How the Selection of Training Data and Modeling Approach Affects the Estimation of Ammonia Emissions from a Naturally Ventilated Dairy Barn—Classical Statistics versus Machine Learning






Abstract
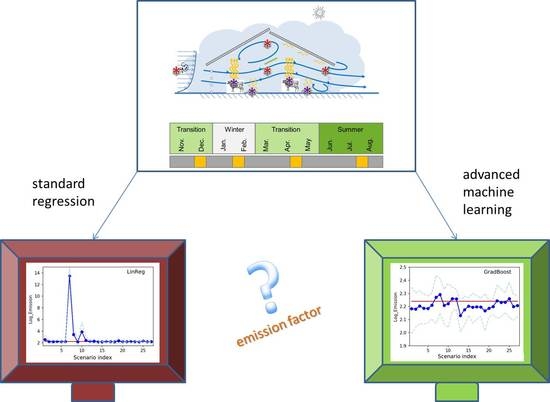
:
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.1.1. Measurement Site
2.1.2. Measurement Setup
2.1.3. Derivation of Hourly Emission Values
2.2. Regression Analysis
2.2.1. Machine Learning Methods
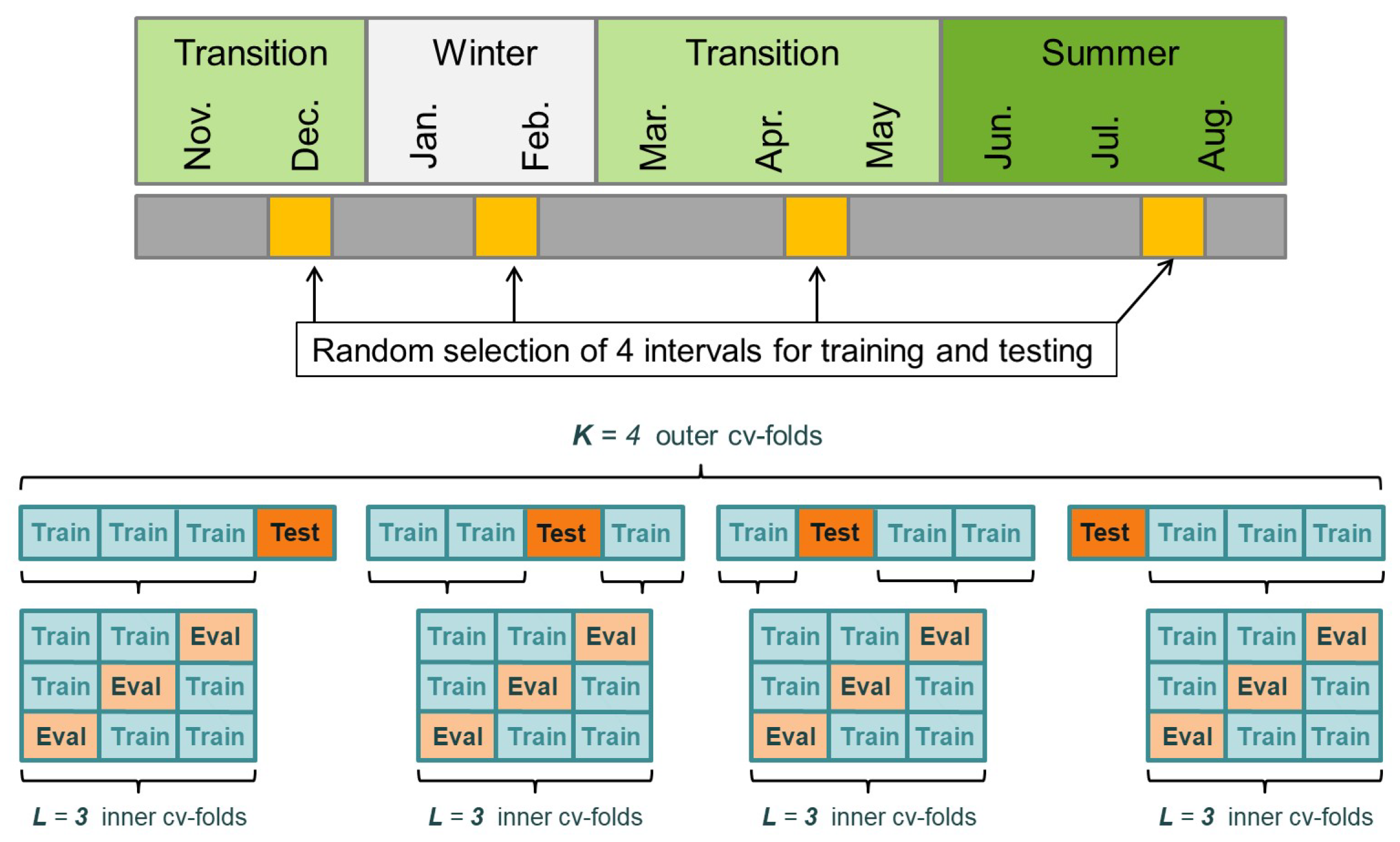
2.2.2. Sampling of Training Data and Cross-Validation
2.2.3. Evaluation Measures
2.2.4. Graphical Representations
3. Results
3.1. Prediction Accuracy
3.2. Evaluation Criterion and Model Selection
3.3. Scenarios of Temporal Sampling
4. Discussion
4.1. Importance of Temporal Sampling and Added Value of Machine Learning
4.2. Sound Selection of Model Evaluation Criteria
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FTIR | Fourier Transform Infrared |
| LU | Livestock Unit (500 g body mass equivalent) |
| GradBoost | Gradient Boosting |
| RandForest | Random Forest |
| Ridge | Regularized Multilinear Regression |
| LinReg | Ordinary Multilinear Regression |
| ANN | Artificial Neural Network |
| fixAnn | Artificial Neural Network with fixed number of hidden layers and nodes |
| GaussProc | Gaussian Process |
| SVM | Support Vector Machine |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Square Error |
| TAE | Total Absolute Error |
References
- Sutton, M.A.; Bleeker, A.; Howard, C.; Erisman, J.; Abrol, Y.; Bekunda, M.; Datta, A.; Davidson, E.; de Vries, W.; Oenema, O.; et al. Our Nutrient World. The Challenge to Produce More Food & Energy with Less Pollution; Technical Report; Centre for Ecology & Hydrology: Edinburgh, UK, 2013. [Google Scholar]
- Hempel, S.; Menz, C.; Pinto, S.; Galán, E.; Janke, D.; Estellés, F.; Müschner-Siemens, T.; Wang, X.; Heinicke, J.; Zhang, G.; et al. Heat stress risk in European dairy cattle husbandry under different climate change scenarios—Uncertainties and potential impacts. Earth Syst. Dyn. 2019, 10, 859–884. [Google Scholar] [CrossRef] [Green Version]
- Amon, B.; Kryvoruchko, V.; Amon, T.; Zechmeister-Boltenstern, S. Methane, nitrous oxide and ammonia emissions during storage and after application of dairy cattle slurry and influence of slurry treatment. Agric. Ecosyst. Environ. 2006, 112, 153–162. [Google Scholar] [CrossRef]
- Monteny, G.; Groenestein, C.; Hilhorst, M. Interactions and coupling between emissions of methane and nitrous oxide from animal husbandry. Nutr. Cycl. Agroecosyst. 2001, 60, 123–132. [Google Scholar] [CrossRef]
