1. Introduction
Innovation commonly initiates when prevalent problems are accurately identified. For effective innovative endeavors, an innovator must define the currently existing problems and select which of them to prioritize and focus on. Patents are practical sources from which to identify problems to be solved because they possess solutions to specific problems in the form of the most state-of-the-art innovations. Thus, patent analysis is an effective way to identify problems to be solved for sustainable technology development and management. To obtain valuable information from patents, the analysis is generally performed manually by technology domain experts. However, manual analysis requires extensive time and effort. Moreover, in the contexts of identifying problems, a simple bibliographic analysis is not applicable, since problems are described in natural language in the description sections of patents.
Hence, to alleviate the time and labor for manual patent analysis, a plethora of research has dedicated much effort for the advancements of natural language processing methods in the contexts of patents. As a result, various influential and effective methods of computer-assisted patent analysis utilizing natural language processing and text mining have been reported [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17]. The majority of these methods are founded on keyword-based patent analysis, which extracts keywords from the patent descriptions and ascertains patterns with technical significance [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. These keyword-based methods, however, reveal severe limitations in finding exact correlations between the extracted keywords and how the keywords are exactly related to the technologies (i.e., problems to be solved) achieved in patents. Later, to overcome such limitations, grammar-based methods of patent analysis have been proposed [
11,
12,
13,
14,
15,
16,
17]. Compared to the keyword-based analyses, the grammar-based methods are more complex because of the inclusion of syntactic and semantic analysis, which introduces the concept of ‘function’. Here, ‘function’ is defined as the action changing a feature of any object that may provide valid information on the purposes of a technology [
18]. Despite the analysis complexity, the grammar-based methods have rarely considered the identification of problems, which are directly related to the technology innovated in patents. Since patent descriptions encompass heterogeneous sections such as technology field, prior art, existing problems, summary of invention, and components of inventions, each sentence delineates a different purpose and meaning, even within the same section. Thus, identifying the sentences that describe the problems is essential before conducting grammar-based analyses. To extract the problems solved in patents, the ‘problem-solved concept’ (PSC), a statement of the problem that a patent solves, was first proposed by Phelps [
19] and was further explored by other researchers [
20,
21], who introduced heuristic rules to automatically extract the PSC from a patent description. However, the limitation of this research is the absence of a method for analyses of the extracted PSC results. Moreover, the identification of the problem without information regarding the contexts or circumstances (e.g., where, how, when) of the problem limits the ability to provide perspective and significance of analysis results. For example, when the extracted problem after extraction using text mining takes a form similar to ‘increase sensitivity’, it is difficult to comprehend the meaning, situation, and significance of the problem. On the contrary, with the introduction of context (e.g., ‘of touchpad’), the extracted problem accommodates more meaning and a stronger foundation for subsequent analyses.
In this study, we report a systematic and replicable method of patent analysis to identify key contexts and problems to be solved for sustainable technology development and management. This method is composed of context–problem network (CP net) generation and quantitative analysis (
Figure 1). A CP net is generated in a sequential manner (
Figure 2). In the first stage, sentences derived from patent parsing are selected by matching keyword patterns. Contexts and problems are extracted from the selected sentences by grammar-based text mining. In the second stage, the extracted contexts and problems are further normalized via stop word elimination, stemming, and semantic conversion. In the final stage, the normalized contexts and problems are used to determine co-occurrences by co-word analysis to generate a network, CP net. Then, the resulting CP net data are quantitatively analyzed through a combination of three different approaches (centrality, neighbor, and grammar analyses), providing constructive key information for technology innovation. Our method has been applied to the wireless energy transmission technology domain as a case study. As a result, meaningful information of the field is determined: The contexts, ‘batteries’, ‘power transmission coils’, and ‘cores’, are observed to be most relevant to the problems, ‘maximizing coupling efficiency’, ‘minimizing DC signal components’, and ‘charging batteries’. As shown in the case study, the contexts and problems selected through our proposed method can be meticulously investigated to recognize associated problems and contexts directly related to the specific area of interest. Particularly, the outcomes of the case study are applied and analyzed to correspond to the current status quo of the wireless energy transmission technological domain from the perspectives of individuals, scientific communities, corporations, and market-level stakeholders to demonstrate the feasibility and exploitation of our method and results. Above all, the environmental and sustainability issues pertaining to wireless energy transfer technology and its developments are discussed. The proficiency to cover wide-ranging perspectives for strategic innovation indicates the suitability of this method to many other high-impact technologies, independent of specific subject domains.
The rest of this paper consists of the sections as follows:
Section 2 describes related works,
Section 3 depicts the procedure and methods for generation of the CP net,
Section 4 presents the method for analyzing the CP net,
Section 5 portrays the application of the proposed method in a case study of wireless energy transmission technology, and
Section 6 describes the conclusion.
