1. Introduction
An expeditious rise in the development of network and communication technologies leads to an immense amount of network data generated from a wide range of services. For instance, pervasive computing networks such as the Internet of Things (IoT) generate enormous data [
1,
2,
3]. A wide range of network applications is developed in every domain of life, including business, healthcare, smart homes, and smart cities, to name a few [
4,
5,
6,
7]. The plethora of high-dimensional data increases the need for analysis tools based on advanced data mining and statistical methods [
8,
9]. There is a dire need to tune the contemporary data mining and statistical methods to address the challenges of the growing internet applications, such as bandwidth handling, network intrusion detection, and scalability. Network applications and resources’ security using intrusion detection systems, intrusion prevention systems, and hybrid systems are becoming more challenging due to the enormous number of diverse networking applications. However, the rule-based approach for the analysis of enormous data has many limitations. The existing state-of-the-art intrusion detection-based systems focus on increasing the reliability aspect of these applications [
10]. An efficient intrusion detection system can strengthen the defense system of such applications against anomalies and network intrusion attacks. The intrusion detection system also provides real-time analysis of the collected critical reconnaissance data during defensive attacks. Intrusion detection systems based on artificial intelligence(AI) hold a significant potential to enhance the performance of detection mechanisms by learning from historical data and real-time data patterns.
Scientific community has presented various machine learning-based intrusion detection systems such as support vector machine (SVM) [
11], Naive Bayes (NBs) [
12], clustering [
13], artificial neural network (ANN), and deep learning network (DNN) [
14]. Conventional machine learning algorithms can better classify small and low dimension datasets. However, the classification accuracy of these algorithms deteriorates when it comes to addressing problems involving high dimensionality and nonlinearity. Hence, the need for intrusion detection models to address the classification accuracy problem increases as AI advances. For example, a convolutional neural network (CNN) [
15] and long short-term memory (LSTM) [
16] have been applied in natural language processing (NLP) and computer vision applications. The problem with deep learning techniques such as CNN and LSTM is adaptability to nonlinear and high-dimensional data. The issue of nonlinearity has been addressed in CNN and LSTM for modeling nonlinear systems [
17,
18,
19,
20,
21,
22]. In literature, the issues of high dimensional data are handled in CNN, and LSTM using a deep learning paradigm [
23,
24,
25,
26]. Automated machine learning (autoML) is a newly emerged subfield of machine learning and data science. The feasible adaptability of autoML makes it equally useful for trainees of machine learning, data scientists, and machine learning engineers. Research articles demonstrate that autoML can revolutionize constructing machine learning models without machine learning expertise and knowing technical specifications. AutoML architectures produce a code pipeline by suggesting and selecting a model from a list of machine learning model-based input datasets [
27]. The selection is performed based on the accuracy of these machine learning models. AutoML results in coding the pipeline of the best performing model, which will be very difficult to find using manual configurations of the models’ parameters.
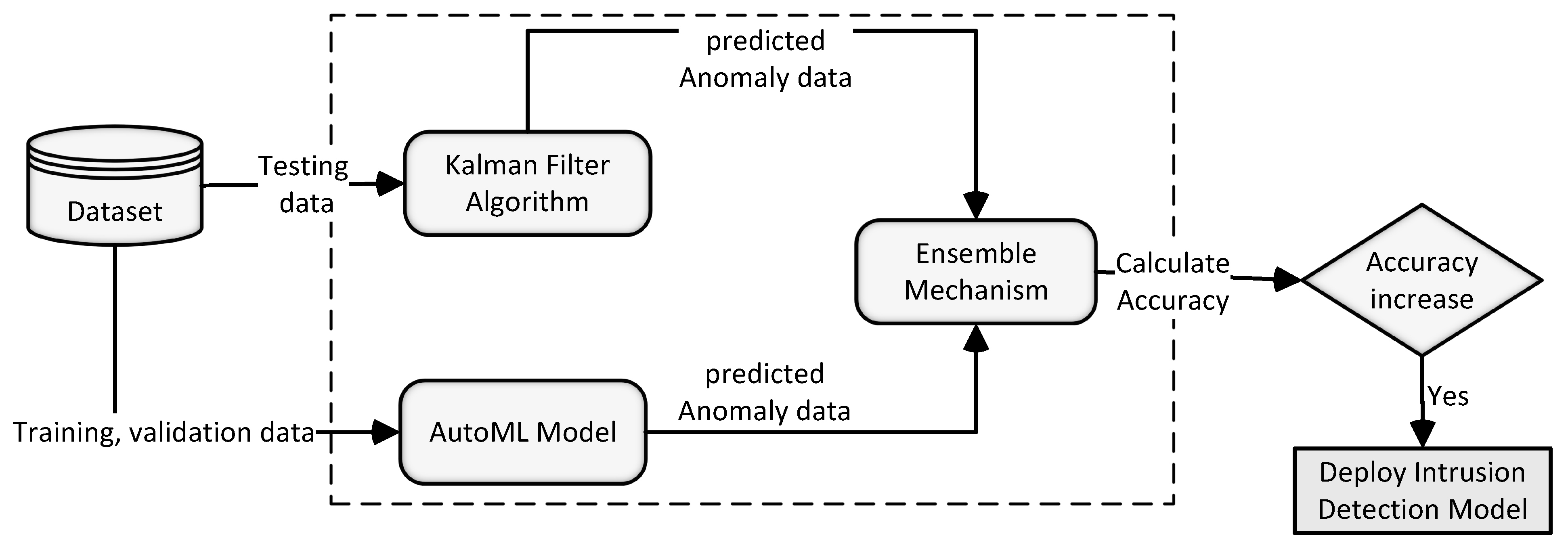
This paper presents an intrusion detection system based on the ensemble of prediction and learning mechanisms to improve intrusion detection accuracy. The conceptual design of the proposed ensemble intrusion detection model for improving the performance accuracy of anomaly detection is envisioned in
Figure 1. The proposed learning mechanism is based on autoML [
28], and the prediction mechanism is based on Kalman filter [
29]. First, the automated neural architecture search paradigm of autoML improves the accuracy of the learning model using parameters optimization. Then, the optimal DNN (o-DNN) model pipeline is created from an autoML based learning mechanism. Next, an optimal Kalman filter-based intrusion detection system is produced using measuring and updating errors. Finally, the o-DNN and Kalman filter are utilized to develop the ensemble intrusion detection model based on the weighted voting mechanism.
