1. Introduction
Rising consumption is leading to increasing resource use and detrimental environmental impacts [
1]. Meanwhile, decision makers at all governmental levels are faced with the challenge of defining measures to reach environmental targets and reduce environmental impacts of consumption. For example, the United Nations Sustainable Development Goal (SDG) 12, Sustainable Consumption and Production, has a target of achieving sustainable management and efficient use of natural resources by 2030 [
2,
3]. This goal is measured against several indicators, including material footprint and domestic material consumption (DMC). Moreover, the SDGs are expected to be met through actions at all governmental levels [
4]. In order to successfully reduce consumption and find relevant priority product groups, it may be helpful to quantify regional consumption levels so that targets are region-appropriate [
5]. Region-specific consumption data may be key to identifying suitable strategies to reach sustainability goals. In this study, we use the term region to mean a geographic area smaller than the national level, like a county or municipality.
There are challenges to quantifying region-specific consumption values, including data scarcity and uncertainties as well as data confidentiality issues. Data can be expensive to procure. Many consumption quantification efforts produce results at the national level, often based on economic or expenditure data, which are then extrapolated to the regional level using per capita values [
6] or applied to specific consumer types (e.g., households) [
7,
8]. Household consumption may also be quantified through household budget surveys [
9,
10]. Some may use bottom-up assessment [
11] or a mix of top-down and bottom-up methods [
12,
13,
14,
15], often using multiregional input–output tables [
16,
17]. In rare cases, region-specific economic data are used to quantify region-specific consumption and its impact [
18,
19]. Although per capita values are often used to downscale national values to the local level, these values may be misleading as urban and rural areas may have different consumption patterns [
11,
20]. Moreover, urban areas have been shown to have different consumption patterns based on their profile (e.g., industrial, service-based), which may indicate a need for more region-specific extrapolations [
21].
Two keys to meeting the SDGs would be to (1) identify materials or products that are consumed in such quantities that reduction in their consumption would make a material difference and then (2) identify measures that the region can take, encourage, or require that will reduce the quantity of consumption [
22]. Identifying these materials in a rigorous way can be a time-consuming and expensive process that can test the resources of the region. The purpose of this investigation is to search for proxies for more detailed analysis that are sufficiently accurate to enable effective decision making within existing financial and time constraints.
To this end, we investigated four alternative methods of downscaling national-level consumption data to different regional levels. Three of the investigated methods connect several economic sectors to each product type. We tested the use of the number of employees working within those sectors in the region to extrapolate from national DMC to regional levels. We then compared those values to consumption results using per capita values (the fourth method) as well as to reported regional consumption values for certain product types. Our aim was to identify a simple method to downscale national-level data to the local level, and, using products where such data are available, to see if the values produced are close enough to the reported values to indicate that use of the method would enable good decision making at a lower cost.
2. Materials and Methods
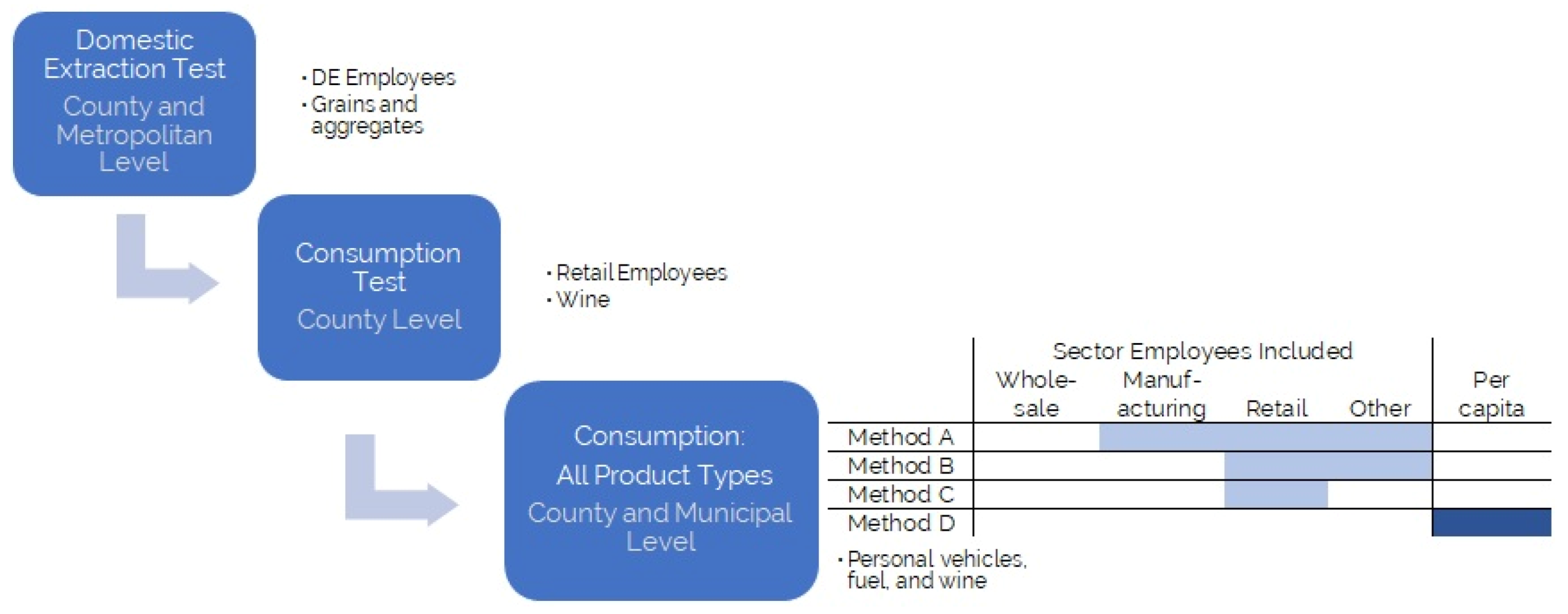
The investigation in this paper was performed by testing different options for extrapolating national consumption data to the regional level. To do so, several steps were needed; each step is described in detail in the following subsections and presented in
Figure 1.
