1. Introduction
A reservoir is a physical structure (artificial and natural) used as water storage for water storage preservation, control, and regulation of water supply [
1]. Thus, climate change is likely to cause parts of the reservoir’s water cycle to intensify as warming global temperatures increase the rate of evaporation around the world. More evaporation is causing more precipitation on average where it leads to increasing of water level in reservoir. When a reservoir is full at the top water level because of excessive inflow, it will cause the water level to rise and increase the rates of discharge over the spillway. This event can cause flooding downstream. Flooding is one of the extreme events that has a major impact on reservoirs, especially at unregulated sites where it can directly or indirectly cause extreme losses to the public such as houses, facilities, assets, or innocent souls [
2]. The water level in all water bodies changes to some extent and the intake facility should be considered in terms of the anticipated varieties. During drought season, the water level in reservoirs will be low and abstraction might not be permitted. Though the abstraction is permitted, the water level may still not be high enough to drive the desired stream into the intake. A weir or torrent may be required to sustain an adequate water level. One major problem in current dam impact studies is the lack of a reliable model for simulating the implications of water level on the reservoir operation. It reduces the efficiency of the reservoir operation as some amount of water has to be released through the spillway to ensure the water level is below the full supply level. In forecasting reservoir water levels, two methods can be applied, which is to weigh the model utilizing the water level’s natural factors and to acknowledge the natural factors effecting historical water level to anticipate future levels [
3]. Essentially, utilizing historical water level information can altogether diminish the inconsistency between factors in a model. Also, the importance of prior knowledge of water level will give benefit to the operator regarding the optimal draw of the water level and sustainable plan for hydropower generation. Therefore, this paper focuses on forecasting changes on water level using Machine Learning (ML) algorithms.
The term ML means to facilitate machines to review without programming them explicitly. In particular, the performance of ML in intelligence tasks is largely due to its ability to discover a complex structure that has not been defined prior [
4]. There are four general ML methods [
5,
6]: (1) Supervised, (2) unsupervised, (3) semi-supervised, and (4) reinforcement learning methods. The difference between supervised and unsupervised learning is that supervised learning already has the expert knowledge to develop the input/output [
7]. Meanwhile, unsupervised learning only has the input and the model will learn the hidden structure or data distribution to produce the output as cluster or feature [
8,
9,
10]. The aim of ML is to allow machines to predict, cluster, extract association rules, or make decisions from a given dataset [
11]. Over the past years, there has been numerous techniques employed in forecasting the hydrological events. Previously, the tools to forecast reservoir water level used conventional approach of linear mathematical relationships based on operator experience, mathematical curves, and guidelines [
12]. However, due to the complexity and lack of access to the data, overestimating parameters and high missing values in data cause poor performances and undermining of numerical models. With regards to these issues, the use of ML approaches has been introduced, on the condition of improved results in modelling nonlinear processes and forecasting than traditional models, such as moving average methods [
13,
14,
15]. The core advantage of this modelling is the skill of the software to plot the input–output patterns without the aforementioned expertise of the factors affecting the forecast parameters [
16,
17]. Hence, researchers have since started to practice this ML to predict variety of modelling approaches and parameters to improve the accuracy and reliability of describing the predicting model.
As such, numerous researchers used ML to forecast water level such as Artificial Neural Networks [
18,
19], Support Vector Machines (SVM) [
17,
19,
20], Adaptive Neuro-Fuzzy Inference Systems (ANFIS) [
17,
18,
19,
20], Radial Basis Neural Networks (RBNN) [
20], Generalized Regression Neural Networks (GRNN) [
20], Radial Basis Function-Firefly Algorithm (RBF-FFA) [
21], and Cuckoo Optimization Algorithms [
18]. Furthermore, few researchers have also used hybrid and improvised models such as Wavelet-Based Artificial Neural Network (WANN) and Wavelet-Based Adaptive Neuro-Fuzzy Inference System (WANFIS) [
22] and Least Squares Support Vector Machine (LSSVM) [
23]. Damien [
24] stated that all approaches of ML are within the same range as they all showed decent prediction in different scenarios and the quality of data used. However, the downside of using these ML techniques, such as ANN and ANFIS, is the outcome dissimilarity that depend on the complexity of the modeled system. Therefore, new ML approaches has been introduced in this study for forecasting the water level, which is Boosted Decision Tree Regression (BDTR). This BDTR has become more popular because of the simplicity of the model system. In spite of the simplicity, it can exhibit good predictive and tends to improve accuracy with minor risk of less coverage.