The proposed ensemble-based intrusion detection model is selected based on accuracy comparison with DNN and Kalman filter-based intrusion detection models. If the accuracy of intrusion detection is improved using the proposed ensemble approach, it is deployed as an intrusion detection model in a network intrusion environment.
The main contributions of this paper are as follows:
Design of ensemble mechanism based on learning and prediction models.
Implementation of ensemble model based intrusion detection system for improving the detection accuracy.
Case studies based on benchmarks’ intrusion detection datasets.
The case studies based on intrusion detection datasets are used to assess the proposed ensemble mechanism for intrusion detection environments. The performance of the proposed model is compared with some contemporary models, including DNN, autoML, and other algorithms from the literature on these benchmark datasets. The case studies are evaluated using benchmark datasets UNSW-NB15 and CICIDS2017.
The rest of the paper is organized as follows: a brief literature review is presented in
Section 2.
Section 3 presents the methodology for the proposed intrusion detection system. Experimental results are discussed in
Section 4.
Section 5 presents performance analysis and significance of the study. Finally, the conclusion and future work directions is presented in
Section 6.
2. Related Work
Artificial intelligence is taking over the current era and is changing the current era into a revolutionary practical world. Data analysis, predictive analytics and optimization models are used for many real-life applications [
30,
31,
32]. Anomaly detection is a type of data analysis used to identify irregular and abnormal data from a given data set. Anomaly detection is the approach used in data mining applications for discovering and finding patterns inside the data [
33]. It is also used as a standalone module in many studies related to machine learning and statistics applications. Deviation detection, outlier detection, and exception mining are related terms used for anomaly detection [
34]. Narayana et al. defined anomaly as a mechanism generated from the deviation of several observations [
35]. Anomaly detection is used in several scientific domains such as healthcare, intrusion detection, sensor network, and fraud detection, to name a few. Detecting irregularities in the network, identifying anomalies in financial transactions, detecting fraudulent activities, and detecting anomalies in medical images are some anomaly detection applications [
36]. In networks, anomaly patterns can be identified based on the classification of packet data containing abnormal patterns.
Xie et al. published a survey study related to intrusion detection in wireless sensor networks [
37]. According to most of the studies, intrusion detection depends on the communication medium; for example, wired connection-based techniques cannot be applied to the wireless communication medium. The survey emphasizes the need for standard anomaly detection techniques for all types of networks. One challenge for detecting anomalies in the network is the lack of a comprehensive dataset. Most of the current anomaly detection systems are based on supervised approaches that use labeled data knowledge. During the past few years, research has been conducted in network intrusion detection segregated into audit source, network behavior, detection method, location, frequency of usage, and detection method. In [
38], Debar et al. presented a standard technique based on the extension of transaction-based detection paradigm. Axelsson et al. [
39] proposed a study based on detection principle and focus on operational aspects. Furnell et al. [
40] proposed an intrusion matrix based on the data scale and output type. Estevez-Tapiador et al. presented a wired-based network intrusion detection based on anomaly detection [
41]. Boukerche et al. presented an outlier-based classified detection approach using the unsupervised and supervised models [
42]. Under the supervised category, a proximity-based technique has been used recently [
43].
Chandola et al. also presented another detailed survey study on anomaly detection [
44]. Their study presents different techniques related to intrusion detections. Some studies proposed several anomaly detection techniques based on supervised, unsupervised, and clustering methods [
45,
46,
47,
48,
49]. The lack of discussion and research problems in the available datasets are one of the research gaps that need to be addressed. The most used datasets for network anomaly detection are the DARPA/KDD, which developed in 2013. Various variants of datasets are developed based on this dataset to address the causes of data errors and inconsistency. As network anomaly detection based on the aforementioned dataset has no significant performance improvements; therefore, more anomaly detection datasets have been introduced recently to improve intrusion detection system efficiency. Some research surveys focused on these dataset issues and challenges to develop an efficient intrusion detection system [
50]. The network attack profile feature relies on classification-based techniques and the size of the data [
51]. The intrusion detection system process is based on the signature of the attack and the capability of intrusion detection system to detect the attack from data patterns [
52]. The intrusion detection engine can also enhance the defense system using intelligent mechanisms for various attacks’ variants. This process is quite expensive for creating a new attack in case of loss or replacement [
53]. Furthermore, the regular traffic does not contain the knowledge base attack, and it will be raising the wrong alarms.
In summary, anomaly detection mechanisms are costly in terms of time and are relying on the existing network traffic dataset. Furthermore, keeping the standard profile up-to-date is very difficult in today’s network. The network traffic analysis dataset does not have easy access due to privacy limitations. Examples of benchmark datasets for intrusion detection are DARPA/KDD, UNSW-NB15, CICIDS2017, and CSE-CIC-IDS2018 [
54]. The main challenge that needs to be addressed is improving intrusion detection systems’ accuracy on these benchmarks’ datasets.
Table 1 presents a summary of existing intrusion detection and prevention systems organized as applications, datasets, models, and relative demerits.
