1. Introduction
The integration of renewables into current power systems is attracting much attention. Indeed, sustainability of energy policies and their mid-term outlooks are currently a topic of interest for major agencies. Ellabban et al. affirm that the renewable energy resource potential is enormous, as such resources can, in principle, exponentially exceed the world’s energy demand [
1]. However, due to the intermittent nature of such renewable energy resources, it is necessary to address different challenging issues, as they are significantly different from the conventional resources [
2]. Moreover, in terms of solar resources, the inherent variability of large-scale solar generation requires an accurate power/irradiance forecasting, which is critical to secure the economic operation of power systems and future smart grids [
3].
A relevant number of methodologies have been proposed to measure and forecast global solar irradiation, being considered essential for the design, economic evaluation, and performance analysis of photovoltaic (PV) power plants and their integration into power systems [
4,
5]. A recent review of power forecasting models for renewables can be found in [
6]. By considering the different methods and proposals, their validations were carried out through a variety of measures of errors based on the author’s criteria and mainly focused on averaged statistical test results. Notton et al. proposed the application of artificial neural networks—assessed by relative root mean square error (rRMSE) and relative mean absolute error (rMAE)—to estimate solar irradiance on tilted planes [
7]. In a similar way, relative mean bias error (rMBE), rRMSE, determination coefficient (
), and ’
d’ Willmott index were used to evaluate both artificial neural networks and support vector machine applications [
8]. Bouchouicha et al. used root mean square error (RMSE) and rRMSE to validate a readjusted model over the Algerian Big South [
9]. Noorian et al. evaluated 12 models to estimate hourly diffuse radiation on inclined surfaces by determining the rRMSE [
10]. An extensive comparison—over 90 contributions—of estimated solar radiation models was performed by Teke et al., to suggest the most accurate models [
11]. In this revision, and according to the most commonly used statistical test results, linear modeling, non-linear modeling, artificial intelligence modeling, and fuzzy approaches were compared accordingly.
According to the specific literature, it can be affirmed that most contributions are evaluated by applying the rRMSE and rMAE. During the last years, different applications have been proposed for global horizontal irradiance (GHI) based on new-generation geostationary satellites; highly appropriate to monitor remote areas and large-scale territories with minimum capital and operating costs. Subsequently, a growing number of solutions and databases are then available online to provide such potential, for instance PVWatts [
12], PVGIS [
13], Global Atlas [
14] and SolarGIS [
15]. Nevertheless, Piasecki et al. affirm in [
16] that, to the best of the authors’ knowledge, the satellite/reanalysis data have so far not been compared with the measurements provided by the National Institute of Meteorology and Water Management (Poland) from the renewable energy sources perspective. Other contributions are focused on analyzing these satellite data. For example, Bódis et al. combined satellite-based and statistical data sources with machine learning to provide a reliable assessment of the technical potential for rooftop PV electricity production with a spatial resolution of 100 m across the European Union (EU) [
17]. Psiloglou et al. recently published a comparison between satellite-based data sets and reanalysis against ground measurements by considering only an isolated rural area [
18]. Boca et al. evaluated a multiple–regression approach model for fast estimation of PV potentials over Europe and Africa based on the PVGIS database and through the mean absolute percent error (MAPE) [
19].
Data based on moderate resolution imaging spectroradiometer (MODIS), along with conventional meteorological data, are used in [
20] to estimate monthly-mean daily global solar radiation. Two statistics: general mean bias deviation (gMBD) and relative general mean bias deviation (rgMBD) are applied in [
21] to validate the estimated GHI by using satellite-based spectral irradiance data. Pierro et al. provided RMSE scores to evaluate PV power estimation and forecasts through satellite and numerical weather prediction data [
22]. In addition, Tang et al. used mean bias error (MBE), RMSE, and rRMSE to evaluate whether GHI estimations can be improved by increasing the frequency of satellite observations. Recently, the mean absolute difference (MAD) was determined in [
23] to compare global irradiation from a satellite estimate model and on-ground measurements. Satellite-based solar radiation data were also used by Buffat et al. to estimate the rooftop solar irradiation potential over large regions. The correlation coefficient and a median monthly relative error were applied to estimate the accuracy of such estimations [
24]. Other authors have proposed methods for estimating the direct normal irradiation from GOES geostationary satellite imagery for concentrating solar systems. In this case, MBE and RMSE averaged values are used to validate the methods [
25]. Pfenninger et al. used RMSE results to validate long-term patterns of European PV output by means of 30 year hourly reanalysis and satellite data [
26]. Ernst et al. compared ground-based and satellite-based irradiance data by using confidence interval results [
27].
