3.1. Proposed Identification Model
In this section, we introduce and discuss in detail our proposed detection model for hearing-loss symptoms. The model diagram shows the components of the proposed model and how each component processes the data. The NB algorithms and Frequent Pattern (FP Growth) were employed in the model as machine learning (ML) methods. A full description of those methods with the reasons behind employing them in the model is provided in this section. In healthcare literature [
30,
31,
32], these methods are commonly used for similar illness and they were reasonably efficient and successful. This has motivated us to utilize these methods in our proposed model. In
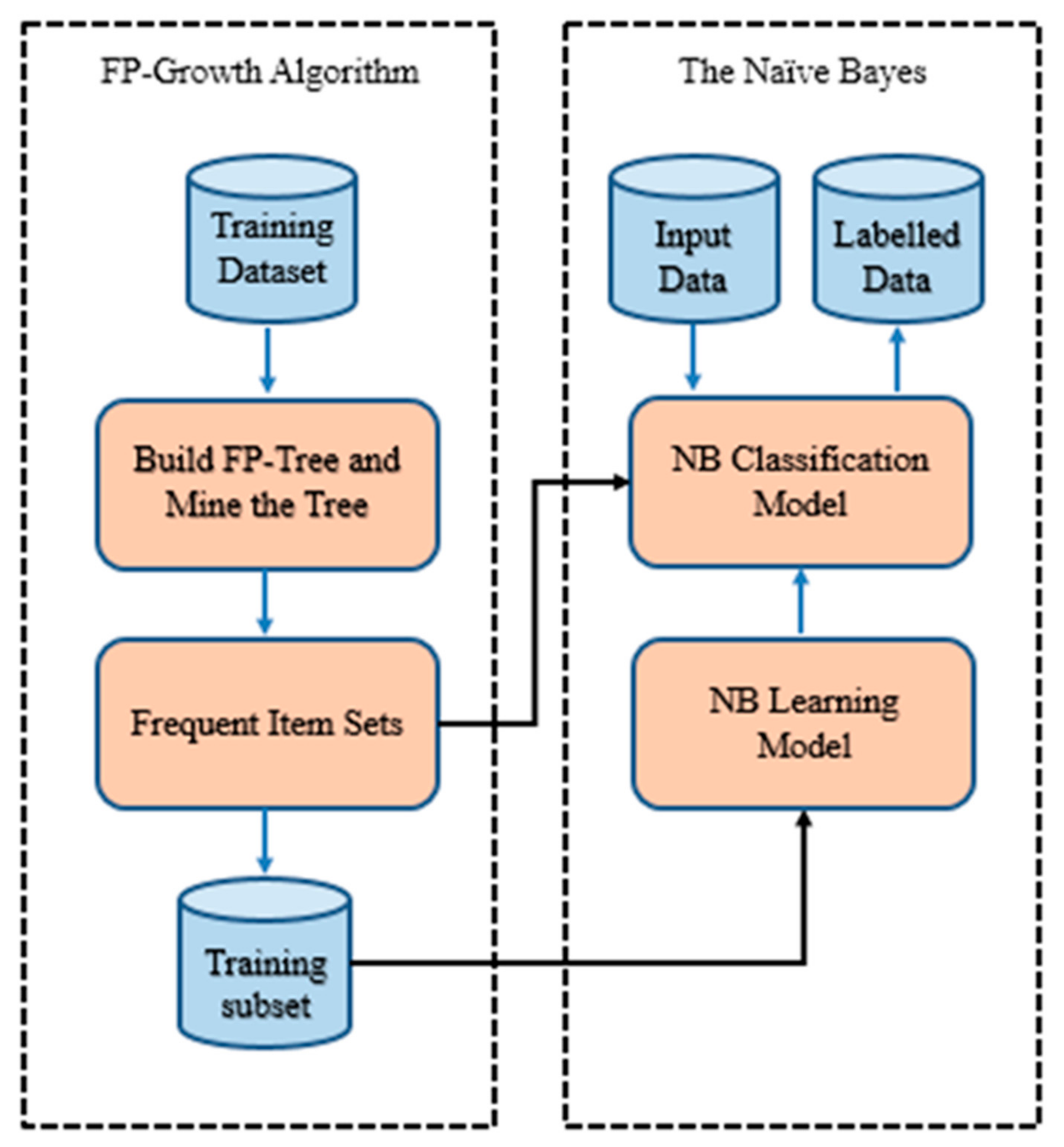
Figure 3, our proposed classification model for hearing-loss symptoms, and how the extracted data are frequently processed using the FP-Growth algorithm, is illustrated.
Each item set from the dataset reflect several features, each feature is a part of the vocabulary. In this model, the FP-Growth algorithm, utilized for processing the feature transformation after the process of selection and extraction of the feature, was conducted. The NB classification method was used for training a subset of frequent item sets that achieved the minimum support threshold, as shown in
Figure 3. In this example, 242 training item sets out of total 399 training item sets achieved the minimum support threshold to be within the training set in the NB classifiers. Our model can minimize the data dimensionality and requirement repository for the classification methods. Besides, it can enhance the performance of the classification methods and eliminate redundancies. In a specific condition, the dimensionality of the whole training data is minimized and added to the training set for the classification method. Therefore, each training example should include some frequent features that achieve the minimum support threshold considered within the training set for the neural network classification method.