- Hristov, A.N. Contribution of ammonia emitted from livestock to atmospheric fine particulate matter (PM2.5) in the United States. J. Dairy Sci. 2011, 94, 3130–3136. [Google Scholar] [CrossRef]
- European Environment Agency (EEA). European Union Emission Inventory Report 1990–2017; European Environment Agency: Copenhagen, Denmark, 2019; Volume 8. [Google Scholar]
- Sanchis, E.; Calvet, S.; del Prado, A.; Estellés, F. A meta-analysis of environmental factor effects on ammonia emissions from dairy cattle houses. Biosyst. Eng. 2019, 178, 176–183. [Google Scholar] [CrossRef]
- Calvet, S.; Gates, R.S.; Zhang, G.Q.; Estellés, F.; Ogink, N.W.; Pedersen, S.; Berckmans, D. Measuring gas emissions from livestock buildings: A review on uncertainty analysis and error sources. Biosyst. Eng. 2013, 116, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Schrade, S.; Zeyer, K.; Gygax, L.; Emmenegger, L.; Hartung, E.; Keck, M. Ammonia emissions and emission factors of naturally ventilated dairy housing with solid floors and an outdoor exercise area in Switzerland. Atmos. Environ. 2012, 47, 183–194. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, G.; Kai, P. Ammonia and methane emissions from two naturally ventilated dairy cattle buildings and the influence of climatic factors on ammonia emissions. Atmos. Environ. 2012, 61, 232–243. [Google Scholar] [CrossRef]
- Hempel, S.; Saha, C.K.; Fiedler, M.; Berg, W.; Hansen, C.; Amon, B.; Amon, T. Non-linear temperature dependency of ammonia and methane emissions from a naturally ventilated dairy barn. Biosyst. Eng. 2016, 145, 10–21. [Google Scholar] [CrossRef] [Green Version]
- Dekock, J.; Vranken, E.; Gallmann, E.; Hartung, E.; Berckmans, D. Optimisation and validation of the intermittent measurement method to determine ammonia emissions from livestock buildings. Biosyst. Eng. 2009, 104, 396–403. [Google Scholar] [CrossRef]
- International VERA Secretariat. VERA TEST PROTOCOL for Livestock Housing and Management Systems, 3rd ed.; International VERA Secretariat: Delft, The Netherlands, September 2018. [Google Scholar]
- Eurich Menden, B.; Wolf, U.; Gallmann, E. Ermittlung von Emissionsdaten für die Beurteilung der Umweltwirkungen der Nutztierhaltung - EmiDaT. Poster at the BTU Conference. 2017. Available online: https://www.ktbl.de/fileadmin/user_upload/Allgemeines/Download/EmiDaT/Poster-EmiDaT.pdf (accessed on 4 December 2019).
