Abstract
Until now, the works regarding the relationships between corporate operating performance and corporate social responsibility (CSR) could not reach a conclusive result (positive, natural, and negative). This circumstance can be attributed to two main reasons: (1) inadequate performance measurement and (2) ignoring the multi-dimensional nature of CSR. To combat this, we provided a hybrid decision framework that consisted of two main procedures: (1) performance measurement via linear programming algorithm and (2) CSR’s multi-dimensional nature extraction via text mining. By joint utilization of a linear programming algorithm and text mining, we could gain more insights from the outcome. The proposed decision framework, tested by real cases, is a promising alternative method for performance prediction. Managers can take this model as a roadmap and allocate resources to suitable places, as well as reach the goal of sustainable development.
1. Introduction
Market crises and accounting scandals like Black October 1987, the 1997 Asia financial turmoil, and the subprime mortgage debacle in the U.S. have received tremendous attention from academia and practitioners, as is evident from current financial literature [1]. These extraordinary and unusual events have had fatal side effects or caused damage not only to the respective financial markets, but also to societies as a whole. Due to such practical significance, a considerable amount of research has looked into corporate financial crisis prediction [2,3].
Preliminary works on financial pre-warning models were frequently based on statistical approaches. Although statistical approaches have satisfactory prediction capabilities, they also confront numerous challenges, such as linear separability, multivariate normality, and independent predictor variables, which do not hold up in real-life applications. With the great improvement in information technology, numerous artificial intelligence (AI) techniques that do not obey strict statistical assumptions have been introduced to solve the aforementioned problems [4,5,6]. In contrast to well-examined issues such as credit rating forecasting and financial crisis prediction, research on corporate operating performance forecasting is rather scant. It is, however, widely acknowledged that the main cause of financial crises on the corporate end is poor management, and operating performance is a suitable and reliable proxy for representing the outcome of corporate management [7,8,9]. Kamei [10] also stated that 99% of financial crises are due to bad operating performance—that is, the decline in operating performance can be viewed as a prior stage before a financial crisis bursts forth.
Return on assets (ROA) and return on equities (ROE) are the most commonly executed performance measures for a firm [11,12]. As these measuring criteria are categorized into one input variable and one output variable, they cannot suitably represent the whole facet of a corporation’s operations in a turbulent economic atmosphere. Data envelopment analysis (DEA) can deal with this obstacle, as it can handle multiple input and multiple output variables without an a priori assumption of profit maximization or cost minimization [13]. It can also be extended into different modifications and provide a synthesized outcome, thus offering adequate flexibility for practical applications [14,15,16]. How to precisely measure a corporation’s operating performance and further construct a reliable forecasting model are notable topics for decision makers [17].
Stein [18] stated that lower capital constraints may be one possible avenue to enhance corporate operating performance, because these constraints have a direct impact on a corporation’s ability to undertake major investment decisions and capital structure selections. Benabou and Tirole [19] revealed that a firm with superior corporate social responsibility (CSR) performance can end up with lower capital constraints. The reasons can be summarized as follows. First, better CSR performance is connected to superior stakeholder engagement, which can eliminate short-term risky and opportunistic investment strategies and, as a consequence, decrease whole contracting costs [20]. Second, a firm with better CSR performance, it can spread positive messages to all market participants to signal its long-term focus [19,21]. Finally, better CSR performance is also linked to data accountability and transparency, thus alleviating the obstacle of information asymmetry between managers and investors and leading to lower capital constraints [22,23,24,25,26].
Friedman [27] conversely viewed CSR as an agency problem and indicated that CSR has a negative effect on operating performance due to corporate costs from CSR. Based on the agency cost theory, Brown et al. [28] stated that top executives may benefit themselves utilizing their corporations’ inherent resources through philanthropy while shareholders incur a loss by such spending on charity. Barnea and Rubin [29] also indicated that top executives overinvest in CSR to build up their personal reputation when agency costs are incurred. Despite the large amount of concentration, a basic question remains unanswered: Does CSR lead to value creation (i.e., enhance corporate operating performance)? If so, in what ways? The extant studies so far have failed to give a conclusive answer [30].
Cavaco and Crifo [31] stated that one possible reason for this absence of consensus lies in the fact that CSR policy is multi-dimensional and consists of social, environmental, and business behavior facets. Merely implementing a singular item as a proxy for generic CSR could lead to a confused result about the relationship between CSR and operating performance [32]. Obviously, there is an urgent requirement to break down CSR among dissimilar dimensions so as to realize its possible differential influence on corporate operating performance [33,34]. To deal with the aforementioned challenge, the topic extraction algorithm, called latent Dirichlet allocation (LDA), was formed [35]. After executing the LDA algorithm, one can extract the informative and interpretable topics/dimensions from CSR reports and then examine the effectiveness of each topic/dimension on operating performance.
The valuable topics/dimensions extracted by LDA and performance rank determined by DEA can then be injected into an extreme learning machine (ELM) (one of the neural network-based (NN-based) techniques) to construct the forecasting mechanism. In contract to a traditional NN-based algorithm, an ELM not only reaches superior generalization ability with an efficient calculation speed (i.e., its input weights and hidden biases are arbitrarily decided, and the output weights are computed by performing a Moore–Penrose (MP) generalized inverse), but also avoids many troubles in manually tuning inherent parameters, such as stopping criteria, learning rate, learning epochs, and local minima [36,37,38].
To our knowledge, extant works have not yet established a forecasting model for operating performance that simultaneously integrates numerical information from financial reports and textual information from CSR reports. This study thus further decomposes CSR into numerous dimensions to realize the effect of each dimension on performance forecasting. By doing so, top executives can realize which dimension has a great effect on operating performance and then allocate valuable resources to suitable places to reach the goal of sustainable development.
