1. Introduction
After agricultural transfers, the second largest share of European Union’s (EU) budget is dedicated to the funding of the Regional Policy. With a share of 40% of EU budget, Regional Policy aims for sustainable local development of EU regions. For this purpose, 347 billion Euros were spent in the 2007–2013 programming period and 347 billion euros are foreseen for the 2014–2020 programming period. Several funds are used for this purpose. European Regional Development Fund “aims to strengthen economic and social cohesion in the European Union by correcting imbalances between its regions” (
https://ec.europa.eu/regional_policy/en/funding/), focusing on investments into research and innovation, support for small- and medium-sized enterprises, the digital agenda and the low-carbon economy. The Cohesion Fund supports large infrastructural investments such as energy and transport investments that benefit the environment in Bulgaria, Croatia, Cyprus, the Czech Republic, Estonia, Greece, Hungary, Latvia, Lithuania, Malta, Poland, Portugal, Romania, Slovakia and Slovenia, i.e., in Member States where Gross National Income per capita is less than 90% of the EU average. The European Social Fund “invests in people, with a focus on improving employment and education opportunities across the European Union. It also aims to improve the situation of the most vulnerable people at risk of poverty” (
https://ec.europa.eu/regional_policy/en/funding/).
In the 2007–2013 programming period, Hungary received some 25 billion euros from these funds. Relatively small compared to these interventions, the European Agricultural Fund for Rural Development provides the means of Rural Development Policy. Within the EU, Hungary is one of the biggest beneficiaries of Rural Development Program (RDP) payments—at least as far as per-capita transfers are considered. In the 2007–2013 programming period, EUR 3.8 billion was spent, while, in the 2014–2020 period, EUR 4.2 billion (of which EUR 740 million in the form of national co-funding) is earmarked for this purpose. The question that naturally arises is: Do these substantial transfers make a difference? The European Commission’s mandatory ex-ante, mid-term and ex-post program evaluations—based on the monitoring of a set of (partial) indicators and qualitative assessment—fail to provide an answer because of the need for uniformity and comparability across Member States.
Papers generally focus on the impact of Structural Funds, more precisely on the impact of Objective 1 programs (Objective 1 programs are the largest measure within the EU cohesion policy, targeting regions with GDP (evaluated at Purchasing Power) less than 75% of the EU average) upon European regions. Several strands of literature may be identified. The first one analyzes to which extent the main goal of the Regional Policy, i.e., the convergence of European regions was achieved [
1,
2,
3]. A second group of papers focus on the impact of structural funds on the economic—most often GDP per capita—growth [
2,
4,
5,
6,
7,
8,
9], or employment growth [
4,
5,
10] of regions. Reference [
11] focused on the impact of Cohesion Policy on the economic performance of the most disadvantaged regions (NUTS3 level), while the effect of European Structural and Investment Fund payments on the performance of local governments in Portugal were assessed by Caldas et al. [
12]. Further, [
13] analyzed the impact of Cohesion Policy on regional productivity growth, and [
14] examined the territorial impacts of EU development policy. The work of Michalek and Zarnekow [
15] is the only paper to describe the Central and Easter European space from this perspective.
Some academics use firm level data for impact evaluation. Thus, [
16] quantified the impact of Rural Development subsidies upon the productivity, profitability and efficiency of Czech meat processing industry, [
17,
18] analyzed the effect of innovation subsidies in Sweden and East German territories, respectively, [
19] analyzed a unique firm level dataset of 2 million projects funded by structural and cohesion funds over the 2007–2013 period for EU 25 countries, and [
20] employed meta-regression to analyze the results of 17 papers providing 323 estimates on the impact of Structural Funds upon growth.
Note, there is a lack of papers focusing on RDP rather than impact of Structural and Cohesion Funds. Policy evaluation or impact assessment of RDP is a rather complicated issue since such complex notions are hard to quantify, while all relevant components of the impact should be captured in a transparent and easy-to-handle fashion. Two notable issues add complexity to any impact analysis. First, the use of partial indicators such as increases in local GDP levels, decreases in unemployment rate, the value of program-generated investment, and the number of programs (or area) supported (see, e.g., [
15] for a detailed discussion). Moreover, GDP data are not available at a disaggregated level, thus analysts are constrained by a lack of data concerning potential indicators. The second issue is the problem of constructing the appropriate counterfactual situation for impact analysis. More exactly, program impact evaluation cannot correctly be undertaken unless the impact is measured by comparing actual and counterfactual outcomes. However, the counterfactual situation may not be observed. Thus, the main challenge of impact analysis is to construct a convincing and reasonable comparison group (counterfactual) for beneficiaries in the absence of data. The very recent paper by Castaño et al. [
21] explores in detail the use of counterfactuals in the ex-post evaluation of 2007–2013 RDP. Using the example of seven evaluations employing rather different empirical methodologies, the authors highlighted the difficulties with respect to data needs and limiting methodological assumptions. They did, however, “recommend the use of advanced counterfactual approaches to provide evidence of programme impacts”. The often-employed naïve approaches to the impact evaluation of RDP (case studies or partial-indicator-based approaches) completely neglect this second issue [
22]. The most important weakness of partial indicators is that they may not be treated as exogenous to levels of development. It follows that, in these analyses, there is no clear unidirectional causality between RDP and local development. The use of a complex Rural Development Indicator (RDI), as originally proposed by Michalek and Zarnekow [
15] and later employed in the Hungarian context by Bakucs et al. [
23], combined with propensity score matching methodology, allows the creation of a counterfactual and thus solves problems with endogeneity.
In this study, we followed this approach and constructed a synthetic development index, complemented by an internal-migration-based index, assuming that, regardless of computed local development scores, people tend to migrate to areas where perceived quality of life is higher. In contrast to [
24], who investigated only the impact of the SAPARD programs in Poland and in Slovakia between 2002 and 2005, we focused on the 2008–2013 period and cover all rural development policy measures. We addressed the following simple question: Has the significant amount of Rural Development funds that have been distributed had any measurable impact? We went beyond estimating the causal effects of RDP and the use of a simple binary treatment indicator by estimating propensity score matching difference-in-differences (PSM-DID) models and using parametric and semiparametric generalized propensity score matching approaches (GPS). Estimating a dose–response function in the framework of GPS provides more information regarding the effectiveness of a program by uncovering heterogeneities in the effects of RDP at different treatment levels. In doing this, we built on recent advances in the applied econometrics of impact evaluation, as well as recent empirical studies using GPS. For example, highly disaggregated (firm-level) data was used by Bia and Mattei [
25] to evaluate the effect of financial support allocated to Piedmont enterprises upon employment growth, while [
26] analyzed the impact of product innovation intensity upon European companies—both approaches employ generalized propensity score matching. Closer to the present topic is research by Michalek and Ciaian [
27], who used generalized propensity score methods to evaluate the capitalization of farm single payments into the land value in the EU and the research of Esposti [
28], who used generalized propensity score matching to identify and estimate the response of farms to decoupling policy as a treatment effect.
We contribute to the impact assessment literature in several ways. First, in a time when politicians and the general public in Old Member States increasingly question the necessity of transfers towards New Member States, we focused on Hungary, a country with a deteriorating Corruption Perception Index (Hungary’s PCI decreased from 55 in 2012 to 48 in 2016 [
29]) and mounting evidence of flawed public procurement system along with high ranked corruption [
30,
31]. Second, by using a territorially disaggregated dataset, on Local Administrative Unit (LAU1) level, we had sufficient observations to analyze the impact of RDP in a single country context, minimizing the heterogeneity of unobservable variables thus increasing the validity of counterfactual ([
10]). Third, we used a spatial spillover panel model to derive the synthetic Rural Development Indicator, thus we avoided the potential bias due to unaccounted spatial variables. Finally, in line with the most recent literature, after estimating PSM-DID models, we shifted from the binary definition of treatment and use Generalized Propensity Score matching eliminating the subjective bias of defining treated and non-treated regions.
The rest of the paper is organized as follows. In
Section 2, we present the data and a description of the methodological approach. In
Section 3, we focus on empirical results. Discussion and some conclusions are provided in the last two sections.
2. Materials and Methods
Hungary, a Central-European Country, acceded to the European Union in 2004. It covers an area of 93,000 km
2 with an approximate population of 9.8 million. At NUTS (Nomenclature des Unités Territoriales Statistiques—nomenclature of territorial units for statistics) 1 level, there are three, at NUTS 2 six, and at NUTS 3 twenty regions (nineteen counties plus the capital city, Budapest). At the Local Administrative Unit level (LAU1, formerly NUTS4), there are 174 small regions composed of 3164 administratively independent settlements. We employed a highly disaggregated dataset of yearly data with respect to these administratively independent settlements, which we believe contributes to the unique nature of this research. The T-STAR database of the Hungarian Central Statistical Office was obtained from the CERS-HAS databank (
http://adatbank.krtk.mta.hu/adatbazisok___tstar). The related data are designed for use in spatial studies and consist of several hundred variables relating to demographics, public health, education, pollution, unemployment, social care, economic entities, infrastructure, commerce and hospitality, tourism, culture, housing stock, municipal aid, municipal budgets, agriculture and personal income tax. These variables are available for the 2007–2013 period for all 3164 administratively independent Hungarian settlements. An internal migration database was provided by the Hungarian Central Statistical Office. Data about development funds for the period 2008–2013 were taken from the Information Systems of National Regional Development. Using total payments per locality, we created three support indicators: total subsidy, subsidy per km
2, and subsidy per capita in LAU1 regions. The descriptive statistics for the development subsidies (years 2008–2013, total per region, per capita and per square km) presented in
Table 1 emphasize the uneven distribution of funds.
