1. Introduction
Data centers around the world are rapidly transforming itself into cloud data centers to create and process large amounts of data due to expansion of businesses such as cloud, big data, artificial intelligence (AI), and Internet of Things(IoT), and are evolving into hyperscale data centers. According to data from Gartner, data center investments were US
$181 billion in 2017, increasing 3.87% year on year to US
$188 billion in 2018, and is expected to reach US
$190 billion by 2019. The amount of cloud-based workloads in data centers is expected to reach 94% in 2021, up from 39% in 2012. The growth in the number of hyperscale data centers, essential for processing and managing exponentially growing volumes of data, has become a global trend. The number of hyperscale data centers increased by 14.2% year on year to 386 in 2017 and to 448 in 2018. It is expected to reach 628 in 2021, a 10.17% increase compared to 2020 [
1,
2].
A data center comprises a lot of servers, storage and network devices, and in addition to power for running the equipment, they also consume a lot of energy for cooling, air conditioning, and emergency power reserves. From 2005 to 2010, data centers saw a rapid increase of power consumption by 24%. It was reported that data centers accounted for approximately 1.1% to 1.5% of the global energy use and approximately 2% of the global greenhouse gas emissions during this period. Based on this, many experts predict that data center energy consumption will continue to increase rapidly. Since data centers need to provide service 24/7/365 without interruption, a power-efficient design and operation are important; however, many governments and corporations continue to operate data centers inefficiently. In many cases, a server operates on its initial setup from its initialization to its disposal, and the requirement for vendors to isolate and run applications is another cause of inefficient server operation [
3,
4,
5,
6,
7,
8].
Many studies have been conducted to solve the power consumption problem of data centers. Typical methodologies include a facility-efficient approach, which improves the efficiency of data center infrastructure facilities by optimizing the airflow, temperature, cooling, and power supply, and an operation-efficient approach, which reduces the number of servers through virtual machine (VM) consolidation and redeployment technique. An analysis of various methodologies that can reduce power consumption in data centers shows that the most efficient power saving method is server transitions to the idle mode as much as possible [
9,
10].
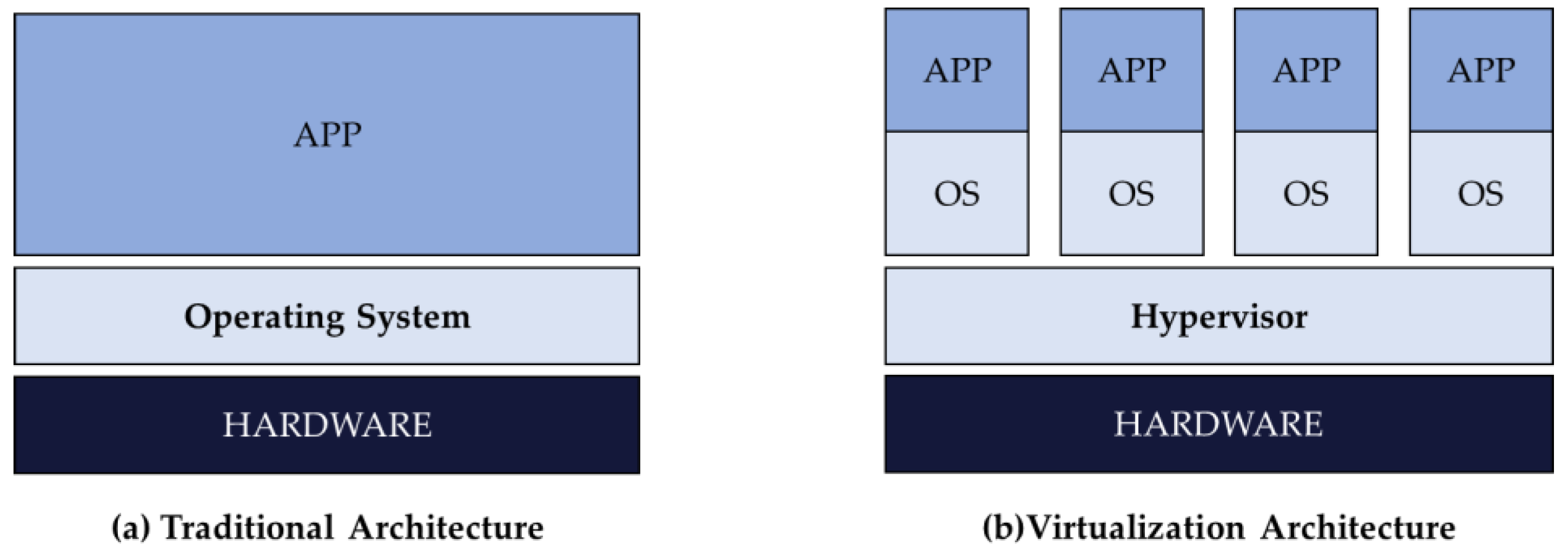
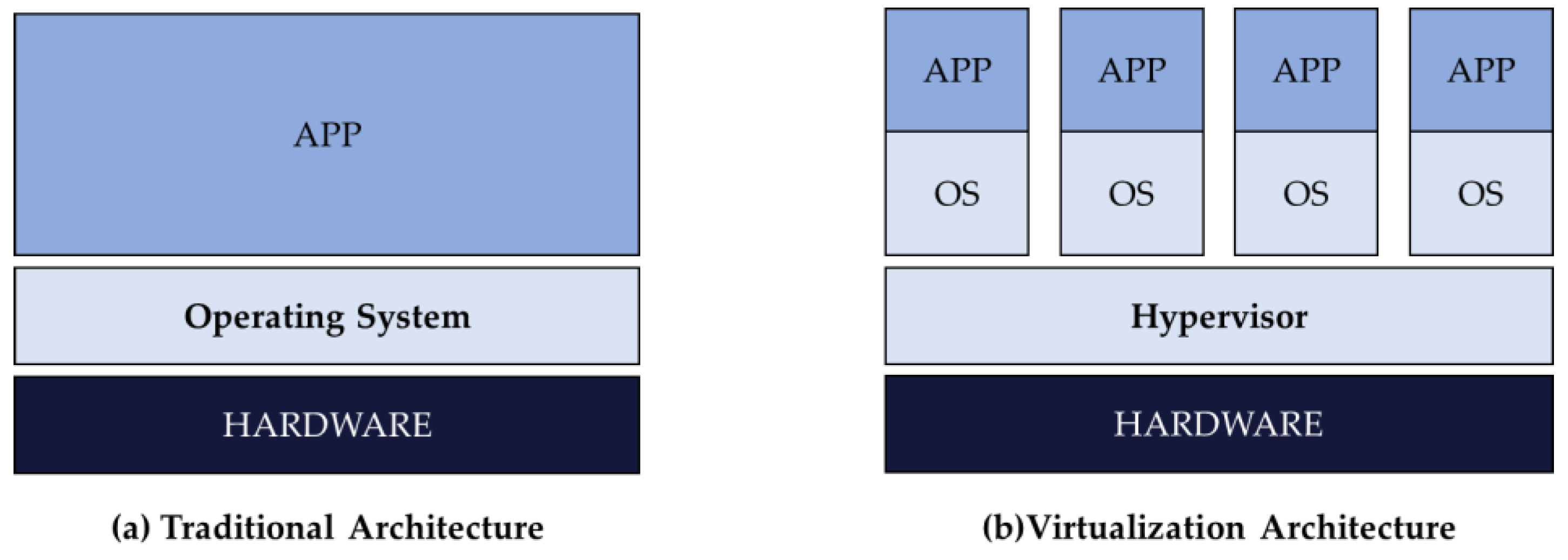
Most data centers today are managed by using virtualization technology that logically reconfigures a physical machine (PM) into multiple virtual machines (VMs). Unlike the traditional structure in which one operating system is installed on one server, virtualization technology allows several operating systems to be run on one server by installing virtualization software known as hypervisor, as shown in
Figure 1. In
Figure 1b, one Operating Systems(OS) unit is called VM, and a certain resource (CPU, memory, etc.) of the server is allocated to the VM. Server virtualization can be expected to reduce complexity and costs and to increase flexibility and agility, but there are frequent service level agreement violations even though there are enough resources available. The operation status still shows lower-than-expected levels, with poor resource utilization due to inefficient VM deployment, the lack of agile response due to an increased number of VMs, and a waste of power and budget of data centers with unnecessary server operation.