We believe that the results herein contribute to the corporate finance and CSR literature in several ways. First, this study proposed a novel mechanism to forecast operating performance, which is widely acknowledged as the prior stage to any financial crisis. Second, rather than simply investigating the influence of generic CSR on corporate operating performance, we broke down CSR into numerous dimensions by a topic extraction technique and then examine the effectiveness of each dimension/topic on corporate operating performance. As the CSR dimension was determined by a data-driven technique (i.e., that is, a topic extraction technique tries to let words speak), the result is less reliant on human involvement and more objective. The CSR measures in this study were totally different from previous studies that focused on developing the measurement of a theoretical construct. The study provides a different viewpoint to discuss the impacts of CSR on performance. Finally, employing a Taiwanese database was appealing, because most practical works on CSR and corporate operating performance assessment have focused on developed economies (such as corporations in the U.S. and EU) with less agency cost between manager and shareholders, and, thus, a positive effect of CSR on performance is generally supported. Firms in developing economies (such as Taiwan) and developed economies have distinctive differences in organizational structures and behaviors [39,40]. Lin [41] also stated that the ownership structure in Taiwan is less dispersed than it is in the United States and United Kingdom—that is, the agency problem in developing economies is much more severe than in developed economies. Thus, this study used results in Taiwan to investigate the relationship between CSR and performance.
This paper is organized as follows. It starts with research methodologies adopted for this study, followed by research design, data illustration, and practical results. This paper closes with conclusions and implications for future research.
2. Methodologies
2.1. Data Envelopment Analysis
Introduced by Charnes et al. [42], DEA is a widely used economic analysis quantitative approach to assess the relative efficiency of a homogeneous set of decision-making units (DMUs) with multiple input and output variables. A performance comparison of the DMUs is conducted through an assessment of the differences in their input and output variables [43]. An input index can utilize consumption, such as economic resources, and labor hours; an output index represents output outcomes, such as sales revenues, and productivity. By integrating the input and output indices, we can make a further comparison of each DMU’s economic benefit.
The synthesized index is set up by assigning a weight to these individual indices and then aggregating the weights. The weights of each input variable and output variable are calculated by optimizing the relative efficiency. This is the reason why DEA can handle a problem with uncertain weights of input and output indices and one that contains a large number of objectives in each DMU’s performance assessment. The BCC (Banker–Charnes–Cooper) DEA model was executed in this study as the corporate operating condition often achieves variable return to scale (VRS), due to imperfect competition, government regulation, and financial constraints. In addition, an output orientation was conducted because once a corporate financial investment decision has been made, it is very complicated to disinvest to save the costs by amending input variables, thereby invalidating the output orientation.
The output-oriented BCC DEA model evaluates the relative efficiency of corporations (). Every uses inputs () and generates outputs (). The relative performance score of can be described as follows:
where is the performance score of corporation ; denotes the -th outputs of the -th DMU; represents the -th inputs of the -th DMU; describes a weight of -th output of corporation and denotes a weight of -th input of corporation . In addition, expresses the extremely small positive number to make all positive; denotes intercept. Based on the above-mentioned model, the optimal input/output multiplier can be decided [44].
2.2. Topic Modeling: Latent Dirichlet Allocation (LDA)
Latent Dirichlet allocation (LDA) is an unsupervised probabilistic generative model for describing the latent topics of documents [35]. It models each document as a distribution over topics and each topic as a distribution over words. These distributions are followed by the Dirichlet distribution. Let and represent the set of users and the bag of words determined by a user , respectively. Let be the set of specific words showing up in a bag of words at least once for a user . Here, expresses the set of latent topics, and the volume of topics is given as a parameter. In LDA’s generative procedure, each user has his/her own preference over the topics expressed by a probabilistic distribution that is a multinomial distribution over , denoted by , and each topic also has to follow a multinomial distribution over , expressed by .
Figure 1 expresses the generative procedure of LDA, represented in a graphical style. In Figure 1, circles are implemented to represent the random variables or model parameters in the LDA model. Shaded circles denote the variables or parameters that are observable in the dataset, and the white circles express the unobservable ones that have to be estimated by inferencing mechanisms. The arrows depict the dependencies between variables. We express LDA’s generative procedures below.
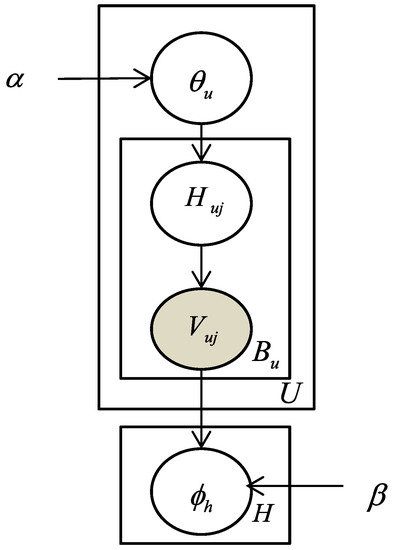
Figure 1.
The graphical expression of latent Dirichlet allocation (LDA) model [45].
For each topic .
Draw a multinomial distribution
For each user .
Draw a multinomial distribution
For each word
(a) Draw a topic
(b) Draw a word
In the LDA model, the multinomial distributions and are sampled from the Dirichlet distribution, there is one kind of conjugate prior distribution, and the inherent parameter of and are and , respectively. Each word in is presumed to be chosen by first drawing a topic , following the topic preference distribution , and subsequently selecting a word from the corresponding distribution of the selected topic . According to the definition of the LDA model, the following equation estimates the probability that a word is constructed by a user .
2.3. The Proposed Model: LDA_ELM_SA
This study introduced an emerging hybrid mechanism, the LDA_ELM_SA model, for operating performance forecasting, which consisted of four main procedures: (1) establishing a CSR-related corpus by a text mining (TM) technique, (2) extracting CSR’s multi-dimensional characteristics by LDA, (3) determining the important features by fuzzy rough set theory (FRST), and (4) constructing a forecasting model by ELM with the self-adaptive mechanism.
• Procedure 1:
In order to handle a tremendous amount of CSR textual information and further condense it into manageable factors, a CSR-related corpus should first be decided. To reliably and soundly establish the CSR-related corpus, we had to gather CSR reports from two different categories: (1) corporations that have received a CSR award (that is, those with good CSR performance), and (2) corporations that have not received a CSR award, or corporations that have violated CSR rules, been fined for environmental pollution, legal problems related to abusing employees, or some social issues (that is, those with bad CSR performance). The CSR award is announced by CommonWealth Magazine, which is one of Taiwan’s most prestigious publishing groups, and is based on four core subjects: corporate governance, enterprise commitment, community involvement and development, and environmental protection.