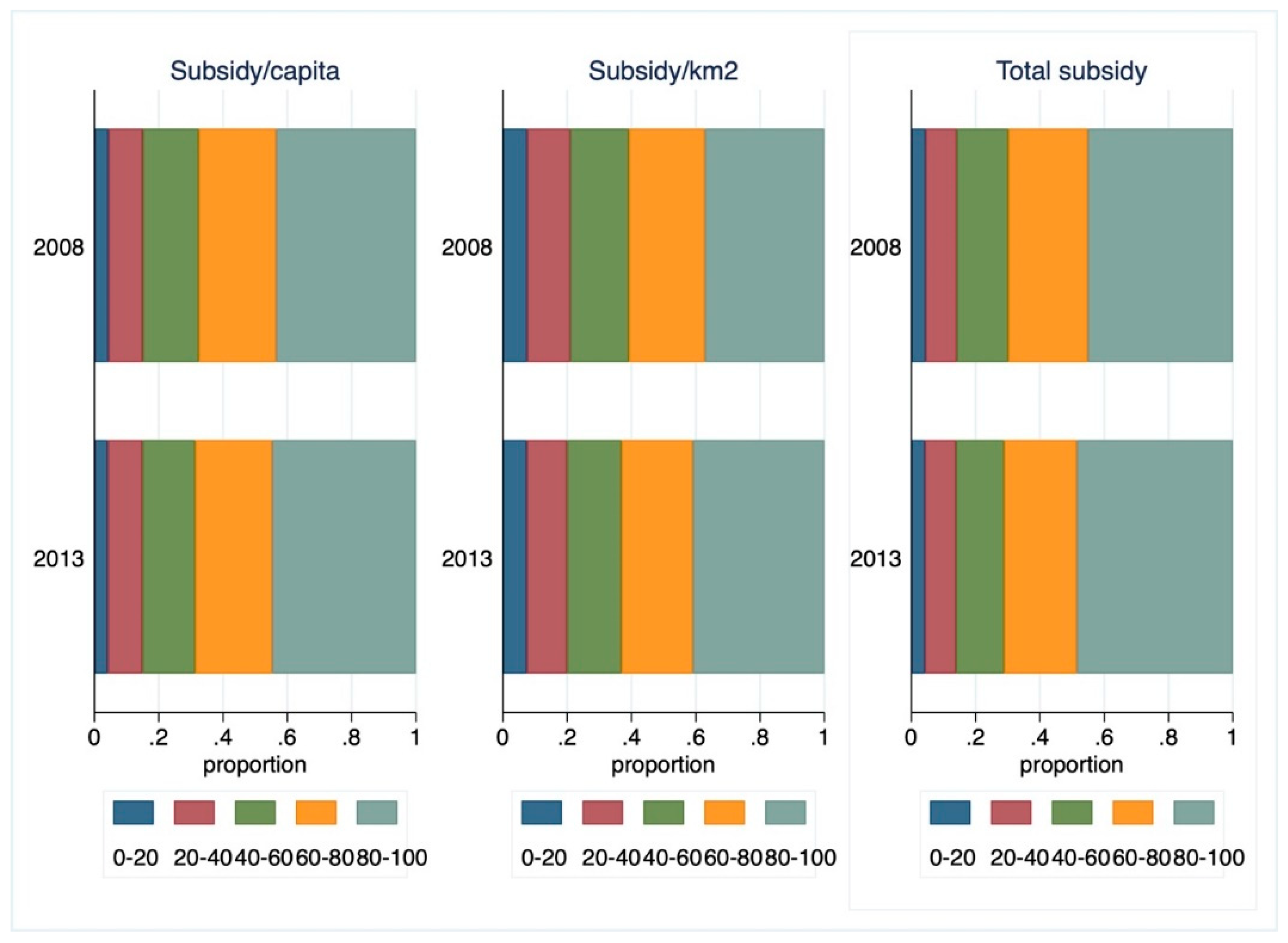
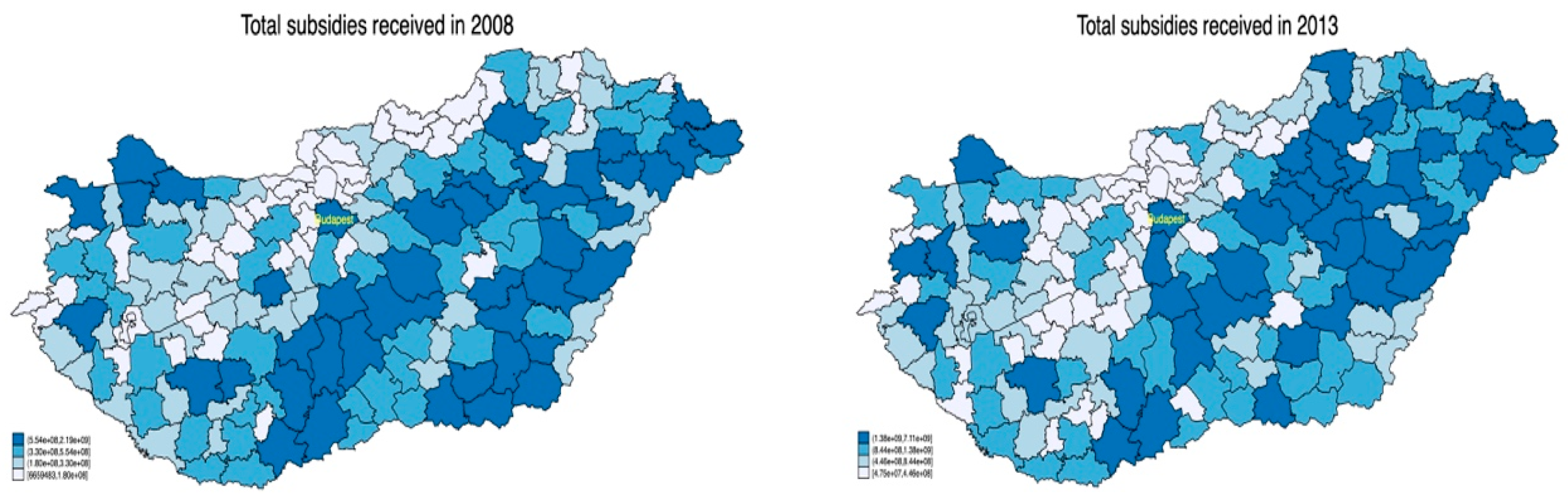
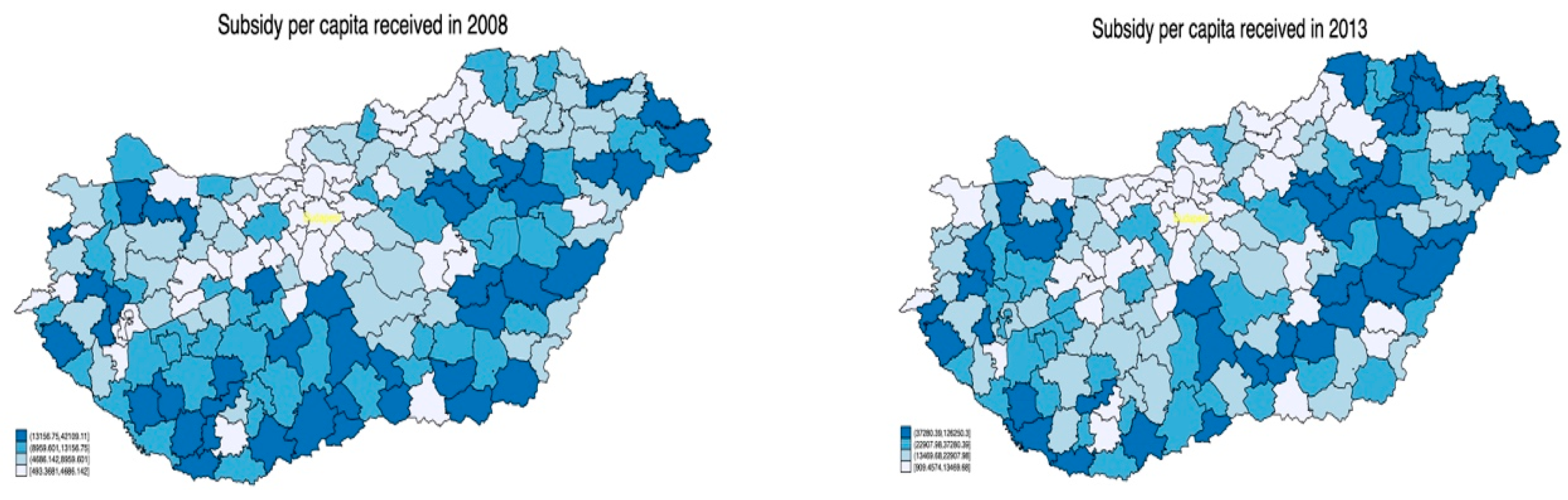
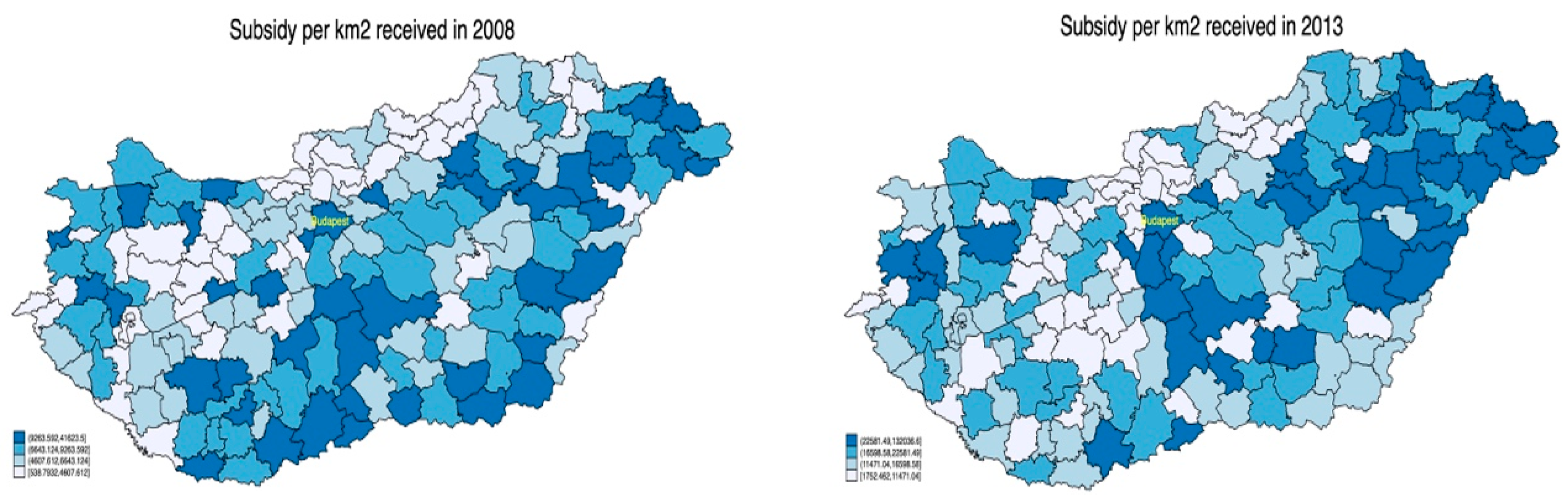
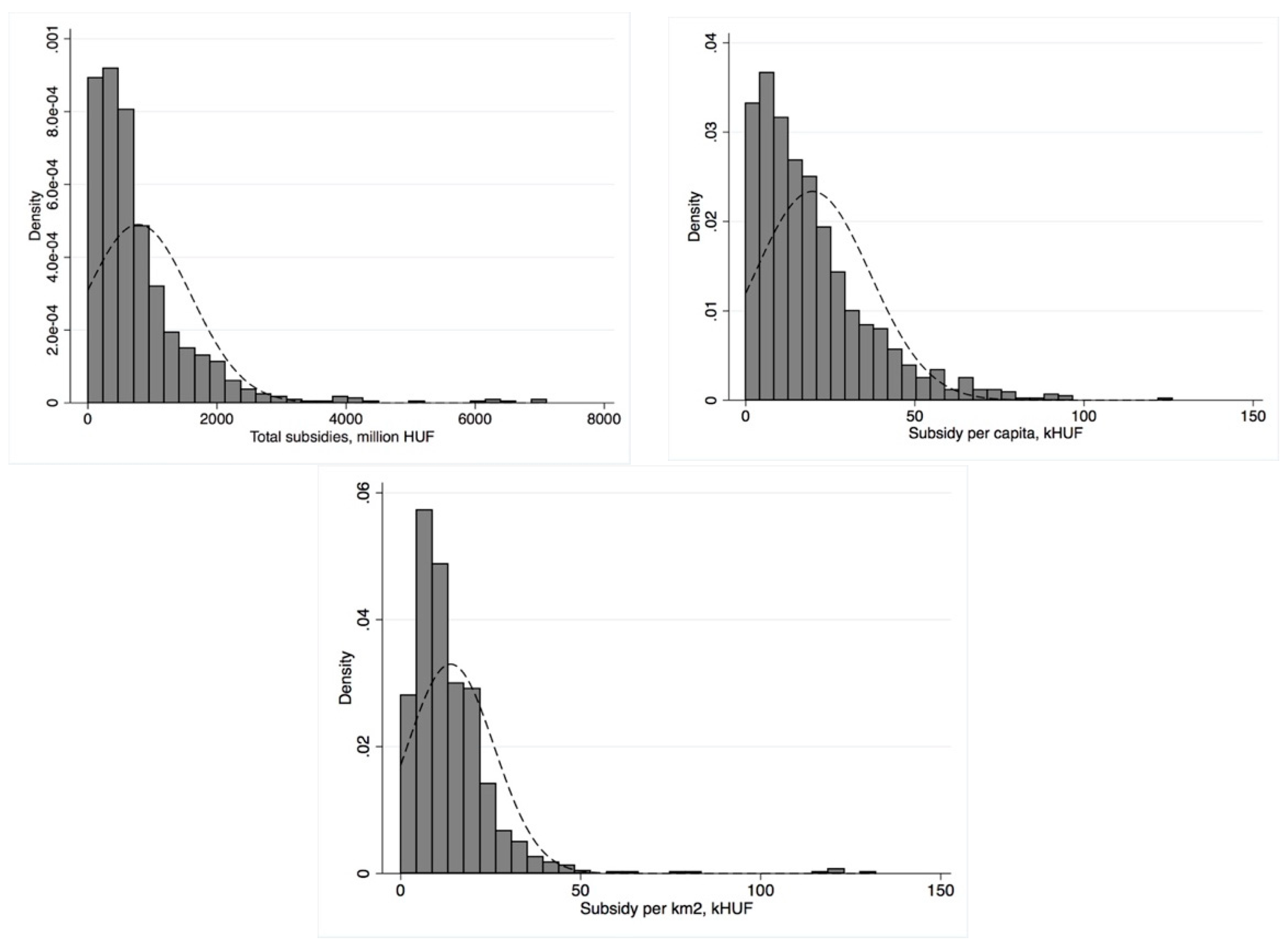
The average value of support per LAU1 region amounted to HUF 780 Million, but there were regions with very low levels of support, while in some regions the maximum value of support reached HUF 7.1 billion. This uneven distribution is also reflected in the extremely high standard deviations. The negative minimum numbers in the table are due to two regions that had to repay RDP funds. The picture is made more nuanced by the last two rows in
Table 1 (per capita and per square km subsidy), in which the inequality of distribution is less prominent. [
23] found an increase in the concentration of subsidies awarded between 2002 and 2008.
