Abstract
Data envelopment analysis (DEA) is a data-driven tool for performance evaluation, benchmarking and multiple-criteria decision-making. This article investigates efficiency decomposition in a two-stage network DEA model. Three major methods for efficiency decomposition have been proposed: uniform efficiency decomposition, Nash bargaining game decomposition, and priority decomposition. These models were developed on the basis of different assumptions that led to different efficiency decompositions and thus confusion among researchers. The current paper attempts to reconcile these differences by redefining the fairness of efficiency decomposition based on efficiency rank, and develops a rank-based model with two parameters. In our new rank-based model, these three efficiency decomposition methods can be treated as special cases where these parameters take special values. By showing the continuity of the Pareto front, we simplify the uniform efficiency decomposition, and indicate that the uniform efficiency decomposition and Nash bargaining game decomposition can converge to the same efficiency decomposition. To demonstrate the merits of our model, we use data from the literature to evaluate the performance of 10 Chinese banks, and compare the different efficiency decompositions created by different methods. Last, we apply the proposed model to the performance evaluation of sustainable product design in the automobile industry.
1. Introduction
Data envelopment analysis (DEA), as introduced by Charnes et al. [1], is a data-driven tool for performance evaluation, benchmarking, and multiple-criteria decision-making [2,3,4]. Through identifying the best practices of peer decision-making units (DMUs) in the presence of multiple inputs and outputs, DEA provides practical insight for managers, policy makers, and so on. It has been widely noted that DMUs may have two-stage network structures with intermediate measures [5,6,7,8,9], and the models for evaluating efficiencies of such DMUs are called two-stage network DEA models. Two-stage network DEA models have been shown to have a variety of applications, such as for schools, banks, energy, and the environment [10,11,12,13,14,15]. In particular, due to the two-stage network DEA taking multiple variables into consideration and balancing multiple objectives in the evaluation process, it has been a popular approach to sustainability-related problems recently, such as the evaluation of sustainability development [16] and sustainable product design [17,18]. One of the merits of two-stage network DEA models is that the estimated sub-stage efficiencies help decision-makers to establish the inefficient source and improvement directions for each DMU under evaluation.
Cook et al. [5] organized the existing two-stage network DEA models into four categories: standard DEA approach, efficiency decomposition approach, network DEA approach, and game-theoretical approach. The standard DEA approach treats the two sub-stages of a two-stage DMU independently, while the other three address the conflicts of intermediate measures between the two sub-stages. The conflicts result from the divergent aims of the two sub-stages: in order to perform better, the first stage increases the intermediate products, while the second stage reduces the intermediate products.
Among the three non-standard DEA approaches, the centralized model proposed by Liang et al. [19] and the relational model proposed by Kao and Hwang [20] are particularly popular and influential. These models both assume that the multipliers of intermediate measures are the same. Regardless of whether the intermediate measures are regarded as outputs of the first stage or inputs of the second stage, the overall efficiency is characterized as the product of two stages. After maximizing the overall efficiency, the sub-stage efficiencies can be achieved by the optimal multipliers. However, it is well known that the optimal multipliers solved by the linear programing may be non-unique, which may lead to non-uniqueness for the achieved sub-stage efficiencies. The purpose of this paper is to develop a fair and reasonable efficiency decomposition method and provide unique sub-stage efficiencies.
In the literature, efficiency decomposition and efficiency aggregation are two approaches to identify the relationships between the system and sub-system efficiencies [21,22]. The efficiency decomposition approach measures the system efficiency from the inputs it consumes and the outputs it produces, and then derives the relationships between them. On the contrary, the efficiency aggregation approach defines the relationships first, then measures the system and sub-system efficiencies based on these. We must clarify that the concept of efficiency decomposition in the current article is different from the one above. In our paper, efficiency decomposition is not to explore the relationships between the system and sub-system efficiencies, but, for a given relationship between a system and sub-system, to examine how fair and reasonable the system efficiency decomposition is so that sub-system efficiencies can be achieved even when non-uniqueness exists. Note that, no matter the efficiency decomposition or efficiency aggregation approach used in the process of efficiency evaluation, non-uniqueness may exist as long as the system and sub-system efficiencies are calculated simultaneously.
There are three major methods for efficiency decomposition: uniform efficiency decomposition [5], Nash bargaining game decomposition [23], and priority decomposition [20]. Liang et al. [19] applied the concepts of game theory and cooperation to examine the two-stage process. They proposed a search for the fairest decomposition at both stages after the optimal value of the centralized efficiency score is determined. They treated the two stages equally: the authors suppose that the same efficiency distribution exists in both stages, thus the product of two stages equals the overall efficiency score. For brevity, we call this the uniform efficiency decomposition method. However, in the study of Liang et al. [19], the authors failed to prove that a set of weights related to the aforementioned efficiency distribution exists, making their model non-applicable in practice.
Zhou et al. [23] reached an opposite conclusion about the roles of the two stages in the spirit of cooperative games. The authors argue that a fair and reasonable decomposition method should view the two stages as two separate parties that will bargain with each other for their own interests, once overall efficiency is obtained. Thus, a new efficiency decomposition method is proposed based on the Nash bargaining game model, which results in unique stage efficiencies as well.
Different from the assumption of the Nash bargaining game in Zhou et al.’s model [23], Kao and Hwang [20] view sub-stages from the perspective of a Stackbelberg game. Specifically, they examine the potential sequences of two stages by assuming that one stage has the priority and maximizing its efficiency, and then calculating the efficiency of the other stage afterwards. For convenience, we call this the priority decomposition method. For cases when the status of the leader cannot be certain, there is further elaboration in Li et al. [24]. We must clarify that Kao and Hwang [20] only suggest that the unique stage efficiencies can be obtained by priority decomposition if necessary. In their case, however, the efficiency decomposition between sub-stages is unique.
The different assumptions of the three methods above have led to confusion for academic researchers and practitioners. Two questions worth asking would be: (1) how should these different methods be viewed? and (2) which method is the best for efficiency decomposition? Furthermore, although these methods have different assumptions in efficiency decomposition, do they have any connections, or is there any way to view them from a holistic perspective?
