Fake News and Propaganda: Trump’s Democratic America and Hitler’s National Socialist (Nazi) Germany



Abstract
:1. Introduction
2. Research Method
3. Results and Interpretation of the Analysis
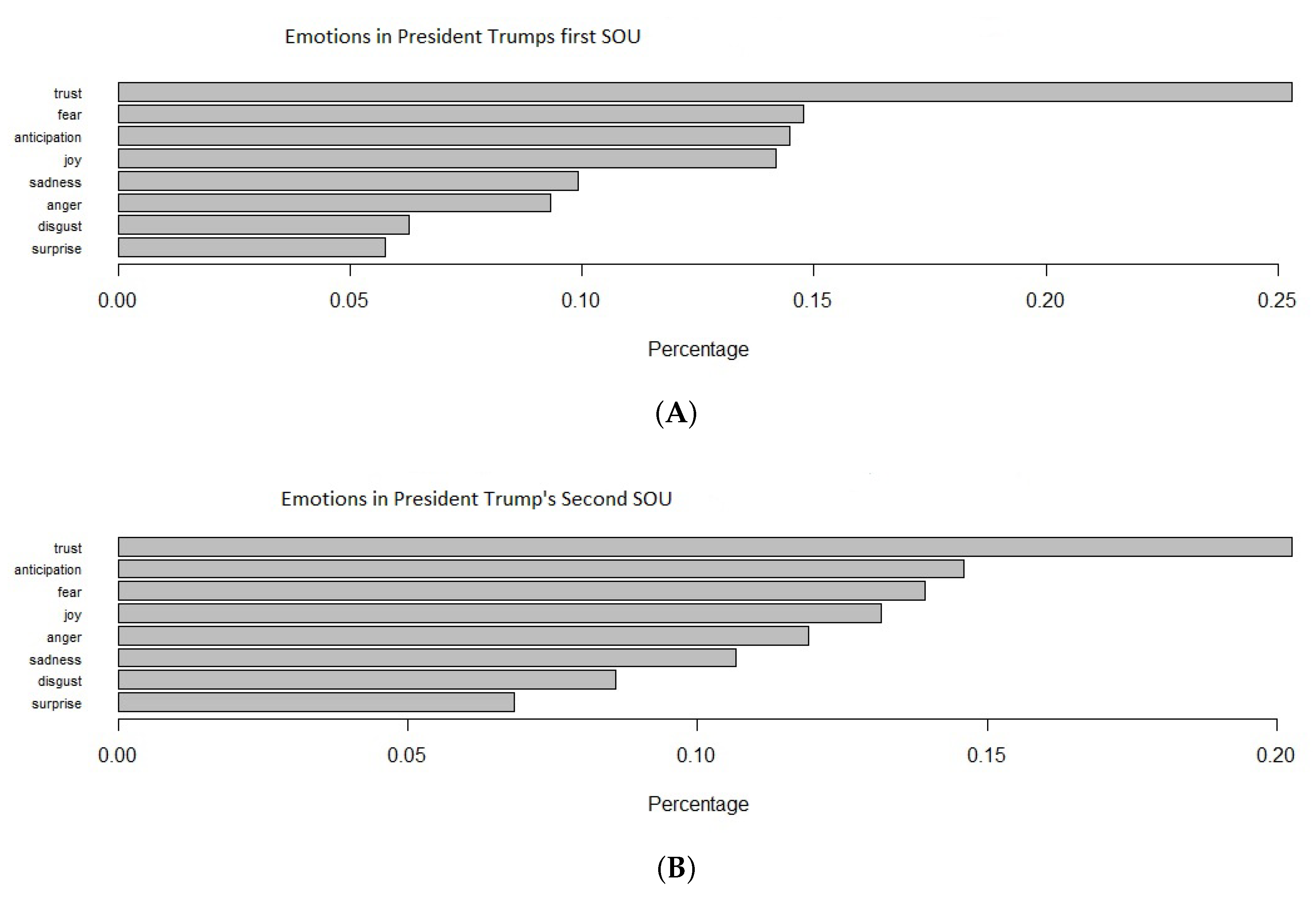