The requirement repository of the classification method is reduced in case frequent features are composed. This is opposite to the traditional method when consisting of the entire features of the training dataset. The common characteristics of the datasets are redundancies and noise. The redundancies can be removed when choosing one frequent item set in the data. It is obvious that the algorithm’s speed and performance can be increased once the dataset becomes small. In our proposed model, feature transformation advantages can be obtained, including construction, selection and extraction. New features can be created through all these feature transformation forms [
33]. Functional mapping is used to extract new features from old ones [
34]. The most important method in the dataset is a frequent feature extraction. Another important method in the dataset is a feature construction that generates additional features to replace the missing data. In this study, we employ the FP-Growth algorithm as linear and non-linear spaces to offer a feature construction process to minimize the data dimensionality and recovering the missing information [
33]. Less data dimensionality makes the process easier and faster. However, feature selection can reduce the requirement repository and enhance the performance of the algorithm by removing the redundancies and noise [
34].
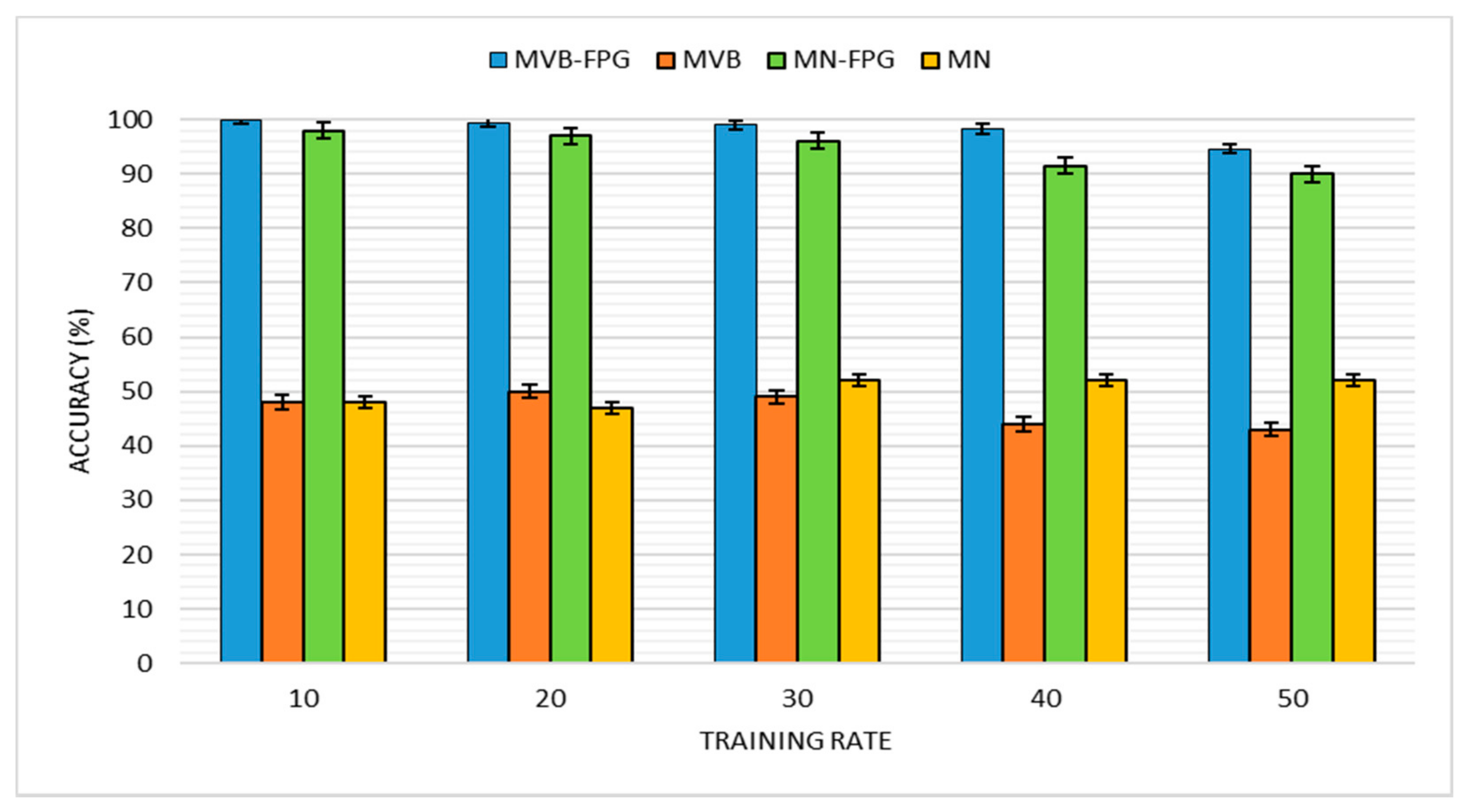
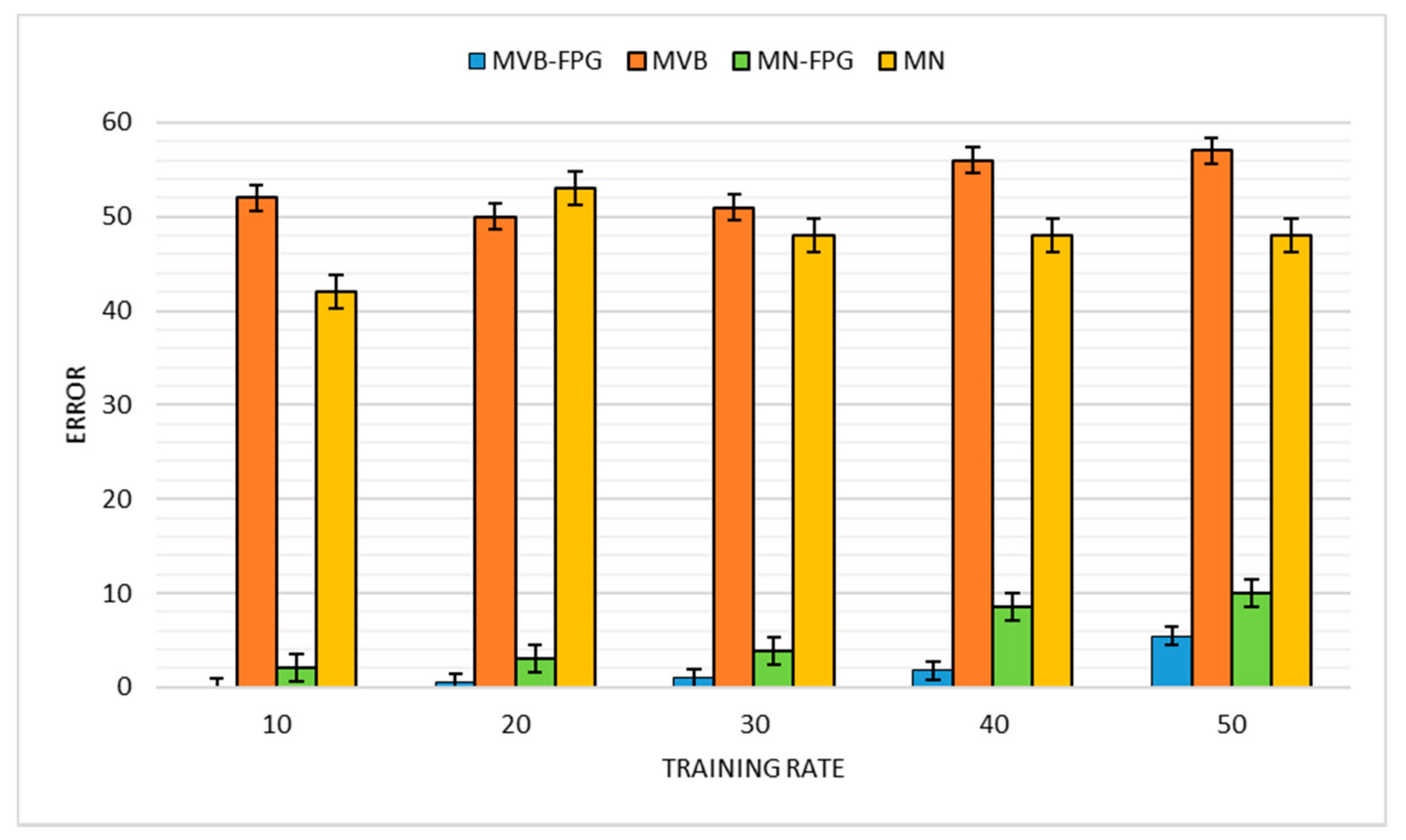
An associative classification, which is a combination of unsupervised learning methods, such as the FP-Growth algorithm or association rule and NB classifiers, performs much better than the standalone classification method [
35]. The hybrid of the FP-Growth algorithm and K-nearest neighbor (KNN) can obtain a high classification accuracy [
36]. Our hearing loss detection model has utilized a combination of unsupervised and supervised learning ML methods, particularly the FP-Growth algorithm and NB classifier. The two versions of the naïve Bayes classification models, which are the multivariate Bernoulli and multinomial model, were explained. The multivariate Bernoulli naïve Bayes model was the model of choice for the classifier as the implementation with the FP-Growth algorithm has proven to be more efficient than the multinomial model. This is against the argument by other researchers that indicate that the multinomial model outperforms the multivariate Bernoulli in every respect, as depicted in the chapter using different kinds of datasets. The justifications for adopting these as the techniques for implementing the model are explained using various research in healthcare that uses a similar method with varying degree of success, as well as by the literature that support the efficiency of these techniques. The identification model for