
Evaluation of Environmental Information Disclosure of Listed Companies in China’s Heavy Pollution Industries: A Text Mining-Based Methodology

Abstract
1. Introduction
2. Literature Review
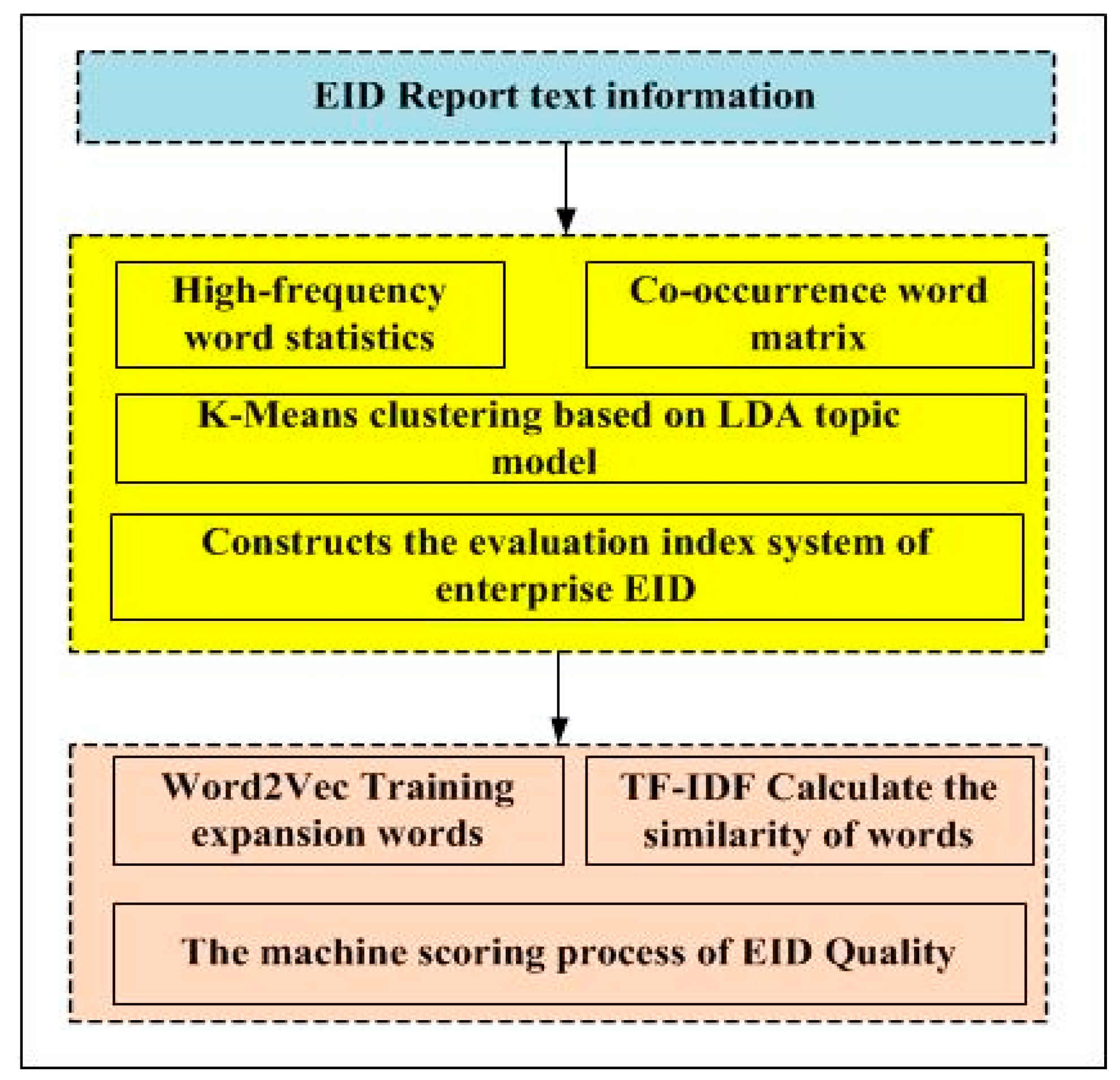
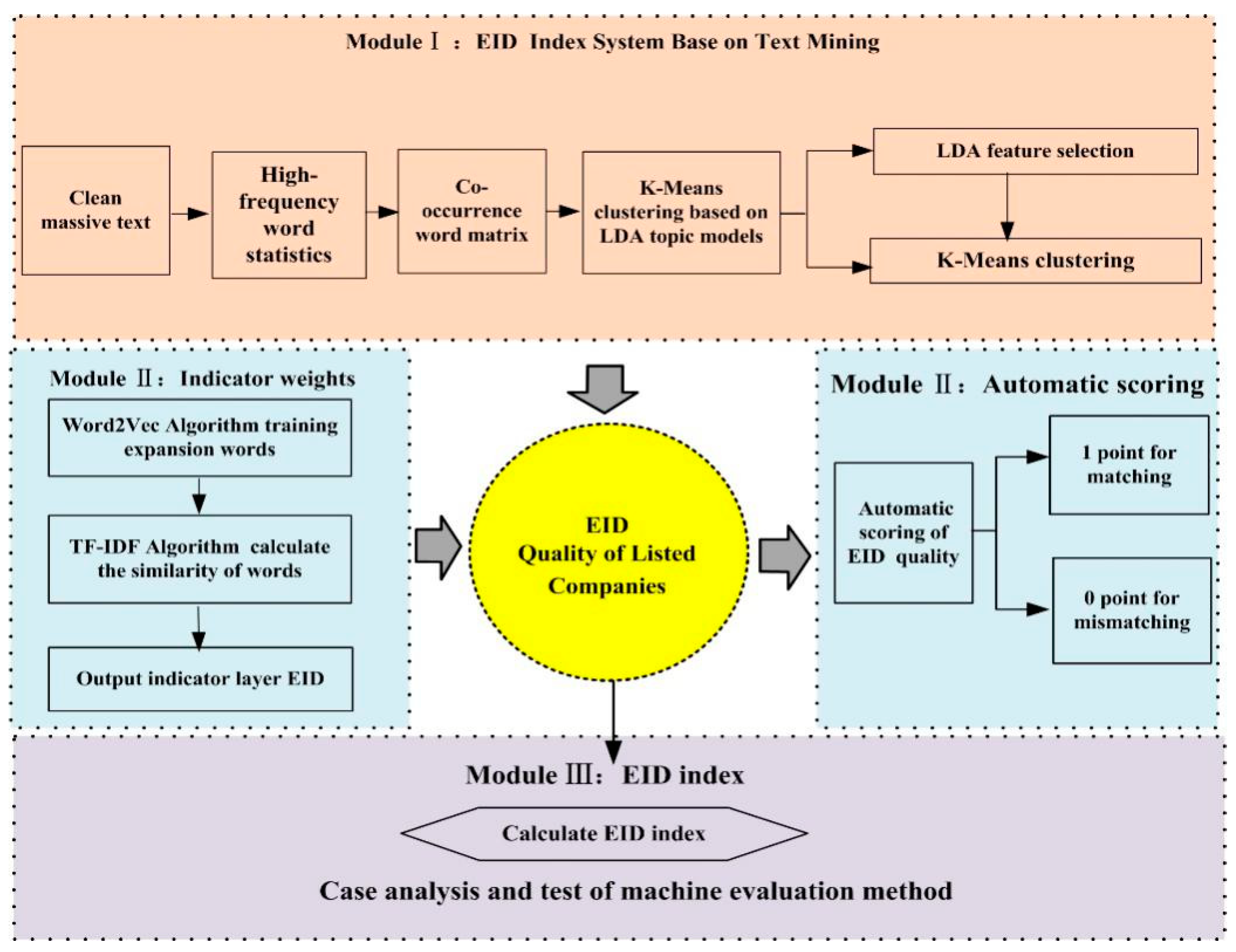
3. Methodology
3.1. Chinese Text Mining Preprocessing Primary Steps
3.1.1. Data Collection
3.1.2. Handling Chinese Encoding Issues
3.1.3. Chinese Word Separation
3.1.4. Introduction of Stop Words
3.2. EID Quality System Construction
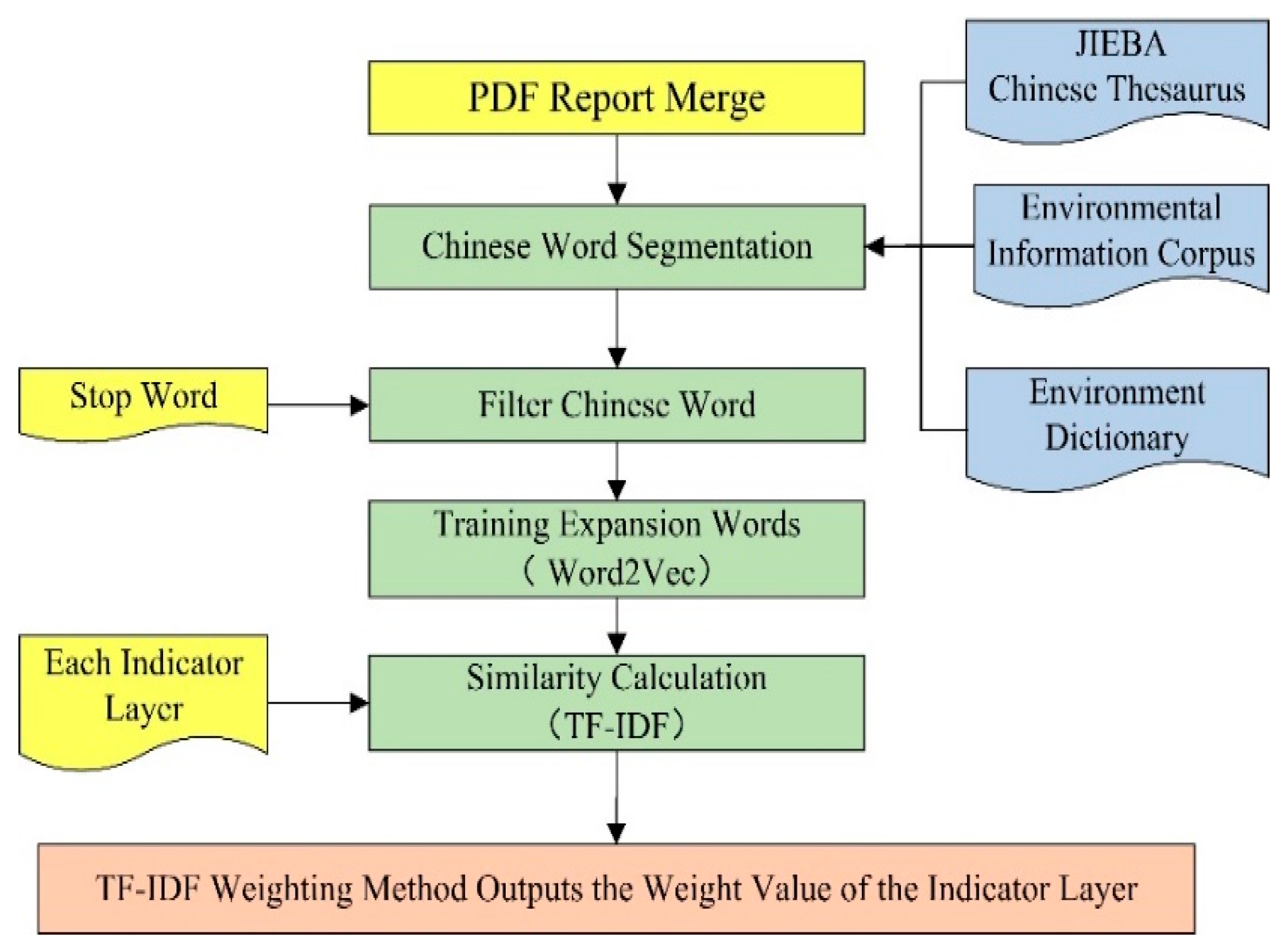
3.3. EID Index Layer Weight Calculation
3.3.1. Keyword Expansion
3.3.2. Extended Word Similarity Calculation Based on the TF–IDF Model
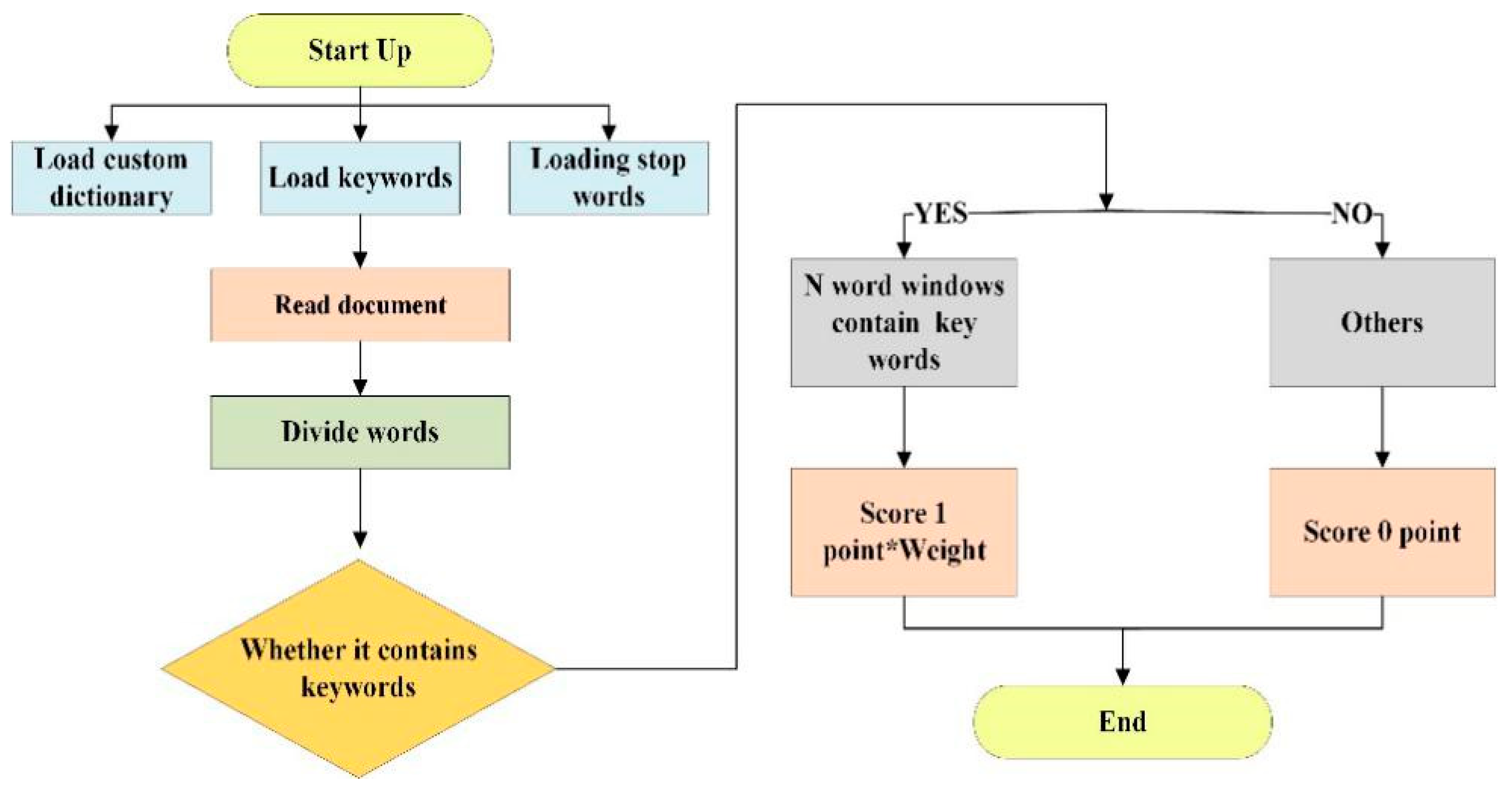
3.4. Automatic Scoring of EID Quality
4. Case Study
4.1. Sample and Data Source
4.2. EID Index System Construction
4.2.1. Keyword Extraction
4.2.2. Co-occurrence Word Matrix Construction
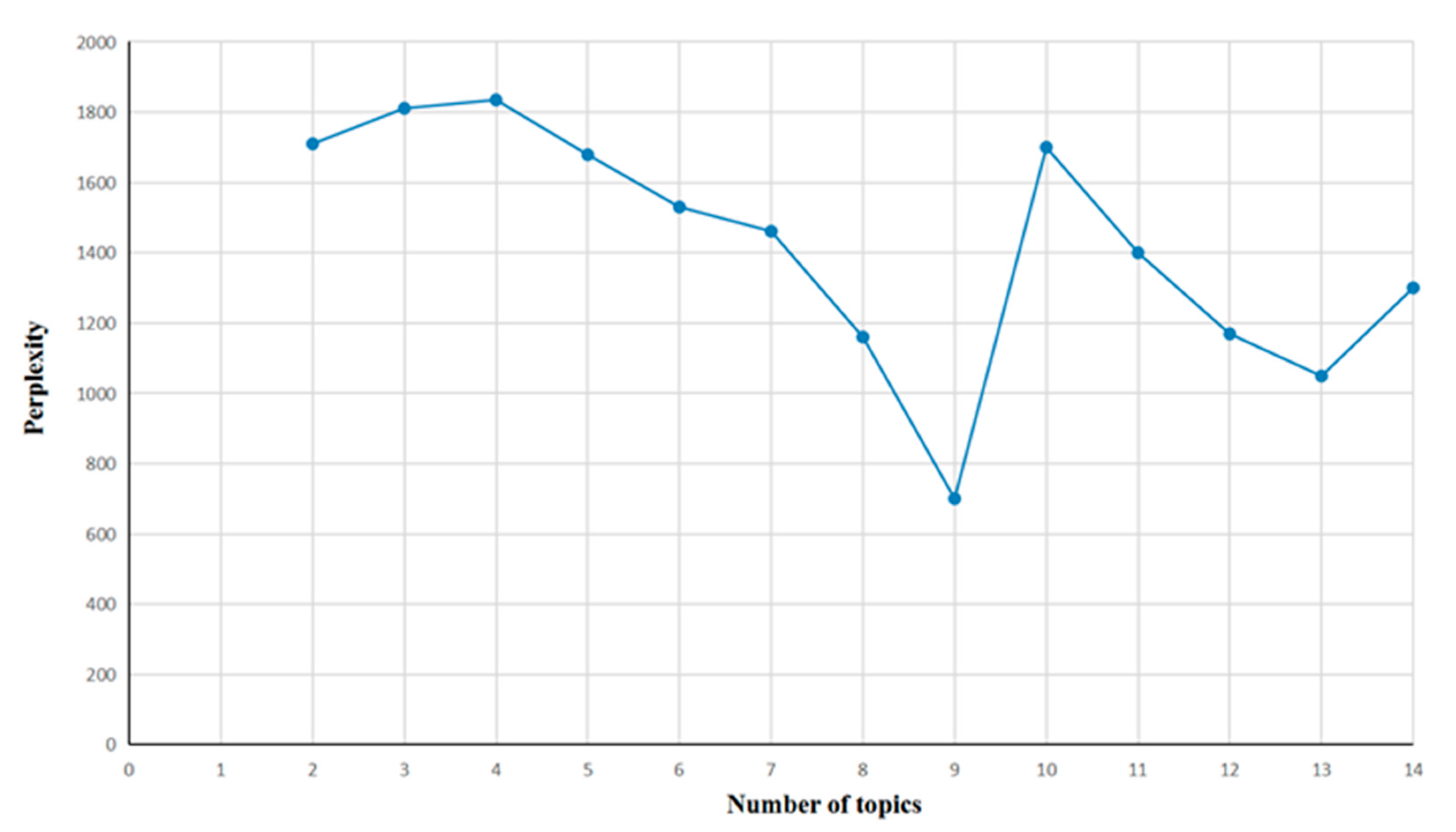
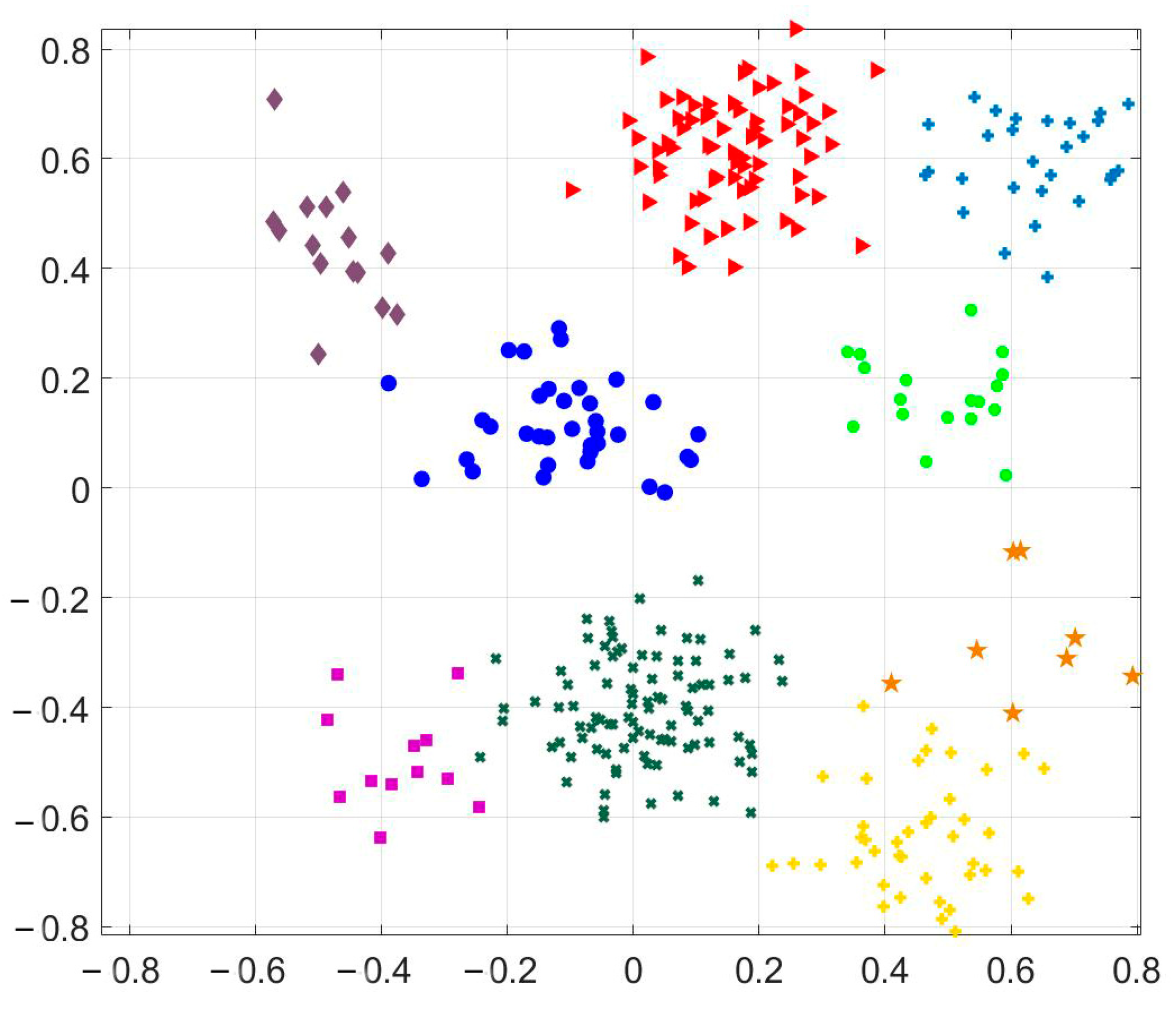
4.2.3. Topic clustering based on K-means clustering based on LDA topic model
4.3. EID Index Layer Weight Calculation
4.4. Automatic Scoring of EID Quality
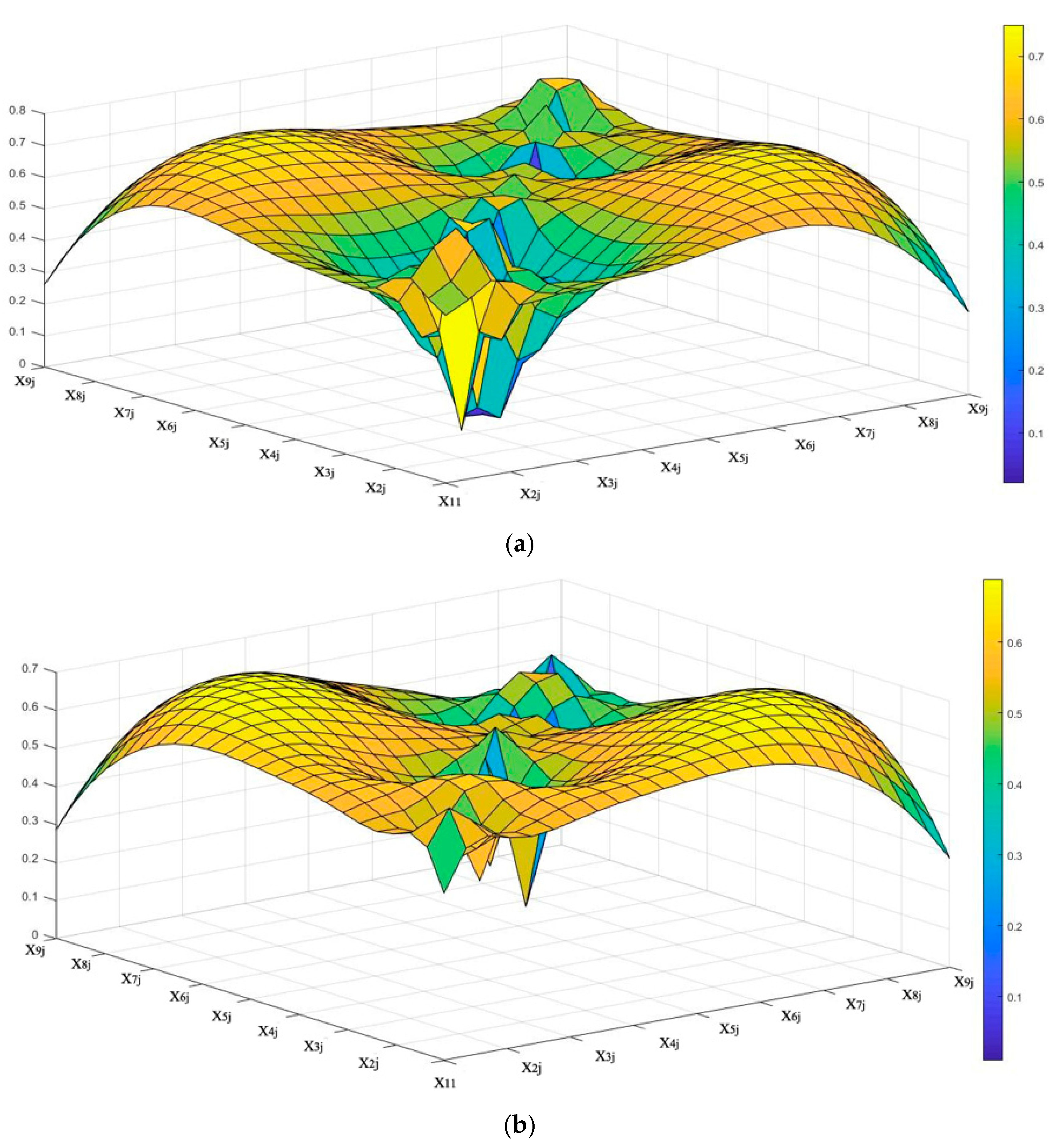
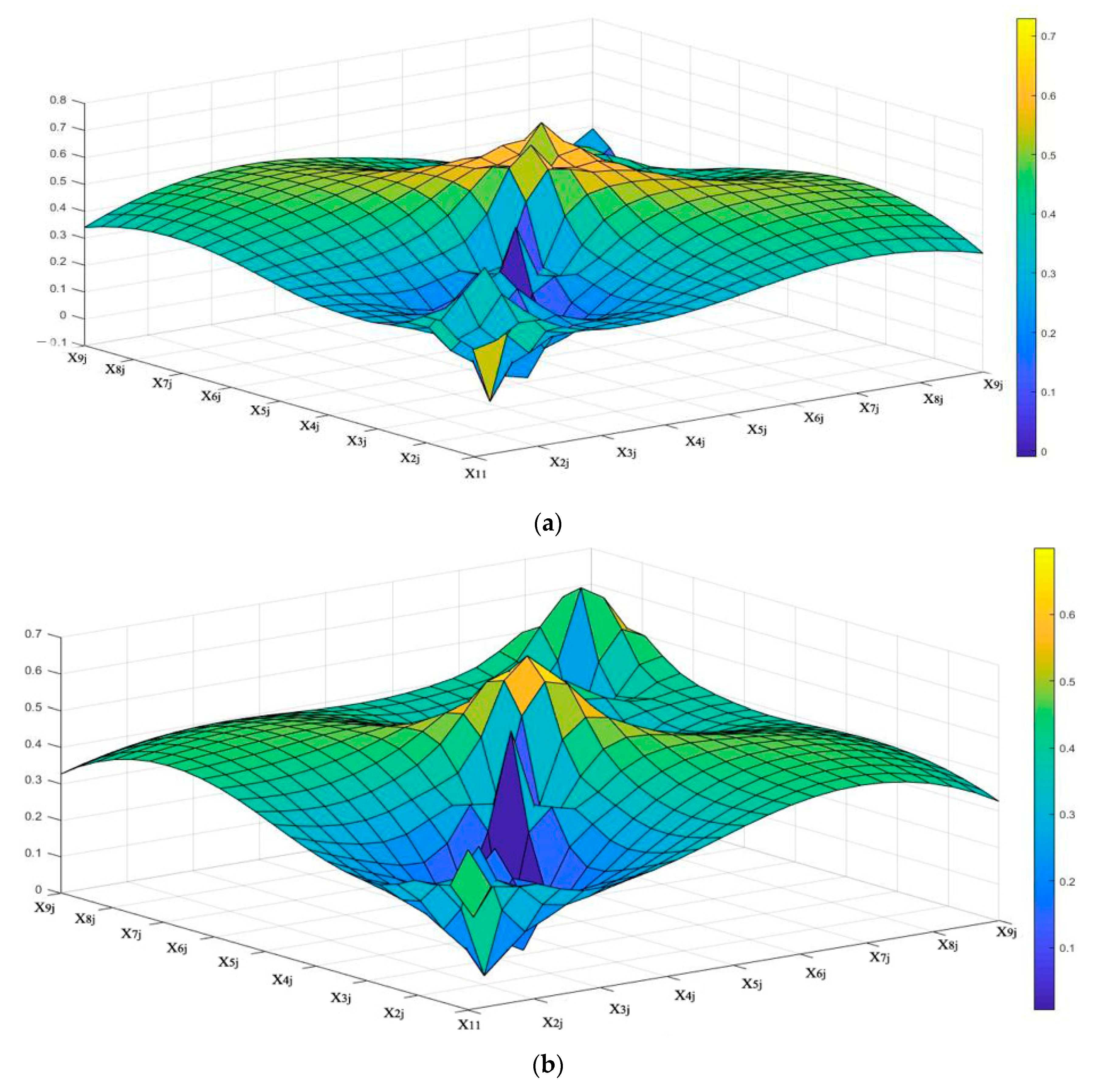
4.5. Constructing the EID-Surface
4.6. The Calculation of the EID Index
4.7. Testing the Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Thematic Layer | Index Layer | China’s 16 Heavily Polluting Industries | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B06 | B07 | B80 | B09 | C17 | C19 | C22 | C25 | C26 | C27 | C28 | C30 | C31 | C32 | C33 | D44 | ||
| (X1) | (X11) | 0.39 | 0.44 | 0.44 | 0.49 | 0.44 | 0.44 | 0.36 | 0.44 | 0.43 | 0.30 | 0.52 | 0.44 | 0.53 | 0.40 | 0.38 | 0.45 |
| (X12) | 0.48 | 0.64 | 0.12 | 0.34 | 0.23 | 0.46 | 0.40 | 0.41 | 0.46 | 0.35 | 0.49 | 0.23 | 0.61 | 0.43 | 0.24 | 0.24 | |
| (X13) | 0.55 | 0.54 | 0.67 | 0.64 | 0.40 | 0.64 | 0.50 | 0.62 | 0.62 | 0.54 | 0.75 | 0.46 | 0.75 | 0.54 | 0.36 | 0.54 | |
| (X14) | 0.46 | 0.46 | 0.01 | 0.12 | 0.02 | 0.12 | 0.03 | 0.46 | 0.46 | 0.01 | 0.04 | 0.06 | 0.08 | 0.06 | 0.46 | 0.46 | |
| (X15) | 0.56 | 0.61 | 0.24 | 0.40 | 0.16 | 0.16 | 0.01 | 0.48 | 0.41 | 0.30 | 0.43 | 0.33 | 0.68 | 0.38 | 0.18 | 0.40 | |
| (X16) | 0.66 | 0.63 | 0.50 | 0.60 | 0.32 | 0.60 | 0.32 | 0.59 | 0.54 | 0.43 | 0.59 | 0.36 | 0.68 | 0.48 | 0.48 | 0.43 | |
| (X17) | 0.58 | 0.58 | 0.01 | 0.12 | 0.04 | 0.01 | 0.67 | 0.55 | 0.07 | 0.01 | 0.10 | 0.67 | 0.07 | 0.14 | 0.67 | 0.14 | |
| (X2) | (X21) | 0.49 | 0.30 | 0.01 | 0.68 | 0.01 | 0.17 | 0.01 | 0.69 | 0.51 | 0.01 | 0.01 | 0.56 | 0.02 | 0.69 | 0.58 | 0.68 |
| (X3) | (X31) | 0.58 | 0.60 | 0.68 | 0.60 | 0.57 | 0.59 | 0.50 | 0.61 | 0.55 | 0.50 | 0.55 | 0.52 | 0.58 | 0.62 | 0.55 | 0.57 |
