
Using Spatial Patterns of COVID-19 to Build a Framework for Economic Reactivation

 , , , and
, , , and
Abstract
:1. Introduction
2. Literature Review
2.1. A Humanitarian Logistics Framework for Pandemic Assessment
2.2. Previous Works on Determinants of COVID-19 Cases and Deaths
2.3. COVID-19 Pandemic in Peru: A Brief Review
2.4. Vulnerability Sources of Peruvian Provinces Regarding COVID-19 Pandemic
- First: a province is vulnerable in the post-lockdown context if it has a lower incidence of poverty, unemployment, and other indicators of bad economic performance. Economic activity, which is inversely related to poverty, requires internal mobility and interpersonal interaction [47]. This does not mean that we should give less importance to poor provinces, even if they might have a lower demand for PRRSGS. The optimal policy must give the latter equal weight in the humanitarian objective function. We argue that this proposition is valid if we measure long-run poverty from households, and short-run measures may not prove this relationship.
- Second: provinces that have more proportion of the vulnerable population in terms of age (the older); sex (the males); skin color (black); and chronic diseases such as hypertension, diabetes, and obesity, among others. Deprivation costs are higher for people with a higher probability of dying due to COVID-19, including people with the aforementioned characteristics [43,44,45] reach the same signs of effects for the case of USA). Two types of overcrowding measures are accounted for regarding vulnerability: overcrowding in households and overcrowding in cities (proxied by population density). Provinces with higher overcrowding in households may have worse COVID-19 outcomes [44]. We expect the same for provinces with higher overcrowding in cities. Poverty is generally negatively associated with overcrowding in cities but positively associated with overcrowding in households [45].
- Third: A short-run households’ income drastically reduced and then slowly recovered, so there is a shortage in the available resources to battle the contagion, which cannot be covered. In the absence of high coverage of health insurance, this would lead to a greater number of deaths. However, we acknowledge that, in order to obtain high health insurance coverage, provinces must work, so the economic activity must be high for provinces with high health insurance coverage, and thus, this could lead to higher mortality rates. In consequence, we face two possible effects of health insurance: whether health insurance coverage positively or negatively affects the number of deaths due to COVID-19 is an empirical question.
- Fourth: health system performance indicators play a key role in the determination of COVID-19 outcomes, especially when the COVID-19 cases exceed the capacity of hospitals and other health facilities. Provinces where the health system performs bad are more vulnerable and likely to have a greater number of deaths [24]. However, as economic activity is a condition for good health system performance, the final effect is theoretically ambiguous [45]. Whether the effect is finally positive or negative regarding COVID-19 deaths is also an empirical question.
- Fifth: the COVID-19 outcome of a province regarding mortality rates may be affected by neighboring provinces with a high incidence of COVID-19 deaths. These are called endogenous interaction effects.
- Sixth: considering previous exploratory works on determinants of COVID-19 cases and deaths, and the previous vulnerability definition block, there is no reason not to suspect that the COVID-19 outcome in a province is affected by the exogenous outcomes of neighboring provinces (i.e., poverty, demographics, health systems, etc.). These are called exogenous interaction effects.
- Seventh: after considering all of the information above, it is possible that the spatial dependence model still has a residual that represents all of the variability of COVID-19 outcomes that could not be explained by the predictors. In this residual, there may be correlated effects, as is pointed out by [48], where the COVID-19 outcomes of a province are affected by unobserved similar characteristics of their neighbors.