hearing-loss symptoms was depicted in a diagram and all the components that make up the model explained. The FP-Growth algorithm serves as a pre-processing mechanism that provides all the elements of data transformation to the data before it becomes part of the classifier’s vocabulary. With that, the advantages inherent in data extraction, selection and construction techniques were all achieved. These advantages include discarding redundant and noisy features in the data, reducing storage requirements and improving the classification algorithm’s performance.
The calculation of these parameters for the prior can be represented as follows:
From the union of all item sets that meets the minimum threshold, extract the vocabulary (V) for each class and get the training cases that have that class:
Calculate P()terms
For each in do
Training cases ← All the
training cases with class =
The algorithm shows the steps used to calculate the prior probability. The vocabulary of the classifier is extracted from the union of all the features in the item sets generated by the FP-Growth algorithm. Then, for every class of the training examples that qualifies to be in the training set, which in this case is the 242 training examples from the 399 in the dataset, calculate the probability of each particular class P(Cj) by getting all the training examples with class Cj among all the classes and divide it by the total number of all the training examples.
The calculation of these parameters for the multinomial likelihood can be represented as follows:
Calculate P()terms
Thresholdsj ← single set containing union of all frequent items sets (vocabulary)
For each in vocabulary
← # of occurrence of
in the
training cases of class =
The algorithm shows the steps for calculating the parameters for multinomial likelihood. To calculate the probability of a class given a particular training example.
P(tk/Cj), the vocabulary, is formed from the union of item sets of the thresholds. Then the number of occurrences of the threshold tk in the training examples of class Cj is calculated plus the alpha (α) divided by the total number of tokens (n) in class Cj plus additive smoothing alpha (α).
The calculation of these parameters for the multivariate Bernoulli likelihood can be represented as follows:
Calculate P()terms
Thresholdsj ← single set containing union of all frequent items sets (vocabulary)
For each in vocabulary
← # of
training cases where
is present
The algorithm shows the steps for calculating the parameters for the multivariate Bernoulli likelihood. To calculate the probability of a class given a particular training example P, the number of training examples nk where the threshold is present is added to the smoothing parameter alpha (α) and divided by total number of tokens plus the alpha (α).
