1. Introduction
Agriculture is considered the most vulnerable sector to yearly climate change and variability, with the greatest impact on agricultural production [
1]. Up to 30% yearly variations in the growing season of most commonly grown crops are attributed to meteorological conditions, including changes in precipitation and temperature variables [
2,
3]. Other factors known to affect crop yields include soil conditions [
4], topography (elevation, slope, and aspect) [
5], and socio-economic factors [
6]. Crop modeling plays a significant role in agricultural production. Farmers and other decision makers in agriculture require precise crop yield prediction methods for better planning and decision-making [
7]. In particular, crop yield predictions can assist farmers in deciding on seasonal crop planning and scheduling [
8], as well as determining the possible future outcome of an event.
Yield prediction methods reported in literature include, regression, simulation, expert systems, and artificial neural network (ANN). Regression models have been widely used in various studies particularly for prediction purposes [
9,
10]. These could be attributed to the fact that they are easy to use and often produce reliable standard tests [
11]. The use of regression models is sometimes limited, especially in complex cases like extreme data values and non-linear relationships. Furthermore, regression models might be inefficient because they do not always fulfill the regression assumptions for multiple co-linearity between the dependent and independent variables [
12,
13]. Diversity of interrelated factors influencing crop production makes describing their associations via conventional methods difficult [
13].
An advantage of the simulation method is its potential to specify relevant factors affecting yield. This allows researchers in different fields of interest to use the same sophisticated model based on physical relationships [
14]. However, simulation requires considerable biophysical inputs that sometimes demand estimation instead of measurement. Also, in areas devoid of established sets of parameters, calibration could be quite time-consuming. In addition, expert systems are highly dependent on human expertise and sets of logical rules to characterize yield. However, these logical rules entail extensive communication with the experts and these rules are not readily automated and are highly subjectable and reliant on a certain set of input data [
14].
The use of ANN often resolves the complex relations and strong nonlinearity between crop production and different interrelated predictor parameters. Such methods are easily automated, contain objective mathematical functions rather than subjective rules, display considerable accuracy for new conditions not denoted in the input data, do not involve pre-established physical relationships, and can be generated using readily available data. According to [
15], the ANN are considered to be the best procedures for extracting information from imprecise and non-linear data. ANN techniques have turned out to be a very vital tool for a wide variety of applications across many disciplines, including crop production prediction. Thus, with varying levels of success, they have been used for maize yield prediction based on soil and weather data [
16,
17].
ANNs are computer programs designed to simulate just the way the human brain processes information. In other words, they are the digitized models of the human brain [
18]. The ANN models are characterized by an initiation function, which uses interrelated information processing units to transform input into output. Knowledge is acquired through neural networks by detecting relationships and patterns in data. Raw input data is received by the first layer of the neural network where it is processed and then transferred to the hidden layers. The hidden layer then passes the information to the last layer where the output is produced. ANNs are trained through experience with suitable learning exemplars in like manner to human but not from programming. They learn from given information, with an identified outcome that optimizes its weights for a better prediction in circumstances where there is an unknown outcome.
