Customer Complaints Analysis Using Text Mining and Outcome-Driven Innovation Method for Market-Oriented Product Development


Abstract
:1. Introduction
2. Theoretical Background
2.1. Text Mining for Market-Oriented Product Development
2.2. Outcome-Driven Innovation Method
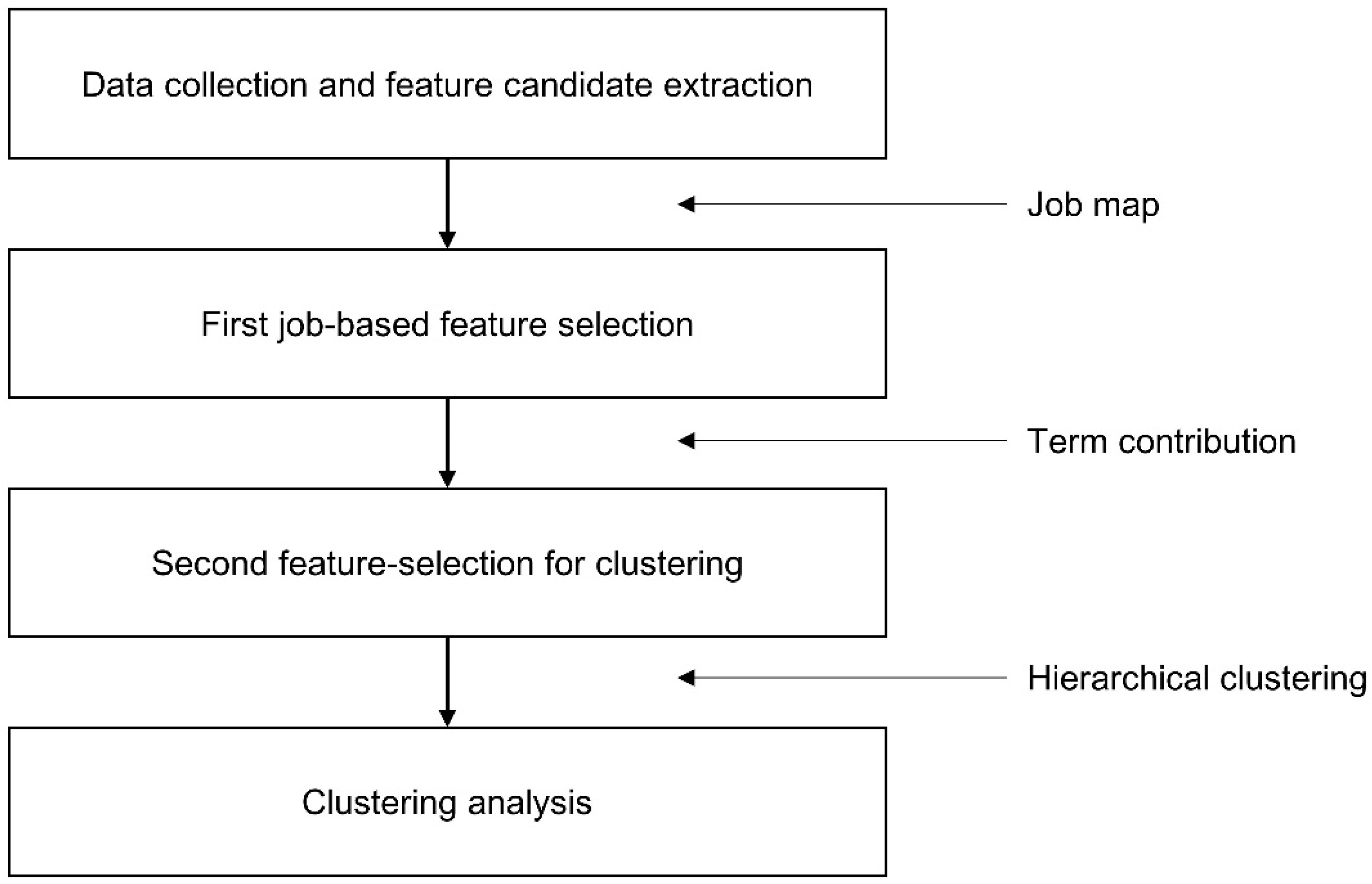
3. Proposed Method
3.1. Overall Research Framework
3.2. Data Collection and Feature Candidate Extraction
3.3. First Job-Based Feature Selection
3.4. Second Feature-Selection for Clustering
3.5. Clustering Analysis
4. Empirical Analysis: The Case of Stand-Type Air Conditioners
4.1. Collecting Data and Extracting Feature Candidates
4.2. Selecting First Job-Based Feature
4.3. Selecting Second Feature for Clustering
4.4. Analysing Clusters
5. Conclusions and Future Study
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. TC Ranking of First Feature Set and the Difference of TC Values

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Feature | TC Value | Rank | Difference |
|---|---|---|---|
| F1 | 13,503.58 | 1 | 374.76 |
| F2 | 13,128.82 | 2 | 2810.48 |
| F3 | 10,318.34 | 3 | 299.43 |
| F4 | 10,018.91 | 4 | 2550.85 |
| F5 | 7468.06 | 5 | 768.88 |
| F6 | 6699.18 | 6 | 361.87 |
| F7 | 6337.31 | 7 | 3223.71 |
| F8 | 3113.6 | 8 | 716.27 |
| F9 | 2397.33 | 9 | 389.86 |
| F10 | 2007.47 | 10 | 282.49 |
| F11 | 1724.98 | 11 | 212.23 |
| F12 | 1512.75 | 12 | 76.25 |
| F13 | 1436.5 | 13 | 0.08 |
| F14 | 1436.42 | 14 | 0.05 |
| F15 | 1436.37 | 15 | 87.29 |
| F16 | 1349.08 | 16 | 53.33 |
| F17 | 1295.75 | 17 | 86.7 |
| F18 | 1209.05 | 18 | 157.99 |
| F19 | 1051.06 | 19 | 61.32 |
| F20 | 989.74 | 20 | 334.91 |
| F21 | 654.83 | 21 | 36.28 |
| F22 | 618.55 | 22 | 59.48 |
| F23 | 559.07 | 23 | 4.36 |
| F24 | 554.71 | 24 | 3.75 |
| F25 | 550.96 | 25 | 23.27 |
| F26 | 527.69 | 26 | 22.75 |
| F27 | 504.94 | 27 | 9.94 |
| F28 | 495 | 28 | 25.43 |
| F29 | 469.57 | 29 | 29.43 |
| F30 | 440.14 | 30 | 17.36 |
| F31 | 422.78 | 31 | 16.66 |
| F32 | 406.12 | 32 | 23.06 |
| F33 | 383.06 | 33 | 162.32 |
| F34 | 220.74 | 34 | 5.14 |
| F35 | 215.6 | 35 | 8.09 |
| F36 | 207.51 | 36 | 1.73 |
| F37 | 205.78 | 37 | 13.6 |
| F38 | 192.18 | 38 | 4.26 |
| F39 | 187.92 | 39 | 1.09 |
| F40 | 186.83 | 40 | 0.34 |
| F41 | 186.49 | 41 | 7.44 |
| F42 | 179.05 | 42 | 9.55 |
| F43 | 169.5 | 43 | 33.1 |
| F44 | 136.4 | 44 | 19.27 |
| F45 | 117.13 | 45 | 7.05 |
| F46 | 110.08 | 46 | 7.19 |
| F47 | 102.89 | 47 | 7.18 |
| F48 | 95.71 | 48 | 4.33 |
| F49 | 91.38 | 49 | 1.03 |
| F50 | 90.35 | 50 | 7.06 |
| F51 | 83.29 | 51 | 3.32 |
| F52 | 79.97 | 52 | 22.49 |
| F53 | 57.48 | 53 | 27.15 |
| F54 | 30.33 | 54 | 30.33 |
Appendix B. The Result of Clustering Analysis on the Stand-Type Air Conditioner
| Number of Clusters (Ratio) | Customer Requirements | Representative Feature | Job Step | |
|---|---|---|---|---|
| Cluster 1 (18.6%) | 1 | Increase the amount of releasing cool air during device operation | Cool air-weak (냉기 약하다) | Execute |
| 2 | Increase the range of releasing cool air during device operation | Execute | ||