This article redefines the concept of fairness in efficiency decomposition, and proposes a rank-based model to obtain unique sub-stage efficiencies when non-uniqueness happens. Our contributions are two-fold. First, we simplify the uniform efficiency decomposition method, and show that the uniform efficiency decomposition and Nash bargaining game decomposition can converge to the same efficiency decomposition. Second, our proposed rank-based model includes the above three major efficiency decomposition methods as special cases when the parameters take special values in our model.
The remainder of this paper is organized as follows. Section 2 briefly introduces the two-stage process. Section 3 proves the continuity of the Pareto front, which is the key to developing the proposed new model and simplifying the uniform efficiency decomposition model. Section 4 redefines fairness and develops a rank-based model for efficiency decomposition. Section 5 discusses the relationships between the different methods. Here we show that the priority decomposition method can be derived from our proposed method, while demonstrating that the assumed efficiency decomposition in Liang et al. [19]’s model exists and can be analytically obtained. We also demonstrate that the uniform efficiency decomposition and Nash bargaining game decomposition are equivalent in nature. To illustrate the new model, two empirical tests are conducted in Section 6, and concluding remarks are provided in Section 7.
2. Two-Stage Process
To present our approach, we use the following notation:
: The index of n DMUs.
: Denotes the evaluated DMU.
: The vector of the initial inputs used by .
: The vector of the intermediate measures for .
: The vector of the final outputs produced by .
: The vector of weights for the initial inputs.
: The vector of weights for the intermediate measures.
: The vector of weights for the final outputs.
: The overall efficiency of .
: The stage 1 efficiency for .
: The stage 2 efficiency for .
: The lower bound of stage-k efficiency for , k = 1,2 while maintaining the overall efficiency .
: The upper bound of stage-k efficiency for , k = 1,2 while maintaining the overall efficiency .
We consider the elementary two-stage system as represented in Figure 1, with each DMU transforming external inputs X into final outputs Y via intermediate measures Z by a two-stage process. In this basic setting, only external inputs to the first stage enter the system, and only outputs to the second stage leave the system. Supposing there are n DMUs in the system, we would typically define the efficiency of the first stage and second stage to as follows:

Figure 1.
Two-stage system.
Notice that, theoretically, the multipliers and for the intermediate measures do not have to be equal in efficiency evaluation. However, DEA researchers have broadly agreed that the same intermediate product has the same multipliers associated with it in modeling network DEA, no matter whether it plays the role of inputs or outputs. In this article, we thus assume .
The overall efficiency of the two-stage process is defined by the following relational model [3], which is the product of the stage efficiencies:
where is a non-Archimedean constant. Further discussion about can be found in Amin and Toloo [25].
Equation (2) represents fractional programming, and can be transformed to linear programming by applying the Charnes‒Cooper transformation [26]. After the overall efficiency is achieved, the stage efficiencies can be calculated via Equation (1). Due to the existence of multiple optimal solutions in a linear program, it may lead to non-uniqueness for sub-stage efficiencies when decomposing the overall efficiency into stage efficiencies. The unique stage efficiency is important both in theory and in practice. This paper develops a rank-based method to achieve unique stage efficiency. For the purpose of comparison between the new approach and previous ones, the following section demonstrates several geometric properties of the Pareto front to simplify the uniform efficiency distribution method proposed by Liang et al. [19].
3. Geometric Properties of Pareto Front
The geometric properties of the Pareto front are the keystone for developing the new approach of efficiency decomposition and simplifying the uniform efficiency distribution. In order to elaborate our purpose, we consider a bi-objective program to be as follows:
Let be the variable space in Equation (3). The functions of stage efficiency, map variable space to the efficiency space (objective function space) in two-dimensional Euclidean space, denoted as . Solving a multiple objective program means finding the efficient (Pareto optimal) solutions in variable space, which are mapped on the Pareto front in objective functions space, i.e., solutions that cannot be altered to increase the value of one objective function without decreasing the value of at least one other objective function. There are multiple approaches to solve the bi-objective program in Equation (3). However, the purpose here is not to solve Equation (3), but the geometric property of the Pareto front. In the following, we will prove that the Pareto front of the bi-objective program in Equation (3) is a bounded and continuous curve in the objective functions space. In order to test this result, we will first need to prove another result about the variable space . Note that, although the geometric properties of Pareto front are demonstrated based on the DMU under evaluation, they apply to any other DMUs. Without a loss of generality, we only consider the situation for the DMU under evaluation.
Lemma 1.
are variables in Equation (3); the variable space is a path connected and closed in Euclidean space.
Proof.
See Appendix A.1.1. □
Theorem 1.
The Pareto front is a continuous and bounded curve in efficiency function space.
Proof.
See Appendix A.1.2. □
In the process of this proof, we showed that one part of the boundary of the efficiency function space is exactly the same with the Pareto front of Equation (3). Due to the closeness of , the corresponding boundary belongs to the efficiency function space . Consequently, for any given point on the Pareto front, there is always a corresponding multiplier coefficient associated with it in variable space of Equation (3). Realizing this point is important in developing the new efficiency decomposition approach and simplifying the uniform efficiency distribution method proposed in Liang et al. [1].
4. Rank-Based Efficiency Decomposition Approach
In this section, we redefine fairness based on efficiency rank and develop a rank-based efficiency decomposition approach.