| (X32) | 0.32 | 0.29 | 0.38 | 0.20 | 0.13 | 0.04 | 0.10 | 0.24 | 0.15 | 0.11 | 0.11 | 0.18 | 0.24 | 0.18 | 0.19 | 0.11 | |
| (X33) | 0.57 | 0.63 | 0.52 | 0.55 | 0.56 | 0.57 | 0.55 | 0.56 | 0.54 | 0.53 | 0.52 | 0.57 | 0.58 | 0.57 | 0.54 | 0.54 | |
| (X34) | 0.40 | 0.49 | 0.59 | 0.52 | 0.70 | 0.49 | 0.54 | 0.59 | 0.57 | 0.71 | 0.72 | 0.66 | 0.60 | 0.62 | 0.68 | 0.53 | |
| (X35) | 0.60 | 0.57 | 0.48 | 0.52 | 0.57 | 0.48 | 0.55 | 0.48 | 0.50 | 0.52 | 0.56 | 0.51 | 0.51 | 0.53 | 0.53 | 0.53 | |
| (X4) | (X41) | 0.37 | 0.51 | 0.71 | 0.44 | 0.18 | 0.60 | 0.51 | 0.66 | 0.72 | 0.73 | 0.69 | 0.68 | 0.61 | 0.76 | 0.70 | 0.62 |
| (X42) | 0.34 | 0.54 | 0.54 | 0.54 | 0.54 | 0.54 | 0.54 | 0.54 | 0.55 | 0.55 | 0.54 | 0.54 | 0.54 | 0.55 | 0.54 | 0.55 | |
| (X5) | (X51) | 0.57 | 0.53 | 0.53 | 0.53 | 0.39 | 0.48 | 0.53 | 0.56 | 0.51 | 0.39 | 0.53 | 0.53 | 0.59 | 0.54 | 0.45 | 0.56 |
| (X52) | 0.13 | 0.01 | 0.01 | 0.24 | 0.01 | 0.04 | 0.02 | 0.06 | 0.01 | 0.01 | 0.01 | 0.24 | 0.10 | 0.03 | 0.03 | 0.08 | |
| (X53) | 0.52 | 0.42 | 0.32 | 0.48 | 0.36 | 0.29 | 0.59 | 0.50 | 0.50 | 0.43 | 0.47 | 0.48 | 0.60 | 0.49 | 0.45 | 0.49 | |
| (X6) | (X61) | 0.38 | 0.55 | 0.28 | 0.34 | 0.46 | 0.46 | 0.53 | 0.47 | 0.40 | 0.49 | 0.46 | 0.49 | 0.51 | 0.48 | 0.50 | 0.31 |
| (X7) | (X71) | 0.46 | 0.55 | 0.44 | 0.42 | 0.37 | 0.25 | 0.44 | 0.63 | 0.50 | 0.44 | 0.40 | 0.43 | 0.66 | 0.50 | 0.30 | 0.48 |
| (X8) | (X81) | 0.19 | 0.15 | 0.22 | 0.57 | 0.26 | 0.57 | 0.26 | 0.26 | 0.24 | 0.30 | 0.50 | 0.26 | 0.37 | 0.20 | 0.27 | 0.20 |
| (X9) | (X91) | 0.64 | 0.55 | 0.77 | 0.69 | 0.64 | 0.70 | 0.60 | 0.01 | 0.61 | 0.01 | 0.61 | 0.58 | 0.65 | 0.65 | 0.54 | 0.65 |
| (X92) | 0.43 | 0.41 | 0.41 | 0.73 | 0.54 | 0.73 | 0.41 | 0.23 | 0.55 | 0.27 | 0.56 | 0.50 | 0.66 | 0.40 | 0.36 | 0.48 | |
| (X93) | 0.53 | 0.38 | 0.50 | 0.50 | 0.36 | 0.29 | 0.28 | 0.54 | 0.46 | 0.39 | 0.48 | 0.38 | 0.39 | 0.65 | 0.21 | 0.54 | |
| 11.20 | 11.38 | 9.38 | 11.26 | 8.26 | 9.72 | 9.25 | 11.18 | 10.86 | 8.33 | 10.64 | 10.66 | 11.61 | 10.89 | 10.19 | 10.58 | ||
References
- Chen, H.; An, M.; Wang, Q.; Ruan, W.; Xiang, E. Military executives, and corporate environmental information disclosure: Evidence from China. J. Clean Prod. 2021, 278, 123404. [Google Scholar] [CrossRef]
- Lu, J.; Li, H. The impact of government environmental information disclosure on enterprise location choices: Heterogeneity and threshold effect test. J. Clean Prod. 2020, 277, 124055. [Google Scholar] [CrossRef]
- Graafland, J.; Gerlach, R.J.E. Economic freedom, internal motivation, and corporate environmental responsibility of SMEs. Environ. Resour. Econ. 2019, 74, 1101–1123. [Google Scholar] [CrossRef]
