Energy Performance Certificates and Its Capitalization in Housing Values in Sweden


Abstract
1. Introduction
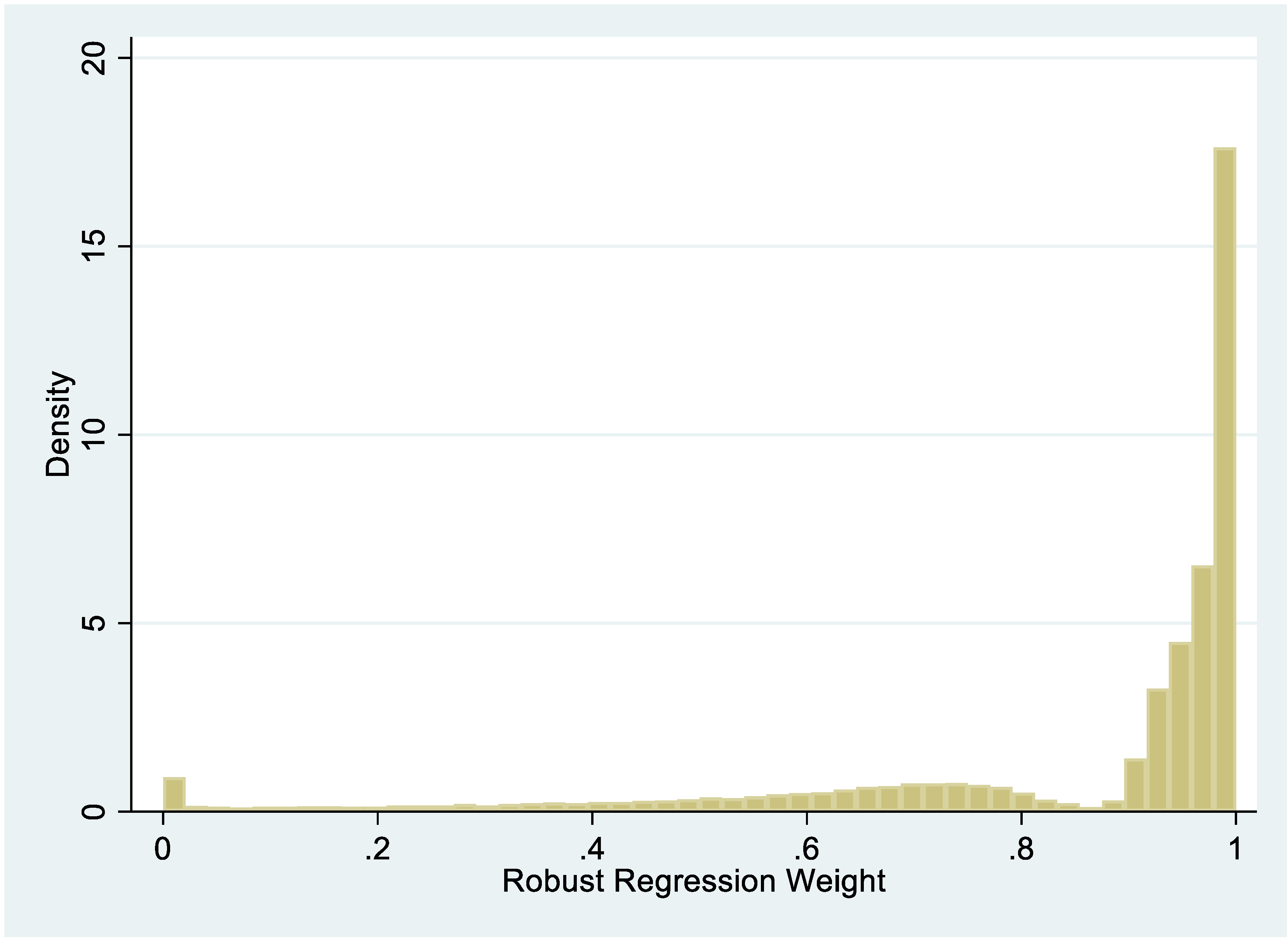
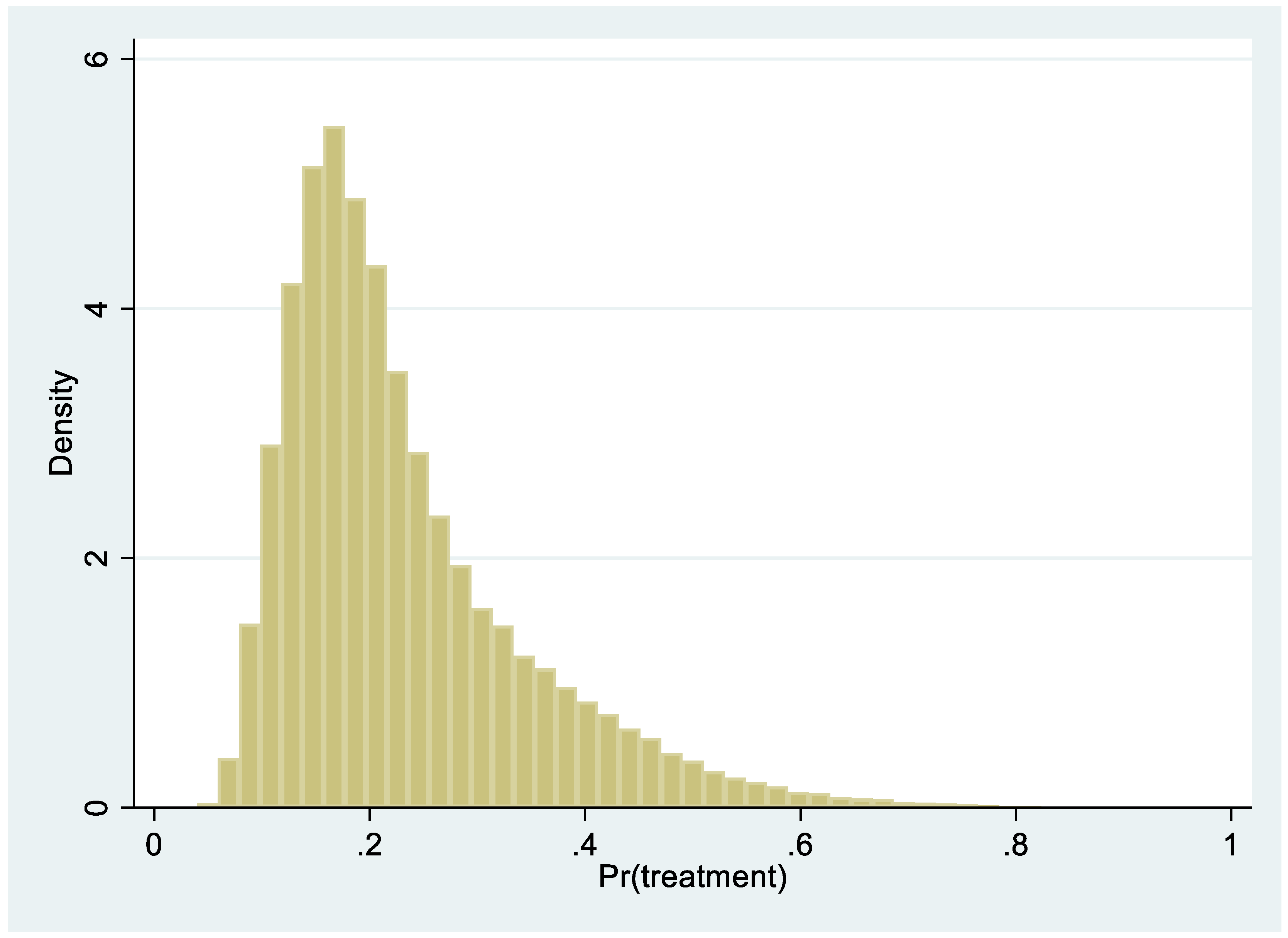
2. Methodology
3. Empirical Analysis
