
Community Detection for Air Traffic Networks and Its Application in Strategic Flight Planning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- -
- we propose and compare different ways of defining flight interactions, which lead to different networks representing one day of flights across Europe;
- -
- we show that it is possible to divide the set of all European flights of one entire day into components that are temporally and/or spatially distinct, such that different components interact weakly;
- -
- we verify, for a relevant problem of strategic flight planning optimisation, that solving the problem on smaller components and then aggregating the solutions can be significantly faster than solving the whole network, at the only expense of a slight deterioration of the optimal solution.
2. Materials and Methods
2.1. Data
2.2. Network of Flights
- For each flight, the sectors-hour that it would cross are determined based on the requested route and requested departure time. Since the requested routes (represented in the DRR2 repository as so6 m0 format, first filed flight plan) are rarely available, here we use DDR2 so6 m1 routes (last filed flight plan) as a proxy. Two flights are linked if they share at least one of these sectors-hour.
- Similar to criterion 1, but now we consider two flights as linked only if they share at least one congested sector-hour. A sector-hour is congested if its capacity utilisation (number of flights accessing it divided by the nominal capacity) exceeds 80%. We determine the number of flights accessing each sector-hour based on the requested trajectories. According to this definition, 4462 sectors-hour are congested on a total of 24,008 (i.e., 18.6%). This network represents a less conservative approach than in 1., as it accounts for the fact that two flights sharing a non-congested sector-hour are not really competing for the sector-hour capacity as there is ample availability of this resource.
- For each flight, we determine the potentially crossed sectors-hour by considering all the possible trajectories that can be assigned to that flight. Two flights are linked if they share at least one of these sectors-hour. The possible trajectories include all the possible routes for that flight (see Section 2.1) and a departure time that can vary within ±30 min with respect to the requested one. Since the SAIPE model used as a benchmark in this study addresses the strategic planning phase, which comes before the publication of the flight schedules, departure and arrival times earlier or later than the requested ones may be assigned.
- Similar to criterion 3, but links are now weighted according to how many sectors-hour are shared and how congested they are. The weight of a link is the sum of the capacity utilisation of the sectors-hour in common between the two flights. We compute the capacity utilisation in a way that accounts for all the possible trajectories, by estimating the number of flights accessing a sector-hour as follows: if a flight has n possible trajectories, of which pass from a certain sector-hour, the latter will be accessed with probability by that flight (assuming that all trajectories are equally probable). We compute the expected number of flights accessing a sector-hour as the sum of its probability to be accessed by each flight. Finally, we divide this number by the nominal capacity to obtain the capacity load.
2.3. Community Detection Algorithms
2.4. Comparing Different Partitions
- The Rand Index (RI) [28] counts the fraction of node pairs that are either in the same set in both partitions or in different sets in both partitions, i.e., the probability that the two partitions agree on a random pair.
- The Mutual Information (MI) [29] of two partitions is defined aswhere and are the communities in the two partitions, is the probability that a node belongs to community in partition and is the joint probability that a node belongs to community in and to community in . The MI quantifies the amount of information on one partition that we obtain by observing the other partition. If the two partitions are completely independent, i.e., for all communities, they have MI .