Our first aim was to evaluate the use of employees as a suitable proxy for downscaling national levels. We tested using the number of employees working in domestic-extraction-related economic sectors in a region to extrapolate the domestic extraction (DE) for that region from national level data. The benefit of using DE was that reported values of extraction at the national, county, and metropolitan scales are available. Using these data, we could see at which scale(s) it is possible to base the estimate of extraction on the number of employees.
Then, we tested whether we could use the number of retail employees to estimate the consumption of a specific product for which we had the reported values of consumption at the county level. Finally, we downscaled national consumption for the year 2010 (1212 product types) to the county and municipal levels using three different sets of employee types and compared the results to per capita values as well as reported values for certain products, including personal vehicles and fuel.
2.1. Terminology
In this paper we refer to several nomenclatures. The statistical classification of economic activities in the European Community (NACE) provides a four-digit code for economic activities, where the first two digits describe the economic activity category and the second two digits provide more specificity (e.g., NACE category 52 is retail trade, NACE code 5242 is retail sale of clothing). In this paper, we use version Rev 1.1 (2002) [
23].
The combined nomenclature (CN) is a system of codes used to classify goods for import and export, used for trade statistics and custom duties [
24], where the first two digits indicate the product category (e.g., 04 is dairy), the next two digits indicate the product type (e.g., 0406 is cheese and curd), and the final four digits add specificity (04064050 is Gorgonzola). The CN corresponds to the Harmonized System used in the United States for trade. The DMC is reported in CN codes and provides annual data on consumed materials and goods at the national level. DMC includes raw materials, intermediate goods, and final goods. All of the extrapolation methods performed in this paper use final goods that have been transformed from raw or intermediate materials using the Urban Metabolism Analyst (UMAn) method [
25], but any transformation method would be acceptable.
The European Union uses the Nomenclature of Territorial Units for Statistics (NUTS), where NUTS1 represents major socioeconomic regions, NUTS2 defines basic regions for application of regional polices, and NUTS3 represents smaller regions for specific diagnoses [
26].
2.2. Extrapolation of Domestic Extraction from Number of Employees
Domestic extraction is the amount of raw material extracted from the natural environment for use in the economy [
27]. Globally, as much as 90% of DE is used domestically [
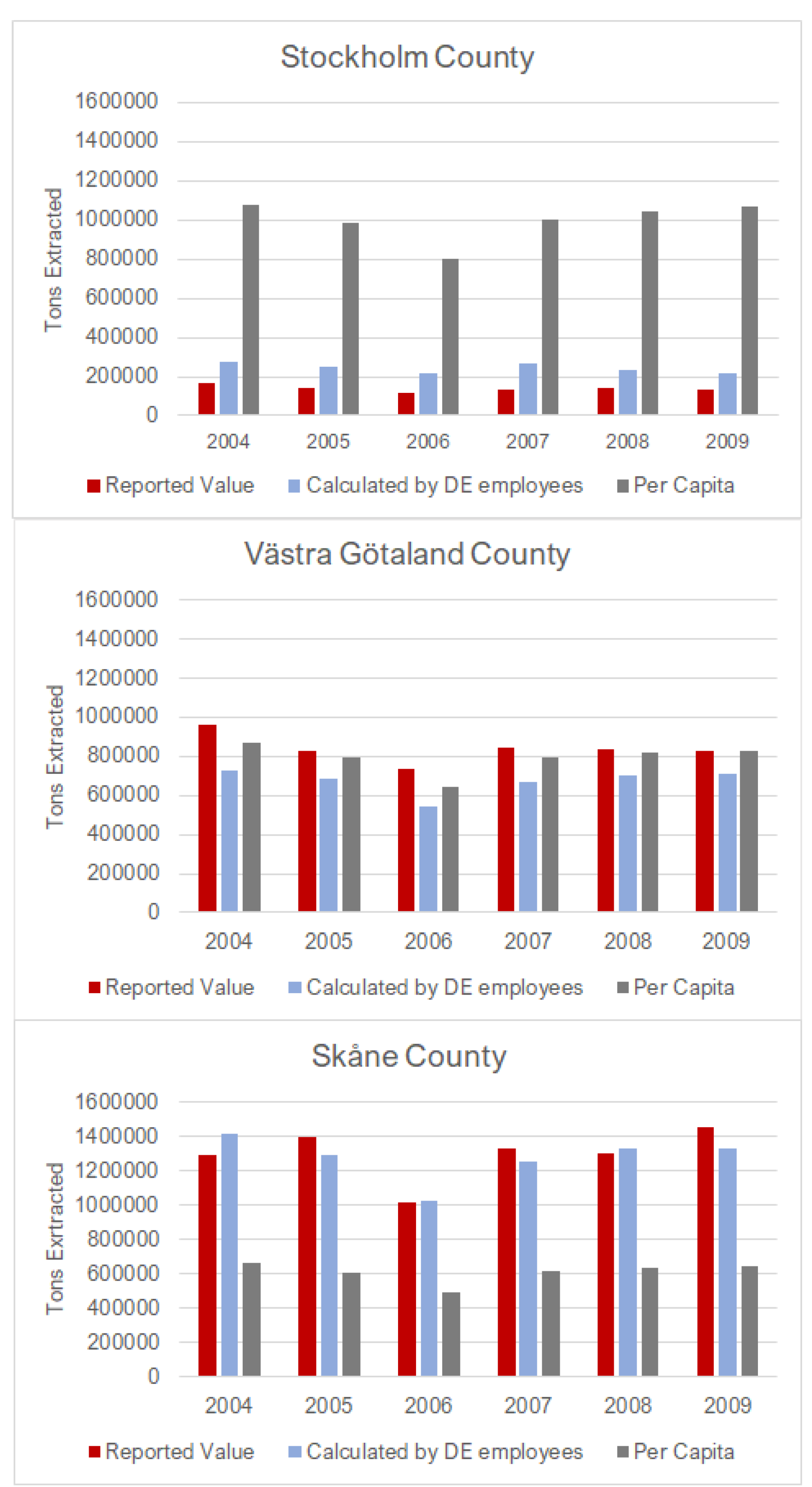
28]; in Sweden, the quantities of extraction are documented by Statistics Sweden (SCB) by region. We estimated regional DE values using winter wheat, spring barley, and construction aggregates, as these are products that were extracted in all regions in Sweden. Data at the county and national level for the years 2004 through 2009 were used.