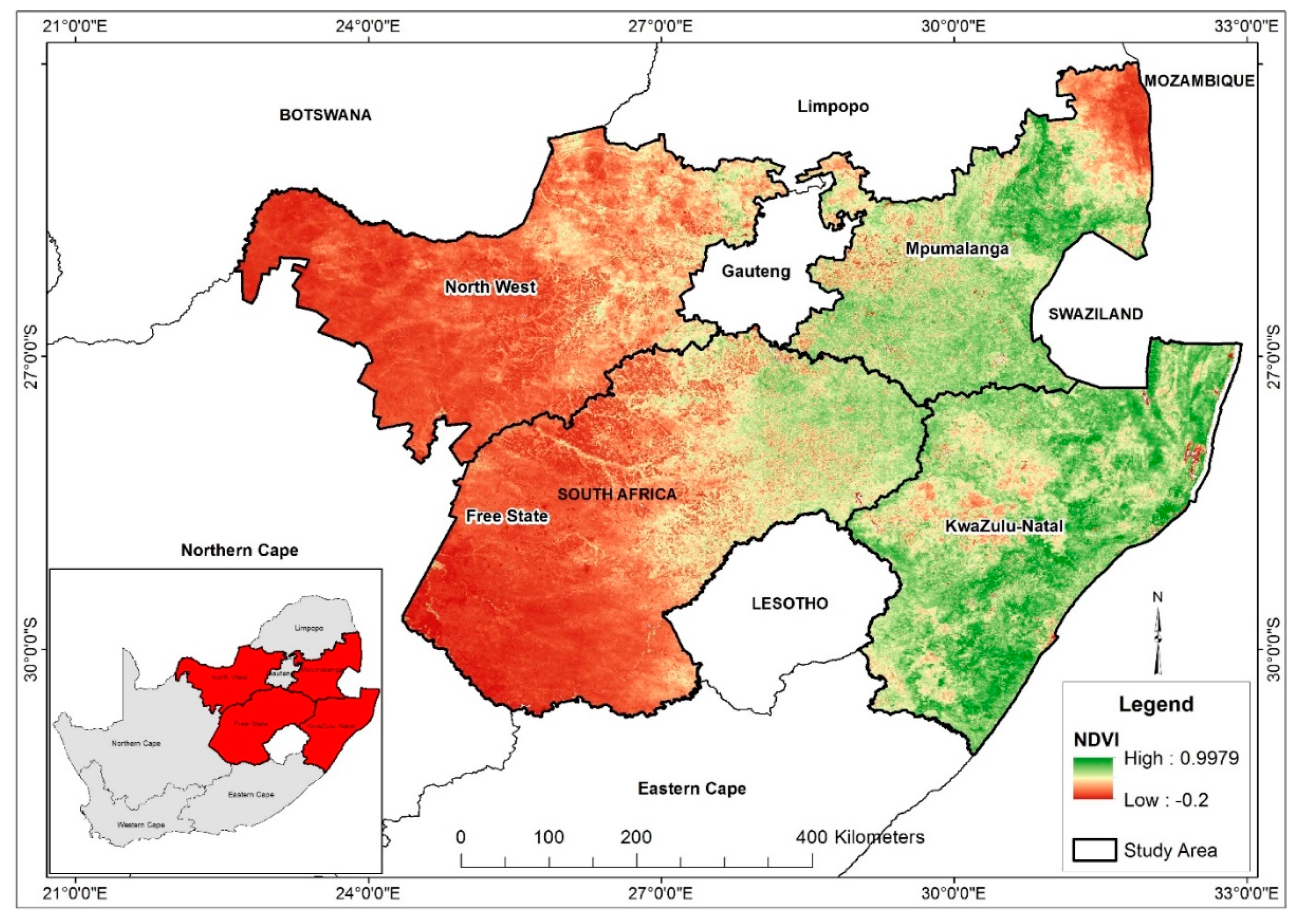
Maize is considered to be the most important grain crop, a staple food for a large proportion of the population and a major input to animal feed in South Africa. In South Africa, maize is produced by both commercial and subsistence farmers and accounts for about 45% of the gross domestic product of the agricultural sector. About 8 million tons of maize grain is produced annually in the country under varying soil, terrain, and climatic conditions. Free State (FS), North West (NW), Mpumalanga (MP) and KwaZulu-Natal (KZN) are the major maize producing provinces in South Africa accounting for about 83% of the total national production. FS and NW provinces both contribute over 60%, followed by MP (~24%) and KZN (less than 5%) [
19].