3. Materials and Methods
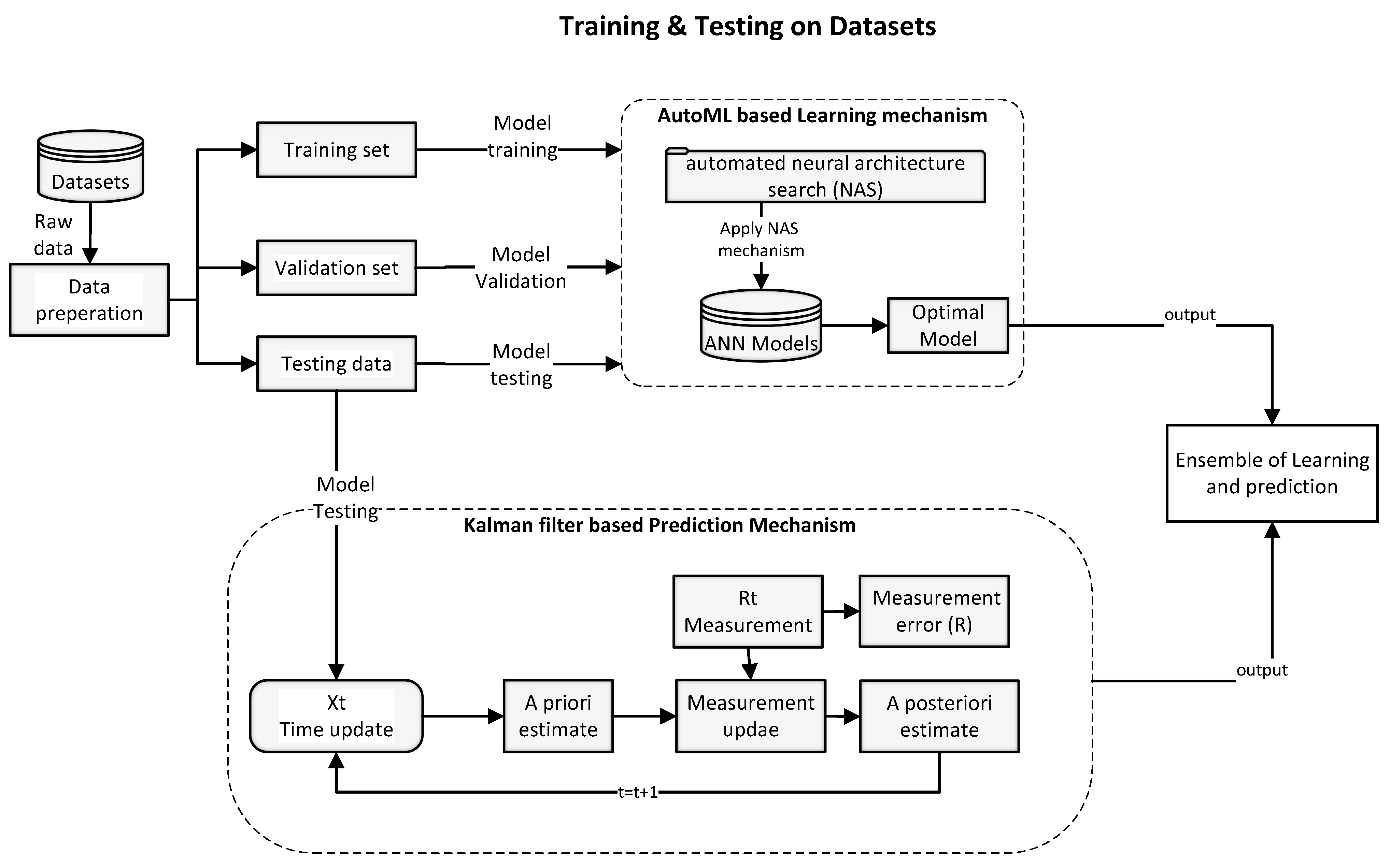
This section presents the design of the proposed ensemble mechanism-based intrusion detection methodology. The datasets and methods used for data preparation are briefly discussed. The intrusion detection system is based on the ensemble of learning and prediction models. The main aim of the proposed ensemble mechanism-based intrusion detection system is to improve the accuracy of intrusion detection. The proposed intrusion detection system has two main phases. The first phase is training, and the second phase is deployment in an intrusion detection environment. The first phase of the methodology for the ensemble intrusion detection model based on comprehensive datasets is shown in
Figure 2. Two comprehensive benchmark datasets are prepared using feature engineering techniques to assess the performance of the proposed ensemble model. The data are prepared and split into training, validation, and testing datasets for the training, testing, and validation of the proposed intrusion detection model.
The autoML based learning mechanism utilizes automated neural architecture search to obtain O-DNN using hyperparameter optimization, and accuracy metric. We used the Bayesian optimization (BayesOpt) method for hyperparameter optimization. Auto-kreas uses BayesOpt as an optimization method for neural network architecture search(NAS). BayesOpt has a sequential procedure for global optimization of black-box functions. The BayesOpt requires a dataset prepared for machine learning models and defined search space. The search space is based on a large set of neural network architectures. The search space consists of architectural parameters such as the number of layers, activation functions, and density. The next step involves defining an objective function that aims to search for architectural parameters to improve the training and testing accuracy. Edit distance function is used to find the distance between architectures. Let f(accuracy) be the objective function for maximizing the accuracy. The goal of the BayesOpt mechanism is to find a deep learning architecture D ∈ set of architectures list, which maximizes f(accuracy). The Kalman filter model is used for intrusion detection, and its parameters are tuned to improve the accuracy. For instance, the final R parameter value of the Kalman filter is selected based on the average of R values which performs better for both comprehensive datasets. The ensemble model is based on the O-DNN model and the Kalman filter. The ensemble model is based on the weighted voting mechanism. The predictions of both learning and prediction mechanisms are weighted based on their average prediction accuracy.