In the basic two-stage setting, only the inputs to the first stage enter the system and only the outputs of the second stage leave the system. To calculate the system efficiency, the most representative approaches are the centralized model proposed by Liang et al. [19] and the relational model by Kao and Hwang [20], which are proven to be equivalent. Essentially, both of these models require the stages to compromise with each other in order to maximize overall efficiency. Making compromises implies that stage 1 and stage 2 cannot obtain the most favorable weights to achieve their respective advantages. The advantages of each stage can only be demonstrated when the stage efficiencies are calculated by a standard DEA model that allows each stage to achieve the best efficiency without compromises. After the overall efficiency is achieved, stage efficiencies can be obtained by decomposing the overall efficiency. When the optimal weights are not unique, non-uniqueness in decomposing the overall efficiency between the two stages may exist. To correctly and effectively identify the source of inefficiency inside DMUs, it is important to decompose the overall efficiency fairly and reasonably. We think that a fair and reasonable efficiency decomposition should meet two basic rules: (1) the decomposed stage efficiencies should objectively reflect the advantages of each stage; (2) the decomposed stage efficiencies should lie on the Pareto front. The first rule requires the decomposed stage efficiencies to maintain the relative advantages between two stages. The second rule requires that the corresponding multipliers to the decomposed stage efficiencies are Pareto optimal solutions. In what follows, we propose an efficiency decomposition approach to satisfy rules 1 and 2.
By applying the standard two-stage DEA model, we can obtain the efficiency score of each stage and its corresponding rank. Note that it is meaningless to compare the efficiency scores between the two stages. Although the efficiency of stage 1 for is greater than that of stage 2, it does not mean that stage 1 performs better than stage 2. However, we can estimate the relative advantages for each stage by rank. For example, the efficiency score of stage 2 is higher than that of stage 1, thus we can judge that stage 2 has advantages relative to stage 1. Therefore, we should bear in mind the relative advantages of the two stages when conducting an efficiency decomposition.
Specifically, for a given , we can calculate the relative rate of increase of the efficiency rank for stage 1 and stage 2:
We use the CCR model to calculate the efficiency rank in this article.
Without a loss of generality, suppose that stage 1 ranks higher than stage 2, i.e., , then the efficiency adjustment of stage 1 should be given priority. Specifically, the efficiency adjustment of stage 2 relative to stage 1 should be proportional to the relative increase rate of efficiency rank of stage 1 relative to stage 2, i.e.,
where M is a positive constant number and is the relative rate of increase in Equation (4). Equation (5) can be written equivalently as follows:
Equation (6) is equivalent to the following expression:
Equation (7) implies that this proposed efficiency decomposition method finds a point on the Pareto front such that the slope of the line that crosses and is . According to Theorem 1, the Pareto front is a continuous and bounded curve with two endpoints and . The slope of the line that crosses and point P ranges from 0 to positive infinity when point P moves from the point to on the Pareto front. Thus, given the parameter values of and , such a combination of efficiency decomposition must exist.
Note that , so Equation (7) can be transformed into
Consider a special case of , implying that the efficiency rank of stage 1 equals that of stage 2. In such a situation, stage 1 and stage 2 have the same relative advantages. Thus, the decomposition of stage efficiencies should be treated equally. From Equation (8), we can easily calculate the stage efficiencies when , i.e.,
This result exactly coincides with Zhou et al. [23], which implies that the Nash game decomposition method is a special case for the rank-based decomposition method. Furthermore, we will show that it is also the same as Liang et al. [19] in the next section, after model simplification. Equation (9) implies that the stage efficiency is the geometric mean of the upper and lower bound of the corresponding stage retaining the overall efficiency if the two stages are treated equally. For the general situation , we can obtain the stage efficiencies via solving Equation (8), i.e.,
From Equation (6), it is easy to conclude that , which naturally leads to . Therefore, the solution is a Pareto optimal solution, bounded between two points and . In terms of the conclusion of Theorem 1, the Pareto front is a continuous curve in efficiency function space, and all Pareto solutions formed by Equation (1) lie on this Pareto front. There has to be a set of weights in variable space corresponding to the solution . Consequently, the proposed decomposition method of stage efficiency meets the requirements of rules 1 and 2, which implies that the new decomposition method is valid.
5. Comparison of Different Efficiency Decomposition Methods
This section establishes the relationships between different efficiency decomposition methods. First, we show that the priority decomposition method can be derived from our model. Second, we simplify the uniform efficiency decomposition method proposed by Liang et al. [1] and conclude that it is a special case of our model. As a result, we show the equivalence between the uniform decomposition method and the priority decomposition method.
5.1. Priority Decomposition Method
To better understand the proposed method, we draw a sketch of a Pareto front based upon its geometric property, as depicted in Figure 2. The coordinates of points A and D represent the stage efficiencies calculated via a decentralized model, where stage 2 and stage 1 are treated as the respective leaders. Note that the stage efficiencies and are the lower and upper bound, respectively, of stage-k efficiency for , k = 1,2, while maintaining the overall efficiency . The coordinates of the points B and C represent the stage efficiencies, calculated via the priority method while maintaining the overall efficiency . Notice that each point on the curve BC maximizes the overall efficiency of the relational model. Point B is identical to point C if the decomposition of stage efficiency is unique.
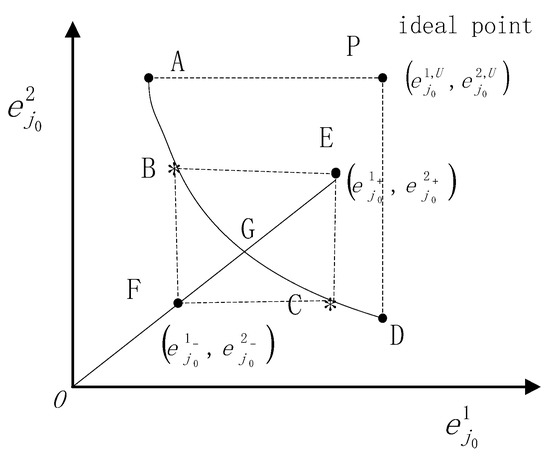
Figure 2.
Pareto front.
