1. Introduction
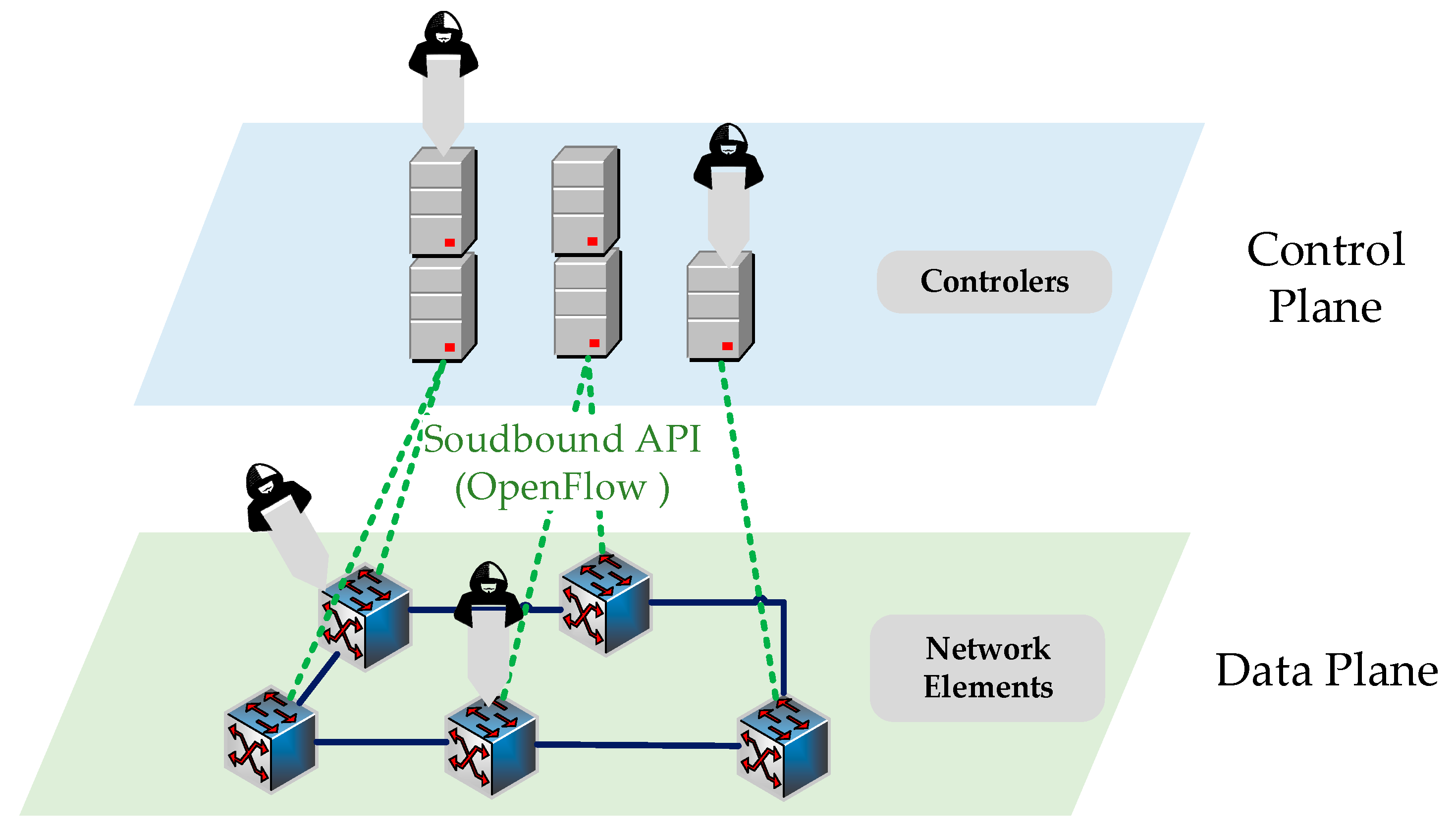
Traditional network infrastructures have been unable to address certain requirements such as high bandwidth, accessibility, high connection speed, dynamic management, cloud computing, and virtualization. Thus, Software Defined Networking (SDN), which has a flexible, programmable, and dynamic architecture, has emerged as an alternative to traditional networks [
1]. SDN architecture consists of control, data, and application planes. Devices, such as switches and routers, are placed on the data plane. This plane is programmed and managed by the control plane [
2]. The control plane is responsible for the management of transmission devices placed on the data plane. The controller, which performs as the brain of the network, is located on this plane. Devices on the data plane carry out packet transmission according to the rules set by the controller. The application plane communicates with the devices located on the network infrastructure via the controller.