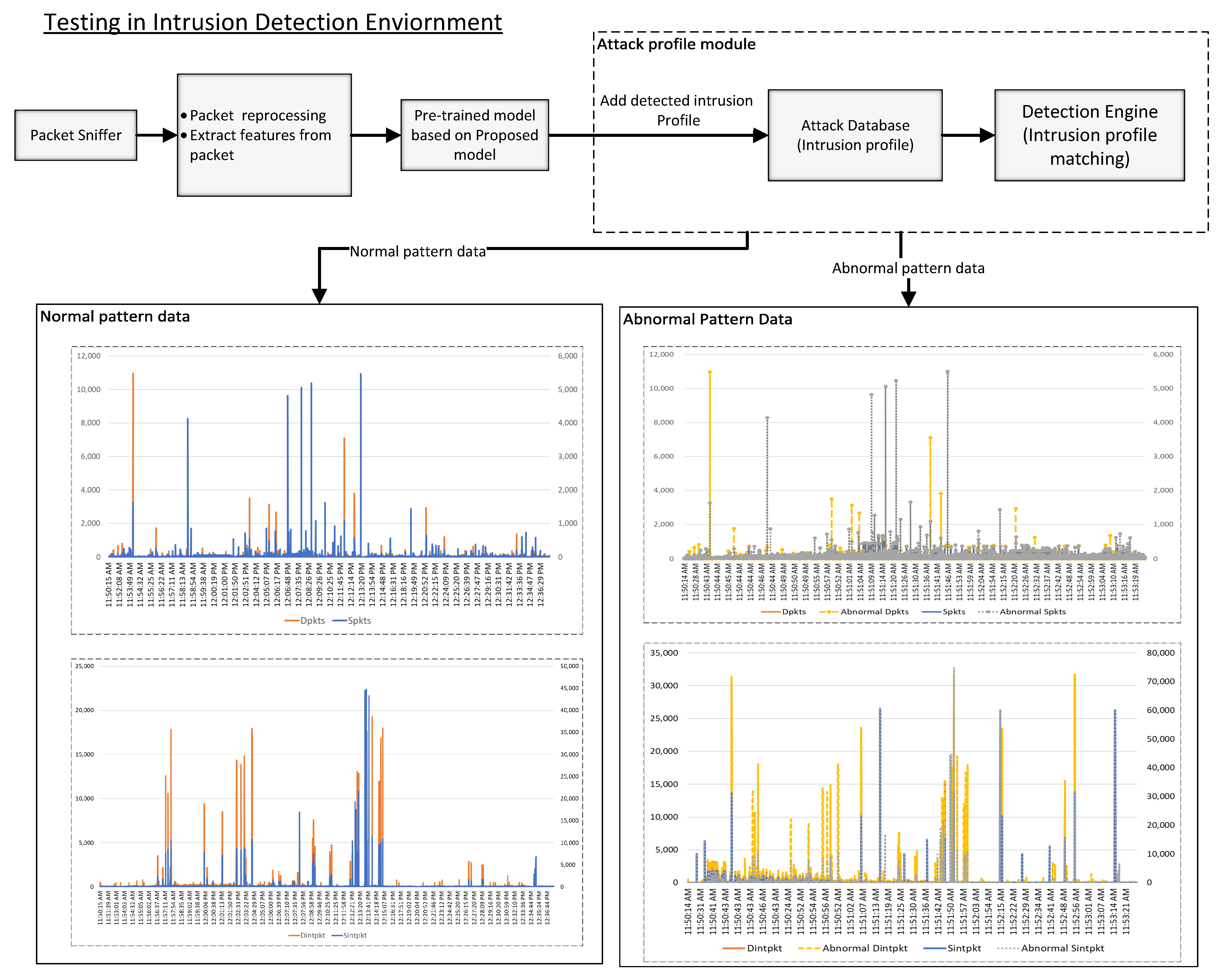
The second phase of the methodology is testing the proposed ensemble model for the intrusion detection system.
Figure 3 presents the testing of the proposed intrusion detection system based on the ensemble model in the intrusion detection environment.
The pre-trained model based on the ensemble mechanism is deployed in a networking environment to predict anomalies in the network data. For network capturing and pre-processing, a Raspberry Pi based capturing probe is used. The extracted data profile is given as an input to the ensemble model to analyze the data pattern for intrusions. If the input packet pattern is abnormal and matches the signatures in the intrusion detection engine, the packet is dropped. Suppose that the abnormal pattern signature is not present in the intrusion detection engine. In that case, the database is updated with the new signature, and the packet is dropped. In summary, the intrusion detection system based on the proposed ensemble model analyzes the packet for intrusion data patterns.
Datasets
An intrusion detection system is evaluated based on their performance analysis of comprehensive labeled data of normal and abnormal behavior to identify types of network attacks [
68]. UNSWNB15 and CICIDS2017 pp. datasets previously used for network intrusion detection [
69]. Older data sets such as KDD CUP 99 [
70] and NSL KDD [
71] have been widely used for evaluating performance of the intrusion detection system. Studies [
72,
73,
74], evaluating intrusion detection system using these data sets do not reflect realistic output performance. The KDD CUP 99 data set contains an enormous amount of redundant data; therefore, it has been improved to obtain the NSL KDD dataset. As the NSL KDD dataset is not comprehensive, the comprehensive dataset of UNSWNB15 is prepared in the cyber range lab of the Australian center for cybersecurity. UNSW-NB15 represents nine types of attacks obtained through the IXIA PerfectStorm tool. The dataset contains 49 features developed using Bro-IDS and Argus tools. These datasets contain a limited number of network attacks and outdated information about packets. The training dataset contains 175,341 data instances, whereas the testing dataset contains 82,332 normal and attack data instances.
Table 2 presents data distribution from the UNSW-NB15 dataset based on the types of data. The issues of the UNSW-NB15 dataset are addressed in the CICIDS2017 dataset.
The CICIDS2017 dataset, on the other hand, is one of the updated intrusion detection systems’ datasets. It contains benign, and seven general network flows’ attacks. The dataset has been used to evaluate the performance of machine learning models on a set of networking traffic data features for anomaly detection. In the paper, the analysis of the CICIDS2017 shows that random forest outperforms other algorithms [
75].
Table 3 presents a summary of the features of CICIDS2017.
As part of data pre-processing, dataset features are transformed and normalized. Categorical features such as attack types are converted into numerical values using one-hot-encoding. Data features with large values are normalized. The intrusion detection datasets contain many redundant data records, which causes biasness toward the many data records [
76]. Furthermore, missing data records are also reasons for changing the characteristics of the data [
77]. Hence, datasets are improved to solve data issues such as unbalancing between normal and abnormal data records and the missing values [
78]. Therefore, data features with irrelevant and redundant data are eliminated, and necessary features are selected. For feature selection, the univariate feature selection technique with analysis of a variance (ANOVA) F-test is used [
79,
80]. An ANOVA f-test is used to analyze to determine x individual performance of all the features and strength of the relationship between the data feature and label features of the dataset. Sklearn library-based Select Percentile is used to select features based on the highest scores percentile. After selecting the subset of the features, the recursive feature elimination technique is applied to eliminate the irrelevant features. After the dataset is prepared, a model based on the ensemble of learning and prediction mechanism is trained and evaluated using the training and validation dataset. The pre-trained model of the ensemble of learning and prediction mechanism is used as an intrusion detection system model in the intrusion detection environment for improving the security of the environment against any malicious traffic. In recent network applications, such as the IoT paradigm-based cloud system, the system transmits data between the cloud and end-user through the IoT gateway. This gateway is an important location for deploying the intrusion detection system based on the proposed ensemble model. Like traditional IDSs, the proposed anomaly detection system uses a set of principal components: a sniffing unit that sniffs packets from the traffic and analyzes them and an intrusion database engine that stores rules and attack profiles. Response units drop the packet with anomalous attack patterns or maintain the traffic if regular. The analyzer unit is a critical component where the data processing techniques are applied on the packet, and detection models are deployed. An enormous amount of network data can be extracted from packets, so pre-processing the data is critical and requires more processing power and resources.
