Research on the Knowledge Association Reasoning of Financial Reports Based on a Graph Network

Abstract
:1. Introduction
2. Literature Review
3. Knowledge Graph Network Model of Financial Reports
3.1. Multi-Domain Knowledge Graph of Financial Reports
3.2. Graph Network Generation Function of Text Information in Financial Reports
3.3. Graph Network Generation Module of Text Information in Financial Reports
| Algorithm 1. Generating Module. |
| Input , |
| for do #Compute updated edge attributes |
| end for |
| for do |
| let #Aggregate edge attributes per node |
| # Compute updated node attributes |
| end for |
| let |
| let #Aggregate edge attributes globally |
| #Aggregate node attributes globally |
| #Compute updated global attribute |
| return |
| end function |
4. Applications
4.1. Data Preparation
4.2. Graph Network of Related Transactions in a Single Enterprise
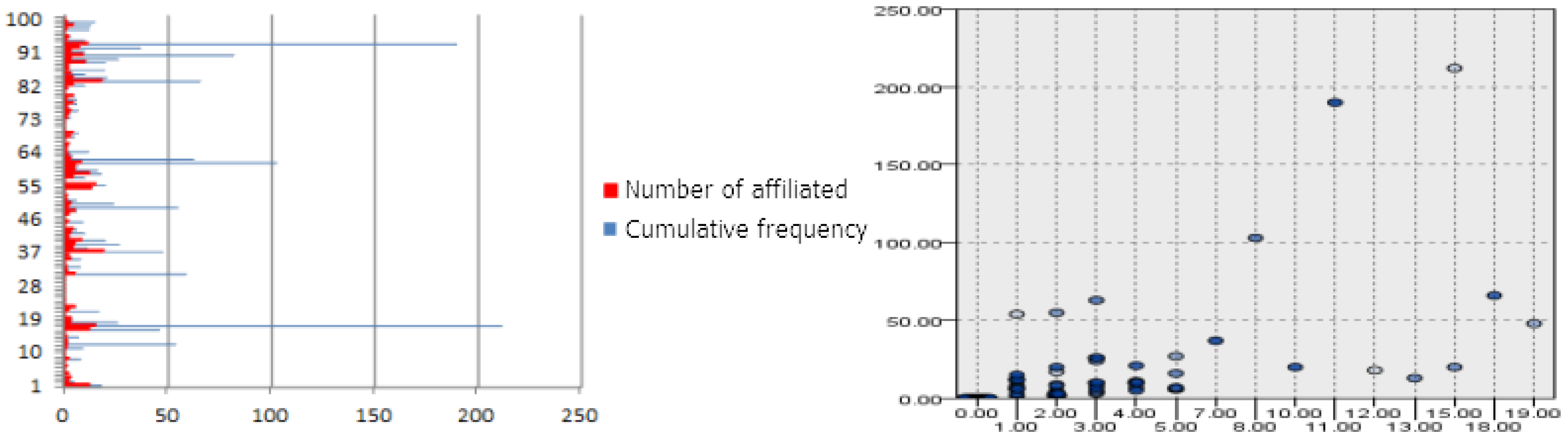
4.3. Graph Network Link Analysis of Enterprise-Related Transactions
4.4. Global Attribute Mining of the Enterprise-Related Transaction Graph Network
5. Discussion
5.1. Similarity
5.2. Distribution of the Clustering Degree
5.3. Clustering Effect
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cazier, R.A.; Pfeiffer, R.J. Why are 10-k filings so long? Account. Horiz. 2015, 30, 150731110748009. [Google Scholar]
- Li, F.; Lundholm, R.; Minnis, M. A Measure of Competition Based on 10-K Filings. J. Account. Res. 2012, 51. [Google Scholar] [CrossRef]
- Hodder, L.; Koonce, L.; McAnally, M.L. SEC market risk disclosures: Implications for judgment and decision making. Account. Horiz. 2001, 15, 49–70. [Google Scholar] [CrossRef]
- Chaudoir, S.R.; Fisher, J.D. The disclosure processes model: Understanding disclosure decision making and postdisclosure outcomes among people living with a concealable stigmatized identity. Psychol. Bull. 2010, 136, 236. [Google Scholar] [CrossRef] [Green Version]
- Mayew, W.J.; Sethuraman, M.; Venkatachalam, M. MD&A disclosure and the firm’s ability to continue as a going concern. Account. Rev. 2015, 90, 1621–1651. [Google Scholar]
- Shirata, C.Y.; Takeuchi, H.; Ogino, S.; Watanabe, H. Extracting key phrases as predictors of corporate bankruptcy: Empirical analysis of annual reports by text mining. J. Emerg. Technol. Account. 2011, 8, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Shuai, F.; Bonan, G.; Guohua, J. Value Investment: A Study on the Cumulative Effects of the Value of Accounting Information. Accouting Res. 2018, 366, 38–46. [Google Scholar]
- Merkley, K.J. Narrative disclosure and earnings performance: Evidence from R&D disclosures. Account. Rev. 2014, 89, 725–757. [Google Scholar]
- Davis, A.K.; Tama-Sweet, I. Managers’ use of language across alternative disclosure outlets: Earnings press releases versus MD&A. Contemp. Account. Res. 2012, 29, 804–837. [Google Scholar]
- Wu, X.; Tian, G.L.; Li, Y.T. Linkage of Operating Information Disclosure and Stock Returns-Analysis Based on Notes to Financial Report Texts. Nankai Bus. Rev. Int. 2019, 3, 173–186. [Google Scholar]
- Song, Y.; Huang, Q. Research on Disclosure of Notes to Financial Statements Based on Text Mining Technology. Friends Account. 2019, 601, 144–149. [Google Scholar]
- Chou, C.C.; Chang, C.J.; Peng, J. Integrating XBRL data with textual information in Chinese: A semantic web approach. Int. J. Account. Inf. Syst. 2016, 21, 32–46. [Google Scholar] [CrossRef]
