properties of terms [
11]. In particular, key terms are essentials for exploring the overall data set, and text mining uses them to inspect and process the obtained texts through typical preparation steps.
Table 1 shows recent studies (2014–2018) in which key terms were extracted and used for text mining applications. The previous works in
Table 1 can be grouped according to the final application of their identified key terms: indexing, clustering, summarization, classification (or categorization), or mapping [
12,
13]. Indexing, in which textual data are represented with a set of extracted key terms, is a research goal on its own, and is also a step in most text mining applications, such as feature generation and text representation [
14]. Clustering is to group textual data on the basis of their attributes to identify important themes, patterns, or trends [
15], and it is employed for topic detection (TD) [
16]. Summarization focuses on creating a summary that contains the most important points of the original documents [
17]. Classification assigns textual data to two or more categories [
18,
19]. Mapping focuses on information visualization and supports effective and efficient searches of important subjects or topic areas, which are identified from textual data [
15,
20].
In addition,
Table 1 provides three taxonomies for the key term identification of the previous works. First, the key terms can be discovered to best describe the textual data at different levels: the sentence level [
21,
22,
23], the document level [
24], and the topic level [
6]. Second, the key term identifications used in the previous text mining applications can be divided into three categories: manual, automatic, and hybrid approaches. Third, particularly for the automatic approach, four types of techniques have been used: statistical, linguistic, machine-learning-based, and hybrid approaches [
12,
24,
25]. While the statistical approaches do not require any learning mechanism and use statistical information of terms, e.g.,
tf,
idf, and
tfidf [
26,
27], the linguistic approaches use linguistic features of terms, e.g., parsing, sentiment analysis, and semantics [
28,
29]. Machine-learning-based approaches use key terms that are extracted from the collected textual data by means of a training process and apply them to a machine learning model to find key terms in new textual data [
12,
28]. The hybrid approaches combine one or more techniques [
17,
30].
According to
Table 1, most prior text mining applications are either automatic approaches or hybrid approaches, and they have adopted either statistical techniques or hybrid techniques for extracting their key terms. Theoretically, under these taxonomies, this study can be categorized into classifying the topic-level key noun terms from online news articles into the SocialTERMs and the EventTERMs by adopting a hybrid technique, as highlighted in
Table 1. Consequently, according to
Table 1, the key theoretical contributions of this paper can be summarized as follows:
First, to the best of our knowledge, based on
Table 1, there exists a research gap that no previous work has dealt with: the automatic classification of key noun terms that were identified by TD into the SocialTERMs and the EventTERMs. This paper contributes to addressing this research gap.
Second, to label the identified topics, most of the previous works in
Table 1 used simple statistical approaches for characterizing key terms from clustered documents. On the other hand, this paper proposes and employs temporal weight features, sentiment features, and complex network structural features to represent key noun terms, which can be identified to label the detected SPRTs, after reviewing the features that were used in the previous works of
Table 1.
Third, according to
Table 1, no previous study has compared the performances of the state-of-the-art classification techniques, particularly deep learning, for distinguishing between the SocialTERMs and the EventTERMs among the key terms of the detected SPRTs. This paper extends the related literature by taking on such a challenging issue.
1.3. Purpose and Organization of This Paper
To resolve the abovementioned challenging issues, this paper proposes an automatic approach, namely SocialTERM-Extractor, which identifies the SPRTs from a large number of Korean online news articles and classifies the key noun terms of the detected SPRTs into the SocialTERMs and the EventTERMs.
To design and examine the proposed approach, three research questions can be formulated as below, and a research framework is constructed to answer those research questions:
RQ1. How well do the three types of features, namely temporal weight, sentiment, and complex network structural features, perform in distinguishing the SocialTERMs and the EventTERMs among the key noun terms of the detected SPRTs from a large number of online news articles by using different classification techniques? Moreover, which feature set and features give the best results?
RQ2. Which classification technique among the five base learners, namely Decision Tree (DT), Naïve Bayes (NB), Radial Basis Function Network (RBFN), Support Vector Machine (SVM), and Deep Belief Network (DBN), is best suited for differentiating the key noun terms of the detected SPRTs into the SocialTERMs and the EventTERMs?
RQ3. Which ensemble learning method gives the best results? Is there a single ensemble method that achieves the best performances for the all feature sets with any given base learner?
The rest of the paper is organized as follows:
Section 2 outlines the proposed a research framework to design and examine the SocialTERM-Extractor, and explains it in detail.
Section 3 presents the results of applying the suggested research framework to the online news articles, which are collected from the best-known Korean news portal site in South Korea.
Section 4 discusses the application results in terms of designing an automatic system. Finally,
Section 5 presents the conclusions of this paper with reflections on limitations and future works.
2. Materials and Methods
To answer the research questions in the previous section, a research framework is proposed as summarized in
Figure 1. First, online news articles reporting social-problem-related events are collected from a test-bed news portal site. Second, sentiment analysis selects online news articles with negative sentiment from the collected data. Then, from the online news articles having negative sentiment, the SPRTs are detected, and labelled by their key noun terms. Third, the three types of features regarding the key noun terms of the detected SPRTs are measured: temporal weight, sentiment, and complex network structural features. Fourth, the configurations of different feature sets and different classification techniques are evaluated respect to three performance measures, namely accuracy,
F-measure, and area under accuracy (AUC). Then, the comparative studies are performed for different feature sets and different classification techniques. Following subsections explain the steps of the proposed research framework in detail.