- Omer, A.M. Energy, environment and sustainable development. Renew. Sustain. Energy Rev. 2008, 12, 2265–2300. [Google Scholar] [CrossRef]
- Kouloukoui, D.; de Oliveira Marinho, M.M.; da Silva Gomes, S.M.; Kiperstok, A.; Torres, E.A. Corporate climate risk management and the implementation of climate projects by the world’s largest emitters. J. Clean Prod. 2019, 238, 117935. [Google Scholar] [CrossRef]
- da Silva, P.C.; de Oliveira Neto, G.C.; Correia, J.M.F.; Tucci, H.N.P. Evaluation of economic, environmental and operational performance of the adoption of cleaner production: Survey in large textile industries. J. Clean Prod. 2020, 278, 123855. [Google Scholar] [CrossRef]
- Yang, R.; Wong, C.W.Y.; Miao, X. Analysis of the trend in the knowledge of environmental responsibility research. J. Clean Prod. 2021, 278, 123402. [Google Scholar] [CrossRef]
- Antons, D.; Grünwald, E.; Cichy, P.; Salge, T.O.J.R. The application of text mining methods in innovation research: Current state, evolution patterns, and development priorities. R&D Manag. 2020, 50, 329–351. [Google Scholar]
- Tadros, H.; Magnan, M.J.S.A. How does environmental performance map into environmental disclosure? Sustain. Account. Manag. Policy J. 2019. [Google Scholar] [CrossRef]
- Chen, W.Y.; Cho, F.H.T. Environmental information disclosure and societal preferences for urban river restoration: Latent class modeling of a discrete-choice experiment. J. Clean Prod. 2019, 231, 1294–1306. [Google Scholar] [CrossRef]
- Ahmad, N.; Li, H.-Z.; Tian, X.-L. Increased firm profitability under a nationwide environmental information disclosure program? Evidence from China. J. Clean Prod. 2019, 230, 1176–1187. [Google Scholar] [CrossRef]
- Rivière-Giordano, G.; Giordano-Spring, S.; Cho, C.H. Does the level of assurance statement on environmental disclosure affect investor assessment? Sustain. Account. Manag. Policy J. 2018. [Google Scholar] [CrossRef]
- Beattie, V.; McInnes, B.; Fearnley, S. A methodology for analyzing and evaluating narratives in annual reports: A comprehensive descriptive profile and metrics for disclosure quality attributes. Account. Forum 2004, 28, 205–236. [Google Scholar] [CrossRef]
- Michelon, G.; Pilonato, S.; Ricceri, F. CSR reporting practices and the quality of disclosure: An empirical analysis. Crit. Perspect. Account. 2015, 33, 59–78. [Google Scholar] [CrossRef]
- Qin, Y.; Harrison, J.; Chen, L. A framework for the practice of corporate environmental responsibility in China. J. Clean Prod. 2019, 235, 426–452. [Google Scholar] [CrossRef]
- Clarkson, P.M.; Fang, X.; Li, Y.; Richardson, G. The relevance of environmental disclosures: Are such disclosures incrementally informative? J. Account. Public Policy 2013, 32, 410–431. [Google Scholar] [CrossRef]