By considering the contributions previously discussed, and regarding the appropriate metrics, most of the authors propose and use the following strategies: RMSE, MBE, and the relative versions of each (rRMSE and rMBE), the mean absolute error (MAE), Pearson correlation coefficient (
r), and the standard deviation of the residual (SD). Moreno et al. is a recent example of the metric application from Meteosat Second Generation (MSG) images [
28]. Gueymard reviews validation methodologies and statistical performance indicators for modeled solar radiation data, dividing possible statistical indicators into four categories, directly proposed by the author [
29]. In this framework, a review of the literature demonstrates that there is a lack of agreement in validation strategies for a bankable, satellite-derived solar irradiance dataset [
30]. Therefore, and due to the lack of agreement in validation methodologies of solar irradiance datasets, the aim of this paper is focused on the following objectives:
An extended estimations of metrics to compare GHI satellite data to on-ground data.
A correlation analysis to identify similarities by considering homogeneous behaviors of such metrics.
A principal component analysis (PCA) application to divide the metrics into different categories and propose independent indicator groups to be considered for comparison data purposes.
The rest of the paper is structured as follows.
Section 2 describes the proposed methodology;
Section 3 gives a description of the case study;
Section 4 provides results and discusses the suitability of the proposed characterization; and finally, conclusions are given in
Section 5.
2. Methodology
According to the literature review, different metrics have been defined and used to validate the GHI data from ground measures or satellite–derived data.
Table 1 summarizes such definitions by including expressions and mathematical references, where
and
represent the
satellite-based GHI and the ground-measured GHI values, respectively.
is the normalized value and
n is the number of data samples. By considering previous contributions, a diversity of averaged GHI values have been suggested as the normalizing value in order to determine the relative magnitude of error metrics. For example, Paoli et al. compute the normalized error metrics from the mean global radiation obtained on the season [
31]; Nik et al. calculate monthly mean hourly global solar radiation values [
32]; and Lu et al. estimate daily global solar radiation [
33]. A detailed review of accuracy tests used in the specific literature was reviewed by Teke et al. in [
11]. Therefore, and taking into account the proposed characterization of metrics, the daily average GHI values are considered by the authors to normalize and determine the relative magnitude of error metrics. From the expressions and approaches proposed in previous contributions to characterize the metrics, it is desirable to determine the similarities among them and propose different groups of metrics in order to estimate the complementary information in a data comparison process. A characterization and classification methodology to identify similarities among metrics applied on the GHI data is thus proposed and described. This approach classifies the metric differences for a large amount of irradiance data determined through a variety of sources: satellite–derived, on-ground installations, and/or estimated irradiation values. Therefore, an autonomous and flexible solution to compare different irradiation data sources is proposed in this work; allowing us to select complementary metrics, which offer non-redundant information to evaluate differences among those irradiation data.
The proposed methodology is first based on an estimation of metrics for the different irradiation data sources. Subsequently, a matrix of differences for the different metrics is then determined for each station, according to the selected sample time—a one-hour sample time for the case study discussed in
Section 4. After this initial metric estimation, a multiple correlation analysis is carried out on each station, to identify metrics with a relevant (or not) dependence. This correlation analysis is then used as the input for a clustering process, grouping by each location, those metrics with similar behaviors and thus, metrics that provide similar information. A graphical representation is proposed by the authors to visualize in a more convenient way these multiple correlation results as well as the clustering process.
From these results, we can then compare the clustering results for all locations, estimating the homogeneity of the different groups according to the specific locations. In a complementary way, a statistical analysis—the mean and standard deviation—is then applied to each metric correlation coefficient corresponding to all considered locations. This statistical analysis gives an additional estimation of the homogeneity of such correlations, as well as their independence (or not) from the specific locations. Subsequently, from the clustering process and the additional statistical analysis, we can then estimate the metric correlation dependence from the locations, as well as the similarity of the metric grouping according to a visual comparison of the clustering process.