The major aim of the study is to provide the operator of the reservoir with accurate water level forecasting tool and investigate different modelling approaches like Boosted Decision Tree Regression (BDTR), Decision Forest Regression (DFR), Bayesian Linear Regression (BLR), and Neural Network Regression (NNR) and the effectiveness of these algorithms in learning the parameter pattern of water level. Secondly, the objective of this study is to assess and evaluate different scenarios and time horizons to find the most accurate and reliable model. Thirdly, this study is essential for industrial activities and progress, and better forecasting accuracy for water level would help generate better operation policies for the reservoir, which leads to better condition for water users including the business of agricultural process, industrial activities, and hydropower generation. As a result, the accurate forecasting for water level will positively affect for better planning for all related industrial and business activities. In a nutshell, the motivation of this study is necessary for predicting/forecasting the water level in the reservoir as it is an important variable for the decision-maker or the operator of the reservoir to know in order to be able to optimize the water resources planning.
3. Results and Discussion
This study aimed to forecast the water level at time t (for seven days ahead) mimicking the closest values to actual by using four ML’s algorithm (BDTR, DFR, NNR, and BLR) for both SC1 and SC2 and the performance was accessed for each model for seven days. Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Relative Absolute Error (RAE), Relative Squared Error (RSE), and Coefficient of Determination (R2) was the indexed used to validate the performance of each model. All of the model was then optimized in order to improve accuracy by tuning the hyperparameter and learning rate of each model. The thorough results are defined in the following sections.
3.1. Models Performance and Optimization for SC1 and SC2
Table 3 (represent SC1) and
Table 4 (represent SC2) summarizes the metrics for each model for both result of train and tuning hyperparameter. Column 1 in
Table 3 and
Table 4 presents the one-day-ahead forecasting of the water level, column 2 presents the train model, and column 3 presents the hyperparameter, which searches for a configuration that results in the best performance across different hyperparameter configurations. As summarized in
Table 3 and
Table 4 for study location at Kenyir Dam, the average performance of the correlation coefficient was 0.99 and 0.95 for training and tuning hyperparameter, respectively.
For SC1, all models are able to perform well in forecasting the water level. In the comparison between four models used, the outcome of the results showed that the BLR outperformed the other models for both training and tuning. By comparing the scenarios in BLR, it is clear that the model performs better in predicting WL+1 in terms of R compared with its performance in predicting WL+7. RMSE and MAE for BLR also shows much a lower value of WL+1 (RMSE = 0.090613, MAE = 0.044009) than the others model, which indicates that the smaller the result, the better the performance of the model shows.
For SC2 in
Table 4,
R² shows that the performance decreasing along the water level one day ahead. This not only happens in one ML Algorithms, the coefficients of determination for all model (DFR, NNR, BLR, and BDTR) have the same pattern. Hence, water level for the first day (WL+1) is more accurate in forecasting for all the ML Algorithms because the nearest
R² value to 1 means there is a perfect fit. In addition, the BDTR model gives the best performance in forecasting water level compare to other ML algorithms. When referring to
R², BDTR has the highest value for training (0.999368, 0.997656, 0.995418, 0.993893, 0.99146, 0.990325, 0.988958) followed by tuning hyperparameter (0.99992, 0.999774, 0.999518, 0.999279, 0.998875, 0.998596, 0.998363) to improve the model accuracy.