Furthermore, the Food and Agriculture Organization of the United Nations (FAO) has recently reported maize as the largest grain crop (in metric tons) produced in the world [
20]. Therefore, in order to ensure food security for a rapidly growing population, in the face of climate variability, several studies have been conducted on maize ranging from climate influence on maize to yield predictions. To this end, numerous researchers across the globe have used ANNs to predict maize yield and have proven this method to be reliable. For instance, Maryland’s corn and soybean were predicted by developing a feed-forward back-propagation ANN model using the rainfall and soil properties [
21]. Similarly, [
14] predicted maize yield at three scales in east-central Indiana, USA, with local crop-stage weather and yield data spanning from 1901 to 1996 using a fully connected back-propagation ANN together with regression models. In addition, [
22] developed a feed-forward neural network to estimate the nonlinear relationship between soil parameters and crop yield. The results indicated a relatively high degree of accuracy for crop yield prediction. Furthermore, a study by [
23] in eastern Ontario, Canada, evaluated the predicting power of ANN for corn and soybean yield using remotely sensed variables. The model was found to report an error level below 20% indicating the reliability of the model in predicting corn and soybean yield. Using climate data and fertilizer as predictors, [
24] predicted maize yield in Jilin, China. The authors reported a close similarity between the predicted yield and the observed yield. Despite proven reliability of the application of ANNs to maize yield production, only a few studies have used these models for predicting maize yield in South Africa. Many of the existing studies have relied on the use of crop-based models which are in most cases expensive and data intensive. The aim of this study is to develop an artificial neural network for predicting maize yield in the major maize producing areas of South Africa (FS, NW, MP, and KZN).
3. Results
3.1. Optimizing Combinations of Variable Selection
Owing to the fact that there is no standard method for the selection of variables in the neuron network, it is usually done by testing various variable combinations so as to arrive at the best combination for the model. In this case, as reported by [
29], the major agro-climatic variable that influences maize yield varies across the maize producing areas of South Africa. According to the current study, the TMX is the major determinant in the FS and MP provinces, while the TMN is largely responsible for changes in maize yield in the NW province. Both the PET and TMN are found to be the major drivers of maize yield in KZN. These variables were selected as a baseline for the variable combination check, by holding them constant in all the combinations. Since six variables (i.e., PET, PRE, TMN, TMX, Land and SM) were used in the model, 12 combinations were created for each province except for KZN province, which had just 10 because two climatic variables largely determine its maize yield.
Table 2 illustrate the combination of variables, the hidden neuron, overall error, and accuracy of the best three ranked combinations that best predict maize yield in each of the provinces.
According to
Table 2, in the FS province, the combination of TMX, Land and SM variables at different automated two hidden neurons with vector (8,9) ranked first within this group with 76.64% accuracy and has a root mean squared error (RMSE) of 0.038. The combination of the PET, PRE, TMN, TMX, Land and SM using vector (5,8) resulted in an accuracy of 82.42% and RMSE of 0.037 and ranked first. On the other hand, an accuracy of 82.46% and RMSE of 0.035 was achieved when PRE, TMN, TMX, Land and SM were combined using vector (2,6). Hence, the combination of variables PRE, TMN, TMX, Land and SM with vector (2,6) was chosen to model maize production for the FS province. For the NW province, the combination of only two variables TMN and SM using vector (2,8) gave an accuracy of 69.22% and had RMSE of 0.014. When PRE was added to TMN and SM but with vector (5,6) the accuracy improved to 71.51% with RMSE of 0.014. However, a higher accuracy of 73.74% with RMSE of 0.015 was attained with the variable combination of TMN, Land, and SM with vector (3,4). Considering the combination with the highest accuracy, a variable combination of TMN, Land and SM with vector (3,4) was selected for the model for the NW province.