| Cluster 2 (9.5%) | 3 | Minimize the time to achieve target indoor temperature during device operation | Cool (시원한) Temperature (온도) | Execute |
| Cluster 3 (12.0%) | 4 | Minimize the frequency of at which device stops releasing cold wind | Wind (바람) Temperature (온도) | Execute |
| 5 | Minimize the time to take to release cold wind after turning on device | Execute | ||
| Cluster 4 (5.5%) | 6 | Minimize the time to monitor cooling capacity of the device | Temperature (온도) | Monitor |
| Cluster 5 (4.0%) | 7 | Minimize the likelihood of side effect after installation | Installation (설치) | Prepare |
| 8 | Minimize the time to identify side effect after installation | Confirm | ||
| Cluster 6 (6.2%) | 9 | Minimize scratches on the surface of the device | Scratch (기스) | Monitor |
| 10 | Minimize cracks on the surface of the device | Monitor | ||
| 11 | Minimize discoloration on the surface of the device | Monitor | ||
| Cluster 7 (7.0%) | 12 | Minimize the likelihood of malfunction after voice command | Voice (음성) | Execute |
| 13 | Increase speech recognition rate during voice command mode | Execute | ||
| Cluster 8 (4.9%) | 14 | Minimize the frequency of hiatus of device operation | Power supply (전원) | Execute |
| 15 | Minimize number not to run power button | Execute | ||
| Cluster 9 (5.2%) | 16 | Minimize noise of parts which decide the direction of the wind during device operation | Noise (소음), wing (날개) | Monitor |
| Cluster 10 (5.6%) | 17 | Minimize the frequency not to function the direction of the wind in modifying the wind | wing (날개) | Modify |
| Cluster 11 (5.3%) | 18 | Minimize the frequency which device emits stench during device operation | Smell (냄새) | Monitor |
| Cluster 12 (4.7%) | 19 | Minimize indoor noise during device operation | Indoor (실내), Noise (소음) | Monitor |
| Cluster 13 (5.4%) | 20 | Minimize outdoor noise during device operation | Outdoor (실외), Noise (소음), Operation (작동) | Monitor |
| 21 | Minimize the time to monitor loudness level of noise during device operation | Monitor | ||
| Cluster 14 (6.0%) | 22 | Minimize noise in performing specific function | Noise (소음) | Modify |
References
- Lengnick-Hall, C.A. Customer contributions to quality: A different view of the customer-oriented firm. Acad. Manag. Rev. 1996, 21, 791–824. [Google Scholar] [CrossRef]
- Nambisan, S. Designing virtual customer environment for new product development: Toward a theory. Acad. Manag. Rev. 2002, 27, 392–413. [Google Scholar] [CrossRef]
- Rigby, D.; Zook, C. Open-market innovation. Harv. Bus. Rev. 2002, 80, 80–81. [Google Scholar] [CrossRef] [PubMed]
- Atuahene-Gima, K. An Exploratory Analysis of the impact of market orientation on new product performance: A contingency approach. J. Prod. Innov. Manag. 1995, 12, 19. [Google Scholar] [CrossRef]
- Zhan, J.; Loh, H.T.; Liu, Y. Gather customer concerns from online product reviews—A text summarization approach. Expert Syst. Appl. 2009, 36, 2107–2115. [Google Scholar] [CrossRef]