2.5. The SAIPE Model
2.6. Comparing Constraint Violations
3. Results and Discussion
3.1. Comparison of Results of Community Detection in Different Scenarios
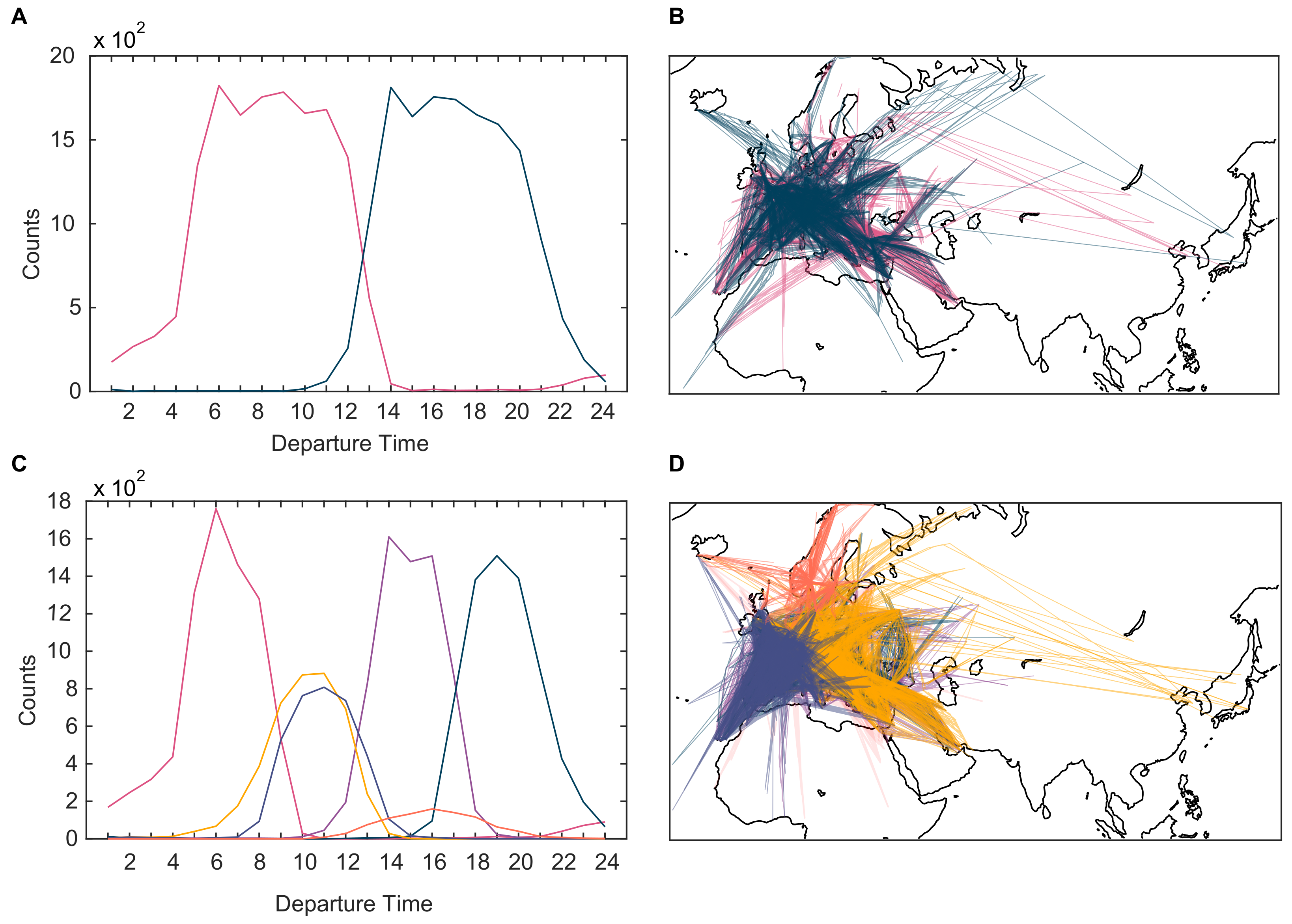
3.2. Temporal and Spatial Analysis of Clusters
3.3. A Trade-Off between the Number of Capacity Violations and the Resolution Time
3.4. Comparison with Actual Capacity Violations
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- EUROCONTROL. Five-Year Forecast 2020–2024. European Flight Movements and Service Units. Three Scenarios for Recovery from COVID-19. 2020. Available online: https://www.eurocontrol.int/sites/default/files/2020-11/eurocontrol-five-year-forecast-europe-2020-2024.pdf (accessed on 6 August 2021).
- EUROCONTROL. Performance Review Report. An Assessment of Air Traffic Management in Europe during the Calendar Year 2019. 2020. Available online: https://www.eurocontrol.int/publication/performance-review-report-prr-2019 (accessed on 6 August 2021).