Furthermore, for MP province, the combination of variables PET and TMX using vector (4,7) gave an accuracy of 88.39% and RMSE of 0.025. The accuracy for a variable combination that better combined to predict maize yield improved to 92.02% when PET, PRE, TMN, TMX and Land were combined. The accuracy further improved to 93.79% with RMSE of 0.024 when variables TMN, TMX, Land and SM were combined using vector (3,4). Consequently, the combination of TMN, TMX, Land and SM with vector (3,4) were selected as the model for MP province. In the case of KZN, the combination of PET, TMN, TMX, Land, and SM with vector (1,8) produced an accuracy of 61.23% and RMSE of 0.0036. When the PET, PRE, TMN and TMX were combined with vector (3,5) an accuracy of 89.39% was achieved. However, the combination of PET, PRE, TMN, TMX, Land, and SM using vector (7,8) gave 93.90% accuracy and RMSE of 0.003 in predicting maize yield in KZN. Therefore, the combination of the PET, PRE, TMN, TMX, Land and SM variables with two hidden neurons of (7,8) was selected for the model for KZN province.
3.2. Generalized Weight of the Variables
Table 3,
Table 4,
Table 5 and
Table 6 show the generalized weight expressing the effect of each independent variable on the dependent variable in the combination. As shown in
Table 3, PRE, TMX and Land have a positive linear effect on maize production for all the trained years in the FS province. This indicates a favorable relationship between PRE, TMX, Land and maize production in the area with variance ranging from 0.01 to 0.42, 0.24 to 7.88 and 0.19 to 5.24 for PRE, TMX and Land, respectively. A negative effect is noticed between SM and maize production with variance ranging from −5.56 to −0.20, suggesting an unfavorable relationship between the two variables. Similarly, there exist both negative (40.91%) and positive (59.09%) effects between TMN and maize production for the trained year. The relationship was negative for years 1991, 1992, 1995, 2003, 2004, 2005, 2009, 2010, and 2011 with its variance ranging from −5.56 to −0.20, suggesting an unfavorable relationship between the two variables in those corresponding years.
The generalized weight for the independent variables for the NW province is shown in
Table 4. Both TMN and Land depict a positive linear effect on maize production in the province with variance ranging from 1.12 to 1.70 and 0.36 to 0.54, respectively. This suggests a favorable relationship between the two independent variables and maize production in the province. On the other hand, SM has a negative linear effect on maize production in the province with the variance ranging from −1.55 to −0.95. This implies an unfavorable relationship between the two variables.
Table 5 depicts the generalized weight for the independent variables in MP province. The TMX depicts a positive linear effect on maize production in the province with its variance ranging from 1.19 to 2.23. This implies that TMX has a favorable relationship with maize production. However, TMN, Land and SM display a negative linear effect on maize production with their variance ranging from −1.03 to −0.25, −0.20 to −0.01 and −54 to −0.38, respectively. Thus, these variables have an unfavorable relationship with maize production in the province.
As depicted in
Table 6, the PET and SM have a negative linear effect on maize production in KZN province with their variance ranging from −6.22 to −1.04 and −5.37 to −1.61, respectively. Therefore, these variables have an unfavorable relationship with maize production in the area. The following variables PRE, TMX, and Land display a positive linear effect on maize production in the province and their variances range from 0.42 to 1.06, 1.95 to 8.76 and 0.76 to 2.95, respectively. The case is different for TMN where 45.45% of this variable has a negative linear effect on maize production in the area as its variance ranges from −1.66 to −0.02. The remaining 54.55% has a positive linear effect on maize production in the province and its variance ranges from 0.13 to approximately 1.81.