2.1. Collect Data
In the first component of
Figure 1, news sections related to society are targeted for data collection. Then, the data collection is performed mainly by two steps, crawling and parsing:
First, a distributed web-crawling program is developed to collect the online news articles from the Internet in a significantly reduced timespan. In detail, the distributed web-crawling program is based on the simple remote procedure call (SRPC) framework, in which two tasks from a master computer are delivered to slave computers with various hardware configurations, i.e., a uniform resource identifier (URI) to crawl and how to crawl the given URI. Consequently, a large number of online news articles, published in the chosen society-related news sections of a test-bed news portal service, are collected as raw HTML pages.
Second, the textual data in <title>…</title> and <content>…</content> of the collected online news articles are parsed out from the raw HTML pages, and are stored in a relational database. In addition, the publication date of each online news article is stored in the database for the TD. This results in NEWS0,t = {news | online news articles, published at time t and collected from the chosen society-related news sections of the test-bed news portal service} for time t = 1, …, T.
2.2. Detect Social-Problem-Related Topics (SPRTs)
2.2.1. Select Online News Articles with Negative Sentiment
In this step, online news articles with negative sentiment are selected to focus on online news articles more related to social problems. Considering the wide applicability to different languages, the sentiment of an online news article is obtained based on multilingual sentiment feature set, made by two main parts proposed in Dang et al. [
43]: the extraction of English sentiment feature set from SentiWordNet (
http://sentiwordnet.isti.cnr.it/), and the construction of multilingual sentiment feature set.
To explain, for the multilingual sentiment features in SentiWordNet, the average polarity score is calculated by using the prior–polarity formula, defined as
where
senti is a sentiment feature in SentiWordNet,
pos is a sentiment related part-of-speech (POS) sense,
pos ∈ {verb, adverb, adjective},
pol is a type of polarity scores,
pol ∈ {objective, positive, negative},
SYNSET(
senti,
pos,
pol) is a set of synsets, i.e., synonyms, belonging to
senti when
pos and
pol are given, and
swnscore(
synset,
pos,
pol) is the SentiWordNet score of
synset with given
pos and
pol.
From
score(
senti,
pos,
pol), the final sentiment score is determined by the sentiment feature–calculation strategy. In the strategy, the sentiment features satisfying both
score(
senti,
pos,
pol = objective) < 0.5 and |
score(
senti,
pos,
pol = negative)| ≠ |
score(
senti,
pos,
pol = positive)| are taken into account, and the final negative sentiment score of a multilingual sentiment feature is calculated as
Then, using the constructed multilingual sentiment feature set, the sentiment score of an online news article,
news, is obtained by
where
NEWSSENTI(
news) is a set of the multilingual sentiment features appearing in
news ∈
NEWS0,t.
In particular, this study uses the multilingual sentiment feature set of English and Korean, constructed by Suh [
8], because of the following reasons: it is based on the commonly used approach for measuring multilingual sentiment, proposed by Dang, Zhang and Chen [
43]; it enables researchers of the other lingual cultures to make use of this study’s research framework; Korean, selected for this study, is taken into account as the non–English for the multilingual sentiment features; the sentiments of synonyms for a English sentiment feature are considered for the corresponding Korean sentiment feature; and the additional Korean sentiment features are generated and included to consider the negation.
To explain briefly, the Korean sentiment feature, constructed by Suh [
8], inherits the final sentiment score and POS sense of its corresponding English sentiment feature, generated by Dang, Zhang and Chen [
43]. For instance, as shown in
Table A1 of
Appendix A, the sentiment value of ‘더럽히/pvg+다/ef’ is −0.7500 for
pos = verb, and comes from the corresponding English sentiment feature, ‘soil’. If the English sentiment feature has synonyms, the final sentiment scores of the synonyms are averaged for the corresponding Korean sentiment feature. For example, the sentiment value of ‘즉시/mag’ is the average of sentiment values from five English sentiment features: ‘instantly’, ‘straight_away’, ‘right_away’, ‘at_once’, and ‘swiftly’. Moreover, if the morphological analysis splits the Korean sentiment feature into a stem and ending(s), the extended Korean sentiment features are generated by adding various endings to the stem in possible POS senses and tenses. For instance, the stem of ‘더럽히/pvg+다/ef’ is ‘더럽히/pvg’, and the extended Korean sentiment features of ‘더럽히/pvg+다/ef’ are listed in
Table A2 of
Appendix A. They inherit sentiment values from the original Korean sentiment feature, ‘더럽히/pvg+다/ef’, and, when negation is added to their endings, −1 is multiplied to their sentiment values.
As a consequence, to select online news articles more concerned with social problems, the online news articles with newsnegscore(news) > 0 are chosen for the TD of the next step. This leads to NEWS1,t = {news | online news articles, published at time t, and turned out to have negative sentiment’s online news articles from NEWS0,t} for time t = 1, …, T.
2.2.2. Detect the SPRTs from the Collected and Negative Online News Articles
An event is defined as a real-world incident that is related to time(s) and location(s), e.g., 9/11 attacks of 2001, Hurricane Catalina of 2004, and North Korea’s nuclear weapon test [
44]. Due to the rapid growth and popularity of the Web, when an event occurs, a large number of event-related textual data are published online [
45]. Generally, online news articles are starting points, and Web 2.0 has recently led to the tremendous distribution of online news articles through individuals on social media [
46,
47]. As a result, managing, interpreting, and analyzing such a huge volume of online news articles that are related to events has been a difficult task. To address this, many online news articles that are related to a set of events and interconnected with one another need to be grouped into the same topic [
16]. Then, such topics and their changes can be identified over time by using TD methods [
48]. Formally, a topic is a seminal event that is associated with all related events, that is, a set of related events [
49].