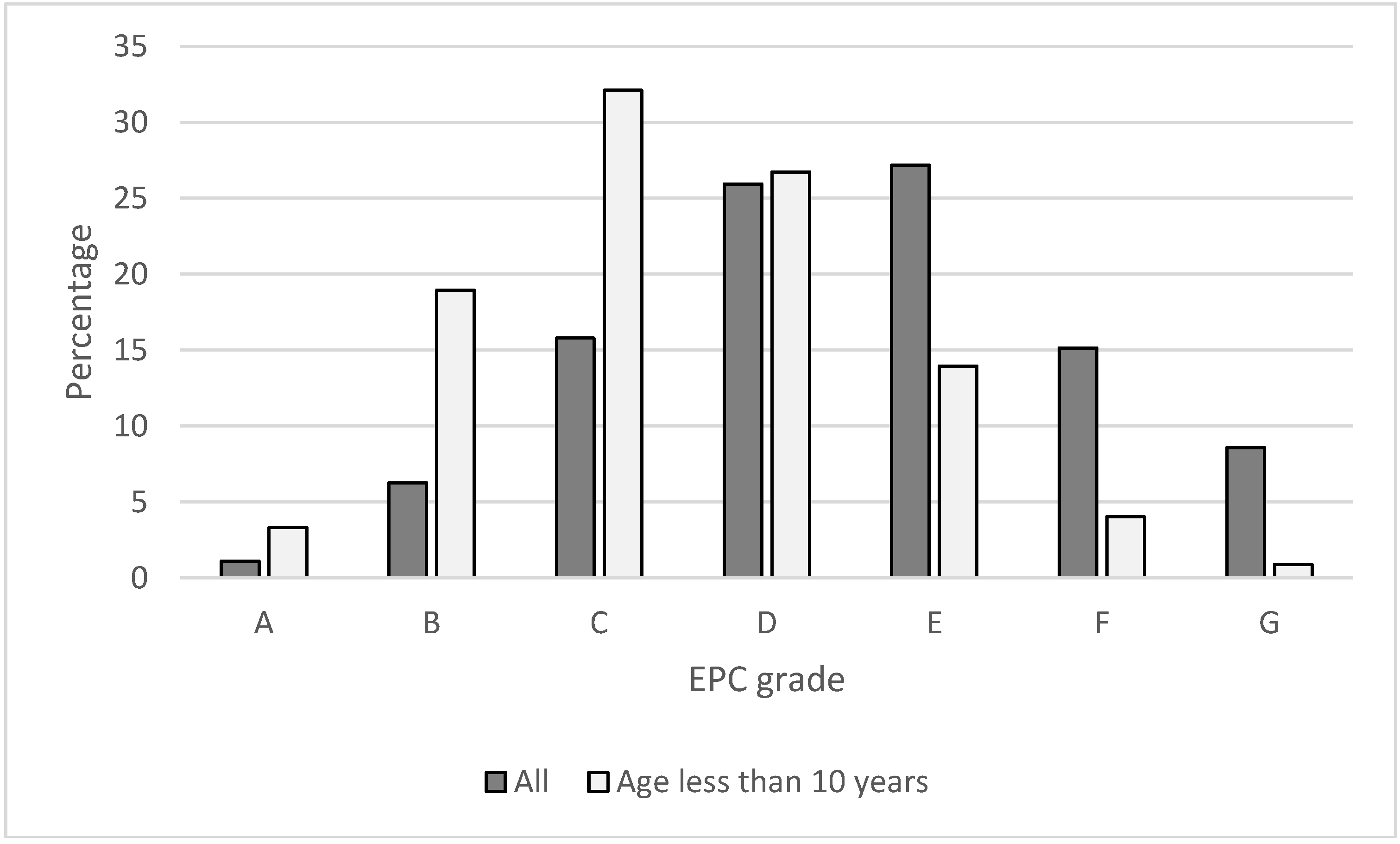
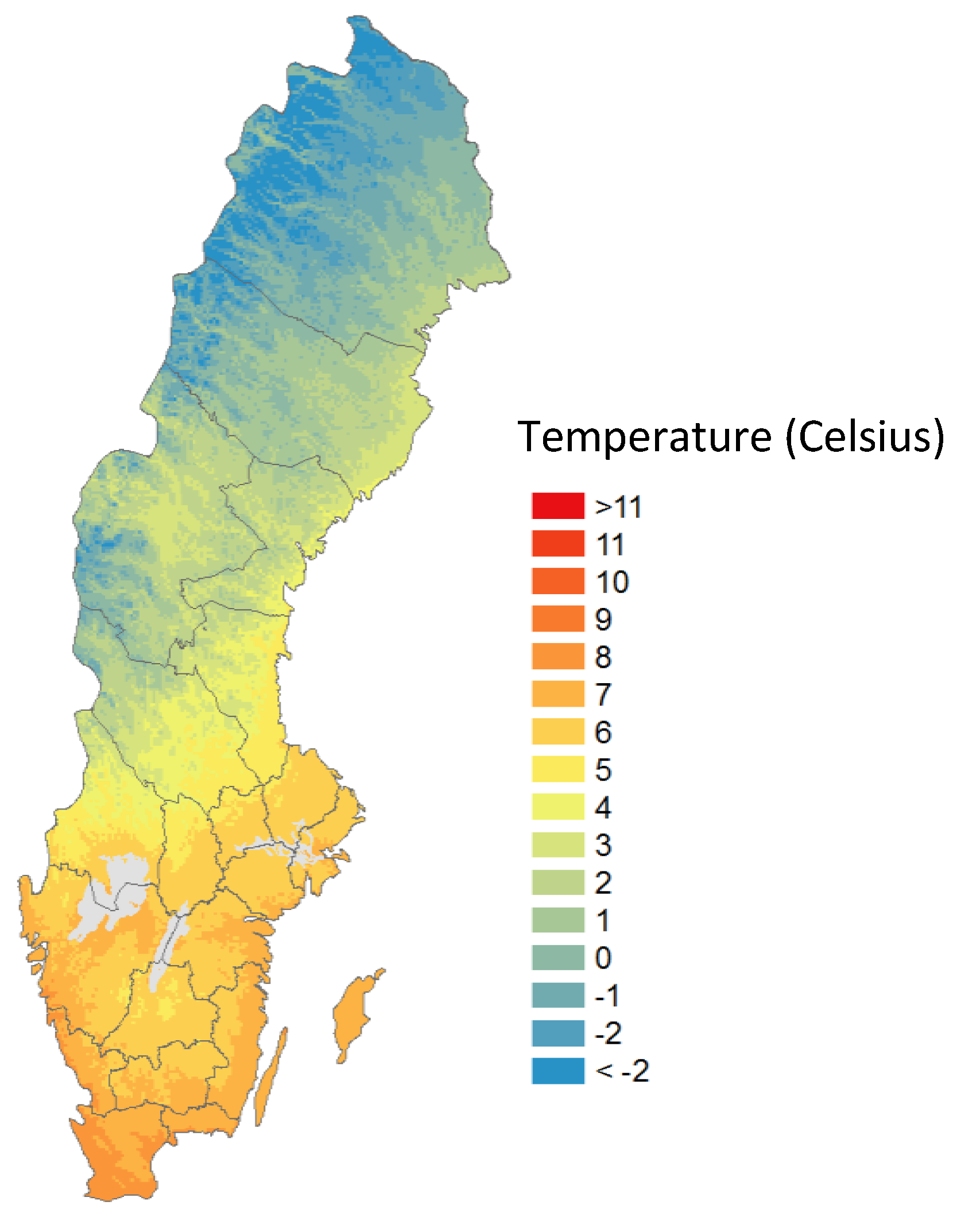
Data
4. Discussion and Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Energy consumption and use by households. Available online: https://ec.europa.eu/eurostat/web/products-eurostat-news/-/DDN-20190620-1 (accessed on 29 October 2019).
- Takano, A.; Pal, S.K.; Kuittinen, M.; Kari Alanne, K. Life cycle energy balance of residential buildings: A case study on hypothetical building models in Finland. Energy Build. 2015, 105, 154–164. [Google Scholar] [CrossRef]
- ECOFYS. Prices and Costs of EU Energy, the European Commission; Directorate-General for Energy: Brussels, Belgium, 2016.