Li [46] indicated that financial reports contain a large number of optimistic terms that could represent a corporation’s chances of gaining profit in the following years. Based on this concept, we collected CSR reports from two categories and then performed Chi-square to identify the representative special terms from two distinctive categories—that is, the terms in two different categories are quite different. How to quantify the importance of each special term is another interesting topic for users. The entropy technique, which has been commonly performed in computational linguistic analysis as a measure of the relative weights among all special terms, was conducted. As corporate CSR reports are guided by Global Reporting Initiatives (GRI), terms used in the reports are very specific and precise. Thus, the result from the entropy method is reliable.
• Procedure 2:
In order to deal with the nature of CSR’s multi-dimensional characteristics, LDA was performed. LDA is a generative model that can be implemented to a corpus of documents made up of categorical data [35,47,48]. In this algorithm, each document is expressed as a random mixture of latent topics, which are multinomial distributions over the unique words in a corpus [49]. The generative procedure for a document includes determining a topic distribution that satisfies the corpus-level Dirichlet distribution. Sequentially, for each word embedded into the document, a topic is decided and a word is picked up from the corresponding multinomial distribution. After executing the LDA algorithm, we could decompose CSR into some essential dimensions and further match the preserved dimensions with a pre-determined CSR corpus so as to condense a large amount of textual information into manageable elements. By doing that, we could examine which dimension had a great effect on performance.
• Procedure 3:
The collected information was usually full of irrelevant, redundant, and useless material, which in most situations would mislead the research findings, obtain biased results, and increase computational burdens. Feature subset selection is an inevitable prior stage before forecasting model construction. The purpose of feature selection is to remove redundant or useless features without significantly deteriorating the forecasting performance of the model constructed merely by the selected feature subsets being as close as possible to the original class distribution [50]. Rough set theory (RST) was proposed by Pawlak [51] as a tool for handling data with uncertainty, vagueness, and incompleteness and has been applied successfully to feature subset selection and rule induction in numerous research fields [52]. However, the classical RST is defined with equivalence relations that impede its capability at handling data with numerical or fuzzy values [53]. Discretization of the numerical data is one avenue to solve this challenge, but it may result in the problem of information loss. In order to cope with categorical and numerical data in datasets, fuzzy rough set theory (FRST) was introduced by Dübois and Prade [54] through a combination of RST and fuzzy set theory (FST) together. In this approach, a fuzzy similarity relation is executed to assess the similarity between samples. The fuzzy upper and lower approximations of a decision are then determined by utilizing the fuzzy similarity relation [55]. The fuzzy positive region is denoted as the union of the fuzzy lower approximations of decision equivalence classes. As the fuzziness is introduced to RST, more valuable information of real-valued data is easily preserved. Feature subset selection with FRST has gained considerable attention in recent years [56]. Thus, FRST was conducted in this study. For a more detailed illustration of FRST, please refer to Jensen and Shen [57].
• Procedure 4:
The selected features by FRST were finally executed to construct the corporate operating performance forecasting model. In traditional ELM, the number of hidden nodes is pre-decided, and the hidden node parameters are arbitrarily decided and remain unchanged during the training process, resulting in the existence of non-optimal nodes and a failure to reach the aim of cost function minimization [58]. In order to overcome the aforementioned problems, ELM with a self-adaptive (ELM_SA) mechanism was proposed. In ELM_SA, the hidden node learning parameters are optimized by a self-adaptive differential evolution approach, whose trial vector construction strategies and their associated control parameters are self-adaptive in a strategy pool by learning from their prior experiences in providing a promising solution, and the network output weights are computed via the Moore–Penrose (MP) generalized inverse. To ameliorate the impact of over-fitting, five-fold cross-validation was conducted. Figure 2 depicts the flowchart of the proposed LDA_ELM_SA model.
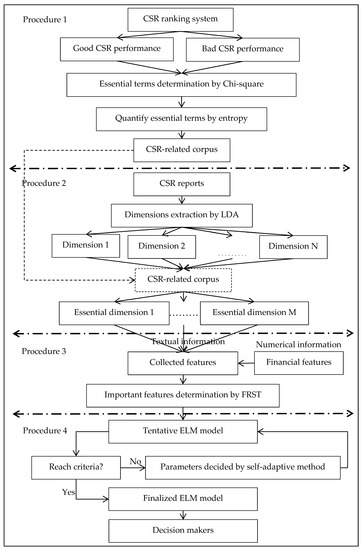
Figure 2.
The flowchart of LDA_ELM_SA model. Abbreviations: CSR—corporate social responsibility, FRST—fuzzy rough set theory, ELM—extreme learning machine, SA—self-adaptive.
2.4. The Empirical Question
After going through the aforementioned procedures (see Figure 2), we introduced the model. The performance status (i.e., dependent indicator) was determined by DEA. The independent indicators were mainly collected from two parts: (1) quantitative predictors derived from financial statements, and (2) qualitative predictors collected from CSR reports. Our study examined whether the CSR textual reports contained supplementary information beyond what numerical indicators could reveal. Therefore, we proposed the following hypothesis.
Hypothesis 1 (H1).
The performance forecasting model with textual indicators has higher forecasting capability than the traditional numerical models.
3. Research Results
3.1. The Sample
Taiwan has not only been admired as an economic miracle of the world, but also has tremendous impacts on the global electronics supply chain and its capital market plays an essential role for global stock market investors. Among all of the industries in Taiwan, the electronics industry has caught the most attention from researchers. It is because the public sectors or central government have announced many financing or investment incentives and allocated tremendous economic resources to this specific industry, turning it into a mainstay of the domestic stock market. Moreover, stock transactions in the electronics sector make up over 70% of Taiwan’s stock market turnover. Thus, this specific industry was taken as our research target, with the data gathered from public websites and databases, such as the Taiwan Stock Exchange (TWSE), Taiwan Economic Journal (TEJ) databank, and Taipei Exchange (TE) from the period 2016–2018.