- Decker, R.; Trusov, M. Estimating aggregate consumer preferences from online product reviews. Int. J. Res. Mark. 2010, 27, 293–307. [Google Scholar] [CrossRef]
- Park, Y.; Lee, S. How to design and utilize online customer centre to support new product concept generation. Expert Syst. Appl. 2011, 38, 10638–10647. [Google Scholar] [CrossRef]
- Aguwa, C.C.; Monplaisir, L.; Turgut, O. Voice of the customer: Customer satisfaction ratio based analysis. Expert Syst. Appl. 2012, 39, 10112–10119. [Google Scholar] [CrossRef]
- Wang, Y.; Tseng, M.M. A Naïve Bayes approach to map customer requirements to product variants. J. Intell. Manuf. 2015, 26, 501–509. [Google Scholar] [CrossRef]
- Aguwa, C.; Olya, M.H.; Monplaisir, L. Modeling of fuzzy-based voice of customer for business decision analytics. Knowl.-Based Syst. 2017, 125, 136–145. [Google Scholar] [CrossRef]
- Liang, R.; Guo, W.; Yang, D. Mining product problems from online feedback of Chinese users. Kybernetes 2017, 46, 572–586. [Google Scholar] [CrossRef]
- Qiao, Z.; Zhang, X.; Zhou, M.; Wang, G.A.; Fan, W. A domain oriented LDA model for mining product defects from online customer reviews. In Proceedings of the 50th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 4–7 January 2017. [Google Scholar]
- Wang, Y.; Lu, X.; Tan, Y. Impact of product attributes on customer satisfaction: An analysis of online reviews for washing machines. Electron. Commer. Res. Appl. 2018, 29, 1–11. [Google Scholar] [CrossRef]
- Min, H.; Yun, J.; Geum, Y. Analysing dynamic change in customer requirements: An approach using review-based Kano analysis. Sustainability 2018, 10, 746. [Google Scholar] [CrossRef]
- Leonard, D. The limitations of listening. Harv. Bus. Rev. 2002, 1, 155–171. [Google Scholar]
- Füller, J.; Matzler, K. Virtual product experience and customer participation—A chance for customer-centred, really new products. Technovation 2007, 27, 378–387. [Google Scholar] [CrossRef]
- Christensen, C.M.; Anthony, S.D.; Berstell, G.; Nitterhouse, D. Finding the right job for your product. MIT Sloan Manag. Rev. 2007, 48, 38. [Google Scholar]
- Ulwick, A.W. What Customers Want: Using Outcome-Driven Innovation to Create Breakthrough Products and Services; McGraw-Hill: New York, NY, USA, 2005. [Google Scholar]
- Ulwick, A.W. Jobs to Be Done: Theory to Practice; IDEA BITE Press: New York, NY, USA, 2016. [Google Scholar]
- Menon, R.; Tong, L.H.; Sathiyakeerthi, S.; Brombacher, A.; Leong, C. The needs and benefits of applying textual data mining within the product development process. Qual. Reliab. Eng. Int. 2004, 20, 1–15. [Google Scholar] [CrossRef]
- Bradley, G.L.; Sparks, B.A.; Weber, K. Perceived prevalence and personal impact of negative online reviews. J. Serv. Manag. 2016, 27, 507–533. [Google Scholar] [CrossRef]
- Hennig-Thurau, T.; Gwinner, K.P.; Walsh, G.; Gremler, D.D. Electronic word-of-mouth via consumer-opinion platforms: What motivates consumers to articulate themselves on the Internet? J. Interact. Mark. 2004, 18, 38–52. [Google Scholar] [CrossRef]