3. Generation of CP Net
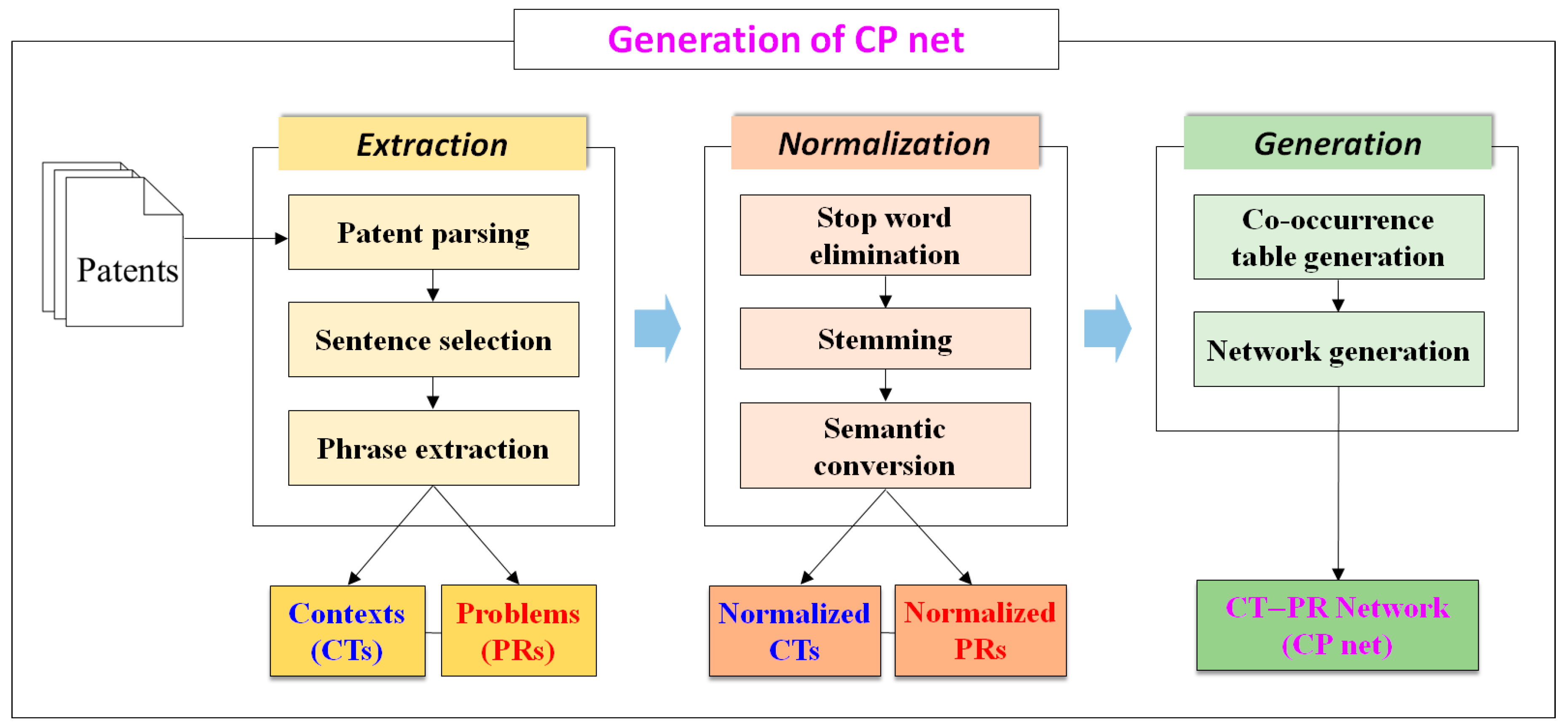
In this study, the procedure for generating a CP net is composed of three stages: Extraction, normalization, and generation (
Figure 2). Specific methods of the stages are described in the following sections.
3.1. Extraction of Contexts and Problems
Full-text patent documents have various formats, according to the patent office, database, and file type. This research utilizes US patents retrieved from the United States Patent and Trademark Office (USPTO). From the website, full-text patents are retrieved in html format. By utilizing Python-based natural language processing libraries, such as BeautifulSoup, unstructured texts can be extracted and categorized into subsections. The subsection ‘background of the invention’ is particularly significant due to the high likelihood of containing the description of the problem.
In our study, ‘problem’ is defined as a minimum expression of the problem (i.e., invention or invented one) which a patent solved. The ‘context’ is defined as a modifier of the problem, which includes interacting products, services, humans, tasks, and environments. Such components are described in the research of context-aware computing [
41,
42,
43,
44,
45,
46]. The context provides keys to understand the problem exactly, because they are direct or indirect causes of the problem.
In general, a patent is documented with numerous sentences that consist of contexts and further describe problems to be solved. In this study, sentences derived from patent parsing are selected by matching to keyword patterns. Sentences from patents can typically be categorized into four types: (i) Description of problems, (ii) description of the needs of users, (iii) description of objectives, and (iv) description of functions. In addition to these patterns, an enormous number of expressions may exist. However, this study uses four representative types of patterns to select sentences, as listed in
Table 1 [
19]. Utilizing these keyword patterns, the sentences from the full texts of patents are matched, selected, and categorized using code implemented in Python. If a sentence results in a positive keyword match with one or more of the keyword patterns (
Table 1), it is placed in a collective list of sentences categorized by the patent of origin. Sentences that describe problems straightforwardly depict the problem precisely (e.g., “the existing problem is inefficiency of searching” or “the matter is that the speed of the transference is too slow”). Moreover, particular sentences describe the needs of users, such as “there is a need for improving efficiency” and “accurate methods are required”. There also exist sentences that describe objectives of the patents, like “objective of this invention is to reduce human errors” and “purpose is to increase convenience”. Certain sentences include verbs which have an increasing, decreasing, or solving connotation that denote functionality, like “to maximize heat conductivity” and “to improve mechanical strength”.
After sentence selection, grammar-based text mining is applied to extract contexts and problems by employing extraction rules (
Table 2). Most problems can be modeled as an action–object structure, i.e., a combination of a verb (VB) and an object of the verb (OV) [
19]. Such modeling is also valid for the four types of problems, for example, “problem is interrupting (VB) communications (OV)”, “there is a need for transferring (VB) electricity (OV)”, “objective of this invention is to increase (VB) efficiency (OV)”, and “purpose is to minimize (VB) interruption (OV)”.
In contrast to the problem identification, modeling of the context has yet been studied. Thus, a key strength of our research is the extraction of the context in addition to the problem. In fact, the context is a surrounding situation when problems arise. Examples include a product, a service, a component, a human, a task, or an environment. Therefore, the context typically explains what is connected to the problem, and how it is associated. In this study, the preposition–object structure is used for modeling the context. The object, usually a noun phrase, refers to an object (OP) of the preposition and explains the identity or circumstance connected to the problem. The preposition (PP) explains how the OP is connected to the problem. For example, a context ‘in the wireless communication network’ means a problem occurs ‘in’ (PP) the environment of the wireless communication network (OP).
Because the problem and the context are modeled as grammatical structures, the part-of-speech (POS) of each word must be identified. In this research, the Stanford Log-linear Part-Of-Speech Tagger is used [
47]. It tags all words with one of 36 POS tags or 12 punctuation tags. After tagging, the grammatical structures are identified by matching to sequences of POS tags. Specifically, the context is identified by a sequence of the preceding preposition and the following noun phrase, whereas the problem is identified by a sequence of the preceding verb phrase and the following noun phrase. Overall, CPs are extracted by patent parsing, sentence selection, and phrase extraction (
Figure 2).
3.2. Normalization of Extracted Contexts and Problems
The contexts and the problems, which are extracted in the first stage, are further normalized for statistical analysis. First of all, ‘stop words’ such as ‘the’, ‘a’, ‘what’, ‘they’, and ‘himself’ [
48] are eliminated. Additionally, some POSs, such as article determiners and personal pronouns, provide insignificant value for analysis, and are excluded.
Every word has various inflected or derived words. Specifically, a word takes different forms depending on the tense, person, plurality, gender, and case. Humans can easily recognize that the words are closely related, but computers recognize them as different entities. Thus, to enable a computer to process inflected or derived words accurately, they must be converted to a common form. For this purpose, the morphological approach is usually applied. In our study, Porter’s stemmer was used for such purposes [
49]. Porter’s stemmer reduces words to their stem. For example, the different words ‘argue’, ‘argued’, ‘arguing’, and ‘argues’ are reduced to their stem ‘argu’. Even though the suffixes are removed, the fundamental meaning is still clear and does not affect the interpretation of the original word.