Reconsider Equation (7) . Note that the left-hand side of Equation (7) stands for the slope of the line that crosses the points and . The right-hand side is an adjusted slope based on the line that crosses the origin and the point , and the adjusted coefficient is . From a geometric perspective, the essence of the newly proposed decomposition method in the current paper is to find a point on the Pareto front such that the slope of the line that crosses the point and is . Since the parameter is entirely determined by the relative rank of the two stages, the adjusted coefficient only depends on the parameter . We can clearly see that the effect of with a value of 0 on stage efficiency decomposition is the same when takes a value of 0 with the corresponding point being . As the value of increases, the point moves to the right along the Pareto front. Specifically, as the value of goes to positive infinity, the point will become the limit point . This result can be analytically obtained by making in Equation (10), i.e.,
This result is an exact priority decomposition, which is achieved through assuming the first stage has priority while retaining the overall efficiency . Each value of corresponds to a point that lies on the Pareto front between the points and . We could take the parameter as the decision-maker’s preference, and reflects that the decision-maker treats two stages equally; indicates that the decision-maker prefers the stage with higher rank; represents the decision-maker giving absolute priority to the stage with a higher rank.
Similarly, another type of priority decomposition can be achieved through taking the value of positive infinity if the rank of stage 2 is higher than that of stage 1, i.e., . These two kinds of limited value scenarios imply that the newly proposed method in this paper includes the priority decomposition method as a special case.
5.2. Uniform Efficiency Decomposition Method
As in the current paper, a two-stage series process was under consideration in Liang et al. [19]’s paper. In order to calculate the overall efficiency of the two-stage process, a centralized model was proposed in their paper. The centralized model is equivalent in nature to the relational model proposed by Kao and Hwang [20]. In the centralized model, the overall efficiency is first obtained via maximizing the geometric mean of the two stages’ efficiency. The stage efficiencies are then calculated ex post. In cases of multiple optimal solutions that lead to non-uniqueness of and , they developed a procedure to achieve an alternative distribution of and between the two stages. Specifically, they suppose that there exists a , , such that
Let be the optimal solution of Equation (12); the stage efficiency distribution can be obtained as follows:
This procedure tests whether a set of weights is related to the efficiency distribution in Equation (12). If not, they need to find a set of weights and another efficiency distribution by solving a series of linear program problems to make sure the corresponding efficiency distribution is close to the distribution in Equation (12); see the details in Liang et al [19]. This procedure offers a perspective on how to fairly calculate stage efficiencies, but leads to complications for the calculation process, meaning it is not practical in many applications. Based on the continuity of the Pareto front, we can easily show that an efficiency distribution (Equation (12)) does exist that simplifies the calculation process of this procedure.
Looking at Figure 2, we can apply Cook, Liang, and Zhu [5]’s approach in a new way: to see whether a convex combination between the two points E and F exists such that the corresponding point lies on the Pareto front, that is
According to Figure 2, the answer is obvious, and point G is exactly the combination point. Since G is on the Pareto front, the corresponding weights exist naturally in the variable space. Furthermore, we can analytically provide the coordinates of G and the expression of . Consider the points and , which both have the same overall efficiency, i.e.,
Equivalently, we have , which implies that points E and F have the same slope. Obviously, point G has the same slope as E and F. Let G’s coordinates be , then we have
From Equation (15), we can easily obtain
Note that , . Then we can obtain
So far, we have simplified and provided the analytical expressions for the efficiency distribution and stage efficiencies. From Equation (17), we can see that Liang et al. [19]’s model is a special case of our model when the parameter or equals 0.
Different from the uniform efficiency decomposition, Zhou et al. [23] argued that a fair and reasonable method for efficiency decomposition is to make the two stages compete with each other to maximize their own efficiency when overall efficiency has been obtained under the cooperative game model. Surprisingly, we find that the result from Zhou et al. [23]’s model completely coincides with that in Liang et al. [19], which implies that the Nash bargaining game decomposition method is also a special case of our model.
In summary, our proposed model includes the three major efficiency decomposition methods as special cases. Furthermore, for any method of efficiency decomposition, it is necessary to find a point on the Pareto front such that the overall efficiency remains. Since we can always obtain a pair of given stage efficiency decompositions through adjusting the preference coefficient , our newly proposed method is more general and incorporates other methods of efficiency decomposition into a unified framework.
6. Empirical Tests
In this section, we perform tests to demonstrate the applications of our model. Two separate tests are conducted to obtain the unique and reasonable stage efficiencies with data from the banking industry and the automobile industry.
6.1. Performance Evaluation of Banking
Efficiency evaluation in the banking industry has always been an important issue and received much attention [27,28,29,30]. For the purpose of comparison, we recalculate the case in Zhou et al. [23]. The authors applied the bargaining game model to determining the efficiency decompositions of 10 branches of China Construction Bank (CCB) in Anhui province, China (see Appendix A for the data). All the data are taken from the Annual Report [31] of China Construction Bank (CCB) in Anhui province. The processes of bank branches can be modeled as a two-stage system. In the first stage, employees (EMs), fixed assets (FAs), and expenses (EXs) are consumed to produce the outputs of credit (CR) and interbank loans (ILs). In the second stage, the outputs from the first stage are used as the inputs of the second stage to produce the outputs loan (Lo) and profit (PR).
The overall efficiency of the system is calculated by the relational model [20], and the second column in Table 1 lists all of the DMUs’ overall efficiency scores. Under the condition of retaining the overall efficiency, the lower and upper bound efficiency scores for stage 1 and stage 2 are presented in columns 3 to 6 in Table 1. Columns 7 and 8 give the standard efficiency scores for stage 1 and stage 2, as obtained by the CCR model. Since Liang et al. [19] and Zhou et al. [23]’s model lead to the same stage efficiency decompositions, we only demonstrate Zhou et al. [23]’s result for the purpose of comparison. As illustrated in Table 2, the second and third columns give standard efficiency scores for stage 1 and stage 2; the fourth and fifth columns present stage efficiencies for stage 1 and stage 2 according to Zhou et al. [23]’s model, which is the bargaining game model, abbreviated as “BG model” in Table 2. Similarly, the rank-based model proposed in this article is abbreviated as “R-B model” in Table 3 and Table 4. The value of can be easily calculated via the second and third columns in Table 1. For the purpose of comparison, we calculate six different sets of values of M for our model, as listed in Table 3 and Table 4, with all the corresponding ranks listed in parentheses.