Therefore, to detect the topics of this study’s interest, i.e., SPRTs, this step clusters online news articles, which are collected and evaluated to have negative sentiment. First, noun terms are identified from the online news articles through a series of natural language processing (NLP) techniques, i.e., spacing, part-of-speech (POS) tagging, regular expressions-based noun extraction, and stop words removal. In this way, only noun terms are used for the TD because of the following reasons: first, the target key terms of this study, i.e., SocialTERMs and EventTERMs, are noun terms according to the introduction of this paper; second, the other types of key terms, i.e., verbs, adjectives, and adverbs, are more relevant to sentiments rather than topics [
6,
7,
8]. Next, let
news be an online news article in
NEWS1,t, and
noun be a noun term in
NEWSNOUN0(
news) = {
noun | all noun terms in
news}. Then, the weight score of
noun in
news ∈
NEWS1,t is obtained by
Here,
tf(
noun,
news) is the normalized frequency of
noun appearing in
news, and it is defined as
where
f(
noun) is the frequency of
noun in <content>…</content> of
news. In addition,
idft(
noun) is the inverse document frequency of
noun, defined as
where
ht(
noun) is the number of online news articles containing
noun among online news articles in
NEWS1,t, and
Ht is the number of online news articles in
NEWS1,t. On the other hand,
ths(
noun,
news) is the existence of
noun in <title>…</title> of
news, given by
Using the obtained
w(
noun,
news) values, five noun terms with the highest weights are selected as key noun terms for
news. This results in
NEWSNOUN1(
news) = {
noun | five key noun terms for
news}, and
news is represented by the vector of its five key noun terms due to its simplicity, compared to the other textual representations models, e.g., the graph-based model, and the fuzzy set model [
50,
51]. Here, one may argue about how to decide the number of key noun terms for an online news article, but this study refers to the number of key noun terms used to represent an online news article in the previous works, i.e., three to five keywords [
6,
8,
52,
53]. Therefore, in this study, the number of key noun terms for an online news article is set to five as default.
Then, Algorithm 1 is adopted to cluster online news articles in
NEWS1,t for
t = 1, …,
T. The Algorithm 1 is a modified version from the algorithm that was used in He, Chang, Lim and Banerjee [
16] and Suh [
8], which has been widely used and known effective for TD because it overcomes the following drawbacks. While previous TD models are broadly classified into two types, i.e., non–probabilistic and probabilistic [
16], non-probabilistic models do not provide the number of topic clusters, and existing probabilistic models, especially latent Dirichlet allocation (LDA), seem to be overly complex for the TD problems.
Consequently, the Algorithm 1 extracts the topics of similar online news articles from NEWS1,t for t = 1, …, T. Over the iterations in executing Algorithm 1, the centroid of each topic keeps less than α key noun terms while excluding less important key noun terms. In consequence, Algorithm 1 results in TOPIC(topic) = {topic | SPRTs detected from NEWS1,t for t = 1, …, T}, TOPICNEWS(topic) = {news | online news articles, classified to topic ∈ TOPIC}, and TOPICNOUN(topic) = {noun | key noun terms in the centroid of topic ∈ TOPIC}.
| Algorithm 1 Detecting the SPRTs from online news articles in NEWS1,t (t = 1, …, T). |
| Input: | Online news articles in NEWS1,t and their noun score vectors, and threshold ε |
| Output: | TOPIC, TOPICNEWS(topic), and TOPICNOUN(topic) |
| 1: | for time t = 1 (i.e., the first publication date among online news articles of NEWS1,t) to t = T (i.e., the last publication date among online news articles of NEWS1,t) do |
| 2: | | | select online news articles in NEWS1,t; |
| 3: | | | ift = 1 and n(TOPIC) = 0 then |
| 4: | | | | create a topic, set the online news article as a centroid of the new topic, and announce it; |
| 5: | | | else |
| 6: | | | | for each online news article of NEWS1,t do |
| 7: | | | | | compute the cosine similarity of an online news article with the centroid of each topic in TOPIC, defined as where is the weight vector, is the dot product of two weight vectors, and is the magnitude of ; |
| 8: | | | | | if cosine similarity > threshold ε then |
| 9: | | | | | | assign the new article to the nearest topic and update the centroid of the nearest topic with the new article by averaging their weight vectors; |
| 10: | | | | | else |
| 11: | | | | | | create a new topic, assign the online news article to the new topic, and announce it; |
| 12: | | | | | end if |
| 13: | | | | | if the number of noun terms in the updated centroid > α then |
| 14: | | | | | | keep only the top α noun terms with the highest weight scores as key noun terms; |
| 15: | | | | | end if |
| 16: | | | | end for |
| 17: | | | end if |
| 18: | end for |
| 19: | select topics with >β online news articles, and define them as the SPRTs. |
2.3. Measure the Three Types of Features to Represent the Key Noun Terms of the SPRTs
To label the identified topics, most of the previous works in
Table 1 used simple statistical approaches for characterizing key terms from clustered documents. In contrast, this paper proposes and employs temporal weight features, sentiment features, and complex network structural features to represent key noun terms, which can be identified to label the detected SPRTs, after reviewing the features that were used in the previous works of
Table 1. Details of the proposed three features can be explained as follows:
Temporal weight features. Temporal IR attempts to consider not only relevance but also temporal correspondence based on the underlying temporal factor behind search intension. A relatively large number of key noun terms, i.e., queries, for information access have temporal information needs [
54]. Hence, to represent the temporally changing importance of a key noun term in the identified topics, this study modifies the traditional weighting statistics, e.g.,
tf,
idf, and
tfidf, by taking into account time, which yields temporal weight features. In addition, basic statistics such as the mean, variance, and |skewedness| are measured for the temporal weight features, to consider the distributional characteristics over the given time period. Here, the absolute value of skewedness is to measure the shape of skewedness irrespective of whether it is skewed to the left/negative or to the right/positive.