The numbers of employees working in either agriculture (NACE code 0111, “growing of cereals”) or quarrying/gravel extraction (NACE code 1421, “operation of gravel and sand pits”) within each respective NACE code for each metropolitan area and region (NUTS3) and for the country as a whole were found using national statistics. The share of national employees working in each NACE code in each region was calculated (the “employee ratio”) as shown in Equation (1).
where
ERn,r is the employee ratio for NACE sector
n and region
r, En,r is the number of employees for NACE sector
n and region
r, and
En is the total number of employees in the country for NACE sector
n.
The total masses of winter wheat, spring barley, and aggregates extracted nationally were multiplied by the employee ratio for each geographical region, as shown in Equation (2), and compared to reported values extracted within the region as well as to per capita values.
where
DEn,r is domestic extraction for NACE sector
n and region
r,
ERn,r is the employee ratio for NACE sector
n and region
r, and
DEn is total domestic extraction in the country for NACE sector
n.
2.3. Extrapolation of Product Consumption from Number of Employees
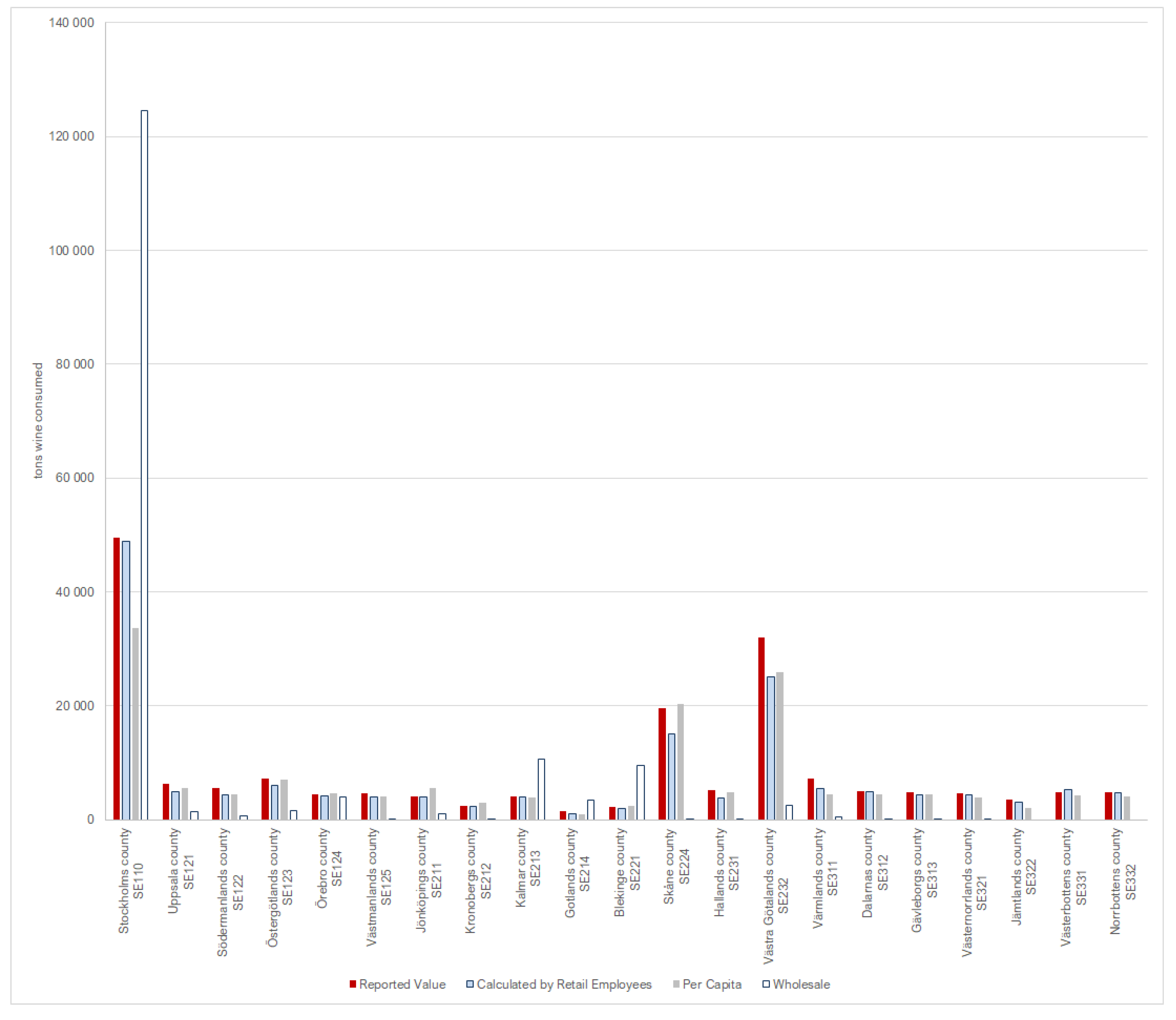
We next assessed whether employees could be used to estimate consumption (Equation (3)). To test this, we first evaluated one product that is primarily imported and for which we have reported values of consumption. The sale of alcohol is regulated and limited to sale by a single, state-owned retailer in Sweden, which allows for accurate data availability. Wine falls under the category of alcoholic beverages and is mostly imported. The DMC of wine (CN2204) for the year 2010 was extrapolated to the regional (county) level using the employee ratio for employees working in NACE code 5225, “retail sale of alcoholic and other beverages”, and compared to reported values consumed at the regional level published by the Swedish Public Health Administration.
where
n = appropriate for product
x sector,
Cx,r is the consumption of product
x by NACE sector
n in region
r, ERn,r is the employee ratio for NACE sector
n and region
r, and
DMCx is the total domestic consumption of product
x by NACE sector
n in the country.