As explained earlier in the datasets, basic features are extracted for the data flow. Furthermore, the extracted data features are standardized for the pre-trained intrusion detection system model to reduce the data dimensionality problems. Therefore, the analyzer unit helps prevent biases and confusion for the intrusion detection system. The pre-processed data are sent to the intrusion detection model for making the final decision on each data batch. The intrusion detection model detects known and unknown attacks by learning from real-time data and updating the intrusion database engine. If the input data profile does not match the normal network profile stored in the intrusion database, it is classified as an attack. The response unit alerts the system’s administrator with abnormal behavior based on the predicted attack profile. The response unit also updates the new signature of the attack types into the intrusion database engine.
4. Results and Discussion
In this section, the implementation results are discussed. Firstly, we will discuss the implementation environment and the datasets. The implementation environment and software used in the experimentation are illustrated in
Table 4. Four sets of Raspberry Pi devices are utilized for the experimentation. However, two Raspberry Pi devices are enough to evaluate intrusion detection systems in the local area network. The other two Raspberry Pi devices are used for checking the performance of the intrusion detection system in an online environment such as a wide area network. One Raspberry Pi device is used for IoT server configurations that communicate with a PC-based server. The second Raspberry device is used to test the proposed ensemble model in a local area network-based intrusion environment. The third Raspberry Pi is connected to a network switch, where three virtual area networks are configured to make a wide area network. The third Raspberry Pi based intrusion detection testing is implemented to evaluate the performance of the proposed ensemble model for larger networks like workplaces. Finally, the fourth Raspberry Pi is used to create a snort software-based intrusion prevention system for real-time traffic and packet analysis. Normal and abnormal traffic is generated on the PC server and passed to the networking server.
As part of the descriptive analysis, the comprehensive dataset is analyzed using pre-processing techniques. As a result, the prepared datasets are easily interpretable for the proposed intrusion detection model. In addition, descriptive analytics are presented on the intrusion detection datasets to identify attacks and normal traffic data patterns. Finally, the datasets used for the case studies are split into training, test, and validation sets for training, testing, and validation of the proposed intrusion detection system model. To implement NAS, AutoKeras is used. AutoKeras is an autoML framework for deep learning using the Keras library’s APIs. NAS is the process of neural network architecture searching to solve a problem using neural networks efficiently. For instance, an AutoKeras based anomaly detection engine is used to discover optimal classification models on classification datasets.
Table 5 presents some parameters that resulted from the NAS in AutoKeras.
Table 6 presents Kalman filter configurations and prediction accuracy with various sets of R parameter values. For instance, for the UNSW-NB15 dataset, the Kalman filter with an R-value of 15 achieves high accuracy, whereas, for the CICIDS2017 dataset, the Kalman filter with an R-value of 10 achieves high accuracy.
The training, test, and validation split ratio used is 70, 20, and 10 percent, respectively, for both datasets. The ten-fold cross-validation mechanism is used with stratified splits, keeping 20 percent for testing and 80 percent for cross-validation. The averages of the ten folds are used to pick the best model. Statistics of normal and attack data instances in the training, test, and validation sets of the UNSW-NB15 dataset are given in
Table 7. In the training set, there are 1,014,221 normal training data records and 157,748 attack data records. In the testing set, there are 289,777 normal testing data records and 45,071 attack data records. In the validation set, there are 144,889 normal validation data records and 22,535 attack data records.
Statistics of normal and attack data instances in the training, test, and validation sets of the CICIDS2017 dataset are given in
Table 8. There are 318,014 normal training data records 7800 attack data records. There are 90,861 normal testing data records and 2229 test set-based attack data records. There are 45,431 normal validation data records and 1114 validation set-based attack data records.
The attack data of the UNSW-NB15 dataset comprises nine types: analysis, fuzzers, shellcode, reconnaissance, generic, backdoor, doS, and exploits. Statistics of these attack data in training, test, and validation datasets are given in
Table 9.
CICIDS2017 dataset’s data imbalance issue is addressed by introducing new labeling attack types. The newly labeled attack data of the CICIDS2017 dataset is comprised of six types: bot, brute force, infiltration, DoS/DDoS, web attack, and port scan. Statistics of these attack data in training, testing, and validation sets are given in
Table 10.
Before performing correlation analysis, feature engineering techniques are applied to the dataset, including analysis of feature types such as finding continuous, categorical, date, and features with text. The dataset is transformed by encoding categorical features using one-hot-encoding (one-of-K) and converting text features to numeric. The mean values of the feature data are used for handling missing values. The performance of machine learning models is good if the data are good. Hence, appropriate pre-processing and cleaning of the data are a significant step. Those features that contribute most to a machine learning model’s performance should be used for training the intrusion detection system model to improve the accuracy of intrusion detection.
Feature selection is a technique used to eliminate features from the dataset that do not solve or contribute to the problem’s solution. For the selection of the features, feature importance and correlation analysis methods are used. Data correlation analysis is used to understand the relationship between the dataset’s features. The association of multiple features with other dataset features is analyzed during correlation analysis. Correlation analysis is used in the literature as an essential technique for feature selection and reduction.
Figure 4 visualizes a heatmap of correlation analysis of the dataset.
The highly correlated features are listed below:
Source to destination packet count (Spkts), source to destination bytes (sbytes), and source packets re-transmitted or dropped (sloss).
Destination to source packet count (Dpkts), destination to source bytes (dbytes), and destination packets re-transmitted or dropped (dloss).
Source inter-packet arrival time (sinpkt), IP address, and port number based on source (is_sm_ips_ports).
Source TCP window advertisement (swin), and destination TCP window advertisement (dwin).
The sum of TCP acknowledgment data features (Tcprtt) and time between SYN and SYN_ACK packet of the TCP (synack).
Connection count with same service and source address (Ct_srv_src), connection count with same service and destination address (ct_srv_dst), connection count of same source and destination address (ct_dst_src_ltm), connection count of the same source address and destination port number (ct_src_dport_ltm), and connection count of the same destination address and source port number (ct_dst_sport_ltm).
Access to ftp session (Is_ftp_login), and (Flows count in ftp session consists of commands(ct_ftp_cmd).
Features such as sloss, dloss, sbytes, and dbytes are dropped because they have a high correlation with spkts and dpkts features. Stcpb and dtcpb are dropped because the range of the TCP base sequence is high (0 to ). However, connections containing anomalies are close to 0. Tcprtt is the round trip time of connection setup and the sum of synack and ackdat features. Tcprtt is dropped because it does not add any extra information to the model. Synack, sload, dload, sjit, djit, and ackdat are dropped because they have not played a role in improving the accuracy of the model.