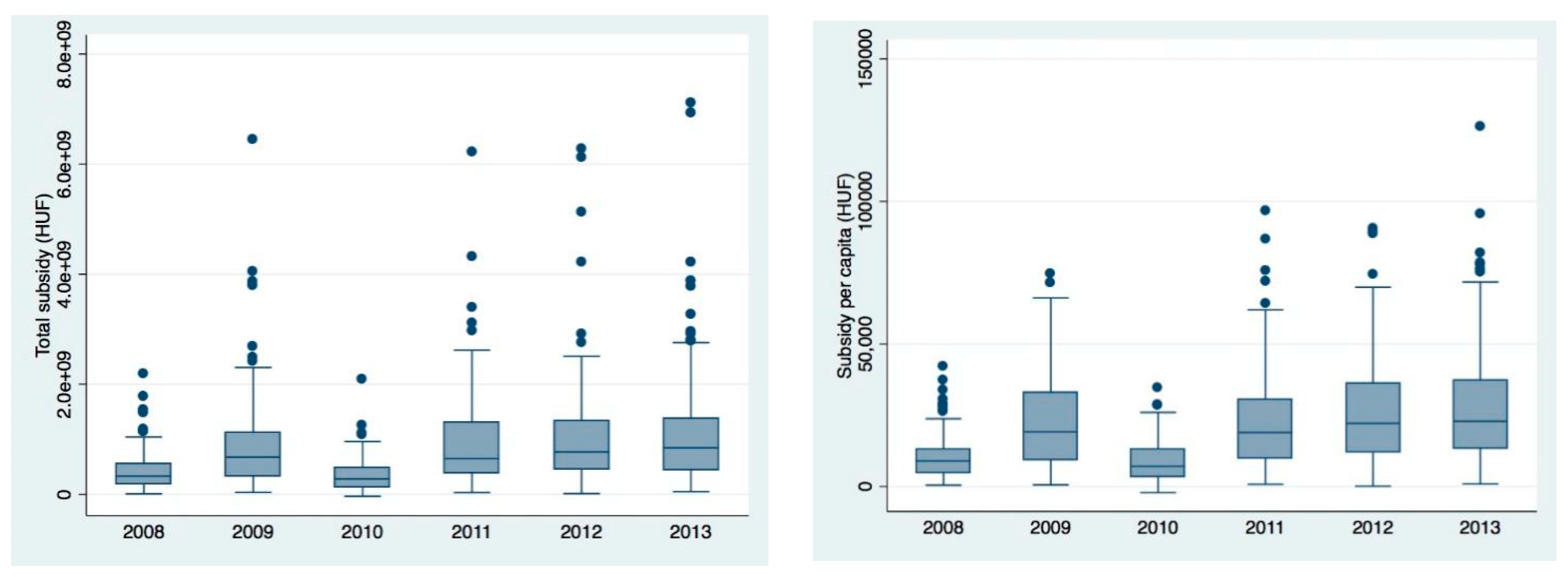
Figure 1 suggests that the concentration of subsidies further increased in the period under examination.
This concentration was more prominent for total subsidy and subsidy per capita, and somewhat less for subsidy per km
2.
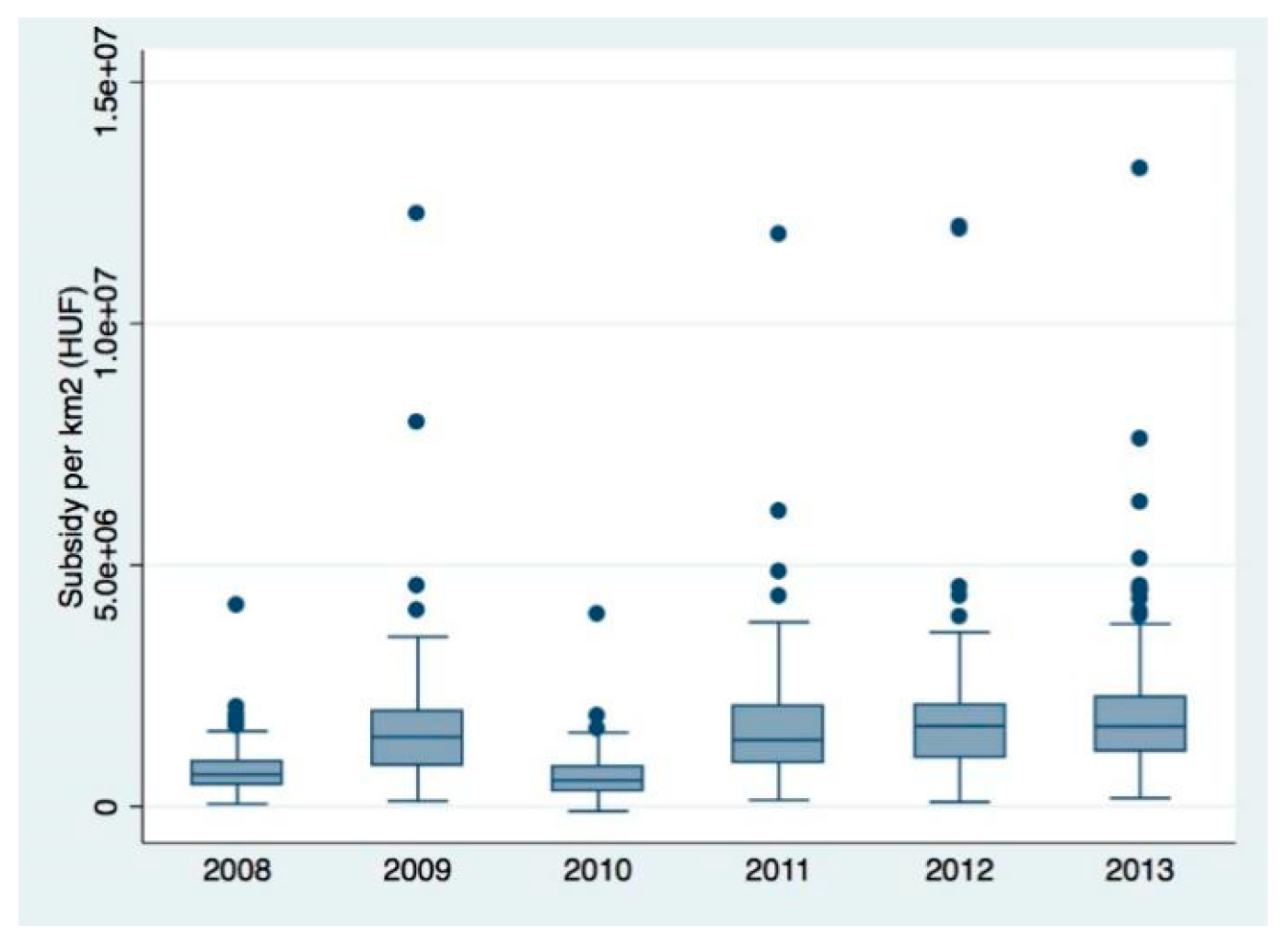
Figure A1 in
Appendix A depicts the box plot graphs of total, per capita and per km
2 subsidies; here, we focus on the yearly average and median values of all subsidy variables (
Table 2).
The interesting numbers are the average subsidies paid in 2009 and 2010. National elections were held in 2010, thus in 2009 the distribution of payments was sped up (see the doubled mean and median values) by the government—which ultimately lost the election. The newly elected Government in 2010 completely reorganized the system and agency of payments, thus the means of subsidy variables for 2010 were almost three times lower than those of earlier years.