Referring
Table 3 and
Table 4, the result for MAE, RMSE, RAE, and RSE is increased along the water level one day ahead. This shows that WL+1 for each ML Algorithms has the same pattern, which is increasing, and it means that the lowest value gave the better performance. Therefore, the rank from highest to lowest performance for other models in SC1 is BLR, BDTR, DFR, and NNR. Meanwhile, for SC2, the rank performance is BDTR, DFR, BLR, and NNR. The results of each model for the time horizon between two days to six days prediction are given in
Appendix A and
Appendix B.
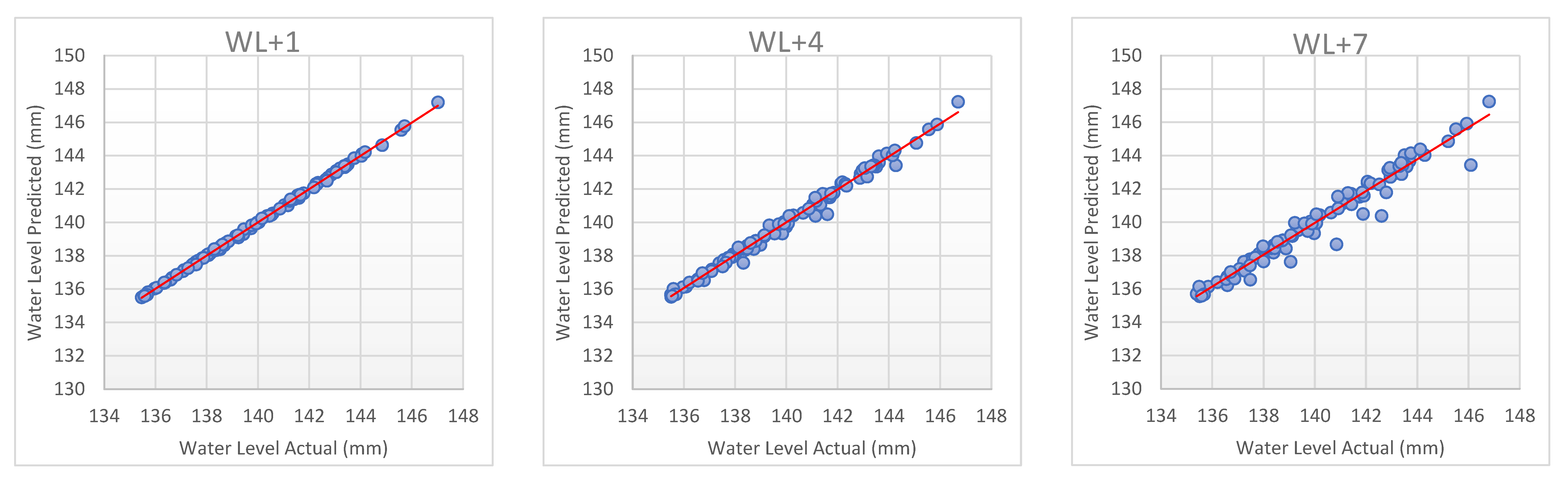
3.2. Scatter Plot for Best Forecasting Model Performance
Figure 8 and
Figure 9 represent scatter plot the best models of dataset. WL+1 for both scenarios of the dataset shows that the plot/distribution is close to each other compared to the next day of water level until WL+7. The scatter plot of each model for the time horizon are given in
Appendix C and
Appendix D. It can be seen clearly in scenario one that BLR has outstanding performance in predicting the water level in the reservoir with a high level of precision for one day and seven days ahead. Similarly, the same performance has been noticed for scenario two when BDTR was used. These results indicate that these two models can be used to predict the expected changes in water level one week ahead.
3.3. Uncertainty Analysis of Best Model of SC1 and SC2
UA of the best model for SC1 is BLR while SC2 is BDTR was calculated using 95PPU and d-factor.
Table 5 represent the uncertainty analysis results for seven days and one day ahead of forecasting water level.