Sentiment features. The sentiment features of a key noun term are measured by sentiment analysis on the large-scale online news articles. In general, sentiment analysis determines whether a textual data instance is objective or subjective and whether a subjective textual data instance contains positive or negative statements, and measures the sentiment value of a subjective textual data instance [
55,
56]. In this paper, the approach of Suh [
8] that uses SentiWordNet as a lexicon is adopted to extract multilingual sentiment features and score their sentiment values mainly for two reasons: it enables researchers in the other countries to use the research framework of this paper by constructing sentiment features with their own languages; and it takes into account the negations. In addition, this study exploits the basic statistics of a key noun term’s sentiment features to represent the distributional characteristics over the news and topics that contain the key noun term.
Complex network structural features. Using the co-occurrence relationships of the key noun terms as links, which are called co-news and co-topic links, the complex networks of the key noun terms are constructed, and their complex network structural properties are measured by referring to the standard measures of node centrality, i.e., the degree, closeness, and betweenness centralities [
57,
58,
59], and used as features for this study. In addition, after specifying a boundary, such as identified SPRTs and detected topical communities, to the complex networks of the key noun terms, the basic statistics are measured to represent the distributions of a key noun term’s in-boundary network properties over the different SPRTs and topical communities.
Thus, in this
Section 2.3, the proposed three types of features are measured for all the extracted key noun terms of the SPRTs, i.e.,
noun ∈
. The measured three types of features for the topic-level key noun term are used to decide automatically whether the topic-level key noun term is a SocialTERM or EventTERM in the next
Section 2.4.
2.3.1. Measure the Temporal Weight Features of the SPRTs’ Key Noun Terms
The temporal weight features of noun ∈ , namely F1, are measured with four respects: df, tf, ths, and idf. Moreover, these temporal weight features are measured with two different respects: at the news level and at the topic level.
First, the temporal weight features of
noun at the news level are measured as follows: Given that
NOUNNEWSt(
noun) is a set of online news articles, containing
noun and published at time
t,
is the normalized number of online news articles in
NOUNNEWSt(
noun), and it is given by
Given that
is the frequency of
noun, which occurred in the content of
news ∈
,
is obtained by normalizing
by the number of online news articles in
NOUNNEWSt(
noun), and it is defined as
is the normalized
ths(
noun,
news) for online news articles in
, and it is given by
where
ths(
noun,
news) is 2 if
noun appears in the title of
news, otherwise it is 1.
is the inverse of the number of online news articles, containing
noun at time
t, and it is defined as
To represent the distribution of each of the Equations (9)–(12) over time t = 1, …, T, the mean, variance, and |skewness| are measured, and added as the temporal weight features of noun at the news level to F1. As a consequence, 12 features are measured as the news-level temporal weight features of noun.
Second, the temporal weight features of
noun at the topic level are obtained as follows: Given that
NOUNTOPICt(
noun) is a set of the detected SPRTs that contain online news articles in
NOUNNEWSt(
noun) and thereby are related to
noun,
is the normalized number of the detected SPRTs in
NOUNTOPICt(
noun), defined as
is obtained by normalizing
over the detected SPRTs related to
noun, and defined as
In the same way,
is got by normalizing
over the detected SPRTs related to
noun, given by
and
is the normalized
over the detected SPRTs regarding to
noun, given by
To represent the distribution of each of Equations (13)–(16) over time
t = 1, …,
T, 12 topic-level temporal weight features on
noun are measured, and added to F1. Consequently,
Table 2 shows that 24 temporal weight features on
noun, measured at both news and topic levels.
2.3.2. Measure the Sentiment Features of the SPRTs’ Key Noun Terms
This component extracts features related to the sentiment of
noun, namely F2. To do so, this paper adopts the multilingual sentiment feature set, constructed by Suh [
8] through two main parts: the extraction of English sentiment feature set from SentiWordNet (
http://sentiwordnet.isti.cnr.it/), and the construction of multilingual sentiment feature set.
Let
NOUNSENTI(
noun) be a set of the constructed multilingual sentiment features that contain
noun. Then, the sentiment score of a multilingual sentiment feature including
noun with the given
pos is obtained by
In addition, the sentiment score of
noun is defined as
The sentiment score of
noun at the news level is obtained by averaging the sentiment scores of online news articles, containing
noun, and it is given by
where
NOUNNEWS(
noun) =
NOUNNEWS1(
noun)∪…∪
NOUNNEWST(
noun) for time
t = 1, …,
T. Here, the sentiment score of an online news article,
news, is given by
where
NEWSSENTI(
news) is a set of the multilingual sentiment features appearing in
news. In addition, to represent the distribution of the sentiment scores of online news articles that contain
noun, variance, and |skewness| for
newssentiscore(
news) are measured over
news ∈
NOUNNEWS(
noun), and they are added as the sentiment features of
noun to F2. Here, the mean value of
newssentiscore(
news) is equal to
sentiscore1(
noun).
The sentiment score of
noun at the topic level is defined as
Here, the sentiment score of the detected topic,
topic, is given by
In addition, to represent the distribution of the sentiment scores over the detected SPRTs, whose online news articles are containing
noun, the mean, variance, and |skewness| for
topicsentiscore(
topic) are measured over
topic ∈
NOUNTOPIC(
noun), and they are added as the sentiment features of
noun to F2. Here, the mean value of
topicsentiscore(
topic) is equal to
sentiscore2(
noun). Consequently, 10 sentiment features of
noun are measured as shown in
Table 3, and F22 and F23 are particularly measured to represent the distributions of the sentiment scores of
noun over its
news and
topic.