- Joo, H.; Ndegwa, P.; Heber, A.; Ni, J.Q.; Bogan, B.; Ramirez-Dorronsoro, J.; Cortus, E. Greenhouse gas emissions from naturally ventilated freestall dairy barns. Atmos. Environ. 2015, 102, 384–392. [Google Scholar] [CrossRef]
- Ngwabie, N.M.; Vanderzaag, A.; Jayasundara, S.; Wagner-Riddle, C. Measurements of emission factors from a naturally ventilated commercial barn for dairy cows in a cold climate. Biosyst. Eng. 2014, 127, 103–114. [Google Scholar] [CrossRef]
- König, M.; Hempel, S.; Janke, D.; Amon, B.; Amon, T. Variabilities in determining air exchange rates in naturally ventilated dairy buildings using the CO2 production model. Biosyst. Eng. 2018, 174, 249–259. [Google Scholar] [CrossRef]
- Ulens, T.; Daelman, M.R.; Mosquera, J.; Millet, S.; van Loosdrecht, M.C.; Volcke, E.I.; Van Langenhove, H.; Demeyer, P. Evaluation of sampling strategies for estimating ammonia emission factors for pig fattening facilities. Biosyst. Eng. 2015, 140, 79–90. [Google Scholar] [CrossRef]
- Kafle, G.K.; Joo, H.; Ndegwa, P.M. Sampling Duration and Frequency for Determining Emission Rates from Naturally Ventilated Dairy Barns. Trans. ASABE 2018, 61, 681–691. [Google Scholar] [CrossRef]
- Saha, C.; Ammon, C.; Berg, W.; Fiedler, M.; Loebsin, C.; Sanftleben, P.; Brunsch, R.; Amon, T. Seasonal and diel variations of ammonia and methane emissions from a naturally ventilated dairy building and the associated factors influencing emissions. Sci. Total Environ. 2014, 468, 53–62. [Google Scholar] [CrossRef]
- Wang, C.; Li, B.; Shi, Z.; Zhang, G.; Rom, H. Comparison between the Statistical Method and Artificial Neural Networks in Estimating Ammonia Emissions from Naturally Ventilated Dairy Cattle Buildings. In Proceedings of the Livestock Environment VIII, Iguassu Falls, Brazil, 31 August–4 September 2008; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2009; p. 7. [Google Scholar]
- Boniecki, P.; Dach, J.; Pilarski, K.; Piekarska-Boniecka, H. Artificial neural networks for modeling ammonia emissions released from sewage sludge composting. Atmos. Environ. 2012, 57, 49–54. [Google Scholar] [CrossRef]
- Stamenković, L.J.; Antanasijević, D.Z.; Ristić, M.Đ.; Perić-Grujić, A.A.; Pocajt, V.V. Modeling of ammonia emission in the USA and EU countries using an artificial neural network approach. Environ. Sci. Pollut. Res. 2015, 22, 18849–18858. [Google Scholar] [CrossRef]
