
Multicriteria Definition of Small-Scale Biorefineries Based on a Statistical Classification



Abstract
:1. Introduction
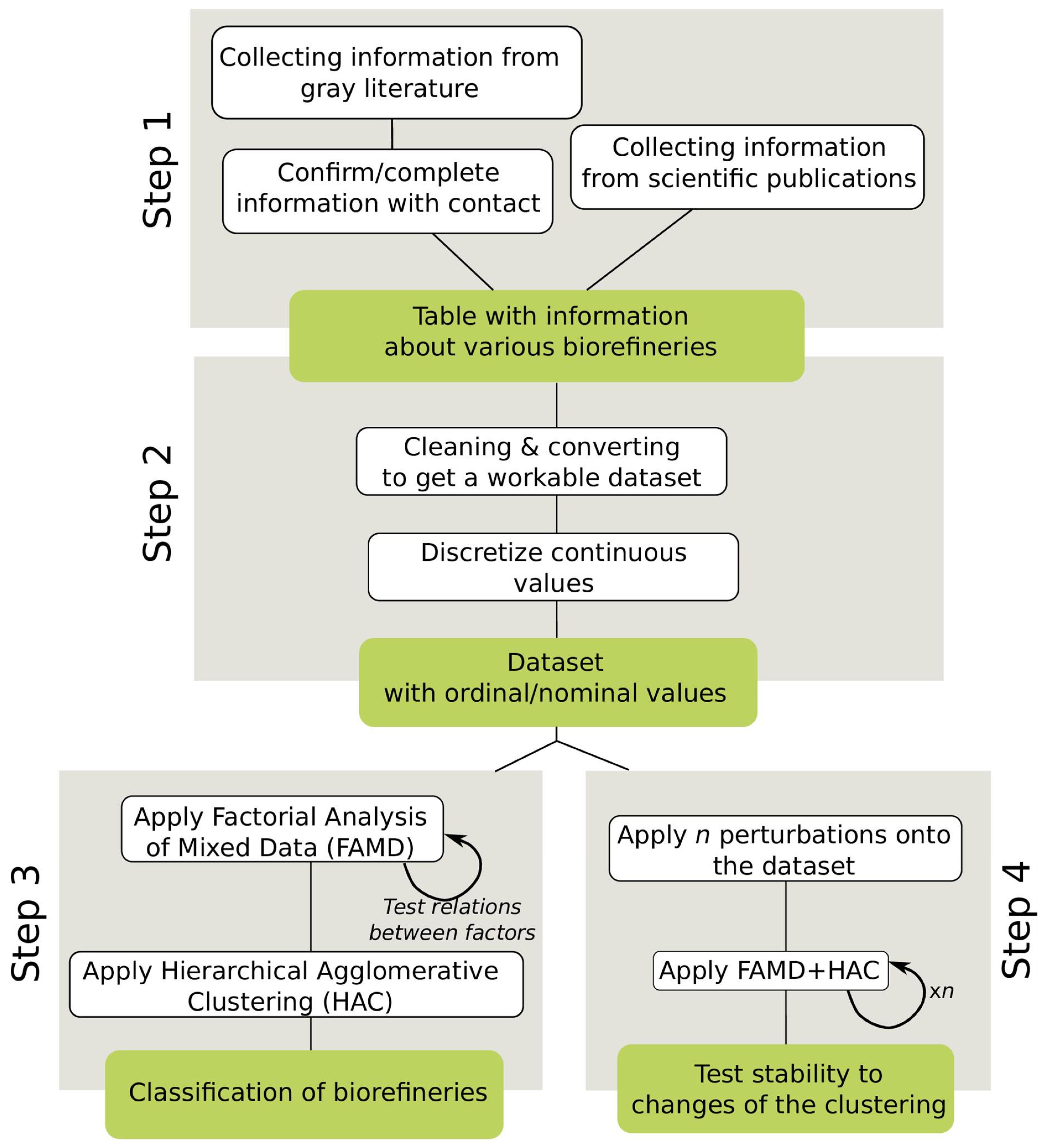
2. Materials and Methods
2.1. Step 1: Collecting Information about Biorefineries
- Identification (project name, comments about why it may be seen as small- or large-scale)
- Socioeconomic characteristics (geographical area, crop area, investment cost, runtime, direct stakeholders, ownership (public/private), sustainability assessments)
- Process information (biomass, process type, process scheme, complexity of the process, products, raw material processed, production capacity, flexibility)
2.2. Step 2: Building Dataset and Data Pretreatment
2.3. Step 3: Establishing a Classification through Clustering Analysis
2.4. Step 4: Testing HAC Stability over Perturbations in the Dataset
- Generate the combinations of factors;
- For each combination of factors, exclude the selected factors and run FAMD+HAC to generate a hierarchical clustering visualized as a tree-like representation called dendrogram;
- Go through each branching from top (2 clusters) to bottom (1 individual per cluster) to compute the matrix of pairwise proximity measures (proportional to the separation level);
- Average proximity measures over all the combinations to get a single matrix of proximity;
- Run HAC on the matrix to cluster individuals by pairwise proximities and obtain an average clustering.
3. Results
3.1. Description and Treatment of the Collected Information (Step 1 and Step 2)
- Processing capacity (P.C) in t/day, quantitative variable, value domain: [2, 205];
- Investment cost (I.C) in M€, quantitative variable, value domain: [<1, 82.5];