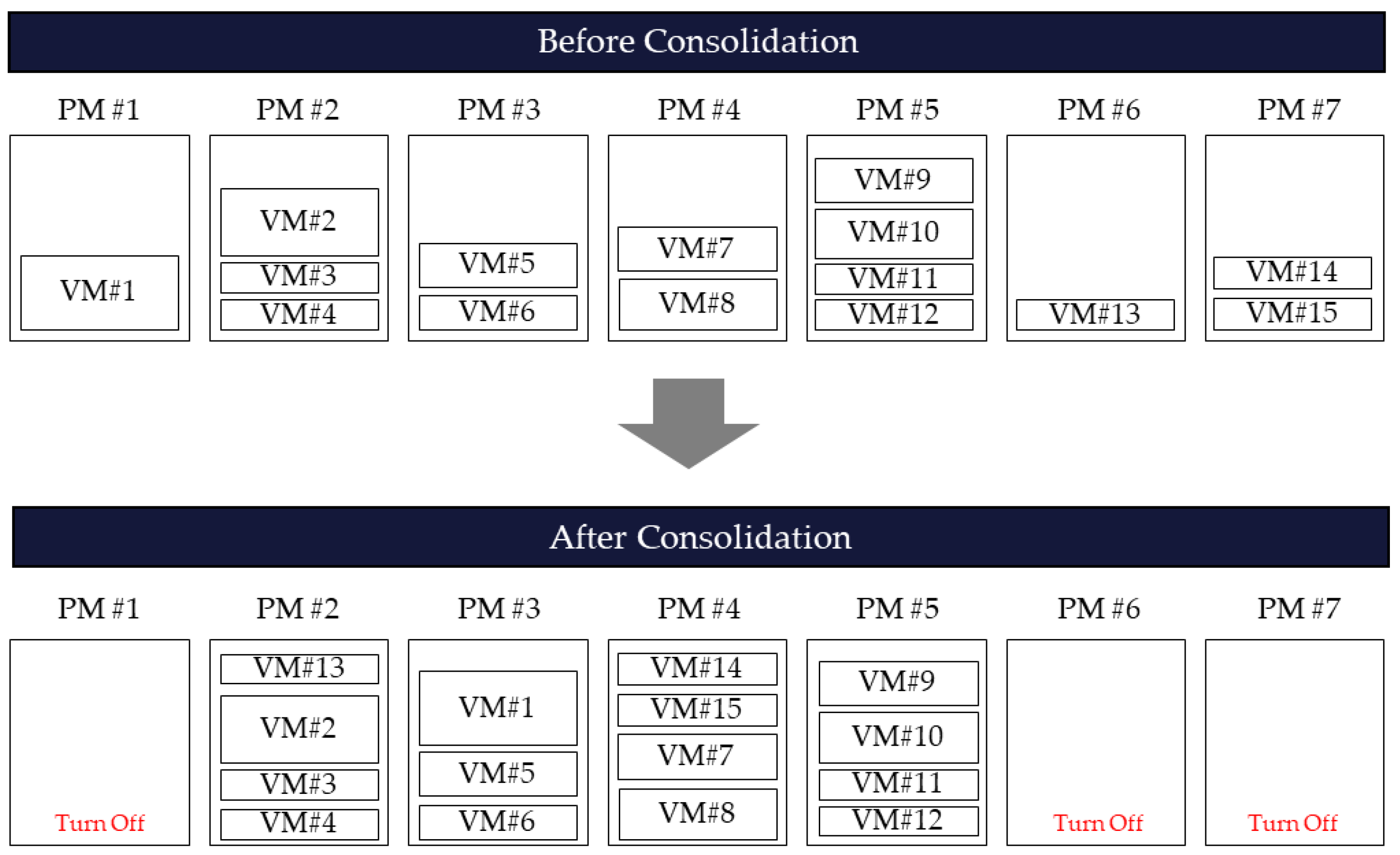
Hypervisor can move a running VM to another PM and supports the live migration function, which maintains the application’s service on the move [
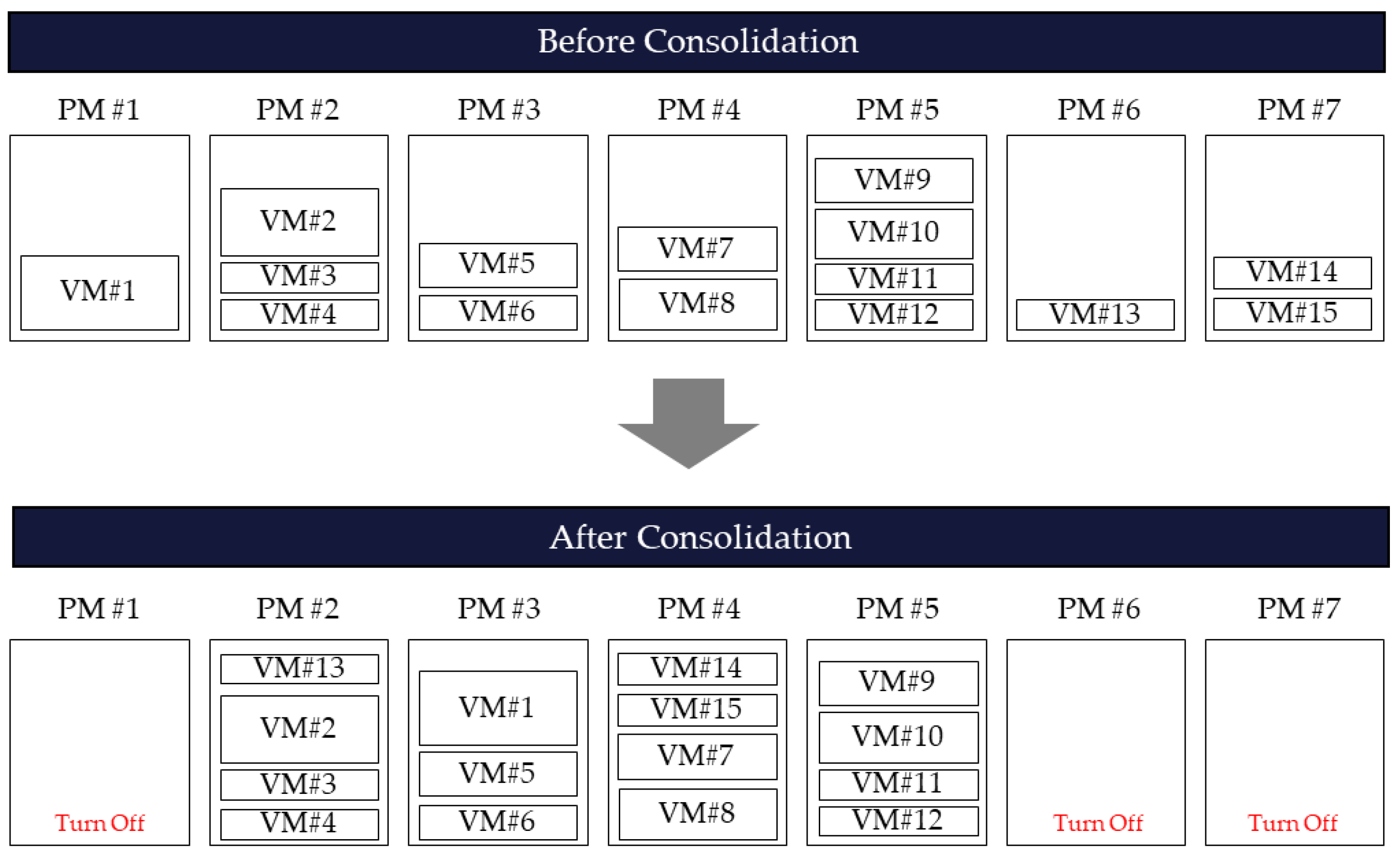
11]. If the destination PM can allow the resources allocated to the VM, migration is possible. If all VMs located in one PM are migrated to another PM, the existing server can be stopped because it is empty. Migrating VMs for server transition to the idle mode and minimizing power usage is called virtual machine consolidation (VMC), as shown in
Figure 2. This study aims to induce the transition of PMs to the idle mode, which is the most efficient power saving method for data centers, through VMC, and proceeds with efficient algorithm design for VMC problem solutions.
This paper is organized as follows:
Section 2 describes VMC and related research.
Section 3 defines the problems of VMC that this study aims to solve.
Section 4 describes the design of metaheuristic technique for solving VMC problems.
Section 5 describes the experiment design and results, and
Section 6 describes the conclusions.
2. Literature Review
VMC basically has the same mechanism as that of the bin packing problem. The bin packing problem is a typical NP-hard problem in which N items are filled into M bins as much as possible, under the assumption that N items have fixed weight, size, etc. and that M bins have a limited maximum capacity. The difference between the bin packing problem and VMC is that the bin packing problem is to fill items into an empty bin in an initially clean state, whereas VMC is more difficult as the VM that already exists in PM needs to be re-allocated. In addition, unlike the bin packing problem, which only considers the surface area and, additionally, the value, VMC has many things to consider such as CPU occupancy, memory usage, network bandwidth, and so on.
PM and VM deployment and the addition and removal of PMs and VMs due to new events are ongoing and common tasks in data centers. Initially optimized deployment reduces the operational efficiency and stability of systems over time due to operational changes in services and newly added PMs and VMs. VMC technique keeps data center resources optimized by redeploying VM tasks to remaining PM resources and migrating VMs from resource-lacking PMs to other locations [
12]. This optimization is an important means of managing data centers’ Service Level Agreements (SLAs) and Quality of Service(QoS). In addition, redeployment of resources can keep PMs in the idle state. Research has shown that reducing the number of PMs through VMC is the most obvious way to minimize data center energy consumption because nearly 70% of the server’s energy is consumed even with a server simply being turned on without a VM [
13]. VMC migrates VMs from underutilized PMs to highly utilized PMs, consolidating VMs into fewer PMs than before. The state of a PM without a VM can be changed from an active state (that is, a turned-on state) to a low energy consumption state such as sleep mode, thereby minimizing energy consumption. Several studies on VMC have been undertaken to balance energy efficiency with QoS, which is well known as an NP-hard problem that can no longer solve sudden computational complexity by intuitive human judgments or optimization methodologies using formulas such as integer programming in large-scale and complex data center environments [
10].