- Chou, C.C.; Hwang, N.C.R.; Wang, T.; Debreceny, R. The topical link model-integrating topic-centric information in XBRL-formatted reports. Int. J. Account. Inf. Syst. 2018, 29, 16–36. [Google Scholar] [CrossRef]
- Kartun-Giles, A.P.; Bianconi, G. Beyond the clustering coefficient: A topological analysis of node neighbourhoods in complex networks. ChaosSolitons Fractals 2019, 1, 100004. [Google Scholar] [CrossRef]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. Ieee Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Birch, J. Modelling Financial Markets using Methods from Network Theory. Ph.D. Thesis, University of Liverpool, Liverpool, UK, 2015; pp. 48–54. [Google Scholar]
- Tumminello, M.; Aste, T.; Di Matteo, T.; Mantegna, R.N. A tool for filtering information in complex systems. Proc. Natl. Acad. Sci. USA 2005, 102, 10421–10426. [Google Scholar] [CrossRef] [Green Version]
- Di Matteo, T.; Pozzi, F.; Aste, T. The use of dynamical networks to detect the hierarchical organization of financial market sectors. Eur. Phys. J. B 2010, 73, 3–11. [Google Scholar] [CrossRef]
- Musmeci, N.; Nicosia, V.; Aste, T.; Di Matteo, T.; Latora, V. The multiplex dependency structure of financial markets. Complexity 2017. [Google Scholar] [CrossRef]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Gulcehre, C. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Sanchez-Gonzalez, A.; Heess, N.; Springenberg, J.T.; Merel, J.; Riedmiller, M.; Hadsell, R.; Battaglia, P. Graph networks as learnable physics engines for inference and control. In Proceedings of the 35th International Conference on Machine Learning (ICLR), Stockholm, Sweden, 30 April 2018. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. In Advances in Neural Information Processing Systems; Mit Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Kipf, T.; Fetaya, E.; Wang, K.-C.; Welling, M.; Zemel, R. Neural relational inference for interacting systems. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Hamaguchi, K.; Kurihara, T.; Fujimoto, M.; Iemitsu, M.; Sato, K.; Hamaoka, T.; Sanada, K. The effects of low-repetition and light-load power training on bone mineral density in postmenopausal women with sarcopenia: A pilot study. Bmc Geriatr. 2017, 17, 102. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yang, Y.; Zheng, X.; Sun, Z. Coal Resource Security Assessment in China: A Study Using Entropy-Weight-Based TOPSIS and BP Neural Network. Sustainability 2020, 12, 2294. [Google Scholar] [CrossRef] [Green Version]
- Khalili, H.; Rincón, D.; Sallent, S.; Piney, J.R. An Energy-Efficient Distributed Dynamic Bandwidth Allocation Algorithm for Passive Optical Access Networks. Sustainability 2020, 12, 2264. [Google Scholar] [CrossRef] [Green Version]
- Hamrick, J.B.; Allen, K.R.; Bapst, V.; Zhu, T.; McKee, K.R.; Tenenbaum, J.B.; Battaglia, P.W. Relational inductive bias for physical construction in humans and machines. arXiv 2018, arXiv:1806.01203. [Google Scholar]
- Griffiths, T.L.; Chater, N.; Kemp, C.; Perfors, A.; Tenenbaum, J.B. Probabilistic models of cognition: Exploring representations and inductive biases. Trends Cogn. Sci. 2010, 14, 357–364. [Google Scholar] [CrossRef]
- JuChao informaiton network. Available online: www.cninfo.com.cn (accessed on 24 November 2019).