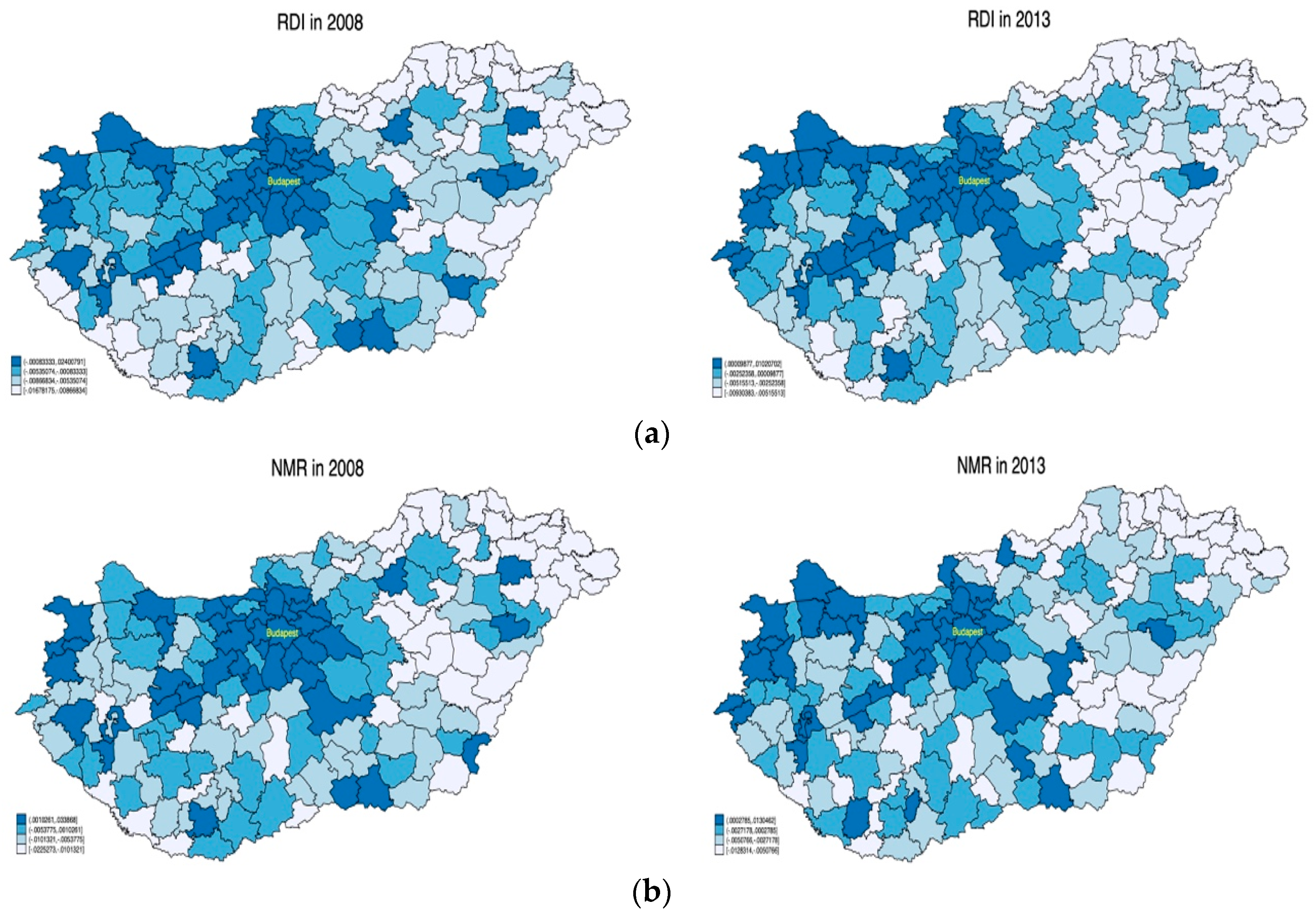
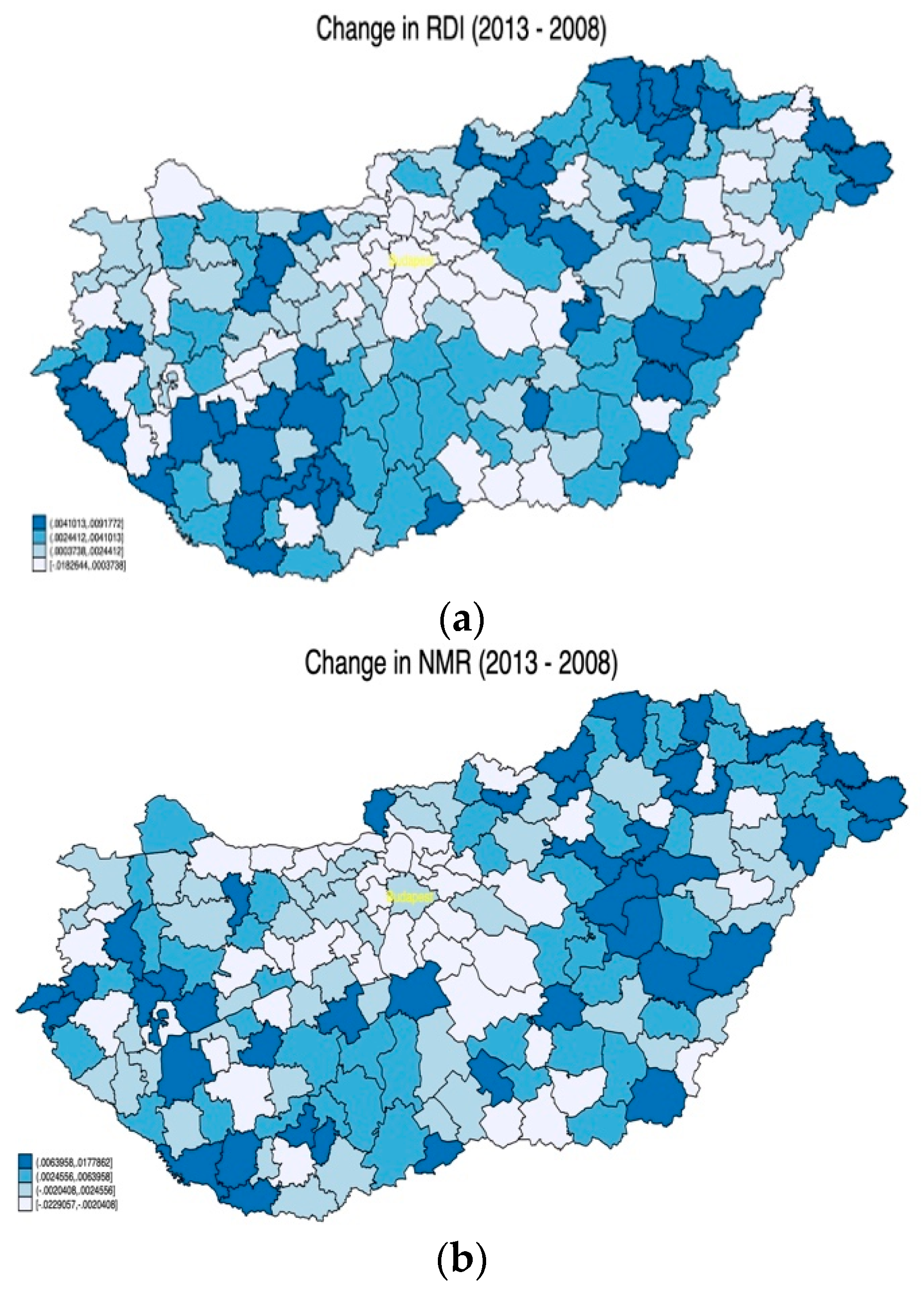
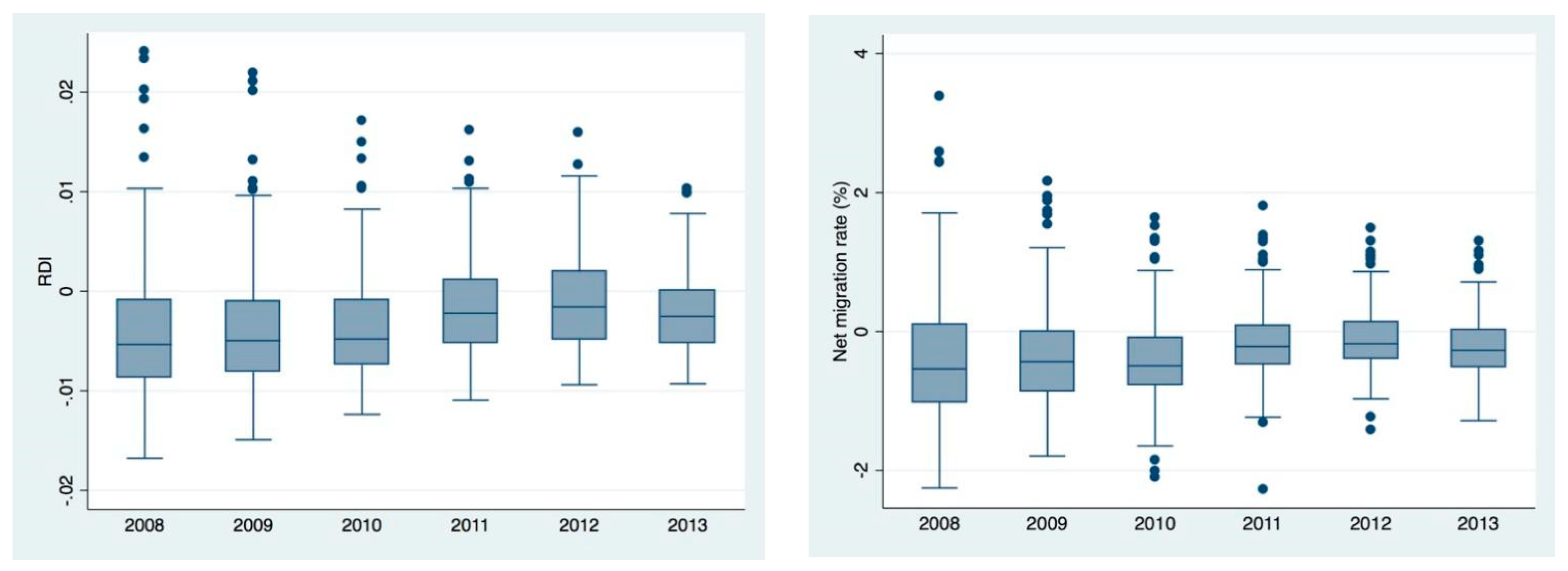
Our empirical strategy consisted of three steps. First, we calculated the region- and year-specific net migration rate variable as a proxy indicator for quality of life in a given region (Equation (1)):
where inmigr is the inflow of people into a LAU1 region, outmigr is the outflow and pop is the local population. Since the seminal article of [
32], the “voting by foot” theory has often been used to proxy the perceived quality of life in a region. In its simplest way it states that people move to locations where they are better off, and thus analyzing regional migration rates may approximate local development levels ([
33,
34,
35] or more recently [
36,
37]).
Second, we composed a local, composite development indicator based on the wealth of variables available in the T-STAR database. There are several potential approaches to this. One common approach is to manually select variables of importance and use various weighting schemes to compose the indicator. Obviously, this approach is highly subjective and the weighting formula is often questionable at best. The most often used methods, however, involve factor/principal component analysis (i.e., “let the data choose”) and the construction of indicators based on selected variables. Factor and Principal Component Analysis was used by Michalek and Zarnekow [
15] to evaluate the SAPARD program in Poland and Slovakia. In the Hungarian context, references [
38,
39] used factor and PCA analysis and employed the same T-STAR dataset as used in this paper to compute regional competitiveness indices. Further, [
23] employed similar techniques to derive the dominant factors responsible for regional development levels for the 2002–2008 period. We used all 170 variables expressed as natural units of measurement (number of, quantity of, length of, etc.) that were available for all years and all 3164 administratively independent Hungarian localities. These describe local statistics with respect to demographics, health services, business units, tourism and catering, retail sector, transport and infrastructure, environment, education, culture unemployment, social security, number of dwellings, personal income tax collected, rank (village town, county seat) of the locality, and distance to nearest county seats. The complete list of variables is available upon request. We then summarized local data into 174 LAU1 Hungarian regions and normalized them according to the population of these regions. PCA and factor analysis then followed to reduce the number of variables. Data were first tested to determine the applicability of PCA (Kaiser–Meyer–Olkin’s measure and Bartlett’s test), followed by a rotation algorithm (Varimax). Finally, we used Kaiser selection criteria to retain factors with Eigen values larger than one. The resulting 29 factors could then be used to compose the RDI. A key issue, however, was determining the weight of each factor that was incorporated into the RDI. These weights may be perceived as relative social values attached to each factor, thus the RDI may be biased if equal or other subjectively determined weights are applied. Following the theory presented in [
32], later applied by a great number of researchers (e.g., [
35,
40,
41,
42]) and the methodology suggested by Michalek and Zarnekow [
15], we used within-country migration flows to estimate the social weight of each factor. The underlying idea is simple: individuals implicitly evaluate the importance of local living conditions when deciding to migrate (Equation (2)).
where mp
it is net migration into region I normalized by the total population of the region i, α
0 is a constant, and F
ikt is the value of factor k in region i, at time t. Thus, β
k accounts for the impact of factor k (F
k) upon net migration, and was used as a weight in the construction of RDI. Finally, v
i is the region-specific residual and ε
it is the residual with the usual white noise properties. Given the panel structure of data and the strict underlying assumptions of panel models, various models were estimated using specification and diagnostic tests to facilitate selection of the best one (see, for example, a handbook by Baltagi [
43]). The RDI index takes the following form:
where RDI
it is the Rural Development Index in region i and year t, F
ikt is the factors as defined under Equation (2), and β
kt is the weights for each factor specific to region i and time t resulting from the estimation of the migration function (2). That is, Equation (3) calculates the RDI as the proportion of migration flows explained by local characteristics represented by the factors.