In addition, the semantic approach was used for understanding human expression through language. This approach guides a computer-based system to understand the meanings of expressions. Semantic dictionaries such as WORDNET [
50] have been used in the semantic approach of this study. By using the dictionary, words can be converted into their real meanings, and this process reduces problems of synonymy and homonymy. However, in certain cases, word conversions may be inaccurate because the dictionary is not customized to fit specific technological domains, thereby causing confusion especially when analyzing technology-specific patents. For this reason, only a few general words, such as words signifying ‘maximize’, ‘minimize’, ‘transfer’, and ‘provide’, have been converted in this study.
3.3. Context–Problem Network Generation
In this stage, CWA is performed for the normalized contexts and problems in order to generate a co-occurrence table, which records co-occurrences of contexts and problems. The co-occurrence table is for allowing initial observation and assessment of the relationships between all contexts and problems by organizing them in a matrix, and further providing the basis for generating a context–problem network. Importantly, co-occurrences between a single context and a problem are most common, but in alignment with the goals of this research to identify key contexts and problems, instances of context–context and problem–problem co-occurrences are also considered when applicable. The inclusion of context–context and problem–problem pairs prevents important information from loss or distortion for sentences with multiple problems or contexts, while also providing vital relationships of pairs of contexts or problems that may exist in the same patent. Henceforward, ‘co-occurrence’ refers to the link or relationship discovered through CWA between context and problem, context and context, and problem and problem.
In generating the co-occurrence table, co-occurrences of contexts and problems are recorded following three main rules: (i) Add one point for each sentence of a patent when the co-occurrence exists in the same sentence, (ii) add one point when the co-occurrence exists in the same patent, but (iii) a maximum of one point per patent is allowed in the case of multiple co-occurrences. The logic behind this scoring method of the co-occurrence table is (a) to add importance to context and problem co-occurrences for each existing sentence, (b) to add significance to context and problem co-occurrences in the same patent, and (c) to avoid over-exaggeration of the importance of the co-occurrence due to multiple co-occurrences within the same patent. Redundant points awarded to each co-occurrence within the same patent can affect the resulting network generated from the co-occurrence table negatively by misleadingly emphasizing their importance. The reasoning for acknowledging the co-occurrences within the same patent is to account for co-occurrences that transpire in separate sentences. For example, when considering the following two sentences, ‘new features of the touchpad provide the following functionalities’ and ‘4. increased sensitivity and precision’, the context ‘of the touch pad’ is related to the problems ‘increase sensitivity’ and ‘increase precision’. However, this relationship will be unnoticed if only co-occurrences in the same sentence are considered.
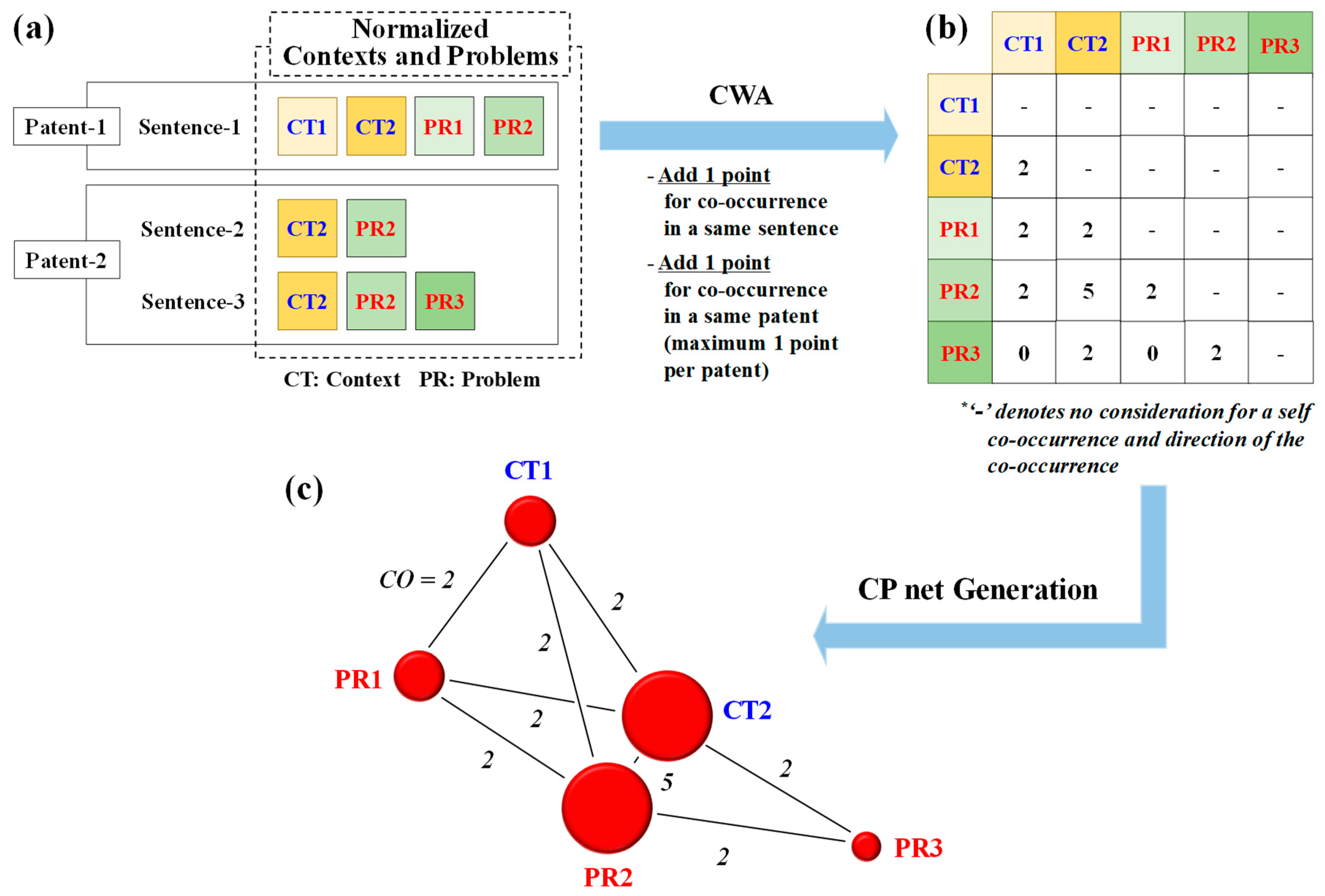
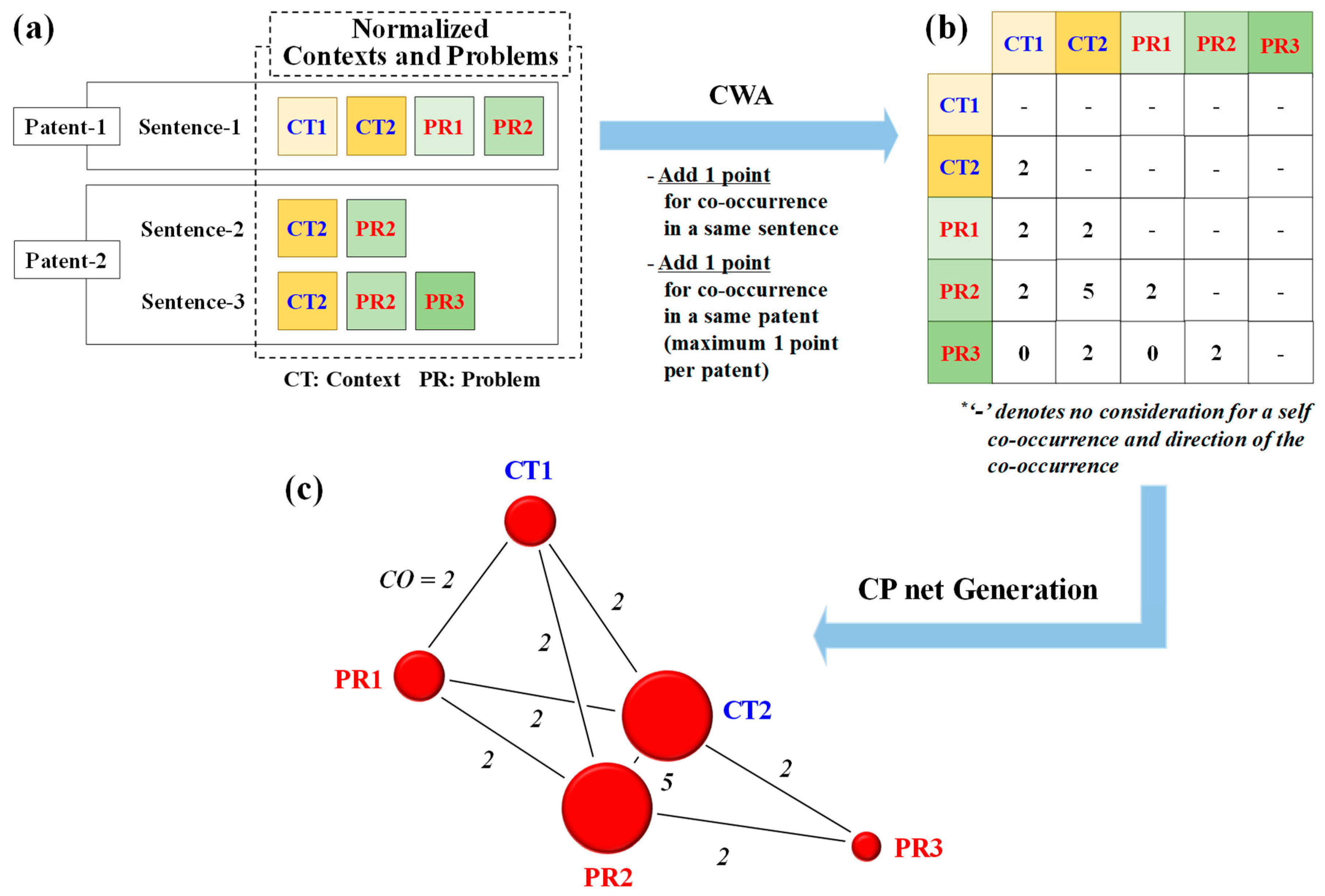