VMC can be classified by objective function into energy consumption minimization, network traffic minimization, economical revenue maximization, performance maximization, resource utilization maximization, and so on [
14,
15,
16,
17,
18,
19]. Among these, energy consumption minimization, performance maximization, and resource utilization maximization belong to a similar theme. The most common problem was minimizing the number of PMs or minimizing the power as calculated directly by the researcher. The problem of minimizing energy consumption through VMC inevitably correlates with VM migration minimization and SLA violations. Live migration is an expensive operation that includes CPU throughput for the source PM, link bandwidth between the source and target PMs, service downtime in the migration VM, and overall migration time. As it is a sensitive task that is also related to the stability of service operations, minimizing VM migration also becomes an important objective function. Migration has a different weight depending on the service sensitivity of the task. Due to slight downtime, certain sensitive service tasks may not be able to migrate VMs if they put all of their value on service stability rather than economic utility. SLAs are an important requirement for data center operations to maintain the desired QoS, and QoS requirements are typically formulated in an SLA format that specifies service level requirements for the data center in terms of minimum latency or maximum response time.
VMC is usually a matter of determining the following three pivotal components [
10]. First is source host selection. A PM set is selected among all PMs from which the VM is to be migrated. Generally, selection is made using threshold-based methods, which include static and adaptive methods. The adaptive threshold-based method is generally used in most cases. Second is VM selection. At least one VM is selected from source PM for migration. For this step, methodologies such as random choice, minimization of VM migration, high potential growth, minimization of migration time, and maximum correlation are commonly used. Third is destination PM selection. Lastly, destination PM selection is a series of processes that select the PM for the deployment of the selected VM. Various methodologies exist including random PM selection, optimization, heuristic, metaheuristic, etc.
When the existing research is classified by methodology for solving VMC, there are studies using optimization techniques such as binary integer programming, constraint programming, dynamic programming, integer linear programming, linear programming, etc. The limitations include that the conditions were simplified for solutions and the execution time was too long compared to performance. Generally, about 10 to 20 VMs are allocated to one PM. Since it is difficult to derive the optimal value and it takes a long time when the size of PM is large, most studies used heuristics. As this is also an NP-hard problem, it is more efficient to approach it with a heuristic or metaheuristic method than with an optimization method. Heuristic techniques include studies using best fit decreasing (BFD), best fit (BF), first fit (FF), and first fit decreasing (FFD), while many studies using the greedy algorithm also exist. Recently, due to the increasing complexity of VMC following the increased size of data centers, many studies on methodologies using metaheuristics are being conducted. Y. Gao [
20] and four others presented the ant colony optimization (ACO) suitable for a multi-objective problem in order to reduce wasted server resources and power, and compared it with the genetic algorithm (GA) and max–min ant system in a study. K.Y. Chen [
21] and four others calculated the cost of VM deployment and solved the problem of minimizing the cost with cut-and-search. C.C.T. Mark [
22] and two others presented an evolutionary algorithm that predicts the resource demands of VMs and optimizes VM deployment to minimize costs. A.C. Adamuthe [
23] and two others designed the GA suitable for VM deployment and compared the performance with FFD. G. Wu [
24] and three others solved the problem of maximizing load balancing and profits and minimizing the waste of resources using GA, NSGA and NSGA-II. Y. Wu [
25] and two others used simulated annealing (SA) to solve a VM deployment problem [
26], and T. Ferreto and two others proposed the Tabu search (TS) algorithm that ensures that migration is completed within the specified maximum time.
Virtualization has a characteristic that the size of the VMC problem is large-scale because multiple VMs are assigned to one PM. For this reason, many studies have applied metaheuristic because it is difficult to solve the global optimal solution. As a result of analyzing the existing studies using metaheuristics, only the design of the algorithm is presented, and few studies have suggested how to solve the large-scale problem effectively. In this study, we propose a grouping representation method to effectively searches for optimal solutions even at large scale, reflecting the characteristics of VMC.
3. Virtual Machine Consolidation Modeling
VMC can reduce PM power through VM migration, but VM migration is one of the tasks to avoid. This is because virtual machine migration itself is a resource-intensive task, and there is slight downtime during the migration [
11]. From a practical point of view, administrators should also be aware of the mapping information of PMs and VMs. If the mapping information of multiple PMs and VMs is changed frequently, the complexity of management points will increase. For these reasons, VM migration is rarely used during operation and is used to plan a regular inspection schedule in advance and migrate a VM that is powered off or suspended between hosts (cold migration). Therefore, this study reflects such environments of data centers and considers the VMC’s original purpose of reducing the amount of power and minimizing the number of VM migrations. VMC constraints are set as follows.
VM allocation constraints: Virtualization technology makes it possible to assign multiple VMs to a single PM. This is indicated as in Equation (1) and
shows whether the VM
has been allocated to the PM
. The value is 1 when allocated; if not, the value is 0. The condition is that a VM cannot be assigned to multiple PMs. Therefore, the sum of
for VM
j should be 1 as in Equation (2), and it means that the VM should be allocated to one PM.
PM capacity constraints: The number of VMs allowed by PM
can be calculated through CPU and memory. As in Equations (3) and (4), the CPU usage (
) and memory usage (
of PM
is calculated as the total sum of the CPU (
) and memory (
of VMs allocated to the PM
. In general, PM is set to have a workload not exceeding a certain threshold for stable operation. In other words, PM
’s workload should not exceed the threshold (
), and thus the usage is calculated by dividing the quantity of CPU and Memory currently being used by the total capacity of (
,
of the CPU and Memory of the PM.
PM released constraints: PMs without any VMs can be turned off to reduce power. Equation (4) indicates the value of 0 if at least 1 VM is allocated to the PM
because PM cannot be released; otherwise,
it indicates 1. It is used as the sum (
of the number of released PMs in the calculation of the objective function, and is calculated as in Equation (8).
Number of VM migration calculation: In the initial state, VMC derives
, the PM–VM allocation information through an operation. When the initial PM–VM allocation information is
and the PM–VM allocation information changed through VM migration is
, the number of migrations is calculated as shown in Equation (9).
Objective function: Murtazaev et al. [
27] refers to migration efficiency as a performance measure that measures the maximum of transitions of PMs to the idle mode with minimum migrations. The higher the value, the higher the efficiency. For example, if three PMs transition to the idle mode by three migrations, the migration efficiency is 100%. The objective function of this study is to maximize migration efficiency, and the formula for calculation is as in Equation (10).
The primary goal of this study was for PM transition to the idle mode, which is the basic purpose of VMC, and at the same time, the goal was to maximize PM transitions to the idle mode with minimum migrations. Since VMC is known as an NP-hard, a metaheuristic suitable for this was adopted as a methodology.
Section 4 describes the efficient metaheuristic operator design for solving VMC problems.
4. Proposed Grouping Harmony Search for Virtual Machine Consolidation
This section described the detailed procedures of harmony search (HS) and grouping harmony search (GHS), one of the metaheuristic techniques used to solve VMC, and the contents of the operators designed to efficiently solve VMC problems.
4.1. Overview of Harmony Search
HS is an optimization algorithm that was created based on the observation that better chords are produced by repeated practice in improvisation of jazz. This refers to a series of processes that the most beautiful chords (global optimum) can be made through repetitive practice (iteration) when played by a variety of instruments.
In the case of GA, inspired by population genetics inspired by population genetics, generates new genes from two genes, but HS generates new solution from multiple solution, which has a high probability of searching for global optimal. Compared to SA and TS, which are typical single solution based metaheuristics, population based HS has a high global search capability. In the case of SA and TS, it is possible to drive a good quality through a mechanism that probabilistically adopts a bad solution. When HS generates a new solution, it adopts a quality solution within the population and searches for an optimal solution.