- Biomass type (B.T), nominal variable; modalities are: CoProd for co-product represents the valuable biomass obtained in the production of primary products (e.g., crops) or during monitoring operations such as tree pruning (e.g., NETTENERGY). Waste corresponds to low-quality biomass of null or negative values that has been left out by its owners, as is the case, for instance, for HEPHAETUS that uses agricultural waste from locally harvested selected sorghum. DediBiomass is for dedicated biomass, a raw biomass and a primary product for the biorefinery, as in the case for DATCO, which processes manioc roots.
- Biorefinery mobility (B.M), nominal variable; modalities are: Centralized, static facility, Mobile, mobile facility. Herein a mobile biorefinery means a facility that has the refining process built on a moving track. This comes in contrast to the conventional stationary centralized organization of biorefineries.
- Added value (A.V), ordinal variable derived from the product type (see Supplementary Data). Possible product types are bioenergy and heat, biomaterials (bioplastics and polymers), bulk chemicals and biofuels, food additives and fine chemicals. These categories are codified in this order into a scale of five levels of increasing added value (from very low for bioenergy to very high for fine chemicals). This is based on the “Market prices versus market volumes biobased products” classification from de Jong et al. [25];
- Process complexity (P.Co), ordinal variable, substitutes process type and process scheme (Supplementary Data), given that they provide a too-detailed and hard-to-compute description of the biorefinery process. Modalities of P.Co are: Low, when the process is mainly mechanical and/or thermal and is easily manageable with minimum engineering skills. Medium, when the process is mainly mechanical and chemical or chemical and biotech, with more processing steps than for low-complexity process. High, when many processes (mechanical, chemical and biotech, etc.) are involved, which requires significant engineering resources to run sophisticated facilities.