3.3. Network Topology
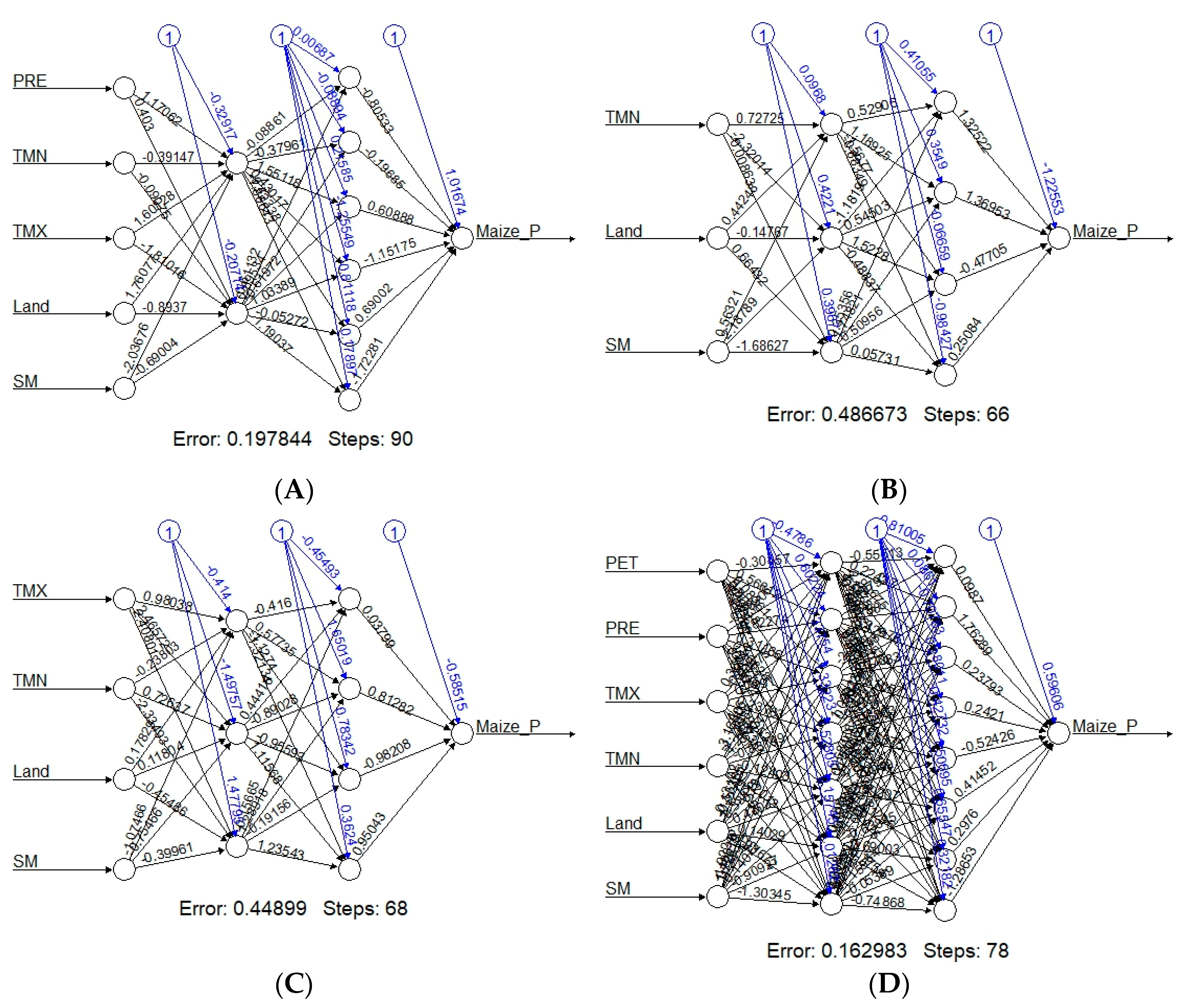
The training process results are illustrated in
Figure 2A–D. The figure reflects the structure of the trained neural network for each province. The network topology conveys basic information such as the trained synaptic weights, the number of steps needed for converge and the overall errors. For the purpose of this study, the threshold for the partial derivatives of the error function was set at 0.01. Each province has its own unique variable combinations as well as hidden neurons (see
Table 2; i.e., the FS province has PRE, TMN, TMX Land and SM with hidden neuron c(2,6); NW province TMN, Land and SM with hidden neuron c(3,4); MP province TMN, TMX, Land, and SM with hidden neuron c(3,4); and KZN province PET, PRE, TMN, TMX, Land and SM with hidden neuron c(7,8).