3.2. The Indicators
Dependent indicator—this study set up a model to forecast which operating performance indicators of corporations belong to the efficient sample and which belong to the inefficient sample. How to appropriately discriminate the efficient samples from inefficient samples is an interesting task. We used DEA to handle the aforementioned task, because it has proven remarkably popular for conducting performance measurement tasks in recent decades. In accordance with previous related works [8,15,16], we chose total assets (TA) and total liabilities (TL) as input variables and designated three profitability measures, return on assets (ROA), sales growth rate (SGR), and profit margin (PM), as output variables. To test the representativeness of the chosen variables, the Pearson correlation was performed.
Table 1 presents the results. We can see that all the chosen variables have a positive correlation—that is, no chosen variables should be omitted. Sequentially, we arranged corporate operating performances from efficient to inefficient guided by the DEA’s synthesized value and further designated the top 20% as the efficient category and the bottom 20% as the inefficient category. Doing so helped us to transform the forecasting problem into a classical binary classification task.

Table 1.
The result of Pearson correlation.
Independent indicators—it is widely recognized that the relationship between corporate operating performance and corporate financial crisis is significantly positive. Thus, the chosen indicators in financial crisis assessment must be reliable in order to become the surrogate for joining up with the independent indicators. The independent indicators implemented herein can be divided into two main categories: (1) numerical financial ratios derived from financial statements and (2) textual indicators derived from CSR reports. To extract the inherent information from multi-dimensional CSR reports, we executed LDA to break down these reports into some manageable dimensions. Perplexity is a commonly used measure in information theory to determine the optimal number of topics as well as to represent how well the model describes a dataset. The lower the perplexity is, the more superior the probabilistic model is [35]. According to the result (see Figure 3), we preserved four topics: environment–business-related dimension (EBRD), product–business-related dimension (PBRD), community–business-related dimension (CBRD), and customer–supplier-related dimension (CSRD).
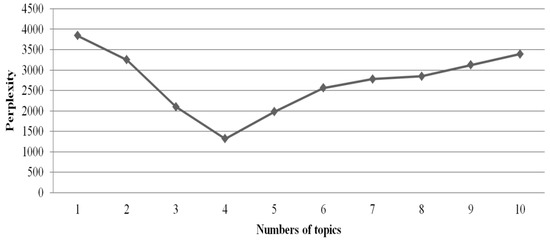
Figure 3.
The perplexity result.
We sequentially matched each dimension’s textual information with the pre-determined CSR-related corpus to convert a large amount of textual information into numerical information, as well as to eliminate computational cost. The CSR-related corpus was constructed by the joint utilization of the Chi-square approach () and entropy.
The Chi-square approach () was first used to extract the representative special terms from both categories (i.e., good CSR performance and bad CSR performance), which has demonstrated its usefulness in text categorization [59]. Entropy has been successfully implemented in computational linguistic analysis as a measure of the relative weights among all special terms [50], and thus it was conducted to determine the strength of each term. After finishing all the processes, we established the CSR-related corpus (i.e., a weighted list of words) (see Table 2). This corpus consists of two parts: one makes up the optimistic terms with a specific weight within the good CSR performance category, and the other encompasses the pessimistic terms with a specific weight within the bad CSR performance category. Table 3 presents the independent indicators used in this study.
Table 2.
The partial of CSR-related corpus.
Table 3.
The independent indicators.
Figure 4 illustrates the difference of each CSR-related dimension between a corporation with superior operating status and a corporation with inferior operating status. The result reveals that a corporation with superior operating performance played a satisfactory job in CSR performance among all assessing criteria. This finding corresponds to the previous work done by McGuire et al. [60] who stated that a corporation with better CSR performance may face relatively lower capital constraints, fewer labor problems, and consumers who may be favorably disposed to its products as well as enhance its economic benefits. Furthermore, a corporation with better CSR performance may also have a lower financial risk owing to sustaining much more stable relations with the public sectors and financial communities.
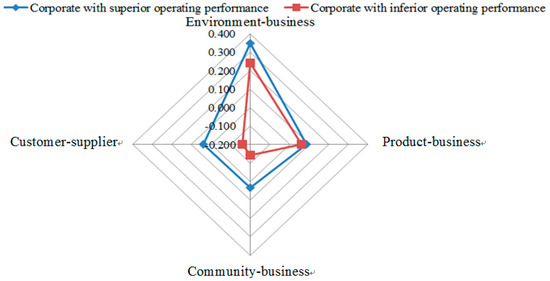
Figure 4.
The CSR-related results.
3.3. The Practical Results
Before forecasting model construction, the feature subset selection technique was executed by FRST, which is an inevitable data pre-processing procedure in data mining and pattern recognition domains. Figure 5 depicts the selected features.
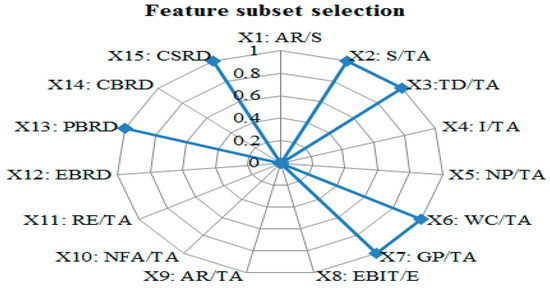
Figure 5.
The selected feature subsets.
One of the interesting findings is that the selected features include CSR-related indicators. To examine the effectiveness of CSR-related indicators, this study set up two scenarios: (1) the model with CSR-related indicators and (2) the model without CSR-related indicators. There are many performance measures proposed for classification, with the commonly implemented performance measures being accuracy and error rate. However, merely performing one assessment criterion to determine the quality of the forecasting model is not reliable and trustworthy. Thus, this study adopted two other performance measures: sensitivity and specificity. The confusion matrix (see Table 4) and performance measures are illustrated as follows.
Table 4.
The confusion matrix.