3.2. Multifactorial Classification of Scale-Based Designs (Step 3)
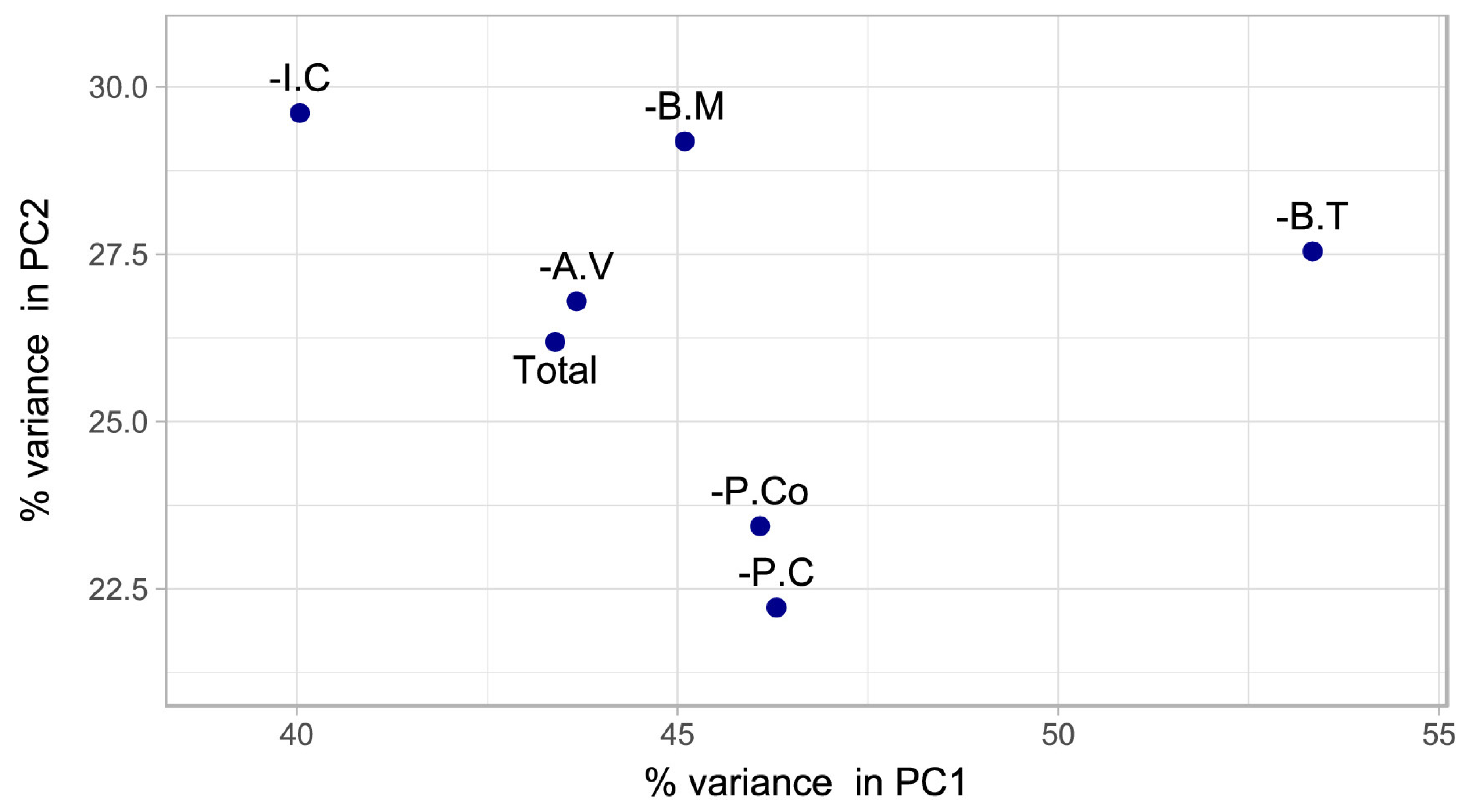
3.2.1. Selecting Factors for Clustering
3.2.2. Describing the Relations between the Factors
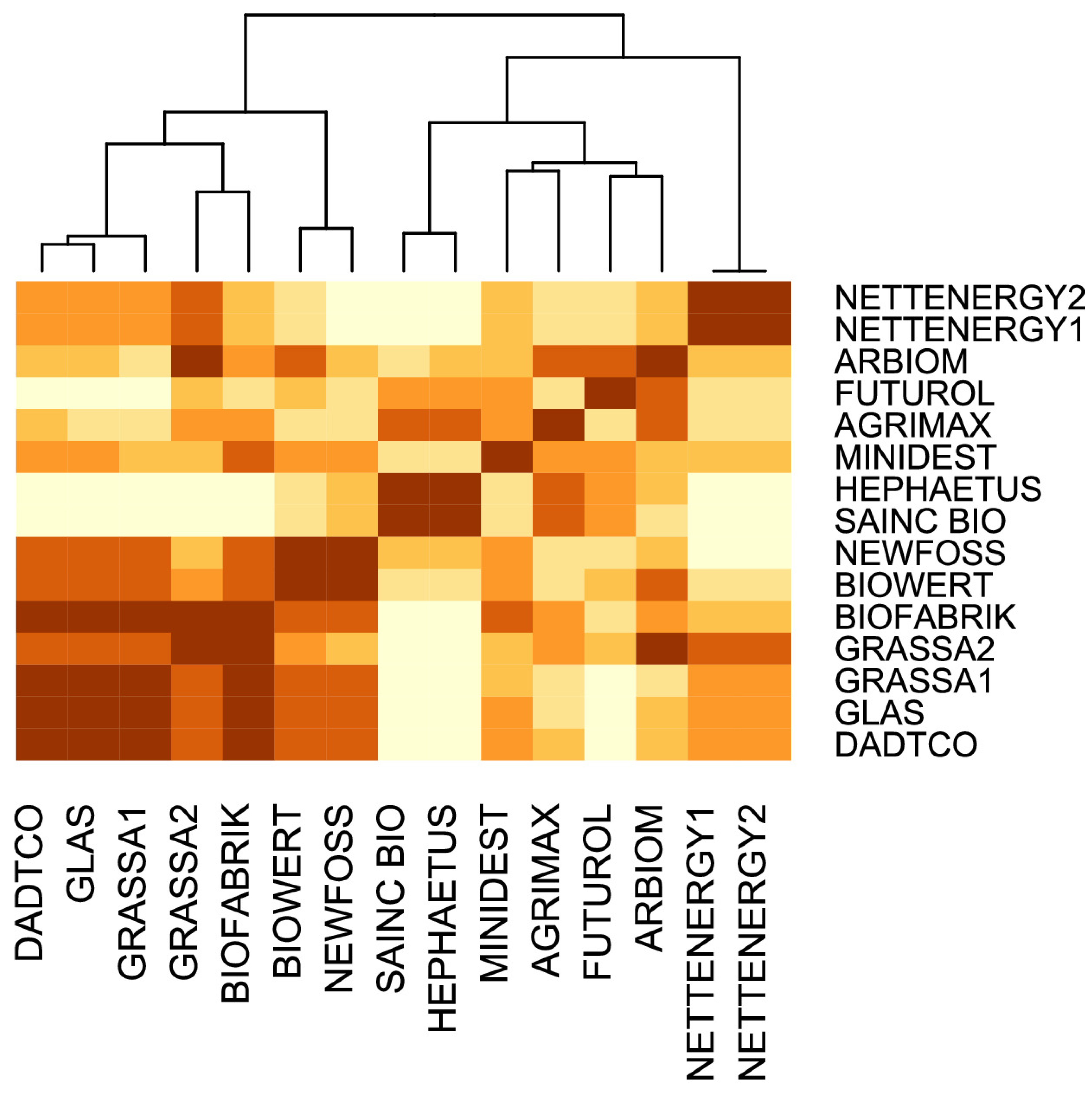
3.2.3. Clustering Results
3.2.4. A Classification of Scale-Based Designs
- Smallest-Scale Biorefinery. NETTENERGY1&2 characterize the smallest scale biorefinery cluster in our dataset. It is outlined by a low processing capacity (2–10 t/day), a small investment cost (≤1 M€), a mobile facility that can move close to feedstock depots to process it on site. The process converts low energy density and low-value product (e.g., wood residues) into high-energy-density products (bio-oil, biochar), that have low added value. The compactness of the process is crucial to fit in a mobile plant. Small processing capacity and affordable low-complexity technology (pyrolysis) make it inexpensive to build. Finally, the plant produces its own heat and power from the biomass, which favors the circularity of energy consumption and lowers the operational costs. These elements meet some requirements listed by Bramsiepe et al. [26] to obtain viable small-scale biorefineries. The business model is to commercialize truck-scale biorefineries to the producers of biomass feedstocks (farmers, wood producers, municipalities, etc.), who prefer to process the waste with little transportation instead of storing it with little valorization.