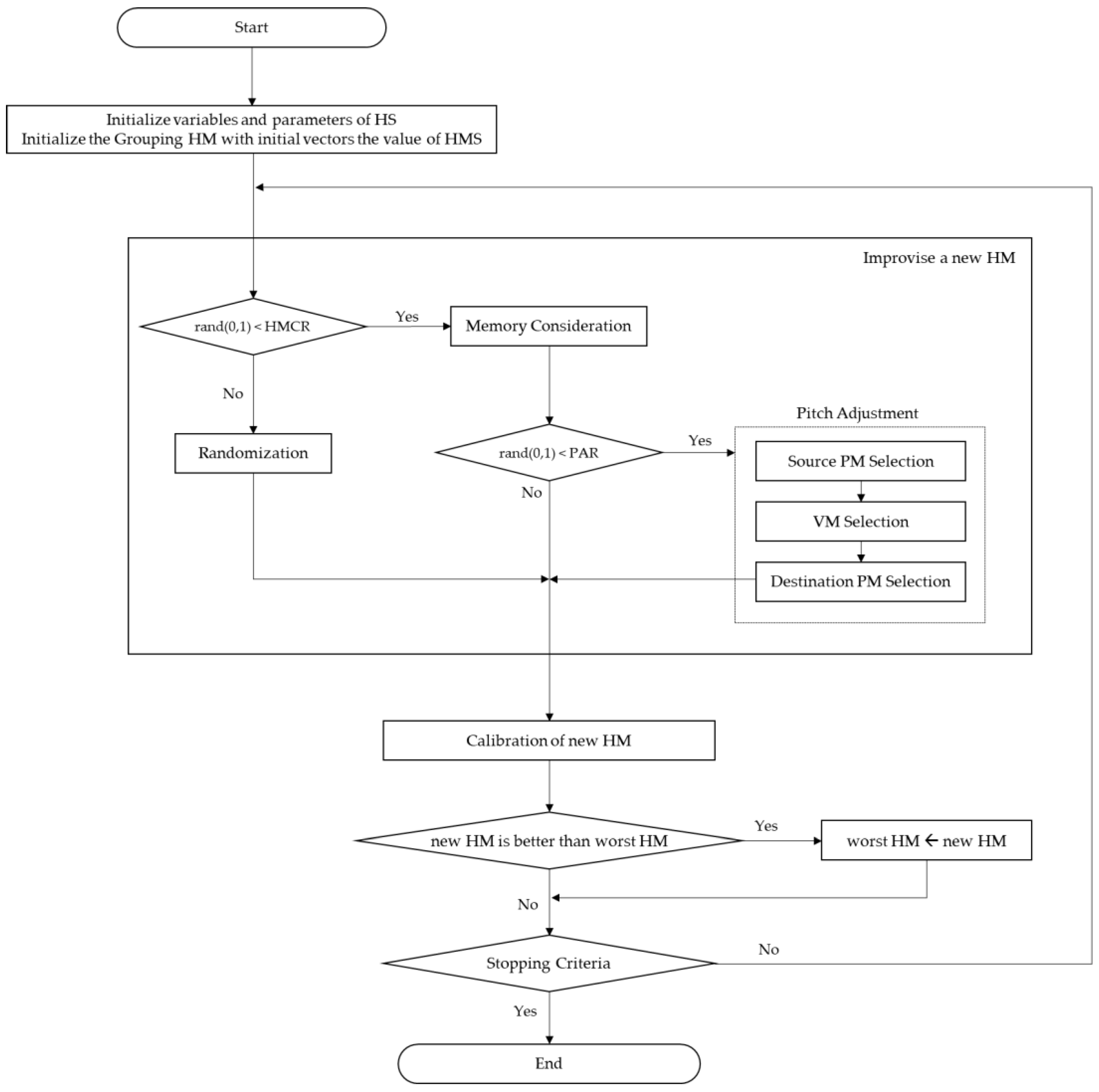
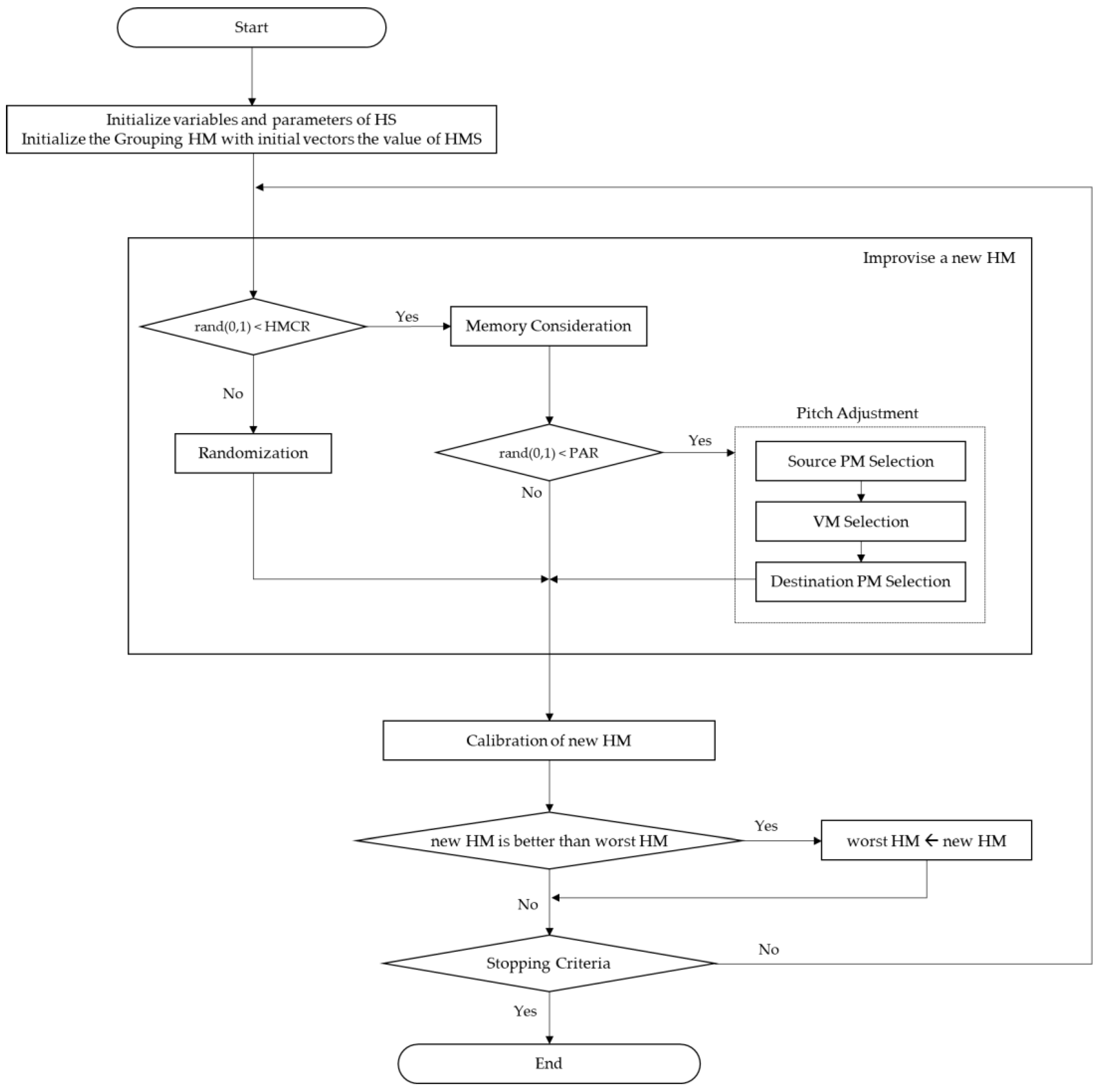
HS consists of three operators in total: memory considering, pitch adjusting, and random playing. Each operator determines the frequency of operation based on predefined parameter values. The pseudo code of HS is shown in
Table 1.
HS generates one solution (HM, harmony memory) per iteration (line 5–17). New Harmony x’ is generated through memory considering, pitch adjusting, and random playing operators by increasing the index (line 6). The operator of HS generates the first random number (line 7) to determine whether to calculate the memory considering (line 8). If the first random number is smaller than the predefined harmony memory considering rate (HMCR), memory considering is executed. If the first random number is larger than HMCR, random playing is executed (line 13). Random playing is a method of adopting the value of one of the feasible solution groups. Memory considering adopts the value of one of several solutions of harmony memory size (HMS). When the solution is generated through memory considering, the operation for pitch adjusting is determined by generating a second random number. If the second random number is smaller than the predefined pitch adjusting rate (PAR), pitch adjusting is executed (line 10). Pitch adjusting means the neighboring value of the solution generated by memory considering. The target value is calculated once x’ is generated, and if it has a better value than the target value of the worst HM in the HMS, the solution is replaced with new harmony (line 16–17). HS repeats the above process until the end condition is met.