- Arcipowska, A.; Anagnostopoulos, F.; Mariottini, F.; Kunkel, S. Energy Performance Certificate across the EU; Buildings Performance Institute Europe (BPIE): Brussels, Belgium, 2014. [Google Scholar]
- Mangold, M.; Österbring, M.; Wallbaum, H. Handling data uncertainties when using Swedish energy performance certificate data to describe energy usage in the building stock. Energy Build. 2015, 102, 328–336. [Google Scholar] [CrossRef]
- Amecke, H. The impact of energy performance certificate: A survey of German homeowners. Energy Policy 2012, 46, 4–14. [Google Scholar] [CrossRef]
- Hårsman, B.; Daghbashyan, Z.; Chaudhary, P. On the quality and impact of residential energy performance certificates. Energy Build. 2016, 33, 711–723. [Google Scholar] [CrossRef]
- Jensen, O.M.; Hansen, A.R.; Kragh, J. Market response to the public display of energy performance rating at property sales. Energy Policy 2016, 93, 229–235. [Google Scholar] [CrossRef]
- Fuerst, F.; McAllister, P.; Nanda, A.; Wyatt, P. Energy performance ratings and house prices in Wales: An empirical study. Energy Policy 2016, 92, 20–33. [Google Scholar] [CrossRef]
- Wahlström, M. Doing good but not that well? A dilemma for energy conserving homeowners. Energy Econ. 2016, 60, 197–205. [Google Scholar] [CrossRef]
- De Ayala, A.; Galarraga, I.; Spadaro, J.V. The price of energy efficiency in the Spanish housing market. Energy Policy 2016, 94, 16–24. [Google Scholar] [CrossRef]
- Hyland, M.; Lyons, R.C.; Lyons, S. The value of domestic building energy efficiency-evidence from Ireland. Energy Econ. 2013, 40, 943–952. [Google Scholar] [CrossRef]
- Högberg, L. The impact of energy performance on single-family home selling prices in Sweden. J. Eur. Real Estate Res. 2013, 6, 242–261. [Google Scholar] [CrossRef]
- Cerin, P.; Hassel, L.G.; Semenova, N. Energy performance and housing prices. Sustain. Devel. 2014, 22, 404–419. [Google Scholar] [CrossRef]
- Fuerst, F.; Oikarinen, E.; Harjunen, O. Green signaling effects in the markets for energy-efficient residential buildings. Appl. Energy 2016, 180, 560–571. [Google Scholar] [CrossRef]
- Bruegge, C.; Carrión-Flores, C.; Pope, J.C. Does the housing market value energy efficient homes? Evidence from the energy star program. Region. Sci. Urban Econ. 2016, 57, 63–76. [Google Scholar] [CrossRef]
- Zhang, L. Flood hazards impact on neighborhood house prices: A spatial quantile regression analysis. Region. Sci. Urban Econ. 2016, 60, 12–19. [Google Scholar] [CrossRef]
- Rosen, S. Hedonic Prices and Implicit Markets: Product Differentiation in Pure Competition. J. Political Econ. 1974, 82, 34–55. [Google Scholar] [CrossRef]
- Schumacker, R.E.; Monahan, M.P.; Mount, R.E. A comparison of OLS and robust regr4ession using S-PLUS. Mult. Linear Regres. Viewp. 2002, 28, 10–13. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; Wiley Interscience: New York, NY, USA, 1987. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Beaton, A.E.; Tukey, J.W. The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data. Technometrics 1974, 16, 147–185. [Google Scholar] [CrossRef]
- Berk, R.A. A primer on robust regression. In Modern Methods of Data Analysis; Fox, J., Long, J.S., Eds.; Sage: Newbury Park, CA, USA, 1990; pp. 292–324. [Google Scholar]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score on observational studies for causal effects. Biometrica 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Jauregui, A.; Tidwell, A.; Hite, D. Sample Selection Approaches to Estimating House Price Cash Differentials. J. Real Estate Financ. Econ. 2015, 54, 117–137. [Google Scholar] [CrossRef]