3. Materials and Methods
3.1. Data Collection Methods
3.2. Data Processing Methods
3.3. Demand Assessment
- : Low demand
- : Medium demand
- : High demand
- : Very high demand
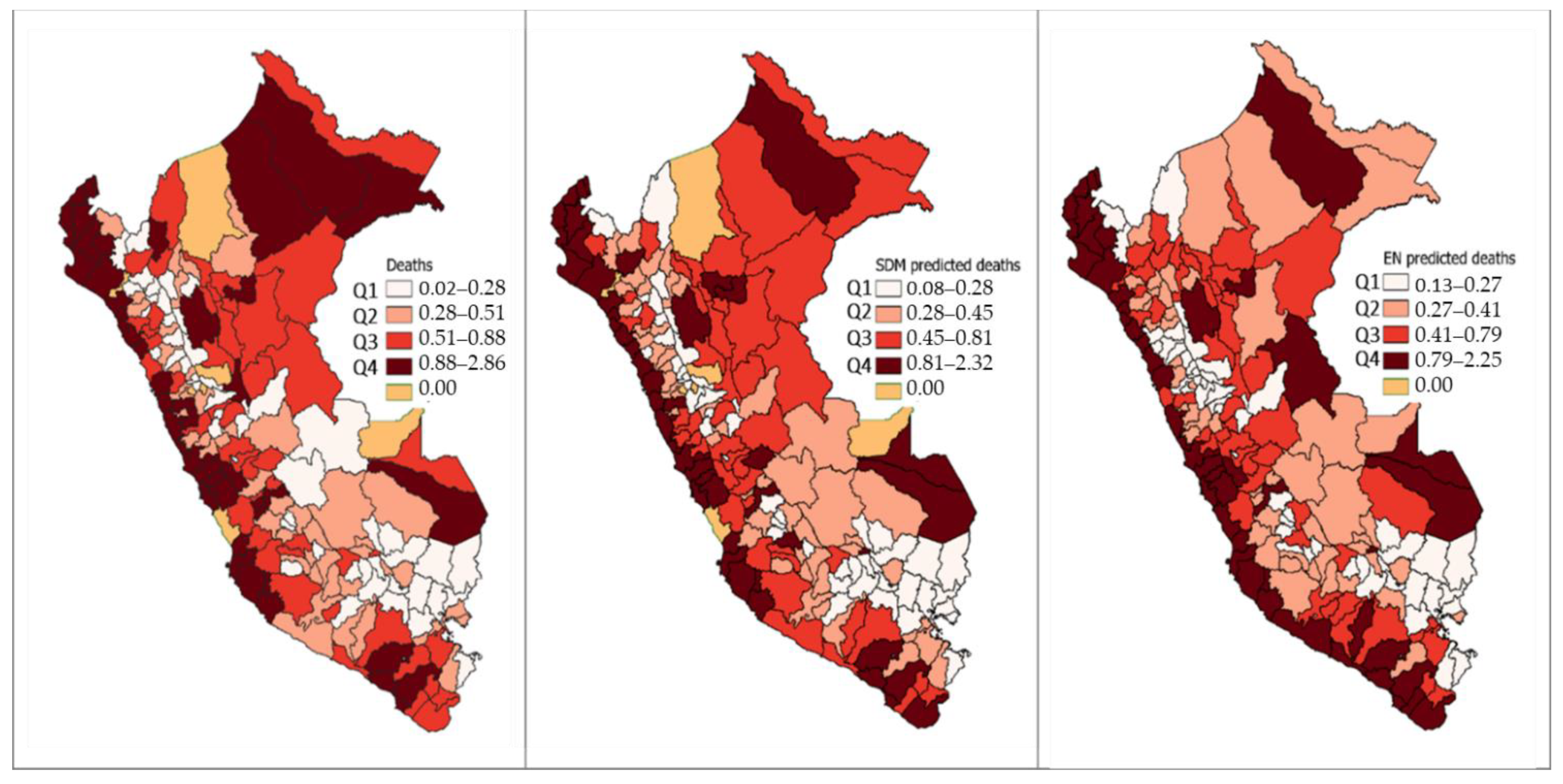
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Presidencia del Consejo de Ministros. Decreto Supremo que precisa los alcances del artículo 8 del Decreto Supremo N 044-2020-PCM, que declara el estado de emergencia nacional por las graves circunstancias que afectan la vida de la nación a consecuencia del brote del COVID-19. In Decreto Supremo N° 045-2020-PCM; El Peruano: Lima, Peru, 2020. [Google Scholar]
- Presidencia del Consejo de Ministros. Decreto Supremo que modifica el Decreto Supremo N° 116-2020-PCM, Decreto Supremo que establece las medidas que debe seguir la ciudadanía en la nueva convivencia social y prorroga el Estado de Emergencia Nacional por las graves circunstancias que afectan la vida de la Nación a consecuencia del COVID-19, modificado por los Decretos Supremos N° 129-2020-PCM, N° 135-2020-PCM, N° 139-2020-PCM, N° 146-2020-PCM, N° 151-2020- PCM, N° 156-2020-PCM, N° 162-2020-PCM y N° 165-2020-PCM. In Decreto Supremo N° 170-2020-PCM; El Peruano: Lima, Peru, 2020. [Google Scholar]
- Poder Ejecutivo. Decreto de urgencia que establece el retiro extraordinario del fondo de pensiones en el sistema privado de pensiones como medida para mitigar efectos económicos del aislamiento social obligatorio y otras medidas. In Decreto de Urgencia N° 034-2020; El Peruano: Lima, Peru, 2020. [Google Scholar]