To further demonstrate how the co-occurrence table is generated, the process of recording the five co-occurrences of CT2 and PR2 in
Figure 3a,b is examined as follows. When considering Sentence-2 (‘the purpose is to increase transmission speed in the wireless network’) in Patent-2, one point for the co-occurrence between the normalized context CT2: ‘in wireless network’ and the normalized problem PR2: ‘maxim transmiss speed’ is recorded. Furthermore, if Sentence-3 of Patent-2 states ‘apparatus provides power and increases transmission speed in all wireless networks’, another point for the co-occurrence between the context CT2: ‘in wireless network’ and problem PR2: ‘maxim transmiss speed’ is documented. Furthermore, this CT2–PR2 co-occurrence takes place in the same patent (i.e., Patent-2), registering one additional count. Thus, a resulting total of three co-occurrences are registered for the pair from Patent-2. Likewise, when considering Sentence-1 (‘transfer power and amplify energy transmission speed in wireless network by primary coil’) in Patent-1, the CT2–PR2 co-occurrence is recorded with a value of two: One count for co-occurring in the same sentence (i.e., Sentence-1) and one count for co-occurring in the same patent (i.e., Patent-1). Hence, the CT2–PR2 co-occurrence total in
Figure 3a,b equates to five, with three counts from Patent-2 and two counts from Patent-1. Additionally, self-co-occurrences (i.e., CT1–CT1; PR1–PR1) and the directions of the co-occurrences (i.e., CT1 → PR1; PR2 ← CT2) imply insignificant meaning to the context–problem pair relationships and are not considered for our research, and thus, are represented as ‘-’ in the co-occurrence table. In such a manner, all possible co-occurrences can be counted and accumulated by analyzing the remaining normalized contexts and problems.
With the three main rules described above, the total number (
) of the co-occurrences of each pair of interest among all the normalized contexts and problems can be formulated as an equation in the following:
where
x is a node (i.e., a context or a problem) and
y is another node (i.e., a context or a problem) where
x ≠
y,
is the
th of
sentences,
is the
th of
patents,
is a co-occurrence of
x and
y in the
th sentence (1 if they co-occur; 0 otherwise), and
is a co-occurrence of
x and
y in the
th patent (1 if they co-occur; 0 otherwise). Consequently, the values of the co-occurrences of contexts and problems are assessed for all patents to generate the co-occurrence table.
The co-occurrence table often leads to a complex network of contexts and problems. Thus, applying a cut-off value (
CV) to
is quite beneficial to transfigure the co-occurrence table into a network in a simpler but more valuable form. As
CV increases, the efficiency of network generation and the simplicity of the resulting network increase, so that analysis can be performed intuitively. However, if the cut-off value is too high, important connections may be omitted. Thus, the
CV should be determined case-by-case. Use of
CV binarizes the weight (
) of the links between the paired nodes (i.e.,
x and
y in Equation (1)):
Here, the co-occurrence weight () determines the unique strength, which is illustrated by the different numbers and distances of the links between the x and y node pairs. Overall, adjustments to the CV are performed to reduce network complexity while preserving important co-occurrences prior to proceeding to the analysis of the generated context and problem network.