- EUROCONTROL. ATM Cost-Effectiveness (ACE) 2019 Benchmarking Report with Special Focus on COVID-19 Impacts in 2020. 2021. Available online: https://www.eurocontrol.int/sites/default/files/2021-05/eurocontrol-ace-2019-benchmarking-report-special-focus-covid-19-impact-2020.pdf (accessed on 6 August 2021).
- European Aviation Environmental Report. 2019. Available online: https://ec.europa.eu/transport/sites/default/files/2019-aviation-environmental-report.pdf (accessed on 6 August 2021).
- Delgado, L. European route choice determinants. In Proceedings of the 11th USA/Europe Air Traffic Management Research and Development Seminar, Lisbon, Portugal, 23–26 June 2015. [Google Scholar]
- Ngo, D.; Shamoun, F. Environmental Cost of Different Unit Rates. Master’s Thesis, Linköping University, Linköping, Sweden, 2016. [Google Scholar]
- Bolić, T.; Castelli, L.; Rigonat, D. Peak-load pricing for the European Air Traffic Management system using modulation of en-route charges. EJTIR 2017, 1, 136–152. [Google Scholar]
- Verbeek, R.J.; Visser, H.G. Why aircraft will fly more fuel-efficiently on FRIDAY: The FRIDAY route charges method. In Proceedings of the 7th International Conference on Research in Air Transportation, Philadelphia, PA, USA, 20–24 June 2016. [Google Scholar]
- Bertsimas, D.; Lulli, G.; Odoni, A. An integer optimization approach to large-scale air traffic flow management. Oper. Res. 2011, 59, 211–227. [Google Scholar] [CrossRef]
- Sherali, H.D.; Hill, J.M.; McCrea, M.V.; Trani, A.A. Integrating Slot Exchange, Safety, Capacity, and Equity Mechanisms Within an Airspace Flow Program. Transp. Sci. 2011, 45, 271–284. [Google Scholar] [CrossRef]
- Castelli, L.; Corolli, L.; Lulli, G. Critical Flights Detected with Time Windows. Transp. Res. Rec. 2011, 2214, 103–110. [Google Scholar] [CrossRef]
- Agustín, A.; Alonso-Ayuso, A.; Escudero, L.; Pizzaro, C. On air traffic flow management with rerouting. Part I: Deterministic case. Eur. J. Oper. Res. 2012, 219, 156–166. [Google Scholar] [CrossRef]
- Barnhart, C.; Bertsimas, D.; Caramanis, C.; Fearing, D. Equitable and Efficient Coordination in Traffic Flow Management. Transp. Sci. 2012, 46, 262–280. [Google Scholar] [CrossRef] [Green Version]
- Bertsimas, D.; Gupta, S. Fairness and Collaboration in Network Air Traffic Flow Management: An Optimization Approach. Transp. Sci. 2015, 50, 56–76. [Google Scholar] [CrossRef]
- Xu, Y.; Dalmau, R.; Melgosa, M.; Montlaur, A.; Prats, X. A framework for collaborative air traffic flow management minimizing costs for airspace users: Enabling trajectory options and flexible pre-tactical delay management. Transp. Res. Part B Methodol. 2020, 134, 229–255. [Google Scholar] [CrossRef]
- Xu, Y.; Prats, X.; Delahaye, D. Synchronised demand-capacity balancing in collaborative air traffic flow management. Transp. Res. Part C Emerg. Technol. 2020, 114, 359–376. [Google Scholar] [CrossRef] [Green Version]
- Ivanov, N.; Jovanović, R.; Fichert, F.; Strauss, A.; Starita, S.; Babić, O.; Pavlović, G. Coordinated capacity and demand management in a redesigned Air Traffic Management value-chain. J. Air Transp. Manag. 2019, 75, 139–152. [Google Scholar] [CrossRef]
- Starita, S.; Strauss, A.K.; Fei, X.; Jovanović, R.; Ivanov, N.; Pavlović, G.; Fichert, F. Air Traffic Control Capacity Planning under Demand and Capacity Provision Uncertainty. Transp. Sci. 2020, 54, 882–896. [Google Scholar] [CrossRef]
- Cook, A.; Blom, H.A.; Lillo, F.; Mantegna, R.N.; Miccichè, S.; Rivas, D.; Vázquez, R.; Zanin, M. Applying complexity science to air traffic management. J. Air Transp. Manag. 2015, 42, 149–158. [Google Scholar] [CrossRef] [Green Version]