4.2. Grouping Representation for Virtual Machine Consolidation
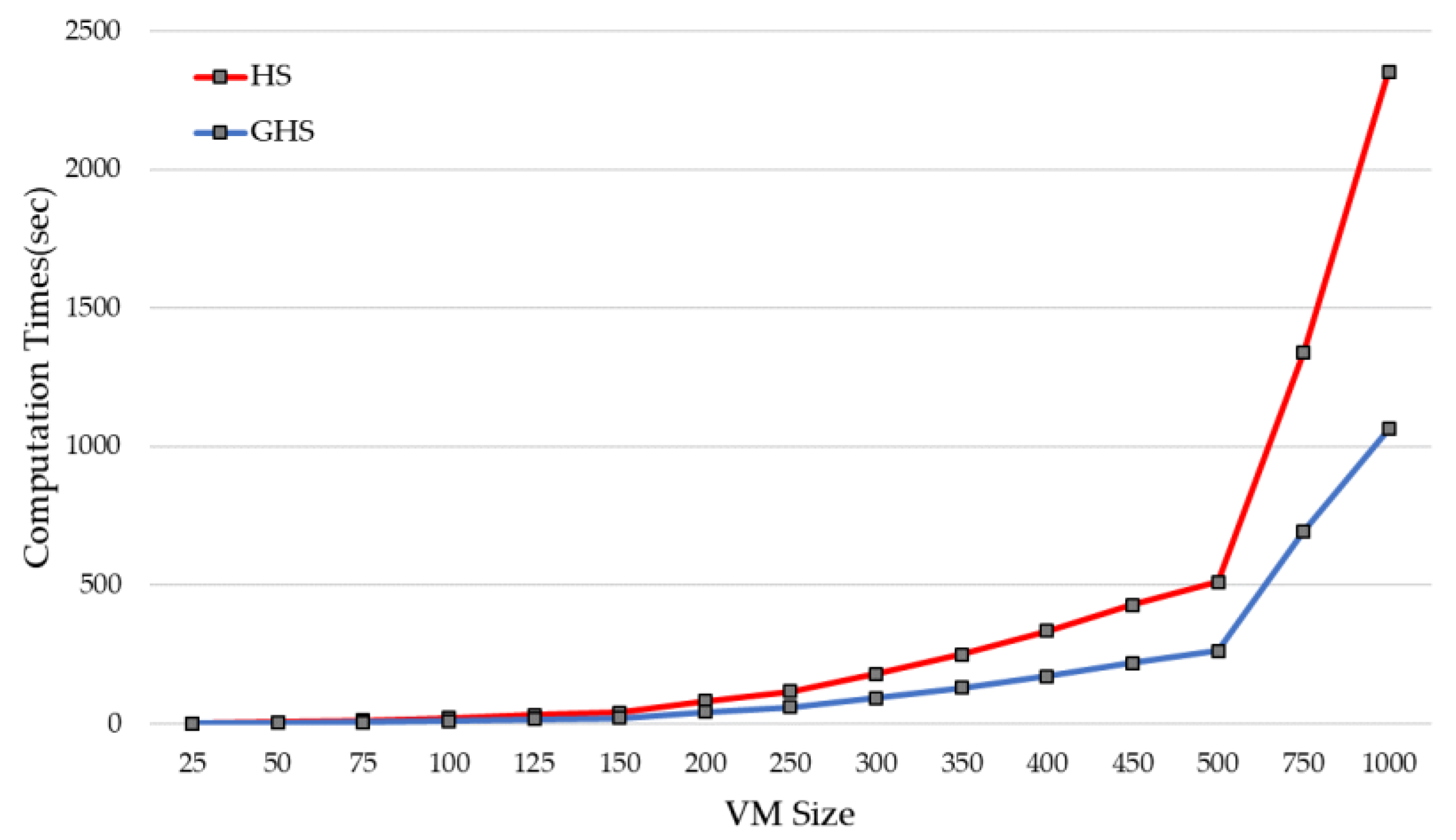
Harmony search is population-based metaheuristics that generate new HMs by combining multiple HMs and has the advantage of having a high degree of diversification; however, as a result of controlling a large number of HMs, there is a disadvantage that computation times increase compared to single solution metaheuristics. As the size of the node grows, the HMS also needs to grow to increase the efficiency of searching for a solution, so the problem occurs when handling a large-scale problem. To solve this problem, we adopted grouping representation in this study for the efficient design of algorithms.
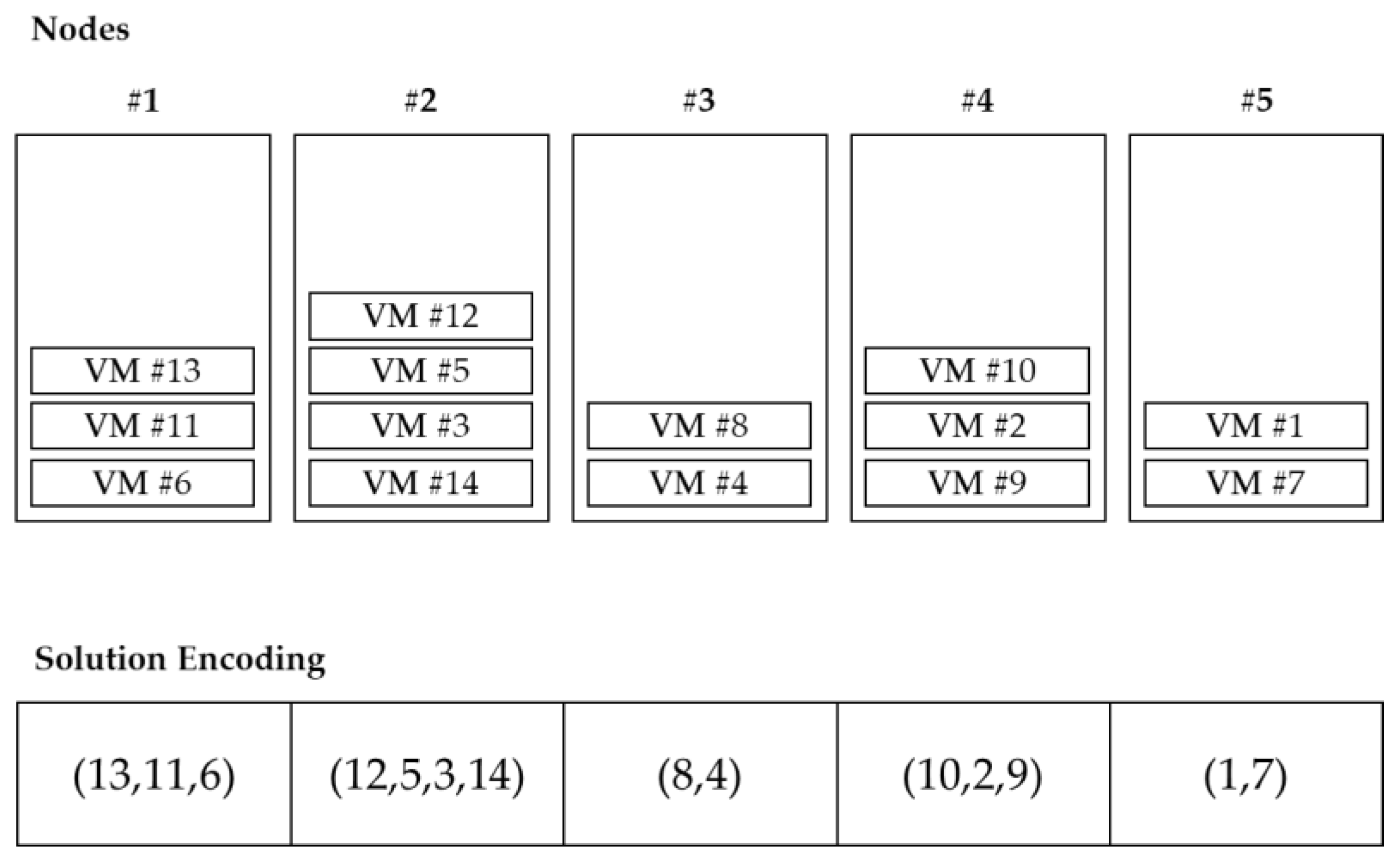
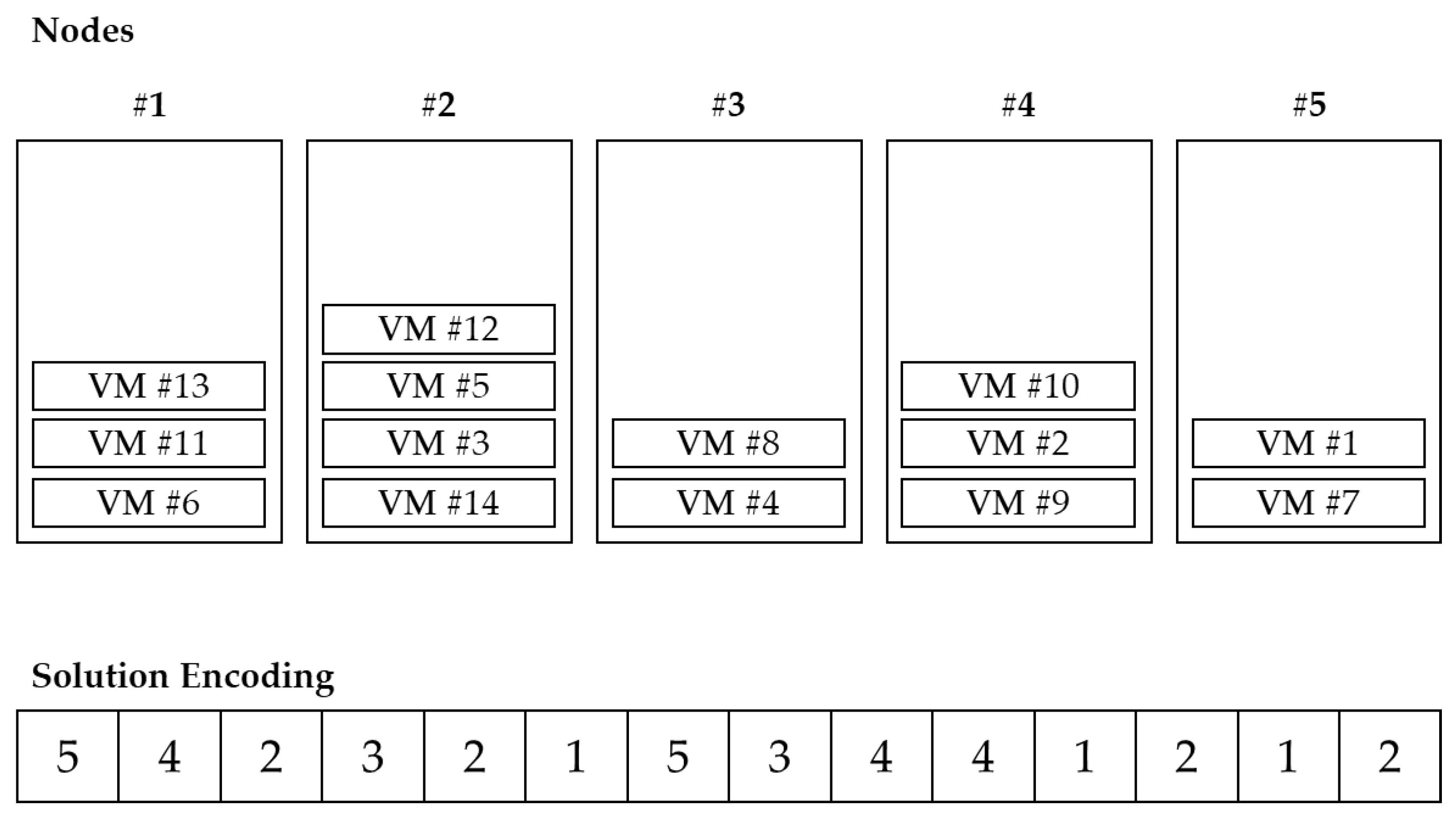
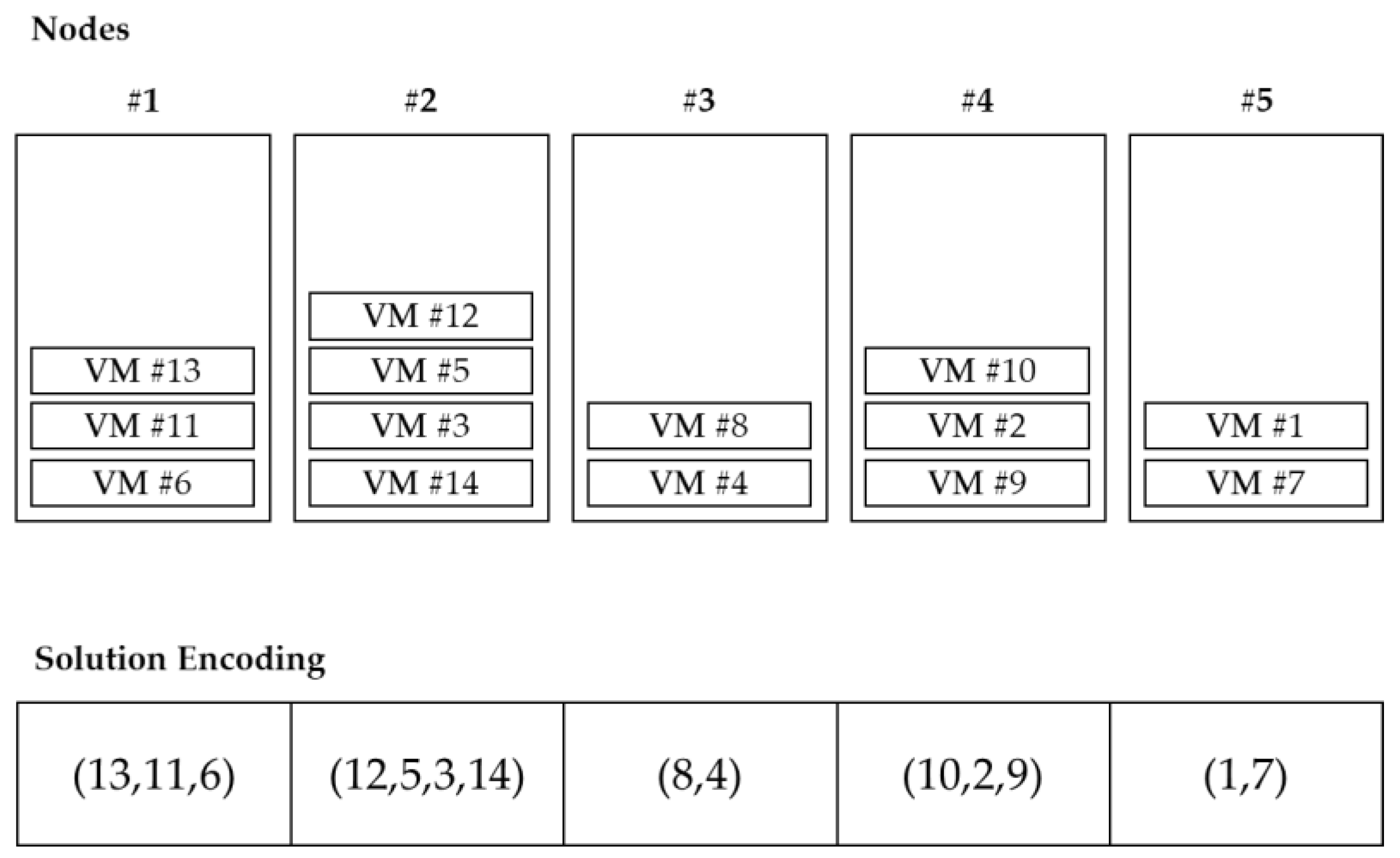
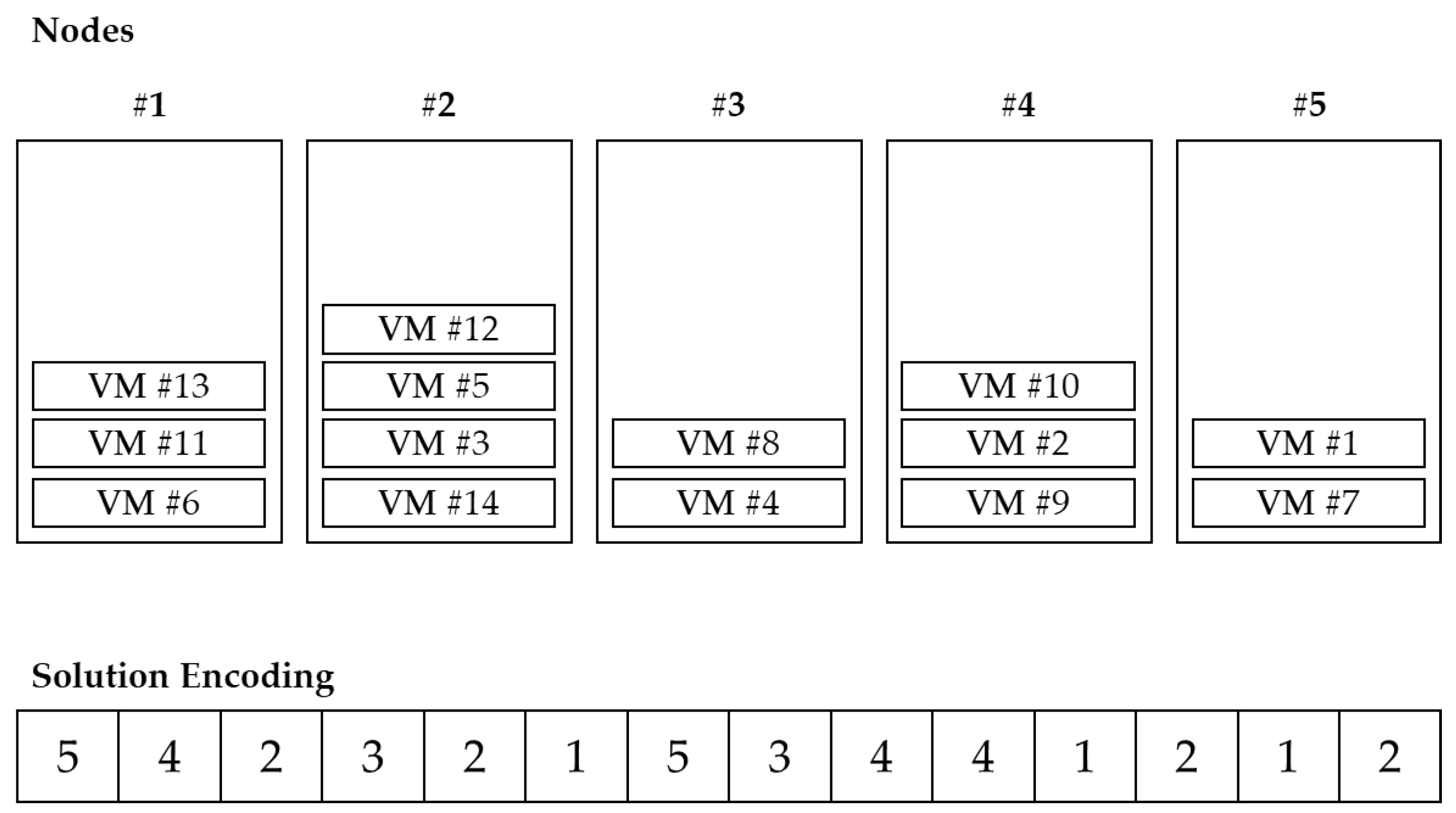
VMC belongs to grouping problems, and the ordering of objects within a group is meaningless. In other words, the combination of VMs located in the PM is important, not the order in the group. Since it also deals with virtualization environments, the number of PMs is basically smaller than the number of VMs. Since there are multiple VMs in one PM, if the problem size is adjusted, the increase in VM is higher than the increase in PM. If the solution is encoded in the permutation form of the VM, the length of the solution also increases as the number of VMs increases. This method is inefficient when searching for a solution as the solution space is increased with many duplicate solution representations. Therefore, PM-oriented representation is more efficient than VM-oriented solution representation. Falkenauer [
30] proposed a one-gene-for-one-group method for one solution grouping problem. With this in mind, this study represented PM and VM information based on groups as shown in
Figure 3. The index of each array indicates the index of PM, and the value of each array indicates the index of VM located in the corresponding PM, which is controlled in the form of a list.