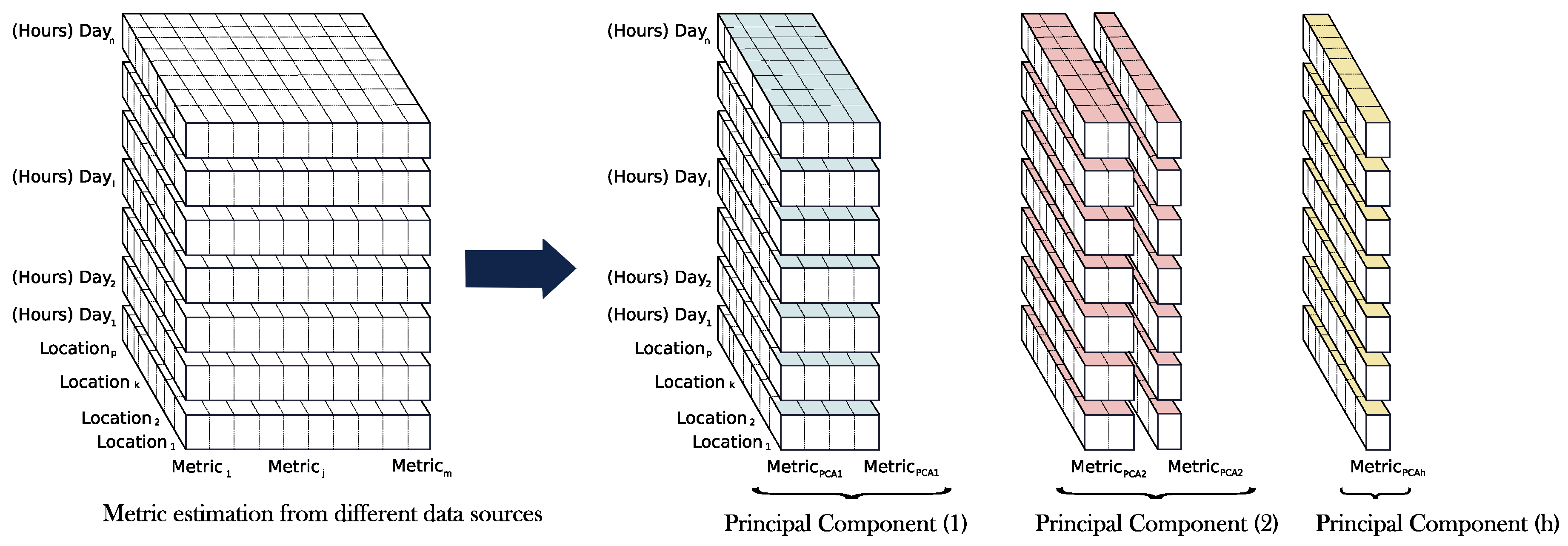
Figure 1 schematically shows the proposed methodology by considering
m different metrics determined from
p-locations and corresponding to
n-days hourly data. The correlation and metric clustering are then carried out by each specific location. Subsequently, a metric clustering estimation for all locations is proposed to determine the homogeneity of such metric clustering processes, including an additional statistical analysis for each group of metrics.
From the previous clustering and statistical analysis, we then propose to apply PCA for all metrics and locations. In fact, PCA is helpful in this context, when the group of variables—the metrics depicted in
Table 1—are highly correlated and a dimensionality reduction is convenient. Moreover, PCA is also an appropriate solution to identify the
’principal components’, which account for most of the variance in the observed/measured variables [
38]. In our case, an
m–dimensional vector [
] is initially identified corresponding to the different metrics determined. A
data matrix
X corresponds to the
observations of the
variable. We then estimate a linear combination of each
m–dimensional vector [
] of matrix
X with maximum variance. Such linear combinations are given by
where
is a
m-dimensional vector of constants [
], and the variance of any such linear combination is given by
, with
S being the sample covariance–variance matrix associated with the data and
denoting the transpose. Identifying the linear combination with maximum variance is equivalent to determining an
m-dimensional vector maximizing
and requiring
. A Lagrange multiplier approach with constraints can be then used to show that the full set of eigenvectors of
S is the solution to the linear combination with a maximum variance problem, obtaining up to
m new linear combinations,
which successively maximize variance, uncorrelated with other linear combinations [
39]. PCA is thus a statistical technique for reducing the dimension of the initial data, increasing their interpretability, but at the same time, minimizing any information loss. A recent PCA review and developments can be found in [
40]. Therefore, and by determining these principal components and their corresponding metric relations, different groups of differences—errors—are then identified and graphically represented. Moreover, they can be selected independently to provide a complementary information about the irradiance data source discrepancies.
Figure 2 shows graphically the PCA application on the irradiance data metrics. As can be seen, different principal components are then estimated according to the metric dependence, decreasing the initial
m-dimension of the metrics, allowing for a low-dimensional graphical representation and providing a reduced number of components independent among them. It is relevant to point out that this metric characterization has not been discussed previously in the specific literature; previous authors proposed a variety of different metrics without analyzing their dependence and subsequently neglecting the possible redundancies of such metrics.
The proposed methodology is implemented in the well-known
R environment [
41]. The following contribution packages are used for methodology implementation purposes:
ggplot2 to create graphics [
42],
corrplot to visualize correlation matrices [
43],
FactoMineR for the PCA application [
44], and
dtw and
dtwclust for the dynamic time warping (DTW) and shape based distance (SBD) metrics estimation [
45,
46].