2.4. Extrapolation of Total Regional Consumption
Expanding the extrapolation method using employees required two steps: (1) transforming DMC into final goods, described in
Section 2.4.1, and (2) associating CN product types with NACE economic sectors, described in
Section 2.4.2. The regional employee ratio of each economic sector was then used to extrapolate national-level consumption to the region of interest, described in
Section 2.4.3. We also extrapolated regional consumption using per capita values, described in
Section 2.4.4. The extrapolation was performed at both the county and municipal levels.
All extrapolations were summed to find the total tonnage of all consumption in the region. This was done with the intention of seeing if any of the methods resulted in outliers or unusual results. The extrapolated values were also compared to known values of consumption for specific products. These reported values were primarily collected through Statistics Sweden (SCB). Reported values included personal vehicles (CN code 8703), based on the number of newly registered vehicles in each county or municipality, multiplied by the average mass of a personal vehicle in Sweden in 2010 (1400 kg) [
29,
30]. Total volumes of delivered fuel (CN code 2710) are also collected at the county and municipal levels. These volumes were converted to tons using density and compared to the extrapolated values. Reported values for wine consumption (CN code 2204), as described in
Section 2.3, were available at the county level.
2.4.1. Transformation of Products into Final Goods
National statistics offices collect DMC data; however, product data are often in the raw or intermediate state. For example, while values of aluminum consumption are reported, the identity of products produced (like automobiles) from the consumed aluminum are not reported. Transformed DMC, where DMC has been transformed into final goods, must be used for this step to get an accurate understanding of what is being consumed.
We used national-level results from the Urban Metabolism Analyst (UMAn) model for Sweden [
21,
25,
31], where DMC is transformed into final goods using production and transport data. The model quantifies final good DMC by calculating domestic extraction plus imports, minus exports, using statistical transport and trade data. Transformation of raw goods and intermediate products into final goods is based on the economic activities found in the area of study. Final goods are categorized using the CN. The UMAn model results used were for the year 2010, as this was the most recent year available with corresponding reported values. Any transformation method can be used, however, and the extrapolation methods assessed in this paper are not limited to the UMAn model.
2.4.2. Identifying Relevant Economic Sectors for Product types
In this step, we linked CN4 product types to NACE economic sectors using international trade statistics. There are over one thousand products at the CN4 level, and there is no current linkage between the two nomenclatures. To identify the economic sector that sells or uses the good manually would be inefficient and subjective. Trade statistics report which NACE codes import which CN products, which means that trade data can be used to identify this link. Since we are investigating consumption, the relevant NACE codes are those that represent the end of the supply chain prior to consumption, and thus a selection of suitable NACE codes was necessary. For example, wholesale companies are often centralized and not located in all regions, but they are often responsible for importing goods. Results are likely to be misleading if national consumption is extrapolated to the regional level using values based on wholesale imports. Wholesale employees have therefore been excluded from this analysis.
Moreover, many importing economic sectors are manufacturers and are thus also not responsible for the end of the supply chain. With these uncertainties in mind, we tested three alternatives for identifying the most appropriate NACE code for each CN4 product type:
Method A: Use all economic sectors with the exception of wholesale (i.e., use all NACE codes except for those in category “51”).
Method B: Use all economic sectors with the exception of wholesale and manufacturing (i.e., use all NACE codes except for those in categories “01” through “36” and “51”).
Method C: Use only retail economic sectors (i.e., any NACE codes in categories “50” or “52”).
Some CN codes are linked to several NACE codes. In these cases, the mass of the CN4 was allocated to each NACE code using the import ratios. We assumed that domestically produced goods mirror the import ratios for imported goods.
2.4.3. Extrapolation of Total Regional Consumption
In the final step, final good consumption was extrapolated to the regional level using the employee ratio from each linked NACE code. First, the country DMC in tons of each CN4 product type
xi,
i = [1…
p], was multiplied by the mass fractions
ai,n going to each economic sector (NACE code)
n = [1…
m] (Equation (4)) to produce
Ci,n—the product
xi’s consumption per NACE code
n.
Then, the
Ci,n for each NACE code
n was multiplied by the
ER for that NACE code in the region. Finally, consumption
C for each region
r = [1...
q] was summed for each CN4 (one CN4 may correspond to multiple NACE codes), where
ER is employee ratio and
n is the NACE code.
This analysis was performed first at the county (NUTS3) level and then at the municipal level. All 22 counties were analyzed. Sweden has 295 municipalities, which are categorized by the Swedish Association of Local Authorities and Regions (SALAR) into nine groups based on structural parameters like population and commuting patterns [
32]; see
Table S5 for the classification system description. Three municipalities were selected from each group, with at least one municipality from each county included in the sample.
2.4.4. Extrapolation of Regional Consumption using Per Capita Values
Per capita consumption was found by taking the total consumption of final goods from 2010 [
31] and dividing the value by the population in Sweden in 2010. The per capita value was then multiplied by the population of the region to find the regional consumption. In
Section 3, per capita is referred to as “Method D”.