Devices on the network are programmed by applications using Northbound and Southbound interfaces. The controller communicates with the services working on the application layer by means of the Northbound interface and communicates with the devices on the data layer by means of the Southbound interface. The most popular protocol used in this interface is the OpenFlow protocol [
3]. As the control logic has been taken from local devices and become central, SDN is structured from a single spot and dynamically optimized [
4]. Although certain security threats are general in computer networks, SDN has brought its own security threats. There are at least seven different threat vectors identified with SDN [
5]. The most important threat vector for SDN is Distributed Denial of Service (DDoS) attacks. They can be against the controller in SDN or in the storage capacity of the flow table in the OpenFlow switch.
The controller is exposed to DDoS attacks through the communication line between the controller and the data plane. DDoS attacks direct a large amount of traffic to the OpenFlow switch on the data plane. If packets arriving at the OpenFlow switch do not match with the flow input in the flow table (miss flow), packets are taken into the flow buffer. Then, they are transmitted to the controller with the Packet-In message to write a new rule. In this situation, the sources of the controller (memory, processor, bandwidth, etc.) remain incapable and the network becomes inoperative. In addition, the bandwidth of the communication line between the controller that is exposed to attack traffic and the OpenFlow switch is negatively affected. Therefore, network performance severely declines [
6].
The data plane is exposed to DDoS attacks through the flow table located in the network devices. In such DDoS attacks, packets are sent to the switch from unknown sources. The controller writes a rule for these arriving packets and forwards them to the flow table of the switch. After a while, the capacity of switch flow table becomes full. Consequently, new rules cannot be written to the flow table and packets cannot be forwarded. In addition, the incoming packets fall automatically as the buffer capacity becomes full with the attack [
7]. OpenFlow switches manage the packets with only the flow entry coming from the controller. Thus, decreasing DDoS attacks in SDN is more difficult when compared to traditional networks.
Machine learning-based approaches can provide more dynamic, more efficient, and smarter solutions for SDN management, security, and optimization. In order to ensure network security, the detection of DDoS attacks is very important for taking the necessary measures in a timely manner. Processing SDN flow data with the machine learning-based DDoS attack detection systems integrated into SDN structures can lead to a self-determining network that is able to learn and act. Moreover, SDN having an integrated machine learning application may be a reference model in forming a secure structure in studies providing for the integration of 5G networks.
This paper consists of five sections. The second section presents a short review on DDoS attacks against the controller and DDoS attacks against the OpenFlow switch, along with SDN architecture and properties and security gaps. In the third section, under Materials and Methods, process steps for applying the feature selection methods and machine learning models, and experimental setup and data collection from SDN are presented in detail. In the fourth section, the experimental results are analyzed and implications are drawn from the findings. In the last section of the study, the concluding remarks of the study are presented.