- Rocha, L.E. Dynamics of air transport networks: A review from a complex systems perspective. Chin. J. Aeronaut. 2017, 30, 469–478. [Google Scholar] [CrossRef]
- Fleurquin, P.; Ramasco, J.J.; Eguiluz, V.M. Systemic delay propagation in the US airport network. Sci. Rep. 2013, 3, 1159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gegov, E.; Postorino, M.N.; Atherton, M.; Gobet, F. Community structure detection in the evolution of the United States airport network. Adv. Complex Syst. 2013, 16, 1350003. [Google Scholar] [CrossRef]
- Gurtner, G.; Vitali, S.; Cipolla, M.; Lillo, F.; Mantegna, R.N.; Miccichè, S.; Pozzi, S. Multi-Scale Analysis of the European Airspace Using Network Community Detection. PLoS ONE 2014, 9, e94414. [Google Scholar] [CrossRef] [Green Version]
- Zaoli, S.; Mazzarisi, P.; Lillo, F. Trip Centrality: Walking on a temporal multiplex with non-instantaneous link travel time. Sci. Rep. 2019, 9, 10570. [Google Scholar] [CrossRef]
- Bolić, T.; Castelli, L.; Corolli, L.; Rigonat, D. Reducing ATFM delays through Strategic Flight Planning. Transp. Res. Part E 2017, 98, 42–59. [Google Scholar] [CrossRef] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Rosvall, M.; Bergstrom, C.T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [Green Version]
- Rand, W.M. Objective Criteria for the Evaluation of Clustering Methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Entropy, Relative Entropy, and Mutual Information. In Elements of Information Theory; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005; Chapter 2; pp. 13–55. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Vinh, N.X.; Epps, J.; Bailey, J. Information Theoretic Measures for Clusterings Comparison: Variants, Properties, Normalization and Correction for Chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- IATA. Worldwide Slot Guidelines, 10th ed.; IATA: Montreal, QC, Canada, 2019; Available online: https://www.iata.org/contentassets/4ede2aabfcc14a55919e468054d714fe/wsg-edition-10-english-version.pdf (accessed on 6 August 2021).
- Ribeiro, N.A.; Jacquillat, A.; Antunes, A.P.; Odoni, A.R.; Pita, J.P. An optimization approach for airport slot allocation under IATA guidelines. Transp. Res. Part B Methodol. 2018, 112, 132–156. [Google Scholar] [CrossRef]
- Pellegrini, P.; Bolić, T.; Castelli, L.; Pesenti, R. SOSTA: An effective model for the Simultaneous Optimisation of airport SloT Allocation. Transp. Res. Part E Logist. Transp. Rev. 2017, 99, 34–53. [Google Scholar] [CrossRef] [Green Version]
- Benlic, U. Heuristic search for allocation of slots at network level. Transp. Res. Part C Emerg. Technol. 2018, 86, 488–509. [Google Scholar] [CrossRef]
- Wang, D.; Zhao, Q. A simultaneous optimization model for airport network slot allocation under uncertain capacity. Sustainability 2020, 12, 5512. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaoli, S.; Scaini, G.; Castelli, L. Community Detection for Air Traffic Networks and Its Application in Strategic Flight Planning. Sustainability 2021, 13, 8924. https://doi.org/10.3390/su13168924
Zaoli S, Scaini G, Castelli L. Community Detection for Air Traffic Networks and Its Application in Strategic Flight Planning. Sustainability. 2021; 13(16):8924. https://doi.org/10.3390/su13168924
Chicago/Turabian StyleZaoli, Silvia, Giovanni Scaini, and Lorenzo Castelli. 2021. "Community Detection for Air Traffic Networks and Its Application in Strategic Flight Planning" Sustainability 13, no. 16: 8924. https://doi.org/10.3390/su13168924