- Poder Ejecutivo. Decreto de urgencia que establece medidas para reducir el impacto en la economía peruana, de las disposiciones de prevención establecidas en la declaratoria de estado de emergencia nacional ante los riesgos de propagación del COVID-19. In Decreto de Urgencia N° 033-2020; El Peruano: Lima, Peru, 2020. [Google Scholar]
- Ministerio del Interior. Aprueban protocolo para la implementación de las medidas que garanticen el ejercicio excepcional del derecho a la libertad de tránsito en el marco del Estado de Emergencia Nacional declarado mediante D.S. N° 044-2020-PCM. In Resolución Ministerial N° 304-2020-IN; El Peruano: Lima, Peru, 2020. [Google Scholar]
- Ministerio de Economía y Finanzas. Aprueban el Reglamento Operativo del Fondo de Apoyo Empresarial a la MYPE (FAE-MYPE). In Resolución Ministerial N° 124-2020-EF/15; El Peruano: Lima, Peru, 2020. [Google Scholar]
- Montoro, C.; Pérez, F.; Herrada, R. Medidas del BCRP Frente a la Pandemia del Nuevo Coronavirus. Rev. Moneda 2020, 182, 10–18. [Google Scholar]
- Brodeur, A.; Gray, D.; Islam, A.; Bhuiyan, S. A Literature Review of the Economics of Covid-19. IZA Discussion Paper No. 13411. 2020. Available online: https://ssrn.com/abstract=3636640 (accessed on 20 December 2020).
- Acemoglu, D.; Chernozhukov, V.; Werning, I.; Whinsnton, M.D. A Multi-Risk SIR Model with Optimally Targeted Lockdown Working Paper No. 27102; Working Paper Series; National Bureau of Economic Research: Cambridge, MA, USA, 2020. [Google Scholar] [CrossRef]
- Béland, L.-P.; Brodeur, A.; Mikola, D.; Wright, T. The Short-Term Economic Consequences of Covid-19: Occupation Tasks and Mental Health in Canada; Social Science Research Network: New York, NY, USA, 2020; Available online: https://papers.ssrn.com/abstract=3602430 (accessed on 20 December 2020).