2.3.3. Measure the Complex Network Structural Features of the SPRTs’ Key Noun Terms
A network whose structure is irregular, complex, and dynamically evolving over time is defined as a complex network. The research on complex networks has resulted in the identification of a series of unifying principles and statistical properties that are common to most real networks [
60]. For a given plain graph, approaches that are based on the structure-based patterns of complex networks can be grouped into feature-based and proximity-based approaches: feature-based approaches extract graph-centric features, e.g., node degree; proximity-based approaches quantify the closeness of nodes in the graph to identify associations, e.g., PageRank [
61]. In particular, feature-based approaches compute various measures that are associated with the nodes, dyads, triads, egonets, communities, and global graph structure. Among these measures, this paper focuses on the nodes and communities because they both correspond to the node perspective.
Network properties characterize an individual node’s position within a complex network. The three most widely investigated concepts for evaluating such network properties are the degree, closeness, and betweenness centralities [
57,
58,
59]. These are the standard measures of node centrality, which were originally introduced to quantify the importance of an individual in a social network. Given an adjacency matrix
of networks, where
n is ≥3, the three normalized network centralities can be respectively defined as follows:
where
mij = 1 if node
i is connected to node
j. A high value of
degreei means that node
i acts as a center in the network.
where
dij is the number of edges in the shortest path from node
i to node
j.
closenessi indicates the influence of node
i on the other nodes.
where
gjk is the number of the shortest paths between node
j and node
k, and
gjik is the number of the shortest paths between node
j and node
k that contain node
i. A high betweenness
i value means that node
i is located at the core of the networks and has higher momentum of transition.
A community is a densely connected subgroup, which is known to exist in many real-world networks, and community detection (CD) can help us understand networks more deeply and identify interesting properties that are shared by the nodes [
62,
63]. The fundamental idea behind most CD methods is to partition the nodes of the network into modules [
64]. For the agglomerative methods of CD, there are two commonly used algorithms: first, Newman’s CD algorithm is a widely used agglomerative method that uses modularity to measure the goodness of the current partitioning; second, the recently developed Louvain method [
65] is an agglomerative method and is commonly used because of its low computational complexity and high performance. When merging communities, the Louvain method considers not only the modularity but also the consolidation ratio [
41]. Newman’s algorithm is effective but slow, whereas Louvain’s method is much more computationally efficient [
66]. Therefore, this paper adopts the Louvain method for detecting topical communities from complex networks of key noun terms, which are used to label the detected SPRTs.
Based on the abovementioned definitions related to complex networks, this component extracts the complex network structural features regarding
noun, namely F3, by constructing two types of the complex networks of the SPRTs’ key noun terms: cross-boundary networks and in-boundary networks.
Figure 2 describes how the networks of the key noun terms are constructed respectively, and details are explained as follows:
The cross-boundary networks (CBNs) are constructed by using the key noun terms as nodes, and setting edges by the co-occurrence relationship between the key noun terms in terms of news and topics. In other words, CBNco-news is constructed by making the key noun terms as nodes and their co-occurrence frequencies in online news articles, i.e., co-news frequencies, as the corresponding link weights. Similarly, by setting co-occurrence frequencies in the detected topics, i.e., co-topic frequencies, as the corresponding link weights, CBNco-topic is constructed.
In-boundary networks (IBNs) are built up by using the key noun terms in a particular boundary, and their co-occurrence relationships with respect to the boundary. For IBNs, this study uses two types of boundaries, topics, and communities. First, let ITNco-news(topic) be a kind of IBNs, constructed by setting topic as the boundary and co-news frequencies of the key noun terms as link weights. Second, the Louvain method-based CD on CBNco-topic is performed to take into account the semantic relationship among the key noun terms in terms of their co-topic frequencies. Unlike the TD, the CD allows noun to only one of the detected communities. For each detected community, community, an in-community network, i.e., ICNco-topic(community), is formed by setting co-topic frequencies of the key noun terms in the boundary of community as the link weights.
To evaluate the network properties of
noun in both CBN
co-news and CBN
co-topic, degree, closeness, and betweenness are respectively measured as the complex network structural features of
noun. Relating to the IBNs, the network properties of
noun in ITN
co-news(
topic) are
degree(
noun, ITN
co-news(
topic)),
closeness(
noun, ITN
co-news(
topic)), and
betweenness(
noun, ITN
co-news(
topic)). In particular, to represent the distribution of the three network centralities of
noun over the detected SPRTs, the mean, variance, and |skewness| are measured regarding
noun, and they are added as the complex network structural features of
noun to F3. Then, the structural properties of
noun in its corresponding ICN
co-topic(
community) are obtained as
degree(
noun, ICN
co-topic(
community)),
closeness(
noun, ICN
co-topic(
community)), and
betweenness(
noun, ICN
co-topic(
community)). As a result,
Table 4 shows that 18 complex network structural features of
noun for each of the constructed complex networks of the SPRTs’ key noun terms.
2.4. Classify the Key Noun Terms of the SPRTs into the SocialTERMs and the EventTERMs
This subsection defines a target variable for classification, and introduces machine learning techniques used for classification in the previous text mining applications. In addition, it explains the experimental settings to generate configurations, which result from combining the different feature sets and different classification techniques.
2.4.1. Definition for a Target Variable
By referring to the examples, mentioned in the introduction, SocialTERM and EventTERM can be defined as below:
Definition 1. (SocialTERM) Given social-problem-related topics (SPRTs) and their key noun terms, the SocialTERM of a SPRT is defined as a key noun term that are perceived as: characterizing the SPRT as a social problem; and being a useful cue to identifying and monitoring the ongoing and future events of the social problem. SocialTERMs are irrelevant of the event-specific characteristics of the SPRTs, e.g., when and where the events of the SPRT happened, but reflective of the social-problem-specific perspectives of the SPRTs, e.g., what social problems the SPRT includes, and what causes are underlying such social problems.