- Overall accuracy: OA = (TN + TP)/(TP + FP + FN + TN)
- Sensitivity: Sen = (TP)/(TP + FN)
- Specificity: Spe = (TN)/(TN + FP)
Table 5 lists the forecasting results. To ensure the outcomes did not happen by chance, this study evaluated the significance of these results through a statistical examination. The Wilcoxon signed-ranks test, a non-parametric alternative to the paired t-test, was undertaken. It assumes commensurability of difference, but merely qualitatively: greater differences still count more, which are probably desired, but their absolute magnitudes are ignored [61]. From the aspect of statistics, this test is safer than the paired t-test since it does not assume normal distributions. Furthermore, the outliers have a lesser influence on the Wilcoxon signed-ranks test than on the paired t-test [61]. Table 6 depicts the result. We can see that the model going through the feature selection procedure posed higher forecasting performance (see Model A vs. Model C; Model B vs. Model D). It was because the feature selection posed numerous benefits, such as decreasing a model’s forecasting bias, alleviating the storage requirement, and facilitating data visualization ability. The result also revealed that the forecasting model with CSR-related information not only had higher forecasting performance, but also played a satisfactory role in the other two assessing measures (see Model C vs. Model D). This finding is in accordance with Huang et al. [62], who stated that textual information can bring salient and incremental inherent information beyond a numerical aggregation from financial statements. Even a small improvement in forecasting quality can translate into large future savings for market participants. Due to the essence of textual information, the forecasting model construction should take this kind of information into consideration in order to reach a win–win station [17,63]. According to all of the experimental designs, the proposed model is a promising alternative for corporate operating performance forecasting. Decision makers can take it as a decision support system to allocate their valuable resources to reliable targets and to assist in forming their final decisions.
Table 5.
The forecasting results (Avg. %).
Table 6.
The statistical results.
3.4. Robustness Examination
A large number of previous related works choosing a model with the best forecasting performance actually merely rely on one pre-decided database. It is a widely accepted idea that different assessment measures will result in different research outcomes. To strengthen the final decision we made, we tested the proposed model with another database. The variable of return on equities (ROE) was taken as a performance measure in the new database. The outcome is in Table 7. We can easily see that the proposed model still outperforms the other three mechanisms under whole assessment criteria.
Table 7.
The outcomes.
The introduced model could also be extended to a classifier ensemble. The basic idea of a classifier ensemble is to take advantage of various information outcomes by multiple dissimilar case classifiers instead of using the outcome of a traditional single classifier, so that forecasting performance can be facilitated and a biased decision can be prevented [64]. The consensus of domain experts attests to the effectiveness of a classifier ensemble resting on the preciseness and diversity of the base classifier [65,66].
To increase the range of the proposed model, this study executed two approaches: (1) kernel type diversity and (2) inherent parameter diversity. To make a fair comparison, this study took the proposed model with an ensemble structure as a benchmark and compared it with other classifier ensembles for operating performance forecasting, such as a neural network ensemble (NNE) [67] and support vector machine ensemble (SVME) [68]. Table 8 lists the test result, which proves that the proposed model performs a satisfactory job in forecasting the task with higher quality. No matter which structure the proposed model belongs to (individual or ensemble), it is indeed a promising alternative for corporate operating performance forecasting.
Table 8.
The comparison results.
To further examine the explanation ability of CSR-related ratios, we put the selected ratios into the regression model. We can see that the model with CSR-related ratios had a higher explanation ability than the model without CSR-related ratios. The results (see Table 9) provide evidence for the usefulness of textual information.
Table 9.
The results.
3.5. Discussion
For more than three decades of CSR discussions and debates in previous research works, no single and conclusive definition of this concept exists [69]. One definition comes from the European Commission, in which CSR as a “concept whereby firms integrate social and environmental concerns in their business operations and in their interaction with their stakeholders on a voluntary basis” appears to be the most suitable description of it. The relationship between CSR and corporate financial performance turns out to be the most widely studied topic in both business and society literature [70,71,72]. Many empirical studies have been conducted over the last three decades, but still do not reach consistent results [73]. Follow-up review studies and empirical works [74,75] conclude on balance that there is a positive, yet mild, relationship between CSR and a firm’s financial performance. Despite this expanding stream of literature, academics and practitioners are still uncertain when it comes to assessing which specific dimension of CSR is the most effective toward a firm’s financial performance [72,73].
To fill the gap in both the CSR and financial performance literature, this study decomposed CSR into numerous dimensions by LDA and further examined each CSR dimension’s influence on a firm’s financial performance. LDA is a data-driven technique without human intervention (that is, it tries to let words speak). Thus, the results derived from LDA are much more objective. As such, firm managers can realize which dimension helps facilitate the firm’s financial performance and re-allocate resources to suitable places.
The research targets in this paper were resource-abundant publicly-listed firms. The managers of these firms are likely to undertake, for example, an employee training program or a boarder community program, because doing so would generate some benefits for the firm’s future prospects [73]. On the other hand, managers of resource-scarce, non-publicly-listed firms (small- and medium-sized enterprises, SMEs) have greater chances to postpone such investments and prioritize more pressing requirements [76]. This is consistent with previous research work done by Panwar et al. [73], who indicated that the firm’s level of CSR highly relates to its financial resources. To gain a more holistic perspective of CSR’s impact on a firm’s financial performance, the study should have taken publicly-listed and non-publicly-listed firms into consideration. However, due to a lack of availability of non-publicly-listed firms’ data, this study just considered publicly-listed firms’ data to reach our research findings.
Clearly distinguishing between CSR dimensions makes it easier and more tangible for decision makers to assess CSR engagement’s benefits by focusing on their firm’s stakeholders: customers, employees, suppliers, shareholders, environment, and the local community [77]. Phole and Hittner [78] indicated that a qualitative research method seems to be a proper approach to depict the relationships between CSR dimensions. Thus, much research relied on solid qualitative methods to determine the components of CSR [77]. The customer domain encompasses issues such as fair prices, clear labeling, safe and high-quality products, etc. The employee domain addresses issues like appropriate remuneration, reliable promotion systems, and good working conditions. The supplier domain emphasizes the topic of the fairness of issues like supplier determination, internal auditing, product conditions, and shipping contracts. The shareholder domain addresses topics that generate profit and maximize personal wealth. The environment domain consists of topics such as a reduction in polluted products and wastes, eliminating toxic chemicals, and saving energy. The local community covers topics such as creating jobs for people living in the community, making contributions to a region’s development, and sourcing locally. All addressed domains are included in CSR. However, this study just considered four dimensions of CSR (environment–business-related dimension: EBRD, product–business-related dimension: PBRD, community–business-related dimension: CBRD, and customer–supplier-related dimension: CSRD) by performing a perplexity score and further examined each dimension on a firm’s financial performance. To reach an overarching and robust conclusion, future studies can take more dimensions into consideration and examine each dimension’s impact on a firm’s financial performance.