- Overstreet, R.E.; Hall, D.J.; Hanna, J.B.; Rainer, R.K. Research in humanitarian logistics. J. Humanit. Logist. Supply Chain Manag. 2011, 1, 114–131. [Google Scholar] [CrossRef]
- Holguín-Veras, J.; Pérez, N.; Jaller, M.; Van Wassenhove, L.N.; Aros-Vera, F. On the appropriate objective function for post-disaster humanitarian logistics models. J. Oper. Manag. 2013, 31, 262–280. [Google Scholar] [CrossRef]
- Leiras, A.; Junior, I.D.B.; Peres, E.Q.; Bertazzo, T.R.; Yoshizaki, H.T.Y. Literature review of humanitarian logistics research: Trends and challenges. J. Humanit. Logist. Supply Chain Manag. 2014, 4, 95–130. [Google Scholar] [CrossRef]
- Renteria, R.; Chong, M.; de Brito Junior, I.; Luna, A.; Quiliche, R. An entropy-based approach for disaster risk assessment and humanitarian logistics operations planning in Colombia. J. Humanit. Logist. Supply Chain Manag. 2021, 11, 428–456. [Google Scholar] [CrossRef]
- Andersen, L.M.; Harden, S.R.; Sugg, M.M.; Runkle, J.D.; Lundquist, T.E. Analyzing the spatial determinants of local Covid-19 transmission in the United States. Sci. Total Environ. 2021, 754, 142396. [Google Scholar] [CrossRef]
- Khalatbari-Soltani, S.; Cumming, R.G.; Delpierre, C.; Kelly-Irving, M. Importance of collecting data on socioeconomic determinants from the early stage of the COVID-19 outbreak onwards. J. Epidemiol. Community Health 2020, 74, 620–623. [Google Scholar] [CrossRef] [PubMed]
- Pedrosa, N.L.; de Albuquerque, N.L.S. Spatial analysis of COVID-19 cases and intensive care beds in the state of Ceará, Brazil. Cienc. Saude Coletiva 2020, 25, 2461–2468. [Google Scholar] [CrossRef]
- Rollston, R.; Galea, S. COVID-19 and the Social Determinants of Health. Am. J. Health Promot. 2020, 34, 687–689. [Google Scholar] [CrossRef]
- Sugg, M.M.; Spaulding, T.J.; Lane, S.J.; Runkle, J.D.; Harden, S.R.; Hege, A.; Iyer, L.S. Mapping community-level determinants of COVID-19 transmission in nursing homes: A multi-scale approach. Sci. Total Environ. 2020, 752, 141946. [Google Scholar] [CrossRef]