Definition 2. (EventTERM) Given SPRTs and their key noun terms, the EventTERM of a SPRT is defined as a key noun term that is not perceived as a SocialTERM, because it is not able to explain the social-problem-specific characteristic of the SPRT but the event-specific characteristics of the events that belong to the SPRT. Thus, the EventTERMs are considered not useful to identifying and monitoring the ongoing and future events of social problems.
For the key noun terms obtained from the detected topics, their target variables,
y(
noun), are manually identified by three professional and experienced social scientists, invited as inspectors. Defined as Equation (26), these are used as the true values to be compared to the estimated values.
To assure the reliability of the manual investigation, Cohen’s Kappa,
k, is calculated for the inter-agreement between the three inspectors, and it is defined as
where
is the relative observed agreement among the three inspectors, and
is the hypothetical probability of chance agreement. The Cohen’s Kappa is a statistic that measures inter-rater agreement for categorical items, and it serves as an evidence that the combination of several sources reduced the bias of individual sources [
56,
67,
68]. For these reasons, it is adopted in this study to evaluate the consistency of annotated results by the three inspectors.
2.4.2. Machine Learning Techniques for Classification in the Previous Text Mining Applications
To distinguish between the SocialTERMs and the EventTERMs among the key noun terms of the detected SPRTs, this paper adopts supervised classification techniques, which have been extensively studied due to their high classification performance. Of the classification techniques that were used in the previous works in
Table 1, four commonly used classification techniques and a recently proposed deep-learning-based technique are adopted as base learners for this study. To name, they are C4.5 as Decision Tree (DT) [
9,
69], Naïve Bayes (NB) [
70,
71,
72], Radial Basis Function Network (RBFN) [
9], Support Vector Machine (SVM) [
73,
74], and Deep Belief Network (DBN) [
75,
76,
77]. Each of them is explained in the S.1 of
Supplementary Materials.
In addition to the five base learners, three types of ensemble methods are combined with each of the five base learners for this study. Ensemble learning is a machine learning paradigm in which multiple learners are trained to solve the same problem. In contrast to the base learners, which try to learn one hypothesis from the training data, the ensemble learning methods try to learn a set of hypotheses and combine them for use. In general, ensemble methods are divided into two categories: instance partitioning and feature partitioning. Bagging and Boosting are instance partitioning methods; RS is a feature partitioning method [
78].
Particularly, the three ensemble methods, namely Bagging, Boosting, and RS, are summarized as follows: Bagging is one of the simplest ensemble methods but has surprisingly good performance. The combination strategy of base learners for Bagging is majority voting. This strategy reduces the variance when combined with the base learner generation strategies. Bagging is particularly appealing when the available data are of limited size [
79]. Unlike Bagging, Boosting produces different base learners by sequentially giving instances that have been misclassified by the previous base learner larger weight in the next iteration of training. The final model that is obtained by Boosting is a linear combination of several base learners, which are weighted by their own performances. There are several Boosting algorithms; the most widely used is AdaBoost [
78]. RS is an ensemble construction technique, which uses random subspaces to both construct and aggregate the base learners. If a dataset has many redundant or irrelevant features, base learners in random subspaces may be better than in the original feature space. The combined decision of such base learners may be superior to that of a single classifier that is constructed on the original training dataset in the complete feature sets.
To the best of our knowledge from
Table 1, no previous study has compared the performances of the state-of-the-art classification techniques, particularly DBN, in distinguishing between the SocialTERMs and the EventTERMs among the key terms of the detected SPRTs. Hence, this study adopts the five base learners and their combinations with the three ensemble methods. Moreover, these classification techniques are compared in terms of their performances.
2.4.3. Experimental Settings on Features and Classification Techniques
In this paper, the experiments are performed with 60 configurations, which result from combining the three feature sets, namely F1, F1 + F2, and F1 + F2 + F3, and 20 classification techniques. Details on the experimental settings are as follows.
The three types of features, i.e., F1, F2, and F3, are obtained after the feature extraction of the
Section 2.3. Based on these different types of features, three feature sets are constructed in an incremental way: feature set F1; feature set F1 + F2; and feature set F1 + F2 + F3. This incremental order implies the evolutionary sequence of features [
19,
80].
In addition, three popular ensemble methods, i.e., Bagging, Boosting, and RS, are implemented respectively with the five base learners. Consequently, the paper uses 20 classification techniques to differentiate the SocialTERMs from the EventTERMs as described in
Table 5. For an experiment that uses one of the 20 classification techniques, a 10 fold validation is performed to train a classifier and evaluate it. Before performing the experiments, if the sample sizes of two classes in
y(
noun) of the data set for an experiment are imbalanced, the imbalanced problem has to be resolved because imbalanced datasets may have problems such as small sample size, overlapping or class separability, and small disjunctions [
81]. Previous approaches for dealing with imbalanced datasets are grouped into four categories: algorithm-level, e.g., Hellinger Distance Decision Trees; data-level, e.g., random oversampling and synthetic minority oversampling technique (SMOTE); cost-sensitive, e.g., AdaCost; and classifier ensembles, e.g., Bagging [
82]. Among them, the SMOTE approach is known for its good performances when adopted with ensemble methods [
81], and therefore it is used to deal with the imbalance problem of this study [
83].