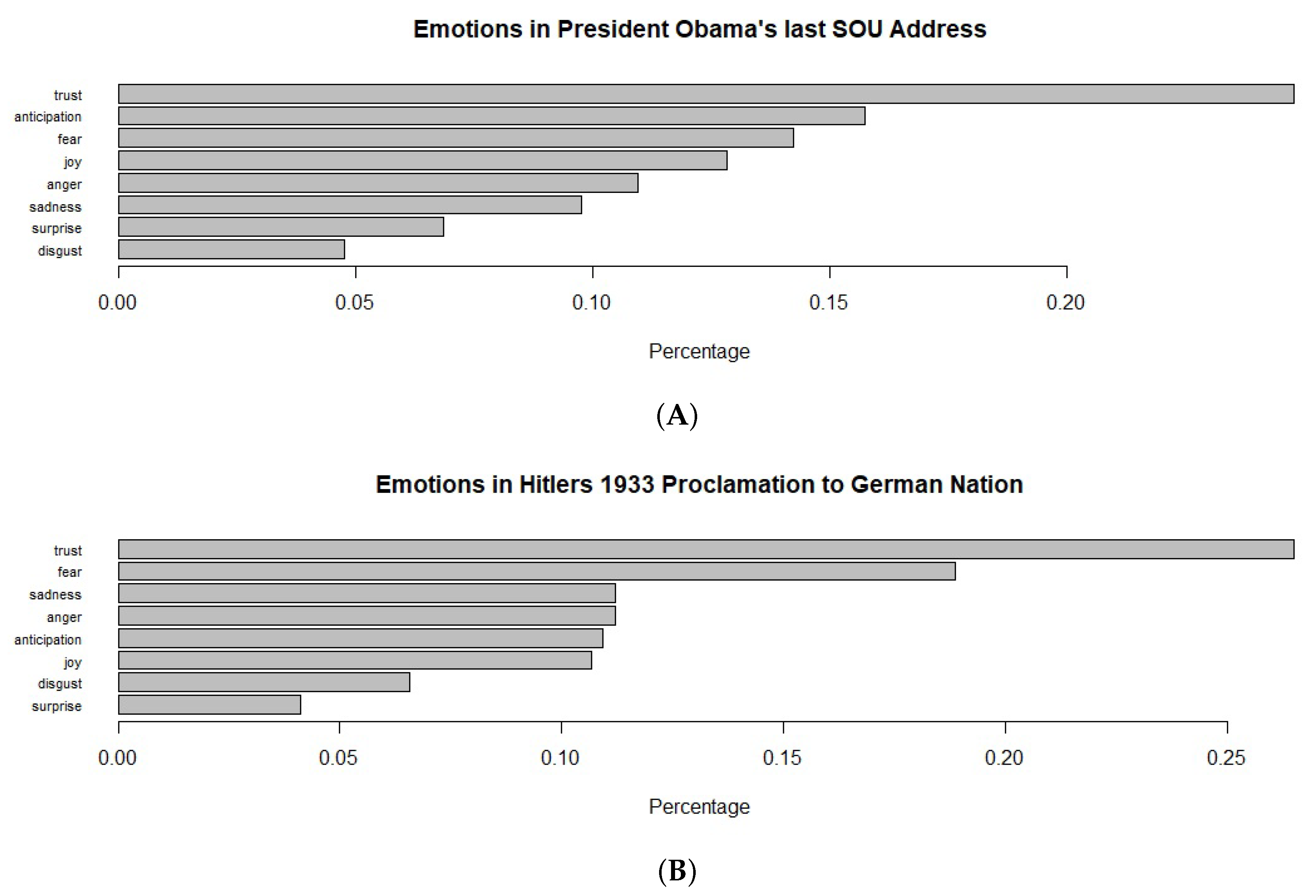
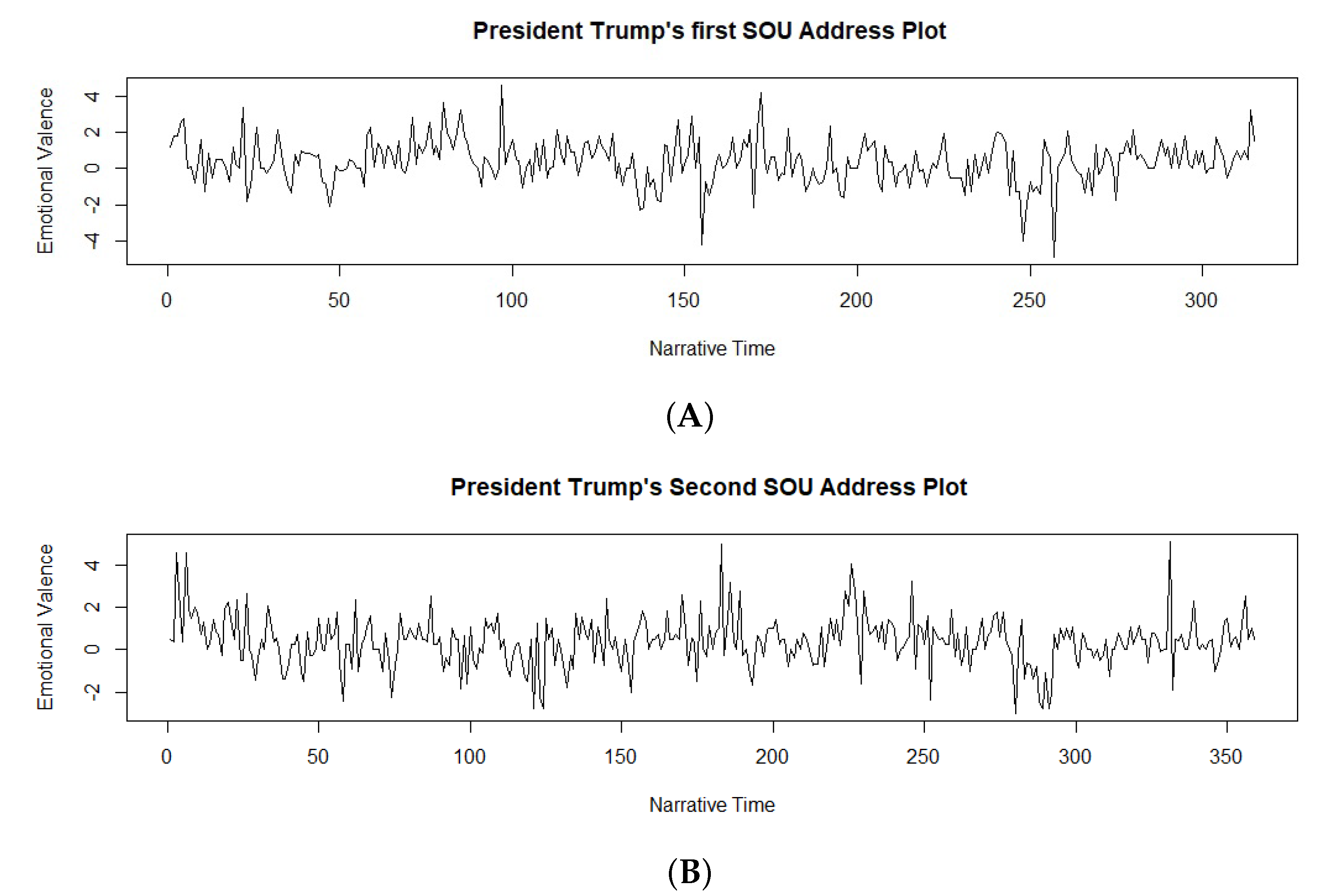
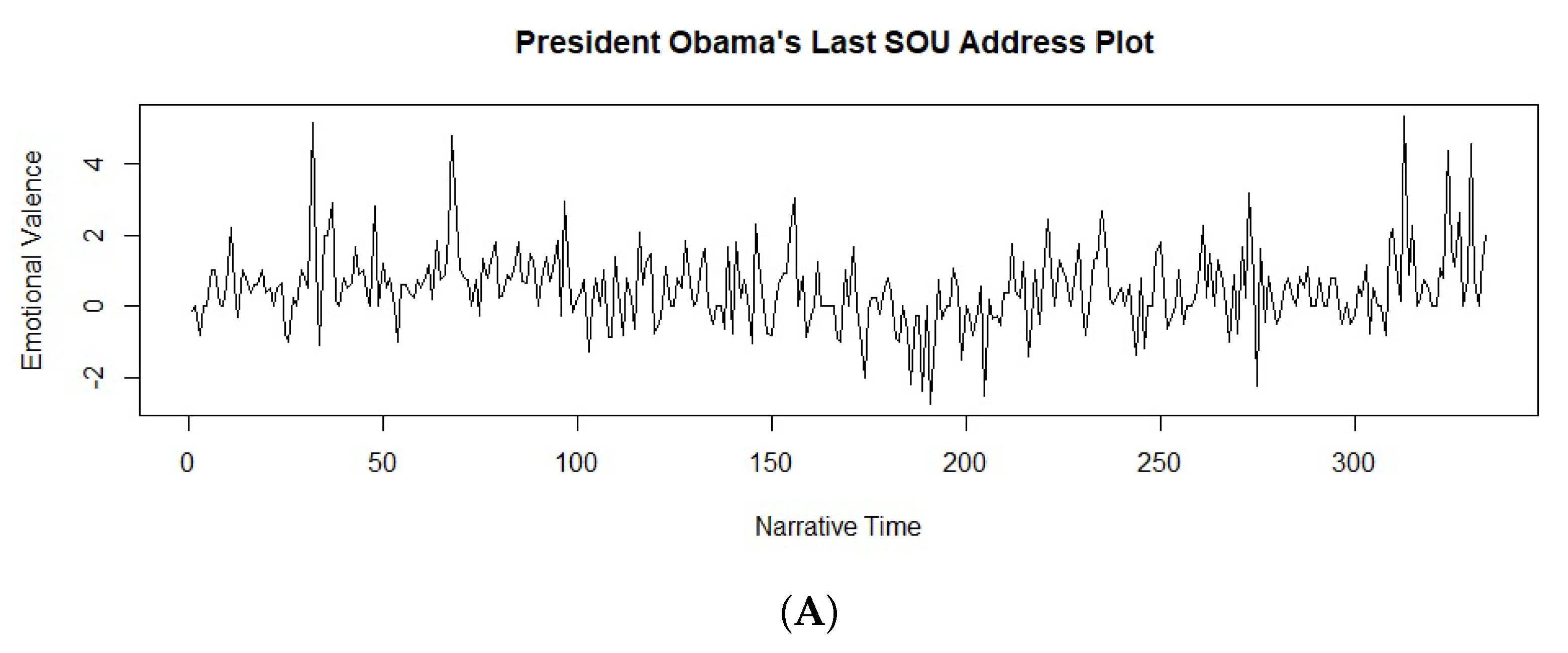
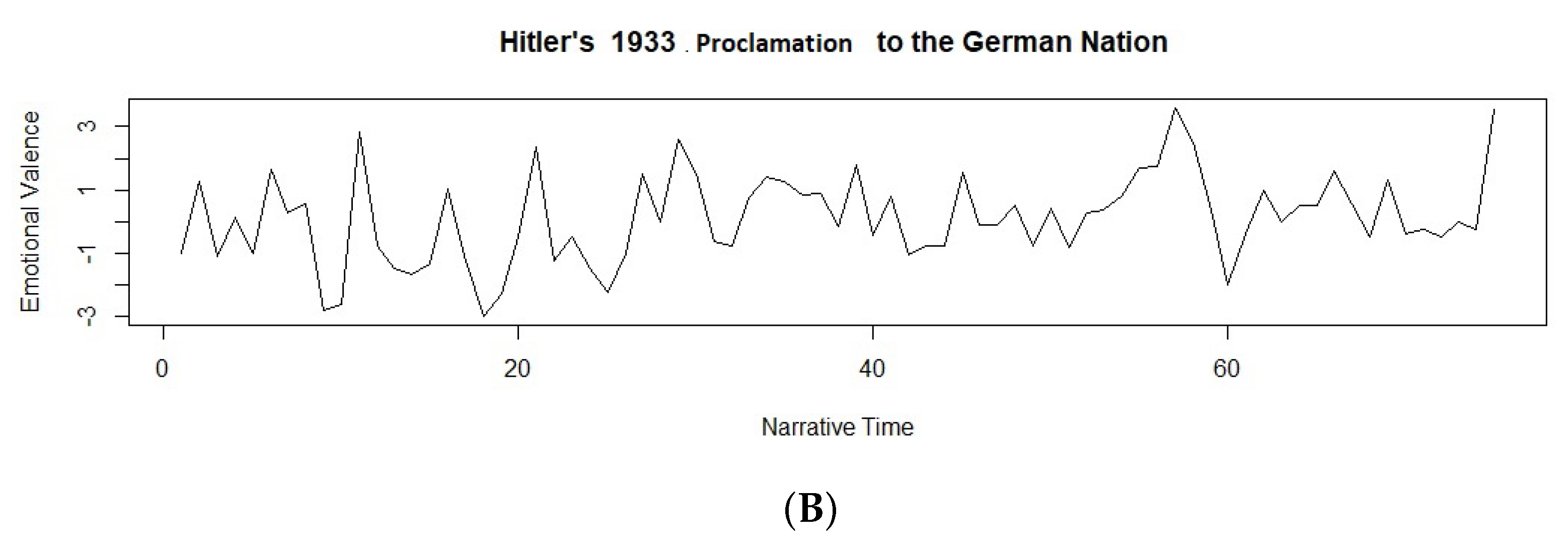
3.1. Sentiment Analysis
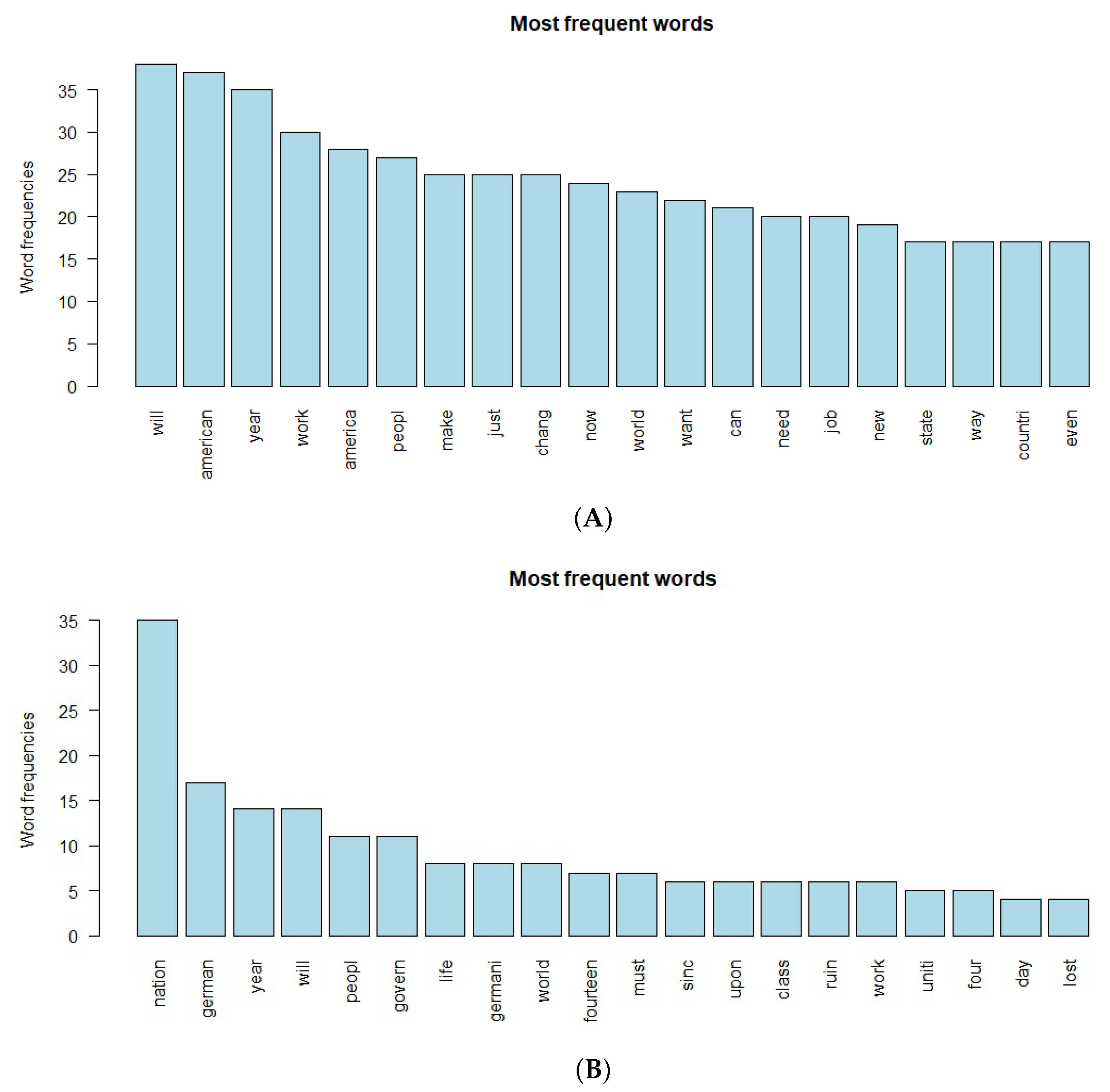
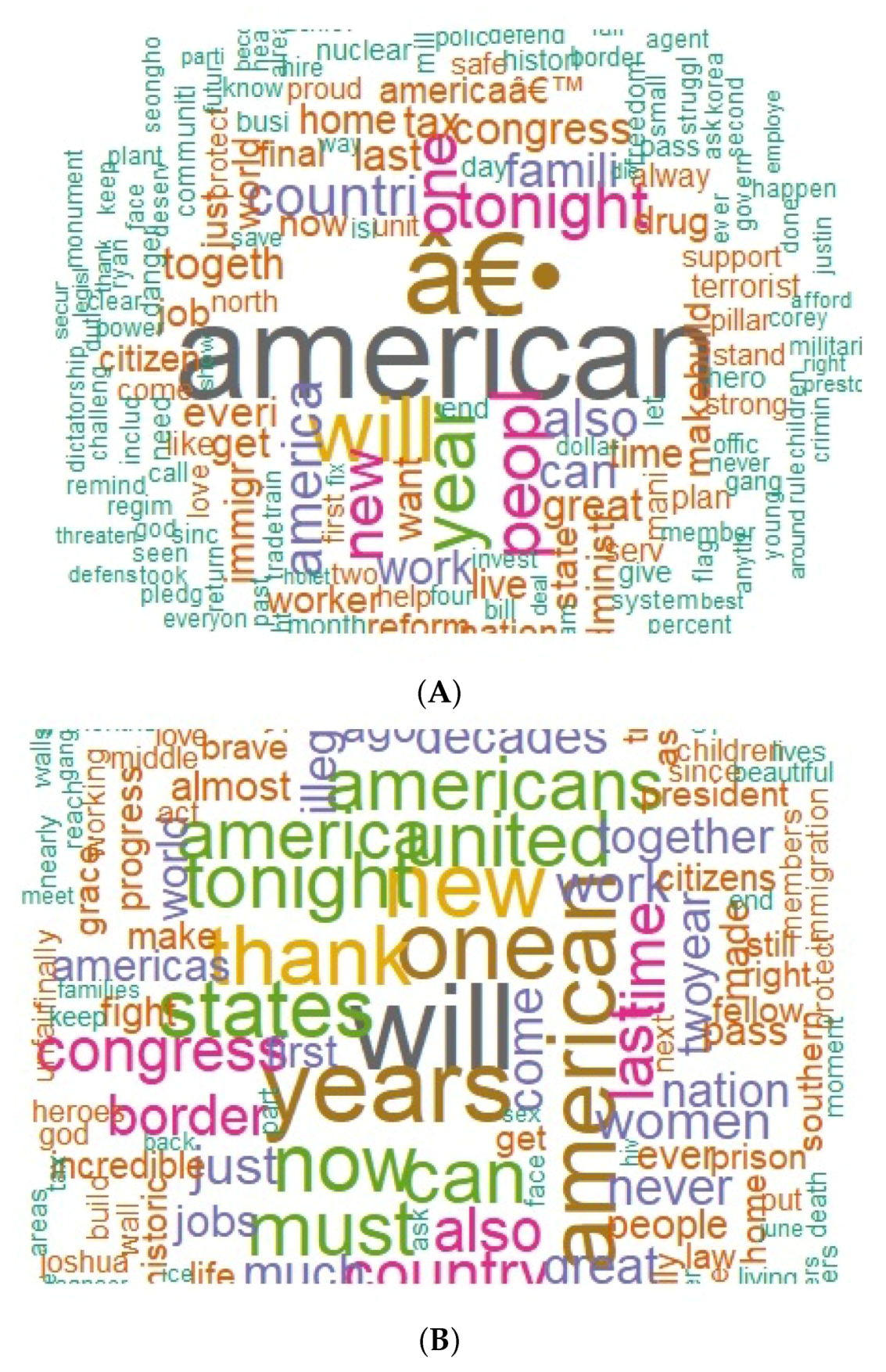