- White, E.R.; Hébert-Dufresne, L. State-level variation of initial COVID-19 dynamics in the United States. PLoS ONE 2020, 15, e0240648. [Google Scholar] [CrossRef]
- Gupta, A.; Banerjee, S.; Das, S. Significance of geographical factors to the COVID-19 outbreak in India. Model. Earth Syst. Environ. 2020, 6, 2645–2653. [Google Scholar] [CrossRef]
- Benzakoun, J.; Hmeydia, G.; Delabarde, T.; Hamza, L.; Meder, J.; Ludes, B.; Mebazaa, A. Excess out-of-hospital deaths during the COVID -19 outbreak: Evidence of pulmonary embolism as a main determinant. Eur. J. Heart Fail. 2020, 22, 1046–1047. [Google Scholar] [CrossRef]
- Zhang, C.H.; Schwartz, G.G. Spatial Disparities in Coronavirus Incidence and Mortality in the United States: An Ecological Analysis as of May 2020. J. Rural. Health 2020, 36, 433–445. [Google Scholar] [CrossRef]
- Bruno, G.; Wemole, R.; Ronsivalle, G.B.; Foresti, L.; Poledda, G. A Prototype Model of Georeferencing the Inherent Risk of Contagion from COVID-19; ResearchGate preprint: Rome, Italy, 2020. [Google Scholar] [CrossRef]
- Carrillo-Larco, R.M.; Castillo-Cara, M. Using country-level variables to classify countries according to the number of confirmed COVID-19 cases: An unsupervised machine learning approach. Wellcome Open Res. 2020, 5, 56. [Google Scholar] [CrossRef]
- Chakraborti, S.; Maiti, A.; Pramanik, S.; Sannigrahi, S.; Pilla, F.; Banerjee, A.; Das, D.N. Evaluating the plausible application of advanced machine learnings in exploring determinant factors of present pandemic: A case for continent specific COVID-19 analysis. Sci. Total Environ. 2021, 765, 142723. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Mehmood, A.; Ullah, S.; On, B.-W.; Aslam, W.; Choi, G.S. COVID-19 Future Forecasting Using Supervised Machine Learning Models. IEEE Access 2020, 8, 101489–101499. [Google Scholar] [CrossRef]
- Crandall, M.S.; Weber, B.A. Local Social and Economic Conditions, Spatial Concentrations of Poverty, and Poverty Dynamics. Am. J. Agric. Econ. 2004, 86, 1276–1281. [Google Scholar] [CrossRef] [Green Version]
- Wardhana, D.; Ihle, R.; Heijman, W. Agro-clusters and Rural Poverty: A Spatial Perspective for West Java. Bull. Indones. Econ. Stud. 2017, 53, 161–186. [Google Scholar] [CrossRef]
