Performance Evaluation of Distance Measurement Methods for Construction Noise Prediction Using Case-Based Reasoning



Abstract
:1. Introduction
2. Preliminary Research
2.1. Literature Review
2.2. Similarity Distance Measurement with CBR
3. Model Development
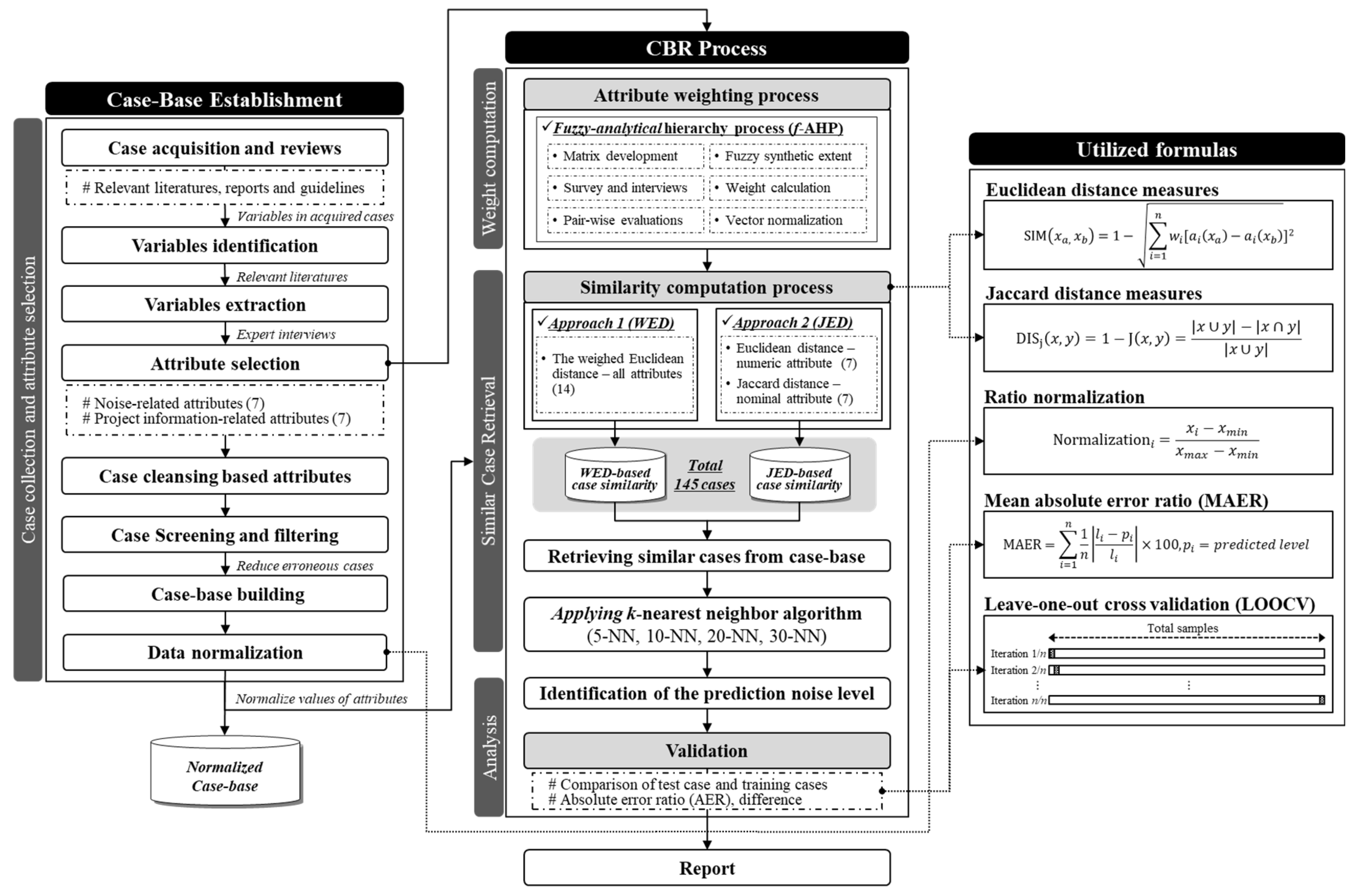
3.1. Establishment of the Case-Base
3.2. Attribute Weighting
3.3. Case Retrieval
4. Experiment
4.1. Experiment Design and Process
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chetoni, M.; Ascari, E.; Bianco, F.; Fredianelli, L.; Licitra, G.; Cori, L. Global noise score indicator for classroom evaluation of acoustic performances in LIFE GIOCONDA project. Noise Mapp. 2016, 3, 157–171. [Google Scholar] [CrossRef]
- Dratva, J.; Phuleria, H.C.; Foraster, M.; Gaspoz, J.M.; Keidel, D.; Künzli, N.; Liu, L.J.; Pons, M.; Zemp, E.; Gerbase, M.W.; et al. Transportation Noise and Blood Pressure in a Population-Based Sample of Adult. Environ. Health Perspect. 2012, 120. [Google Scholar] [CrossRef] [PubMed]
- Gagliardi, P.; Teti, L.; Licitra, G. A statistical evaluation on flight operational characteristics affecting aircraft noise during take-off. Appl. Acoust. 2018, 134, 8–15. [Google Scholar] [CrossRef]
- Minichilli, F.; Gorini, F.; Ascari, E.; Bianchi, F.; Coi, A.; Fredianelli, L.; Licitra, G.; Manzoli, F.; Mezzasalma, F.; Cori, L. Annoyance Judgment and Measurements of Environmental Noise: A Focus on Italian Secondary Schools. Int. J. Environ. Res. Public Health 2018, 15, 208. [Google Scholar] [CrossRef] [PubMed]
- Kwon, N.; Park, M.; Lee, H.S.; Ahn, J.; Shin, M. Construction Noise Management Using Active Noise Control Techniques. J. Constr. Eng. Manag. 2016, 142, 04016014. [Google Scholar] [CrossRef]