- Andersen, S.; Nielsen, K.M. Fire Sales and House Prices: Evidence from Estate Sales Due to Sudden Death. Manag. Sci. 2017, 63, 201–212. [Google Scholar] [CrossRef]
- Austin, P.C. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Mult. Behav. Res. 2011, 46, 399–424. [Google Scholar] [CrossRef] [PubMed]
- Reichardt, A. Operating Expenses and the Rent Premium of Energy Star and LEED Certified Buildings in the Central and Eastern U.S. J. Real Estate Financ. Econ. 2013, 49, 413–433. [Google Scholar]
- Hirano, K.; Imbens, G.W.; Ridder, G. Efficient estimation of average treatment effects using the estimated propensity score. Econometrica 2003, 71, 1161–1189. [Google Scholar] [CrossRef]
- Ding, L.; Quercia, R.Q.; Li, W.; Ratcliffe, J. Risky Borrowers or risky mortgage disaggregating effects using propensity score models. J. Real Estate Res. 2011, 33, 245–277. [Google Scholar]
- Holupka, S.; Newman, S.J. The Effects of Homeownership on Children’s Outcomes: Real Effects or Self-Selection? Real Estate Econ. 2012, 40, 566–602. [Google Scholar] [CrossRef]
- Liu, Y.; Gallimore, P.; Wiley, J.W. Nonlocal Office Investors: Anchored by their Markets and Impaired by their Distance. J. Real Estate Financ. Econ. 2012, 50, 129–149. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- McMillen, D. Changes in the distribution of house prices over time: Structural characteristics, neighborhood, or coefficients? J. Urban Econ. 2008, 64, 573–589. [Google Scholar] [CrossRef]
- Ceccato, V.; Wilhelmsson, M. Crime and its impact on apartment prices: evidence from Stockholm, Sweden. Geogr. Ann. Ser. B 2011, 93, 81–103. [Google Scholar] [CrossRef]
- Liao, W.-C.; Wang, X. Hedonic house prices and spatial quantile regression. J. Hous. Econ. 2012, 21, 16–27. [Google Scholar] [CrossRef]
- Zahirovich-Herbert, V.; Gibler, K.M. The effect of new residential construction on housing prices. J. Hous. Econ. 2014, 26, 1–18. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, X. Effectiveness of macro-regulation policies on housing prices: A spatial quantile regression approach. Hous. Theory Soc. 2016, 33, 23–40. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Y.; Stephenson, R.; Ashuri, B. Valuation of energy efficient certificates in buildings. Energy Build. 2018, 158, 1226–1240. [Google Scholar] [CrossRef]
- Amédée-Manesme, C.-O.; Baroni, M.; Barthélémy, F.; des Rosiers, F. Market heterogeneity and the determinants of Paris apartment prices: A quantile regression approach. Urban Stud. 2017, 54, 3260–3280. [Google Scholar] [CrossRef]
- Waltl, S. Variation across price segments and locations: A comprehensive quantile regression analysis of the Sydney housing market. Real Estate Econ. 2019, 47, 723–756. [Google Scholar] [CrossRef]
- Rajapaksa, D.; Wilson, C.; Hoang, V.-N.; Lee, B.; Managi, S. Who responds more to environmental amenities and dis-amenities? Land Use Policy 2017, 62, 151–158. [Google Scholar] [CrossRef]
- Yoo, J.; Frederick, T. The varying impact of land subsidence and earth fissures on residential property values in Maricopa County—A quantile regression approach. Int. J. Urban Sci. 2017, 21, 204–216. [Google Scholar] [CrossRef]
- Zietz, J.; Zietz, E.N.; Sirmans, G.S. Determinants of house prices: A quantile regression approach. J. Real Estate Financ. Econ. 2008, 37, 317–333. [Google Scholar] [CrossRef]
- Becker, S.O.; Ichino, A. Estimation of average treatment effects based on propensity scores. Stata J. 2002, 4, 358–377. [Google Scholar] [CrossRef]
