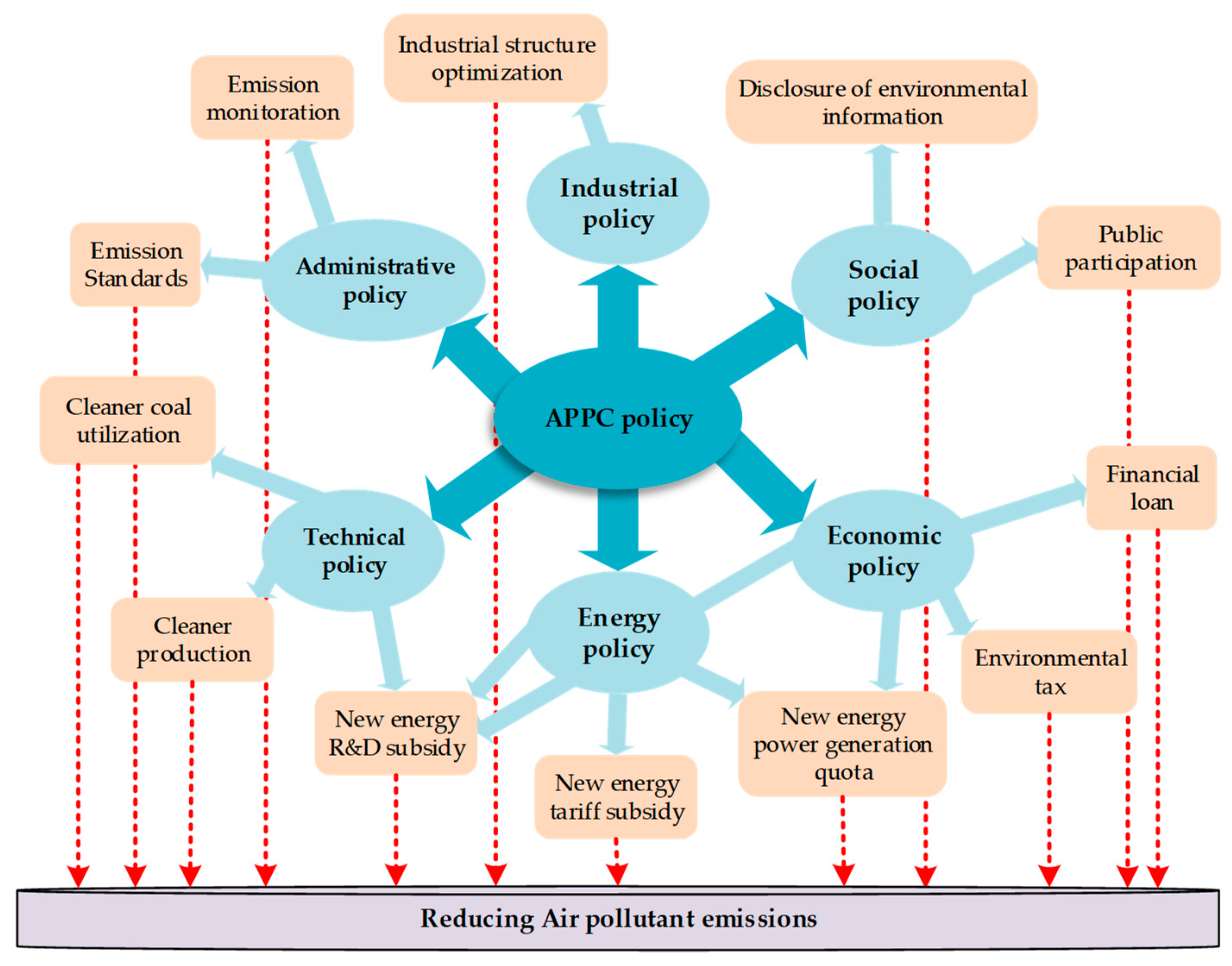
3.1. Model Construction Ideas and Variable Selection
In this paper, the basic idea of constructing short-term load forecasting model considering the impact of APPC measures is that based on the traditional short-term load forecasting framework, the APPC measures are introduced as a policy impact variable to construct the mapping relationship between APPC measures and regional short-term load, so as to forecast the regional short-term load.