- Middel, H.; Verones, F. Making Marine Noise Pollution Impacts Heard: The Case of Cetaceans in the North Sea within Life Cycle Impact Assessment. Sustainability 2017, 9, 1138. [Google Scholar] [CrossRef]
- Park, T.; Kim, M.; Jang, C.; Choung, T.; Sim, K.A.; Seo, D.; Chang, S.I. The Public Health Impact of Road-Traffic Noise in a Highly-Populated City, Republic of Korea: Annoyance and Sleep Disturbance. Sustainability 2018, 10, 2947. [Google Scholar] [CrossRef]
- Kwon, N.; Song, K.; Lee, H.S.; Kim, J.; Park, M. Construction Noise Risk Assessment Model Focusing on Construction Equipment. J. Constr. Eng. Manag. 2018, 144, 04018034. [Google Scholar] [CrossRef]
- Eom, C.S.; Paek, J.H. Risk index model for minimizing environmental disputes in construction. J. Constr. Eng. Manag. 2009, 135, 34–41. [Google Scholar] [CrossRef]
- Fernández, M.D.; Quintana, S.; Chavarría, N.; Ballesteros, J.A. Noise exposure of workers of the construction sector. J. Appl. Acoust. 2009, 70, 753–760. [Google Scholar] [CrossRef]
- Kim, T.; Lim, H.; Kim, C.W.; Lee, D.; Cho, H.; Kang, K.I. The Accelerated Window Work Method Using Vertical Formwork for Tall Residential Building Construction. Sustainability 2018, 10, 456. [Google Scholar] [CrossRef]
- Ministry of Environment (MOE). Guidance of Noise and Vibration Control under Construction; MOE: Sejong City, Korea, 2006.
- Bunn, F.; Zannin, P.H.T. Assessment of railway noise in an urban setting. Appl. Acoust. 2016, 104, 16–23. [Google Scholar] [CrossRef]
- Çelik, T.; Kamali, S.; Arayici, Y. Social cost in construction projects. Environ. Impact Assess. Rev. 2017, 64, 77–86. [Google Scholar] [CrossRef]
- NECRC (National Environmental Conflict Resolution Commission in Korea). Environmental Dispute Mediation Status Report; NECRC: Seoul, Korea, 2018.