Third, we evaluated the impact of RDP on LAU1 regions (see the textbook of Cerulli [
44] for a detailed discussion on impact evaluation). While in standard policy analysis settings, sample-average treatment effects cannot be calculated because only one of the two possible outcomes for each region can be observed, this issue was solved by the estimated indicators that allowed the creation of the counterfactual. The counterfactual analytical framework developed by Rosenbaum and Rubin [
45] and the employment of propensity score matching enabled us to predict the probability of a region being subsidized on the basis of observed covariates for both subsidized and non-subsidized regions. The method balances the observed covariates between the subsidized and non-subsidized regions based on the similarity between the predicted probabilities of a region being selected as a treated region. The most common evaluation parameter of interest is the Average Treatment Effect on the Treated (ATT), defined in Equation (4) as:
where Y
0 and Y
1 are the outcomes in the non-treated and treated states, respectively. Estimating the treatment effects based on Propensity Score Matching (PSM) requires making two assumptions. First, the Conditional Independence Assumption (CIA) states that for a given set of covariates participation is independent of potential outcomes. The second condition is that the ATT is only defined within the region of common support. For a more comprehensive discussion of the econometric theory behind this methodology, we refer the reader to the works of Imbens and Wooldridge [
46] and Guo and Fraser [
47].
For the empirical analysis, we employed two approaches: difference-in-differences treatment effect estimations combining PSM, and generalized propensity score matching. The advantage of the first approach is that it can evaluate treatment effects in a dynamic setting, making full use of our panel dataset. Having data about subsidized and non-subsidized regions over time can also help with accounting for some unobserved selection bias by combining PSM and the Difference-in Differences estimator (conditional DID estimator). The conditional DID estimator (e.g., [
48]) is very applicable in the case that the outcome data about program participants (i.e., subsidized regions) and nonparticipants (non-subsidized regions) are available for both “before” and “after” periods (2008 and 2013, respectively). In our study, PSM-DID measured the impact of the subsidies by using the
differences in selected outcome indicator (ATE or ATT) between subsidized (D = 1) and non-subsidized sub regions (D = 0) in the before and after situations. The main advantage of the PSM-DID estimator is that it can relax the assumption of unconfoundedness.