3.2. Identifying the Relationship with Association Analysis Algorithms
Unsupervised learning methods, such as association analysis algorithms, have the capability to find a correlation with invisible datasets [
37]. Frequent features (item sets) and association rules can be found using this method as discovered segments. If there is a strong relationship between more than two item sets in the dataset, then this is a suggestion of an association rule, which is represented by A → B, where A and B are distinct item sets. The support and confidence metrics are used to measure the correlation of the item set elements in a dataset. Support metric reflects the frequent number of a rule that is used in the dataset at hand.
ADi audiology data compresses the
S item set where
S is a subset of
ADi, mathematically formulated as follows:
σ(
S) represents support for an itemset
S.
ADi represents individual audiology data with
S as its subset (
SADi). This is means that each item of
S is can be an item in
ADi, where
ADi is also an element of the dataset (
D). A confidence metric is used to measure the interface reliability of an association rule. It suggests a strong correlation between items within an itemset in the preceding and succession of the rule. In instance, the rule TNTS → 2000:30 shows a big confidence value with a big probability hearing threshold between 2000 and 30 in the individual audiology data
ADi that included TNTS. The confidence metric reflects the frequency of a number of elements in the
S itemset in
ADi data that compress the
T item. The
Confidence and
Support measurements can be formulated as follows:
The combination of the FP-Growth algorithm and association analysis is powerful and have a capability of item extraction from the dataset [
38]. The FP-Growth algorithm is used to generate a frequent itemset within a dataset for patients with hearing loss. The FP-Growth algorithm represents the dataset in a tree data structure known as the FP-tree. Each FP-tree has a path that maps to certain training example after it is scanned by the FP-Growth algorithm [