- Harris, C.M. Handbook of Acoustical Measurements and Noise Control; McGraw-Hill: New York, NY, USA, 1991. [Google Scholar]
- Hong, T.; Ji, C.; Park, J.; Leigh, S.; Seo, D. Prediction of environmental costs of construction noise and vibration at the preconstruction phase. J. Manag. Eng. 2014, 31, 04014079. [Google Scholar] [CrossRef]
- Muzet, A. Environmental noise, sleep and health. Sleep Med. Rev. 2007, 11, 135–142. [Google Scholar] [CrossRef] [PubMed]
- Passchier-Vermeer, W.; Passchier, W.F. Noise exposure and public health. J. Environ. Health. Perspect. 2000, 108, 123–131. [Google Scholar]
- Babisch, W.; Beule, B.; Schust, M.; Kersten, N.; Ising, H. Traffic Noise and Risk of Myocardial Infarction. Epidemiology 2005, 16, 33–40. [Google Scholar] [CrossRef]
- Matthews, J.C.; Allouche, E.N.; Sterling, R.L. Social cost impact assessment of pipeline infrastructure projects. Environ. Impact Assess. Rev. 2015, 50, 196–202. [Google Scholar] [CrossRef]
- Kwon, N.; Park, M.; Lee, H.S.; Ahn, J.; Kim, S. Construction Noise Prediction Model Based on Case-Based Reasoning in the Preconstruction Phase. J. Constr. Eng. Manag. 2017, 143, 04017008. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Martin, V. Life Cycle Assessment of Railway Ground-Borne Noise and Vibration Mitigation Methods Using Geo synthetics, Metamaterials and Ground Improvement. Sustainability 2018, 10, 3753. [Google Scholar] [CrossRef]
- Jakovljevic, B.; Paunovic, K.; Belojevic, G. Road-traffic noise and factors influencing noise annoyance in an urban population. Environ. Int. 2009, 35, 552–556. [Google Scholar] [CrossRef]
- Licitra, G.; Fredianelli, L.; Petri, D.; Vigotti, M.A. Annoyance evaluation due to overall railway noise and vibration in Pisa urban areas. Sci. Total Environ. 2016, 568, 1315–1325. [Google Scholar] [CrossRef] [PubMed]
- Licitra, G.; Ascari, E.; Fredianelli, L. Prioritizing Process in Action Plans: A Review of Approaches. Curr. Pollut. Rep. 2017, 3, 151–161. [Google Scholar] [CrossRef]
- Kephalopoulos, S.; Paviotti, M.; Anfosso-Lédée, F.; Maercke, D.V.; Shilton, S.; Jones, N. Advances in the development of common noise assessment methods in Europe: The CNOSSOS-EU framework for strategic environmental noise mapping. Sci. Total Environ. 2014, 482–483, 400–410. [Google Scholar] [CrossRef] [PubMed]
- Ruiz-Padillo, A.; Ruiz, D.P.; Torija, A.J.; Ramos-Ridao, Á. Selection of suitable alternatives to reduce the environmental impact of road traffic noise using a fuzzy multi-criteria decision model. Environ. Impact Assess. 2016, 61, 8–18. [Google Scholar] [CrossRef]
- Iglesias-Merchan, C.; Diaz-Balteiro, L.; Soliño, M. Transportation planning and quiet natural areas preservation: Aircraft overflights noise assessment in a National Park. Transp. Res. D 2015, 41, 1–12. [Google Scholar] [CrossRef]
- Kerr, M.J.; Brosseau, L.; Johnson, C.S. Noise levels of selected construction tasks. AIHA J. 2002, 63, 334–339. [Google Scholar] [CrossRef]
- Neitzel, R.; Seixas, N.S.; Camp, J.; Yost, M. An assessment of occupational noise exposures in four construction trades. J. Am. Ind. Hyg. Assoc. 1999, 60, 807–817. [Google Scholar] [CrossRef] [PubMed]
- Cueto, J.L.; Petrovici, A.M.; Hernández, R.; Fernández, F. Analysis of the Impact of Bus Signal Priority on Urban Noise. Acta Acust. United Acust. 2017, 103, 561–573. [Google Scholar] [CrossRef]
- Gilchrist, A.; Allouche, E.N.; Cowan, D. Prediction and mitigation of construction noise in an urban environment. Can. J. Civ. Eng. 2003, 30, 659–672. [Google Scholar] [CrossRef]