4. Discussion
The purpose of this investigation was to search for proxies for more rigorous analysis that are sufficiently accurate to enable effective decision making. The evaluation of extrapolation methods began with a test to see how well the employee ratio method estimated extraction as a precursor to estimating consumption. The results indicated that using an economic sector’s employee ratio may estimate domestic extraction with reasonable accuracy at the county (NUTS3) level, giving a significantly more accurate estimate of true extraction than using per capita values. This was particularly true for Stockholm and Skåne counties, which may be due to the metabolism types of these regions. For example, Stockholm County houses the Stockholm Metropolitan Area, which has a service-based economy, and Skåne is responsible for most agriculture in Sweden. This indicates that per capita calculations would not be able to capture the difference in these areas. However, both the employee ratio method and the per capita calculation overestimated the metropolitan area DE for Gothenburg and Malmö metropolitan areas. This may be due to the fact that domestic extraction of aggregates tends to take place outside of metropolitan areas [
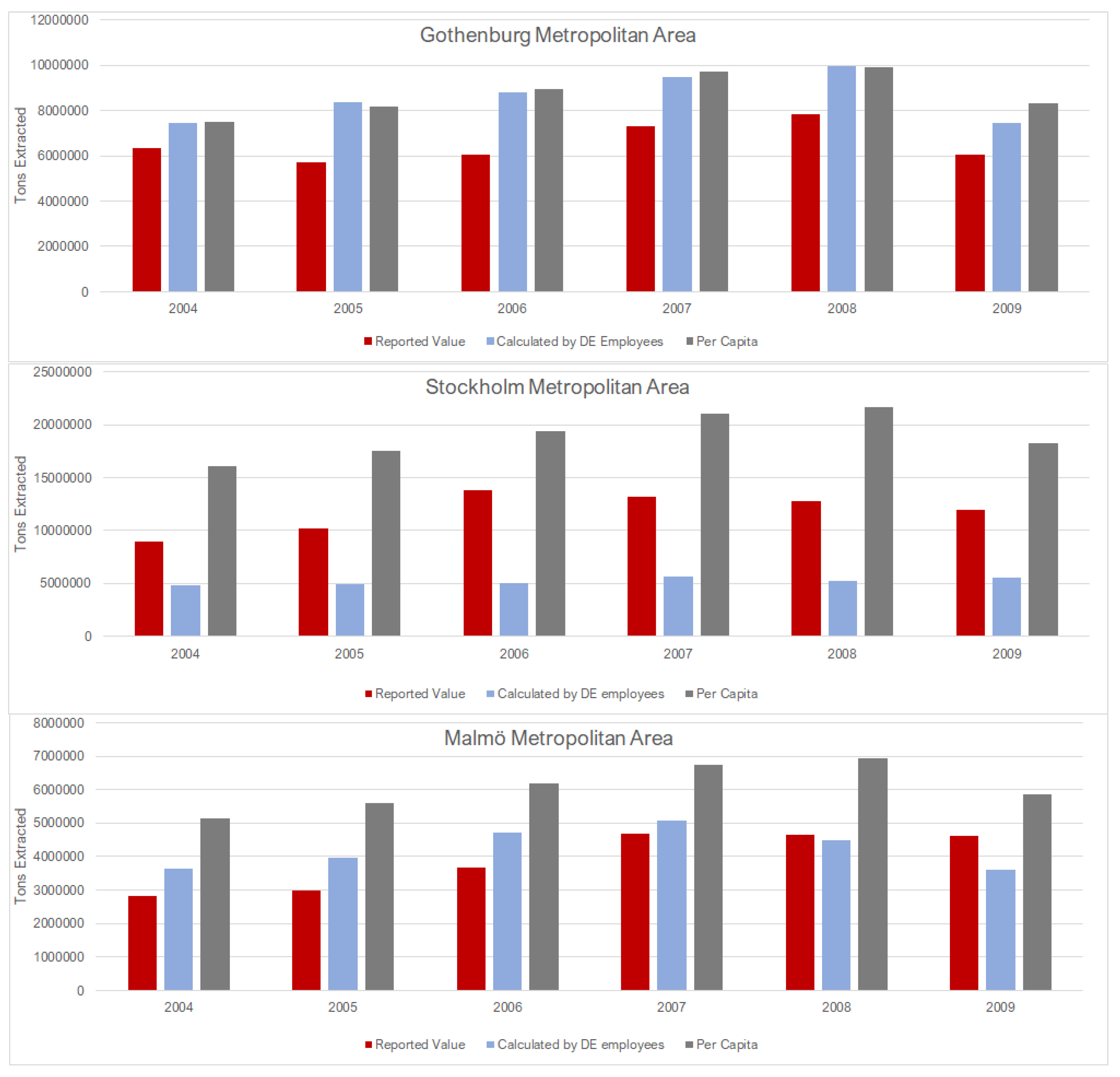
33]. Stockholm Metropolitan Area aggregate consumption was underestimated by the employee ratio, which may indicate that there are employees working for companies registered in the surrounding area that are extracting materials within the metropolitan area instead.
Wine consumption was accurately estimated using the retail employee ratio at the county level. The results show, however, that the inclusion of wholesale employees would clearly lead to a significant misrepresentation of consumption values. Given that wholesale distributors are often located in one or a few locations [
34], this would likely be the case for the majority of product types. Swedish employee data show that most employees working in wholesale NACE categories are centralized in one or a few regions.