- Fan, L.; Yang, K.; Liu, L. New media environment, environmental information disclosure, and firm valuation: Evidence from high-polluting enterprises in China. J. Clean Prod. 2020, 277, 123253. [Google Scholar] [CrossRef]
- Lu, Y.; Abeysekera, I. Stakeholders’ power, corporate characteristics, and social and environmental disclosure: Evidence from China. J. Clean Prod. 2014, 64, 426–436. [Google Scholar] [CrossRef]
- Zeng, S.X.; Xu, X.D.; Dong, Z.Y.; Tam, V.W. Towards corporate environmental information disclosure: An empirical study in China. J. Clean Prod. 2010, 18, 1142–1148. [Google Scholar] [CrossRef]
- Pejić Bach, M.; Krstić, Ž.; Seljan, S.; Turulja, L. Text mining for extensive data analysis in financial sector: A literature review. Sustainability 2019, 11, 1277. [Google Scholar] [CrossRef]
- Wiseman, J. An evaluation of environmental disclosures made in corporate annual reports. Account. Organ. Soc. 1982, 7, 53–63. [Google Scholar] [CrossRef]
- Al-Tuwaijri, S.A.; Christensen, T.E.; Hughes Ii, K. The relations among environmental disclosure, environmental performance, and economic performance: A simultaneous equations approach. Account. Organ. Soc. 2004, 29, 447–471. [Google Scholar] [CrossRef]
- Aerts, W.; Cormier, D. Media legitimacy and corporate environmental communication. Account. Organ. Soc. 2009, 34, 1–27. [Google Scholar] [CrossRef]
- De Villiers, C.; Van Staden, C.J. Can less environmental disclosure have a legitimizing effect? Evidence from Africa. Account. Organ. Soc. 2006, 31, 763–781. [Google Scholar] [CrossRef]
- Cho, C.H.; Patten, D.M. The role of environmental disclosures as tools of legitimacy: A research note. Account. Organ. Soc. 2007, 32, 639–647. [Google Scholar] [CrossRef]
- Neu, D.; Warsame, H.; Pedwell, K. Managing public impressions: Environmental disclosures in annual reports. Account. Organ. Soc. 1998, 23, 265–282. [Google Scholar] [CrossRef]
- Rhodes, S.; Kartell, B.; Palmer, C.; Blazek, M. Standardization of the life cycle environmental performance in the energy sector: ASTM draft standard: E067110 quantifying and reporting the environmental performance of electric power generation facilities and infrastructure; Implications to the electronics sector. In Proceedings of the 2006 IEEE International Symposium on Electronics & the Environment, Scottsdale, AZ, USA, 8–11 May 2006; Conference Record. IEEE: New York, NY, USA, 2006; p. 61. [Google Scholar]
- Aerts, W.; Cormier, D.; Magnan, M. Corporate environmental disclosure, financial markets, and the media: An international perspective. Ecol. Econ. 2008, 64, 643–659. [Google Scholar] [CrossRef]