- Morley, D.W.; de Hoogh, K.; Fecht, D.; Fabbri, F.; Bell, M.; Goodman, P.S.; Elliott, P.; Hodgson, S.; Hansell, A.L.; Gulliver, J. International scale implementation of the CNOSSOS-EU road traffic noise prediction model for epidemiological studies. Environ. Pollut. 2015, 206, 332–341. [Google Scholar] [CrossRef]
- Michaud, D.S.; Feder, K.; Keith, S.E.; Voicescu, S.A.; Marro, L.; Than, J.; Guay, M.; Denning, A.; McGuire, D.; Bower, T.; et al. Exposure to wind turbine noise: Perceptual responses and reported health effects. J. Acoust. Soc. Am. 2016, 139, 1443. [Google Scholar] [CrossRef] [PubMed]
- Seo, J.W.; Choi, H.H. Risk-based safety impact assessment methodology for underground construction projects in Korea. J. Constr. Eng. Manag. 2008, 134, 72–81. [Google Scholar] [CrossRef]
- Kwon, N.; Cho, J.; Lee, H.S.; Yoon, I.; Park, M. Compensation Cost Estimation Model for Construction Noise Claims Using Case-Based Reasoning. J. Constr. Eng. Manag. 2019. accepted. [Google Scholar]
- Elliott, S.J.; Nelson, P.A. Active Control of Sound; Academic: New York, NY, USA, 1993. [Google Scholar]
- Casanovas, M.M.; Armengou, J.; Ramos, G. Occupational risk index for assessment of risk in construction work by activity. J. Constr. Eng. Manag. 2013, 140, 04013035. [Google Scholar] [CrossRef]
- Ahn, J.; Park, M.; Lee, H.S.; Ahn, S.J.; Ji, S.H.; Song, K. Covariance effect analysis of similarity measurement methods for early construction cost estimation using case-based reasoning. Autom. Constr. 2017, 81, 254–266. [Google Scholar] [CrossRef]
- Ji, S.H.; Park, M.; Lee, H.S. Case adaptation method of case based reasoning for construction cost estimation in Korea. J. Constr. Eng. Manag. 2012, 138, 43–52. [Google Scholar] [CrossRef]
- Jin, R.; Cho, K.; Hyun, C.; Son, M. MRA-based revised CBR model for cost prediction in the early stage of construction projects. Expert Syst. Appl. 2012, 39, 5214–5222. [Google Scholar] [CrossRef]
- Kim, J.K.; Kim, K. Preliminary Cost Estimation Model Using Case-Based Reasoning and Genetic Algorithms. J. Comput. Civ. Eng. 2010, 24, 499–505. [Google Scholar] [CrossRef]
- Leśniak, A.; Zima, K. Cost Calculation of Construction Projects Including Sustainability Factors Using the Case Based Reasoning (CBR) Method. Sustainability 2018, 10, 1608. [Google Scholar] [CrossRef]
- Ryu, H.G.; Lee, H.S.; Park, M. Construction Planning Method Using Case-Based Reasoning (CONPLA-CBR). J. Comput. Civ. Eng. 2007, 21, 410–422. [Google Scholar] [CrossRef]
- Zhang, Y.; Ding, L.; Love, P.E.D. Planning of deep foundation construction technical specifications using improved case-based reasoning with weighted k-nearest neighbors. J. Comput. Civ. Eng. 2017, 31, 04017029. [Google Scholar] [CrossRef]
- Chua, D.K.H.; Li, D.Z.; Chan, W.T. Case-based reasoning approach in bid decision-making. J. Constr. Eng. Manag. 2001, 127, 35–45. [Google Scholar] [CrossRef]
- Morcous, G.; Rivard, H.; Hanna, A.M. Case-based reasoning system for modeling infrastructure deterioration. J. Comput. Civ. Eng. 2002, 16, 104–114. [Google Scholar] [CrossRef]
- Arditi, D.; Tokdemir, O.B. Comparison of case-based reasoning and artificial neural networks. J. Comput. Civ. Eng. 1999, 13, 162–169. [Google Scholar] [CrossRef]
- Ozorhon, B.; Dikmen, I.; Birgönül, M.T. Case-based reasoning model for international market selection. J. Constr. Eng. Manag. 2006, 132, 940–948. [Google Scholar] [CrossRef]
- Ding, J.; Jia, J.; Jin, C.; Wang, N. An Innovative Method for Project Transaction Mode Design Based on Case-Based Reasoning: A Chinese Case Study. Sustainability 2018, 10, 4127. [Google Scholar] [CrossRef]