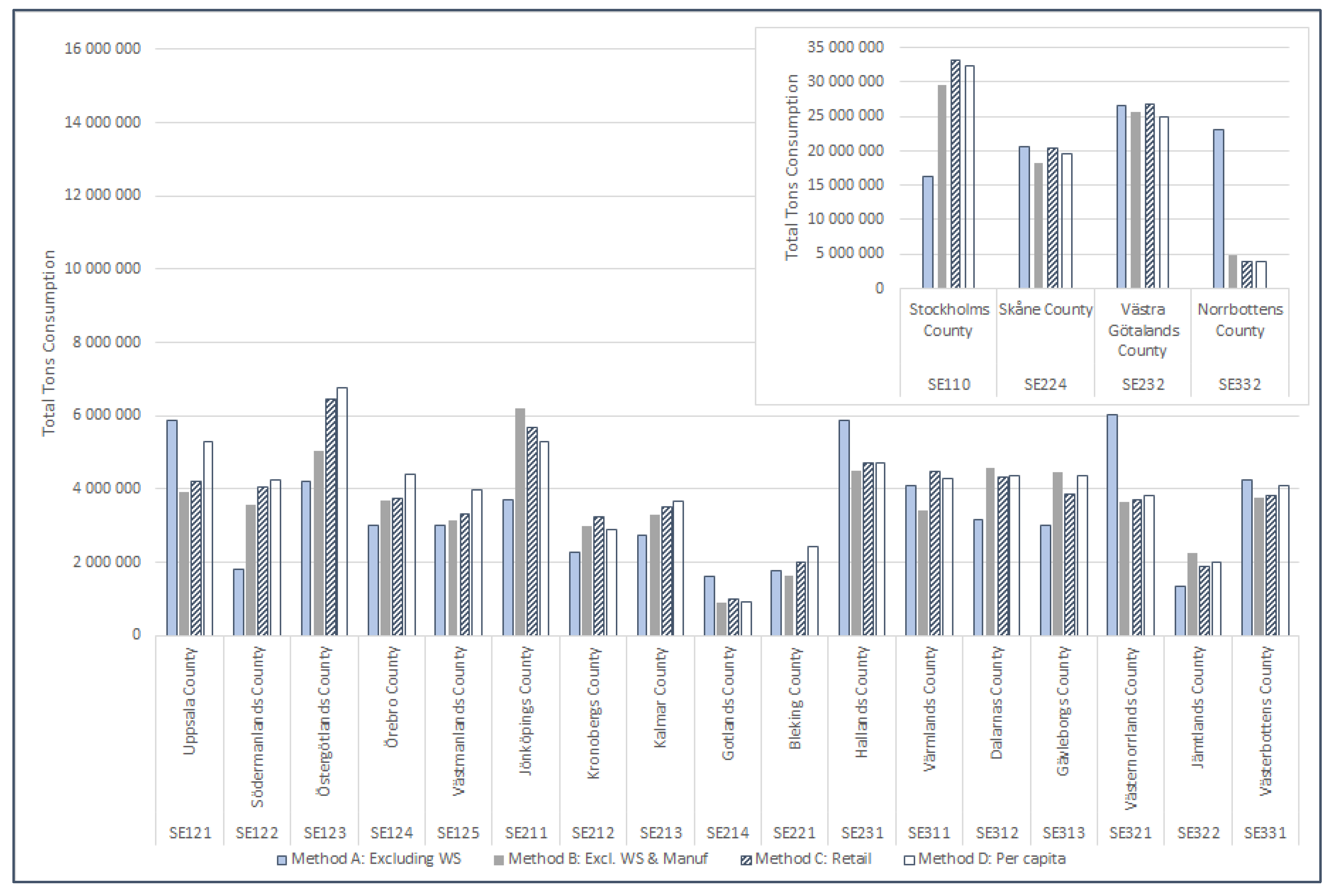
We can compare the total tons of consumption (all products) of Stockholm County (SE110), which is synonymous with the Stockholm Metropolitan Area, to the UMAn model results in Kalmykova et al. (2015b). Method A (all NACE codes except for wholesale) had similar results to the sum total (approximately 16 million tons using Method A, 19 million tons using the UMAn model), while Methods B (all NACE codes except wholesale and manufacturing), C (only retail NACE codes), and D (per capita) had significantly higher results (29 to 33 million tons total). The driver of the mass differences was primarily construction materials like wood (CN category 44) and stone (CN category 25). Product category CN25 is the heaviest of all CN2 categories and therefore can affect total tonnage results significantly. The differences in values for both CN25 and CN44 may be because they are both final and intermediate goods. In the UMAn results, category CN25 comprises approximately 50% of the total consumption mass, which is also true for Methods B, C, and D. Only Method A results in a smaller value than 50%, i.e., 34% of the total consumption mass. This further indicates that including manufacturing NACE codes (Method A) leads to inaccuracies. This also means that construction materials may therefore require additional analysis if measures requiring the use of these product types are to be considered. The majority of the remaining product categories are within the same percentage range as the UMAn model. Further details can be found in
Supplementary Tables S3 and S4.