- King, R.A.; Racherla, P.; Bush, V.D. What we know and don’t know about online word-of-mouth: A review and synthesis of the literature. J. Interact. Mark. 2014, 28, 167–183. [Google Scholar] [CrossRef]
- Johnson, P.A.; Sieber, R.E.; Magnien, N.; Ariwi, J. Automated web harvesting to collect and analyse user-generated content for tourism. Curr. Issues Tour. 2012, 15, 293–299. [Google Scholar] [CrossRef]
- Liu, B. Web Data Mining: Exploring Hyperlinks, Contents and Usage Data; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Mankad, S.; Han, H.S.; Goh, J.; Gavirneni, S. Understanding online hotel reviews through automated text analysis. Serv. Sci. 2016, 8, 124–138. [Google Scholar] [CrossRef]
- Miguéis, V.L.; Nóvoa, H. Exploring online travel reviews using data analytics: An exploratory study. Serv. Sci. 2017, 9, 315–323. [Google Scholar] [CrossRef]
- Ordenes, F.V.; Theodoulidis, B.; Burton, J.; Gruber, T.; Zaki, M. Analysing customer experience feedback using text mining: A linguistics-based approach. J. Serv. Res. 2014, 17, 278–295. [Google Scholar] [CrossRef]
- Bettencourt, L.A.; Ulwick, A.W. The customer-centered innovation map. Harv. Bus. Rev. 2008, 86, 109. [Google Scholar] [PubMed]
- Ulwick, A.W. Turn customer input into innovation. Harv. Bus. Rev. 2002, 80, 91–97. [Google Scholar] [PubMed]
- Leonard, D.; Rayport, J.F. Spark innovation through empathic design. Harv. Bus. Rev. 1997, 75, 102–115. [Google Scholar] [CrossRef]
- Bettencourt, L. Service Innovation: How to Go from Customer Needs to Breakthrough Services; McGraw Hill Professional: New York, NY, USA, 2010. [Google Scholar]
- Lim, J.; Choi, S.; Lim, C.; Kim, K. SAO-based semantic mining of patents for semi-automatic construction of a customer job map. Sustainability 2017, 9, 1386. [Google Scholar] [CrossRef]
- Oestreicher, K.G. Segmentation & the jobs-to-be-done theory: A conceptual approach to explaining product failure. J. Mark. Dev. Compet. 2011, 5, 103. [Google Scholar]
- Boyd-Graber, J.; Mimno, D.; Newman, D. Care and feeding of topic models: Problems, diagnostics and improvements. In Handbook of Mixed Membership Models and Their Applications; CRC Press: Boca Raton, FL, USA, 2014; pp. 225–255. [Google Scholar]
- Mitra, P.; Murthy, C.A.; Pal, S.K. Unsupervised feature selection using feature similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Liu, S.; Chen, Z.; Ma, W. An evaluation on feature selection for text clustering. In Proceedings of the 20th International Conference on Machine Learning, Washington DC, USA, 21–24 August 2003; pp. 488–495. [Google Scholar] [CrossRef]
- Alelyani, S.; Tang, J.; Liu, H. Feature selection for clustering: A review. Data Clust. Algorithms Appl. 2013, 29, 110–121. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: Berlin, Germany, 2002. [Google Scholar]
- Slonim, N.; Tishby, N. Document clustering using word clusters via the information bottleneck method. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 208–215. [Google Scholar]