3. Case Study
Different ground-based meteorological stations were considered, comparing their GHI data to the satellite-based values for one year (2018). For the present analysis, the Network of the Agricultural Information System of Murcia (SIAM) was selected to provide ground-based irradiance data. SIAM consists of 49 automatic stations, ground-based installations that are geographically distributed along the Region of Murcia (11,300 km
); 32 stations are from the Murcian Institute of Agricultural and Food Research and Development (IMIDA) Regional Government of Murcia, 15 are from the Spanish Ministry of Agriculture, Food and Environment, one is from the Universidad Politécnica de Cartagena (Murcia, Spain), and one is from the City Council of Mazarrón (Murcia, Spain). The IMIDA and Ministry stations were financially supported by European fund projects [
47].
Figure 3 shows some examples of such meteorological stations and
Figure 4 depicts some examples of data available online from these ground-based stations. As an attempt to cover a relevant area of study, seven ground-based stations geographically distributed along this south-east Spanish Region have been selected for the present analysis. In this way,
Figure 5 shows the selected ground-based station locations in universal transverse Mercator (UTM) coordinates. The different colors in
Figure 5 are related to the altitude of each ground-based meteorological station (depicted in UTM coordinates). Regarding satellite-based irradiance data, and among the different satellite-based irradiance data currently available online, the authors selected Copernicus, which is the European Union’s Earth Observation Programme. This online platform provides a variety of information services based on satellite earth observation and in situ (non-space) data. The programme is currently coordinated and managed by the European Commission and it is implemented in partnership with the member states, the European Space Agency (ESA), the European Organisation for the Exploitation of Meteorological Satellites (EUMETSAT), the European Centre for Medium-Range Weather Forecasts (ECMWF), EU Agencies, and Mercator Océan. A relevant amount of global data is then available to provide information and help service providers, public authorities and other international organizations. The information services provided are freely and are openly accessible to its users [
48].
According to the information available in the Network of the SIAM, irradiance values were collected by such ground-based meteorological stations, providing hourly average GHI data. Ten-minute sampling time is available for the Copernicus satellite-based data. Therefore, the corresponding hourly average satellite GHI values were then determined from the Copernicus satellite-based data to compare to the ground-based data. Nevertheless, and in line with the study presented by Kim et al. in [
50], hourly average values can smooth the error metric bias. Moreover, if the instantaneous snapshot values are used in the error metric evaluation, the results would be worse. In this case, a total amount of 429,240 data points were initially analyzed, which correspond to the ground-based and satellite-based values accordingly. By considering this initial group of GHI values, a preliminary comparison of data was required to visualize some possible discrepancies among the sources and data. With this aim,
Figure 6 summarizes some consecutive days along 2018 and compares both the irradiance database values by considering hourly average values. The time series of bias, as satellite-based as ground-measured GHI values, are also included in such figure. These days correspond to weeks covering all seasons of the year, where the irradiance levels are considerably different and where several cloudy days and oscillating irradiance values can be also identified.
As a preliminary analysis, the irradiance data from both sources are significantly similar. Moreover, both irradiance curves are practically overlapping and, as was expected, a detailed metric analysis was required to compare the different sources in a more extended way. Subsequently, an estimation of metrics is then determined according to
Table 1, where a variety of metrics used and proposed by previous contributions is summarized. With this aim,
Figure 7 shows the daily evolution of such metrics, depending on each location and with a one hour sample time.
Table 2 summarizes some descriptive statistics of the error metrics (including average values, minimum, maximum, and quartiles). These metrics were determined from both irradiation data sources and they provide a variety of alternatives to estimate the differences between the data. From these metrics, a characterization and classification by considering the proposed methodology, as described in
Section 2, was carried out by the authors. The results are presented and discussed in
Section 4. In addition, PCA was also applied to identify the main relationships among the metrics, reduce the number of variables and allow us a graphical representation of such metrics in a low-dimensional environment.