- Wilhelmsson, M. Spatial models in real estate economics. Hous. Theory Soc. 2002, 19, 92–101. [Google Scholar] [CrossRef]
- Elhorst, J.P. Applied Spatial Econometrics. Spat. Econ. Anal. 2010, 5, 9–28. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Treatment | Control | Total | |
|---|---|---|---|
| Price (SEK) | 3,257,628 | 3,133,500 | 3,162,818 |
| (2,088,475) | (2,104,361) | (2,101,268) | |
| Living area (Square meter) | 140 | 130 | 132 |
| (43) | (44) | (44) | |
| Number of rooms | 5.50 | 5.15 | 5.23 |
| (1.42) | (1.49) | (1.48) | |
| Age(years) | 45 | 52 | 51 |
| (28) | (27) | (28) | |
| Plot size (square meter) | 2358 | 2199 | 2237 |
| (20,008) | (16,743) | (17,569) | |
| Year-month | 2015-06 | 2016-06 | 2015-22 |
| (126) | (128) | (128) | |
| Latitude | 58.10 | 59.10 | 58.64 |
| (2.42) | (2.42) | (2.23) | |
| Longitude | 15.44 | 15.23 | 15.28 |
| (2.70) | (2.56) | (2.59) | |
| Number of observations | 19,550 | 63,224 | 82,774 |
| Nearest Neighbor | Within Radius | |||
|---|---|---|---|---|
| Treated | Control | Treated | Control | |
| Age (years) | 45.94 | 49.17 | 51.85 | 51.20 |
| (27.71) | (27.60) | (24.42) | (26.92) | |
| Living area (square meters) | 139.84 | 134.51 | 132.60 | 131.43 |
| (42.42) | (41.16) | (36.72) | (37.50) | |
| Plot size (square meters) | 2271.13 | 2185.66 | 2216.00 | 2104.97 |
| (19,562) | (15,091) | (18,353) | (15,982) | |
| Number of rooms | 5.50 | 5.32 | 5.32 | 5.23 |
| (1.42) | (1.44) | (1.30) | (1.34) | |
| Year-month | 2015-12 | 2015-12 | 2015-12 | 2015-12 |
| (137.09) | (133.27) | (128.29) | (129.80) | |
| Latitude | 59.11 | 58.77 | 58.54 | 58.54 |
| (2.42) | (2.24) | (2.06) | (2.07) | |
| Longitude | 15.43 | 15.33 | 15.16 | 15.21 |
| (2.70) | (2.64) | (2.57) | (2.59) | |
| Price (SEK) | 3,241,247 | 3,245,903 | 3,158,499 | 3,217,498 |
| (2,047,234) | (2,128,380) | (1,998,327) | (2,111,472) | |
| Number of observations | 18,774 | 10,814 | 9312 | 7658 |
| Default | Multivariate (1) | Multivariate (2) | Matched (1) | Matched (2) | Stratified | |
|---|---|---|---|---|---|---|
| EPC | 0.0514 | 0.0368 | 0.0410 | 0.0331 | 0.0356 | 0.0371 |
| (17.66) | (16.72) | (17.19) | (10.29) | (8.76) | (16.91) | |
| Ln(Living area) | 0.5925 | 0.5502 | 0.5603 | 0.5763 | 0.5445 | 0.5282 |
| (108.75) | (116.06) | (76.83) | (76.81) | (54.50) | (96.42) | |
| Number of rooms | 0.0359 | 0.0243 | 0.0431 | 0.0398 | 0.0444 | 0.0303 |
| (32.41) | (22.62) | (23.50) | (26.99) | (21.69) | (22.72) | |
| Plot size | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| (24.53 | (26.46) | (7.48) | (16.40) | (10.45) | (26.80) | |
| Ln(Age) | −0.0998 | −0.0404 | −0.0801 | −0.0879 | −0.0817 | −0.0472 |
| (−56.05) | (−12.43) | (−46.58) | (−45.20) | (−21.52) | (−12.35) | |
| Propensity score | - | 0.5042 | - | - | - | - |
| 16.27 | ||||||
| Constant | 55.4015 | 58.0831 | 71.8171 | 73.3430 | 76.7408 | 76.7566 |
| (47.32) | (46.70) | (45.02) | (43.37) | (31.95) | (73.77) | |
| Fixed strata effect | No | No | No | No | No | Yes |
| Sample weights | No | No | Yes | No | No | No |
| Fixed county and municipality effects | Yes | Yes | Yes | Yes | Yes | Yes |
| Fixed time effects | Yes | Yes | Yes | Yes | Yes | Yes |
| R2 adjusted | 0.7507 | 0.8636 | 0.8653 | 0.8553 | 0.8489 | 0.8581 |
| Shapiro-Francia (p-value) | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | - |
| Breusch-Pagan (p-value) | 0.0000 | 0.0000 | - | 0.0000 | 0.0000 | - |
| VIF (Treatment) | 1.06 | 1.13 | 1.12 | 1.08 | 1.05 | - |