3. Materials and Methods
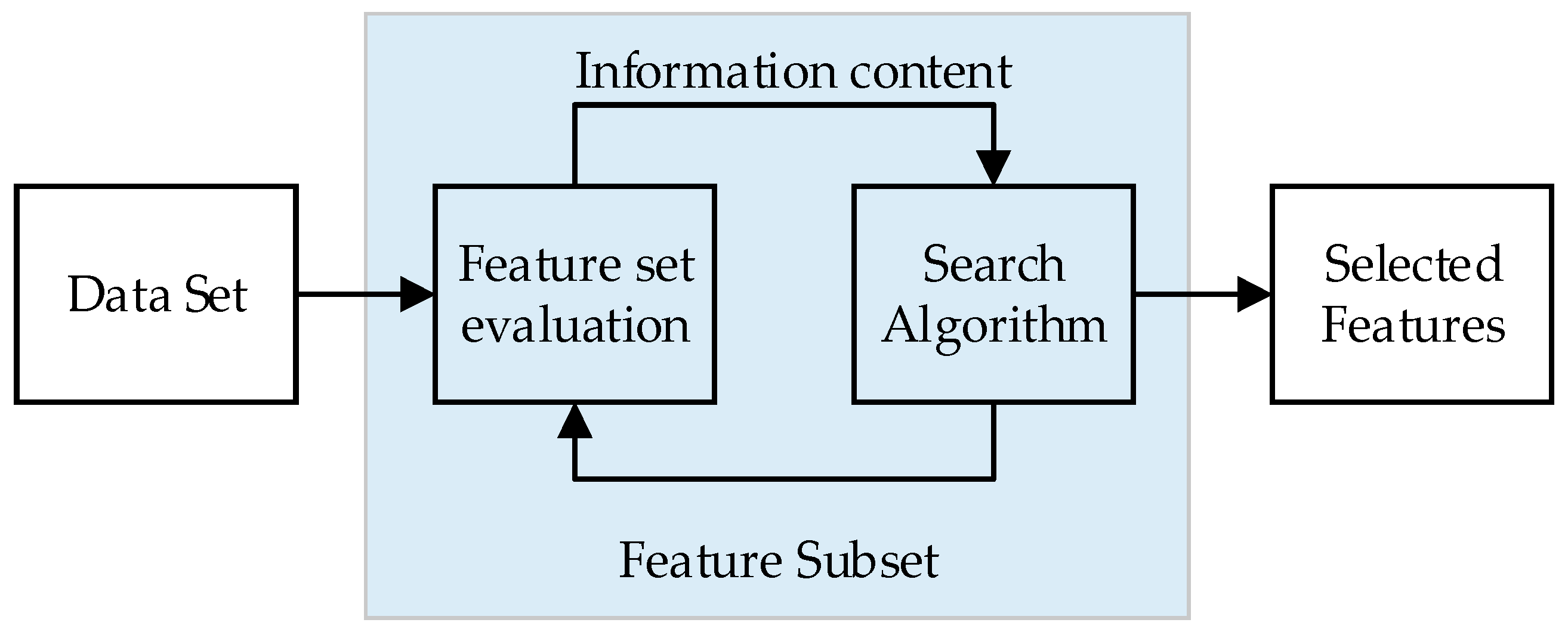
The process steps for applying the feature selection methods and machine learning models are given in
Figure 2. Additionally, in this section, how the data is obtained from the dataset, and the features and classes of the dataset are explained. The features in the dataset, created within the scope of the study, were obtained from the main metrics that are vital for the continuity of the SDN architecture. The attack data, obtained as a result of DDoS attacks, were classified using machine learning techniques. Features in the dataset were selected using feature selection methods and the performances of the classifiers on the obtained feature set were examined. The analysis of the application was performed in a Matlab environment.
3.1. Feature Selection Methods and Machine Learning Models
To detect DDoS attacks, machine learning models supported with feature selection methods are used in this study. Machine learning is a method that draws implications from existing data by using mathematical and statistical methods, and makes predictions about the unknown with these implications. In the literature, a variety of machine learning models have been proposed. The taxonomy of models can be summarized with the kernel-based, distance-based, neural network- based and probability-based characteristics. The continuing research suggests that there is no universal best model for all classification tasks. The literature suggests that SVM, KNN, ANN (Artificial Neural Network), and NB models have shown good performance for solutions of classification problems. In this study, as candidates of their classification group, the performance rate for detecting DDoS attacks from SVM, KNN, ANN, and NB models were investigated.
The datasets used in the training test of machine learning models can contain a large number of features. Although some of these features have a high degree of influence on the classification result, some features may have little or no effect on the classification result. Using features that have little impact on classification can increase time and process costs. The goal is to reduce the features that have a low impact on the classification and to provide the use of highly effective features.