Table 5 specifies that about 95.42%, 95.41%, 95.37%, 95.36%, 95.39%, 95.35%, and 95.35% of data for the best BLR in SC1 and 96.12%, 96.1%, 95.97%, 95.78%, 95.74%, 95.69%, 95.67% of data for the best BDTR in SC2 relate to WL+1, WL+2, WL+3, WL+4, WL+5, WL+6, and WL+7, respectively. Hence, the d-factor has values of 0.000075605, 0.000075771, 0.000075350, 0.000075458, 0.000076068, 0.000075577, 0.000075658 in SC1 and 0.000028308, 0.000029241, 0.000029441, 0.00003123, 0.000031504, 0.000031501, 0.000031828 in SC2 for WL+1, WL+2, WL+3, WL+4, WL+5, WL+6, and WL+7, respectively.
This finding of the uncertainty analysis revealed that the proposed model exhibited a high level of accuracy in predicting the water level where all 95PPU for the different time horizons attained more than 80% and the d-factor value was at a very acceptable level, which fell below this. However, in spite of such results, there is still a need for further analysis to adopt this model on another study area, which can be achieved by modifying the architecture of the proposed model since each study area has its own pattern in water level.
3.4. Taylor Diagram for Best Performance in Each Scenarios
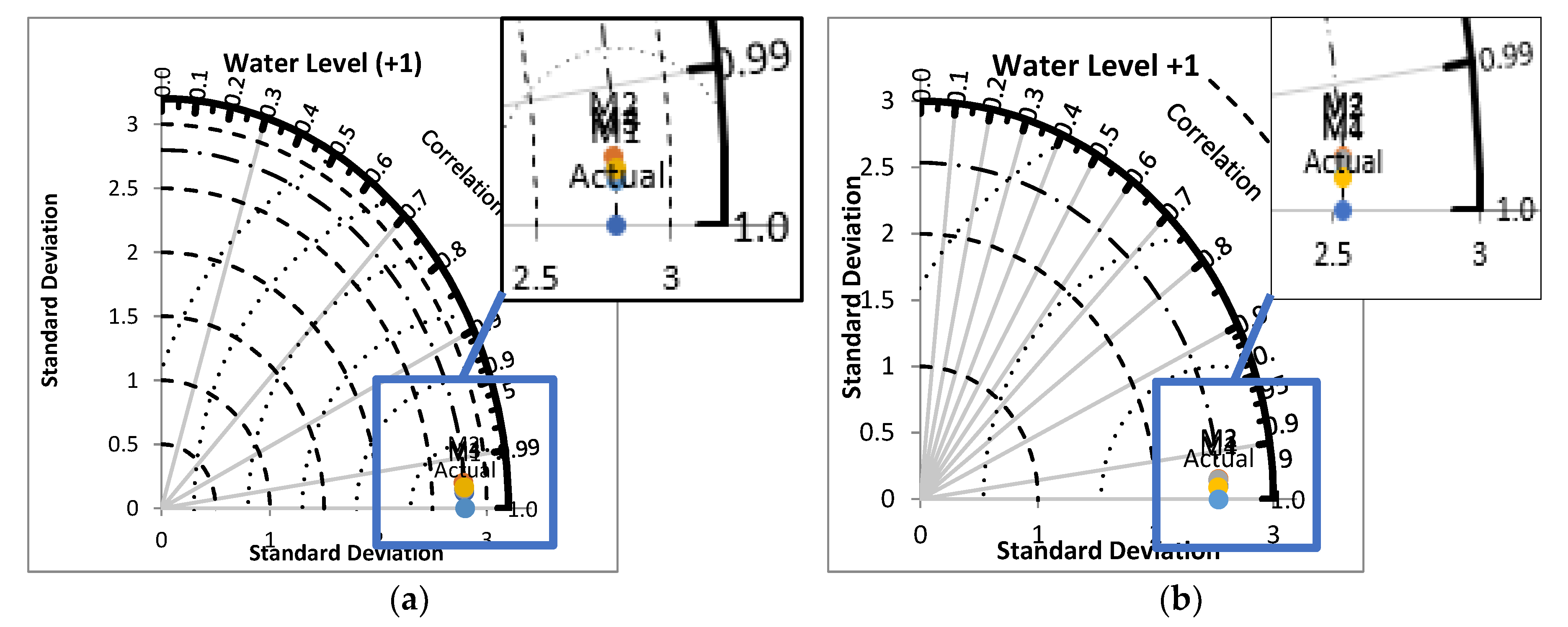
Figure 10 shows the Taylor diagram from water level one day ahead. Taylor diagrams will facilitate the comparative assessment of different models. It is used to quantify the degree of correspondence between the modeled and observed behavior in terms of three statistics: The Pearson correlation coefficient, the root-mean-square error (RMSE) error, and the standard deviation.