4. Results
As was previously discussed, by considering the different metrics summarized in
Table 1 and according to the database described in
Section 3, a total of ten metrics are determined by each location, with a one hour sample time and using the 2018 GHI data. Consequently, 17,520 values are then available by each location. An example of such different metrics can be found in
Figure 7. From these preliminary results, an initial correlation analysis for the different locations is first carried out by the authors, in line with the proposed methodology depicted in
Figure 1. These correlations are summarized in
Figure 8, where all of the locations are individually analyzed and depicted. As can be seen, some groups of metrics can be identified, which correspond to a more relevant correlation. Therefore, these preliminary results provide an initial identification of groups of metrics that are highly correlated and, consequently, they offer a similar metric information. As an attempt to characterize the variability of these correlations in terms of the diversity introduced by the geographical dispersion, an additional statistical analysis was proposed and carried out as well. With this aim,
Figure 8 also shows the mean and standard deviation values of the correlation coefficients by considering the metrics results of each location. As can be seen, and in this specific case study, the statistical results provide a low variability of metric correlations and, consequently, it is then proposed to analyze all of the metrics simultaneously and independently of the location. Therefore, the rest of the proposed methodology can be applied simultaneously to all metric estimations and without any dependence on the geographical location. Nevertheless, the proposed methodology can also be applied to other situations where the location dependence is more relevant and it cannot be neglected. In that case, the rest of methodology will be repeated by each location. As an additional result, and following with the present case study,
Figure 9 shows the correlation matrices of the error metrics by considering all locations simultaneously. A similar group of relevant correlations is also identified in line with the previous correlation results depicted in
Figure 8.
In order to explore patterns of similarities and gain an understanding of the structure of variability between metrics, the PCA approach was then applied to the metrics. A reduction of dimension was also achieved by using such analysis. Moreover, by considering only the most relevant components, it should be informative enough to allow for pattern detection in similar metric studies. With this aim, and considering the proposed methodology by including the PCA approach from all metrics and locations as discussed in
Section 2—and graphically given in
Figure 2 for the current case study—the
’principal components’ are subsequently estimated for all metric results. By applying the PCA technique,
Figure 10 shows the scree plot of the components (eigenvalues and percentage of variance accounted for by the principal components). As can be seen, when considering only the four most representative principal components, about 94% of the metric variability can be identified, which significantly reduces the metric dimension from 10-dimensions—see
Table 1 and preliminary results in
Figure 7—to four-dimensions. Therefore, and by considering these results, the first component explains 58.2% of the total variability, while the second component explains 16.1%, leaving the remaining third and fourth component with the explanation of around 10% of the variability for each one. As a consequence, an effective and convenient dimension reduction is achieved by considering the first four components of the PCA algorithm. For a more extensive analysis, the Appendix summarizes both eigenvalue and eigenvector results—see
Table A1 and
Table A2, respectively.
With regard to the relevance of each metric on the selected
’principal components’,
Table 3 provides the relative weight of each metric for the corresponding relevant principal components. The bold marked values in
Table 3 correspond to the most influent metrics for each principal component. In line with these results,
Figure 11 gives the contributions, as a percentage, for each metric variable to the most relevant dimension corresponding to the PCA application. In addition, a dashed-line has been included to point out such relevant metrics corresponding to each dimension. Moreover, the dimensions clearly depend on different metrics, which enhances the preliminary correlations given in
Figure 8 and
Figure 9. Consequently, and in line with a main objective of this work, it is then possible to identify different groups of metrics that provide complementary information and, thus, they can be combined to characterize convenient differences among different database sources.
Finally,
Figure 12 summarizes the metric correlation with the four selected
’principal components’, which represent about 94% of the global metric variability. In this graphical representation, circles correspond to
and
variability explained by the components respectively. Therefore, the area within both circles contains the most representative metrics depending on each principal component. These results are thus a complementary characterization of the metrics, considering their correlation with the selected principal components.
5. Conclusions
A characterization of metrics based on GHI data from different sources is described and assessed in order to identify different groups of similar metrics. From the specific literature, a group of ten different metrics is initially selected, which have been proposed by other contributions to compare different irradiation data. A location dependence analysis and a PCA application process is proposed to characterize such metrics and identify the similarities and explore the differences among them. The proposed methodology has been evaluated from satellite-based and ground-measured GHI data collected for one year in seven different Spanish locations, using average hourly estimations. We analyzed an initial database of 429,240 data points, which corresponds to the satellite-based and ground-measured values accordingly. The selected metrics are determined by each pair of irradiance data and the correlation matrices for each location are estimated.
PCA application allows us to explore similarities among metrics and identify the most relevant ’principal components’. Moreover, a reduction of dimension is also addressed by this technique. In this case, a group of four-’principal components’ is selected, which accounts for 94% of the metric variability. Therefore, a dimension reduction and an identification of metric groups with similar information are provided, which outlines the suitability of the process. Moreover, the initial variety metrics are representative of different principal components and, thus, it is possible to identify and select such groups of metrics that offer complementary information. Non-redundant information metric groups are then available to determine the differences among irradiation database sources. This work provides a solution to compare metrics, despite the lack of agreement in validation strategies for irradiance databases that has been currently detected by the authors.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}