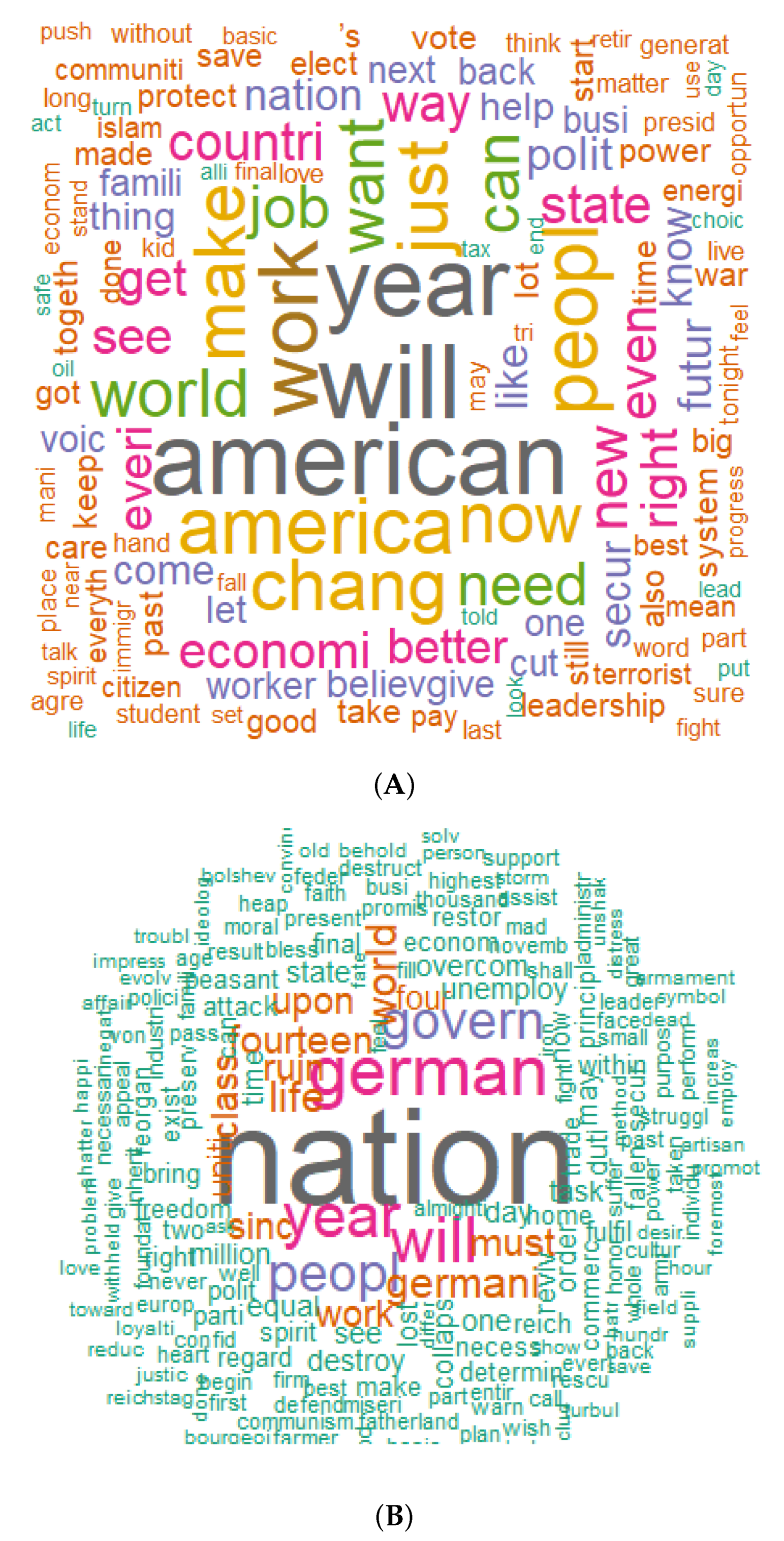
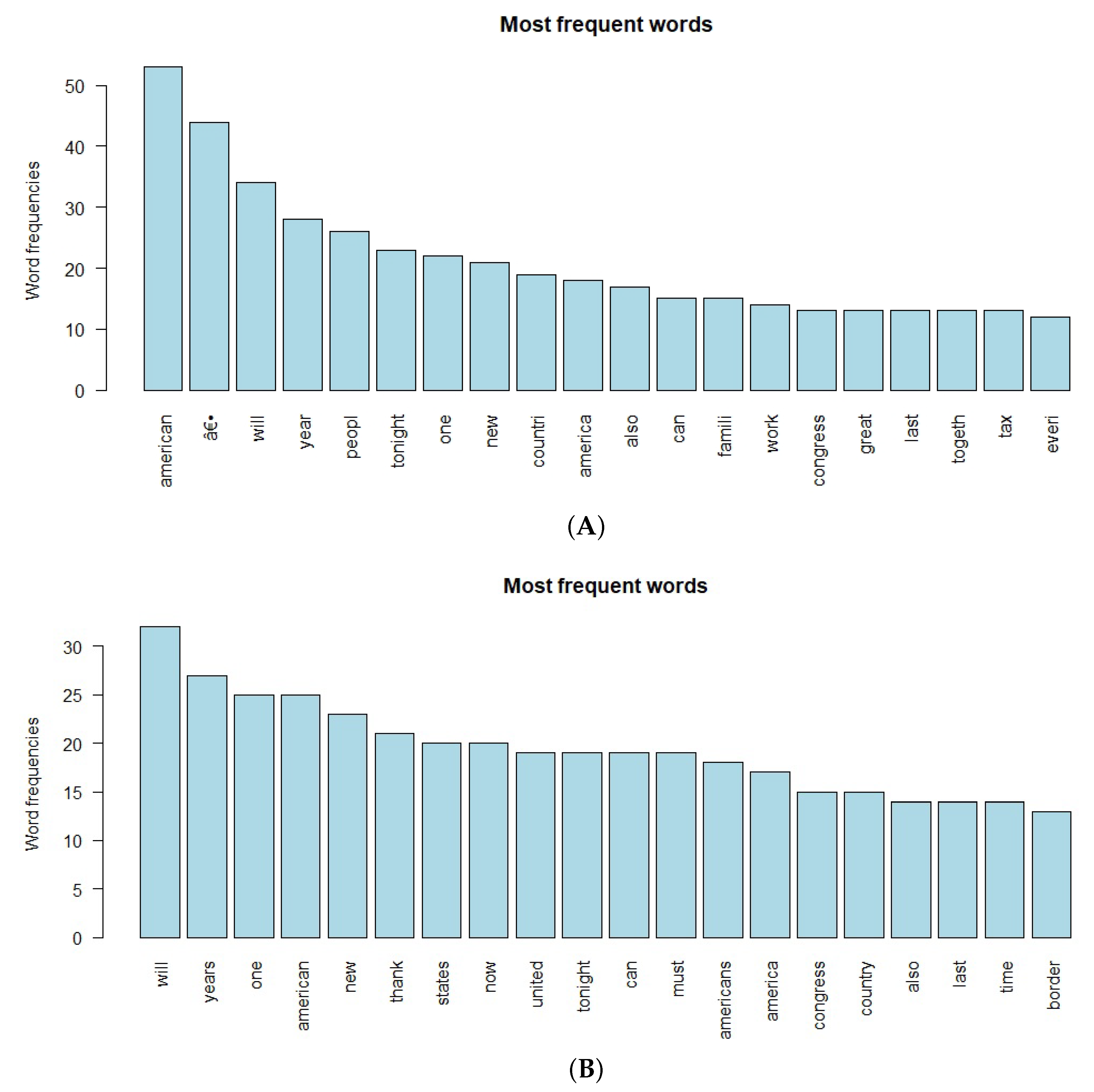
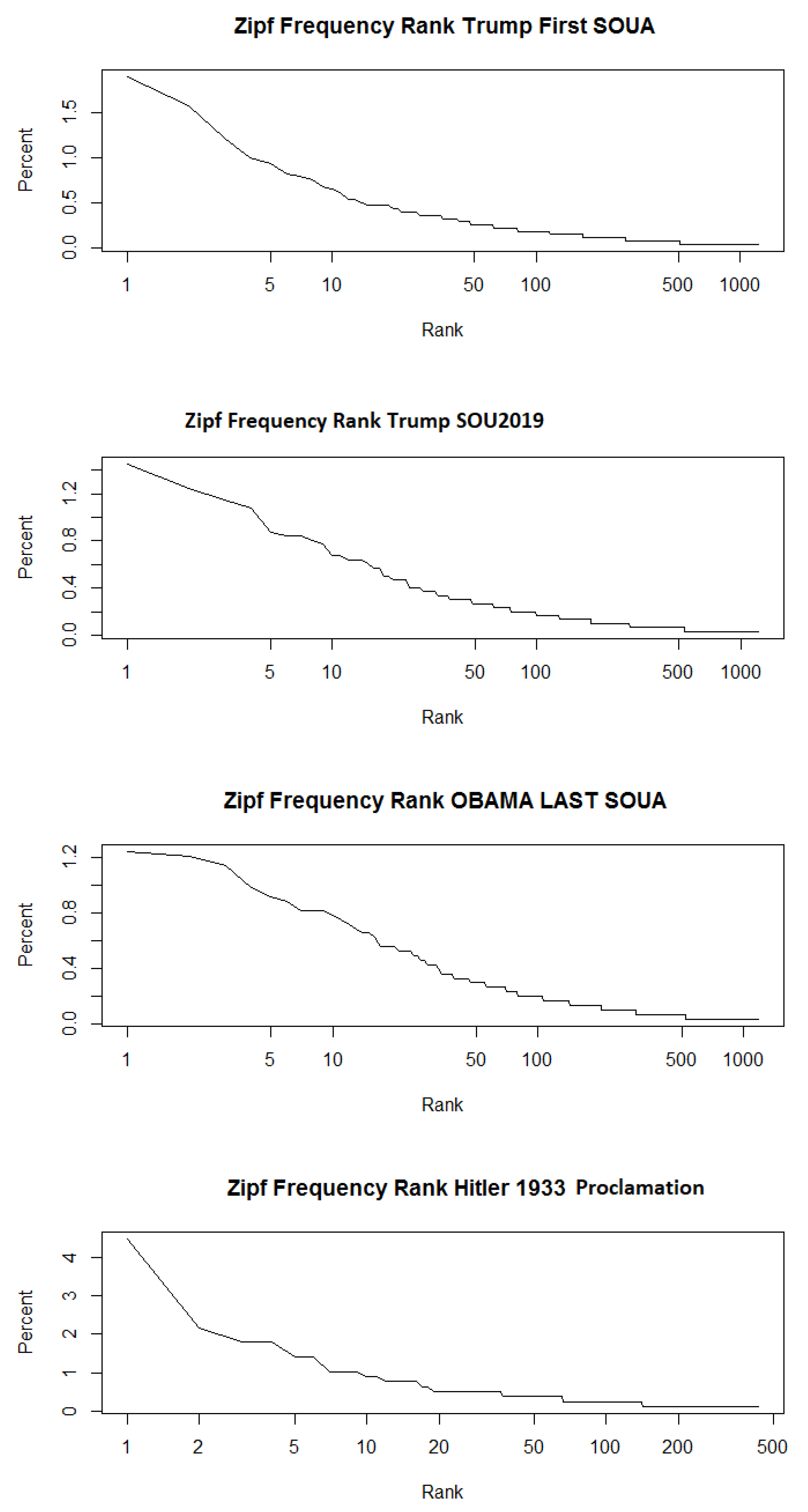
3.2. Zipf Mandelbrot Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Allen, D.E.; McAleer, M. Fake News and Indifference to Scientific Fact: President Trump’s Confused Tweets on Global Warming, Climate Change and Weather. Scientometrics 2018, 117, 625–629. [Google Scholar] [CrossRef]
- Allen, D.E.; McAleer, M. President Trump Tweets Supreme Leader Kim Jong-Un on Nuclear Weapons: A Comparison with Climate Change. Sustainability 2018, 10, 2310. [Google Scholar] [CrossRef]
- Allen, D.E.; McAleer, M.; Reid, D.M. Fake News and Indifference to Truth: Dissecting Tweets and State of the Union Addresses by Presidents Obama and Trump. Adv. Dec. Sci. 2018, 22. [Google Scholar] [CrossRef]
- Feinerer, I.; Hornik, K. Tm: Text Mining Package. R Package Version 0.7-6. 2018. Available online: https://CRAN.R-project.org/package=tm (accessed on 27 August 2019).