Figure 2A shows that in the FS province, the training process needed 90 steps to achieve less error function (i.e., < threshold of 0.01). The process has an overall error of about 0.20. In the NW province, according to
Figure 2B, the training process needed 66 steps until all absolute partial derivative of the error function were smaller than 0.01 with the process having an overall error of about 0.49. On the other hand, in MP province (
Figure 2C), the training process needed 68 steps until all absolute partial derivatives of the error function were smaller than the default threshold of 0.01 with the process having an overall error of about 0.45. In KZN (see
Figure 2D) the training process needed 78 steps until all absolute partial derivatives of the error function were smaller than 0.01, and the overall error was 0.16.
3.4. Maize Prediction and Validation
Having trained the neural network with 80% of both the independent and dependent variables, and the best combinations with the hidden neuron selected, the prediction for maize production per province was made for the same time frame (2012–2017) of the testing data (20%). The predicted output was then compared with the reserved 20% that was not used for machine learning. The results are displayed in
Table 7,
Table 8,
Table 9 and
Table 10. The accuracy level of the prediction varies for each province. For instance, the model for the FS province has an adjusted R
2 of 0.75, and NW, MP and KZN provinces have an R
2 of 0.67, 0.86 and 0.82, respectively.
As depicted in
Table 7, the predicted maize production in the FS province deviated from the actual maize production by −0.13 (13%), −0.34 (34%), −0.002 (0.2%), −0.46 (46%) and −0.30 (30%) for years 2012, 2013, 2014, 2016, and 2017, respectively. The results suggest an under-prediction of maize production in the province. On the other hand, 2015 resulted in over-prediction (i.e., 0.26 which is equivalent to 26%) of maize production.
As shown in