- Hasseldine, J.; Salama, A.I.; Toms, J.S. Quantity versus quality: The impact of environmental disclosures on the reputations of UK Plcs. Br. Account. Rev. 2005, 37, 231–248. [Google Scholar] [CrossRef]
- Beck, A.C.; Campbell, D.; Shrives, P.J. Content analysis in environmental reporting research: Enrichment and rehearsal of the method in a British–German context. Br. Account. Rev. 2010, 42, 207–222. [Google Scholar] [CrossRef]
- Rupley, K.H.; Brown, D.; Marshall, R.S. Governance, media and the quality of environmental disclosure. J. Account. Public Policy 2012, 31, 610–640. [Google Scholar] [CrossRef]
- O’donovan, G. Environmental disclosures in the annual report. Account. Audit. Account. J. 2002. [Google Scholar] [CrossRef]
- Gray, R.; Milne, M.J. It’s not what you do; it’s the way that you do it? Of method and madness. Crit. Perspect. Account. 2015, 32, 51–66. [Google Scholar] [CrossRef]
- Neuman, S.P. Maximum likelihood Bayesian averaging uncertain model predictions. Stoch. Environ. Res. Risk Assess. 2003, 17, 291–305. [Google Scholar] [CrossRef]
- Feldman, R.; Sanger, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Milne, M.J.; Adler, R.W. Exploring the reliability of social and environmental disclosures content analysis. Account. Audit. Account. J. 1999. [Google Scholar] [CrossRef]
- Aureli, S. A comparison of content analysis usage and text mining in CSR corporate disclosure. Int. J. Digit. Account. Res. 2017, 17. [Google Scholar] [CrossRef]
- Sebestyén, V.; Domokos, E.; Abonyi, J. Focal points for sustainable development strategies—Text mining-based comparative analysis of voluntary national reviews. J. Environ. Manage. 2020. [Google Scholar] [CrossRef]
- Yang, H.-C.; Lee, C.-H. Semantics-Based Image Retrieval by Text Mining on Environmental Texts; Document Recognition and Retrieval X, 2003; International Society for Optics and Photonics: Bellingham, WA, USA, 2003; pp. 266–277. [Google Scholar]
- Modapothala, J.R.; Issac, B. Assessing corporate environmental and sustainability reports using text mining and bayesian estimate. In Software Technology and Engineering; World Scientific: Singapore, 2009; pp. 151–155. [Google Scholar]
- Huang, A.H.; Zang, A.Y.; Zheng, R. Evidence on the information content of text in analyst reports. Account. Rev. 2014, 89, 2151–2180. [Google Scholar] [CrossRef]
- Riffe, D.; Lacy, S.; Fico, F.; Watson, B. Analyzing Media Messages: Using Quantitative Content Analysis in Research; Routledge: Abingdon, UK, 2019. [Google Scholar]
- Bonzanini, M. Mastering Social Media Mining with Python; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Lee, J.; Lee, M.J. Measuring Contribution of Spatial Information to Environmental Research Using Text Mining Techniques. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA, 2018; pp. 5289–5291. [Google Scholar]