Among the 20 classification techniques, to implement the conventional 16 classification approaches of DT, NB, RBFN, and SVM, the data mining toolkit WEKA (Waikato Environment for Knowledge Analysis) version 3.7.0 is used because it is the best-known open-source toolkit with a collection of various machine learning algorithms for solving data mining problems [
19,
78]. In detail, for the base learners, J48 module (WEKA’s own version of C4.5) for DT, RBFNetwork module for RBFN, NaïveBayes module for NB, and SMO module for SVM; for the ensemble methods, Bagging module for Bagging, AdaBoostM1 module for Boosting, and RandomSubSpace module for RS. Moreover, for DBN and its ensemble learning methods, python-based deep learning tutorials from ‘
www.deeplearning.net’ are used as references, and modified. In implementing DBN, the number of hidden layers is set to two, and the dimension in each layer is set to 100 by default.
2.5. Evaluate Results with Comparisons
This component assesses the performance of the configurations of three feature sets and 20 classification techniques for classifying the key noun terms of the SPRTs into the SocialTERMs and the EventTERMs. Among the standard metrics, widely used in IR and text classification studies, this paper uses the three performance measures, i.e., accuracy,
F-measure, and AUC to evaluates each configuration. In particular, the definition of accuracy can be explained with a confusion matrix as shown in
Table 6, and it is defined as
and
F-measure is obtained by
In addition, pairwise
t tests are used for the comparisons because they are the simplest statistical tests, and they are commonly used for comparing the performance of two algorithms. The pairwise
t tests examine whether the average difference in two approaches is significantly different from 0 by repeating the same experiments many times, particularly 50 times for this study [
19]. In detail, the effect of adding one feature set on the three performance measures for a certain classification technique is investigated by conducting 60 individual pairwise
t tests, i.e., 60 = three feature set comparisons
20 classification techniques. Moreover, classification techniques for a certain feature set are compared in terms of the three performance measures by conducting 120 individual pairwise
t tests, which are composed as follows: 30 between five BL classification techniques, i.e., 30 = 10 technique comparisons
three feature sets; 45 between five BL classification techniques and 15 ensemble learning methods, i.e., 45 = 15 technique comparisons
three feature sets; and 45 between 15 ensemble learning methods, i.e., 45 = 15 technique comparisons
three feature sets.
5. Conclusions
This paper proposed and examined an automatic approach, namely SocialTERM-Extractor, for distinguishing between the SocialTERMs and the EventTERMs among the key noun terms of the detected SPRTs from a large number of Korean online news articles. It aimed at resolving the challenging issues that were mentioned in
Section 1. Using the best-known news portal site of South Korea as a test-bed, experiments were conducted by following the proposed research framework, as explained in
Section 2. The experimental results in
Table 8 showed that the configuration of the full feature set, namely F1 + F2 + F3 and Boosting DT gave the best performances for accuracy, as well as
F-measure and AUC. Its high performances, e.g., 83.8769% accuracy, implies that the proposed approach can automatically identify the SocialTERMs in a reliable way (
RQ1 was partly answered).
Furthermore, according to
Figure 3, the pairwise
t tests on three performance measures for adding a feature set in
Table A6 indicated that most of the 20 classification techniques agreed that the three feature sets, namely F1, F2, and F3, contributed to improving the classification performance in a statistically significant way. In particular, it was agreed by all 20 classification techniques that adding sentiment feature set F2 improved the classification performance, in particular unanimously in terms of accuracy and AUC. When the best classification technique, namely Boosting DT, was used,
Table 9 showed that the individual addition of feature subsets such as F11, F12, F21, F23, and F31 increased all three performance measures actually. This indicates that the significant improvement in terms of three performance measures by adding feature sets in
Table A6 is attributed to such feature subsets (
RQ1 was partly answered).
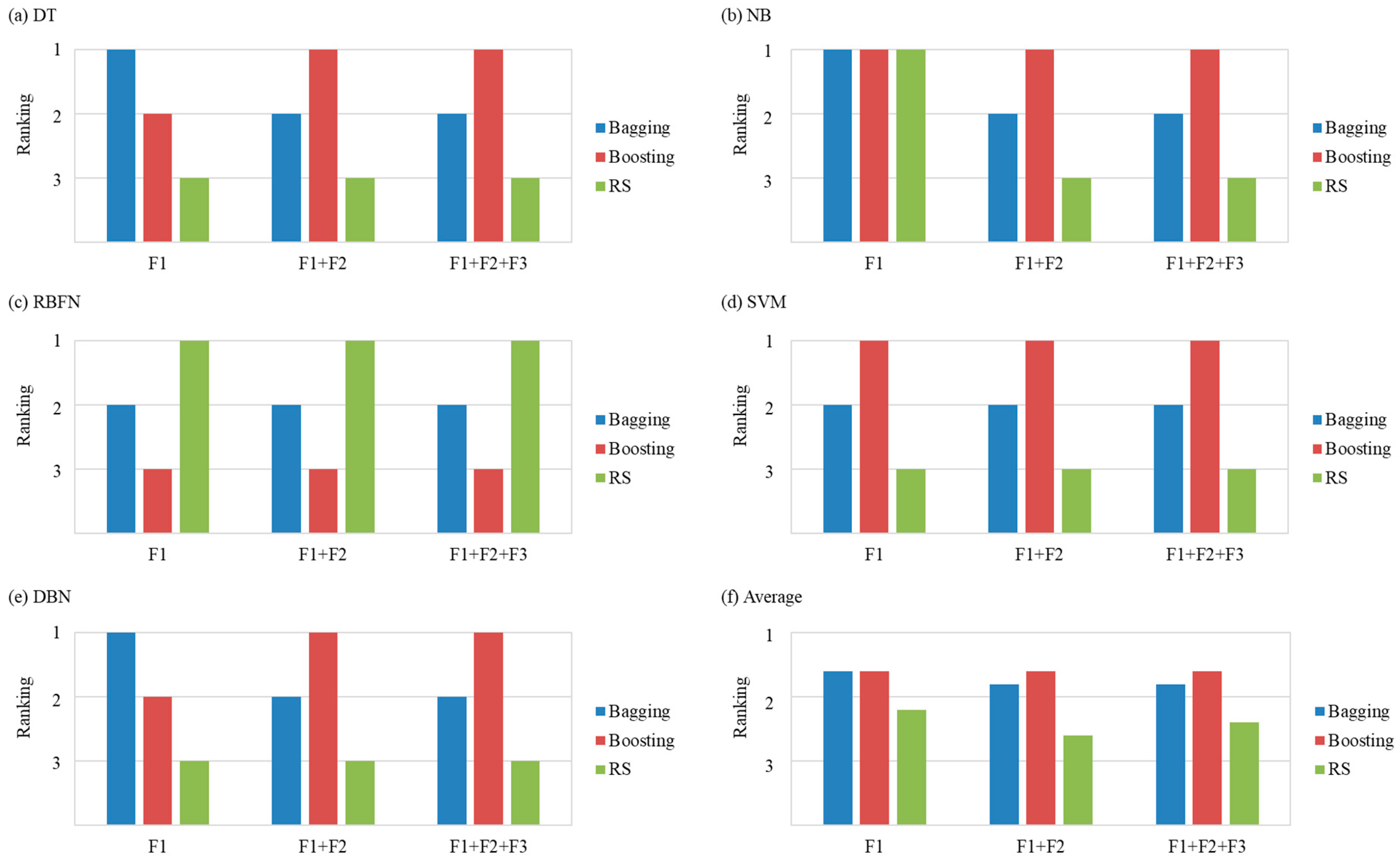
Relating to the comparisons of the classification techniques, according to
Figure 4 (and
Table A7), the performance rankings of all five base learners differed according to the selected feature sets (
RQ2 was answered). In addition,
Figure 5 (and
Table A8) revealed that most of the 20 configurations agreed that most ensemble learning methods produced better performances than the base learners (