Considering that the APPC policy has characteristics that are difficult to quantify, this paper takes the factor that most influences APPC measures, namely the air quality indicator, as the policy impact variable, which is based on the following assumption: when the regional air quality indicator reaches a certain level, different levels of air pollution warning will be triggered, and different levels of APPC measures will be initiated accordingly. By acting on different power users, the electricity consumption behavior of these users will be affected, thus affecting the short-term power load in this area.
Commonly used air quality indicators include air quality index (AQI) value, PM2.5 concentration and PM10 concentration. According to the meaning of different indicators and the conditions for air quality warning starting [
49], this paper uses AQI, an indicator that can comprehensively reflect regional air quality as a policy impact variable for APPC measures. According to the correspondence between the air pollution warning level and the AQI value, this paper classifies the AQI value, and then analyzes the changes of short-term load in different air quality levels, which reflects the impact of APPC measures on regional short-term load.
In line with the research results of traditional short-term load forecasting [
31,
37,
38,
40], and combined with the above-mentioned analysis of the impact mechanism of APPC measures on short-term power load, the short-term power load influencing factors in this paper including temperature and meteorological indicators, date type indicators, and APPC impact indicator, and each variable and the valuing rules are shown in
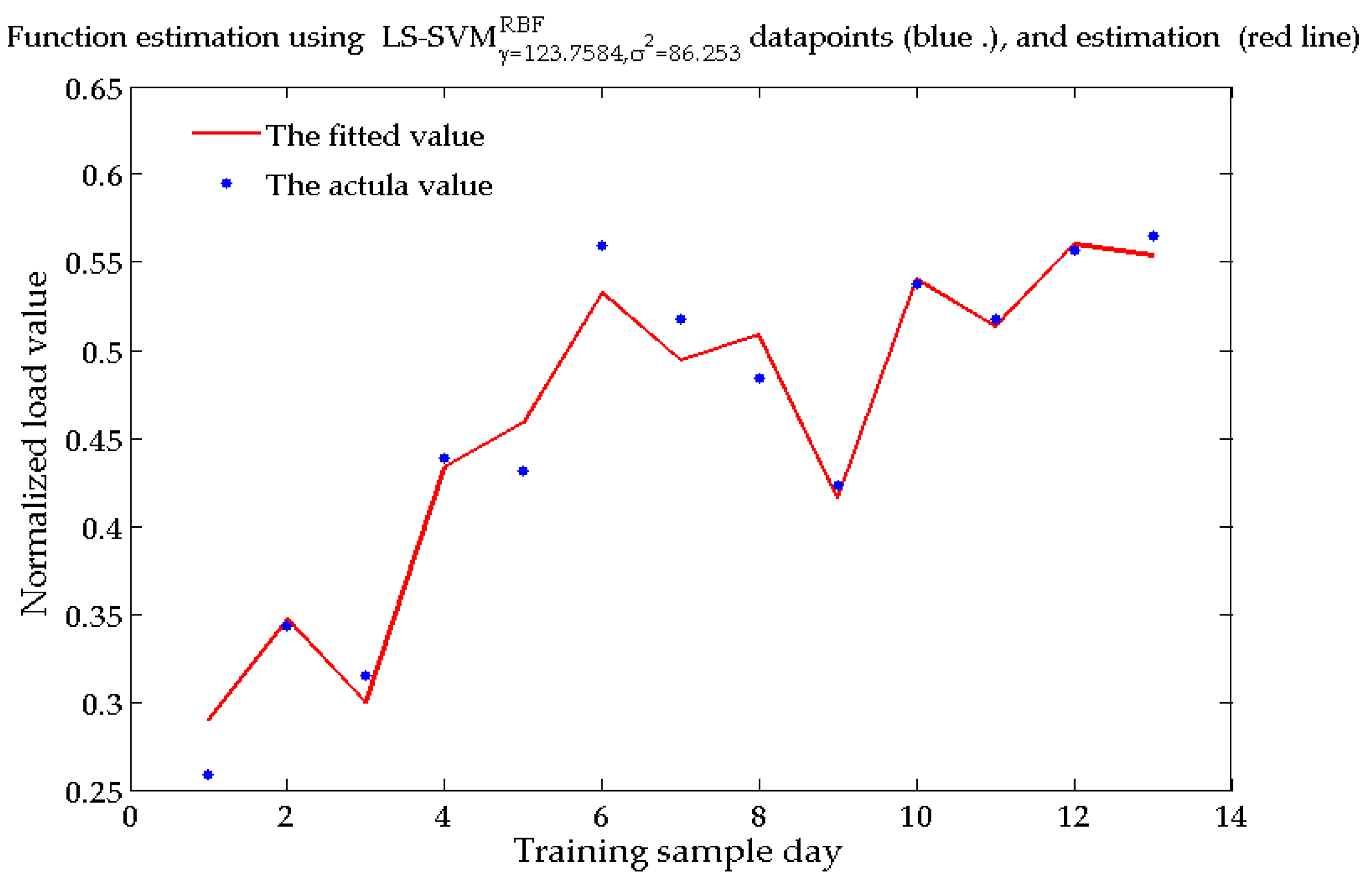
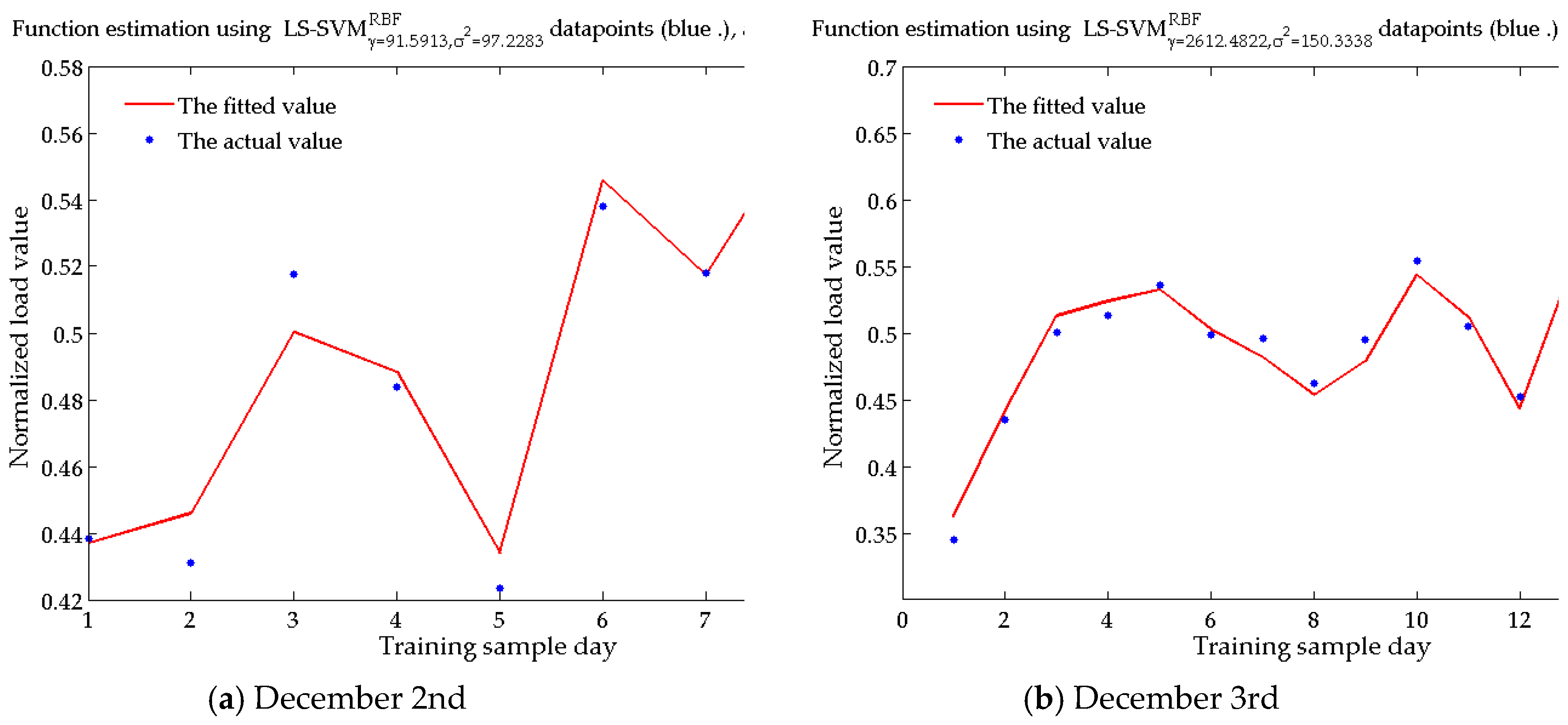
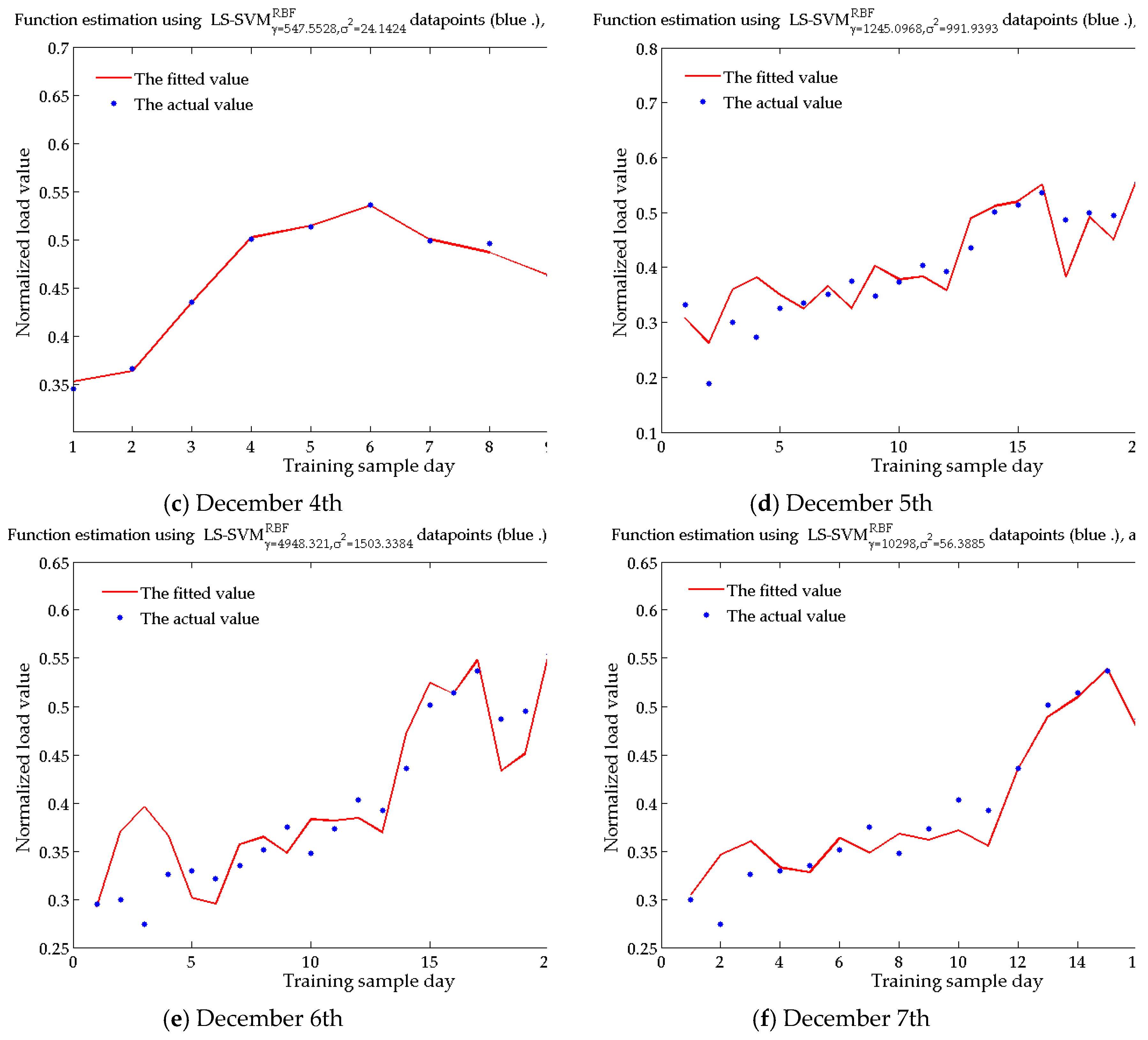