Table 1.
Efficiency scores for banks.
Table 2.
BG model: efficiency scores and rankings.
Table 3.
R-B model: efficiency scores and rankings.
Table 4.
R-B model: efficiency scores and rankings.
From Table 2, only performs efficiently in both stages and the whole system. For the rest of the nine DMUs, non-uniqueness exists in the efficiency decomposition between two stages for each DMU since the maximal and minimal achievable efficiency scores for each stage are not the same. As explained in Section 4, a reasonable and fair efficiency decomposition method should maintain the relative advantages between the two stages. Hence, we focus the analysis of this empirical test on the rank differences.
As an example, we consider a special case, M = 4. We first consider the situation of the first stage. In Table 2, the second and fourth columns present the efficiency scores and corresponding ranks of stage 1, obtained by the CCR model and bargaining game model, respectively. The second column of Table 3 lists the results calculated by the rank-based model. Under the decomposition of the bargaining game model, only three DMUs have the same ranks as the standard CCR model, i.e., , and , but six DMUs for the rank-based model have the same rank, i.e., , , , , and . For the rest of the DMUs, the bargaining game model has five DMUs with one rank difference, namely , , , and , but four DMUs for rank-based model, namely , , , . For the case of the two and three rank differences, the bargaining game model has and , but there are none for the rank-based model.
If we define the absolute rank difference as the sum of all rank differences, then we can calculate the rank difference of stage 1 for the bargaining game model and rank-based model as 10 and 4, respectively. Obviously, the lower the , the better the efficiency decomposition method works. From this standpoint, the newly proposed method with M = 4 works better than the bargaining game model.
A similar analysis can be applied to stage 2. From Table 2 and Table 4, we see that the bargaining game model and the rank-based model have four identical DMUs with zero rank difference, , , , . For the case of one rank difference, the two decomposition methods have the same result, namely . For the case of two rank differences, the bargaining game model has and the rank-based model has , and . Notice that has a difference of three ranks and has five under the bargaining game model. For and , the rank differences of the bargaining game model are 5 and 4, while those of the rank-based model are 3 and 4, respectively. Similarly, we can calculate that the absolute rank difference of stage 2, and the (stage 2) of the bargaining game model and rank-based model are 20 and 14, respectively. Accordingly, the total rank difference of the bargaining game model and rank-based model are 30 and 18, respectively. The rank-based model works better for maintaining the relative advantages between two stages. Note that the rank difference of stage 2 is significantly greater than for stage 1, probably due to the efficient DMUs in stage 2 being significantly greater than in stage 1. We rank all the efficient DMUs of stage 2 as one, meaning that the rank difference lacks discrimination.
For different values of M, the total rank difference is (M = 1) = 24, (M = 2) = 22, (M = 3) = 21, (M = 5) = 20, (M = 6) = 20. From the numerical results, we see that there is an inverted U-shaped relationship between the total rank difference and M. However, we cannot find an optimal value of M for the rank-based model, which is a shortcoming of this paper.
6.2. Performance Evaluation of Sustainable Designs
In recent years, sustainable design or, sometimes equivalently, design for the environment, has been considered as one of the most important practices for achieving sustainability. In this section, we apply the two-stage DEA framework for the sustainable design performance evaluation proposed in Chen at al. [18], which uses design efficiency as a performance measure to evaluate how well multiple product specifications and attributes are combined in a product design to achieve better environmental performance. Contrary to the traditional measures for sustainable design, which mostly focus on the absolute environmental performance, this two-stage DEA model includes an “industrial design stage” (stage 1) and a “bio design stage” (stage 2) in order to identify the most efficient way to combine the product specifications and attributes to achieve better environmental performance through product design.
The testing data are collected from the 2013 vehicle emissions testing database published by the U.S. EPA [32], which includes valid data on 12 new models introduced by three different manufacturers (see Appendix A for the original data). In the two-stage DEA model, cubic inch displacement (cid), rated horsepower (rhp), engine speed versus vehicle speed at 50 mph (n/v ratio), and axle ratio (axle) are treated as the inputs; equivalent test weight (etw) and fuel economy (mpg) as the intermediates; and hydrocarbon emissions (hc), carbon monoxide emissions (CO), carbon dioxide emissions (), and nitrogen oxide emission () as outputs. Note that higher levels of outputs usually indicate better performance in DEA. Thus, we treat the reciprocals of cubicinch displacement, rated horsepower, compression ratio, and equivalent test weights in our analysis to fit the DEA use.
The results are listed in Table 5. The second column presents the overall efficiencies based on the two-stage DEA model. Under the condition of retaining the overall efficiency, the lower and upper bound efficiencies of stage 1 and stage 2 are listed in columns 3 to 6. The last two columns list the CCR efficiency scores of stage 1 and stage 2, respectively. According to the unique test procedure proposed in Liang et al [19], all DMUs have unique stage efficiencies except since its lower and upper bound efficiencies are not equal. Based on the rank of stage 1 and stage 2 determined by its CCR efficiency scores, we can easily calculate the value of , which equals 90.91%. Table 6 lists four sets of efficiency scores for stage 1 and stage 2, which are calculated by a rank-based model. The stage efficiencies calculated by the bargaining model are presented in the last row. The last column of Table 6 shows that both the rank-based model and the bargaining game model have the same rank differences, which implies that the two models work identically in this case. The reason is that only needs an efficiency decomposition, and there are no other DMUs whose stage efficiencies are between the lower bound and upper bound of . Therefore, no matter how the values of M are selected, there is no impact on the rankings.
Table 5.
Efficiency scores for sustainable design.
Table 6.
Efficiency decomposition: R-B model vs. BG model.