4. Conclusions and Implications
Prior related works have yielded non-conclusive results regarding the relationships between corporate operating performance and corporate social responsibility. Those conflicting results may be attributed to two differences in measuring financial performance and CSR status [32,79]. Accounting-based ratios, such as ROA and ROE, are the most commonly implemented to determine corporate operating performance, but they are categorized into the domain of one input variable and one output variable. However, employing only one input variable and one output variable to determine such performance is not reliable in this highly fluctuating economic atmosphere. To overcome the obstacle, this study executed DEA as it can handle multiple input variables and multiple output variables simultaneously.
A firm’s CSR policy is multi-dimensional and includes numerous aspects, such as environmental, business, and social factors [79]. Performing merely one general indicator to depict a corporation’s CSR status could cause some uncertainties. Thus, to better understand the relationship between CSR and corporate financial performance, this study opened up the black-box of CSR (i.e., breaking it into numerous dimensions by LDA) and examined the impact of each CSR dimension on corporate financial performance. Doing so allows top executives to allocate limited resources to specific CSR dimensions that are highly related to corporate financial performance.
In contrast with well-studied works such as financial crisis prediction, research on corporate operating performance is quite rare. It is widely deemed that a corporation with worse operating performance could be at the stage before a financial crisis bursts out. If top executives can receive this red flag signal (that is, crisis warning signal) earlier, then they can initiate a modification of their firm’s capital structure and adjust investment strategies so as to enhance its risk absorbing ability. To our knowledge, there is no study in the literature that has introduced a model for corporate operating performance forecasting that simultaneously considers multiple dimensions of CSR broken down by LDA and uses DEA as the performance measure. To fill this gap in the CSR and corporate finance literature, this study proposed an emerging corporate operating performance forecasting model that consists of multiple dimensions of CSR, feature subset selection by FRST, and model construction by ELM_SA. The proposed model, examined through real cases, is a promising alternative for corporate operating performance.
This study had some limitations that could be addressed in future studies. First, we worked on the target sample of Taiwan’s electronic industry, which suggests that the ability to generalize the results is limited. Second, future research can enhance the model’s forecasting quality by integrating much more sophisticated structures, such as ensemble learning and stacking [80,81]. Finally, recent related works suggest that the debate concerning corporate operating performance and CSR status should be taken further by including additional intermediate variables or the variables derived from theoretical constructs that can enhance our realization of the procedures through which CSR influences corporate operating performance [72,73,76,82].
Author Contributions
Conceptualization, Y.-L.H. and M.L.; methodology, M.L.; software, M.L.; validation, Y.-L.H.; formal analysis, Y.-L.H.; investigation, Y.-L.H. and M.L.; resources, Y.-L.H.; data curation, Y.-L.H.; writing—original draft preparation, Y.-L.H. and M.L.; writing—review and editing, Y.-L.H. and M.L.; visualization, Y.-L.H. and M.L.; supervision, M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yu, L.; Wang, S.; Lai, K.K.; Wen, F. A multiscale neural network learning paradigm for financial crisis forecasting. Neurocomputing 2010, 73, 716–725. [Google Scholar] [CrossRef]
- Lin, C.H. Did international production/distribution networks mitigate the effect of the global financial crisis? Evidence from Taiwan machinery industry. Asia-Pac. J. Acc. E 2018, 25, 98–112. [Google Scholar] [CrossRef]
- Wang, T.; Wang, Y.; McLeod, A. Do health information technology investments impact hospital financial performance and productivity? Int. J. Acc. Inform. Syst. 2018, 28, 1–13. [Google Scholar] [CrossRef]
- Back, B.; Toivonen, J.; Vanharanta, H.; Visa, A. Comparing numerical data and text information from annual reports using self-organizing maps. Int. J. Acc. Inform. Syst. 2001, 2, 249–269. [Google Scholar] [CrossRef]
- Gray, G.L.; Debreceny, R.S. A taxonomy to guide research on the application of data mining to fraud detection in financial statement audits. Int. J. Acc. Inform. Syst. 2014, 15, 357–380. [Google Scholar] [CrossRef]
- Amani, F.A.; Fadlalla, A.M. 2017. Data mining applications in accounting: A review of the literature and organizing framework. Int. J. Acc. Inform. Syst. 2017, 24, 32–58. [Google Scholar] [CrossRef]
- Xu, X.; Wang, Y. Financial failure prediction using efficiency as a predictor. Expert Syst. Appl. 2009, 36, 366–373. [Google Scholar] [CrossRef]
- Hsu, M.F.; Yeh, C.C.; Lin, S.J. Integrating dynamic Malmquist DEA and social network computing for advanced management decisions. J. Intell. Fuzzy Syst. 2018, 35, 231–241. [Google Scholar] [CrossRef]
- Hsu, M.F. A fusion mechanism for management decision and risk analysis. Cyber Syst. 2019, 50, 497–515. [Google Scholar] [CrossRef]
- Kamei, T. Risk Management; Dobunkan: Tokyo, Japan, 1997. [Google Scholar]
- Magni, C.A. Investment, financing and the role of ROA and WACC in value creation. Eur. J. Oper. Res. 2015, 244, 855–866. [Google Scholar] [CrossRef]
- Rodriguez-Fernandez, M. Social responsibility and financial performance: The role of good corporate governance. BRQ Bus. Res. Quart. 2016, 19, 137–151. [Google Scholar] [CrossRef]