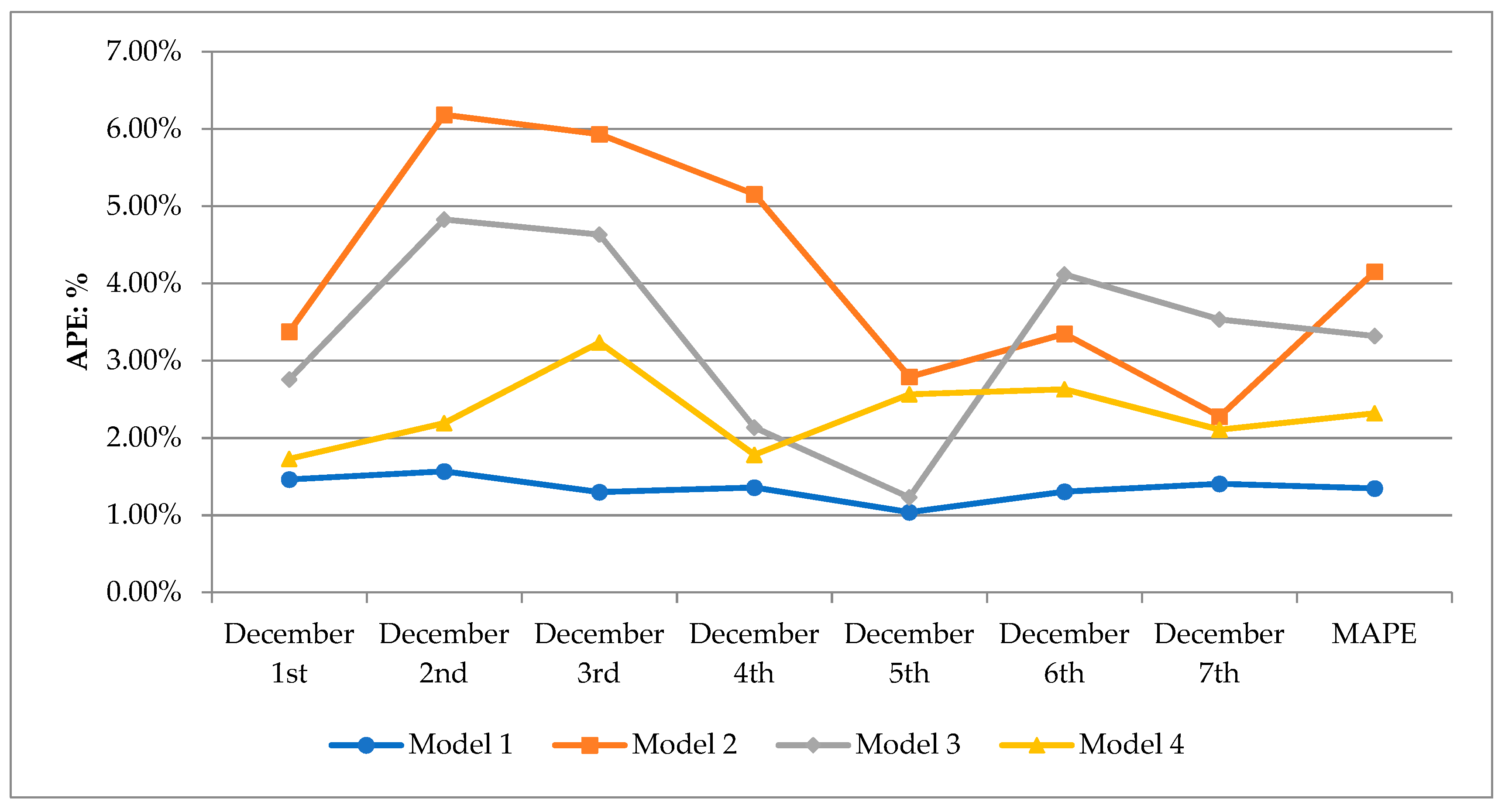
Table 1. Taking the above-mentioned influencing factors as the input variables, and the regional daily load as the output variable, according to the characteristics of the day to be predicted, the BWM-GRA method is used to select the similar day to construct training sample set from the historical day, and the SSA-LSSVM technique is adopted to train and obtain the short-term load forecasting model that can reflect the quantitative relationship between each influencing factor and the regional short-term load. Finally, an actual example is used to verify the validity of the model.