- Language technology platform. Available online: http://www.ltp-cloud.com/ (accessed on 1 February 2020).
- Vo, D.T.; Bagheri, E. Extracting temporal event relations based on event networks. In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2019; pp. 844–851. [Google Scholar]
- Li, P.; Zhou, G.; Zhu, Q. Semantics-based joint model of Chinese event trigger extraction. J. Softw. 2016, 27, 280–294. [Google Scholar]
- Boccaletti, S.; Bianconi, G.; Criado, R.; Del Genio, C.I.; Gómez-Gardenes, J.; Romance, M.; Zanin, M. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef] [Green Version]
- Krzakala, F.; Moore, C.; Mossel, E.; Neeman, J.; Sly, A.; Zdeborová, L.; Zhang, P. Spectral redemption in clustering sparse networks. Proc. Natl. Acad. Sci. USA 2013, 110, 20935–20940. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, S.; Halappanavar, M.; Tumeo, A.; Kalyanaraman, A.; Lu, H.; Chavarria-Miranda, D.; Gebremedhin, A. Distributed louvain algorithm for graph community detection. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 885–895. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Hoffman, M.; Steinley, D.; Brusco, M.J. A note on using the adjusted Rand index for link prediction in networks. Soc. Netw. 2015, 42, 72–79. [Google Scholar] [CrossRef]
- Amini, A.A.; Chen, A.; Bickel, P.J.; Levia, E. Pseudo-likelihood methods for community detection in large sparse networks. Ann. Stat. 2013, 41, 2097–2122. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Space Name | Attribute Description |
|---|---|
| Enterprise attribute space | Correlation property represents the correlation property belonging to the index type and takes an integer value in [1,5]. |
| Size represents the related enterprise scale and belongs to the numerical type. Size = . The amount of registered capital of the related parties is the logarithm with a base of 10,000. | |
| Industry belongs to the index type and adopts the code of the annual industry classification guidance of China Securities Regulatory Commission (CSRC). | |
| Attribute space of transaction relationship | = (Type, Contract amount, Frequency) |
| Type represents the type of related transaction and belongs to the index type. It takes an integer value in [1,11] and refers to the 11 types of related transactions of enterprise accounting standards. | |
| Contract amount refers to the transaction contract amount, which is a numerical type and a positive real number. | |
| Frequency represents the transaction frequency, which belongs to the numerical type and is an integer. | |
| takes the capital flow direction as the marking basis of the access node. For example, in commodity sales, the enterprise receiving funds are in the investment, the enterprise paying the funds are . | |
| Notes | 1. This paper takes the domestic region as an example, and then the overseas region can be embodied by the expanded code. 2. The numerical attributes in the attribute space of the related transactions can only be algebraic, set, or Boolean, while the attributes in the enterprise attribute space can only be set or Boolean. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Z.; Pan, D.; Deng, Y. Research on the Knowledge Association Reasoning of Financial Reports Based on a Graph Network. Sustainability 2020, 12, 2795. https://doi.org/10.3390/su12072795
Liang Z, Pan D, Deng Y. Research on the Knowledge Association Reasoning of Financial Reports Based on a Graph Network. Sustainability. 2020; 12(7):2795. https://doi.org/10.3390/su12072795
Chicago/Turabian StyleLiang, Zhuoqian, Ding Pan, and Yuan Deng. 2020. "Research on the Knowledge Association Reasoning of Financial Reports Based on a Graph Network" Sustainability 12, no. 7: 2795. https://doi.org/10.3390/su12072795
APA StyleLiang, Z., Pan, D., & Deng, Y. (2020). Research on the Knowledge Association Reasoning of Financial Reports Based on a Graph Network. Sustainability, 12(7), 2795. https://doi.org/10.3390/su12072795