- Zhu, J. Multi-factor performance measure model with an application to Fortune 500 companies. Eur. J. Oper. Res. 2000, 123, 105–124. [Google Scholar] [CrossRef]
- Lin, B.; Fei, R. Regional differences of CO2 emissions performance in China’s agricultural sector: A Malmquist index approach. Eur. J. Agron. 2015, 70, 33–40. [Google Scholar] [CrossRef]
- Sueyoshi, T.; Goto, M. Undesirable congestion under natural disposability and desirable congestion under managerial disposability in U.S. electric power industry measured by DEA environmental assessment. Energ. Econ. 2016, 55, 173–188. [Google Scholar] [CrossRef]
- Hsu, M.F.; Chang, T.M.; Lin, S.J. News-based soft information as a corporate competitive advantage. Technol. Econ. Dev. Econ. 2020, 26, 48–70. [Google Scholar] [CrossRef]
- Zhu, Q.; Liu, J.; Lai, K. Corporate social responsibility practices and performance improvement among Chinese national state-owned enterprises. Int. J. Prod. Econ. 2016, 171, 417–426. [Google Scholar] [CrossRef]
- Stein, J. Agency, information, and corporate investment. In Handbook of the Economics of Finance; Constantinides, G., Harris, M., Stulz, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2003; pp. 111–166. [Google Scholar]
- Benabou, R.; Tirole, J. Individual and corporate social responsibility. Economica 2010, 77, 1–19. [Google Scholar] [CrossRef]
- Liang, D.; Lu, C.C.; Tsai, C.F.; Shih, G.A. Financial ratios and corporate governance indicators in bankruptcy prediction: A comprehensive study. Eur. J. Oper. Res. 2016, 252, 561–572. [Google Scholar] [CrossRef]
- Dhaliwal, D.; Li, O.Z.; Tsang, A.H.; Yang, Y.G. Voluntary non-financial disclosure and the cost of equity capital: The case of corporate social responsibility reporting. Acc. Rev. 2011, 86, 59–100. [Google Scholar] [CrossRef]
- Botosan, C. Disclosure level and the cost of equity capital. Acc. Rev. 1997, 72, 323–349. [Google Scholar]
- Chen, K.; Chen, Z.; Wei, K. Legal protection of investors, corporate governance, and the cost of equity Capital. J. Corp. Financ. 2009, 15, 273–289. [Google Scholar] [CrossRef]
- El-Ghoul, S.; Guedhami, O.; Kwok, C.C.Y.; Mishra, D.R. Does corporate social responsibility affect the cost of capital? J. Bank Financ. 2011, 35, 2388–2406. [Google Scholar] [CrossRef]
- Hu, K.H.; Lin, S.J.; Hsu, M.F. A fusion approach for exploring the key factors of corporate governance on corporate social responsibility performance. Sustainability 2018, 10, 1582. [Google Scholar] [CrossRef]
- Činčalová, S.; Hedija, V. Firm characteristics and corporate social responsibility: The case of Czech transportation and storage industry. Sustainability 2020, 10, 3872. [Google Scholar] [CrossRef]
- Friedman, M. Money and income: Comment on Tobin. Q. J. Econ. 1970, 84, 318–327. [Google Scholar] [CrossRef]
- Brown, W.; Helland, E.; Smith, J. Corporate philanthropic practices. J. Corp. Finan. 2006, 12, 855–877. [Google Scholar] [CrossRef]
- Barnea, A.; Rubin, A. Corporate social responsibility as a conflict between shareholders. J. Bus. Ethics 2010, 97, 71–86. [Google Scholar] [CrossRef]
- Margolis, J.D.; Elfenbein, H.A.; Walsh, J.P. Does it Pay to be Good? A Meta-Analysis and Redirection of Research on the Relationship between Corporate Social and Financial Performance; Working paper; Harvard Business School, Harvard University: Boston, MA, USA, 2007. [Google Scholar]
- Cavaco, S.; Crifo, P. CSR and financial performance: Complementarity between environmental, social and business behaviours. Appl. Econ. 2014, 46, 3323–3338. [Google Scholar] [CrossRef]
- Surroca, J.; Tribò, J.A.; Waddock, S. Corporate responsibility and financial performance: The role of intangible resources. Strateg. Manag. J. 2010, 31, 463–490. [Google Scholar] [CrossRef]
- Crifo, P.; Diaye, M.A.; Pekovic, S. CSR related management practices and firm performance: An empirical analysis of the quantity–quality trade-off on French data. Int. J. Prod. Econ. 2016, 171, 405–416. [Google Scholar] [CrossRef]
- Barcos, L.; Barroso, A.; Surroca, J.; Tribo, J. Corporate social responsibility and inventory policy. Int. J. Prod. Econ. 2013, 143, 580–588. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L. Convex incremental extreme learning machine. Neurocomputing 2007, 70, 3056–3062. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef]
- Fan, J.; Wei, K.C.; Xu, X. Corporate finance and governance in emerging markets: A selective review and an agenda for future research. J. Corp. Financ. 2011, 17, 207–214. [Google Scholar] [CrossRef]
- Kao, E.H.; Yeh, C.C.; Wang, L.H.; Fung, H.G. The relationship between CSR and performance: Evidence in China. Pac. Basin Financ. J. 2018, 51, 155–170. [Google Scholar] [CrossRef]
- Lin, T.H. A cross model study of corporate financial distress prediction in Taiwan: Multiple discriminant analysis, logit, probit and neural networks models. Neurocomputing 2009, 72, 3507–3516. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W.; Thrall, R.M. Classifying and characterizing efficiencies and inefficiencies in data development analysis. Oper. Res. Lett. 1986, 5, 105–110. [Google Scholar] [CrossRef]
- Lai, P.L.; Potter, A.; Beynon, M.; Beresford, A. Evaluating the efficiency performance of airports using an integrated AHP/DEA-AR technique. Transp. Policy 2015, 42, 75–85. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Li, F. The information content of forward-looking statements in corporate filings-A naive Bayesian machine learning approach. J. Acc. Res. 2010, 48, 1049–1102. [Google Scholar] [CrossRef]
- Blei, D.M.; Jordan, M. Variational inference for Dirichlet process mixtures. J. Bayesian Anal. 2006, 1, 121–144. [Google Scholar] [CrossRef]
- Zhang, W.; Clark, R.A.J.; Wang, Y.; Li, W. Unsupervised language identification based on Latent Dirichlet Allocation. Comput. Speech Lang. 2016, 39, 47–66. [Google Scholar] [CrossRef]