- Alexander, D.E. Principles of Emergency Planning and Management; Oxford University Press: Oxford, UK, 2002. [Google Scholar]
- Smith, C.D.; Mennis, J. Incorporating Geographic Information Science and Technology in Response to the COVID-19 Pandemic. Prev. Chronic Dis. 2020, 17, 246. [Google Scholar] [CrossRef] [PubMed]
- Zeckhauser, R. The economics of catastrophes. J. Risk Uncertain. 1996, 12, 113–140. [Google Scholar] [CrossRef]
- Pindyck, R.S.; Wang, N. The Economic and Policy Consequences of Catastrophes. Am. Econ. J. Econ. Policy 2013, 5, 306–339. [Google Scholar] [CrossRef] [Green Version]
- Yoshizaki, H.; de Brito Junior, I.; Hino, C.; Aguiar, L.; Pinheiro, M. Relationship between Panic Buying and Per Capita Income during COVID-19. Sustainability 2020, 12, 9968. [Google Scholar] [CrossRef]
- Gutjahr, W.J.; Fischer, S. Equity and deprivation costs in humanitarian logistics. Eur. J. Oper. Res. 2018, 270, 185–197. [Google Scholar] [CrossRef]
- Alibaba. COVID-19 Outbreak Hospital Response Strategy; Zhejiang University School of Medicine: Hangzhou, China, 2020. [Google Scholar]
- Alibaba. Handbook of COVID-19 Prevention and Treatment; Zhejiang University School of Medicine: Hangzhou, China, 2020. [Google Scholar]
- Guliyev, H. Determining the spatial effects of COVID-19 using the spatial panel data model. Spat. Stat. 2020, 38, 100443. [Google Scholar] [CrossRef]
- Sun, F.; Matthews, S.A.; Yang, T.-C.; Hu, M.-H. A spatial analysis of the COVID-19 period prevalence in U.S. counties through 28 June 2020: Where geography matters? Ann. Epidemiol. 2020, 52, 54–59.e1. [Google Scholar] [CrossRef]
- Schwalb, A.; Seas, C. The COVID-19 Pandemic in Peru: What Went Wrong? Am. J. Trop. Med. Hyg. 2021, 104, 1176–1178. [Google Scholar] [CrossRef] [PubMed]
- Alvarez-Risco, A.; Mejia, C.R.; Delgado-Zegarra, J.; Del-Aguila-Arcentales, S.; Arce-Esquivel, A.A.; Valladares-Garrido, M.J.; Del Portal, M.R.; Villegas, L.F.; Curioso, W.H.; Sekar, M.C.; et al. The Peru Approach against the COVID-19 Infodemic: Insights and Strategies. Am. J. Trop. Med. Hyg. 2020, 103, 583–586. [Google Scholar] [CrossRef] [PubMed]