- Small-Scale Biorefinery. This cluster gathers biorefineries with either a mobile—GRASSA1, DADTCO, GLAS—or a centralized facility—GRASSA2, BIOFABRIK. These biorefineries have a low-to-medium processing capacity (≤100 t/day), low investment cost (<2 M€), a mostly mechanical process with low complexity, producing medium-to-high added-value products, such as fibers, proteins and amino acids, inter alia. Looking into the biorefineries’ descriptions (Supplementary Data), one important point of this design is the limitation of the transportation of the feedstock. Mobile units can visit different feedstock depots and farms to transform the biomass close to the production sites, while centralized biorefineries are built in the vicinity of feedstock production sites. In the same line, BIOFABRIK’s principle is to set the conversion process up inside an already existing biogas plant, which provides the necessary infrastructure, as well as large quantities of raw materials. BIOFABRIK brings expertise to biogas plants for converting grass into proteins and amino acids in addition to biogas, without investment or additional expenditure. Moreover, while profiting from the existing machinery, it is environmentally beneficial for having low CO2 emissions [27].
- Hybrid-Scale Biorefinery. This cluster gathers biorefineries with intermediary characteristics between the small and the large-scale biorefineries. MINIDEST, ARBIOM and AGRIMAX are centralized facilities with low processing capacities (30 t/day on average), variable investment cost and added value, and medium-to-high process complexity.
- Large-Scale Biorefinery. This cluster gathers centralized biorefineries with the highest investment cost and the highest processing capacity. The process complexity level is high or very high, and the main end-products range from medium-to-low added value. NEWFOSS and BIOWERT are grouped here for their relatively higher added value compared to biorefineries producing mainly energy and bulk chemicals. FUTUROL, SAINC BIO and HEPHAESTUS process corn or sorghum residues to produce mainly ethanol and bulk chemicals. Large-scale biorefineries involve significant logistical costs to collect and manage the volume of feedstock, but the flexibility of the conversion processes can ensure feedstock availability throughout the year and thereby, a controlled collection area and price. Besides, this type of biorefineries aims at benefitting from an economy of scale [28], as is the case for traditional refineries and other industrial sectors [29].
3.3. Stability of the Clusters (Step 4)
4. Discussion
4.1. Defining Small-Scale Biorefinery
4.1.1. Focus on Investment Cost and Processing Capacity in This Work
4.1.2. A Data-Based Definition of the Scale of Biorefinery
4.1.3. Limitations of the Work
4.2. Classification Method for Biorefinery Systems
4.3. Future Works
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- European Commission. Bioeconomy|Horizon. 2020. Available online: https://ec.europa.eu/programmes/horizon2020/en/h2020-section/bioeconomy (accessed on 16 September 2020).
- United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development. Available online: https://sustainabledevelopment.un.org/content/documents/21252030%20Agenda%20for%20Sustainable%20Development%20web.pdf (accessed on 25 September 2020).
- Heimann, T. Bioeconomy and SDGs: Does the Bioeconomy Support the Achievement of the SDGs? Earths Future 2019, 7, 43–57. [Google Scholar] [CrossRef] [Green Version]
- IEA Biorefinery Task 42 Biorefinery. Available online: https://www.iea-bioenergy.task42-biorefineries.com/upload_mm/5/8/2/a47bd297-2ace-44d0-92bb-cb7cc02f75de_Brochure_Totaal_definitief_webs.pdf (accessed on 26 September 2019).