3.2. Similar Day Selection Based on BWM-GRA
Considering the characteristics of the days to be predicted, if use all the daily data in the historical sample set as the training samples, there may be a bias in the forecasting result due to the difference between characteristics of the historical sample days and the days to be predicted. Therefore, it is necessary to select days which have similar daily characteristics to the predicted days from the historical sample set as the training sample set. In this section, the indicators that reflect the characteristics of the days are the input variables including AQI, meteorological indicators and date type, as shown in
Table 1.
Because the data in the sample set is characterized by high dimensionality, numerical type, and no markup, this paper employs the GRA method to classify the training sample set according to relevant references [
37,
40,
42]. However, the traditional GRA method assumes that each feature variable in the sequence is equivalent, that is, the similarity degree of each feature variable has the same effect on the overall gray relation degree of the sequence. In fact, when selecting similar days for short-term load forecasting, the indicators that constitute similar day characteristics have different effects on short-term loads. For example, the effect of temperature on the daily load is usually large, while the influence degree of wind speed on the daily load is less than temperature. Therefore, when GRA is used to select similar days, the sample days with similar temperatures should be more similar to the sample days with similar wind speeds, that is, have higher closeness.
According to the above discussion, this paper improves the similar day selection method based on traditional GRA by introducing the index weighting method, and proposes a similar day selection method based on BWM-GRA, of which BWM is the best and worst method, and its advantages are [
41,
50,
51]:
Firstly, the BWM method requires less information on the object to be evaluated. The basic idea of determining the weight based on BWM is to judge the importance according to the nature of the indicator. Therefore, the actual value of each indicator is not needed, revealing that it can be applied to the indicator system with qualitative indicators, and also to the issue where only one evaluation object is involved.
Secondly, the BWM method is simple and logically rigorous. Compared with AHP, BWM greatly simplifies the process of comparing indicators by setting best and worst indicators. In addition, by turning the indicator weighting problem into an optimization problem, the reliability of the weighting result is improved.
The similar day selection steps based on BWM-GRA proposed in this paper are as follows:
Step 1: Construct a similar daily sample set. Based on the valuing rule of the indicators in
Table 1, the values of the seven daily characteristic indicators of all historical sample days are collected to form a total similar daily sample set.
Step 2: Characteristic indicator weighting. The BWM method is used to determine the weight of each characteristic indicator, which reflects the influence degree of each characteristic indicator on the similar day selection result.
Step 3: Use the GRA method to select similar days. Firstly, it is assumed that the characteristic vector is composed of the values of the daily characteristic indicators, the daily characteristic vectors of the day to be forecasted is , and the daily characteristic vectors in the similar daily sample set are , where is the dimension of the feature vector, is the number of similar days, represents the -th characteristic indicator value of the day to be predicted, and represents the -th characteristic indicator value of the -th sample day in the similar daily sample set.
Secondly, the characteristic indicator is normalized by the following method:
where,
.
Thirdly, considering the determination of the resolution coefficient in the traditional GRA method is subjective, this paper uses a gray relational construction method based on the differential and exponential operation to define the comprehensive gray relational degree. Specifically, the difference between each day characteristic indicator of the day to be forecasted and the day in a similar daily sample set is calculated by:
Furthermore, according to
, the indicator similarity gray relational degree is constructed by:
Finally, the gray relational degree of indicator similarity is integrated with the indicator weight to obtain the comprehensive gray relational degree, that is:
Step 4: For each day to be predicted, set a gray relational threshold of the day, and select the similar day sample whose gray relational degree value is greater than the given threshold to constitute the training sample set for the day to be predicted.