All LAU1 regions in our study received some support. Thus, in the binary PSM framework, the treated/non-treated division of the regions may only be done using arbitrary thresholds. Recent developments in applied econometrics, however, allowed us to implement Generalized Propensity Score Matching, as originally proposed by Gelman and Meng [
49] for continuous treatment effects. As the second approach to evaluation described in this paper, GPS eliminates the subjectivity that can occur when classifying regions into treated and non-treated ones. While in a binary PSM setting logit or probit is used to estimate the probability of a unit (region) being treated conditioned on covariates X, with continuous treatment parametric generalized linear models are used to estimate GPS using alternative distributional assumptions. More specifically, it is assumed that:
where g is a link function (e.g., logarithm), ψ is the probability density function (e.g., normal, gamma, igamma, or beta), h is a flexible, X covariate vector and unknown γ parameter dependent function, and
is a scale parameter. T
i is the treatment variable. Following the estimation by maximum likelihood of the treatment conditional distribution parameters γ and
, the GPS is estimated:
Similar to the PSM method, GPS also requires that covariates are sufficiently balanced across units with different treatment levels. [
50] implemented the method developed by Flores et al. [
51] using likelihood ratio tests. This consists of estimating three regressions (the dependent variable is the continuous treatment variable): one unrestricted which includes both the X covariates and GPS scores, and two restricted ones, one including X covariates only, and one including GPS terms only.