- International Society of Parametric Analysts (ISPA). Parametric Estimating Handbook, 4th ed.; ISPA: Vienna, VA, USA, 2008. [Google Scholar]
- Koo, C.; Hong, T.; Hyun, C.; Koo, K. A CBR-based hybrid model for predicting a construction duration and cost based on project characteristics in multi-family housing projects. Can. J. Civ. Eng. 2010, 37, 739–752. [Google Scholar] [CrossRef]
- Aamodt, A.; Plaza, E. Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI Commun. 1994, 7, 39–59. [Google Scholar]
- Watson, I. Applying Case-based Reasoning: Techniques for Enterprise System; Morgan Kaufmann: San Francisco, CA, USA, 1997. [Google Scholar]
- Doğan, S.Z.; Arditi, D.; Günaydin, H.M. Determining Attribute Weights in a CBR Model for Early Cost Prediction of Structural Systems. J. Constr. Eng. Manag. 2006, 132, 1092–1098. [Google Scholar] [CrossRef]
- Du, J.; Bormann, J. Improved similarity measure in case-based reasoning with global sensitivity analysis: An example of construction quantity estimating. J. Comput. Civ. Eng. 2014, 28, 04014020. [Google Scholar] [CrossRef]
- Torija, A.J.; Ruiz, D.P. A general procedure to generate models for urban environmental-noise pollution using feature selection and machine learning methods. Sci. Total Environ. 2015, 505, 680–693. [Google Scholar] [CrossRef] [PubMed]
- Richter, M.M.; Weber, R.O. Case-Based Reasoning: A Textbook; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Kim, B.; Hong, T. Revised case-based reasoning model development based on multiple regression analysis for railroad bridge construction. J. Constr. Eng. Manag. 2011, 138, 154–162. [Google Scholar] [CrossRef]
- Pereira, E.; Hermann, U.; Han, S.U.; AbouRizk, S. Case-based reasoning approach for assessing safety performance using safety-related measures. J. Constr. Eng. Manag. 2018, 144, 04018088. [Google Scholar] [CrossRef]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. Miscellaneous Clustering Methods in Cluster Analysis, 5th ed.; John Wiley & Sons: Chichester, UK, 2011. [Google Scholar]
- Ahn, J.; Ji, S.H.; Park, M.; Lee, H.S.; Kim, S.; Suh, S.W. The attribute impact concept: Applications in case-based reasoning and parametric cost estimation. Autom. Constr. 2014, 43, 195–203. [Google Scholar] [CrossRef]
- Salleh, S.S.; Aziz, N.A.A.; Mohamad, D.; Omar, M. Combining Mahalanobis and Jaccard Distance to Overcome Similarity Measurement Constriction on Geometrical Shapes. IJCSI 2012, 9, 124–132. [Google Scholar]
- McLachlan, G.J. Discriminant Analysis and Statistical Pattern Recognition; Wiley & Sons: Hoboken, NJ, USA, 1992. [Google Scholar]
- Pal, S.K.; Shiu, S.C. Foundations of Soft Case-Based Reasoning; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Niwattanakul, S.; Singthongchai, J.; Naenudorn, E.; Wanapu, S. Using of jaccard coefficient for keywords similarity. In Proceedings of the International Multi Conference of Engineers and Computer Scientists, Hong Kong, China, 13–15 March 2013. [Google Scholar]
- Saaty, T.L. How to make a decision: The analytic hierarchy process. Eur. J. Oper. Res. 1990, 48, 9–26. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83–98. [Google Scholar] [CrossRef]
- Al Harbi, K. Application of AHP in project management. Int. J. Proj. Manag. 2001, 19, 19–27. [Google Scholar] [CrossRef]
- Shapira, A.; Goldenberg, M. AHP-based equipment selection model for construction projects. J. Constr. Eng. Manag. 2005, 131, 1263–1273. [Google Scholar] [CrossRef]