- Maeda, T.; Chujo, Y.; Park, E. Text Mining Analysis on Determinants of Environmental Costs Expenditure as Time Series Data. In Proceedings of the 3rd Technology Innovation Management and Engineering Science International Conference (TIMES-iCON), Bangkok, Thailand, 12–14 December 2018; IEEE: New York, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Lock, I.; Seele, P. Quantitative content analysis as a method for business ethics research. Bus. Ethics Eur. Rev. 2015, 24, S24–S40. [Google Scholar] [CrossRef]
- Park, K.; Kremer, G.E.O. Text mining-based categorization and user perspective analysis of environmental sustainability indicators for manufacturing and service systems. Ecol. Indic. 2017, 72, 803–820. [Google Scholar] [CrossRef]
- Rabiei, M.; Hosseini-Motlagh, S.-M.; Haeri, A. Using text mining techniques for identifying research gaps and priorities: A case study of the environmental science in Iran. Scientometrics 2017, 110, 815–842. [Google Scholar] [CrossRef]
- Villeneuve, H.; O’Brien, W.J.B. Environment, Listen to the guests: Text-mining Airbnb reviews to explore indoor environmental quality. Build. Environ. 2020, 169, 106555. [Google Scholar] [CrossRef]
- Wang, F.; Peng, X.; Qin, Y.; Wang, C. What can the news tell us about the environmental performance of tourist areas? A text mining approach to China’s National 5A Tourist Areas. Sustain. Cities Soc. 2020, 52, 101818. [Google Scholar] [CrossRef]
- Prihatini, P.M.; Suryawan, I.K.; Mandia, I.N. Feature extraction for document text using Latent Dirichlet Allocation. J. Phys. Conf. Ser. 2018, 953, 12047. [Google Scholar] [CrossRef]
- Alhawarat, M.; Hegazi, M. Revisiting K-Means and Topic Modeling. a Comparison Study to Cluster Arabic Documents. IEEE Access 2018, 6, 42740–42749. [Google Scholar] [CrossRef]
- Bui, Q.V.; Sayadi, K.; Amor, S.B.; Bui, M. Combining Latent Dirichlet Allocation and K-Means for documents Clustering; Effect of Probabilistic Based Distance Measures. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Kanazawa, Japan, 3–5 April 2017; pp. 212–232. [Google Scholar]
- Salton, G.; Allan, J.; Buckley, C.; Singhal, A. Automatic analysis, theme generation, and summarization of machine-readable texts. Science 1994, 264, 1421–1426. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. Available online: https://arxiv.org/abs/1301.3781 (accessed on 4 July 2020).
- McCormick, C. Word2vec Tutorial-the Skip-Gram Model. In Retrieved: 2016. Available online: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model (accessed on 8 March 2020).