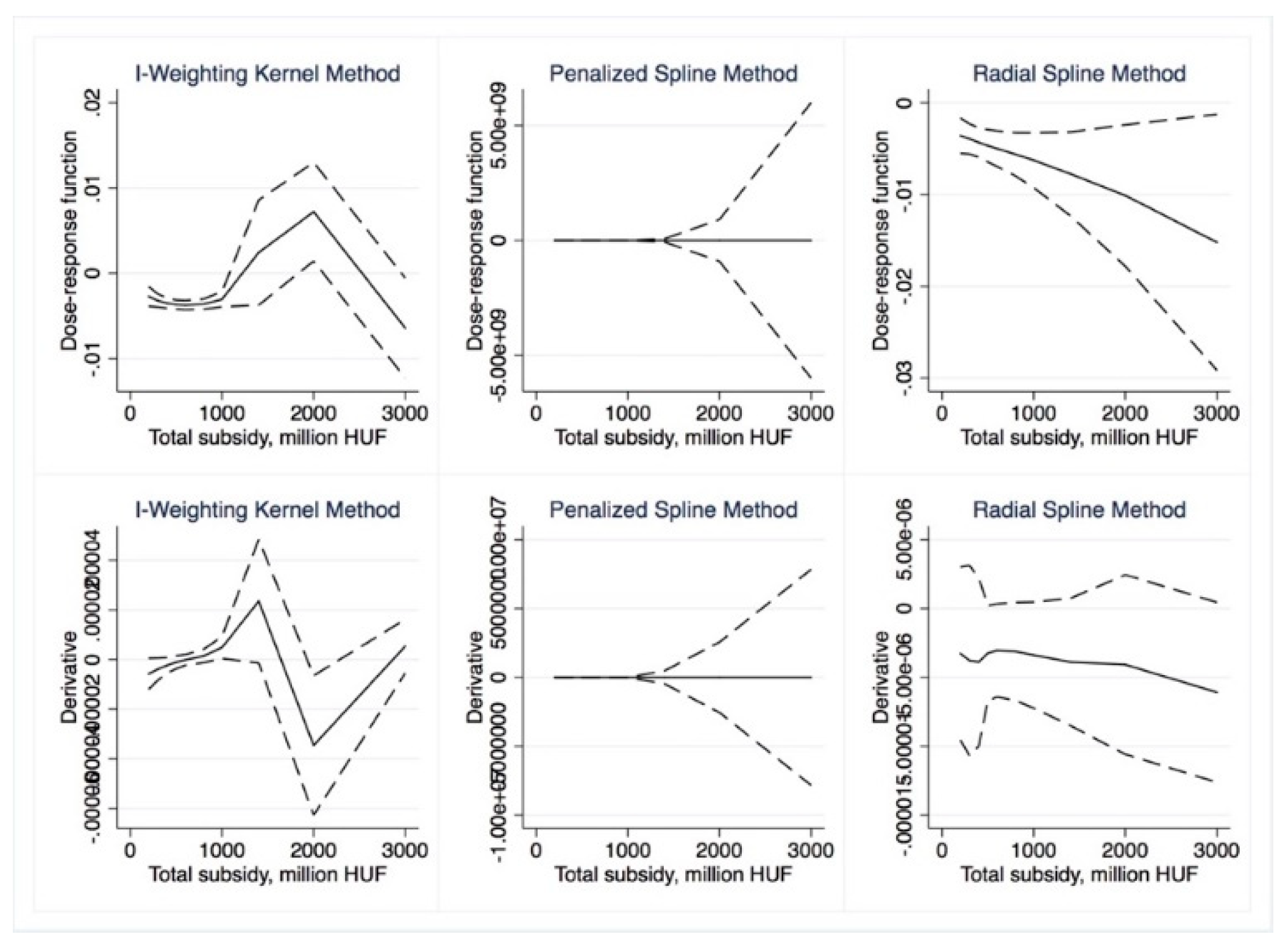
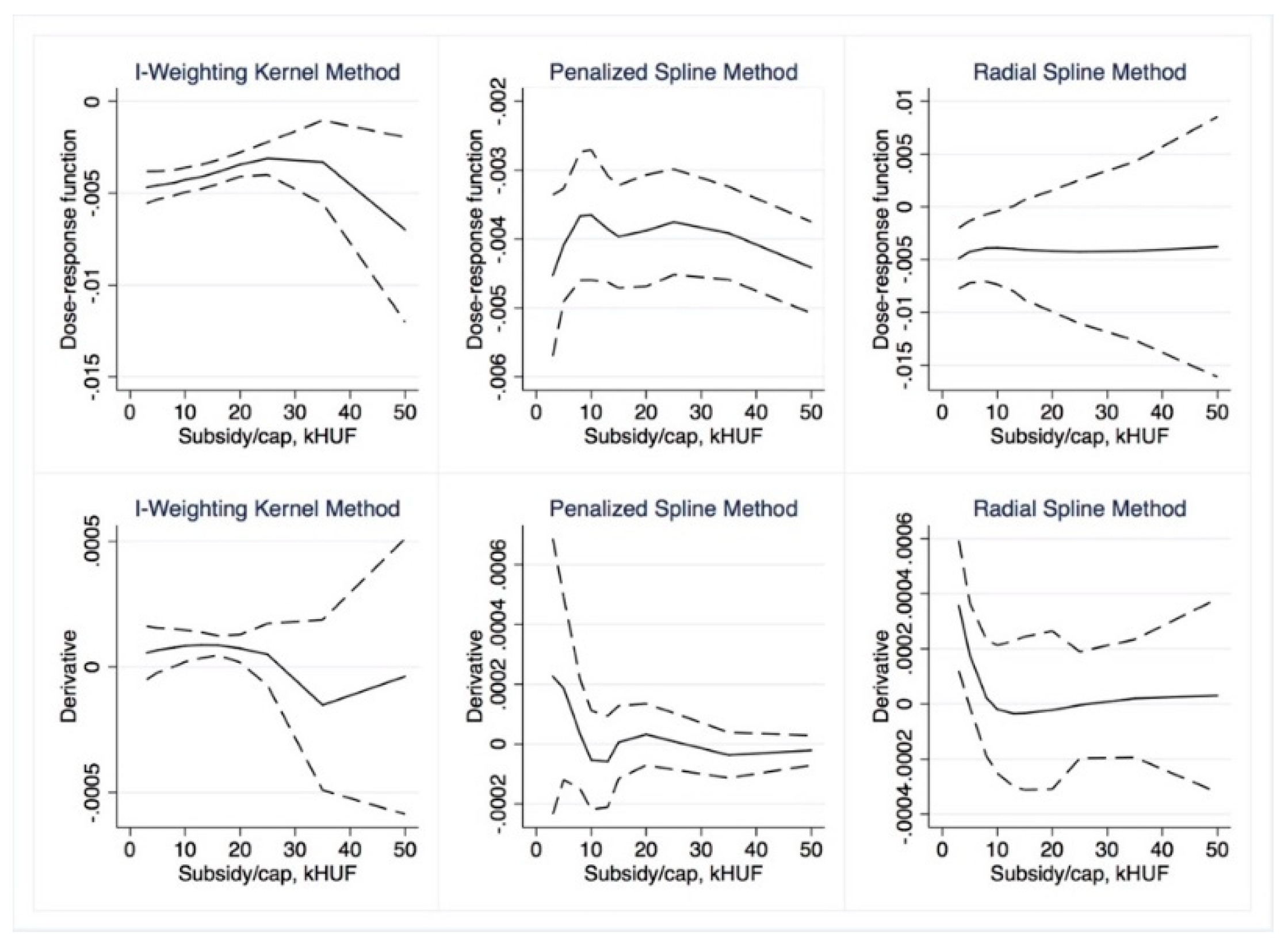
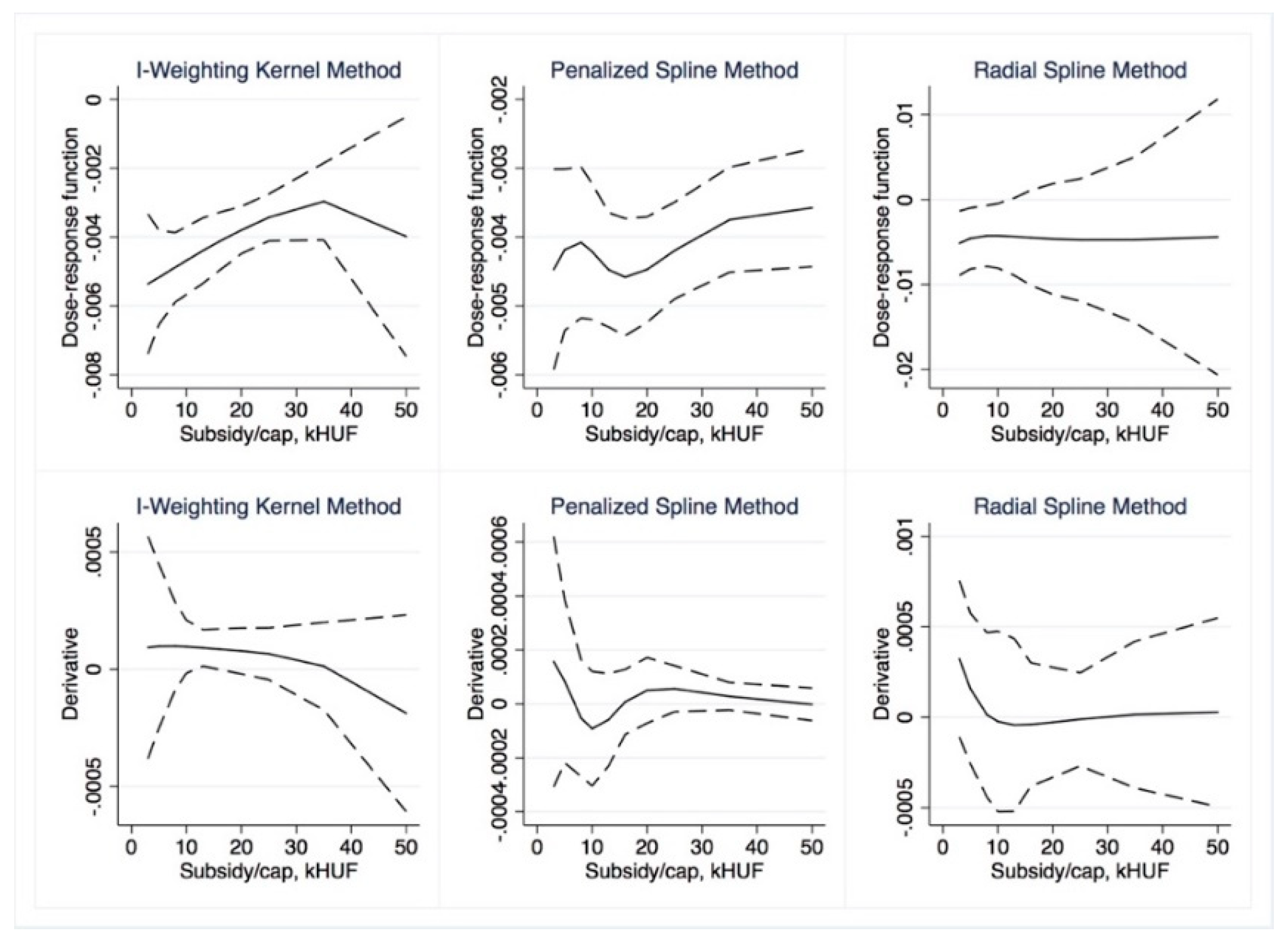
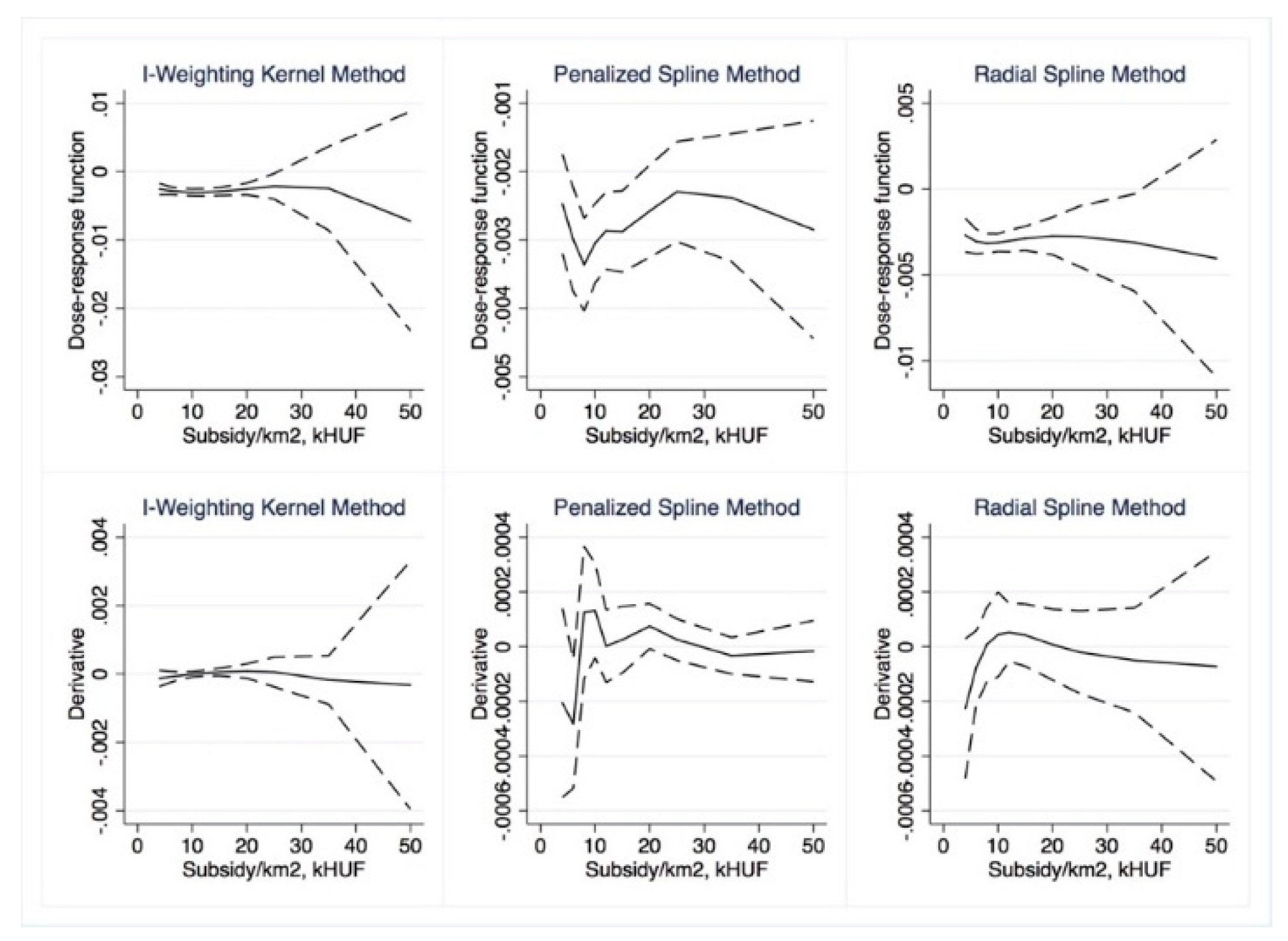
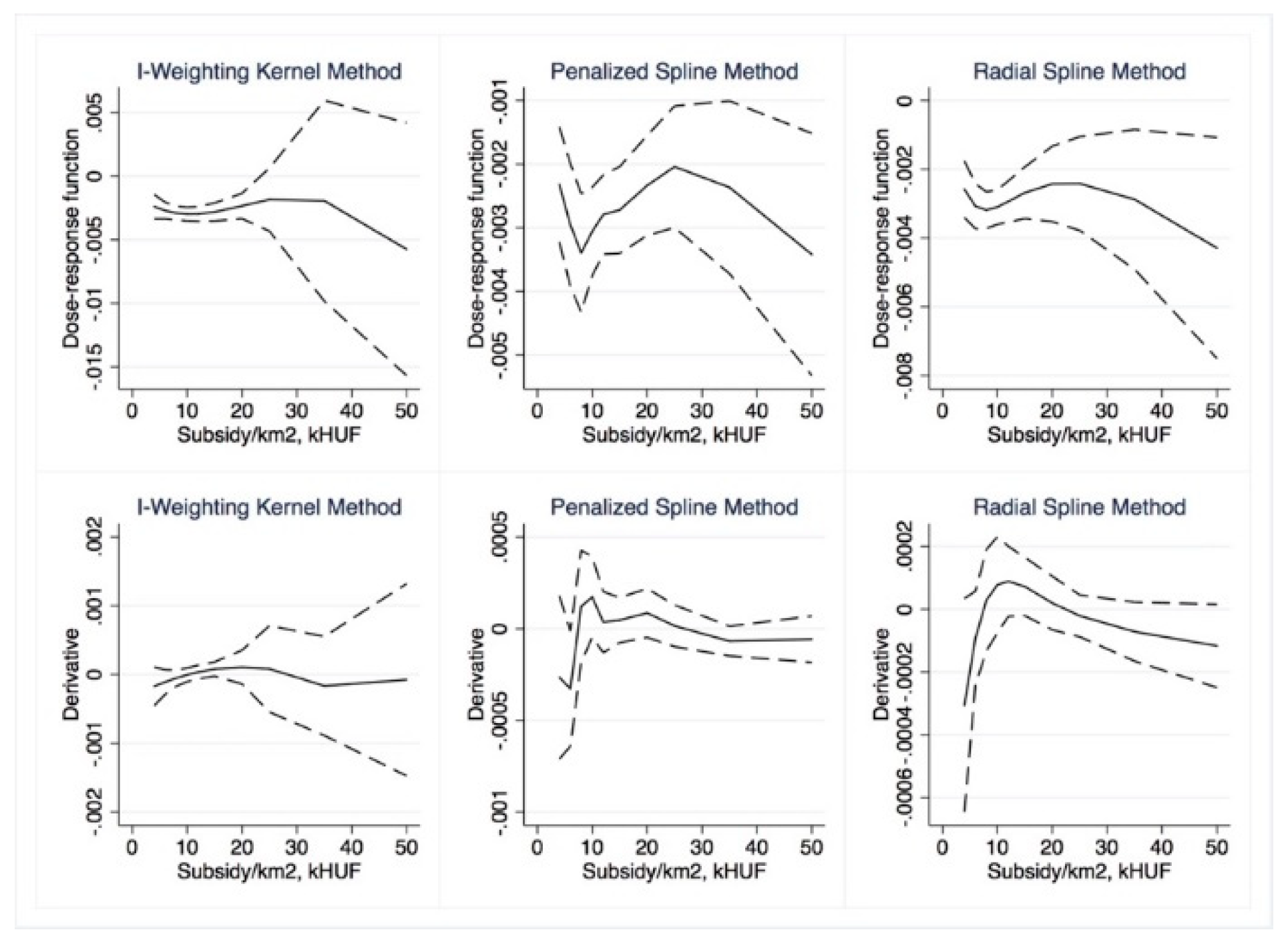
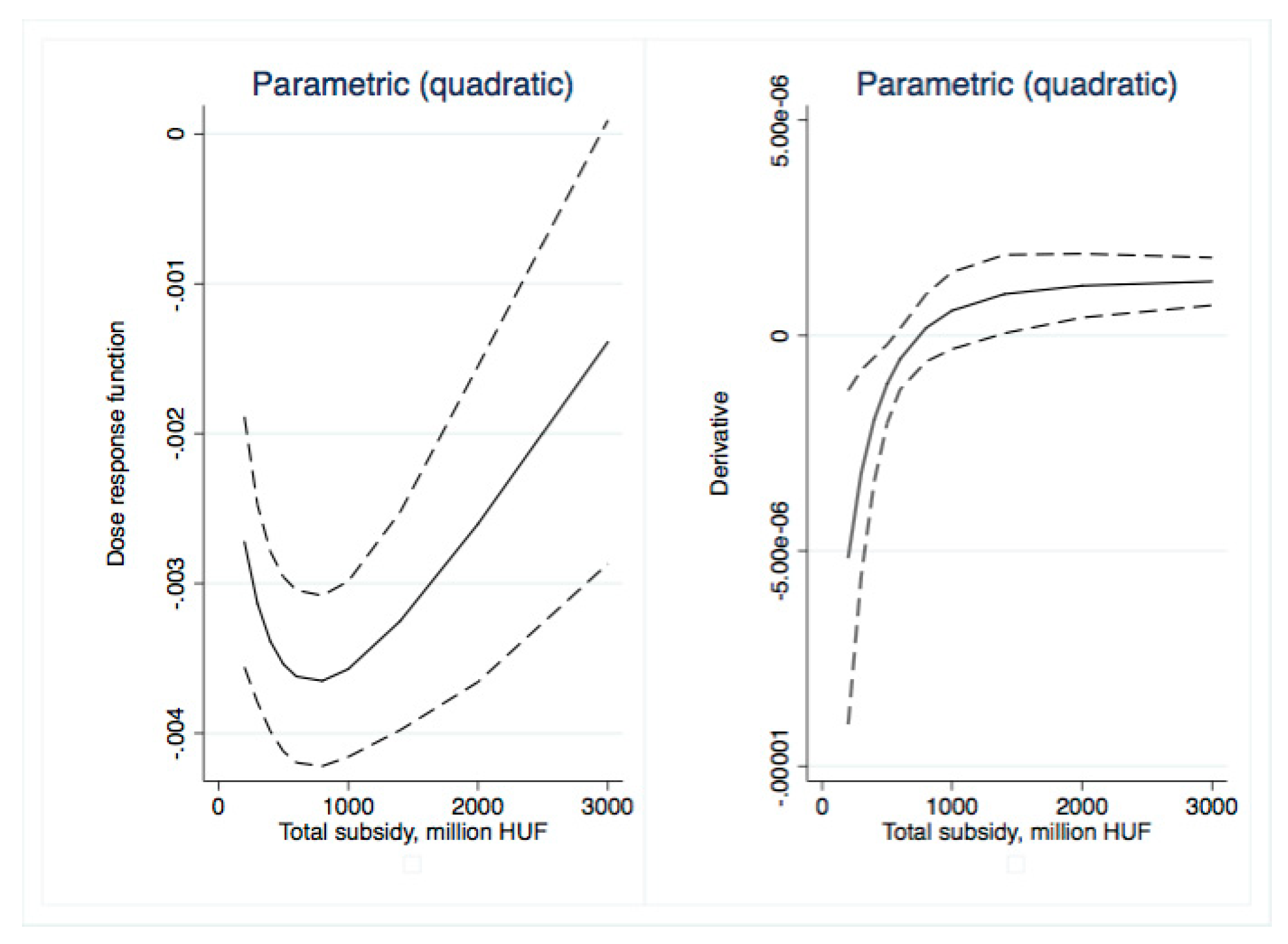
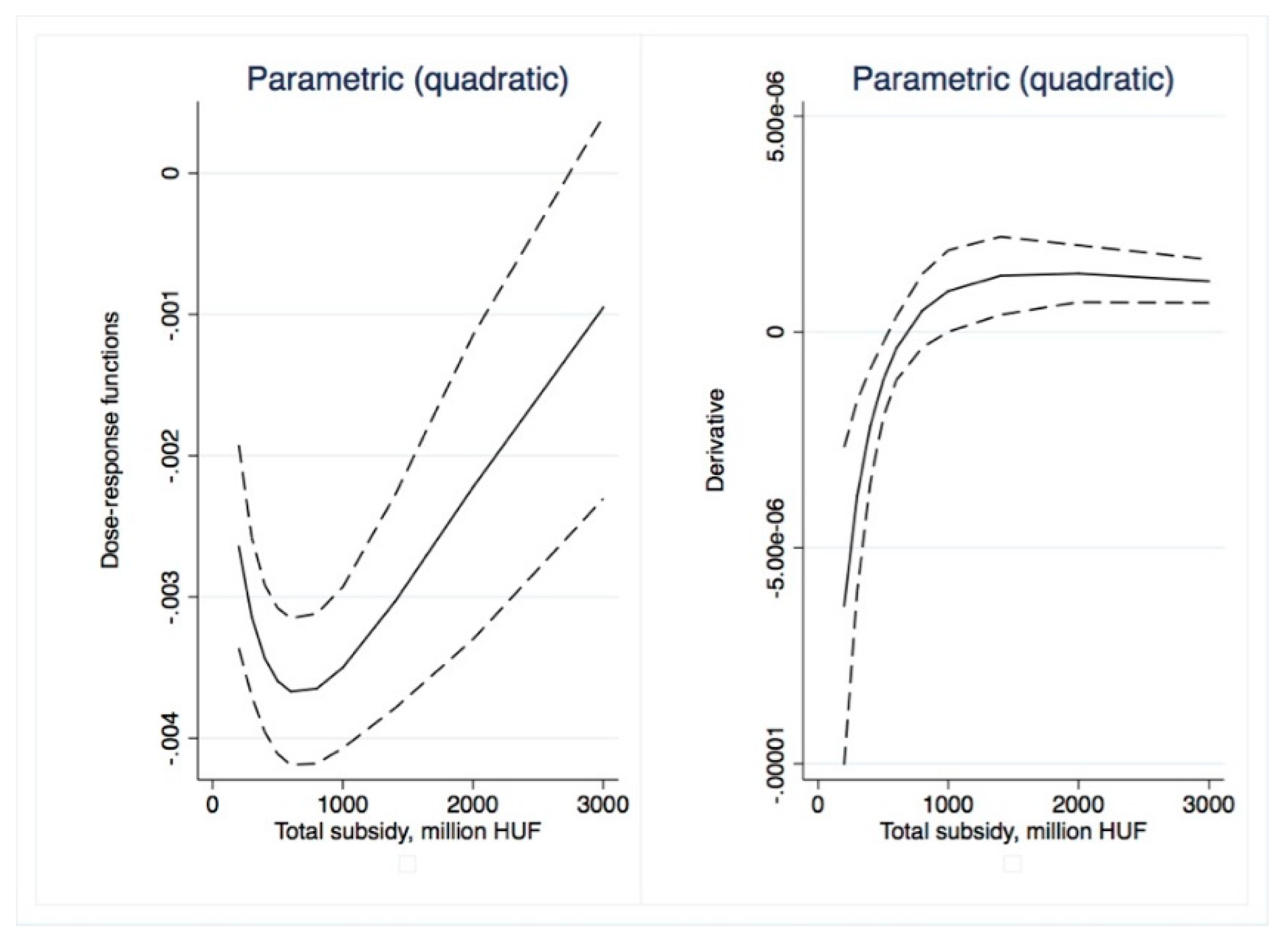
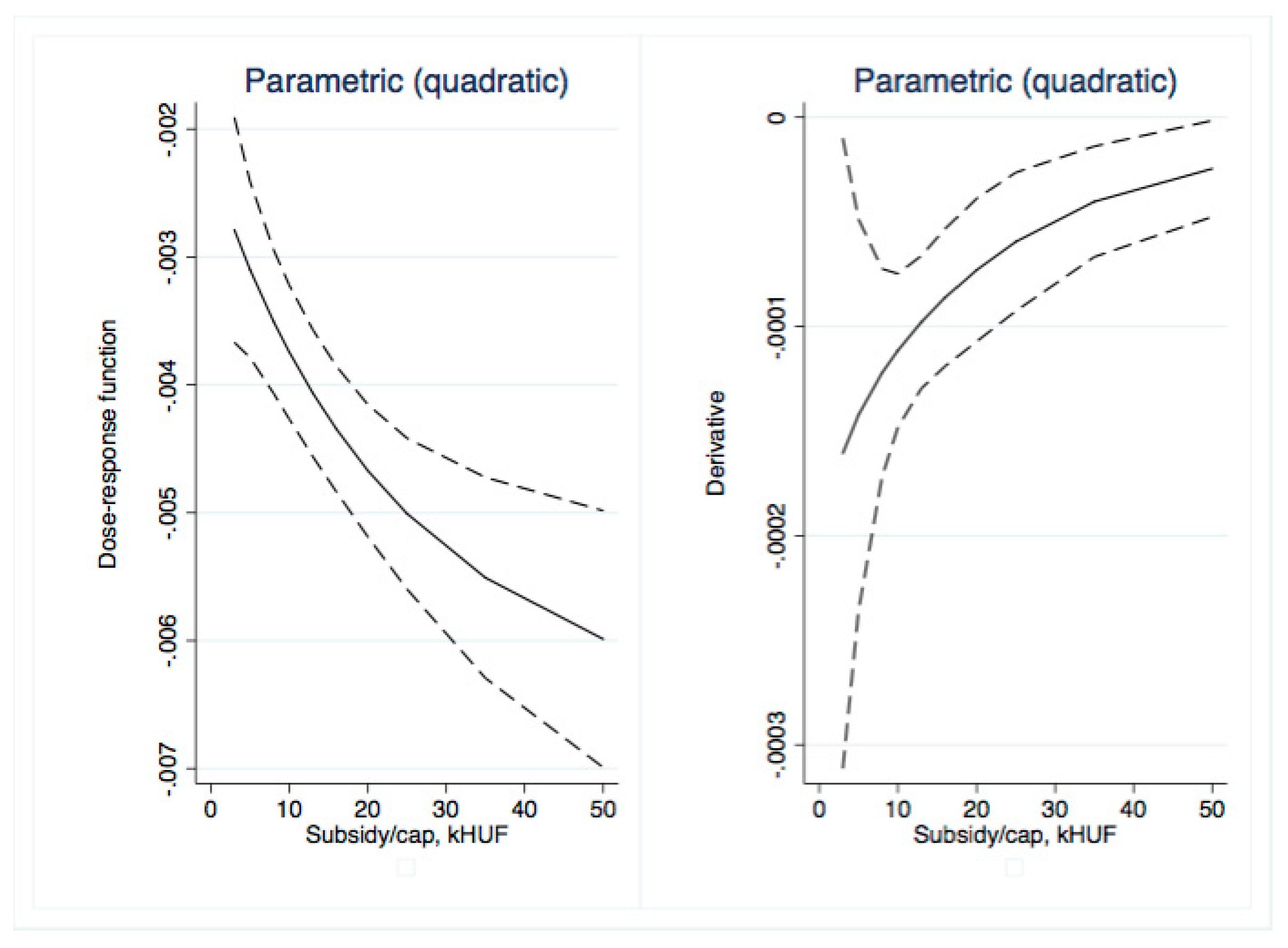
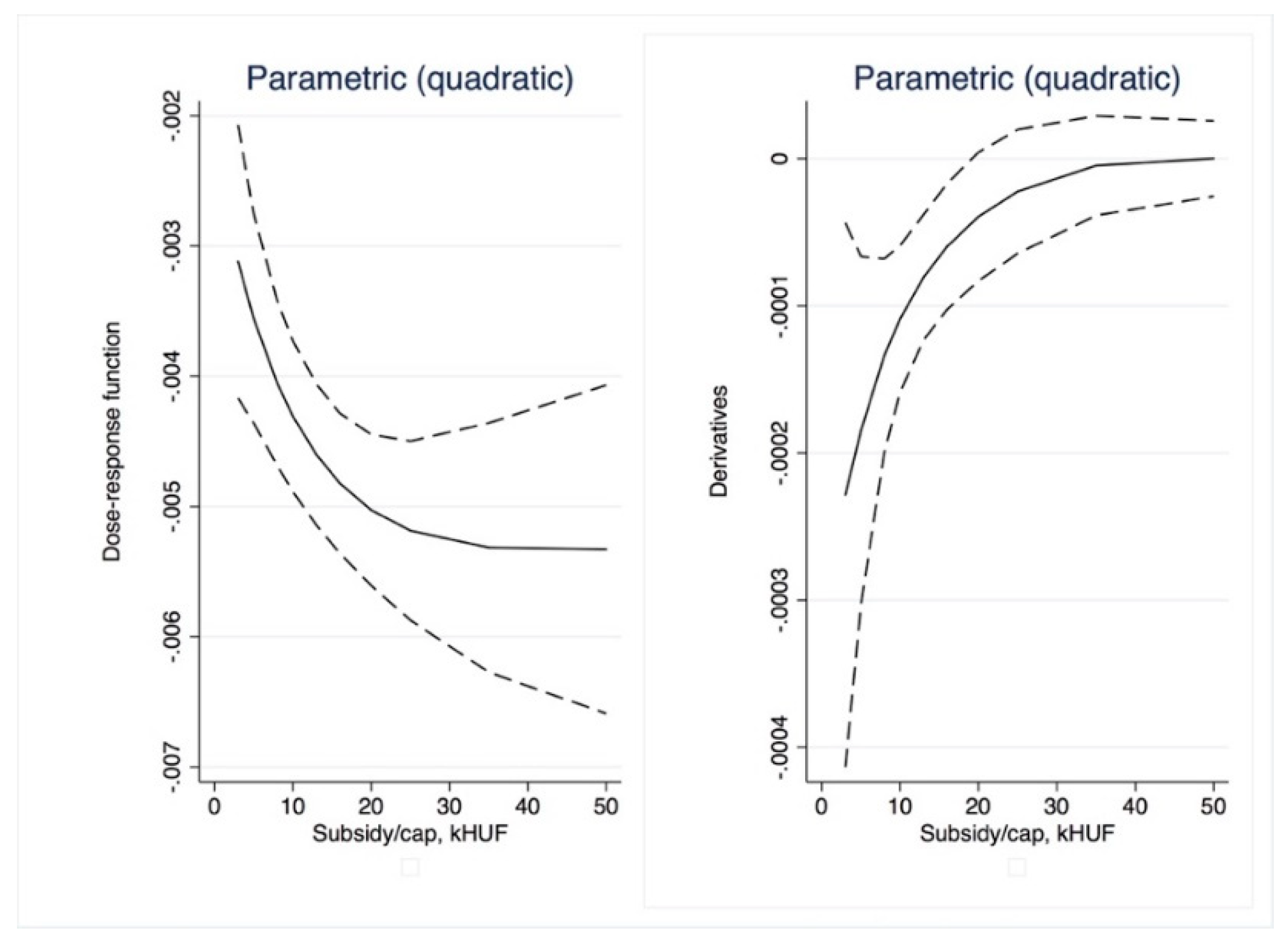
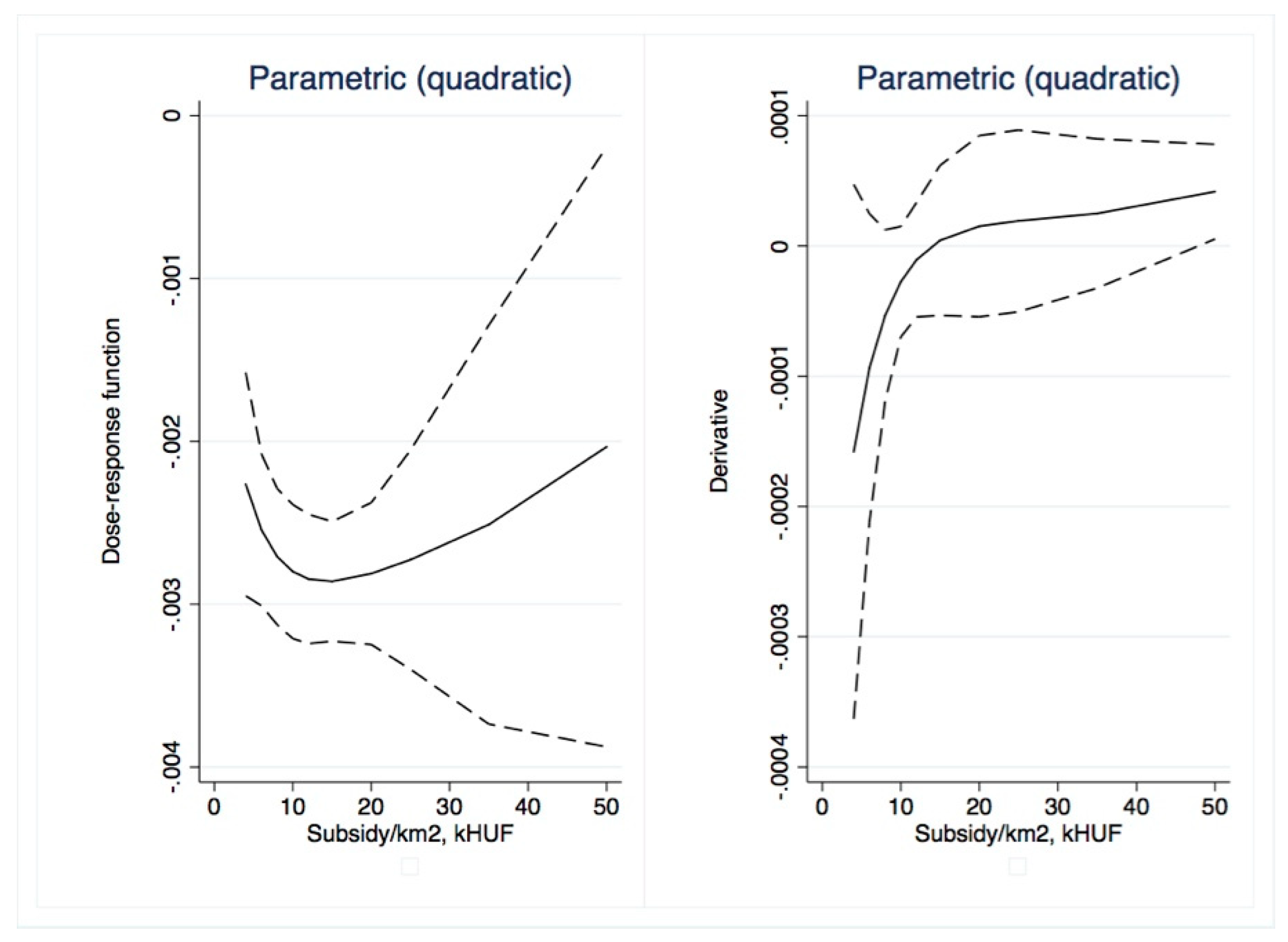
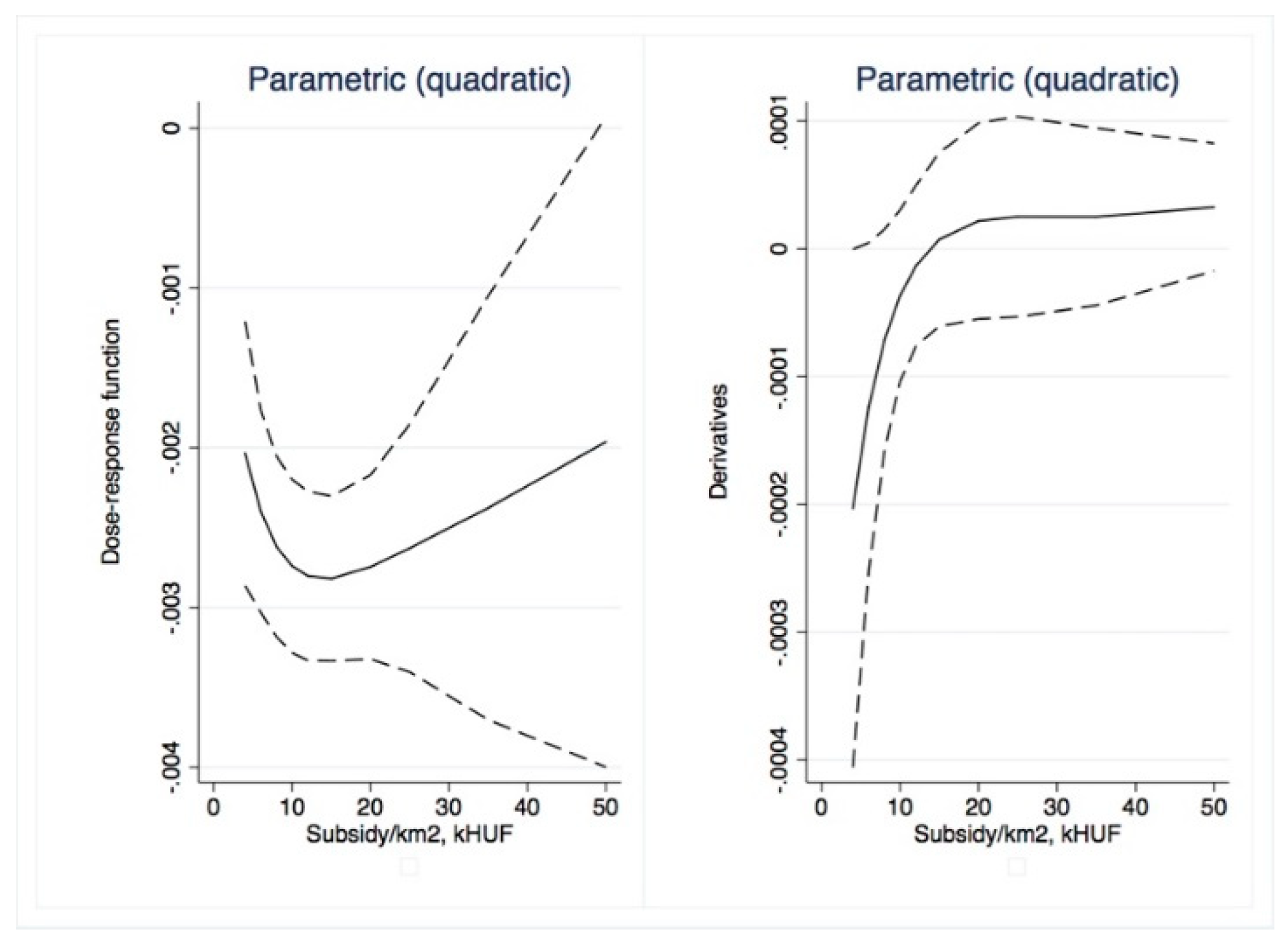
Dose–response and average treatment effect functions are then derived. For the research described in this paper, we employed the semi-parametric approach using Inverse Weighting Kernel, Second-Order Penalized Spline, and Radial Spline methods developed by Bia et al. [
50]. For robustness, we complemented our estimations with the (parametric) generalized linear model approach suggested by Guardabascio and Ventura [
52]. Within the parametric dose–response estimations, the balancing property is checked by dividing the treatment sample into subsamples and testing whether pre-treatment variables given a GPS score are significantly different in individual treatment intervals. The conditional expectation of outcomes is estimated using parametric methods, similar to Equation (7):





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