39]. Different features can be reflected by various training examples. The deep interference of the structure of the FP-tree leads to better dataset compression for the FP-tree.
Table 2 illustrate the structure of the dataset in details.
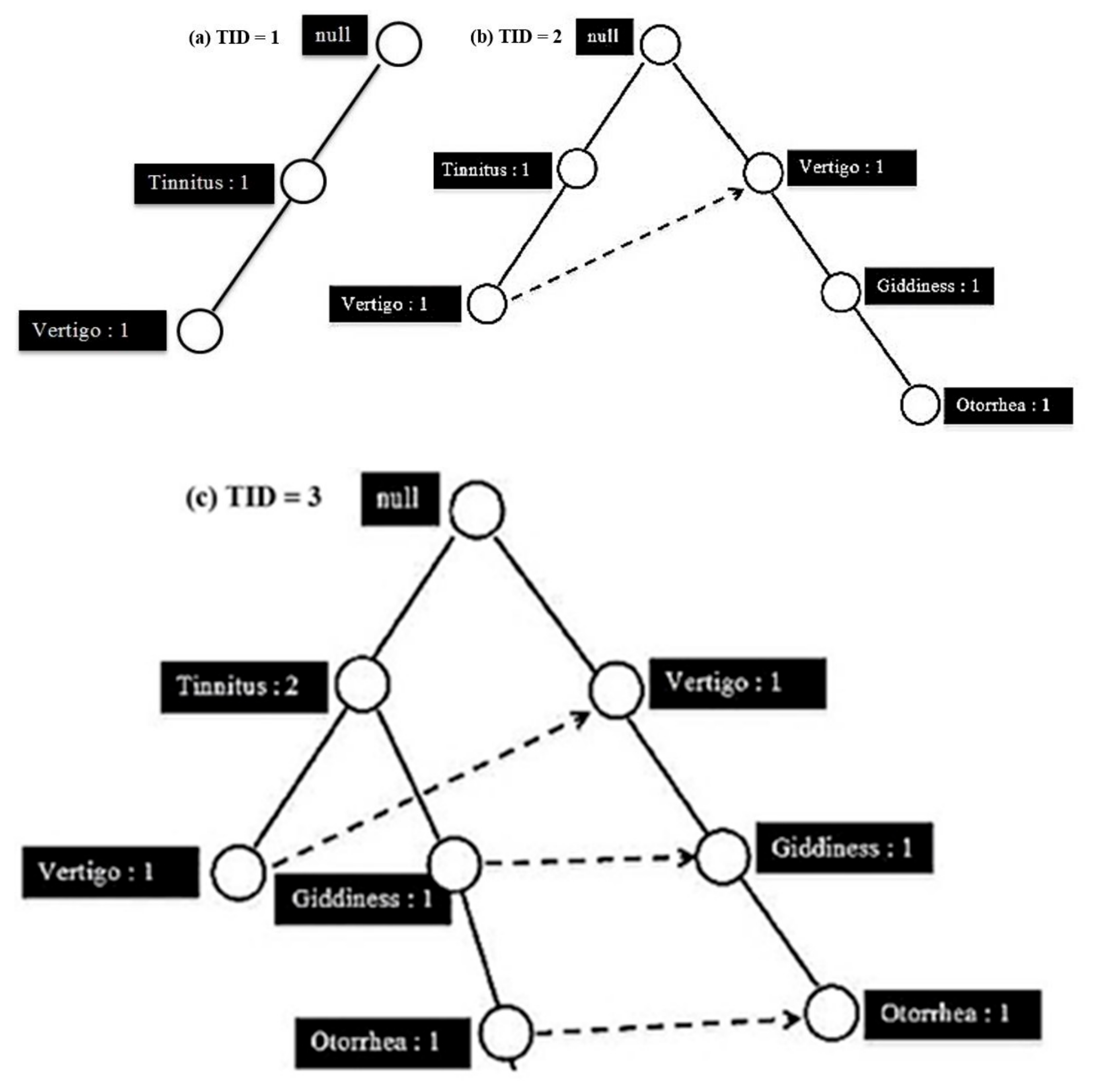
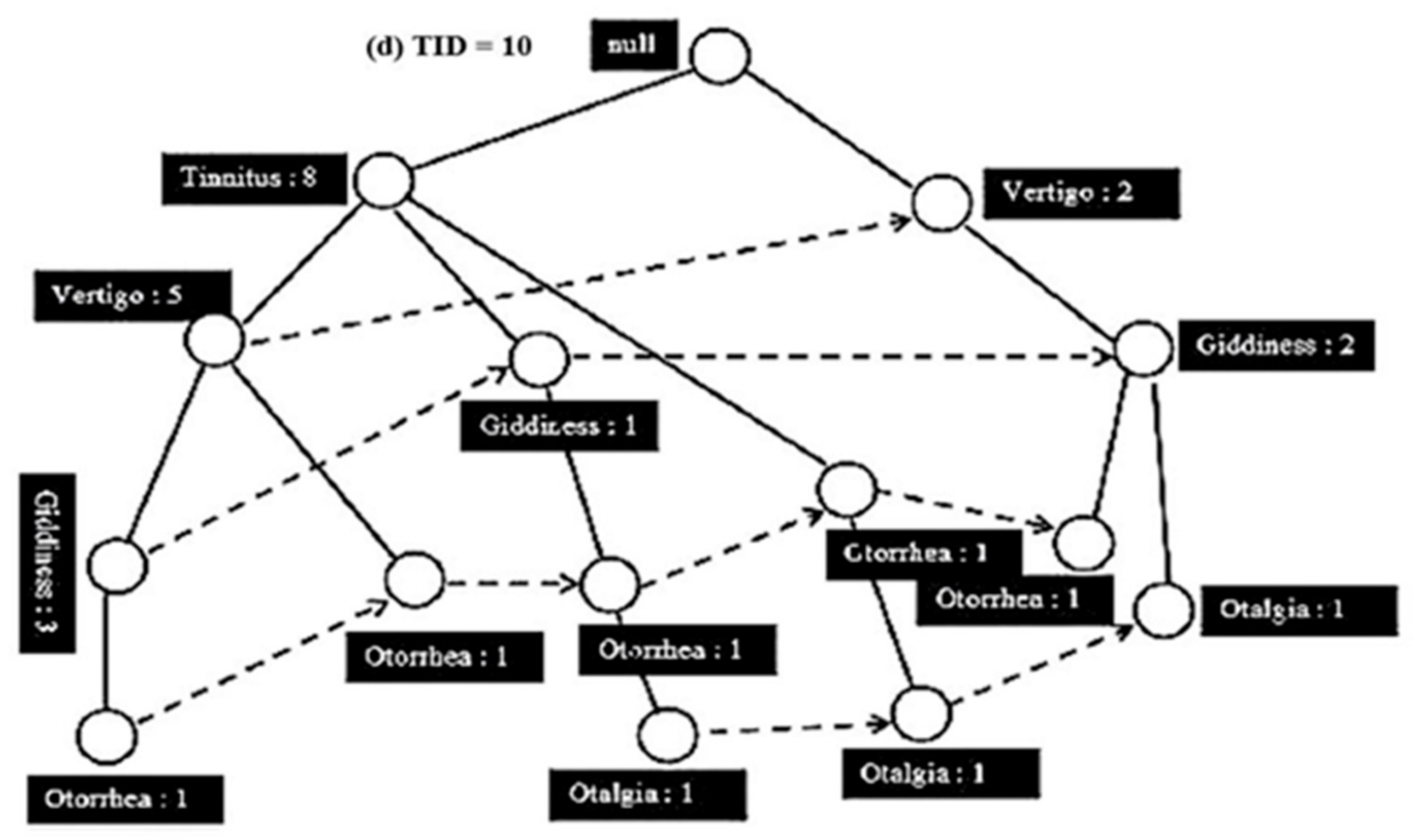
Figure 4 illustrates the FP-tree structure of the dataset where each consists of five features and ten training examples, including (a) TID 1, (b) TID 2, (c) TID 3 and (d) TID 10.
In the FP-tree, for each given path, each node represents a feature with a counter for the training example number that is mapped to this path. In the FP-tree, null is the root node, representing the starting point of the FP-tree. Firstly, the FP-Growth algorithm scans the number of frequencies for each item in the dataset and then it removes the item with no frequency count. Thus, an infrequent item leads to infrequency as well. Then the FP-Growth algorithm rescans the number of frequencies to build the structure of FP-tree to extract the frequent item sets [
40]. For example, tinnitus is the most frequent item set in our dataset, followed by vertigo and then giddiness, otorrhea and lastly otalgia. After the FP-Growth algorithm generates an FP-tree structure, it crosses the first training example to generate the nodes as Tinnitus → Vertigo. Initially, the FP-tree start from the null node then the other path will be created by the training example as null → Tinnitus → Vertigo. In the example, each node in this path has a frequency count equal to 1. In the second training example, another path will be created from nodes the Vertigo, Vertigo, Giddiness and Otorrhea as null → Vertigo → Giddiness → Otorrhea. The second path is created due to there being no overlap with the first training example that represents the first feature (tinnitus). However, in the third training example, there is an overlap with the first training example in the first feature (tinnitus). So, for the path of null → Tinnitus → Giddiness → Otorrhea → Otalgia, the count feature (tinnitus) becomes two as it is overlapping with the third training example.