The filter, embedded, and wrapper methods were used as feature selection methods. The filter method mainly focuses on the intrinsic properties of the features, while the wrapper method focuses on the usefulness of features based on the classifier performance. The embedded method tries to use the properties of both the filter and wrapper methods to optimize the performance of a learning algorithm or model. Each feature selection method has different algorithms to achieve their goals. Our classification problem is a binary classification problem and in our dataset there is no missing data. Therefore, the relief filtering algorithm inspired by instance-based learning was selected for filter-based feature selection.
A greedy search-based Sequential Forward Selection (SFS) algorithm was preferred due to its proven success in finding an optimal feature subset among the wrapper-based feature selection methods. Lasso or L1 algorithm was selected as the embedded feature selection method as it adds a penalty against complexity to reduce the degree of overfitting, which improves the optimization performance of the model.
3.1.1. Filter-Based Feature Selection
The filter-based feature selection method contributions to the achievement of the results of the features are calculated using statistical methods. A reduced feature set is created by selecting the best feature set from the rated features, as seen in the process given in
Figure 3. In the study, the Relief algorithm, which is one of the filter-based feature selection algorithms, is used. The Relief algorithm calculates the relation of each sample in the dataset with other instances in its class and its distance to different classes. As a result of this calculation, it creates a model and performs the feature selection process [
22,
23].
3.1.2. Wrapper-Based Feature Selection
The wrapper method aims to find the most ideal attributes by trying all features in the classification algorithm. When the ideal subset of features is reached, the process is completed and a reduced dataset is created (
Figure 4). This may be more successful than statistical methods; however, depending on the classification algorithm, it may be disadvantageous in terms of speed. In the study, the sequential forward floating selection algorithm, which is one of the wrapper-based feature selection algorithms, is used. When selecting a feature, the same direction is used until the classification success reaches a higher value [
22,
23].
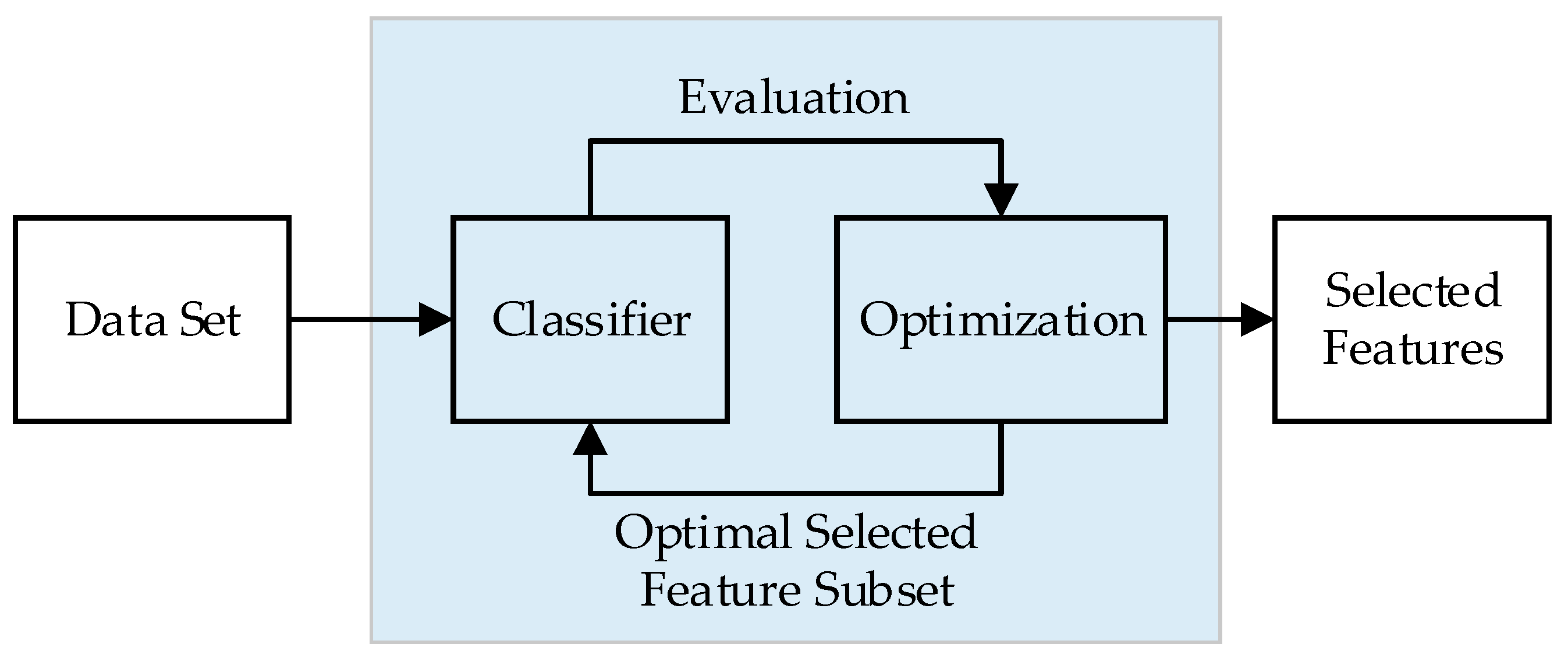
3.1.3. Embedded-Based Feature Selection
Embedded-based feature selection methods are feature selection algorithms that are included in the classification algorithm. These algorithms make their selection of features by identifying the features that will best contribute to the accuracy of the model (
Figure 5). They have been developed to combine the advantages of filter and wrapper-based methods. In this method, a learning algorithm takes advantage of its variable selection process and simultaneously performs feature selection and classification [