3.3. Short-Term Load Forecasting Model Based on SSA-LSSVM
The least squares support vector machine (LSSVM) [
52] is a form of SVM under the quadratic loss function. It is a model that uses the statistical learning theory of small sample data to find the optimal linear regression hyperplane to retrieve data in high dimensional feature space. The basic idea of the LSSVM is derived from the optimal separation hyperplane, the method of maximizing interval and adopting nuclear learning, which is a concrete realization of the principle of structural risk minimization on statistical learning. It replaces the quadratic programming solution optimization problem by solving linear equations, and has the advantages of simplifying model, solving quickly and without losing precision [
53].
For a training sample set:
, where
is the input vector and
is the output value, the following decision function can be constructed as a learning machine:
where
is a linearly separable nonlinear high-dimensional mapping relation that
maps into high-dimensional space;
is the weight and
is the offset value.
The structural risk function is:
where
is the complexity of the control model;
is the regularization parameter;
is the empirical risk.
In the LSSVM modeling process,
, then the optimization problem of minimizing structural risk can be expressed as:
where
is the error relaxation variable,
.
The Lagrange multiplier and dual transformation method are employed to transform the above planning problems. According to the KKT condition, the following normal equations are collated:
where
is the dual variable of the planning problem. Construct a kernel function that satisfies the Mercer theorem as follows [
54]:
Then the optimization problem shown in Equations (7)–(8) can be expressed as [
42]:
where
,
.
The kernel functions available for the LSSVM model include the Sigmoid kernel function, the Polynomial kernel function, and the Radial Basis Function (RBF) kernel function. The RBF kernel function has fewer preset parameters and thus can be well adapted to practical problems. Therefore, this paper adopts the RBF function as the kernel function of the LSSVM model, that is [
55]:
After selecting the appropriate kernel function
to solve the nonlinear regression problem, Equation (11) can be solved and the following decision function can be obtained:
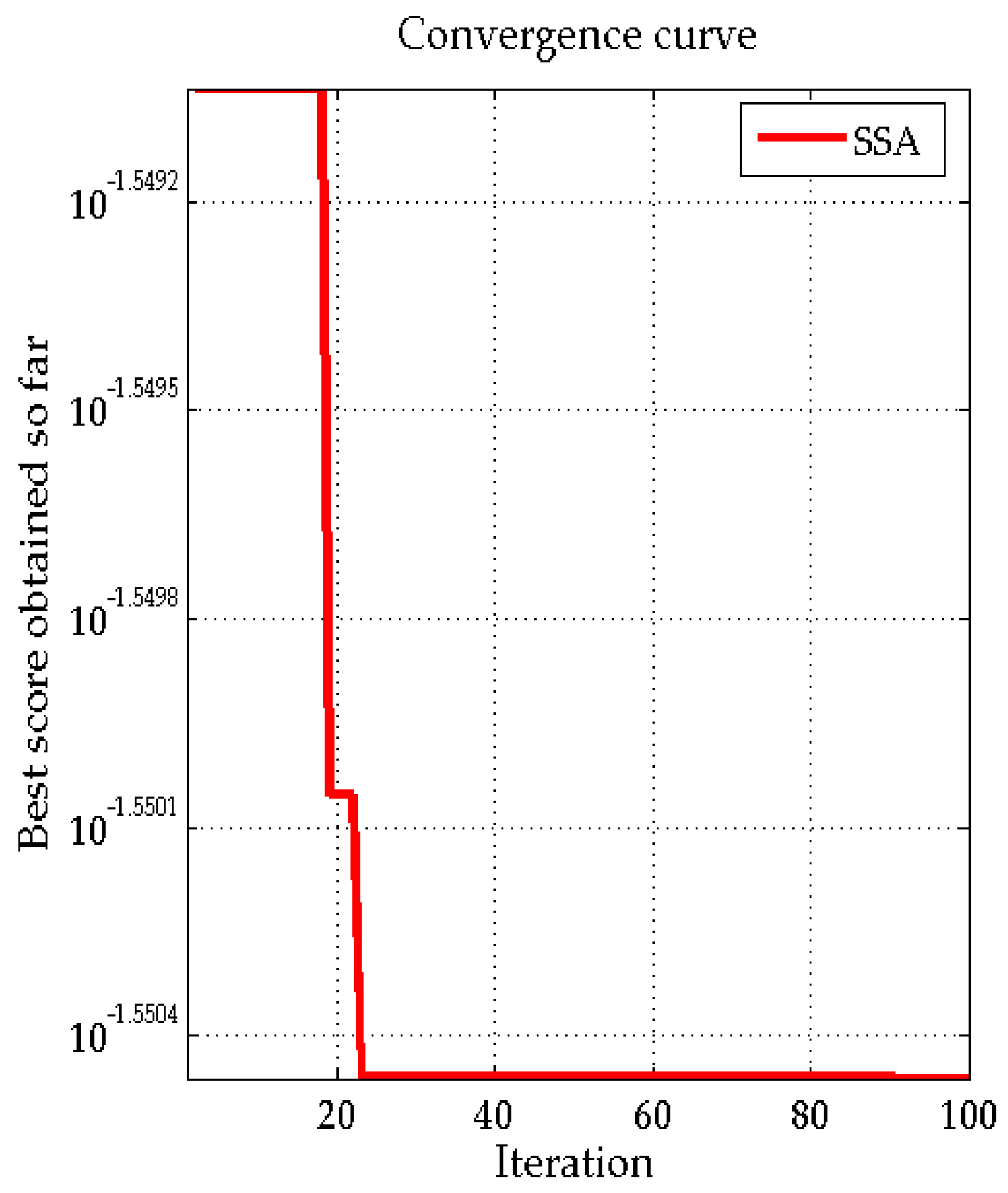
In Equation (13), there are two parameters needed to be determined, that is, the regularization parameter and the kernel function parameter . In order to avoid the influence of subjective factors, this paper uses the salp swarm algorithm (SSA) to automatically find the optimal values of the two parameters.