After completion of the co-occurrence table, the relational data in the form of a matrix can be suitably transfigured into a network of contexts and problems (CP net) to conduct SNA.
Figure 3b,c illustrates the generation of the CP net representing the data collected from the co-occurrence table. The CP net can be generated from the co-occurrence table obtained above by using the NetMiner software (Cyram Company, Seongnam, Korea) as follows. The co-occurrence table is imported into the software, then the ‘Analyze >> Centrality >> Degree/Closeness’ module is utilized to generate the summary statistics, degree centrality vector, spring visualization, and concentric visualization of the data. Furthermore, through this process, vital information of the degree centrality and closeness centrality of the original co-occurrence data is obtained. The degree centrality and closeness centrality indices are formulated by the software.
Here, the degree centrality (
) of a node
x (i.e., a context or a problem) is computed simply by the sum of co-occurrences of its adjacent nodes and then normalized by the total number of nodes,
, in the entire network as:
where
y is the
th of the
p nodes co-occurring with the node
x in which
x ≠
y and the subtraction of ‘1′ from
means the exclusion of the node
x itself. In the degree centrality analysis, it is additionally noted that
p represents the total link number of the node
x to the other nodes (illustrated as node size in the NetMiner software).
The closeness centrality (
) of a node
x is measured by the inverse of the sum of distances,
, from the node
to all other nodes, which is then normalized by multiplying the total number of nodes (except the
x itself) in the entire network:
where
is the
th of
nodes directly or indirectly linked to the node
, and
is the shortest number of hops between the node
and
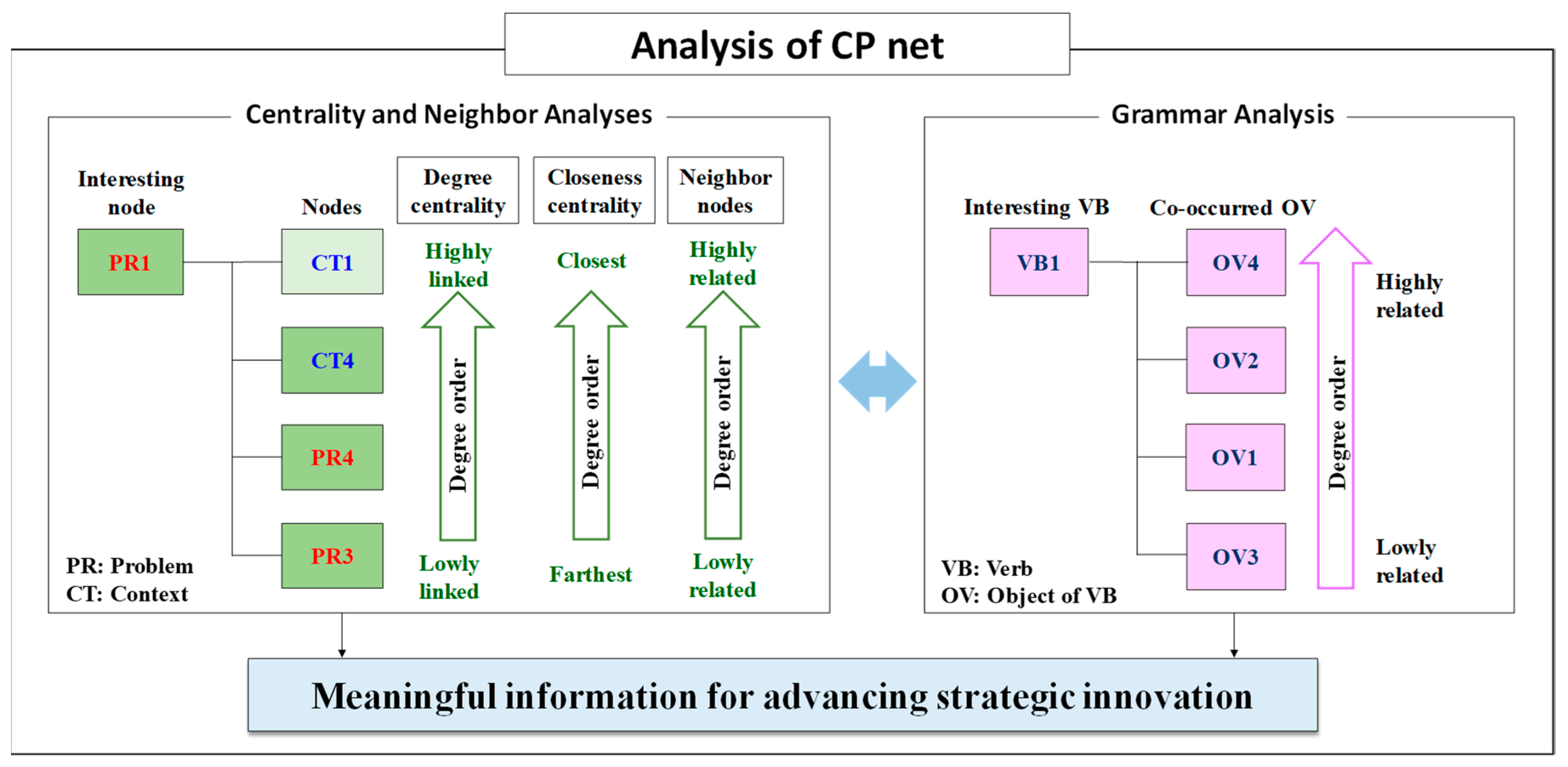
4. Analysis of CP Net
The resulting network, CP net, is one-mode data with undirected links. Thus, in this study, the CP net data could be quantitatively characterized in three types of analyses: (i) Centrality analysis, (ii) neighbor analysis, and (iii) grammar analysis (
Figure 4).
Centrality analysis measures the activities or influences of nodes to find a central node. The centrality of a node determines its relative importance in a social network [
28]. Thus, a context with high centrality indicates important products, services, components, places, times, tasks, or people. On the same principle, a problem with high centrality may indicate important shortages, errors, functions, tasks, objectives, or needs. In general, centrality analysis adopts three measures: Degree, betweenness, and closeness.