- Jockers, M.L. Syuzhet: Extract Sentiment and Plot Arcs from Text. 2015. Available online: https://github.com/mjockers/syuzhet (accessed on 27 August 2019).
- Fellows, I. Wordcloud. 2018. Available online: https://CRAN.R-project.org/package=wordcloud (accessed on 27 August 2019).
- Pröllochs, N.; Fuerriegel, S.; Neumann, D. Understanding Negations in Information Processing: Learning from Replicating Human Behaviour; Working Paper; Information Systems Research, University of Freiburg: Freiburg im Breisgau, Germany, 2017; Available online: https://ssrn.com/abstract=2954460 (accessed on 27 August 2019).
- Allen, D.E.; McAleer, M.; Singh, A.K. Machine News and Volatility: The Dow Jones Industrial Average and the TRNA Real-Time High Frequency Sentiment Series. In Handbook of High Frequency Trading; Gregoriou, G.N., Ed.; Academic Press: Cambridge, MA, USA, 2015; Chapter 19. [Google Scholar]
- Allen, D.E.; McAleer, M.; Singh, A.K. An Entropy-based Analysis of the Relationship Between the DOW JONES Index and the TRNA Sentiment series. Appl. Econ. 2017, 49, 677–692. [Google Scholar] [CrossRef]
- Allen, D.E.; McAleer, M.; Singh, A.K. Daily Market News Sentiment and Stock Prices. Appl. Econ. 2018. [Google Scholar] [CrossRef]
- Tetlock, P.C. Giving Content to Investor Sentiment: The Role of Media in the Stock Market. J. Financ. 2007, 62, 1139–1167. [Google Scholar] [CrossRef]
- Tetlock, P.C.; Macskassy, S.A.; Saar-Tsechansky, M. More than Words: Quantifying Language to Measure Firms’ Fundamentals. J. Financ. 2008, 63, 1427–1467. [Google Scholar] [CrossRef]
- Da, Z.H.I.; Engelberg, J.; Gao, P. In Search of Attention. J. Financ. 2011, 66, 1461–1499. [Google Scholar] [CrossRef]
- Barber, B.M.; Odean, T. All that Glitters: The Effect of Attention and News on the Buying Behaviour of Individual and Institutional Investors. Rev. Financ. Stud. 2008, 21, 785–818. [Google Scholar] [CrossRef]
- diBartolomeo, D.; Warrick, S. Making Covariance Based Portfolio Risk Models Sensitive to the Rate at Which Markets React to New Information; Knight, J., Satchell, S., Eds.; Linear Factor Models; Elsevier Finance: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Mitra, L.; Mitra, G.; diBartolomeo, D. Equity Portfolio Risk (Volatility) Estimation using Market Information and Sentiment. Quant. Financ. 2009, 9, 887–895. [Google Scholar] [CrossRef]
- Dzielinski, M.; Rieger, M.O.; Talpsepp, T. Volatility Asymmetry, News, and Private Investors. In Handbook of News Analytics in Finance; Wiley: Hoboken, NJ, USA, 2011; pp. 255–270. [Google Scholar]
- Cahan, R.; Jussa, J.; Luo, Y. Breaking News: How to Use News Sentiment to Pick Stocks; MacQuarie US Research Report: New York, NY, USA, 2009. [Google Scholar]
- Hafez, P.; Xie, J. Factoring Sentiment Risk into Quant Models, RavenPack International S.L. J. Investig. 2012, 25. [Google Scholar] [CrossRef]
- Kearney, C.; Lui, S. Textual Sentiment in Finance: A Survey of Methods and Models. Int. Rev. Financ. Anal. 2014, 33, 171–185. [Google Scholar] [CrossRef]
- Loughran, T.; McDonald, B. Textual Analysis in Accounting and Finance: A Survey. J. Account. Res. 2016, 54, 1187–1230. [Google Scholar] [CrossRef]
- Zipf, G.K. Selected Studies of the Principle of Relative Frequency in Language; Harvard University Press: Cambridge, UK, 1932. [Google Scholar]
- Mandelbrot, B. Information Theory and Psycholinguistics. In Chapter in Scientific Psychology; Wolman, B.B., Ed.; Basic Books: New York, NY, USA, 1965. [Google Scholar]
- Shannon, C. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 379–423, 623–656. [Google Scholar] [CrossRef]
- Ficcadenti, V.; Cerqueti, R.; Ausloos, M. A Joint Text Mining-rank Size Investigation of the Rhetoric Structures of the US Presidents’ Speeches. Expert Syst. Appl. 2019, 123, 127–142. [Google Scholar] [CrossRef]
- Shklovsky, V. Art as Technique. In Russian Formalist Criticism; Lemon, L.T., Reis, M., Eds.; University of Nebraska Press: Lincoln, NE, USA, 1965. [Google Scholar]
- Propp, V. Morphology of the Folk Tale; English Trans; First Published in Moscow in 1928; University of Texas Press: Laurence Scott, TX, USA, 1968. [Google Scholar]
- Smith, A.D. Gastronomy or Geology? The role of Nationalism in the Reconstruction of Nations. N. Natl. 1994, 1, 3–23. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trump SOU2018 | Trump SOU2019 | ||||
|---|---|---|---|---|---|
| Word | Correlated Words | Correlation | Word | Correlated Words | Correlation |
| American | bridge | 0.34 | Will | never | 0.49 |
| gleam | 0.34 | Afghan | 0.41 | ||
| grit | 0.34 | constructive | 0.41 | ||
| heritage | 0.34 | counter terrorism | 0.41 | ||
| highway | 0.34 | focus | 0.41 | ||