7. Concluding Remarks
Efficiency decomposition can help decision-makers to establish the inefficient source so that appropriate efforts can be devoted to improving performance. To discover the internal inefficiencies, the overall efficiency of the whole system needs to be decomposed into stage efficiencies. Due to the non-unique optimal weights of a linear program, non-uniqueness in efficiency decomposition may exist. Three major efficiency decomposition methods have been proposed: Liang et al. [19]’s uniform efficiency distribution model, Zhou et al. [23]’s bargaining game model, and Kao and Hwang [20]’s priority decomposition model. Each model has a different perspective on efficiency decomposition and claims to achieve fair, reasonable, and unique stage efficiencies. However, the foundations of these models are totally different, which can make it harder for researchers and practitioners to establish their relative superiority. Through proving the continuity of the Pareto front in efficiency function space, we simplified Liang et al. [19]’s model, and found that the efficiency decompositions derived by Cook, Liang, and Zhu [5] and Zhou et al. [23]’s models are the same. Furthermore, based on this geometric property of the Pareto front, we propose a rank-based model to achieve reasonable and unique efficiency decompositions for each stage. The proposed rank-based model allows for the three abovementioned models to be treated as special cases. Liang et al. [19] and Zhou et al. [23]’s models, which were proven to be equivalent, can be unified into the rank-based model as a special case when or M equals 0. Kao and Hwang [20] can also be included as a special case when M takes the value of positive infinity. As presented, there are two parameters in our model, and M. The parameter reflects the relative advantages between two sub-stages, which means the efficiency decomposition can be conducted fairly and reasonably. In practice, another parameter M can be viewed as the preference of the decision-maker. Theoretically, our model can also include any other efficiency decomposition models as special cases as long as the value of the decision-maker’s preferred coefficient M is adjusted appropriately. Thus, the proposed rank-based model provides a unified perspective for investigating different efficiency decomposition methods, as well as a better understanding of the existing efficiency decomposition approaches in the literature. However, the optimal values of M for our model have not been achieved in this current paper. As an example, only a few sets of special values of M are presented to demonstrate the applications of our model. The reason is that the optimal values of M for our model are DMU-specific, and the calculation is too complicated. This is a drawback of this study.
Lastly, the proposed model was applied to evaluate bank performance and the efficiency of sustainable product design in the automobile industry. In the banking evaluation, non-uniqueness of efficiency decomposition occurs in nine out of 10 banks. For the purpose of comparison, the bargaining game and rank-based models are used in this case. Through defining the rank differences, we compared the results of efficiency decomposition derived by these two models. It turns out that our model performance is better than the bargaining model. In a second test, we showed the applicability of our model to the evaluation of sustainable product design in the automobile industry. There are 12 types of vehicles from three different manufacturers included in this case. Only one DMU has the problem of non-uniqueness of efficiency decomposition. We used the rank-based model to achieve unique stage efficiencies. For the purpose of comparison, we also calculated the results by the bargaining model. Since the rank differences would not make any difference no matter whether the rank-based model or bargaining model is used in this case, these two models perform equally well. In addition, although our model was proposed based on the most fundamental two-stage network process, the idea introduced here applies to other types of network DEA model.
Author Contributions
All of the authors have contributed to this research. Conceptualization, H.L.; Formal analysis, H.L.; Funding acquisition, J.X. (Jie Xiong) and J.Z.; Methodology, H.L.; Project administration, J.X. (Jie Xiong); Software, J.X. (Jianhui Xie); Supervision, J.Z.; Validation, J.X. (Jie Xiong); Writing—original draft, H.L.; Writing—review & editing, J.X. (Jie Xiong) and Z.Z.
Acknowledgments
We are grateful for the valuable improvement suggestions from the editor and two anonymous reviewers. This research was funded by the National Social Science Foundation of China, grant number 16ZDA013. The APC was funded by the National Natural Science Foundation of China (grant number 71772142).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Proofs
Appendix A.1.1. The Proof of the Lemma
Proof: the variable space of Equation (3) is the intersection area surrounded by hyperplanes , , j = 1,2,…,n, and . As all the constraint conditions in Equation (3) are linear; and all of these inequalities hold with equality, the complementary set of in -dimensional Euclidean space is an open set. Therefore, is a closed set. Obviously, for any two given different points in , a path connecting them always exists. Thus, is a path-connected space.
Appendix A.1.2. The Proof of the Theorem
Proof: First, we prove that the efficiency function space is a path connected space. Consider the efficiency functions . According to the definition, both efficiency functions are bounded, thus map the variable space to a bounded set in two-dimensional Euclidean space, which is the efficiency function space of Equation (3). Notice that are positive real numbers, and the variables are . The efficiency functions are therefore continuous with respect to the variables in variable space. Based on the basic knowledge of set topology, the continuous function maps a path connected space to a path connected space. According to the Lemma 1, the variable space is a path connected space. Consequently, the efficiency function space is also a path connected space.
Second, we prove that the efficiency function space is a closed set in two-dimensional Euclidean space. Let be the continuous map: . If we want to prove the efficiency function space is a closed set, we only need to prove that the closure of the efficiency space equals itself, i.e., . Equivalently, we only need to prove every accumulation point of belongs to itself. For any given accumulation point of , there is always a sequence of points such that . Accordingly, there exists a sequence of points in , denoted as , such that and . According to the Lemma 1, the variable space is a closed set, and the extreme point thus belongs to , i.e., since is a continuous function. We have:
Due to , we have , i.e., ,which implies every accumulation point of belongs to itself. Therefore, the efficiency function space is closed in two-dimensional Euclidean space, i.e., .
Third, we prove that the Pareto front is a continuous and bounded curve. Consider the two points and . These two points lie on the Pareto front and consist of the upper and lower bound of the Pareto front, respectively. Since the efficiency function space is a path connected and closed set, the boundary of belongs to . Note that only two boundaries connect the points and in . One is on the right of , the other is on the left. Let be the right boundary of efficiency space , with endpoints and . Obviously, the boundary belongs to efficiency function space because of the closure of . In the following, we will prove that the boundary is the same as the Pareto front of the bi-objective program in Equation (3).