- Liakos, K.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D.D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Janke, D.; Willink, D.; Hempel, S.; Ammon, C.; Amon, B.; Amon, T. Influence of Wind Direction and Sampling Strategy on the Estimation of Ammonia Emissions in Naturally Ventilated Barns. In New Engineering Concepts for Valued Agriculture; Groot Koerkamp, P., Lokhorst, C., Ipema, A., Kempenaar, C., Groenestein, C., van Oostrum, C., Ros, N., Eds.; Wageningen University and Research: Wageningen, The Netherlands, 2018; pp. 762–767. [Google Scholar]
- Pedersen, S.; Sällvik, K. Climatization of Animal Houses. Heat and Moisture Production at Animal and House Levels; Research Centre Bygholm, Danish Insitute of Agricultural Sciences: Horsens, Denmark, 2002; pp. 1–46. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random Decision Forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Breiman, L. Arcing The Edge; Technical Report 486; Statistics Department, University of California: Berkeley, CA, USA, 1997. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine; Ims 1999 Reitz Lecture; Sequoia Hall, Stanford University: Stanford, CA, USA, 1999; Available online: http://statweb.stanford.edu/~jhf/ftp/trebst.pdf (accessed on 4 December 2019).
- Hoerl, A.E. Application of ridge analysis to regression problems. Chem. Eng. Prog. 1962, 58, 54–59. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. The Perceptron: A Probabilistic Model For Information Storage And Organization In The Brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Werbos, P. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences; Harvard University: Cambridge, MA, USA, 1975. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representation by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Gordon, G., Dunson, D., Dudík, M., Eds.; Proceedings of Machine Learning Research: London, UK, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 20 January 2020).
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support Vector Regression Machines. In Advances in Neural Information Processing Systems 9; NIPS: Denver, CO, USA, 1996; pp. 155–161. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | |||||
|---|---|---|---|---|---|
| 1, 2, 3 | 1, 7, 14 | 3 | 1 | 1 | 1 |
| 4, 5, 6 | 1, 7, 14 | 4 | 2 | 1 | 1 |
| 7, 8, 9 | 1, 7, 14 | 4 | 2 | 2 | 0 |
| 10, 11, 12 | 1, 7, 14 | 4 | 3 | 1 | 0 |
| 13, 14, 15 | 1, 7, 14 | 6 | 2 | 2 | 2 |
| 16, 17, 18 | 1, 7, 14 | 6 | 3 | 2 | 1 |
| 19, 20, 21 | 1, 7, 14 | 6 | 4 | 1 | 1 |
| 22, 23, 24 | 1, 7, 14 | 6 | 4 | 2 | 0 |
| 25, 26, 27 | 1, 7, 14 | 6 | 5 | 1 | 0 |
| Scenario Unit | MAE ln [g h−1 LU−1] | RMSE 1 | R2 | TAE g h−1 LU−1 | TAE % |
|---|---|---|---|---|---|
| 1 | 0.441 | 0.350 | 0.236 | 0.0782 | 5.6 |