- De Jong, E.; Jungmeier, G. Biorefinery Concepts in Comparison to Petrochemical Refineries. In Industrial Biorefineries & White Biotechnology; Elsevier B.V.: Amsterdam, The Netherlands, 2015; pp. 3–33. [Google Scholar] [CrossRef]
- Aristizábal-Marulanda, V.; Cardona Alzate, C.A. Methods for Designing and Assessing Biorefineries: Review. Biofuels Bioprod. Biorefin. 2019, 13, 789–808. [Google Scholar] [CrossRef]
- FitzPatrick, M.; Champagne, P.; Cunningham, M.F.; Whitney, R.A. A Biorefinery Processing Perspective: Treatment of Lignocellulosic Materials for the Production of Value-Added Products. Bioresour. Technol. 2010, 101, 8915–8922. [Google Scholar] [CrossRef]
- Menon, V.; Rao, M. Trends in Bioconversion of Lignocellulose: Biofuels, Platform Chemicals & Biorefinery Concept. Prog. Energy Combust. Sci. 2012, 38, 522–550. [Google Scholar] [CrossRef]
- Palmeros Parada, M.; Osseweijer, P.; Posada Duque, J.A. Sustainable Biorefineries, an Analysis of Practices for Incorporating Sustainability in Biorefinery Design. Ind. Crops Prod. 2017, 106, 105–123. [Google Scholar] [CrossRef]
- Ubando, A.T.; Felix, C.B.; Chen, W.H. Biorefineries in Circular Bioeconomy: A Comprehensive Review. Bioresour. Technol. 2020, 299. [Google Scholar] [CrossRef]
- Daoutidis, P.; Kelloway, A.; Marvin, W.A.; Rangarajan, S.; Torres, A.I. Process Systems Engineering for Biorefineries: New Research Vistas. Curr. Opin. Chem. Eng. 2013, 2, 442–447. [Google Scholar] [CrossRef]
- Serna Loaiza, S.; Aroca, G.E.; Cardona, C.A. Small-Scale Biorefineries: Future and Perspectives. In Biorefineries Concepts, Advancements and Research; Torres, I., Ed.; Nova Science Publishers, Inc.: New York, NY, USA, 2017; pp. 39–72. [Google Scholar]
- Serna-Loaiza, S.; García-Velásquez, C.A.; Cardona, C.A. Strategy for the Selection of the Minimum Processing Scale for the Economic Feasibility of Biorefineries. Biofuels Bioprod. Biorefin. 2019, 13, 107–119. [Google Scholar] [CrossRef] [Green Version]
- De Visser, C.; Van Ree, R. Small-Scale Biorefining. Available online: http://edepot.wur.nl/405718 (accessed on 11 June 2019).
- Bruins, M.E.; Sanders, J.P.M. Small-Scale Processing of Biomass for Biorefinery. Biofuels Bioprod. Biorefin. 2012, 6, 135–145. [Google Scholar] [CrossRef]
- Clauser, N.M.; Gutiérrez, S.; Area, M.C.; Felissia, F.E.; Vallejos, M.E. Small-Sized Biorefineries as Strategy to Add Value to Sugarcane Bagasse. Chem. Eng. Res. Des. 2016, 107, 137–146. [Google Scholar] [CrossRef]
- Kolfschoten, R.C.; Bruins, M.E.; Sanders, J.P.M. Opportunities for Small-Scale Biorefinery for Production of Sugar and Ethanol in the Netherlands. Biofuels Bioprod. Biorefin. 2014, 8, 475–486. [Google Scholar] [CrossRef]
- Susmozas, A.; Moreno, A.D.; Romero-García, J.M.; Manzanares, P.; Ballesteros, M. Designing an Olive Tree Pruning Biorefinery for the Production of Bioethanol, Xylitol and Antioxidants: A Techno-Economic Assessment. Holzforschung 2018, 73, 15–23. [Google Scholar] [CrossRef]
- Biorrefineria Blogspot. Available online: https://biorrefineria.blogspot.com/p/portada.html (accessed on 1 November 2018).