As explained earlier, the data correlation is used to analyze the relationship between data features. For instance, correlation analysis in machine learning is used to understand the relationship between input data features and output data features. If the machine learning model is trained with a set of data features with little correlation, the results are more likely to be inaccurate [
81,
82,
83]. For example, data features ‘Ct_srv_src’ and ‘ct_srv_dst’ are highly correlated but have poor correlation with the rest of the data features and output feature. Consequently, both ‘Ct_srv_src’ and ‘ct_srv_dst’ are dropped. ‘Dur’ feature is the total duration recorded, ‘Dur’ feature is dropped due to no correlation with the label data feature. The ‘rate’ feature is dropped because it has a value range of up to 1M and anomalous connections are mostly around zero. ‘Sinpkt’ and ‘dinpkt’ are highly correlated, so we dropped ‘dinpkt’ as ‘sinpkt’ has a better correlation with the rest of the data features.
Figure 5 presents the normal and abnormal mean of packet flow size. The mean packet flow size is an essential network measure. Likewise, the flow byte size is a fundamental metric for network measurement. X-axis presents the packet arrival time from the source to destination and vice versa. Y-axis presents comparison of the normal and abnormal mean packet size.
The mean of packet flow size is an essential measure as low-rate distributed denial-of-service is a challenge to network security. In this attack, many attack packets flow similar to regular packet flow is sent to throttle legitimate flows.
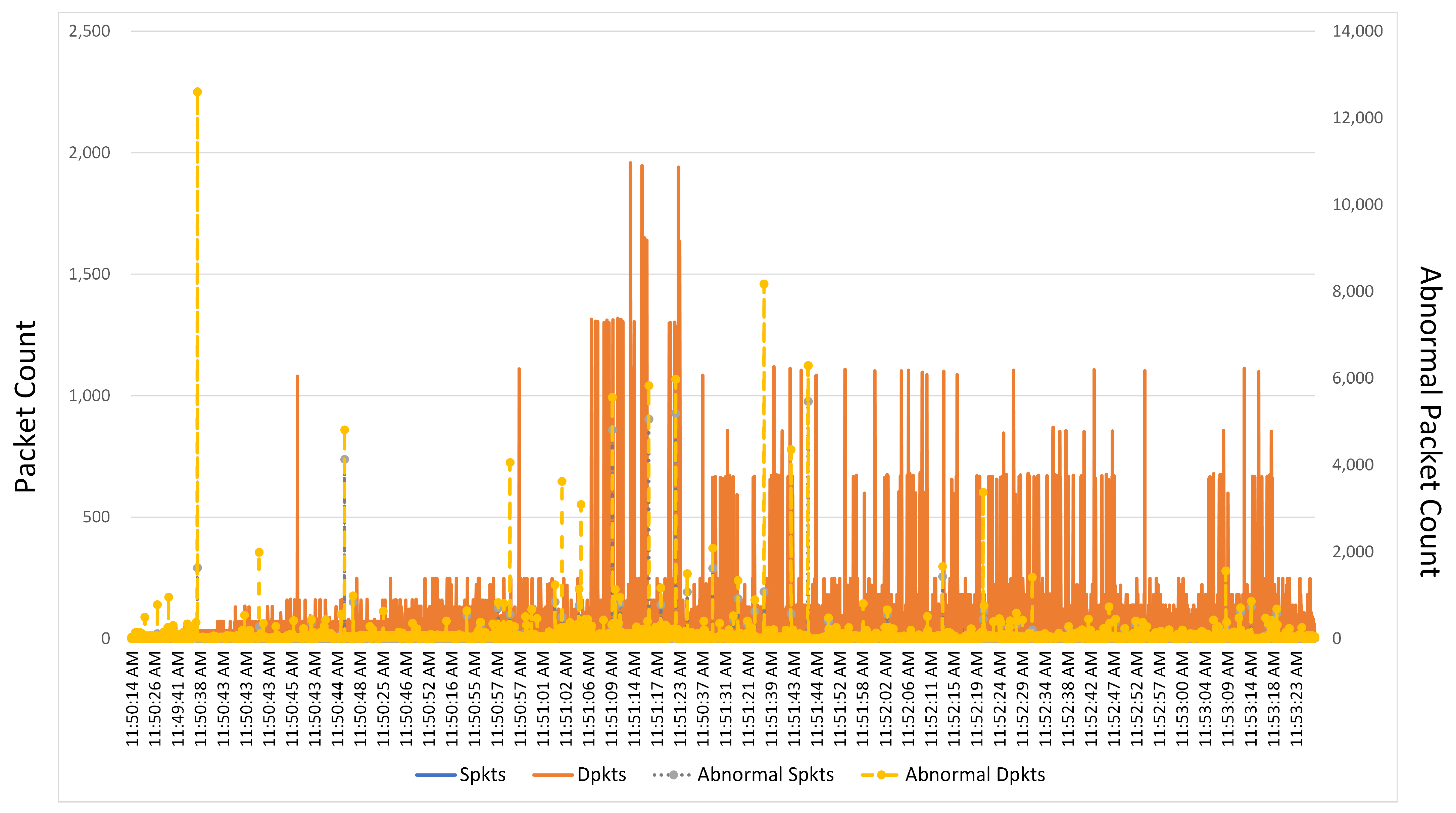
Figure 6 presents a normal and anomalous packet count. The mean packet flow size is an essential network measure. ‘SPKTS’ stands for source to destination packet count, whereas ‘dpkts’ stands for the destination to source packet count. ‘Spkts’ and ‘dpkts’ contain integer values of packet count. The primary axis presents source to destination packet count comparison in terms of normal packet count. The secondary axis presents destination to source packet count comparison in terms of anomalous packet count.