According to the definition of the Pareto front, i.e., solutions that cannot be altered to increase the value of one objective function without decreasing the value of at least the other objective function, we can claim that the boundary is the Pareto front of the bi-objective program in Equation (3). On one hand, for every Pareto optimal solution of Equation (3), the corresponding must lie on the boundary because is the right boundary of efficiency space with endpoints and . Otherwise, we can always increase the value of one objective function without deteriorating the value of the other objective function which would contradict the definition of the Pareto front. On the other hand, for any point on the boundary , we have , . If a point in efficiency space exists, such that , then point must be the point itself. Otherwise, it would contradict with the definition of , i.e., is the rightmost boundary of . Consequently, the boundary is the Pareto front of the bi-objective program in Equation (3).
Since is path-connected, and because is a path connecting and , the continuity of the boundary is obvious. In summary, we proved the whole theorem. #
Appendix A.2. Datasets
Table A1.
Dataset of 10 bank branches.
Table A1.
Dataset of 10 bank branches.
| DMU | Branch | EM (103) | FA (¥108) | EX (¥108) | CR (¥108) | IL (¥108) | LO (¥108) | PR (¥108) |
|---|---|---|---|---|---|---|---|---|
| 1 | Maanshan | 0.4775 | 0.526 | 0.3848 | 49.9174 | 5.4613 | 34.9897 | 0.843 |
| 2 | Anqing | 1.2363 | 0.713 | 0.5547 | 37.4954 | 4.0825 | 20.6013 | 0.4864 |
| 3 | Huangshan | 0.446 | 0.443 | 0.3419 | 20.9846 | 0.6897 | 8.6332 | 0.1288 |
| 4 | Fuyang | 1.2481 | 0.638 | 0.4574 | 45.0508 | 1.7237 | 9.2354 | 0.3019 |
| 5 | Suzhou | 0.705 | 0.575 | 0.4036 | 38.1625 | 2.2492 | 12.0171 | 0.3138 |
| 6 | Chuzhou | 0.6446 | 0.432 | 0.4012 | 30.1676 | 2.3354 | 13.813 | 0.3772 |
| 7 | Luan | 0.7239 | 0.51 | 0.3709 | 26.5391 | 1.3416 | 5.0961 | 0.1453 |
| 8 | Chizhou | 0.3363 | 0.322 | 0.2334 | 16.1235 | 0.4889 | 5.9803 | 0.0928 |
| 9 | Chaozhou | 0.6678 | 0.423 | 0.3471 | 22.1848 | 1.1767 | 9.2348 | 0.2002 |
| 10 | Bozhou | 0.3418 | 0.256 | 0.1594 | 13.4364 | 0.4064 | 2.5326 | 0.0057 |
Table A2.
Dataset of vehicles.
Table A2.
Dataset of vehicles.
| Vehicle Manufacturer Name | Test Vehicle ID | Cid | Rhp | n/v Ratio | Axle | Etw | Mpg | Hc | CO | CO2 | Nox |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Land Rover | LBDVP001 | 122.04749 | 240 | 30.6 | 3.75 | 4500 | 21.8 | 0.04564 | 0.6178 | 406.99 | 0.0012 |
| Land Rover | 0AVP0002 | 305.11872 | 375 | 31 | 3.54 | 6000 | 15.3 | 0.01596 | 0.2238 | 576.48 | 0.0181 |
| Land Rover | LKDTT066 | 305.11872 | 375 | 23.9 | 3.21 | 5500 | 16.8 | 0.01342 | 0.1923 | 531.45 | 0.0114 |
| Land Rover | 3CTTP036 | 122.04749 | 240 | 30.5 | 3.75 | 4250 | 24.6 | 0.0169 | 0.1359 | 362.42 | 0.0078 |
| Land Rover | VX10HWS | 305.11872 | 375 | 32.5 | 3.54 | 6000 | 15.6 | 0.014 | 0.17 | 570.95 | 0.012 |
| Land Rover | 0AVP0049 | 305.11872 | 510 | 32.5 | 3.54 | 6000 | 14.4 | 0.01689 | 0.3361 | 612.43 | 0.0066 |
| Land Rover | LKDTT065 | 305.11872 | 510 | 24.1 | 3.21 | 6000 | 15.7 | 0.02768 | 0.2859 | 565.05 | 0.0112 |
| Maserati | 48675 | 286.8116 | 444 | 32.1 | 3.73 | 4750 | 15.75 | 0.0405 | 0.6305 | 566.841 | 0.017 |
| Maserati | 45367 | 286.8116 | 454 | 30.5 | 3.54 | 4500 | 15.8 | 0.018 | 0.469 | 564.07 | 0.008 |
| Maserati | ZAMJK39A690027157 | 286.8116 | 424 | 31.4 | 3.54 | 4750 | 14.25 | 0.017 | 0.346 | 621.803 | 0.008 |
| VPG | 523MF1163BM000007 | 194.78779 | 240 | 33.3 | 4.06 | 5000 | 19.8 | 0.018 | 0.27 | 441 | 0.022 |
| VPG | 523MF1267BT000001 | 280.70922 | 248 | 28.4 | 3.45 | 5250 | 15.55 | 0.12011 | 2.17351 | 565.85 | 0.0341 |
References
- Charnes, A.; Cooper, W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Kou, G.; Peng, Y.; Wang, G. Evaluation of clustering algorithms for financial risk analysis using MCDM methods. Inf. Sci. 2014, 275, 1–12. [Google Scholar] [CrossRef]
- Li, G.; Kou, G.; Peng, Y. A Group Decision Making Model for Integrating Heterogeneous Information. IEEE Trans. Syst. Man, Cybern. Syst. 2018, 48, 982–992. [Google Scholar] [CrossRef]
- Zhang, H.; Kou, G.; Peng, Y. Soft consensus cost models for group decision making and economic interpretations. Eur. J. Oper. Res. 2019, 277, 964–980. [Google Scholar] [CrossRef]
- Cook, W.D.; Liang, L.; Zhu, J. Measuring performance of two-stage network structures by DEA: A review and future perspective. Omega 2010, 38, 423–430. [Google Scholar] [CrossRef]
- Halkos, G.E.; Tzeremes, N.G.; Kourtzidis, S.A. A unified classification of two-stage DEA models. Surv. Oper. Res. Manag. Sci. 2014, 19, 1–16. [Google Scholar] [CrossRef]
- Chen, Y.; Cook, W.D.; Li, N.; Zhu, J. Additive efficiency decomposition in two-stage DEA. Eur. J. Oper. Res. 2009, 196, 1170–1176. [Google Scholar] [CrossRef]