22]. In this study, the Lasso algorithm, which is one of the embedded-based feature selection algorithms, is used. An important characteristic of the Lasso algorithm eliminates the weights of the least important features. That is, in this way, it naturally makes the attribute selection and outputs a reduced set of features [
22,
23].
3.1.4. Support Vector Machine (SVM)
SVM is a supervised learning model employed in the learning field, which uses classification and regression analysis in defining and analyzing obtained patterns. The working principle of SVM is based on predicting the most appropriate decision function to separate between two classes. In other words, it is based on defining the hyper-plane that can separate two classes. We used SVM with Cubic kernels.
3.1.5. Naive Bayes
NB classification aims to detect the class, namely the category, of the data entered into the system with a series of calculations defined in accordance with the principles of probability [
23]. In NB classification, a certain amount of training data is entered into the system. The data entered for training has to have a class. Test data entered into the system with probability processes carried out on the training data is processed. This process is done according to previously obtained probability values and then the class of the given test data is detected. The more the number of training data, the more accurate it is to detect the real category of the test data. We used NB with Gaussian kernels.
3.1.6. Artificial Neural Network (ANN)
ANN is a strong classifying tool based on the artificial neuron model. It uses neurons as the most basic building block. Artificial neurons are designed to behave similarly to biological neurons. The ANN architecture created in this study contains 12 input units and 10 neurons in a single hidden layer. It should be noted that the number of inputs and the number of neurons in a single hidden layer change according to the chosen filter methods used in feature selection.
3.1.7. K-Nearest Neighbors
The KNN algorithm is a simple, easily applicable, and supervised machine learning algorithm that can be used for solving both classification and regression problems. When new data comes in, it determines the class of the new data by looking at its nearest K neighbors. Manhattan, Minkowski, and Euclidean distance functions are used for the distance between two data. The Euclidean distance function was used in this study. The similarity between the sample to be classified and the samples found in the classes was detected. When new data was encountered, the distance of this data to the data in the training set was calculated individually by using the Euclidean function. Then, the classification set was created by selecting the k dataset from the smallest distance. The number of neighboring KNN (k) is based on the value of classification. During the classification, k was determined as 10.