- Yang, Y.; Pedersen, J.O. A comparative study on feature selection in text categorization. In Proceedings of the Fourteenth International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; pp. 412–420. [Google Scholar]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Salton, G. Automatic text processing: The transformation. Anal. Retr. Inf. Comput. 1989, 14, 15. [Google Scholar]
- Joung, J.; Kim, K. Monitoring emerging technologies for technology planning using technical keyword based analysis from patent data. Technol. Forecast. Soc. Chang. 2017, 114, 281–292. [Google Scholar] [CrossRef]
- Ulwick, A.W.; Bettencourt, L.A. Giving customers a fair hearing. MIT Sloan Manag. Rev. 2008, 49, 62–68. [Google Scholar]
- Wu, H.C.; Luk, R.W.P.; Wong, K.F.; Kwok, K.L. Interpreting TF-IDF term weights as making relevance decisions. ACM Trans. Inf. Syst. 2008, 26, 13. [Google Scholar] [CrossRef]
- Lam, S.K.; Sleep, S.; Hennig-Thurau, T.; Sridhar, S.; Saboo, A.R. Leveraging frontline employees’ small data and firm-level big data in frontline management: An absorptive capacity perspective. J. Serv. Res. 2017, 20, 12–28. [Google Scholar] [CrossRef]



| Rules For Structuring Customer Requirements | |
|---|---|
| 1. | Needs statements must be free from solutions and specifications—and stable over time. |
| 2. | Needs statements must not include words that will cause ambiguity or confusion, for example, certain adjectives and adverbs, pronouns, process words, jargon, acronyms. |
| 3. | Needs statements must be specific without sacrificing brevity. |
| 4. | Needs statements must follow the rules of proper grammar. |
| 5. | Do not use different terms to describe the same item or activity from statement to statement; be consistent in language. |
| 6. | Needs statement must have a consistent structure, content and format. |
| 7. | Needs statements must relate to the primary job of interest and not to ancillary jobs. |
| 8. | Needs statements must be introduced with only one of two words: minimize (90%) or increase (10%). |
| 9. | Needs statements must contain a metric (time, likelihood, number) so performance can be measured. |
| 10. | Examples added to the end of a statement for purposes of clarification must be similarly and consistently formatted. |
| 11. | Needs statements must be usable in all downstream activities, for example, questionnaires, for deployment. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joung, J.; Jung, K.; Ko, S.; Kim, K. Customer Complaints Analysis Using Text Mining and Outcome-Driven Innovation Method for Market-Oriented Product Development. Sustainability 2019, 11, 40. https://doi.org/10.3390/su11010040
Joung J, Jung K, Ko S, Kim K. Customer Complaints Analysis Using Text Mining and Outcome-Driven Innovation Method for Market-Oriented Product Development. Sustainability. 2019; 11(1):40. https://doi.org/10.3390/su11010040
Chicago/Turabian StyleJoung, Junegak, Kiwook Jung, Sanghyun Ko, and Kwangsoo Kim. 2019. "Customer Complaints Analysis Using Text Mining and Outcome-Driven Innovation Method for Market-Oriented Product Development" Sustainability 11, no. 1: 40. https://doi.org/10.3390/su11010040