The salp is a kind of deep-sea animal that usually exhibits collective action, forming a group called the salp chain, so as to achieve better movement by quickly coordinating with the location of the food. Based on this, Australian scholar Mirjalili S proposed a new heuristic optimization method, entitled the salp swarm algorithm (SSA) [
56]. In the SSA method, the initial population is divided into leaders and followers, and the leader leads the chain of the salp, followed by the followers. Assuming that there is a food source in the search space which is the salp chain target, called
, according to the behavior of the salp chain, the specific optimization steps are as follows [
42,
56,
57]:
(1) Set the parameters. SSA mainly includes five parameters, namely, the initial number of population, the number of variables, the maximum number of iterations, the lower bound of the variable and the upper bound of the variable.
(2) Population initialization. In the SSA algorithm, the initial population of the salp group is initialized at random locations, and the position matrix is as follows:
where
is the value of the
-th variable of the
-th salp,
, and
is calculated by Equation (15):
where
is a random matrix whose all elements are distributed in the [0,1] interval.
and
represent the upper and lower bounds of the
-th salp, respectively.
(3) Construct a fitness function. The fitness function is used to calculate each salp’s fitness value determined during the optimization process, and all values are stored in the matrix
as follows:
In the matrix , the position of the salp with the best fitness value is considered as the food source , and its position is tracked by the salp chain, so that the global optimum value can be obtained by moving the food source .
(4) Iterative process. In order to perform a global search and avoid local optimization, all of the salps will update their positions through specific steps in the SSA method. Among them, the way the leader updates the location of the food source is:
where
represents the position of the leader (the first salp) in the
-th dimension,
is the location of the food source,
and
represent the upper and lower bounds, respectively, and
,
and
are all random numbers. Specifically,
and
are randomly generated in the interval [0,1] to determine the step size and direction of the
-th dimension moving to the next position, and
is defined as follows:
where
is the maximum number of iterations and
is the current number of iterations. The follower’s location can be updated as follows:
Except for initialization, all steps are performed during the iteration until the end standard of the SSA iteration is reached.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}