This research uses degree centrality and closeness centrality as representative indices of an importance (
Table 3;
Figure 4). Degree centrality can be calculated by assessing the co-occurrence weights between adjacent nodes. In the perspective of contexts and problems, high degree centrality signifies that the context or problem is directly linked to many nodes. Because only direct links are considered, this measure represents local importance. The closeness measure indicates the distance of a node from all other nodes in a network. A context or problem with short geodesic distances to all (direct and indirect) other nodes has high closeness, thus depicting its overall global importance.
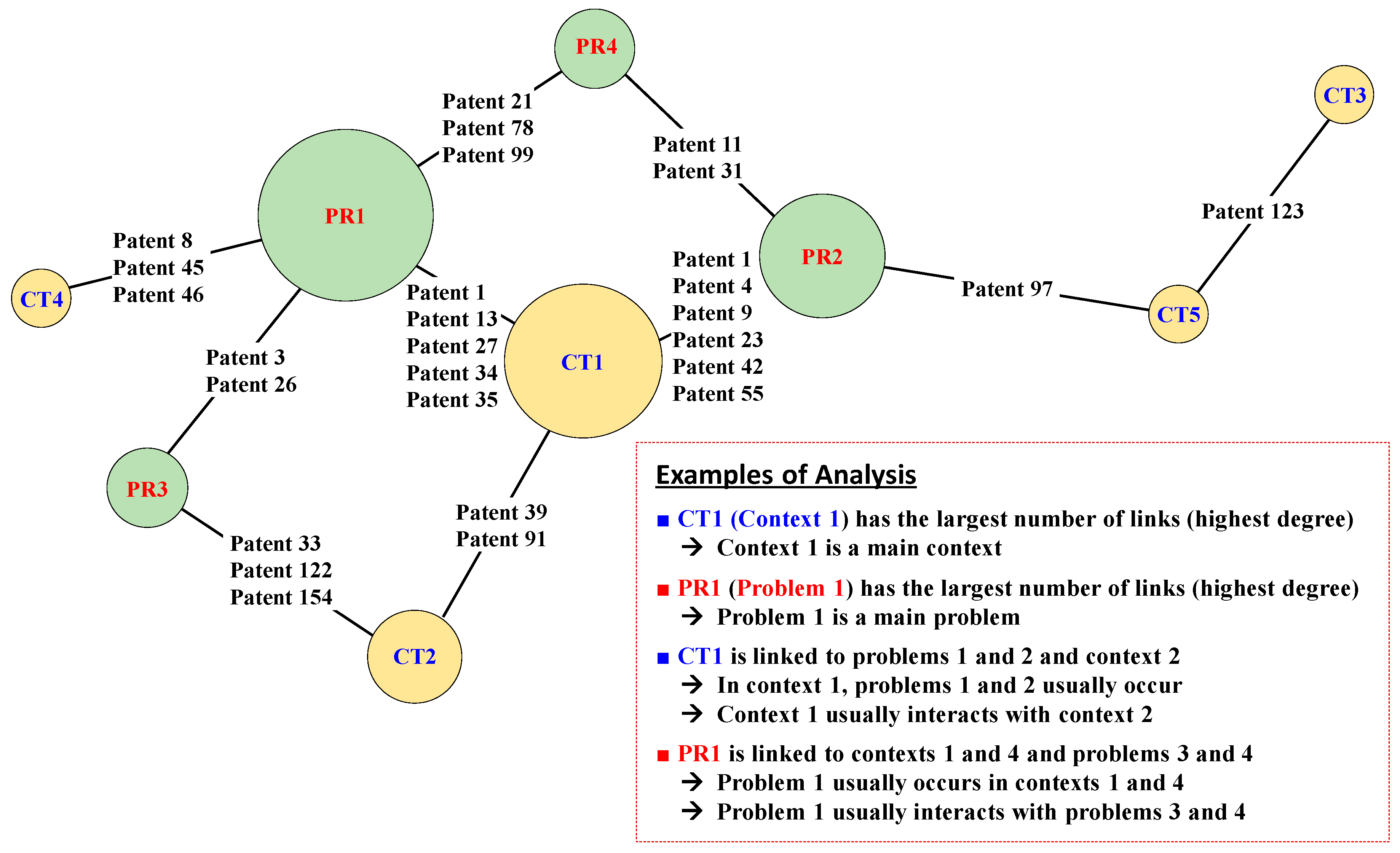
If users are interested in specific contexts or problems, they can select the node of interest and analyze its neighboring nodes (
Figure 4). The highly-related neighbor nodes are identified by referring to the weights of the links. For example, if users are interested in the context ‘of mobil phone’ and neighbor nodes, like the context ‘of convers’, and the problem ‘maxim qualiti’ is identified, they may learn that the important problem is to maximize the quality of conversation in the context of the mobile phone.
The grammar analysis is more specific, which can provide relationships among grammatical components of a context or a problem (
Figure 4). The context usually consists of PP and OP, and the problem usually consists of VB and OV. By separating the grammatical components from the construction, users can focus on a specific component. Especially, the VBs ‘maximize’ and ‘minimize’ are very useful for analyzing problems. For example, if we only consider problems that include the VB ‘maximize’ and sort them by degree order, we can learn which OVs other inventors are trying to maximize. The OV can be related to criteria such as efficiency, convenience, and cost. In a similar way, users can analyze the CP net in depth according to their interest.
5. Case Study: Wireless Energy Transmission Technology
The transfer of electricity over a tiny air gap was first demonstrated in 1888 by using an oscillator of Hertz which was connected with induction coils. Furthermore, long-distance transfer of microwaves was also demonstrated in 1896 by Tesla [
51]. Thereafter, no further introduction of a method converting microwaves back to electricity has been documented for an extensive period. However, sixty-eight years later, the conversion of microwaves to electricity was realized by Brown and coworkers using a rectenna. The rectenna, a rectifying antenna, was invented in 1964 and disclosed as a patent in 1969 [
52]. This invention opened up the possibilities for practical wireless charging technology, namely wireless energy transmission (WET) technology. A mid-range non-radiative wireless charging method was additionally reported in 2007 [
53,
54].
Currently, WET technology has been highly regarded as a next-generation charging technology, which can be used in diverse applications including mobile electronic devices, electric vehicles, and biomedical devices. In particular, the rise in interest for WET technology can be mainly explained by the adoption of the technology in portable electronic devices [
55].
Thus, in this research, the WET technology domain has been selected for the case study. We have constructed and analyzed a CP net using the systematic and replicable method developed above. We have retrieved 737 patents disclosed for WET technology between 2004 and 2013 from the USPTO official website. The patents were full text documents in html file format. Through patent parsing, keyword matching, and grammar-based text mining, a total of 1734 context–problem pairs were extracted, with at least one from each of 515 (69.9%) among 737 patents. To increase extraction efficiency, linguistic research could be beneficial for modeling the contexts and problems in future studies. Following the normalization process via stop word elimination, stemming, and semantic conversion, 1248 contexts and 1261 problems were remained to comprise 2509 nodes and 13,619 undirected links for use in SNA.