4.3. Pitch Adjustments for Virtual Machine Consolidation
HS consists of three operators—memory considering, pitch adjustment, and randomization. Among them, the operator that directly changes the new HM is pitch adjustment. VMC has to decide the source PM selection, VM selection, and destination PM selection as a problem of migrating VM located in one PM to another PM. The pitch adjustment operator changes the solution by determining the above three factors. The criteria for determining each problem are as follows.
4.3.1. Source PM Selection
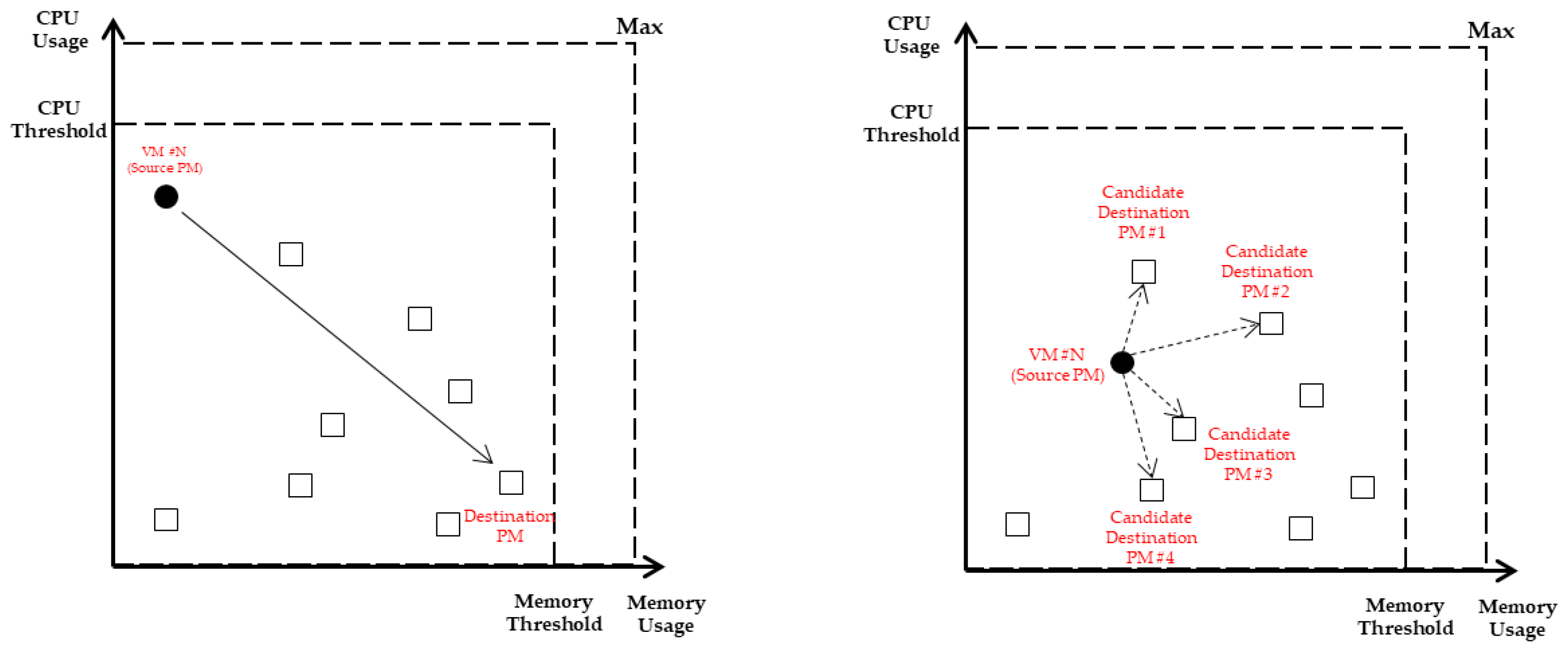
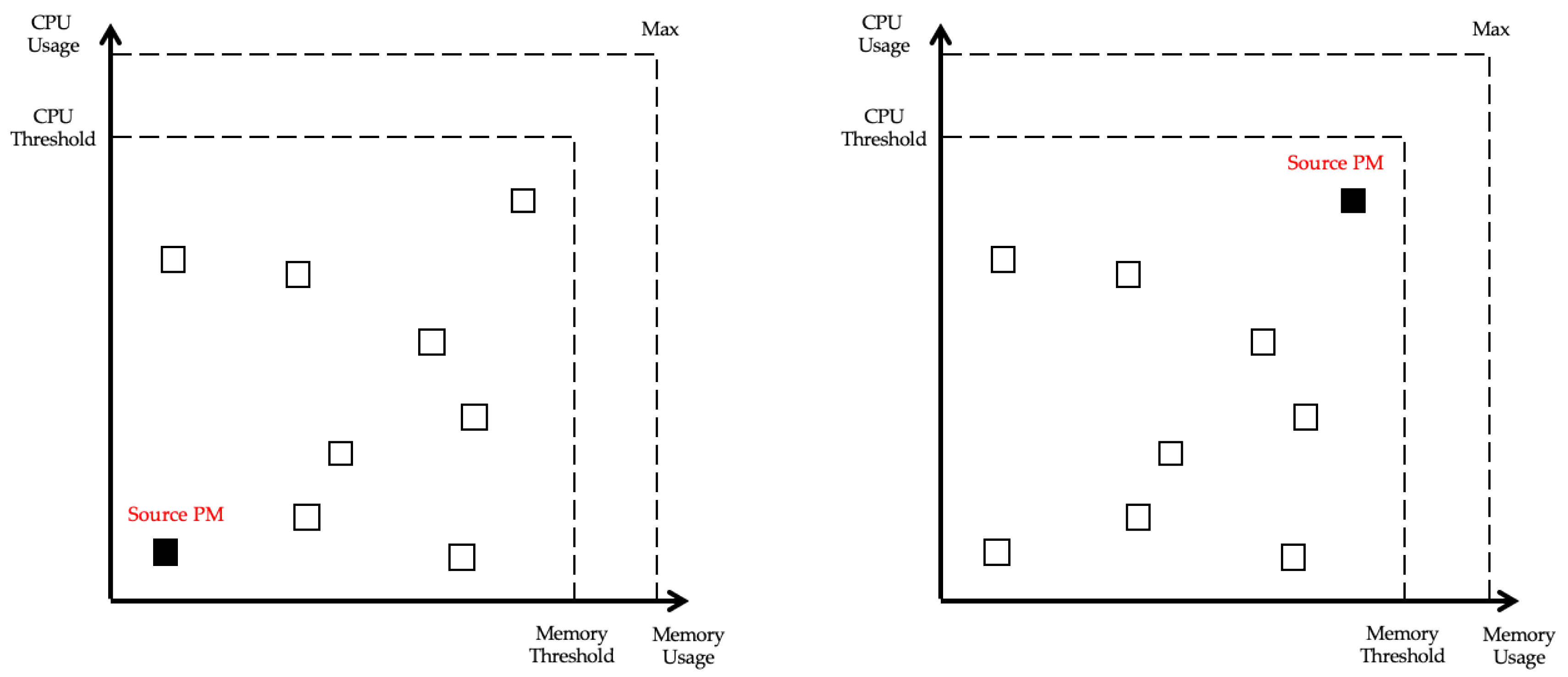
The purpose of VMC is to reduce power usage by migrating VMs and turning off unnecessary servers and to ensure stable operation of the PMs at the same time. Based on this, the selection criteria of the source PM are the PM in the underload state and the PM in the overload state. Since underloaded PM means low resource utilization and the number of VMs is often small, power can be saved with minimum migration. Selecting the overloaded PM is to ensure stable operation, and PM in the overload state should be avoided because it is likely to violate the SLA. The CPU and memory workload status of each PM can be presented by X-Y coordinates as shown in
Figure 4, and the PM that is farthest from the PM (filled square) closest to the origin becomes the source PM.