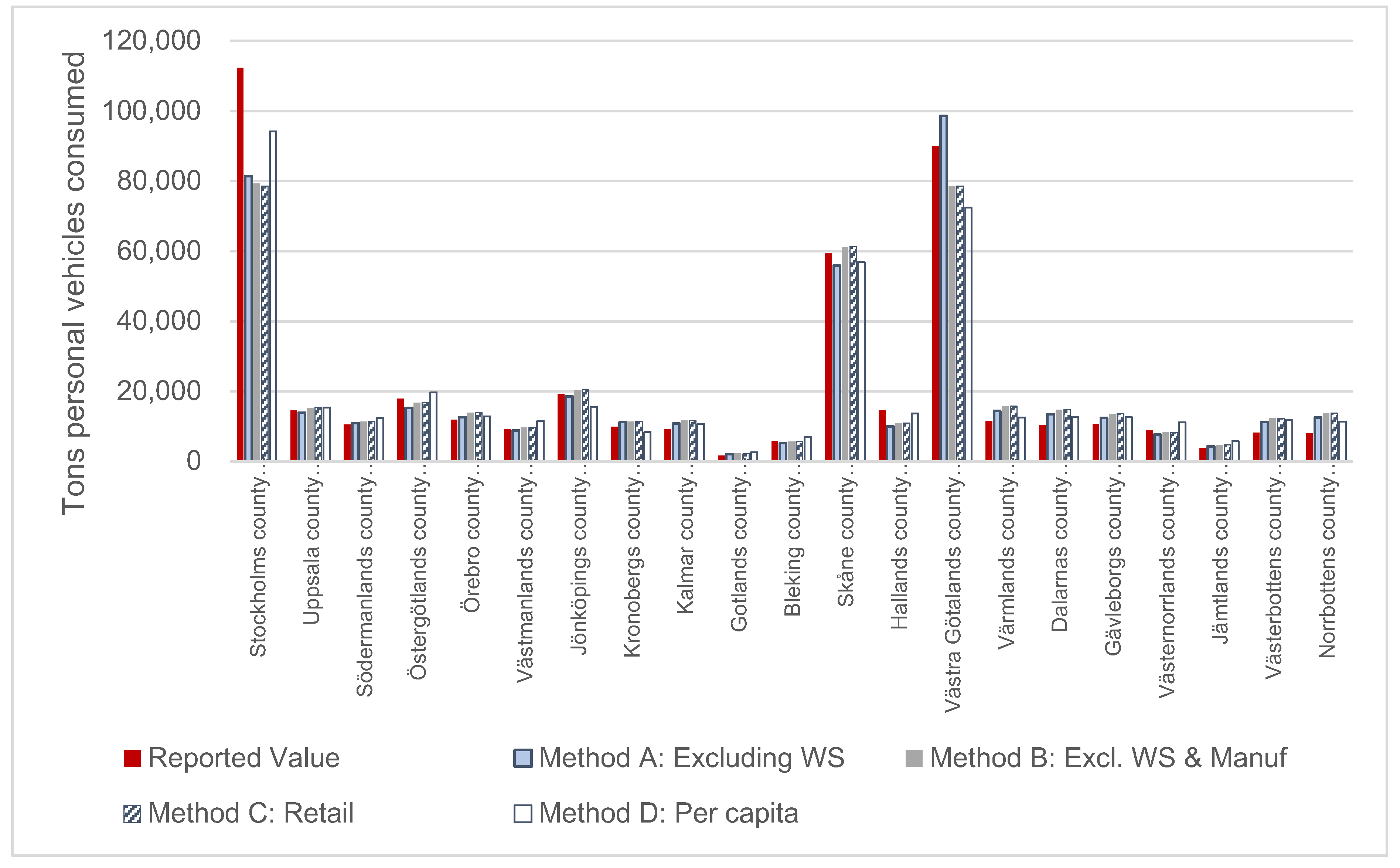
When comparing results to reported values at the county level, results using the employee ratio either did not match reported values as well as per capita estimates or had similar results to per capita results. Of the three novel extrapolation methods analyzed, Method A (all NACE codes excluding wholesale) had the most inaccurate results when compared to reported values at both the county and municipal levels and should therefore not be considered for future applications. At the county level, Methods B, C, and D led to similar results, with a 17% difference among them on average in vehicles and a 24% difference in fuel. The results indicate that at the county (NUTS3) level, per capita values are sufficient for final consumption extrapolation purposes.
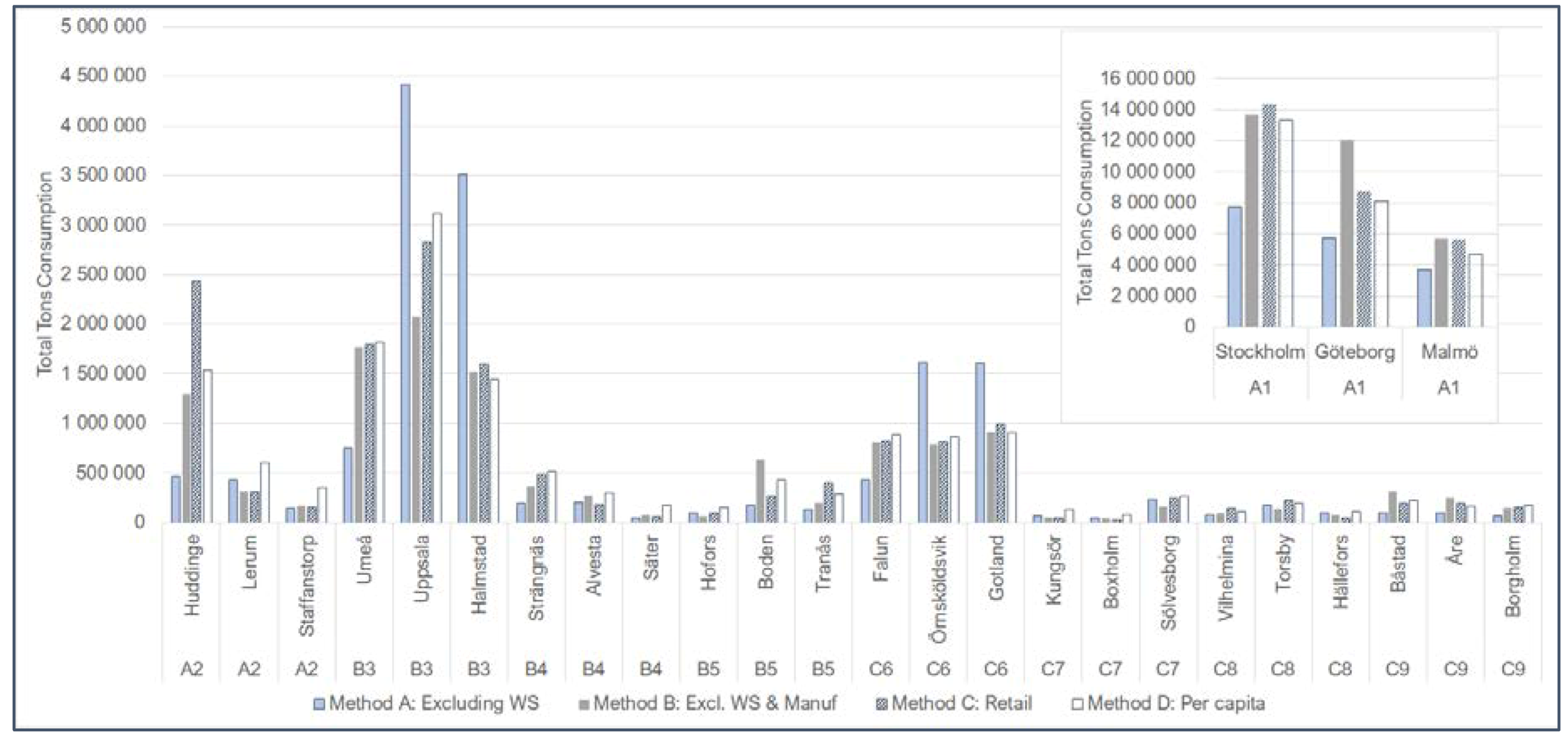
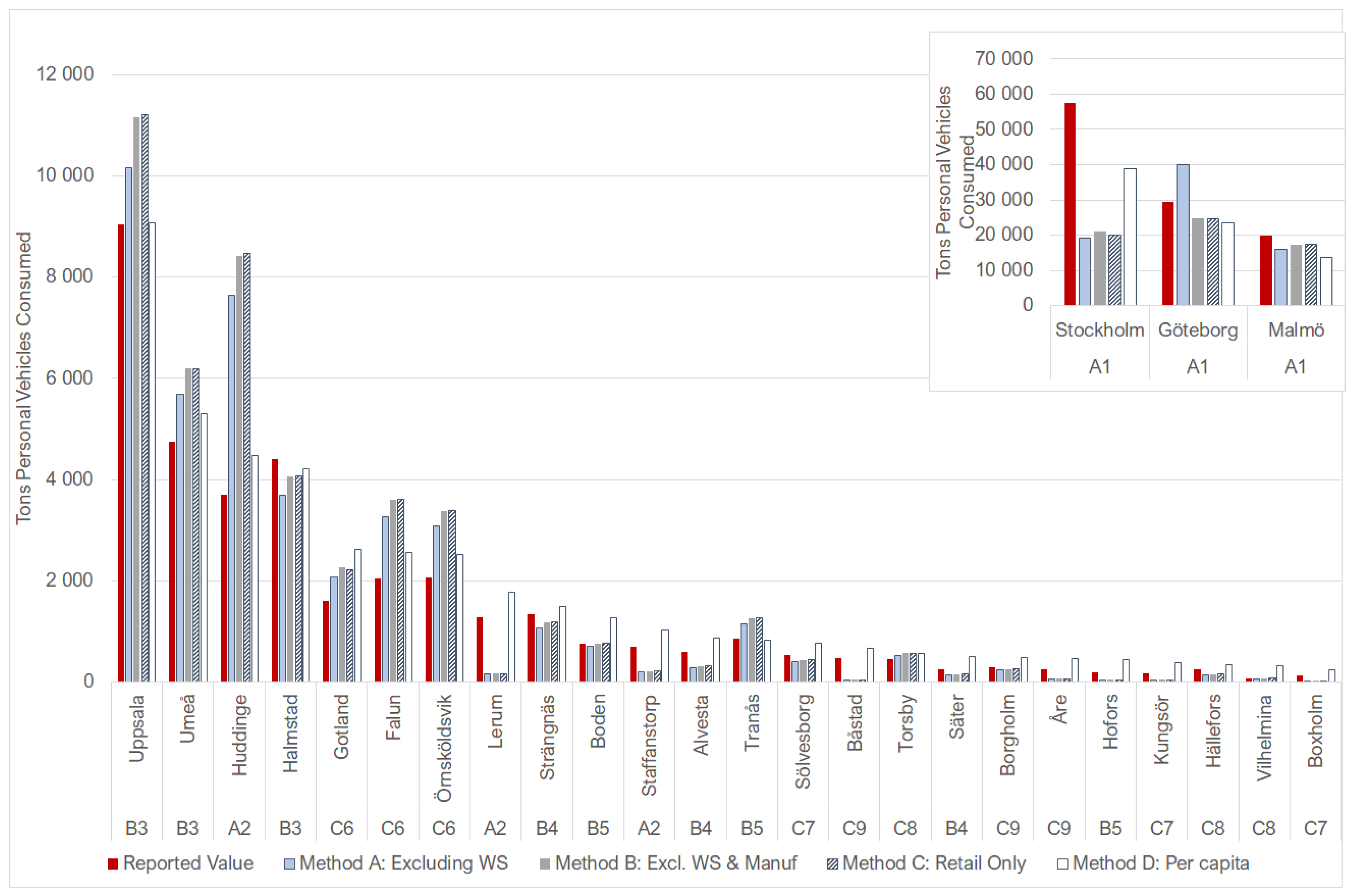
At the municipal level, the results for the employee ratio methods B and C were closer to reported values than per capita values on average but gave inaccurate results for those areas where employees for a certain NACE code were not present. For example, in small municipalities, there may not be any employees working in a particular sector (e.g., vehicle sales), and therefore consumption would be underestimated. The inaccuracies may be due to the fact that metropolitan areas and municipalities can be dependent on the hinterland; consumption in one area may actually be linked to extraction from a geographically distant area [
35]. There was no clear correlation between municipality size and accuracy of results, although per capita values significantly overestimated vehicle consumption in municipalities smaller than 10,000 inhabitants. A link between population size and accuracy was not seen in the fuel results.
We found that using per capita values for final consumption was satisfactory for counties. This was also the case for municipalities with populations outside of major metropolitan areas with population sizes of up to 500,000. Method B (excluding wholesale and manufacturing economic sectors) gave considerably more accurate results than per capita values on average at the municipal level, but there was not a correlation between population size and accuracy. The level of accuracy needed will be dependent on the purpose of the extrapolation.
The method of evaluation presented in this article is limited by the number of products with reported values at the local level and could be improved by including more of these. Moving forward, we would like to gather bottom-up data on product consumption values (thus reducing the limitation to products with reported values) for the purposes of comparison and further evaluation of which method achieves the most reliable results. Testing the methods using other countries’ data would also improve the applicability and allow for greater generalizations.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}