Table 8, the predicted maize production for the NW province deviated from the actual maize production by −0.33 (33%), −0.38 (38%), and −0.13 (13%) for 2013, 2016 and 2017 respectively, thus there was under-prediction of maize production. Contrasting this, maize production was over-predicted by 0.04 (4%), 0.23 (23%) and 0.24 (24%) in 2012, 2014 and 2015, respectively.
From
Table 9, maize production is under-predicted for the MP province across the entire testing period by −0.09 (9%), −0.08 (12%), −0.10 (10%), −0.004 (0.4%), −0.20 (20%) and −0.07 (7%) for the years 2012, 2013, 2014, 2015, 2016, and 2017, respectively.
In KZN province according to the results presented in
Table 10, maize production was under-predicted by −0.13 (13%), −0.03 (3%), −0.06 (6%), −0.10 (10%), −0.22 (22%) and −0.10 (10%) in 2012, 2013, 2014, 2015, 2016 and 2017, respectively.
3.5. Maize Production Projection
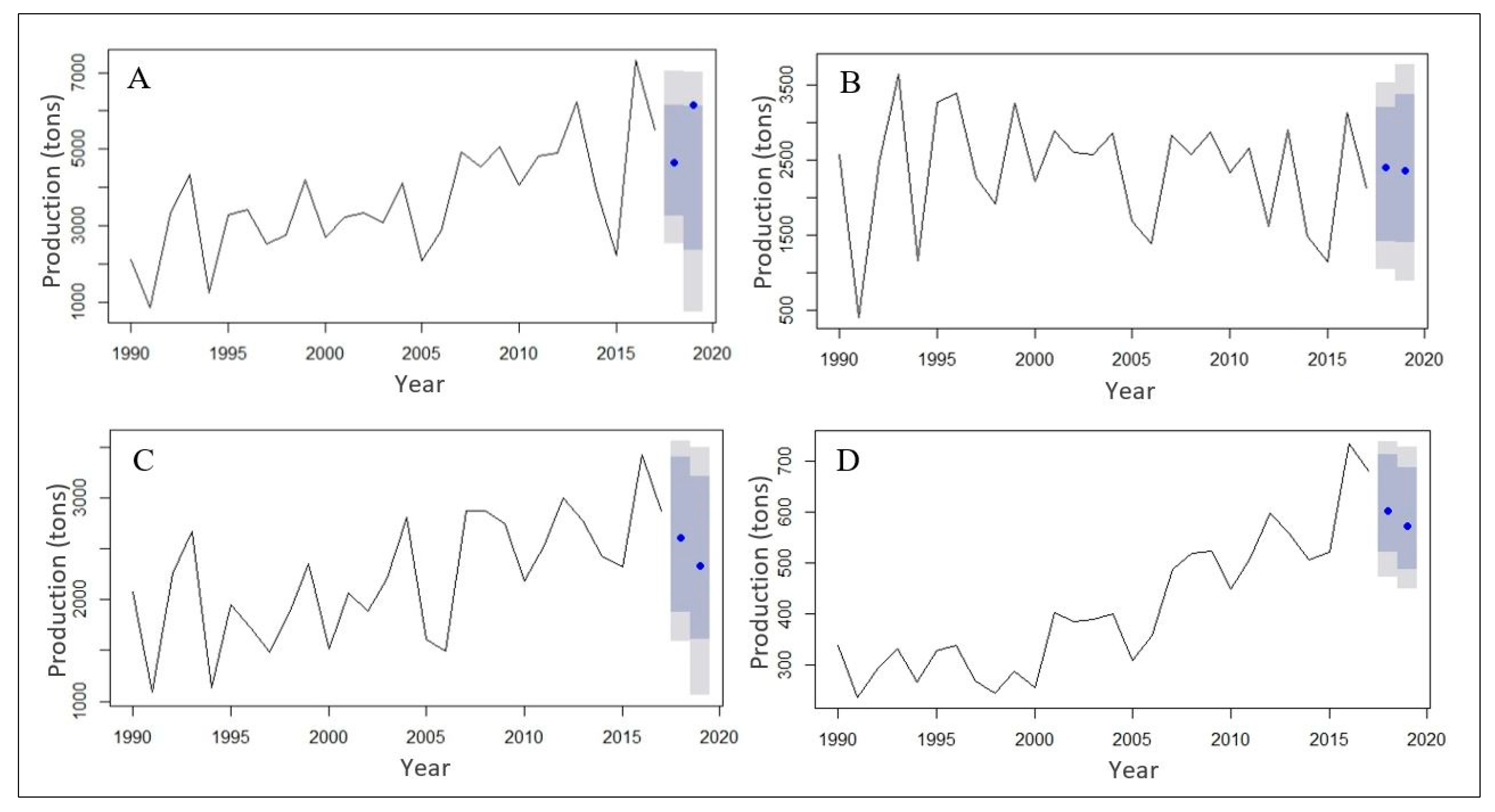
The results of the projected maize production performed with AvNNet() in Caret package across each province for the year 2018 and 2019 is shown in
Figure 3A–D and
Table 11. The results indicate that maize production will decrease across all the provinces (except FS) from the current year 2017 to 2018 and 2019. The FS depicts a 32% increase in maize production, i.e., from 2018 (4651.03 tons) to 2019 (6146.33 tons). In
Figure 3A–D, the dark gray shaded and light gray shaded area is the 80% and 95% prediction confidence interval, respectively.
4. Discussion
In this study, maize production in the FS, NW, MP and KZN provinces of South Africa was modeled based on the ANN approach. The analysis considered various variable combinations and ranked the accuracy of these combinations across the study area. The results indicated spatial dependence of different combinations in different provinces. For instance, the PRE, TMN, TMX, Land and SM with hidden neuron c(2,6) combination were ranked first in the FS province; TMN, Land and SM with hidden neuron c(3,4) in the NW province; TMN, TMX, Land, and SM with hidden neuron c(3,4) in MP and lastly, PET, PRE, TMN, TMX, Land and SM with hidden neuron c(7,8) ranked first in KZN. The three variables, i.e., TMN, Land and SM, seem to dominate in all first ranked levels across all the four provinces.