- Salton, G.; Yang, C.-S.; Yu, C.T. A theory of term importance in automatic text analysis. J. Am. Soc. Inf. Sci. 1975, 26, 33–44. [Google Scholar] [CrossRef]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Liew, W.T.; Adhitya, A.; Srinivasan, R. Sustainability trends in the process industries: A text mining-based analysis. Comput. Ind. 2014, 65, 393–400. [Google Scholar] [CrossRef]
- Liu, F.; Liu, F.; Liu, Y. Automatic keyword extraction for the meeting corpus using supervised approach and bigram expansion. In Proceedings of the 2008 IEEE Spoken Language Technology Workshop, Goa, India, 15–19 December 2008; IEEE: New York, NY, USA, 2008; pp. 181–184. [Google Scholar]
- Tsai, M.-F.; Wang, C.-J. Financial keyword expansion via continuous word vector representations. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1453–1458. [Google Scholar]
- Ruiz Estrada, M.A. The Policy Modeling Research Consistency Index (PMC-Index); Available at SSRN 1689475; Social Science Electronic Publishing: Rochester, NY, USA, 2010. [Google Scholar]
- Estrada, M.A.R. Policy modeling: Definition, classification, and evaluation. J. Policy Modeling 2011, 33, 523–536. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, M.; Cheng, J. Regulation effect of external pressure to the enterprise environment disclosure. Soft Sci. 2016, 30, 74–78. [Google Scholar]
- Mandelbrot, B. New methods in statistical economics. J. Political Econ. 1963, 71, 421–440. [Google Scholar] [CrossRef]
- Donohue, J.C. Understanding Scientific Literature: A Bibliometric Approach; Back to cited text 12; The Massachusetts Institute of Technology Press: Cambridge, MA, USA, 1974; p. 101. [Google Scholar]
- Drake, L. The non-market value of the Swedish agricultural landscape. Eur. Rev. Agric. Econ. 1992, 19, 351–364. [Google Scholar] [CrossRef]
- Costas, R.; Bordons, M. Is g-index better than h-index? An exploratory study at the individual level. Scientometrics 2008, 77, 267–288. [Google Scholar] [CrossRef]
- Woolson, R. Wilcoxon signed-rank test. In Wiley Encyclopedia of Clinical Trials; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2007; pp. 1–3. [Google Scholar]










| High-Frequency Words | Frequency | High-Frequency Words | Frequency | High-Frequency Words | Frequency | |||
|---|---|---|---|---|---|---|---|---|
| Environment | 511,106 | 0.011119 | Construction | 66,305 | 0.001442 | Industry | 24,778 | 0.000539 |
| Protection | 510,009 | 0.011095 | Service | 61,809 | 0.001345 | Energy | 24,396 | 0.000531 |
| Cost-effective | 497,984 | 0.010834 | Invention | 60,013 | 0.001306 | Funds | 21,412 | 0.000466 |
| Investment | 487,238 | 0.010600 | Science | 59,544 | 0.001295 | Improvement | 21,116 | 0.000459 |
| Project | 452,814 | 0.009851 | Investment | 58,548 | 0.001274 | Operation | 17,829 | 0.000388 |
| Cost | 188,522 | 0.004101 | Economy | 55,960 | 0.001217 | Reduction | 15,730 | 0.000342 |
| Pollution | 163,831 | 0.003564 | Responsibility | 55,275 | 0.001203 | Safeguard | 15,727 | 0.000342 |
| Development | 137,724 | 0.002996 | Chemistry | 54,805 | 0.001192 | Manufacture | 13,961 | 0.000304 |
| Management | 136,666 | 0.002973 | Society | 53,020 | 0.001153 | Power | 10,338 | 0.000225 |
| Production | 134,863 | 0.002934 | Accomplishment | 51,753 | 0.001126 | Patent | 10,091 | 0.000220 |
| Reduction 2/5000 reduce | 109,370 | 0.002379 | Execution | 50,266 | 0.001094 | Equipment | 8431 | 0.000183 |
| Matters | 109,237 | 0.002376 | System | 50,070 | 0.001089 | Retrofit | 8393 | 0.000183 |
| Emission | 103,176 | 0.002245 | Conservation | 46,919 | 0.001021 | Engineering | 7993 | 0.000174 |
| Technology | 102,848 | 0.002237 | Safety | 46,166 | 0.001004 | Operation | 7199 | 0.000157 |
| Production | 98,763 | 0.002149 | Governance | 42,869 | 0.000933 | Green | 7146 | 0.000155 |
| Information | 98,715 | 0.002148 | Development | 28,605 | 0.000622 | Decrease | 7067 | 0.000154 |
| Policy | 97,351 | 0.002118 | Enhancement | 28,379 | 0.000617 | Operations | 6382 | 0.000139 |
| Research | 70,553 | 0.001535 | Resources | 26,634 | 0.000579 | Cycle | 6273 | 0.000136 |
| Implement | 66,873 | 0.001455 | Quality | 26,131 | 0.000568 | Waste | 5437 | 0.000118 |
| Fulfillment | 66,438 | 0.001445 | Organization | 26,045 | 0.000567 | Surroundings | 5321 | 0.000116 |
| Environment | Protection | Cost-Effective | Investment | Project | Cost | Pollution | Development | Management | Production | |
|---|---|---|---|---|---|---|---|---|---|---|
| Environment | 0 | – | – | – | – | – | – | – | – | – |
| Protection | 338 | 0 | – | – | – | – | – | – | – | – |
| Cost-effective | 39 | 146 | 0 | – | – | – | – | – | – | – |
| Investment | 84 | 826 | 3812 | 0 | – | – | – | – | – | – |
| Project | 4 | 55 | 2 | 14 | 0 | – | – | – | – | – |
| Cost | 72 | 16 | 19 | 8 | 21 | 0 | – | – | – | – |
| Pollution | 72 | 27 | 8 | 28 | 6 | 31 | 0 | – | – | – |
| Development | 2 | 11 | 5 | 1 | 2 | 0 | 4 | 0 | – | – |
| Management | 6 | 4 | 3 | 2 | 1 | 5 | 71 | 0 | 0 | – |
| Production | 2 | 3 | 7 | 4 | 0 | 17 | 2 | 1 | 13 | 0 |
| Number | Threshold Definition Meth | High-Frequency Threshold | Number of High-Frequency Words Extracted |
|---|---|---|---|
| 1 | Pareto’s law selection method [66] | 10 | 30 |
| 2 | Donohue method [67] | 50 | 3 |
| 3 | Drake Price method [68] | 8 | 34 |
| 4 | g-index method [69] | 10 | 26 |
| Cluster1 | Cluster2 | Cluster3 | Cluster4 | Cluster5 | Cluster6 | Cluster7 | Cluster8 | Cluster9 |
|---|---|---|---|---|---|---|---|---|
| Policy | Consume | Wastewater | Waste materials | Research | Environmental | Sewage | Tax | Reward |
| System | Energy | Emission | Waste product | Protection | Fine | Greening | Exemption | Income |
| Department | Loss | Trash | Castoff | Expenditure | Expenditure | Service | Financial | Benefit |
| Management | Consumption | Poisonous | Recycle | Energy saving | Cost | Governance | Subsidy | Utilization |
| Aims | Expenditure | Noise | Dispose | Surroundings | Pay | Clean | Discount | Exploitation |
| Measures | – | Dust | – | Engineering | Punishment | – | Return | Operations |
| Systematism | – | – | – | Governance | – | – | – | – |
| Standard | – | – | – | Equipment | – | – | – | – |
| Accident | – | – | – | Detect | – | – | – | – |
| Education | – | – | – | – | – | – | – | – |
| Construction | – | – | – | – | – | – | – | – |
| Production | – | – | – | – | – | – | – | – |
| Thematic Layer | Index Layer | Connotation |
|---|---|---|
| Corporate Governance Structure (X1) | Environmental protection concept (X11) | It mainly refers to the EID management mechanism principles and components. The relevant information reflects the importance of environmental protection by listed companies and their intention to release environmental information. Includes information regarding environmental standards used by listed companies, preparations for environmental management systems, and managers’ attitudes towards ecological management |
| Environmental management organization (X12) | ||
| Environmental goals (X13) | ||
| ISO14001 standard (X14) | ||
| Environmental accident (X15) | ||
| Environmental education and training (X16) | ||
| Implement the “Three Simultaneous System” (X17) | ||
| Environmental Responsibility (X2) | Total resource consumption (X21) | Shows the specific energy consumption of the company. The company’s total energy consumption can directly reflect its actual performance in energy conservation. Relevant information can be used to assess the managers’ expectations for environmental protection contributions |
| Environmental Pollution Discharge (X3) | Wastewater disposal (X31) | Describes the company’s specific quantities of waste gas, wastewater, industrial waste, emission noise, and dust. Related information refers to the impacts of the company’s production and operation activities on the natural environment. Relevant information can be used to evaluate the achievements of listed companies in treating environmental pollution. |