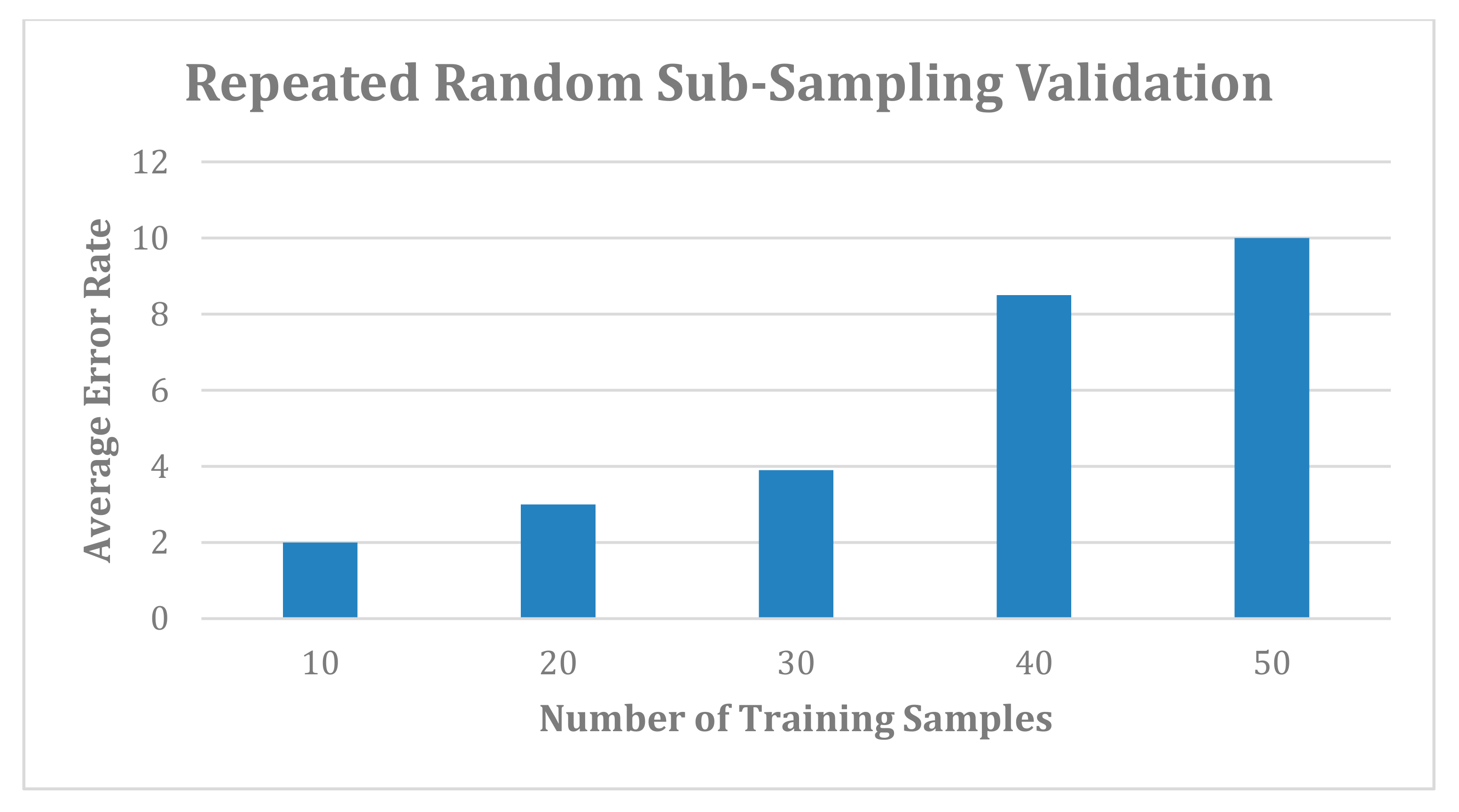
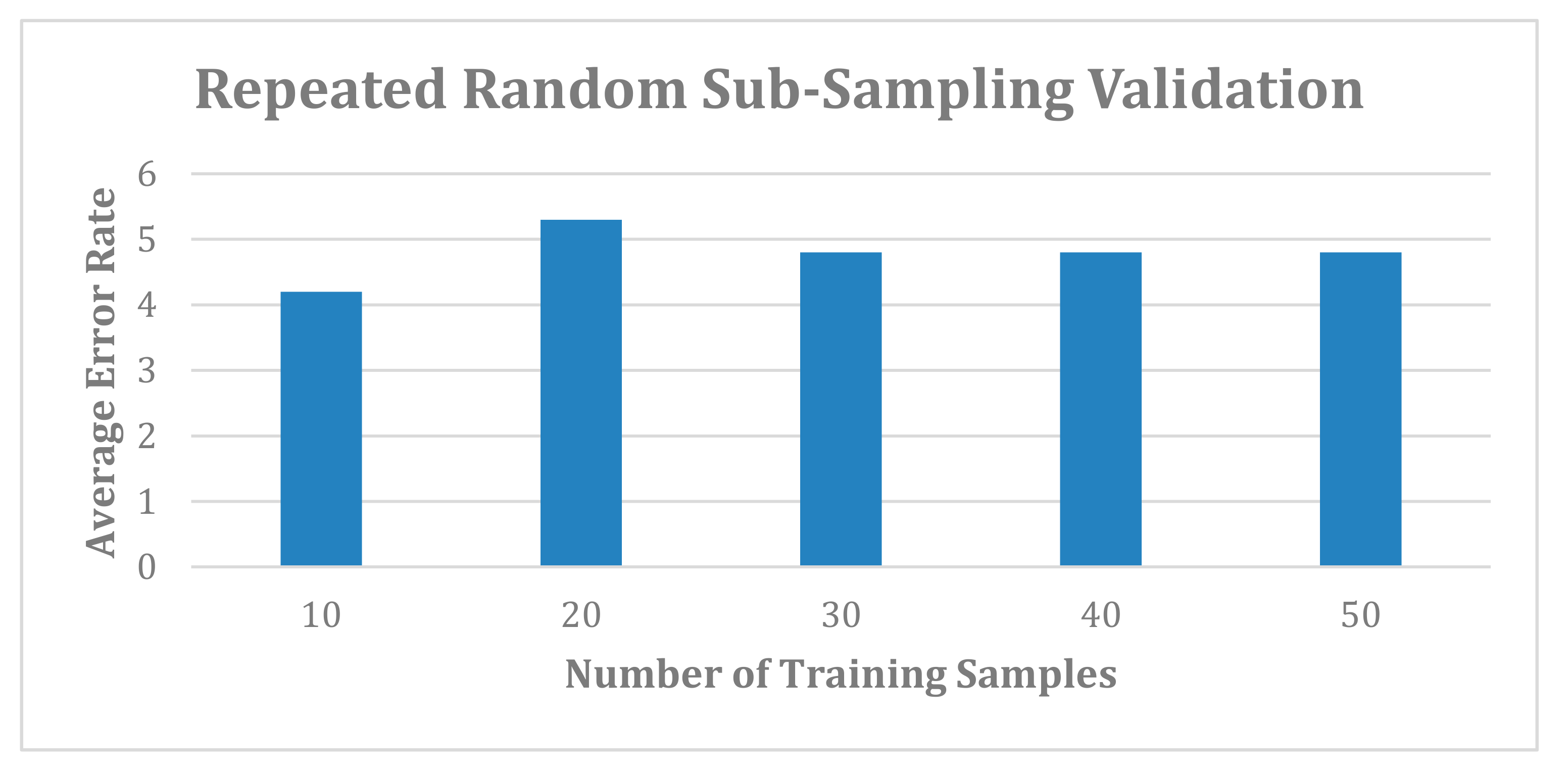
FP-Growth algorithm repeats this process until to reach the tenth training example. In addition, frequent item sets are generated by the FP-Growth algorithm to build a conditional branch of FP-tree in a bottom–top approach. The FP-Growth algorithm finds the frequent item sets ending with otalgia, and then it looks for another itemset that ends with otorrhea, giddiness, vertigo and tinnitus. This process is reasonable as each branch in the FB-tree is mapped to each training example. Therefore, for a given feature, a path is traversing to generate frequent item sets. We used settings 0.1 and 0.7 for the minimum support threshold and confidence thresholds, respectively, on the sample audiology dataset of 50 patients. Furthermore, we used settings of 0.2 and 0.7 for the minimum support threshold and confidence thresholds, respectively, on the sample audiology dataset of 339 patients. It is hard to find lower values for the minimum support and confidence threshold measurements. Therefore, we chose 0.2 (20%) and 0.7 (70%) for the minimum support and confidence threshold values as it could achieve the result at an acceptable level. Setting the values to less than 0.1 (10%) of the dataset leads to an undesired result.
3.3. Feature Transformation with FP-Growth Algorithm
The FP-Growth algorithm was applied on an audiometry dataset of 399 patients using air and bone conduction audiology medical records. The FP-Growth algorithm acts as a frequent item set extraction algorithm with a setting of 0.4 (40%), the minimum support threshold. Each item set in the training examples that pass the minimum threshold is integrated into the training set for the NB as a classification method. Opposite to the traditional method, which extracts the vocabulary form of all item sets (features) in the training examples, the NB extracts the item sets from a union set of item sets. Only 242 out of 399 training examples were found after the process of the item set generation. Those training examples do not belong to their subset of the generated item sets. Only three symptom types were found from the extracted item sets. From 242 training examples, there are tinnitus symptoms and some symptoms of both tinnitus and vertigo and other symptoms with tinnitus, vertigo