- Färe, R.; Grosskopf, S. Productivity and intermediate products: A frontier approach. Econ. Lett. 1996, 50, 65–70. [Google Scholar] [CrossRef]
- Du, J.; Liang, L.; Chen, Y.; Cook, W.D.; Zhu, J. A bargaining game model for measuring performance of two-stage network structures. Eur. J. Oper. Res. 2011, 210, 390–397. [Google Scholar] [CrossRef]
- Seiford, L.M.; Zhu, J. Profitability and Marketability of the Top 55 U.S. Commercial Banks. Manag. Sci. 1999, 45, 1270–1288. [Google Scholar] [CrossRef]
- Zhu, J. Multi-factor performance measure model with an application to Fortune 500 companies. Eur. J. Oper. Res. 2000, 123, 105–124. [Google Scholar] [CrossRef]
- Mardani, A.; Zavadskas, E.K.; Streimikiene, D.; Jusoh, A.; Khoshnoudi, M. A comprehensive review of data envelopment analysis (DEA) approach in energy efficiency. Renew. Sustain. Energy Rev. 2017, 70, 1298–1322. [Google Scholar] [CrossRef]
- Sueyoshi, T.; Yuan, Y.; Goto, M. A literature study for DEA applied to energy and environment. Energy Econ. 2017, 62, 104–124. [Google Scholar] [CrossRef]
- An, Q.; Wang, Z.; Ali, E.; Zhu, Q.; Zhu, X. Efficiency evaluation of parallel interdependent processes systems: An application to Chinese 985 Project universities. Int. J. Prod. Res. 2018, 1–13. [Google Scholar] [CrossRef]
- Wu, J.; Zhu, Q.; Chu, J.; An, Q.; Liang, L. A DEA based approach for allocation of emission reduction tasks. Int. J. Prod. Res. 2016, 54, 5618–5633. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, H.; Chen, Y.; Zhu, J. Data envelopment analysis application in sustainability: The origins, development and future directions. Eur. J. Oper. Res. 2018, 264, 1–16. [Google Scholar] [CrossRef]
- Hwang, S.-N.; Chen, C.; Chen, Y.; Lee, H.-S.; Shen, P.-D. Sustainable design performance evaluation with applications in the automobile industry: Focusing on inefficiency by undesirable factors. Omega 2013, 41, 553–558. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, J.; Yu, J.-Y.; Noori, H. A new methodology for evaluating sustainable product design performance with two-stage network data envelopment analysis. Eur. J. Oper. Res. 2012, 221, 348–359. [Google Scholar] [CrossRef]
- Liang, L.; Cook, W.D.; Zhu, J. DEA models for two-stage processes: Game approach and efficiency decomposition. Nav. Res. Logist. 2008, 55, 643–653. [Google Scholar] [CrossRef]
- Kao, C.; Hwang, S.-N. Efficiency decomposition in two-stage data envelopment analysis: An application to non-life insurance companies in Taiwan. Eur. J. Oper. Res. 2008, 185, 418–429. [Google Scholar] [CrossRef]
- Kao, C. Efficiency decomposition and aggregation in network data envelopment analysis. Eur. J. Oper. Res. 2016, 255, 778–786. [Google Scholar] [CrossRef]
- Kao, C. Efficiency decomposition for general multi-stage systems in data envelopment analysis. Eur. J. Oper. Res. 2014, 232, 117–124. [Google Scholar] [CrossRef]
- Zhou, Z.; Sun, L.; Yang, W.; Liu, W.; Ma, C. A bargaining game model for efficiency decomposition in the centralized model of two-stage systems. Comput. Ind. Eng. 2013, 64, 103–108. [Google Scholar] [CrossRef]
- Li, H.; Chen, C.; Cook, W.D.; Zhang, J.; Zhu, J. Two-stage network DEA: Who is the leader? Omega 2018, 74, 15–19. [Google Scholar] [CrossRef]
- Amin, G.R.; Toloo, M. A polynomial-time algorithm for finding ε in DEA models. Comput. Oper. Res. 2004, 31, 803–805. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W. Programming with linear fractional functionals. Nav. Res. Logist. Q. 1962, 9, 181–186. [Google Scholar] [CrossRef]
- AlHassany, H.; Faisal, F. Factors influencing the internet banking adoption decision in North Cyprus: an evidence from the partial least square approach of the structural equation modeling. Financ. Innov. 2018, 4, 29. [Google Scholar] [CrossRef]
- Tang, Y.; Moro, A.; Sozzo, S.; Li, Z. Modelling trust evolution within small business lending relationships. Financ. Innov. 2018, 4, 19. [Google Scholar] [CrossRef]
- Asongu, S.A.; Odhiambo, N.M. Size, efficiency, market power, and economies of scale in the African banking sector. Financ. Innov. 2019, 5, 4. [Google Scholar] [CrossRef]
- Kou, G.; Chao, X.; Peng, Y.; Alsaadi, F.E.; Herrera-Viedma, E. MACHINE LEARNING METHODS FOR SYSTEMIC RISK ANALYSIS IN FINANCIAL SECTORS. Technol. Econ. Dev. Econ. 2019, 1–27. [Google Scholar] [CrossRef]
- China Construction Bank (Anhui Branch). Annual Report 2004 of China Construction Bank in Anhui Province. 2004. Available online: http://www.ccb.com/cn/uploads/1-26.1118369283972.pdf (accessed on 14 June 2019). (In Chinese).
- United States Environmental Protection Agency. Certification Emission Test Data. 2013. Available online: https://www.epa.gov/ (accessed on 14 June 2019).


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).