- Husson, F.; Josse, J.; Pagès, J. Principal Component Methods—Hierarchical Clustering—Partitional Clustering: Why Would We Need to Choose for Visualizing Data? Available online: http://factominer.free.fr/more/HCPC_husson_josse.pdf (accessed on 15 September 2020).
- Lê, S.; Josse, J.; Husson, F. FactoMineR: An R Package for Multivariate Analysis. J. Stat. Softw. 2008. [Google Scholar] [CrossRef] [Green Version]
- Pagès, J. Analyse Factorielle de Données Mixtes. In Revue de Statistique Appliquée; EDP Sciences: Les Ulis, France, 2004; Volume 52, pp. 93–111. [Google Scholar]
- Hennig, C. Cluster-Wise Assessment of Cluster Stability. Comput. Stat. Data Anal. 2007, 52, 258–271. [Google Scholar] [CrossRef] [Green Version]
- Brock, G.; Pihur, V.; Datta, S.; Datta, S. clValid: An R Package for Cluster Validation. J. Stat. Softw. 2008, 25, 1–22. [Google Scholar] [CrossRef] [Green Version]
- De Jong, E.; van Ree, R.; Sanders, J.P.M.; Langeveld, J.W.A. Biorefineries: Giving Value to Sustainable Biomass Use. In The Biobased Economy: Biofuels, Materials and Chemicals in the Post-Oil Era; Langeveld, J.W.A., Sanders, J.P.M., Eds.; Earthscan: Washington, DC, USA, 2010; pp. 111–131. [Google Scholar]
- Bramsiepe, C.; Sievers, S.; Seifert, T.; Stefanidis, G.D.; Vlachos, D.G.; Schnitzer, H.; Muster, B.; Brunner, C.; Sanders, J.P.M.; Bruins, M.E.; et al. Low-Cost Small Scale Processing Technologies for Production Applications in Various Environments-Mass Produced Factories. Chem. Eng. Process. Process Intensif. 2012, 51, 32–52. [Google Scholar] [CrossRef]
- Muniz Kubota, A.; Dal Belo Leite, J.; Watanabe, M.; Cavalett, O.; Leal, M.; Cortez, L. The Role of Small-Scale Biofuel Production in Brazil: Lessons for Developing Countries. Agriculture 2017, 7, 61. [Google Scholar] [CrossRef] [Green Version]
- Ma, S.; Eckhoff, S.R. Economy of Scale for Biomass Refineries: Bulk Densities, Transportation Cost, and Producer Incentives. Trans. ASABE 2014, 57, 85–91. [Google Scholar] [CrossRef]
- Richard, T.L. Challenges in Scaling up Biofuels Infrastructure. Science 2010, 329, 793–796. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsagkari, M.; Couturier, J.-L.; Kokossis, A.; Dubois, J.-L. Early-Stage Capital Cost Estimation of Biorefinery Processes: A Comparative Study of Heuristic Techniques. ChemSusChem 2016, 9, 2284–2297. [Google Scholar] [CrossRef] [PubMed]
- Schieb, P.-A.; Lescieux-Katir, H.; Thénot, M.; Clément-Larosière, B. Biorefinery 2030: Future Prospects for the Bioeconomy; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Clark, J.H.; Deswarte, F.E.I. The Biorefinery Concept—An Integrated Approach. In Introduction to Chemicals from Biomass; Clark, J., Deswarte, F., Eds.; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2008; pp. 1–20. [Google Scholar] [CrossRef]