and giddiness. The FP-Growth algorithm is fed by the neural network by three labels to identify the symptom of the air and bone conduction audiometry. The first label is tinnitus, the second label is tinnitus and vertigo and the third label a collection of tinnitus, giddiness and vertigo. The air and bone conduction thresholds could consist of undesired frequent aspects for the same frequency or decibel for hearing in both ears of the patient. This can lead to increasing the dataset and features’ dimensionality and resulting in noisy features. The FP-Growth algorithm extracts features patterns to build up the classification vocabulary. New features can be created by one of the common feature transformations, such as feature construction, selection and extraction [
41]. The feature extraction method is used to extract the frequent item sets from the dataset. The feature construction method is a pre-processing method used to reduce the dataset dimensionality. It is a very critical method as the success of machine learning approaches depends on this process. The feature selection method is used to select features from the dataset to reduce the requirements repository and enhance the performance of the classification algorithm [
42].
In this study, we employed all three feature transformation techniques. Extracted item sets (features) were used to build up the vocabulary. This leads to minimizing the feature number for vocabulary. Thus, this minimizes the feature dimensionality as well, which helps the vocabulary keeping the relevant data. The vocabulary consists of a number of disjoint item sets (features) in the training examples [
43]. Thus, the three feature transformations, extraction, selection and construction, are attained. Reducing the requirements repository, removing the noisy feature and lowering the computational complexity result in enhancing the performance of the classification algorithm, and a lower feature number means higher speed processing. Factor analysis, independent component analysis and principal component are the most common techniques used to reduce the feature dimensionality [
44]. In this research, we employ the FP-Growth algorithm in our detection model to offer a feature construction process to minimize the data dimensionality and recovering the missing information [
45].