| No. of observations | 99,877 | 80,260 | 80,260 | 29,588 | 16,970 | 80,260 |
| Percentile | Coefficient | t-Value | Impact (%) |
|---|---|---|---|
| 0.9 | 0.0269 | 7.03 | 2.73 |
| 0.8 | 0.0277 | 7.42 | 2.81 |
| 0.7 | 0.0284 | 7.81 | 2.88 |
| 0.6 | 0.0290 | 8.15 | 2.94 |
| 0.5 | 0.0270 | 7.31 | 2.74 |
| 0.4 | 0.0266 | 7.10 | 2.70 |
| 0.3 | 0.0277 | 7.20 | 2.81 |
| 0.2 | 0.0285 | 7.25 | 2.89 |
| 0.1 | 0.0259 | 5.37 | 2.62 |
| SEM | SAR | SDM | ||||
|---|---|---|---|---|---|---|
| W1 | W2 | W1 | W2 | W1 | W2 | |
| EPC | 0.0342 | 0.0342 | 0.0337 | 0.0340 | 0.0340 | 0.0343 |
| (5.43) | (5.43) | (5.35) | (5.39) | (5.39) | (5.43) | |
| Ln(Age) | −0.0844 | −0.0844 | −0.0837 | −0.0837 | −0.0847 | −0.0849 |
| (−14.33) | (−14.34) | (−14.23) | (−14.22) | (−14.32) | (−14.35) | |
| Ln(Living area) | 0.5460 | 0.5460 | 0.5474 | 0.5473 | 0.5470 | 0.5472 |
| (35.08) | (35.08) | (35.18) | (35.18) | (35.15) | (35.16) | |
| No. of rooms | 0.0453 | 0.0453 | 0.0453 | 0.0453 | 0.0451 | 0.0452 |
| (14.33) | (14.33) | (14.32) | (14.31) | (14.26) | (14.27) | |
| Plot size | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| (9.41) | (9.41) | (9.37) | (9.36) | (9.22) | (9.07) | |
| Constant | 81.3160 | 81.3747 | 81.45453 | 81.5450 | 81.3110 | 81.4391 |
| (20.81) | (24.69 | (23.06) | (27.49) | (19.70) | (23.43) | |
| Rho | −0.0009 | −0.0030 | ||||
| (−0.24) | (−0.79) | |||||
| Lamda | 0.7491 | 0.7087 | ||||
| (6.26) | (6.57) | |||||
| Fixed time effect | Yes | Yes | Yes | Yes | Yes | Yes |
| Fixed county effect | Yes | Yes | Yes | Yes | Yes | Yes |
| Fixed municipality effect | Yes | Yes | Yes | Yes | Yes | Yes |
| Wald test (p-value) | 0.0000 | 0.0000 | 0.8134 | 0.4271 | 0.0000 | 0.0000 |
| Pseudo R2 | 0.8290 | 0.8290 | 0.8290 | 0.8428 | 0.8294 | 0.8293 |
| Interaction | South | North | Stratified | |
|---|---|---|---|---|
| EPC | 0.0316 | 0.0261 | 0.0693 | 0.0347 |
| (9.69) | (7.91) | (7.23) | (15.37) | |
| EPC-north | 0.0208 | - | - | 0.0315 |
| (2.78) | (4.71) | |||
| Ln(Living area) | 0.5758 | 0.5664 | 0.6117 | 0.5277 |
| (76.72) | (72.44) | (28.91) | (96.32) | |
| Number of rooms | 0.0398 | 0.0401 | 0.0366 | 0.03028 |
| (27.01) | (26.29) | (8.63) | (22.73) | |
| Plot size | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| (10.45) | (18.70) | (6.81) | (26.76) | |
| Ln(Age) | −0.0879 | −0.0856 | −0.1105 | −0.0474 |
| (−45.23) | (−43.67) | (−16.62) | (−12.40) | |
| Constant | 75.4048 | 76.5737 | 65.6259 | 76.7954 |
| (43.41) | (38.37) | (16.74) | (73.81) | |
| Fixed strata effect | No | No | No | Yes |
| Fixed county and municipality effects | Yes | Yes | Yes | Yes |
| Fixed time effects | Yes | Yes | Yes | Yes |
| R2 adjusted | 0.8553 | 0.8502 | 0.7878 | 0.8582 |
| No. of observations | 29,588 | 23,995 | 5,633 | 80,253 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wilhelmsson, M. Energy Performance Certificates and Its Capitalization in Housing Values in Sweden. Sustainability 2019, 11, 6101. https://doi.org/10.3390/su11216101
Wilhelmsson M. Energy Performance Certificates and Its Capitalization in Housing Values in Sweden. Sustainability. 2019; 11(21):6101. https://doi.org/10.3390/su11216101
Chicago/Turabian StyleWilhelmsson, Mats. 2019. "Energy Performance Certificates and Its Capitalization in Housing Values in Sweden" Sustainability 11, no. 21: 6101. https://doi.org/10.3390/su11216101
APA StyleWilhelmsson, M. (2019). Energy Performance Certificates and Its Capitalization in Housing Values in Sweden. Sustainability, 11(21), 6101. https://doi.org/10.3390/su11216101