- Eranki, P.L.; Bals, B.D.; Dale, B.E. Advanced Regional Biomass Processing Depots: A Key to the Logistical Challenges of the Cellulosic Biofuel Industry. Biofuels Bioprod. Biorefin. 2011, 5, 621–630. [Google Scholar] [CrossRef]
- Cherubini, F.; Jungmeier, G.; Wellisch, M.; Willke, T.; Skiadas, I.; van Ree, R.; de Jong, E. Toward a Common Classification Approach for Biorefinery Systems. Biofuels Bioprod. Biorefin. 2009, 534–546. [Google Scholar] [CrossRef]
- Gnansounou, E.; Pandey, A. Classification of Biorefineries Taking into Account Sustainability Potentials and Flexibility; Elsevier BV: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef]
- Langeveld, J.W.A.; Dixon, J.; Jaworski, J.F. Development Perspectives of the Biobased Economy: A Review. Crop Sci. 2010, 50 (Suppl. 1), S-142–S-151. [Google Scholar] [CrossRef]
- Díaz-Gaona, C.; Sánchez-Rodríguez, M.; Rucabado-Palomar, T.; Rodríguez-Estévez, V. A typological characterization of organic livestock farms in the Natural Park Sierra de Grazalema based on technical and economic variables. Sustainability 2019, 11, 6002. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CASE STUDIES | Process Capacity | Investment Cost | Biorefinery Mobility | Biomass Type | Added Value | Process Complexity |
|---|---|---|---|---|---|---|
| DADTCO | 1 | 1 | Mobile | DediBiomass | 3 | 1 |
| BIOWERT | 2 | 3 | Centralized | DediBiomass | 2 | 1 |
| NEWFOSS | 3 | 2 | Centralized | DediBiomass | 2 | 1 |
| GRASSA1 | 2 | 0 | Mobile | DediBiomass | 3 | 1 |
| GRASSA2 | 1 | 0 | Centralized | CoProd | 3 | 1 |
| BIOFABRIK | 1 | 0 | Centralized | DediBiomass | 4 | 1 |
| SAINC BIO | 3 | 4 | Centralized | Waste | 1 | 2 |
| NETTENERGY1 | 0 | 0 | Mobile | CoProd | 1 | 2 |
| NETTENERGY2 | 0 | 0 | Mobile | CoProd | 1 | 2 |
| MINIDEST | 1 | 1 | Centralized | DediBiomass | 1 | 3 |
| GLAS | 1 | 0 | Mobile | DediBiomass | 3 | 1 |
| HEPHAETUS | 3 | 3 | Centralized | Waste | 0 | 2 |
| FUTUROL | 2 | 4 | Centralized | CoProd | 0 | 3 |
| ARBIOM | 1 | 3 | Centralized | CoProd | 3 | 2 |
| AGRIMAX | 1 | 1 | Centralized | Waste | 2 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ait Sair, A.; Kansou, K.; Michaud, F.; Cathala, B. Multicriteria Definition of Small-Scale Biorefineries Based on a Statistical Classification. Sustainability 2021, 13, 7310. https://doi.org/10.3390/su13137310
Ait Sair A, Kansou K, Michaud F, Cathala B. Multicriteria Definition of Small-Scale Biorefineries Based on a Statistical Classification. Sustainability. 2021; 13(13):7310. https://doi.org/10.3390/su13137310
Chicago/Turabian StyleAit Sair, Aicha, Kamal Kansou, Franck Michaud, and Bernard Cathala. 2021. "Multicriteria Definition of Small-Scale Biorefineries Based on a Statistical Classification" Sustainability 13, no. 13: 7310. https://doi.org/10.3390/su13137310
APA StyleAit Sair, A., Kansou, K., Michaud, F., & Cathala, B. (2021). Multicriteria Definition of Small-Scale Biorefineries Based on a Statistical Classification. Sustainability, 13(13), 7310. https://doi.org/10.3390/su13137310