3.2. Experimental Setup and Collecting Data from SDN
Experimental SDN topology for collecting normal and DDoS attack data is shown in
Figure 6. In the topology, there are six (PC1-PC6) virtual machines (VMs) that have Ubuntu 18.04, 1 GB RAM, 1 CPU configuration works on VirtualBox-KVM, two VM switches, one Open vSwitch (OVS), sFlow, and InfluxDB docker images, and a Phyton-based open source OpenFlow/SDN (POX) controller. sFlow, and InfluxDB, set up in the same virtual machine, were connected to the OVS switch via a VM switch. The VM switch on the users’ side was connected to the OVS switch with a bridge (br0).
To analyze the effects of the attack traffic, network metrics were collected from the OVS switch by using an sFlowDocker image both at the moment of attack and normal traffic. For this purpose, JavaScript was used to record network metric data on an InfluxDB image with a timestamp, which is an open source time-series platform.
We have applied a protocol-based attack scenario. Three types of flooding attacks Transmission Control Protocol (TCP), User Datagram Protocol (UDP), and Internet Control Protocol (ICMP) were used to create a DDoS attack dataset with an “hping3” packet generator. The Hping3 tool was installed on PC1 in the network and defined as attacker, while PC6 was chosen as the victim. Under attack, PC6 has the 10.0.0.6 IP address with a constant 512 bytes of payload size and constant packet rates of 2000 packet per second (pps) for each protocol-based flooding attack. This leads the number of flow modification messages from a controller to be more than 1304 per second, resulting in the number of flow table entries being 6996.
Due to the generated DDoS attack packets against the controller, the processing, bandwidth, CPU capacity, and communication capacity of the controller was overwhelmed. The capacity of the flow table entries in the switch is exhausted due to the unnecessary flows that the controller creates because of attacking packets. The simulation was conducted in 15 min for each of the sent TCP, UDP, and ICMP packets. By this means, a dataset having 65,000 samples, related to network traffic flow at the moment of DDoS attack, was generated.
In order to obtain normal traffic data for the training and testing, the TPC, UDP, and ICMP traffic data of PC2 and PC5 were recorded. By this means, a dataset, which consists of 64,000 samples where the data related to normal network traffic flow, was obtained. Thus, a new dataset, consisting of 12 features and a total of 129,000 samples, was obtained. Twelve features and the class of the dataset and their explanations are given below.
- (1)
Ifinpkt: Packets entering into the system from data plane.
- (2)
Ifoutpkt: The out packet controls the packet leaving the system according to the flow rule sent by the controller with the “Packet-out” message.
- (3)
Hits: The number of packets matching with the rules previously set by the controller and stored in the flow table of OVS switch.
- (4)
Masks: The “masks” row displays the mega flow mask stats. This row is omitted for data paths not implementing mega flow.
- (5)
Miss: When a new packet arrives at the transmission devices (switch, router, etc.), a match is sought in the flow table. If the arriving packet does not match with any flow input (flow miss), it is forwarded to the controller to set a new flow rule.
- (6)
OpenFlowfrom: The flow modification message sent by the controller. It is one of the main messages sent by the controller. With this message, switch state is changed for the new flow.
- (7)
Cpu_util (CPU Usage in Data Plane): The central processor unit of the computer processes and calculates the arriving data with the help of mathematical operations. The usage percentage of this unit varies according to the processing capacity of the computer. If the percentage is high, it means that the computer performs at maximum or above the normal level for the number of operating applications.
- (8)
Mngmnt_interface_inpkts: Packet arriving at the control plane.
- (9)
Mngmnt_interface_outpkts: Packet leaving the control plane.
- (10)
OpenFlowto: This message is one of the main messages sent by the controller. With this message, switch state is changed for the new flow.
- (11)
OVS Flow: The number of flows in the data path.
- (12)
OVS Lost: The number of packets sent for processing but dropped.
- (13)
Class: The class of traffic. Data used in this study are labelled data. In other words, supervised learning is aimed at four classes: ‘Normal traffic’, ‘ICMP Flood’, ‘TCP Flood’, and ‘UDP Flood’ attack.