- Kaya, T.; Kahraman, C. Multi-criteria renewable energy planning using an integrated fuzzy VIKOR & AHP methodology: The case of Istanbul. Energy 2010, 35, 2517–2527. [Google Scholar]
- Pan, N. Fuzzy AHP approach for selecting the suitable bridge construction method. Autom. Constr. 2008, 17, 958–965. [Google Scholar] [CrossRef]
- Burkhard, H.D. Similarity and distance in case based reasoning. J. Fundam. Inf. 2001, 47, 201–215. [Google Scholar]
- Dattorro, J. Convex Optimization & Euclidean Distance Geometry; Meboo Publishing: Palo Alto, CA, USA, 2008. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Research Objective and Scope | Attribute Weighting | Attribute Types | Consideration of Attributes | Similarity Distance Measurements | Validation |
|---|---|---|---|---|---|---|
| Ahn et al. 2017 | To confirm the estimation accuracy and similarity with case retrieval | GA, HFF | Nominal, numeric | LC | Euclidean distance, Arithmetic summation, Fractional function, Mahalanobis distance | Leave-one-out cross-validation |
| Ding et al. 2018 | To develop a framework for a project transaction mode design based on CBR | AHP | Nominal, numeric | PC | Three-level scoring, Variable interpolation scoring Euclidean distance | Comparison with retrieved cases |
| Doğan et al. 2006 | To compare the accuracy of the optimization techniques | FC, GA, GD | Nominal, numeric | LC | Euclidean distance | Comparison with retrieved cases |
| Du and Bormann 2014 | To improve traditional similarity measures for quantity takeoff based on CBR | SA, ANN | Nominal, numeric | LC | Weighted Mahalanobis distance | K-fold cross-validation |
| Jin et al. 2012 | To improve the cost estimation performance based on CBR | MRA | Numeric | PC | Nearest neighbor matching | Comparison with retrieved cases |
| Kim and Kim (2010) | To propose a CBR-based preliminary cost prediction model using a genetic algorithm | GA | Nominal, numeric | LC | Multiplication of weight and attribute similarity | Comparison with retrieved cases |
| Kwon et al. 2017 | To predict the noise and vibration coming from construction based on CBR | AHP | Numeric | LC | Euclidean distance | Comparison with retrieved cases |
| Kwon et al. 2019 | To estimate a compensation cost related to noise based on CBR | Fuzzy-AHP | Numeric | LC | Euclidean distance | Comparison with retrieved cases |
| Leśniak and Zima (2018) | To estimate a cost considering environmental impact of the building based on CBR | MRA | Nominal, numeric | PC | Fuzzy-based local similarity | Comparison with retrieved cases |
| Ryu et al. 2007 | To develop a construction planning system based on CBR | Interviews | Nominal, numeric | LC | Nearest neighbor matching | Comparison with retrieved cases |
| Zhang et al. 2017 | To propose a framework for searching the optimal process for deep foundation construction | AHP | Nominal, numeric | LC | Minkowski distance | K-fold cross-validation |
| Data Type | Attribute | Attribute Type | Measurement Scale | Attribute Weight |
|---|---|---|---|---|
| Project-related general data | Project duration (day) | Numeric | Real number | 0.0702 |
| Site area (m2) | Numeric | Real number | 0.057 | |
| Gross area (m2) | Numeric | Real number | 0.0561 | |
| Number of floors | Numeric | Integer | 0.0615 | |
| Working days (day) | Numeric | Real number | 0.0983 | |
| Distance with neighbors (m) | Numeric | Real number | 0.1117 | |
| Height of noise barrier (m) | Numeric | Real number | 0.0873 | |
| Nose-related data | Excavator | Nominal | Yes or No | 0.0536 |
| Dump truck | Nominal | Yes or No | 0.0497 | |