| Stable waste discharge (X32) | ||
| Toxic emissions (X33) | ||
| Noise emission (X34) | ||
| Dust emissions (X35) | ||
| Waste Disposal (X4) | Waste disposal (X41) | Shows the disposal of waste products and waste by listed companies. |
| Waste recycling (X42) | ||
| Environmental Governance Expenditure (X5) | Environmental research expenditure (X51) | Records the company’s expenditure on environmental management research and development. Reflect the company’s work in environmental protection for some time, including environmental research expenditures, environmental protection governance expenditures, and environmental equipment expenditures. It can prompt companies to take more significant measures in environmental management. |
| Environmental protection expenditure (X52) | ||
| Environmental equipment expenditure (X53) | ||
| Environmental Fine Expenditure (X6) | Environmental acceptable payment (X61) | Companies’ fines for environmental protection |
| Environmental Protection Expenditure (X7) | Pollution discharge fee, greening fee, environmental protection fee (X71) | Shows the company’s pollution discharge, greening, and environmental protection fees. |
| Environmental Protection Tax Relief (X8) | Tax deduction (X81) | Explains the environmental protection tax reduction and exemption of listed companies. |
| Environmental Rewards (X9) | Environmental rewards (X91) Environmental income (X92) Waste utilization income (X93) | Explains the companies’ incentive income for environmental protection. |
| Thematic Layer | Index Layer | Index Layer Weight Value |
|---|---|---|
| Corporate Governance Structure (X1) | Environmental protection concept (X11) | 0.4415 |
| Environmental management organization (X12) | 0.4899 | |
| Environmental goals (X13) | 0.5394 | |
| ISO14001 standard (X14) | 0.4600 | |
| Environmental accident (X15) | 0.5487 | |
| Environmental education and training (X16) | 0.3706 | |
| Implement the “Three Simultaneous System” (X17) | 0.5476 | |
| Environmental Responsibility (X2) | Total resource consumption (X21) | 0.6859 |
| Environmental Pollution Discharge (X3) | Wastewater disposal (X31) | 0.6851 |
| Stable waste discharge (X32) | 0.2859 | |
| Toxic emissions (X33) | 0.4415 | |
| Noise emission (X34) | 0.4899 | |
| Dust emissions (X35) | 0.4600 | |
| Waste Disposal (X4) | Waste disposal (X41) | 0.3706 |
| Waste recycling (X42) | 0.4899 | |
| Environmental Governance Expenditure (X5) | Environmental research expenditure (X51) | 0.5476 |
| Environmental protection expenditure (X52) | 0.4394 | |
| Environmental equipment expenditure (X53) | 0.5394 | |
| Environmental Fine Expenditure (X6) | Environmental acceptable payment (X61) | 0.5476 |
| Environmental Protection Expenditure (X7) | Pollution discharge fee, greening fee, environmental protection fee (X71) | 0.4415 |
| Environmental Protection Tax Relief (X8) | Tax deduction (X81) | 0.4899 |
| Environmental Rewards (X9) | Environmental rewards (X91) | 0.3859 |
| Environmental income (X92) | 0.4899 | |
| Waste utilization income (X93) | 0.4600 |
| Industry Code | Heavily Polluting Industry | Samples | EID Quality Scores | |||||
|---|---|---|---|---|---|---|---|---|
| 2013 | 2014 | 2015 | 2016 | 2017 | Average | |||
| B06 | Coal mining and washing | 23 | 10.97 | 10.93 | 11.00 | 11.34 | 11.72 | 11.20 |
| B07 | Oil and gas extraction | 3 | 11.16 | 10.52 | 11.35 | 11.29 | 12.59 | 11.38 |
| B08 | Ferrous metal mining and dressing | 5 | 7.86 | 8.88 | 9.51 | 10.16 | 10.51 | 9.38 |
| B09 | Non-ferrous metal mining and dressing | 18 | 11.28 | 10.75 | 11.26 | 11.27 | 11.75 | 11.26 |
| C17 | Textile | 31 | 7.11 | 7.48 | 8.00 | 9.21 | 9.49 | 8.26 |
| C19 | Manufacturing of leather, fur, feathers | 12 | 9.20 | 9.80 | 9.52 | 9.89 | 10.19 | 9.72 |
| C22 | Paper and paper products | 22 | 8.03 | 8.30 | 8.70 | 10.29 | 10.92 | 9.25 |
| C25 | Petroleum processing, coking and nuclear fuel | 10 | 11.49 | 10.67 | 10.73 | 11.49 | 11.53 | 11.18 |
| C26 | Chemical raw materials and chemical products | 198 | 10.32 | 10.65 | 10.76 | 11.15 | 11.42 | 10.86 |
| C27 | Pharmaceutical Manufacturing | 191 | 6.75 | 7.20 | 7.95 | 8.90 | 10.86 | 8.33 |
| C28 | Chemical fibre manufacturing | 15 | 10.05 | 10.23 | 10.33 | 11.22 | 11.37 | 10.64 |
| C30 | Non-metallic mineral products | 73 | 10.21 | 10.84 | 10.45 | 10.75 | 11.03 | 10.66 |
| C31 | Ferrous metal smelting and rolling processing | 25 | 11.07 | 11.49 | 11.56 | 11.80 | 12.13 | 11.61 |
| C32 | Non-ferrous metal smelting and rolling | 58 | 10.60 | 10.85 | 10.73 | 11.01 | 11.29 | 10.89 |
| C33 | Metal products | 54 | 6.03 | 9.67 | 9.75 | 10.30 | 10.62 | 10.19 |
| D44 | Electricity and thermal power production | 63 | 10.16 | 10.36 | 10.59 | 10.86 | 10.94 | 10.58 |
| Total | 801 | – | – | – | – | – | – | |
| Industry | Observations | Environmental Information Disclosure Quality Evaluation Index (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2013 | 2014 | 2015 | 2016 | 2017 | Min | Max | AVG | SD | ||
| B06 | 23 | 45.7083 | 45.5417 | 45.8333 | 47.2500 | 48.8333 | 45.5416 | 48.8333 | 46.6333 | 1.5098 |
| B07 | 3 | 46.5000 | 43.8333 | 47.2917 | 47.0417 | 52.4583 | 43.8333 | 52.4583 | 47.4250 | 3.5677 |
| B08 | 5 | 32.7500 | 37.0000 | 39.6250 | 42.3333 | 43.7917 | 32.7500 | 43.7916 | 39.1000 | 3.0040 |
| B09 | 18 | 47.0000 | 44.7917 | 46.9167 | 46.9583 | 48.9583 | 44.7916 | 48.9583 | 46.9250 | 1.7015 |
| C17 | 31 | 29.6250 | 31.1667 | 33.3333 | 38.3750 | 39.5417 | 29.6250 | 39.5416 | 34.4083 | 4.0012 |
| C19 | 12 | 38.3333 | 40.8333 | 39.6667 | 41.2083 | 42.4583 | 38.3333 | 42.4583 | 40.5000 | 1.1502 |
| C22 | 22 | 33.4583 | 34.5833 | 36.2500 | 42.8750 | 45.5000 | 33.4583 | 45.5000 | 38.5333 | 5.2205 |
| C25 | 10 | 47.8750 | 44.4583 | 44.7083 | 47.8750 | 48.0417 | 44.4583 | 48.0416 | 46.5916 | 1.9524 |
| C26 | 198 | 43.0000 | 44.3750 | 44.8333 | 46.4583 | 47.5833 | 43.0000 | 47.5833 | 45.2500 | 1.4808 |
| C27 | 191 | 28.1250 | 30.0000 | 33.1250 | 37.0833 | 45.2500 | 28.1250 | 45.2500 | 34.7167 | 6.5947 |
| C28 | 15 | 41.8750 | 42.6250 | 43.0417 | 46.7500 | 47.3750 | 41.8750 | 47.3750 | 44.3333 | 2.4609 |
| C30 | 73 | 42.5417 | 45.1667 | 43.5417 | 44.7917 | 45.9583 | 42.5416 | 45.9583 | 44.4000 | 1.0071 |
| C31 | 25 | 46.1250 | 47.8750 | 48.1667 | 49.1667 | 50.5417 | 46.1250 | 50.5416 | 48.3750 | 1.2040 |
| C32 | 58 | 44.1667 | 45.2083 | 44.7083 | 45.8750 | 47.0417 | 44.1666 | 47.0416 | 45.4000 | 1.0092 |
| C33 | 54 | 25.1250 | 40.2917 | 40.6250 | 42.9167 | 44.2500 | 25.1250 | 44.2500 | 38.6416 | 1.8895 |
| D44 | 63 | 42.3333 | 43.1667 | 44.1250 | 45.2500 | 45.5833 | 42.3333 | 45.5833 | 44.0916 | 1.1031 |
| Text | 2015 | 2016 |
|---|---|---|
| z-Statistics | −0.205 | −0.012 |
| p-value | 0.837 | 0.921 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, R.; Lv, T.; Deng, X. Evaluation of Environmental Information Disclosure of Listed Companies in China’s Heavy Pollution Industries: A Text Mining-Based Methodology. Sustainability 2021, 13, 5415. https://doi.org/10.3390/su13105415
Cai R, Lv T, Deng X. Evaluation of Environmental Information Disclosure of Listed Companies in China’s Heavy Pollution Industries: A Text Mining-Based Methodology. Sustainability. 2021; 13(10):5415. https://doi.org/10.3390/su13105415
Chicago/Turabian StyleCai, Rongjiang, Tao Lv, and Xu Deng. 2021. "Evaluation of Environmental Information Disclosure of Listed Companies in China’s Heavy Pollution Industries: A Text Mining-Based Methodology" Sustainability 13, no. 10: 5415. https://doi.org/10.3390/su13105415
APA StyleCai, R., Lv, T., & Deng, X. (2021). Evaluation of Environmental Information Disclosure of Listed Companies in China’s Heavy Pollution Industries: A Text Mining-Based Methodology. Sustainability, 13(10), 5415. https://doi.org/10.3390/su13105415