3.4. Patterns Evaluation
A large number of item sets and form patterns can be generated by the FP-Growth algorithm within the minimum support threshold. The FP-Growth algorithm tends to generate a huge number of patterns since the size of the dataset is very big. The issue is that some of these generated patterns are undesirable. It is not a trivial process to identify the desirable patterns and undesirable ones as this decision depends on many aspects. Thus, using standard evaluation methods for pattern quality is a necessity. Statistical methods are one of these methods used to evaluate the quality of the generated patterns [
46]. It can be considered that the item sets that have a lower number of items or are discovered in less of the training examples are undesirable item sets. An objective interestingness metric can be used to remove these item sets. An objective interestingness metric is based on statistical analysis that identifies which item set should be removed. In the literature, several objective interestingness metrics is proposed to discover the desirable item sets concerning specific aspects. An aggregating method is proposed in [
47] to discover the desirable association rules using an advanced aggregator. The ranking method comprises two processes. The first process is based on the chi-square test technique while the second process is measuring the objective interestingness. Objective interestingness measurement is commonly used in the literature. It relies on the relationship of the confidence threshold and minimum support threshold [
48].
A study on the objective interestingness measurement was conducted by [
49], demonstrating that some interestingness measurements can reduce the association rules number efficiently. However, the accuracy quality is not improved. In addition, no individual interestingness metric is superior to others. Another standard evaluation method in the evaluation of desirable item set quality is subjective arguments. In this method, the itemset can be desired if it offers unpredicted beneficial information for the discovered data. In this study, we employed subjective knowledge arguments as an evaluation method. This is because of the advanced knowledge obtained from the patients’ medical audiology data. The template-based method is employed as a subjective knowledge evaluator to evaluate the extracted item set quality. Thus, the generated item set using the FP-Growth algorithm is allowed to be restricted as all the items are filtered, keeping only the itemset that has one or more symptoms, such as vertigo, tinnitus, otalgia, Meniere, and others. In this paper, the template-based method is used because of its advantages that has been demonstrated in many recent studies. Besides, it can enhance the search of keywords using semantic data [
50]. Researchers and scientists who are experts in this domain can only use their knowledge and experience to discover the important patterns. So, the patterns selected by the expert template only were extracted.
3.5. Symptoms Identification with the Naïve Bayes Algorithm
We performed the classification process on the output of the training set obtained from the recurrent item sets when applied on the FP-growth algorithm. We used two common methods of naïve Bayes, including a multinomial model [
17] and multivariate Bernoulli, to find out the most accurate solution. The naïve Bayes method is applied to the hearing loss classification problem to detect the symptoms for the thresholds of bone conduction audiology and the pure-tone air. In the multivariate Bernoulli method, the vocabulary and a training example act as inputs, after which they are processed to obtain the binary output classification. The binary classification can be represented by a vector of ones to reflect the condition of the existing hearing threshold while it can be represented by a vector of zeros to reflect the condition of the absence hearing threshold. The vocabulary consists of several different features that form the training examples [
18]. The vocabulary length binary should be the same length as the binary vector. The vocabulary results contain various features and thresholds. For a given class, the multinomial model produces the portion of times that the threshold values of the training examples appear. In our proposed model, the threshold value of the frequent item set is insignificant compared to the threshold value state, whether in existence or absent in the training example. Therefore, we employed the multivariate Bernoulli for this purpose. The training example was divided into a number of feature sets to extract the features, including the bone conduction audiology thresholds and symbols of air from the dataset. The threshold of audiology hearing reflects the given frequency level and decibel at the point of hearing the pure tone. A vector of ones and zeros symbols represent every training example. A one value indicates that the symbols are available in the training example while the zero values indicate that the symbols are unavailable the training example. The estimated training examples of the probabilities and conditional probabilities for the given class feature were used to train the classification methods [
19]. The naïve Bays process is formulated in the mathematical equations as follows:
The Bayes rule is formulated as in [
17,
20]:
This is applied in the classification method and formulated as
C_
map represents the best class, which is the one excluded from all classes that maximize the values
argmax and
P(
C/
D). Using the Bayes rule, every class is maximized by Equations (4) and (5):
The class that could maximize the product of P(D/C) P(C) is most likely to be selected. The goal is selecting the class that is associated with the probability bigger than the specific audiology thresholds that have the symptom or set of symptoms.
Equation (6) can be reformulated as
The common probability of x_1 via xn conditioned on a class can be symbolized as the product of independent probabilities .
To calculate the most likely class, the probability of the initial of likelihood features is multiplied by the class probability. This can be reformulated as
C_NB is the best class that maximizes the advance class probability P(Cj) multiplied by each probability of the feature in the given feature class. In the data, for each hearing threshold position in the given class probability, the class is computed and assigned the best probability. The frequent item sets in the data were computed for classification training purposes.
For the advance training example (
t) that is available in a class (
Cj), the number of training examples in class (
Cj) was divided by all training examples counted, as represented by the following equation:
In in multinomial model, the likelihood and the threshold probability
i (
ti) for the given class (
Cj) can be calculated by the number of times the threshold of
i (
ti) is counted for the given class (
Cj) in the training example and then dividing it by the overall threshold number across all training examples of class (
Cj), as represented in the following equation:
The portion of training examples of class (
Cj) of the appeared threshold in the multivariate Bernoulli method is divided by the overall training examples number in class (
Cj), as represented in the following equation:



 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}