| Auger | Nominal | Yes or No | 0.0684 | |
| Pump car | Nominal | Yes or No | 0.0646 | |
| Concrete mixer | Nominal | Yes or No | 0.0499 | |
| Breaker | Nominal | Yes or No | 0.0948 | |
| crusher | Nominal | Yes or No | 0.0767 |
| Case Number | Building Type | Project-Related Information (PI) | Noise-Related Information (NI) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PI1 | PI2 | PI3 | PI4 | PI5 | PI6 | PI7 | NI1 | NI2 | NI3 | NI4 | NI5 | NI6 | NI7 | ||
| 1 | Apartment | 914 | 35,357 | 94,863 | 27 | 641 | 6 | 60 | – | – | – | – | – | – | - |
| 2 | Apartment | 550 | 779 | 8226 | 22 | 425 | 3 | 1.6 | – | – | - | – | – | - | - |
| 3 | Hospital | 291 | 893 | 2394 | 9 | 236 | 6 | 2 | – | – | – | – | – | - | - |
| 4 | Apartment | 1338 | 77,256 | 210,399 | 30 | 233 | 6 | 10 | – | – | – | – | – | – | – |
| 5 | Apartment | 945 | 125,366 | 341,038 | 37 | 313 | 4.5 | 23 | – | – | – | – | – | – | - |
| 6 | Commercial | 202 | 820 | 1958 | 4 | 202 | 6 | 4 | – | – | - | – | – | – | - |
| 7 | Multi-family housing | 222 | 887 | 2218 | 5 | 210 | 2 | 1.5 | – | – | - | – | – | - | - |
| 8 | Church | 277 | 1196 | 2992 | 7 | 87 | 6 | 4 | – | – | – | – | – | - | - |
| 9 | Multi-family housing | 117 | 327 | 651 | 5 | 52 | 2 | 3 | – | – | - | – | – | – | - |
| 10 | Office | 670 | 24,591 | 36,886 | 12 | 72 | 4 | 8 | – | – | - | – | – | – | - |
| Case | Euclidean | Jaccard and Euclidean | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | 1-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | |
| 1 | 0.922 | 0.907 | 0.890 | 0.870 | 0.840 | 0.813 | 0.793 | 0.958 | 0.949 | 0.940 | 0.930 | 0.919 | 0.911 | 0.905 |
| 2 | 0.920 | 0.904 | 0.894 | 0.883 | 0.858 | 0.831 | 0.812 | 0.957 | 0.948 | 0.943 | 0.937 | 0.925 | 0.913 | 0.903 |
| 3 | 0.987 | 0.972 | 0.947 | 0.922 | 0.886 | 0.854 | 0.831 | 0.993 | 0.985 | 0.971 | 0.958 | 0.945 | 0.935 | 0.926 |
| 4 | 0.900 | 0.881 | 0.855 | 0.820 | 0.793 | 0.774 | 0.759 | 0.946 | 0.936 | 0.922 | 0.911 | 0.903 | 0.896 | 0.891 |
| 5 | 0.900 | 0.828 | 0.802 | 0.774 | 0.752 | 0.736 | 0.724 | 0.946 | 0.907 | 0.893 | 0.884 | 0.876 | 0.869 | 0.863 |
| 6 | 0.946 | 0.909 | 0.848 | 0.807 | 0.783 | 0.766 | 0.753 | 0.971 | 0.951 | 0.925 | 0.912 | 0.901 | 0.894 | 0.887 |
| 7 | 0.952 | 0.937 | 0.901 | 0.870 | 0.836 | 0.813 | 0.797 | 0.974 | 0.966 | 0.946 | 0.931 | 0.919 | 0.909 | 0.901 |
| 8 | 0.986 | 0.971 | 0.945 | 0.914 | 0.877 | 0.846 | 0.824 | 0.993 | 0.984 | 0.970 | 0.954 | 0.941 | 0.931 | 0.921 |
| 9 | 0.962 | 0.890 | 0.848 | 0.806 | 0.778 | 0.760 | 0.747 | 0.979 | 0.940 | 0.925 | 0.914 | 0.903 | 0.895 | 0.887 |
| 10 | 0.906 | 0.898 | 0.849 | 0.808 | 0.785 | 0.769 | 0.756 | 0.949 | 0.945 | 0.924 | 0.910 | 0.901 | 0.895 | 0.890 |
| Avg. | 0.938 | 0.910 | 0.878 | 0.847 | 0.819 | 0.796 | 0.780 | 0.967 | 0.951 | 0.936 | 0.924 | 0.913 | 0.905 | 0.897 |
| Case | Original | Predicted Noise Level (dBA) | Absolute Error Rate (AER, %) | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Euclidean | Jaccard and Euclidean | Euclidean | Jaccard and Euclidean | ||||||||||||||||||||||
| 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | ||
| 1 | 65.5 | 60.6 | 59.3 | 58.4 | 58.6 | 58.4 | 58.5 | 60.6 | 59.3 | 58.6 | 59.2 | 59.2 | 59.3 | 7.48 | 9.47 | 10.79 | 10.53 | 10.85 | 10.62 | 7.48 | 9.47 | 10.48 | 9.58 | 9.56 | 9.44 |
| 2 | 77.5 | 82.7 | 82.7 | 83.7 | 83.7 | 84.1 | 84.0 | 82.7 | 82.7 | 83.7 | 83.6 | 83.6 | 83.9 | 6.71 | 6.65 | 7.96 | 8.03 | 8.46 | 8.34 | 6.71 | 6.65 | 7.96 | 7.84 | 7.92 | 8.24 |
| 3 | 70.0 | 66.3 | 66.0 | 65.3 | 65.6 | 65.7 | 66.6 | 66.3 | 66.0 | 65.5 | 66.3 | 66.2 | 67.3 | 5.29 | 5.79 | 6.71 | 6.29 | 6.17 | 4.90 | 5.29 | 5.79 | 6.48 | 5.36 | 5.37 | 3.81 |