4.3.2. VM Selection and Destination PM Selection
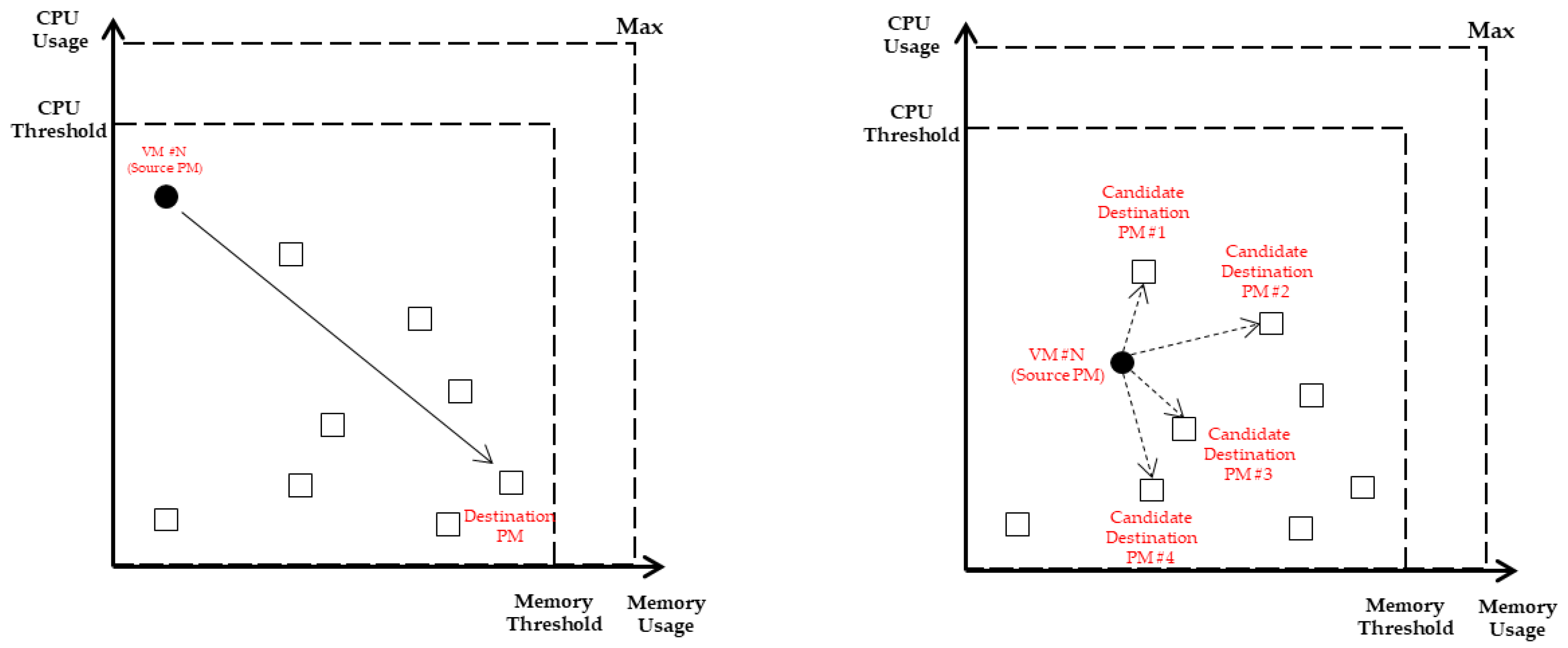
When a source PM is selected, the VM to be migrated should be selected if there are more than one VM in that PM. The selected VM is migrated from the current PM to another PM and the number of VMs that can be migrated depends on the free capacity of the destination PM. VMC is a problem similar to the bin packing problem, and the number of VMs loaded into the PM varies depending on how the VM set is formed. Therefore, VM should be filled with the goal of minimizing the free capacity of each PM. For this reason, VM selection and destination PM selection should not be considered independently, but should be considered in the same line. In
Figure 5. the VM located in the source PM is represented by a filled circle. The VM has an unbalanced characteristic in which the workload is biased toward the Y-axis (CPU usage). The VM can balance the usage of resources of the destination PM if the workload migrates to the unbalanced PM. The destination PM of the VM whose workload is unbalanced is the PM with the longest Euclidean distance. For VMs with unbalanced workloads as in
Figure 5, it is probabilistically selected based on the Euclidean distance between the VM and the destination PM candidates.
4.4. Procedure of GHS for Virtual Machine Consolidation
The GHS procedure for solving VMC is the same as the general HS procedure. However, there is a difference in that the solution representation is a group representation and the calibration method of infeasible solutions generated therefrom is added. (shown as
Figure 6)
4.5. Infeasible Solution Calibration Method
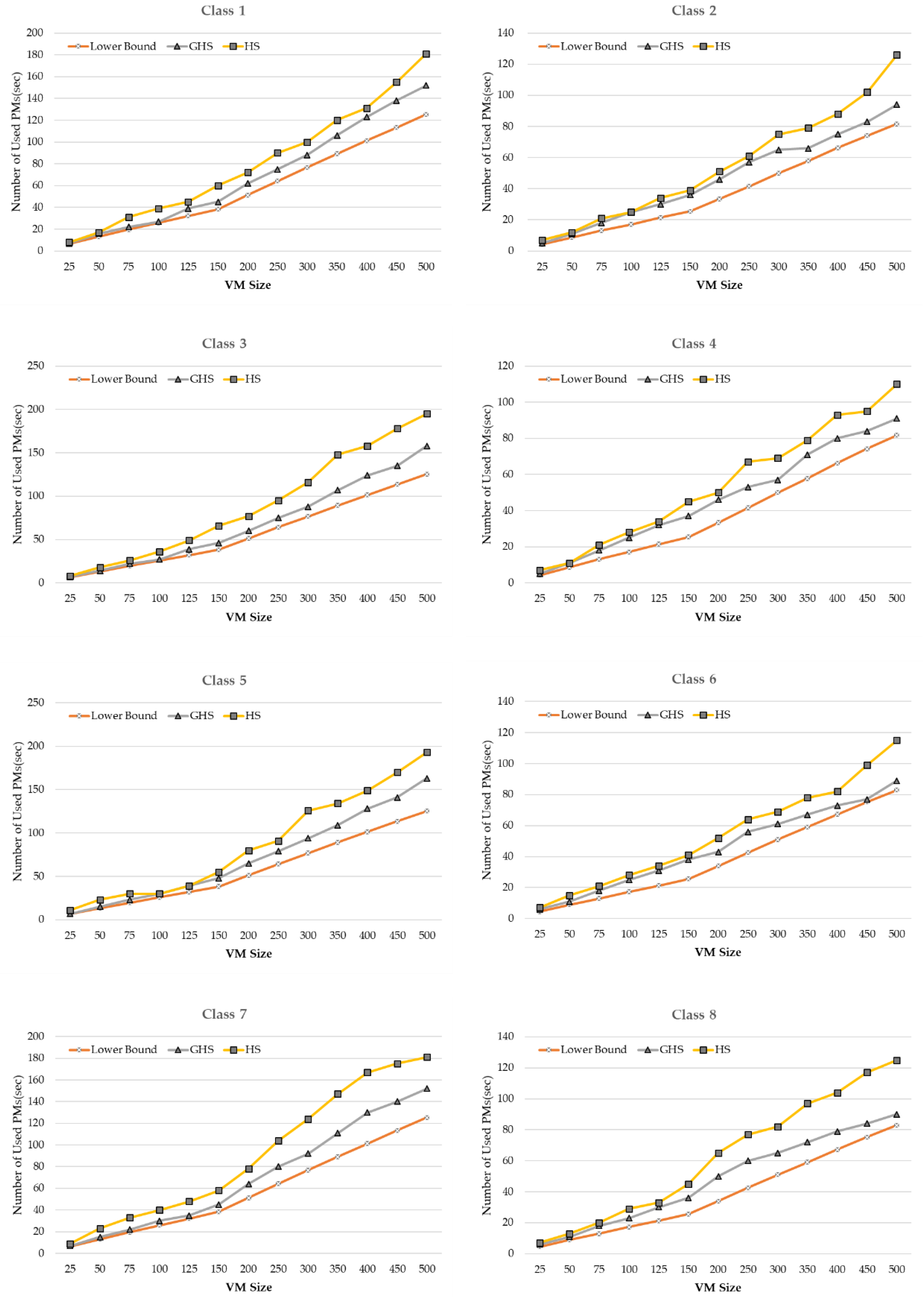
In the case of GHS, VM duplication may occur when creating a new HM in groups. VMC should not allow duplicate VMs due to restrictions on VM allocation. In existing research, heuristic techniques were used to design a separate operator that deletes the duplicate objects properly in the process of solving the grouping problem. Typical heuristic techniques applied to the bin packing problem include FFD and BFD, and an analysis showed that there is no big difference in the performance between the two [
27]. When VM duplication occurs in GHS, the heuristic technique is used to delete the remaining VMs except the best-fit VM. In addition, a solution to which a VM is not allocated may be generated. In this case, a list of unallocated VMs is searched and allocation to PM is done through a heuristic technique.
6. Conclusions
VMC was proposed as one of the ways of effectively solving the power consumption problem of data centers, which is expected to intensify in the future. The power savings of running servers through VMC could reduce the power costs of the servers and reduce the heat, leading to a direct cooling effect in data centers. In addition, PM is a consumable with a persisting period, so the introduction and disposal of equipment should be periodically reviewed from the perspective of operating a data center. If the number of servers required for annual operation can be decreased through VMC, the cost of introducing servers as well as the software licenses installed on servers can be reduced as well. This, in turn, can indirectly reduce the data center operating costs.
In general, a virtualization environment consists of 5 to 20 VMs in one PM. In a data center, tens or hundreds of PMs are managed at the same time. In terms of VMs, a general optimization problem will become a large-scale problem. The size of data centers is expected to increase in the future, and single cloud environments are shifting to multi-hybrid cloud environments. However, due to conservative management that emphasizes stability only, inefficient operation still continues. Management points are too extensive to rely on the intuition of administrators to operate complex data centers, and this can cause human errors. For efficient data center management, managers should move beyond conservative management and examine technologies that contribute to efficient operation. Forward, it is necessary to pursue data center automation and manualization by developing an integrated intelligent cloud management platform using artificial intelligence and big data analysis technology.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}