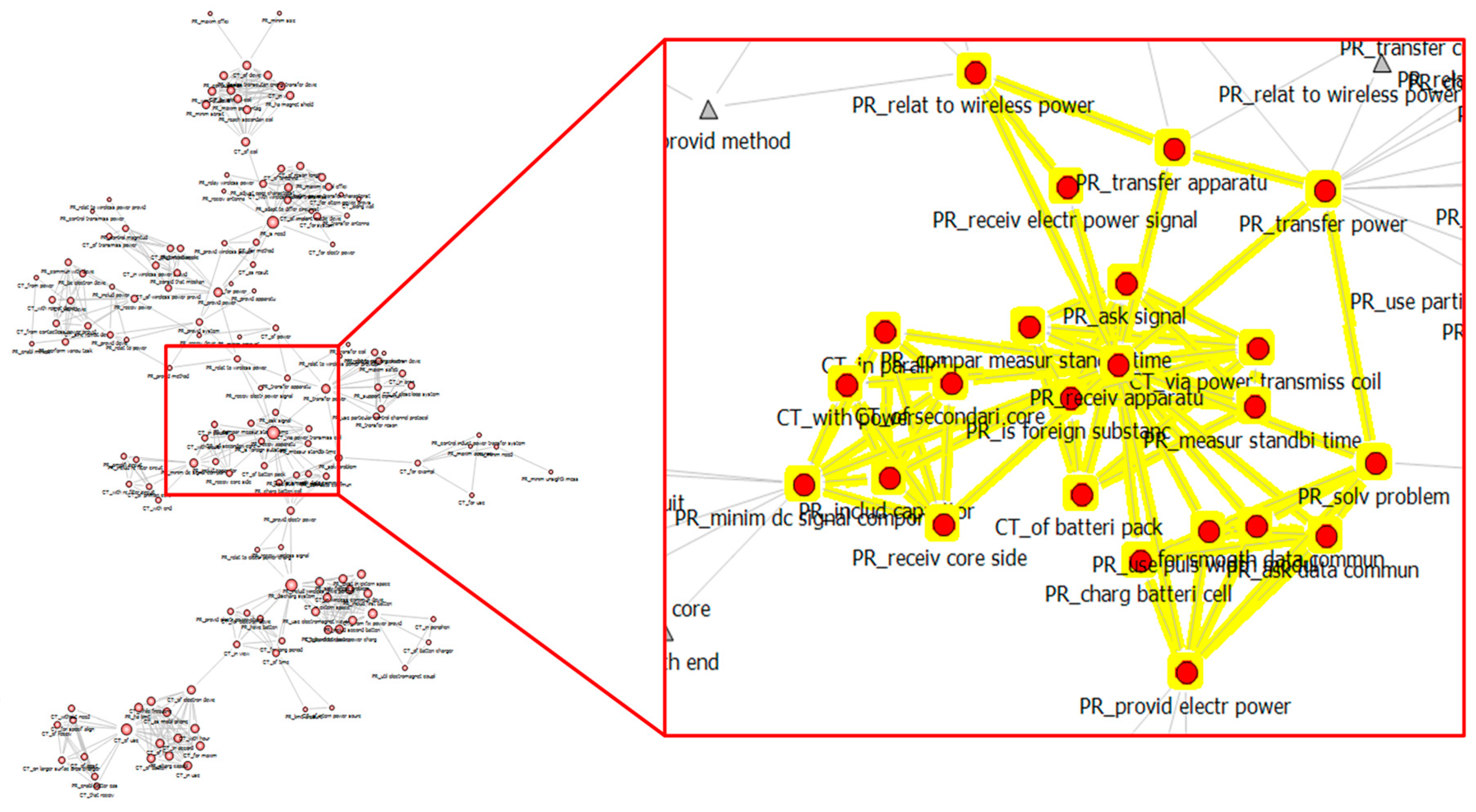
Due to the high complexity of the resulting network, links with
< 7 were eliminated, and then the CP net was re-generated (
Figure 5). Then, centrality analysis was applied (
Figure 6), and top nodes with high centrality were identified (
Table 4). Even though stop words had been eliminated, the result included some meaningless expressions, which were eliminated manually. The significant context included components such as ‘a battery’, ‘a coil’, and ‘a core’. This illustrates that such components are highly related to major problems. In terms of problems, naturally, problems related to ‘providing power’ showed high scores. For example, problems like ‘maximizing coupling efficiency’, ‘minimizing DC signal components’, ‘charging battery’, and ‘discharging system’ are nominated, as shown in
Table 4.
Once the contexts and problems were identified by the centrality analysis, neighbor analysis was performed for specific interests. In this case study, we focused on analyzing the context ‘of coil’ and its neighbors as a trial (
Table 5). According to the result, the coil context was found to have strongest relations with problems such as ‘maximizing coupling efficiency’, ‘having magnetic shield’, ‘disclosing energy transfer devices’, ‘covering primary coil’, ‘maximizing percentage’, ‘getting wind of devices’, ‘reaching secondary coil’, and ‘minimizing sensitivity’. Thus, when considering the component ‘coil’ as a target of improvement or invention, information regarding these relations would be imperative for establishing the purpose and direction.
Finally, grammar analysis was performed for in-depth analysis. For illustration purposes, we focused on problems with the VBs ‘maximize’ or ‘minimize’ (
Table 6). By analyzing the VBs ‘maximize’ and ‘minimize’, we were able to observe that prior inventions have aimed to solve or optimize existing problems in the wireless charging technology field. In other words, the most significant objectives that inventors have directed their efforts toward could be identified. It was discovered that many inventors focused their advancements in maximizing ‘coupling efficiency’, ‘overall efficiency’, ‘safety’, ‘accuracy’, ‘battery life’, and ‘ease of use’. On the other hand, inventors were also trying to minimize ‘DC signal component’, ‘sensitivity’, ‘size’, ‘cost’, and ‘unsightly mess’.
From the results of our patent analysis method, an overview of the existing problems and contexts of the technological domain can be obtained. This is beneficial for inventors to gain extensive insights of the domain at large. Furthermore, the results can also provide valuable, in-depth information of a preselected specific area of interest within the technological domain, whether the initial search begins from the context or problem.