| 4 | 72.5 | 70.5 | 72.3 | 73.4 | 73.1 | 73.2 | 72.9 | 70.5 | 71.9 | 71.8 | 72.4 | 72.6 | 72.9 | 2.76 | 0.34 | 1.24 | 0.83 | 0.99 | 0.55 | 2.76 | 0.90 | 0.92 | 0.17 | 0.19 | 0.55 |
| 5 | 73.5 | 71.5 | 74.9 | 76.3 | 76.0 | 75.8 | 75.1 | 71.5 | 73.7 | 75.9 | 75.2 | 75.1 | 75.0 | 2.72 | 1.90 | 3.76 | 3.37 | 3.10 | 2.11 | 2.72 | 0.27 | 3.31 | 2.35 | 2.12 | 2.00 |
| 6 | 85.0 | 97.7 | 99.4 | 97.4 | 96.0 | 94.8 | 94.5 | 97.7 | 97.8 | 95.3 | 94.3 | 94.5 | 94.9 | 14.9 | 17.0 | 14.5 | 12.9 | 11.6 | 11.2 | 14.9 | 15.1 | 12.1 | 11.0 | 11.2 | 11.6 |
| 7 | 75.0 | 77.4 | 76.5 | 78.5 | 77.5 | 77.3 | 77.2 | 77.4 | 76.5 | 77.6 | 77.4 | 76.7 | 76.1 | 3.20 | 2.00 | 4.67 | 3.27 | 3.04 | 2.87 | 3.20 | 2.00 | 3.42 | 3.20 | 2.32 | 1.44 |
| 8 | 71.5 | 69.2 | 69.1 | 68.8 | 68.7 | 68.9 | 69.6 | 69.2 | 69.1 | 69.8 | 69.5 | 69.8 | 69.8 | 3.22 | 3.36 | 3.78 | 3.95 | 3.69 | 2.63 | 3.22 | 3.36 | 2.42 | 2.83 | 2.43 | 2.42 |
| 9 | 90.5 | 99.3 | 102.2 | 103.4 | 104.0 | 104.8 | 106.2 | 99.3 | 102.1 | 103.3 | 103.9 | 104.6 | 104.8 | 9.72 | 12.87 | 14.25 | 14.86 | 15.76 | 17.33 | 9.72 | 12.82 | 14.18 | 14.81 | 15.54 | 15.80 |
| 10 | 75.0 | 75.7 | 77.5 | 76.9 | 75.6 | 74.4 | 74.3 | 75.7 | 75.7 | 75.6 | 74.8 | 74.7 | 74.8 | 0.93 | 3.38 | 2.47 | 0.79 | 0.78 | 0.99 | 0.93 | 0.91 | 0.83 | 0.24 | 0.38 | 0.27 |
| Mean Absolute Error Ratio (MAER) | 5.70 | 6.27 | 7.02 | 6.49 | 6.44 | 6.16 | 5.70 | 5.72 | 6.21 | 5.74 | 5.71 | 5.56 | |||||||||||||
| Distance Measurement Method | 1-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN |
|---|---|---|---|---|---|---|---|
| Weighted Euclidean distance (WED) | 0.9247 | 0.8949 | 0.8689 | 0.8421 | 0.8174 | 0.7967 | 0.7799 |
| Jaccard and Euclidean distance (JED) | 0.9592 | 0.9417 | 0.9280 | 0.9166 | 0.9069 | 0.8986 | 0.8914 |
| Average | 0.9420 | 0.9183 | 0.8985 | 0.8793 | 0.8622 | 0.8476 | 0.8357 |
| Distance Measurement | Difference (dBA) | Absolute Error Rate (AER, %) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | 1-NN | 5-NN | 10-NN | 15-NN | 20-NN | 25-NN | 30-NN | |
| Weighted Euclidean distance (WED) | 5.091 | 4.090 | 4.269 | 4.440 | 4.395 | 4.367 | 4.354 | 7.07% | 5.65% | 5.89% | 6.15% | 6.09% | 6.04% | 6.02% |
| Jaccard and Euclidean distance (JED) | 5.091 | 4.101 | 4.221 | 4.340 | 4.289 | 4.321 | 4.313 | 7.07% | 5.67% | 5.83% | 6.01% | 5.95% | 5.99% | 5.97% |
| Variations | 0 | −0.011 | 0.048 | 0.1 | 0.106 | 0.046 | 0.041 | 0.00% | 0.02% | 0.06% | 0.14% | 0.14% | 0.05% | 0.05% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, N.; Lee, J.; Park, M.; Yoon, I.; Ahn, Y. Performance Evaluation of Distance Measurement Methods for Construction Noise Prediction Using Case-Based Reasoning. Sustainability 2019, 11, 871. https://doi.org/10.3390/su11030871
Kwon N, Lee J, Park M, Yoon I, Ahn Y. Performance Evaluation of Distance Measurement Methods for Construction Noise Prediction Using Case-Based Reasoning. Sustainability. 2019; 11(3):871. https://doi.org/10.3390/su11030871
Chicago/Turabian StyleKwon, Nahyun, Joosung Lee, Moonsun Park, Inseok Yoon, and Yonghan Ahn. 2019. "Performance Evaluation of Distance Measurement Methods for Construction Noise Prediction Using Case-Based Reasoning" Sustainability 11, no. 3: 871. https://doi.org/10.3390/su11030871
APA StyleKwon, N., Lee, J., Park, M., Yoon, I., & Ahn, Y. (2019). Performance Evaluation of Distance Measurement Methods for Construction Noise Prediction Using Case-Based Reasoning. Sustainability, 11(3), 871. https://doi.org/10.3390/su11030871