- Speier, W.; Ong, M.K.; Arnold, C.W. Using phrases and document metadata to improve topic modeling of clinical reports. J. Biomed. Inform. 2016, 61, 260–266. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 1, 341–356. [Google Scholar] [CrossRef]
- Banerjee, M.; Mitra, S.; Banka, H. Evolutionary rough feature selection in gene expression data. IEEE Trans. Syst. Man Cybern. Part C 2007, 7, 622–632. [Google Scholar] [CrossRef]
- Hu, Q.; An, S.; Yu, D. Soft fuzzy rough sets for robust feature evaluation and selection. Inf. Sci. 2010, 180, 4384–4400. [Google Scholar] [CrossRef]
- Dübois, D.; Prade, H. Rough fuzzy sets and fuzzy rough sets. Int. J. Gen. Syst. 1990, 17, 191–209. [Google Scholar] [CrossRef]
- Wang, C.; Shao, M.; He, Q.; Qian, Y.; Qi, Y. Feature subset selection based on fuzzy neighborhood rough sets. Knowl. Based Syst. 2016, 111, 173–179. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. New approaches to fuzzy–rough feature selection. IEEE Trans. Fuzzy Syst. 2009, 17, 824–838. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. Fuzzy-rough data reduction with ant colony optimization. Fuzzy Sets Syst. 2005, 149, 5–20. [Google Scholar] [CrossRef]
- Cao, J.; Lin, Z.; Huang, G.B. Self-adaptive evolutionary extreme learning machine. Neural Process Lett. 2012, 36, 285–305. [Google Scholar] [CrossRef]
- Chen, Y.T.; Chen, M.C. Using chi-square statistics to measure similarities for text categorization. Expert Syst. Appl. 2011, 38, 3085–3090. [Google Scholar] [CrossRef]
- McGuire, J.B.; Sundgren, A.; Schneeweis, T. Corporate social responsibility and firm financial performance. Acad. Manag. J. 1988, 31, 854–872. [Google Scholar]
- Demsar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn Res. 2006, 7, 1–30. [Google Scholar]
- Huang, A.; Zang, A.; Zheng, R. Evidence on the information content of text in analyst reports. Acc. Rev. 2014, 89, 2151–2180. [Google Scholar] [CrossRef]
- Lin, S.J.; Hsu, M.F. Decision making by extracting soft information from CSR news report. Technol. Econ. Dev. Econ. 2018, 24, 1344–1361. [Google Scholar] [CrossRef]
- Hou, S.; Ramani, K. Classifier combination for sketch-based 3D part retrieval. Comput. Graph. 2007, 31, 598–609. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Using diversity measures for generating error-correcting output codes in classifier ensembles. Pattern Recogn. Lett. 2005, 26, 83–90. [Google Scholar] [CrossRef]
- Sharkey, A.J.C.; Sharkey, N.E. Combining diverse neural nets. Knowl. Eng. Rev. 1997, 12, 231–247. [Google Scholar] [CrossRef]
- West, D.; Dellana, S.; Qian, J. Neural network ensemble strategies for financial decision applications. Comput. Oper. Res. 2005, 32, 2543–2559. [Google Scholar] [CrossRef]
- Li, X.; Wang, F.; Chen, X. Support vector machine ensemble based on choquet integral for financial distress prediction. Int. J. Pattern Recogn. 2015, 29, 1550016. [Google Scholar] [CrossRef]
- Freeman, R.E.; Harrison, J.S.; Wicks, A.C.; Parmar, B.L.; DeColle, S. Stakeholder Theory—The State of the Art; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Pérez, A.; Martínez, P.; Rodríguez del Bosque, I. The development of a stakeholder-based scale for measuring corporate social responsibility in the banking industry. Serv. Bus. 2013, 7, 459–481. [Google Scholar] [CrossRef]
- Martínez, P.; Pérez, A.; Bosque, I.R. Measuring Corporate Social Responsibility in tourism: Development and validation of an efficient measurement scale in the hospitality industry. J. Travel Tour. Mark. 2013, 30, 365–385. [Google Scholar] [CrossRef]
- Öberseder, M.; Schlegelmilch, B.B.; Murphy, P.E.; Gruber, E. Consumers’ Perceptions of Corporate Social Responsibility: Scale Development and Validation. J. Bus. Ethics 2014, 124, 101–115. [Google Scholar] [CrossRef]
- Panwar, R.; Nybakk, E.; Hansen, E.; Pinkse, J. Does the Business Case Matter? The Effect of a Perceived Business Case on Small Firms’ Social Engagement. J. Bus. Ethics 2017, 144, 597–608. [Google Scholar] [CrossRef]
- Carroll, A.B.; Shabana, K.M. The business case for corporate social responsibility: A review of concepts, research and practice. Int. J. Manag. Rev. 2010, 12, 85–105. [Google Scholar] [CrossRef]
- Endrikat, J.; Guenther, E.; Hoppe, H. Making sense of conflicting empirical findings: A meta-analytic review of the relationship between corporate environmental and financial performance. Eur. Manag. J. 2014, 32, 735–751. [Google Scholar] [CrossRef]
- Fassin, Y. SMEs and the fallacy of formalising CSR. Bus. Ethics A Eur. Rev. 2008, 17, 364–378. [Google Scholar] [CrossRef]
- Öberseder, M.; Schlegelmilch, B.B.; Gruber, V. Why don’t consumers care about CSR?’: A qualitative study exploring the role of CSR in consumption decisions. J. Bus. Ethics 2011, 104, 449–460. [Google Scholar] [CrossRef]
- Phole, G.; Hittner, J. Attaining Sustainability Growth Through Corporate Social Responsibility; IBM Global Services: New York, NY, USA, 2008. [Google Scholar]
- Ullmann, A.A. Data in search of a theory: A critical examination of the relationships among social performance, social disclosure, and economic performance of U.S. firms. Acad. Manag. Rev. 1985, 10, 540–557. [Google Scholar]
- Hsu, M.F.; Chang, T.M. Integration of incremental filter-wrapper selection strategy with artificial intelligence for enterprise risk management. Int. J. Mach. Learn Cyb. 2018, 9, 477–489. [Google Scholar]
- Lin, S.J.; Chang, T.M.; Hsu, M.F. An emerging online business decision making architecture in a dynamic economic environment. J. Intell. Fuzzy Syst. 2019, 37, 1893–1903. [Google Scholar] [CrossRef]
- Zhang, Y.; Lee, M. A hybrid model for addressing the relationship between financial performance and sustainable development. Sustainability 2019, 11, 2899. [Google Scholar] [CrossRef]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).