| 2 | 0.428 | 0.333 | 0.260 | 0.0830 | 5.9 |
| 3 | 0.409 | 0.314 | 0.297 | 0.0519 | 3.7 |
| 4 | 0.413 | 0.314 | 0.318 | 0.0747 | 5.3 |
| 5 | 0.404 | 0.303 | 0.335 | 0.0780 | 5.6 |
| 6 | 0.391 | 0.291 | 0.359 | 0.0437 | 3.1 |
| 7 | 0.480 | 0.418 | 0.088 | 0.0413 | 2.9 |
| 8 | 0.449 | 0.373 | 0.182 | 0.0716 | 5.1 |
| 9 | 0.473 | 0.400 | 0.127 | 0.0456 | 3.2 |
| 10 | 0.459 | 0.376 | 0.180 | 0.0277 | 2.0 |
| 11 | 0.428 | 0.343 | 0.256 | 0.0258 | 1.8 |
| 12 | 0.399 | 0.304 | 0.346 | 0.0232 | 1.7 |
| 13 | 0.427 | 0.324 | 0.292 | 0.1461 | 10.4 |
| 14 | 0.399 | 0.298 | 0.341 | 0.0899 | 6.4 |
| 15 | 0.376 | 0.271 | 0.398 | 0.0537 | 3.8 |
| 16 | 0.423 | 0.330 | 0.280 | 0.0651 | 4.6 |
| 17 | 0.394 | 0.296 | 0.346 | 0.0609 | 4.3 |
| 18 | 0.401 | 0.299 | 0.332 | 0.0626 | 4.5 |
| 19 | 0.416 | 0.316 | 0.312 | 0.0998 | 7.1 |
| 20 | 0.395 | 0.292 | 0.363 | 0.0759 | 5.4 |
| 21 | 0.378 | 0.270 | 0.402 | 0.0586 | 4.2 |
| 22 | 0.426 | 0.332 | 0.276 | 0.0047 | 0.3 |
| 23 | 0.418 | 0.323 | 0.302 | 0.0133 | 1.0 |
| 24 | 0.407 | 0.309 | 0.336 | 0.0125 | 0.9 |
| 25 | 0.425 | 0.334 | 0.272 | 0.0253 | 1.8 |
| 26 | 0.399 | 0.296 | 0.352 | 0.0582 | 4.1 |
| 27 | 0.392 | 0.287 | 0.388 | 0.0472 | 3.4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hempel, S.; Adolphs, J.; Landwehr, N.; Janke, D.; Amon, T. How the Selection of Training Data and Modeling Approach Affects the Estimation of Ammonia Emissions from a Naturally Ventilated Dairy Barn—Classical Statistics versus Machine Learning. Sustainability 2020, 12, 1030. https://doi.org/10.3390/su12031030
Hempel S, Adolphs J, Landwehr N, Janke D, Amon T. How the Selection of Training Data and Modeling Approach Affects the Estimation of Ammonia Emissions from a Naturally Ventilated Dairy Barn—Classical Statistics versus Machine Learning. Sustainability. 2020; 12(3):1030. https://doi.org/10.3390/su12031030
Chicago/Turabian StyleHempel, Sabrina, Julian Adolphs, Niels Landwehr, David Janke, and Thomas Amon. 2020. "How the Selection of Training Data and Modeling Approach Affects the Estimation of Ammonia Emissions from a Naturally Ventilated Dairy Barn—Classical Statistics versus Machine Learning" Sustainability 12, no. 3: 1030. https://doi.org/10.3390/su12031030
APA StyleHempel, S., Adolphs, J., Landwehr, N., Janke, D., & Amon, T. (2020). How the Selection of Training Data and Modeling Approach Affects the Estimation of Ammonia Emissions from a Naturally Ventilated Dairy Barn—Classical Statistics versus Machine Learning. Sustainability, 12(3), 1030. https://doi.org/10.3390/su12031030