The dataset created within the scope of the study was reduced by using feature selection methods and then the classification was made on these data. SVM, NB, ANN, and KNN were used as classifiers. The experimental study consisted of two stages. Classifiers were trained and tested with using all the features in the dataset. Using the k-fold cross validation (k = 10) method, the dataset was divided into training and testing sets to test the success of the applied method [
24] in the first stage. In the second stage, feature selection methods were used. Relief, sequential forward floating selection, and Lasso algorithms were used to select the most effective feature in the entire dataset as filter, wrapper, and embedded feature selection methods, respectively. Three different datasets were created from these feature selection methods. For each of the three datasets, the best performance ratio, between 1 and 12 features, was determined by SVM, NB, ANN, and KNN algorithms, separately.
4. Experimental Results
In this study first, data at normal traffic moments and at DDoS attack traffic moments were analyzed on SDN architecture with the dataset. Feature selection methods were not used at this stage of the study. The obtained results of the analysis are presented in
Table 1.
When the success rates are analyzed, KNN and NB exhibited better performance in analyzing SDN data. At the end of the training carried out with the KNN algorithm, a Receiver Operating Characteristic (ROC) curve was prepared (
Figure 7). The ROC curve is a tool for evaluating the test results. It is defined by a two-dimensional graph which has True Positive (TP) as Y-axis and False Positive (FP) as X-axis. TP indicates positive instances correctly classified as positive outputs and FP indicates negative instances wrongly classified as positive outputs. Another metric used in confusion matrices is False Negative (FN) which indicates positive instances wrongly classified as negative output. The TP value was observed to be above 0.9% in ROC curve.
When the performance results were examined, it was found that the KNN classifier was more successful in analyzing the attack data. The ROC curve is shown in
Figure 7, and the confusion matrix shown in
Table 2 was prepared according to the results of the KNN classifier. We observed that the attack traffic type (ICMP, TCP, and UDP) affects the performance rate. The highest performance rate was obtained when the UDP flood attack was performed.
In the second part of the study, in order to obtain the features that have the most powerful effect on the prediction of machine learning models, filtering, wrapping, and embedded-based feature selection methods were applied. The reduced feature dataset obtained by the feature selection methods was applied to each model and the accuracy of the model was tested.
The Relief algorithm was applied to the SVM, KNN, ANN, and NB models as a filtering method. The proximity of each sample in this algorithm dataset to the other samples in its own class and its distance to different classes were calculated. As a result of this calculation, a model was created and feature selection was performed. As a result, 10 of the 12 features were selected for SVM, 6 for KNN, 6 for ANN, and 8 for NB. These features were retrained with each classification algorithm. The results are summarized in
Table 3.
When the Relief algorithm was applied as the filtering method and the feature selection was made, the highest performance rate was obtained with the KNN classifier (
Table 2). The confusion matrix of the classifier with the highest performance rate is given in
Table 4.
The Sequential Forward Floating Selection algorithm was applied to the SVM, KNN, ANN, and NB models with the wrapper method. A feature alone may not reduce the error, but evaluating this feature relative to another feature may improve the classification performance. For this purpose, Floating Algorithms have been developed. These algorithms have a floating variable and the number of features added or removed at each stage is not constant. This creates a plurality of feature subset combinations [
25]. Sequential Feature Selection adds or subtracts the feature based on a user-defined classifier performance metric.
In wrapper-based feature selection algorithm, when the features are reduced with the Sequential Forward Floating Selection algorithm, 8 of the 12 features were selected for SVM, 6 for KNN, 10 for ANN, and 8 for NB. The reduced dataset was rearranged for each classification algorithm. The results are shown in
Table 5.
The highest performance rate was obtained with the KNN classifier when the Sequence Forward Floating Selection algorithm was applied with the wrapping method and feature selection was made (
Table 5). The confusion matrix of the classifier with the highest performance rate is shown in
Table 6.