Maize production in the four selected provinces is highly affected by different agro-climatic parameters, as reported in [
29]. In this study, we found that TMX is the main driver of change in maize yield in the FS and MP, whereas TMN has a dominant impact in the NW. The PET and TMN climate variables dominate in KZN, hence significantly affecting the maize yield in the province. The results indicate that the variables have a linear effect on maize production since their variance was very small. In addition, the influence of TMN on maize production varied in the NW, FS and KZN, having a positive linear effect. However, the TMN in MP exhibited a negative linear effect on maize production. The land has a positive linear effect on maize production across all the provinces except for MP where it has a negative linear effect. Similarly, SM exhibited a negative linear effect on maize production across all the provinces. The TMX displayed a positive linear effect on maize production in the FS, MP and KZN. PRE appeared in the variable combination of just two provinces (FS and KZN) and it has a positive linear effect on maize production in both of these provinces.
The accuracy of the combined variables to predict maize production varied across the provinces. The accuracy was recorded in MP (93.79%) and KZN (93.90%). This accuracy suggests that the TMN, TMX, Land and SM are sufficient for modelling maize production in MP province while PET, PRE, TMN, TMX, Land and SM are ideal for the effective modelling of maize production in KZN. Nevertheless, these results do not extensively mean that other farm management practices such as fertilizer application, irrigation and choice of cultivar are not significant in achieving best output for maize production. They are thought to account for the deviations in the comparison between the actual and predicted maize production. On the other hand, despite the high accuracy of about 82.46% of the combined variables of PRE, TMN, TMX, Land and SM to predict maize production in the FS, a high deviation is noticed between the actual maize production and predicted production particularly in the year 2016 where maize is up by 46%. These results are in contrast with the deviation between actual and predicted maize production in the NW where the selected combination of TMN, Land and SM gave an accuracy of 73.74% but gave a smaller deviation between actual and predicted maize production. This could suggest that the FS province is more prone to the influence of other farm management practices.
The projected maize production indicates that maize production is on the decline across all the provinces. This can be attributed to the future trend of changes in climatic variables as well as a projected increase in drought occurrences [
29,
30].
5. Conclusions
This study demonstrates the value of the artificial neural network in predicting maize yield across the four major maize producing provinces of South Africa. These results agree with the previous research findings [
27]. The results indicate that different climatic variables and/or their combinations serve(s) as major drivers for maize production across the different provinces. The accuracy level of the prediction obtained between the actual and predicted maize production for each province as given by the adjusted R
2 value, with 0.75 in the FS, 0.67 in the NW, 0.86 in MP and 0.82 in KZN. In this study, the adjusted R
2 is used as a measure of future prediction of maize production.
Although the predicted maize production is under-predicted, we conclude that it is better to under-predict than over-predict. This is because an under-prediction will enhance the decision making process of the farmers and/or the policymakers to put in place measures to ensure that loss of production is prevented or minimized, rather than be blinded by expectation of high production. In addition, all the predictions (under-predictions), particularly in MP and KZN, are within 10% of the actual maize production except for the year 2016, in which the production was approximately 20%.
The decline in projected maize production can be attributed to the effects of climate change and variability; hence adequate adaptation and coping measures are needed for both commercial and small-scale farmers to prevent loss of production and aggravated famine.
This research study is essential in South Africa, as food security is threatened by drought due to climate change and variability. The availability of historical and current agro-climatic data combined in a model could serve as a vital decision support system to cope and mitigate climate change. The model is developed to incorporate different farming scenarios such as the combination of agro-climatic parameters with different farming practices to predict maize yield. Hence, this tool can help farmers to make informed choices, which include mitigation and adaptation measures in order to maximize profit on crop production. Furthermore, the model will be operationalized and made available to relevant stakeholders and decision makers such as commercial and small-scale farmers and the Department of Agriculture.
This study can be improved to ensure its operability by incorporating other farm management practices such as fertilizer application that was not available/accessible during the period of undertaking this research. However, the current status of this model can be validated by comparing the projected production of maize with the actual production at the end of the 2018 and 2019 season.

 ,
, 





{kind=link}
{kind=link}
{kind=link}