RQ3 was answered). According to
Figure 6,
Figure 7 and
Figure 8 (and
Table A9), the ensemble method that obtains the best results depends on the feature sets and the base learners. Nevertheless, when the performance rankings of an ensemble method for a feature set were averaged over all types of base learners, ensemble learning methods with Boosting showed comparatively better results for all feature sets (
RQ3 was answered).
Theoretically, this paper contributes to expanding the related literature by applying text mining and machine learning techniques to a large number of online news articles as big data. To the best of our knowledge, this study is the first to provide an automatic approach for identifying and predicting the SocialTERMs of the detected SPRTs from online news articles. The appropriate SocialTERMs can be identified automatically so anybody, even someone who is unfamiliar with the ongoing social problems, can benefit from the automatic approach of this study. It helps enable everyone to recognize the landscape of the SPRTs from a large amount of event-related textual data without difficulty. In addition, this study has a significant impact on sustainability, since the SocialTERMs can be used as key noun terms in searching for technologies that are helpful for solving social problems and monitoring the ongoing and future events that are associated with the social problems. Eventually, the paper may facilitate innovations in our society by driving the development of technologies for ongoing and future social problems.
Practically, by answering RQ1~RQ2, this paper provided a reference and guidance for researchers, government officials, politicians, and companies that are in need of the system implementation. The paper investigated which kinds of feature sets are preferable, what kinds of classification techniques perform better, and how these two factors must be combined to obtain the best results. These results help determine the proper model for building a system with real-world large data. In the suggested research framework, the paper suggested novel approaches for representing the key noun terms: temporal weight, sentiment, and complex network structural features. Moreover, the paper compared state-of-the-art techniques, including the recently proposed DBN, which is a deep-learning-based technique. It showed that the simpler conventional classification method was better for this study, while the more complex DBN gave worse results. This indicates that the deep architecture is not a magic key for all kinds of problems in machine learning research, as it is known that the deep architecture works for big data cases with a lot of variables. However, as the results were not much worse compared to the other approaches, better performances by the deep architecture in the other applications may be possible.
Thus, if the automatic approach is implemented by developing a system, the system can automatically recommend the SocialTERMs, which are useful key noun terms for exploring technologies that can be used to solve social problems. The SocialTERMs can be applied to the prediction of future social problems and the monitoring the ongoing social problems from a large number of online news articles. Thus, this study finally helps obtain the new insights about how to identify ongoing and upcoming social problems from big data, thereby paving a way to big-data-driven social and technological innovations for the public good.
Further research can be conducted to overcome the limitations of this study. First, this study used only a large number of online news articles, but, in addition to online news articles, large-scale data from social media, e.g., YouTube, Twitter, and Facebook, may provide good sources for extracting temporal weight, sentiment, and complex network structural features on the key noun terms of the detected SPRTs. Second, the paper focused on the three types of features, but there may be other useful features, and more sophisticated classification techniques can be taken into account to improve the classification performance.
In addition, as future work, a portal site that provides the proposed methodology can be planned so that this methodology can be available to individuals and groups who are in need of identifying the SPRTs and their SocialTERMs. The easier-to-use method can also be considered in developing the portal site, e.g., k-means and latent Dirichlet allocation (LDA) for the TD approach. If developed, the proposed methodology and system can be evaluated in terms of whether they are helpful for users not only in exploring technologies for solving social problems but also in monitoring ongoing and future social problems based on a large amount of event-related textual data.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}