Finally, the SVM, KNN, ANN, and NB models were applied with the Lasso method as the embedded-based method. Lasso is another regularized variant of linear regression. An important characteristic of Lasso regression is that it eliminates the weights of the least important features. That is, in this way, it naturally makes feature selection and outputs a reduced set of features. With this method, 10 out of 12 attributes were selected for SVM, 8 for KNN, 6 for ANN, and 10 for NB. The reduced dataset was rearranged for each classification algorithm. The results are shown in
Table 7.
When the embedded method, Lasso, was applied and feature selection was made, the highest performance rate was obtained with the KNN classifier (
Table 7). The confusion matrix of the classifier with the highest performance rate is shown in
Table 8.
Throughout the study, all dataset features were used and two different methods were used for reduction (
Table 9). Although the results of classification using all features are acceptable, the performance results increased with the use of feature selection methods.
The highest accuracy rate obtained by applying the test data to the machine learning model, shown in
Table 5, was obtained with the KNN classifier (98.3%) when the wrapper feature selection method was applied. This accuracy rate was obtained through training and testing on six features. We observed that the performance ratios obtained by training classifiers over a dataset containing 12 features increased after using feature selection algorithms. To compare our findings with similar studies, we created a comparison table. The results, as well as the ones reported in the literature, are summarized in
Table 10.
It can be seen from
Table 10, that the proposed machine learning model with feature selection approaches, results in better performance in comparison with the results from [
10,
16,
18,
19,
21]. It should be noted that similar studies in the literature used different datasets and different models. Therefore, justification of the comparison results is difficult.
Results show that the SDN structure proved successful in terms of detecting DDoS attacks with machine learning techniques. With the approaches to be planned on SDN architecture, a secure and efficient mechanism on the network can be developed. The performance of the controllers on large networks can be increased by catching the packets on the traffic and comparing them with the previously learned flow data of the packet. Another approach could be the use of a two-stage system in detecting DDoS attacks on the dataset. While the coming flow data is processed by the controller, it is copied to another module and analyzed by this module. To have any output on the network, the module has to inform the controller whether there is a problem in the coming data or not. Thus, while the controller performs only the network processes, the other module becomes an attack detection system.
In an SDN topology, multiple controllers in the SDN in a hierarchical structure can be located, as discussed in [
26]. In SDN topology with a multi-controller structure, as the network traffic load is distributed among controllers, detection of DDoS attack traffic will be faster than that of a single controller. The location of the controllers in the network is also important at this point. Once the controllers are properly located in the network, the effectiveness of the controllers on the network elements in the data plane will increase and delays will be decreased by optimizing resource utilization. However, in a network where multiple controllers are used, the data flow between controllers should not be interrupted for network service continuity.
In attacks such as DDoS, the attacker may target blocking the communication between controllers. SDN architecture may crash if communication between the controllers is blocked. In our study, a basic SDN topology with a single controller was used to generate DDoS attack traffic and to obtain the dataset, then to classify DDoS attacks with machine learning models, using this dataset. The use of a single-controller or multi-controller structure in the network topology at the stage of obtaining a dataset from SDN will not make a significant difference in methodology. The machine learning model that we have chosen, as the best among the models trained with the created dataset, can be applied to SDN topologies that contain both single- and multi-controllers.
5. Conclusions
In this study, SDN-based detection systems developed for DDoS attacks were analyzed with machine learning systems. In the first proposed approach, by analyzing flow data, algorithms with 98.3% accuracy ensure the detection of attacks without discriminating the type of traffic. Among the proposed systems, the second approach proceeds by labelling DDoS attacks as normal traffic and attack traffic. With 97.7% sensitivity, KNN algorithms can perform this control by lightening the burden of the controller.
With the feature selection methods used in the study, initially 12 features were selected and the selected subset of features was trained using classifiers. The number of features selected was determined either by the algorithm itself or by the threshold value given to the algorithm. By changing this threshold value, different numbers of features can be selected and trained by the classifier. Different numbers of features can change the accuracy. In general, we observed that the performance rate of all models is above 80% and the algorithms used for this dataset are successful. At the same time, network browsing, attacks between layers, and malicious software can be detected on SDN with this approach. For protecting and improving SDN structure, the second approach can be employed.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}