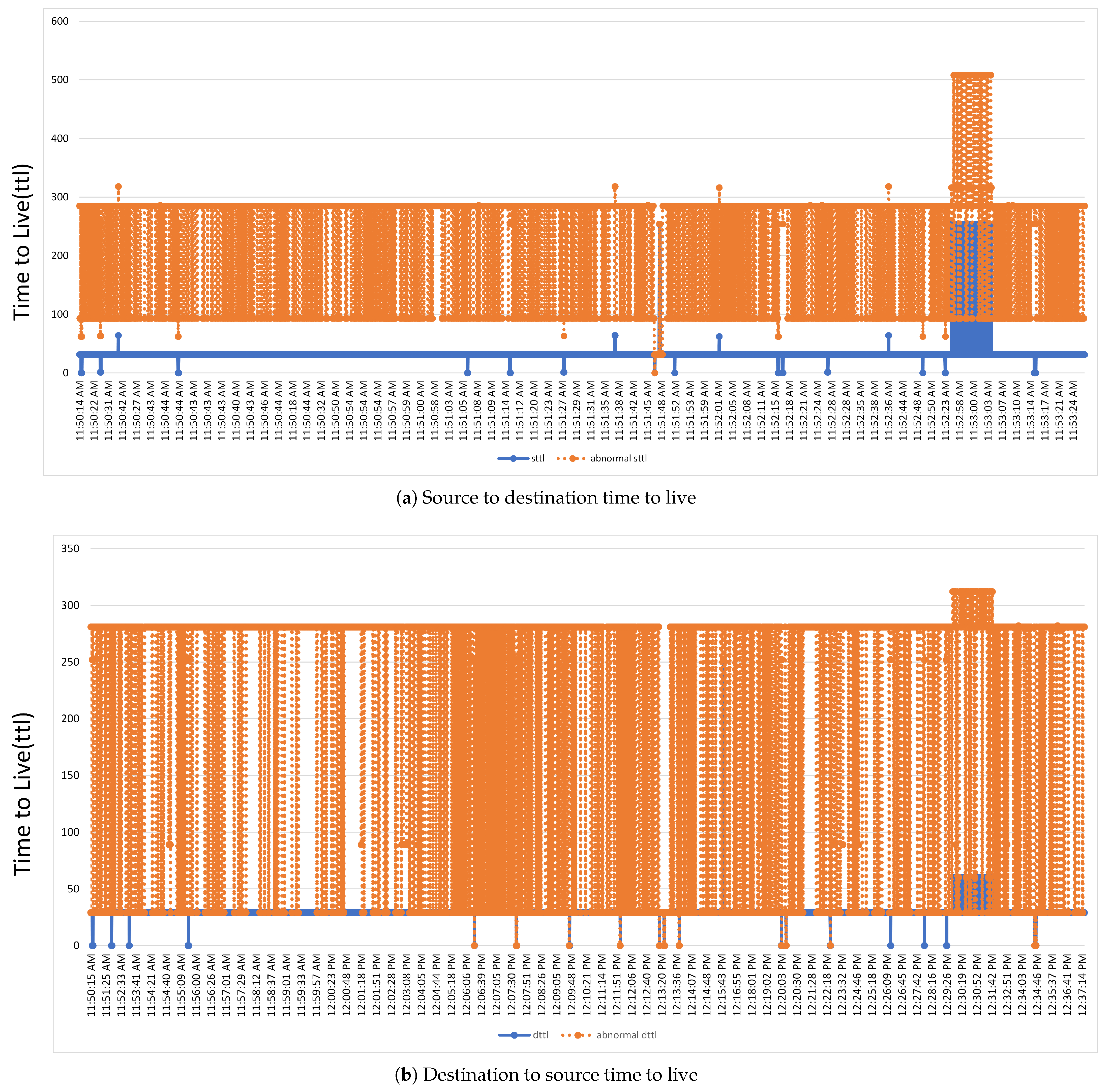
Figure 7 presents normal and anomalous time to live (TTL). TTL, also called hop limit, is a procedure for limiting the lifetime of the data packet in a computer network. TTL is usually implemented as a timestamp or counter mechanism embedded in the data packets.
Figure 7a presents a source to destination time live comparison with anomalous packet time to live.
Figure 7b presents a destination to source time to live comparison with anomalous time to live.
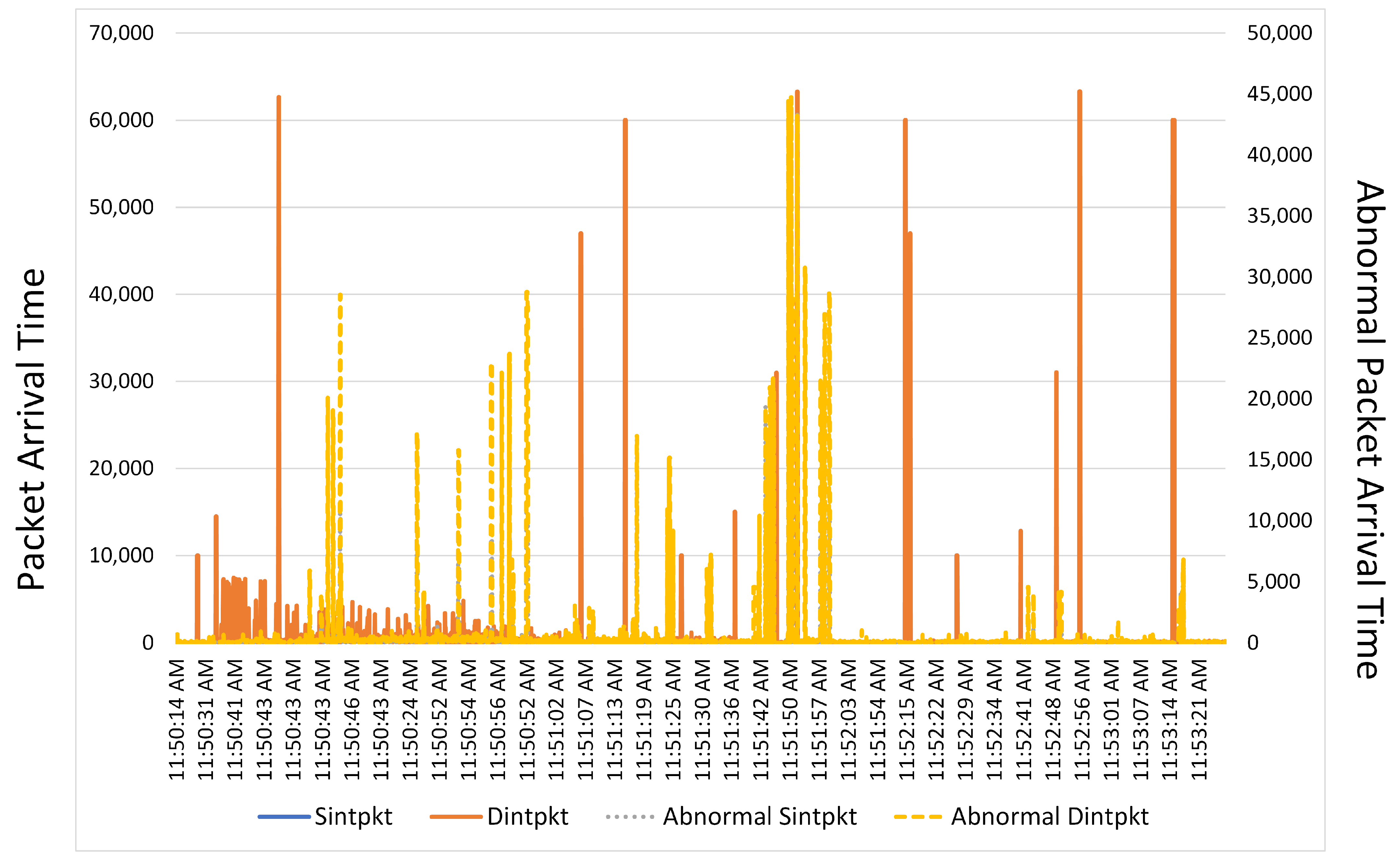
Figure 8 presents normal and anomalous inter-packet arrival time (inpkt). Inpkt is the time taken by a packet to arrive on the host node over a period. It is also known as a delay. ‘Sintpkt’ is the source interpacket arrival time in milliseconds, whereas ‘dintpkt’ is the destination interpacket arrival time in milliseconds. ‘Sintpkt’ and ‘dintpkt’ features contain float values of inter-packet arrival. The primary axis presents source and destination normal inter-packet arrival. The secondary axis presents abnormal source and destination inter-packet arrival.