As an overview of the case study regarding the WET technology domain, we conclude that three main contexts, (i) battery, (ii) power transmission coil, and (iii) core, are the components most relevantly related to the three main problems, (1) maximizing coupling efficiency, (2) minimizing DC signal components, and (3) charging battery. For this technology, it can be observed that these contexts, in accordance to the problems, have been the most imperative features to be satisfied. Once the comprehension of the significant contexts and problems of the entire domain is performed, one can look more meticulously into selected problems (i.e., ‘maximizing of coupling efficiency’/‘minimizing DC signal component’) or contexts (i.e., ‘of coil’) to detect respective contexts or problems directly related to the particular area of interest. For example, when considering the problem ‘maximizing of coupling efficiency’, one could find that this problem pertains mainly to the coil. After identifying the problem and which component to innovate, the user can concentrate on these areas for constructive and effective innovation.
The outcomes of our research provide valuable information that can be utilized at an individual level and also applied to strategic innovative planning from a larger perspective. From the point of view of an individual, user, or inventor, we believe that these findings are beneficial for anyone who is performing innovative research and development (R&D) in the WET technology domain. By accurately identifying the key problematic areas that require solutions for new product development, an individual or small group of inventors can exploit and focus on the outcomes of this research by identifying the contexts referring to the fundamental components (i.e., coil) to accomplish incremental improvements of the component based on the discovered problems and contexts.
Moreover, the yielded results from this research can be applied to a larger technological domain or market-level perspective. Through the outcomes of our method, a scientific or industrial community aimed at advancing and standardizing the WET technology can identify that the major problems of inefficiency and DC signal noise relate to short- and long-ranged (i.e., ‘resonance length’) wireless energy transfer. This holds true for WET technology due to its existing inefficiencies to transfer power as compared to direct, wired energy transfer, both for short-, and more so for long-range applications. As a community, joint efforts and collaborations can be formed among research groups and corporations to develop solutions and set requirements to meet user and industry standards collectively by identification of the most critical problems (‘maximize coupling efficiency’ and ‘minimize DC signal component’) found through our method.
From a market standpoint, the results of our method isolate key contexts (i.e., ‘resonance length’) requiring attention in order to fulfill the needs of consumers, thus increasing the rate of adoption. Presently, short-distance wireless energy transfer is generally utilized for mobile and medical devices. With the inconveniences of being unable to displace the device from the charger, the WET technology domain remains unable to utterly meet consumer and market needs and satisfaction. Additionally, long-range WET technology, usually aimed for larger WET systems (e.g., electric vehicle wireless charging), can also be found in its early development stage of R&D. Moreover, based on these results, industry leaders of WET technology can consolidate their corporate R&D plans around these findings for more cost-effective and revenue-generating directions. Through the developments to increase the efficient range or wireless energy transfer based on the results of our method, we expect rises in market adoption, consumer satisfaction, and new product applications.
Furthermore, these outcomes directly address environmental and sustainability issues in WET technology. At the current development state of WET technology, evolving environmental concerns stem mainly from the inefficiencies (propagation loss and low transfer efficiency) of wireless charging (i.e., more energy is needed to charge battery via wireless charging, compared to traditional wire charging, and thus more conventional fuel consumption is required for WET). Our research points attention toward the problems of maximizing coupling efficiency and minimizing DC signal (i.e., noise) in the contexts of the core and power transmission coil components of WET devices, and helps emphasize the importance of innovation in improving these problems. Fortunately, the innovative goals for these contexts–problems coincide from both technological and environmental perspectives. Supplementary investigation of the direct sustainability and environmental issues caused by WET technology, such as the adverse effects of radiative wireless charging, may be required for additional perspectives and directions for ecofriendly WET innovation.
In summary, the informative results acquired through our method can be widely applied and exploited by individuals, corporations, and research societies to aid in addressing key problems and components to focus strategic innovation in generating satisfactory technological and environmental advancements. Most importantly, this method can be applied universally to different technological domains and applications.
6. Conclusions
In this study, we developed the systematic and replicable method of patent analysis as an identification tool of contexts and problems to be solved in patents. This method generates and further analyzes CP net data in a quantitative manner. The CP net is constructed via the extraction, normalization, and network generation from patent analysis and text mining as follows. Contexts and problems were extracted from full-text patents after sentence selection. The extracted contexts and problems were further normalized by eliminating stop words, stemming, and semantically converting words. From the normalized contexts and problems, a co-occurrence table was generated to create a CP net, which can be analyzed in a comprehensive manner by using the combined centrality, neighbor, and grammar analyses.
This systematic and sustainable method was applied to analyze a total of 737 patents disclosed for advanced wireless energy transfer technology. In this case study, a set of CP net data was successfully generated. The CP net data were analyzed, providing essential information in the wireless charging technology field. The centrality analysis revealed components like ‘battery’, ‘coil’, and ‘core’ as important information. Problems related to providing energy, like ‘maximizing coupling efficiency’, ‘minimizing DC signal components’, and ‘charging battery’ were recognized. When the context ‘a coil’ is focused in the neighbor analysis, several problems like ‘having magnetic shield’, ‘disclosing energy transfer devices’, ‘covering primary coil’, ‘getting wind of devices’, ‘reaching secondary coil’, and ‘minimizing sensitivity’ were found to be highly related. The grammar analysis showed that many inventors are trying to maximize ‘coupling efficiency’, ‘safety’, ‘accuracy’, and ‘battery life’, or to minimize ‘sensitivity’, ‘size’, and ‘cost’. The results were then deliberated and tailored to explain current situations of WET technology R&D. Furthermore, the discussion of strategic innovative planning and implications were further dissected into individual, scientific community, corporate, and market levels. In short, the case study concludes with effective examples in which a wide variety of domain stakeholders can utilize the results acquired through our method for the advancements of the WET technology and efforts required to alleviate its environmental impacts.
Overall, the systematic and sustainable method of patent analysis has been demonstrated as a very powerful tool to identify problems to be solved in patents. Our research intends to contribute to the advancements of patent mining and analysis with focuses in syntactic and semantic analyses, as well as to help provide managerial implications of strategic technological planning and innovation, granted the valuable insights obtained through our method. Furthermore, this method is domain-independent and is applicable in various technologies for technology planning and innovation.
However, the method has a limitation. Namely, despite elimination of stop words, expressions that were overly general remained, and these interfered with clear interpretation. To overcome this limitation, the need for a customized stop word dictionary for contexts and problems identification is necessary. In spite of the limitation, the generation process performed well, and the CP net was useful to identify problems to be solved. The authors’ future research endeavors will aim to improve this method for higher quality of contexts and problems extracted, to incorporate modern, state-of-the-art machine learning and text mining techniques for CP net generation efficiency, and to cope with larger data sets.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}