| railway | 0.34 | groups | 0.41 | ||
| reclaim | 0.34 | indeed | 0.41 | ||
| waterway | 0.34 | taliban | 0.41 | ||
| background | 0.34 | talks | 0.41 | ||
| color | 0.34 | troop | 0.41 | ||
| creed | 0.34 | agreement | 0.38 | ||
| dreamer | 0.34 | achieve | 0.37 | ||
| official | 0.34 | make | 0.37 | ||
| religion | 0.34 | progress | 0.37 | ||
| sacred | 0.34 | proudly | 0.37 | ||
| dream | 0.33 | dream | 0.37 | ||
| hand | 0.33 | holding | 0.37 | ||
| land | 0.31 | whether | 0.35 | ||
| duty | 0.31 | incredible | 0.32 | ||
| right | 0.31 | American | back | 0.51 | |
| arsenal | 0.44 | soldiers | 0.40 | ||
| will | deter | 0.44 | astronauts | 0.37 | |
| magic | 0.44 | Buzz | 0.37 | ||
| part | 0.44 | space | 0.37 | ||
| someday | 0.44 | intellectual | 0.37 | ||
| unfortunate | 0.44 | property | 0.37 | ||
| use | 0.44 | Dachau | 0.37 | ||
| weapon | 0.44 | second | 0.37 | ||
| yet | 0.44 | ||||
| aggression | 0.40 | ||||
| moment | 0.32 | ||||
| modern | 0.32 | ||||
| Obama SOU | Hitler 1933 | ||||
|---|---|---|---|---|---|
| Word | Correlated Words | Correlation | Word | Correlated Words | Correlation |
| American | various numbers | n.a. | Nation | life | 0.42 |
| will | preserve | 0.44 | will | 0.40 | |
| status-quo | 0.44 | govern | 0.37 | ||
| planet | 0.30 | regard | 0.32 | ||
| America | George Washington Carver | 0.36 | will | health | 0.50 |
| Katherine Johnson | 0.36 | lead | 0.40 | ||
| Sally Ride | 0.36 | nation | 0.40 | ||
| unit | 0.35 | back | 0.33 | ||
| assist | 0.33 | ||||
| German | work | 0.34 | |||
| rescue | 0.32 | ||||
| support | 0.32 | ||||
| Coefficient | Std. Error | t-Ratio | p-Value | |
|---|---|---|---|---|
| const | 4.60818 | 0.0301961 | 152.6 | 0.0000 |
| l_RankT1 | −0.674643 | 0.00487040 | −138.5 | 0.0000 |
| Mean dependent var | 0.478800 | S.D. dependent var | 0.687286 | |
| Sum squared resid | 35.08483 | S.E. of regression | 0.168823 | |
| 0.939712 | Adjusted | 0.939663 | ||
| 19187.55 | P-value(F) | 0.000000 | ||
| Log-likelihood | 444.8414 | Akaike criterion | −885.6829 | |
| Schwarz criterion | −875.4484 | Hannan–Quinn | −881.8328 | |
| OLS, using Observations 1–1227 Dependent variable: l_freqT2 | ||||
| Coefficient | Std. Error | -Ratio | p-value | |
| const | 4.83631 | 0.0306320 | 157.9 | 0.0000 |
| l_RankT2 | −0.706661 | 0.00494454 | −142.9 | 0.0000 |
| Mean dependent var | 0.514392 | S.D. dependent var | 0.718456 | |
| Sum squared resid | 35.80636 | S.E. of regression | 0.170967 | |
| 0.943419 | Adjusted | 0.943373 | ||
| 20425.42 | P-value(F) | 0.000000 | ||
| Log-likelihood | 427.1954 | Akaike criterion | −850.3908 | |
| Schwarz criterion | −840.1661 | Hannan–Quinn | −846.5434 | |
| OLS, using Observations 1–433 Dependent variable: l_freqH1 | ||||
| Coefficient | Std. Error | -Ratio | p-Value | |
| const | 3.21372 | 0.0434618 | 73.94 | 0.0000 |
| l_RankH | −0.565233 | 0.00840317 | −67.26 | 0.0000 |
| Mean dependent var | 0.342408 | S.D. dependent var | 0.575778 | |
| Sum squared resid | 12.45621 | S.E. of regression | 0.170002 | |
| 0.913026 | Adjusted | 0.912824 | ||
| 4524.478 | P-value(F) | 1.1e–230 | ||
| Log-likelihood | 153.8538 | Akaike criterion | −303.7076 | |
| Schwarz criterion | −295.5661 | Hannan–Quinn | −300.4936 | |
| OLS, using Observations 1–1189 Dependent variable: l_freqO | ||||
| Coefficient | Std. Error | -Ratio | p-value | |
| const | 5.05132 | 0.0326043 | 154.9 | 0.0000 |
| l_RankO | −0.740851 | 0.00528936 | −140.1 | 0.0000 |
| Mean dependent var | 0.543524 | S.D. dependent var | 0.753179 | |
| Sum squared resid | 38.44997 | S.E. of regression | 0.179979 | |
| 0.942946 | Adjusted | 0.942898 | ||
| 19618.01 | P-value(F) | 0.000000 | ||
| Log-likelihood | 352.9148 | Akaike criterion | −701.8296 | |
| Schwarz criterion | −691.6679 | Hannan–Quinn | −698.0000 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Allen, D.E.; McAleer, M. Fake News and Propaganda: Trump’s Democratic America and Hitler’s National Socialist (Nazi) Germany. Sustainability 2019, 11, 5181. https://doi.org/10.3390/su11195181
Allen DE, McAleer M. Fake News and Propaganda: Trump’s Democratic America and Hitler’s National Socialist (Nazi) Germany. Sustainability. 2019; 11(19):5181. https://doi.org/10.3390/su11195181
Chicago/Turabian StyleAllen, David E., and Michael McAleer. 2019. "Fake News and Propaganda: Trump’s Democratic America and Hitler’s National Socialist (Nazi) Germany" Sustainability 11, no. 19: 5181. https://doi.org/10.3390/su11195181
APA StyleAllen, D. E., & McAleer, M. (2019). Fake News and Propaganda: Trump’s Democratic America and Hitler’s National Socialist (Nazi) Germany. Sustainability, 11(19), 5181. https://doi.org/10.3390/su11195181