5. Performance Analysis and Discussion
This section presents the comparative performance analysis of the proposed ensemble model-based intrusion detection system and state-of-the-art intrusion detection models. Classification metrics such as accuracy, detection rate, false alarm rate, and F1 score are used for the evaluation of the models. First, we discuss the classification metrics used for evaluation and then present the comparison of the performance analysis. The comparison of the performance analysis is made in two stages. The first stage of the comparison is based on the state-of-the-art machine learning models implemented during this study. The second stage is the comparison of the performance analysis with state-of-the-art intrusion detection models from the literature. Now, we discuss the classification metrics along with their mathematical representation.
Accuracy is the percentage of correctly classified anomalies among sets of network data samples. Detection rate is the ratio of positively identified intrusion samples detected correctly [
84]. An anomalies detection rate is calculated using Equation (
1):
False alarm rate is the ratio of negative identified intrusion samples, which are identified as positive ones [
85]. The false alarm rate of anomalies is calculated using Equation (
2):
F1 score is used to calculate the average of precision and recall. The confusion metric is the mathematical matrix used for all these performance measures. Equation (
3) presents the formula for the calculation of the accuracy of classification models [
86]:
F1 score is defined as the weighted average or harmonic mean of precision and recall metrics values [
87]. The F1 score value is between zero and one. The F1 score presents the precision of a classification model. High precision and lower recall lead to high accuracy but are inefficient for large data instances. Therefore, classification models with more excellent F1 scores are better and vice versa. Equation (
4) presents the F1 score:
The precision of a detection system based on supervised machine learning is given in Equation (
5). Thus, the intrusion detection model’s precision is the number of correct anomaly prediction results divided by the total number of anomaly prediction results:
A recall is the number of correct predicted anomalies divided by the number of total samples of an intrusion detection identified anomalies. The recall is given in Equation (
6):
Performance analysis of the proposed intrusion detection system model is compared with state-of-the-art machine learning-based intrusion detection systems from the literature and models implemented during the experimentation. Most of the classification models consider accuracy as the main measuring metric. Despite this, we also compared the proposed intrusion detection model performance with literature on the same datasets and implemented state-of-the-art models using detection rate and F1 score.
Table 11 presents a performance comparison of the proposed intrusion detection system model with DNN, and AutoML for the UNSW-NB15 dataset.
Table 12 presents a performance comparison of the proposed intrusion detection system model on the CICIDS2017 dataset. The proposed intrusion detection system model has identified anomalies with an accuracy of 98.801 percent and F1 score of 98.76 percent on the UNSW-NB15 dataset. The intrusion detection system model based on DNN with one layer performs better than the five variants of DNN models implemented in this study.
The DNN model-based intrusion detection with one layer performs better than the other versions of DNN in terms of classification accuracy and F1 score. The DNN with two layers performs better in terms of detection rate as compared to other variants of the DNN. The proposed intrusion detection model classified anomalies with 97.02 percent accuracy and the F1 score of 96 percent on the CICIDS2017 dataset. In summary, an intrusion detection system based on one layer performs better than the five variants of the implemented DNN.
Significance and Comparison
This section presents the significance and comparison of the proposed ensemble model. The comparison of the proposed ensemble mechanism-based intrusion detection system with the existing state-of-the-art models shows the significance of the proposed intrusion detection model. The performance results of the proposed intrusion detection model with existing models are compared in terms of accuracy, detection rate, false alarm rate, and F1 score. The performance results presented in
Table 13 show that the proposed ensemble model for the intrusion detection model significantly improves the intrusion detection accuracy, detection rate, and F1 score. The accuracy of the proposed ensemble model-based intrusion detection system is 98.801, the detection rate is 97.92 percent, and the F1 score is 98.76. SGM-CNN, a CNN model with synthetic minority over-sampling technique(SMOTE) and Gaussian mixture, is used to develop intrusion detection which performs better than the rest of the intrusion detection models. The accuracy, detection rate, and F1 score of the SGM-CNN are 96.54, 96.54, and 97.26, respectively. The SCM3 + RF model is an ensemble approach for intrusion detection based on the subset combination method (SCM). SCM3 is used to produce the final subset by selecting data features from two subsets SCM1 and SCM2. The intrusion detection is based on the random forest (RF) model. The ensemble model of SCM3 and RF achieved an accuracy of 95.87, the detection rate of 97.80, and a false alarm rate of 7.70.
Table 13 presents significant improvement in the accuracy, detection rate, and F1 score of the intrusion detection model compared to existing intrusion detection models.
In short, the main contribution of this study is to improve the accuracy of the intrusion detection model. The improvement in detection accuracy is evident from the comparative analysis of the proposed intrusion detection system with state-of-the-art models developed during the case study and with existing intrusion detection models from the literature such as SMOTE and Gaussian mixture.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}