Figure 10a shows the four models used; namely, M1 presents BLR, M2 presents NNR, M3 presents BDTR, and M4 presents DFR. Meanwhile,
Figure 10b shows the four models used; namely, M1 presents DFR, M2 presents NNR, M3 presents BLR, and M4 presents BDTR. From the diagram, we can conclude that the most correspondence predicted to actual data is M1 for both scenarios, which represents BLR in SC1 and BDTR in SC2 as the closest to the actual value.
In can be seen based on the correlation and standard deviation between the actual water level and the predicted one from the proposed model that the developed model is not only capable of predicting the changes in water level accurately during the entire dataset, but also the standard deviation of predicted data is close to the actual one. This indicates that the proposed model is capable of mimicking the variation in the dataset.
3.5. Accuracy Improvement
In order to compare between scenario one and scenario two, the percentage of accuracy improvement formula was used as follow:
where
R²
SC1 is the value of the coefficient of determination given by SC1, while
R²
SC2 is the same coefficient of determination given by the proposed SC2. This comparison of R² from the best model of BDTR for the both scenario. Referring to
Table 6, this shows that SC2 has the best result rather than SC1 since the accuracy improvement is positive. The result is the accuracy improvement getting better among the water level for the next seven days. In can be concluded that by introducing scenario two, there is noticeable improvement in predicting the changing in the water level of the reservoir. In addition to that, the accuracy improvement percentage after introducing scenario two shows that the model performs better in predicting water level in different lead times where the highest percentage of accuracy improvement is achieved when the model is used to predict the water level one week ahead.
4. Conclusions
This study investigated different Machine Learning techniques such as Boosted Decision Tree Regression (BDTR), Decision Forest Regression (DFR), Neural Network Regression (NNR), and Bayesian Linear Regression (BLR) to identify the most accurate model for water level prediction based on daily measured historical data from 1985 to 2019. Different time horizons were examined from one day ahead to seven days ahead. The results showed that all the models performed well and can mimic the actual values, however, the BLR model outperformed all other models for SC1 where the predicted values were found to be close to the coefficient of determination of 1 for forecasting water level. Meanwhile, BDTR outperformed all other models for SC2. The best model performance of R² for SC1 is 0.994992, 0.9917, 0.990856, 0.984186, 0.97562, 0.967717 while for SC2 is 0.999368, 0.997656, 0.995418, 0.993893, 0.99146, 0.990325, and 0.988958 for each water level, respectively. After conducting uncertainty for the proposed models, using 95PPU and d-factor analysis, it can be concluded that the BLR (for SC1) and BDTR (for SC2) show high satisfaction in degree of uncertainty. In this study, in spite of introducing few inputs to the proposed models, two input parameters (water level and rainfall) used in SC1 and three input parameters (water level, rainfall, and sent out) used in SC2, it can be seen that the models performed well in predicting the changes in water level with a high level of accuracy. The proposed models can be used as a tool in operating the reservoirs in Malaysia efficiently and could be an effective method for water decision makers by relying on the highly demanding new technologies such as Artificial Intelligence. However, further study is needed by including more input parameters such as the change in rainfall due to climate changes in order to improve the accuracy of the model and also investigate the impact of the projected rainfall on the water level of the reservoir.


 and
and 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