- Alvarez-Risco, A.; Del-Aguila-Arcentales, S.; Yáñez, J.A. Telemedicine in Peru as a Result of the COVID-19 Pandemic: Perspective from a Country with Limited Internet Access. Am. J. Trop. Med. Hyg. 2021, 105, 6–11. [Google Scholar] [CrossRef]
- Turner-Musa, J.; Ajayi, O.; Kemp, L. Examining Social Determinants of Health, Stigma, and COVID-19 Disparities. Health Care 2020, 8, 168. [Google Scholar] [CrossRef]
- Burström, B.; Tao, W. Social determinants of health and inequalities in COVID-19. Eur. J. Public Health 2020, 30, 617–618. [Google Scholar] [CrossRef] [PubMed]
- Fielding-Miller, R.K.; Sundaram, M.E.; Brouwer, K. Social determinants of COVID-19 mortality at the county level. PLoS ONE 2020, 15, e0240151. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N.; Lovinsky-Desir, S.; Bime, C.; Wisnivesky, J.P.; Celedón, J.C. The Structural and Social Determinants of the Racial/Ethnic Disparities in the U.S. COVID-19 Pandemic. What’s Our Role? Am. J. Respir. Crit. Care Med. 2020, 202, 943–949. [Google Scholar] [CrossRef] [PubMed]
- Engle, S.; Stromme, J.; Zhou, A. Staying at Home: Mobility Effects of COVID-19; SSRN: New York, NY, USA, 2020. [Google Scholar]
- Elhorst, J.P. Applied Spatial Econometrics: Raising the Bar. Spat. Econ. Anal. 2010, 5, 9–28. [Google Scholar] [CrossRef]
- Kelejian, H.H.; Prucha, I.R. A Generalized Moments Estimator for the Autoregressive Parameter in a Spatial Model. Int. Econ. Rev. 1999, 40, 509–533. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Lin, H. Spatial Weights Matrix. In Encyclopedia of GIS; Springer: Berlin/Heidelberg, Germany, 2008; p. 1113. [Google Scholar] [CrossRef]
- O. Ogutu, J.; Schulz-Streeck, T.; Piepho, H.-P. Genomic selection using regularized linear regression models: Ridge regression, lasso, elastic net and their extensions. BMC Proc. 2012, 6, S10. [Google Scholar] [CrossRef] [Green Version]
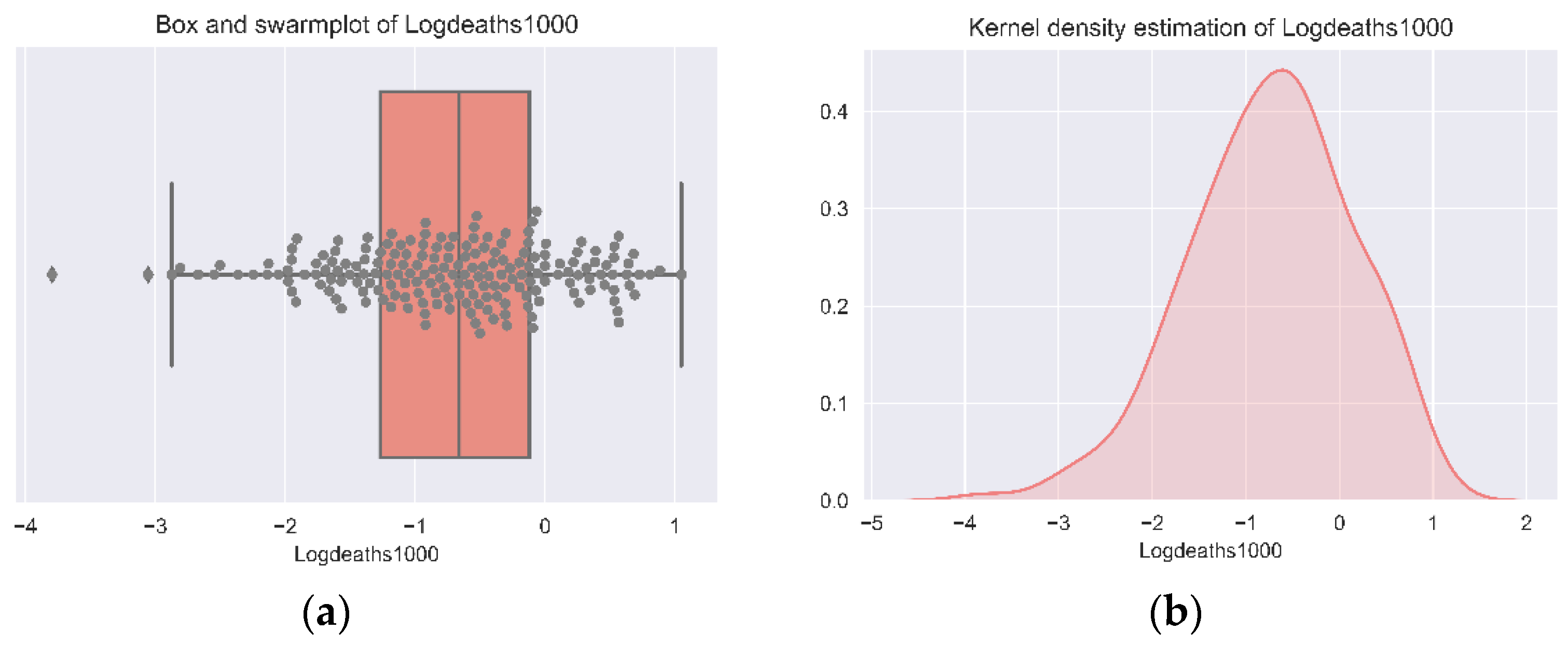




{kind=link}
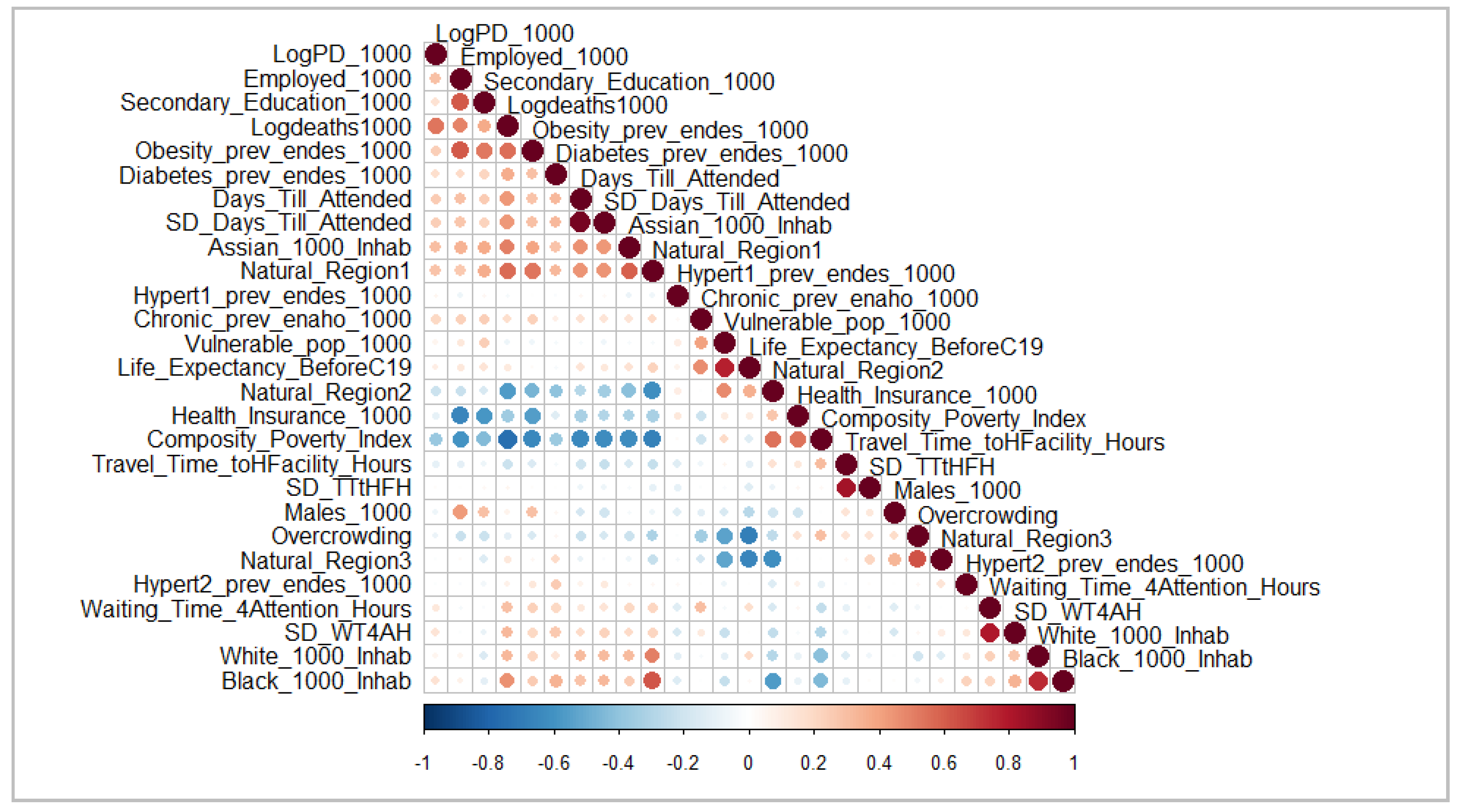{kind=link}
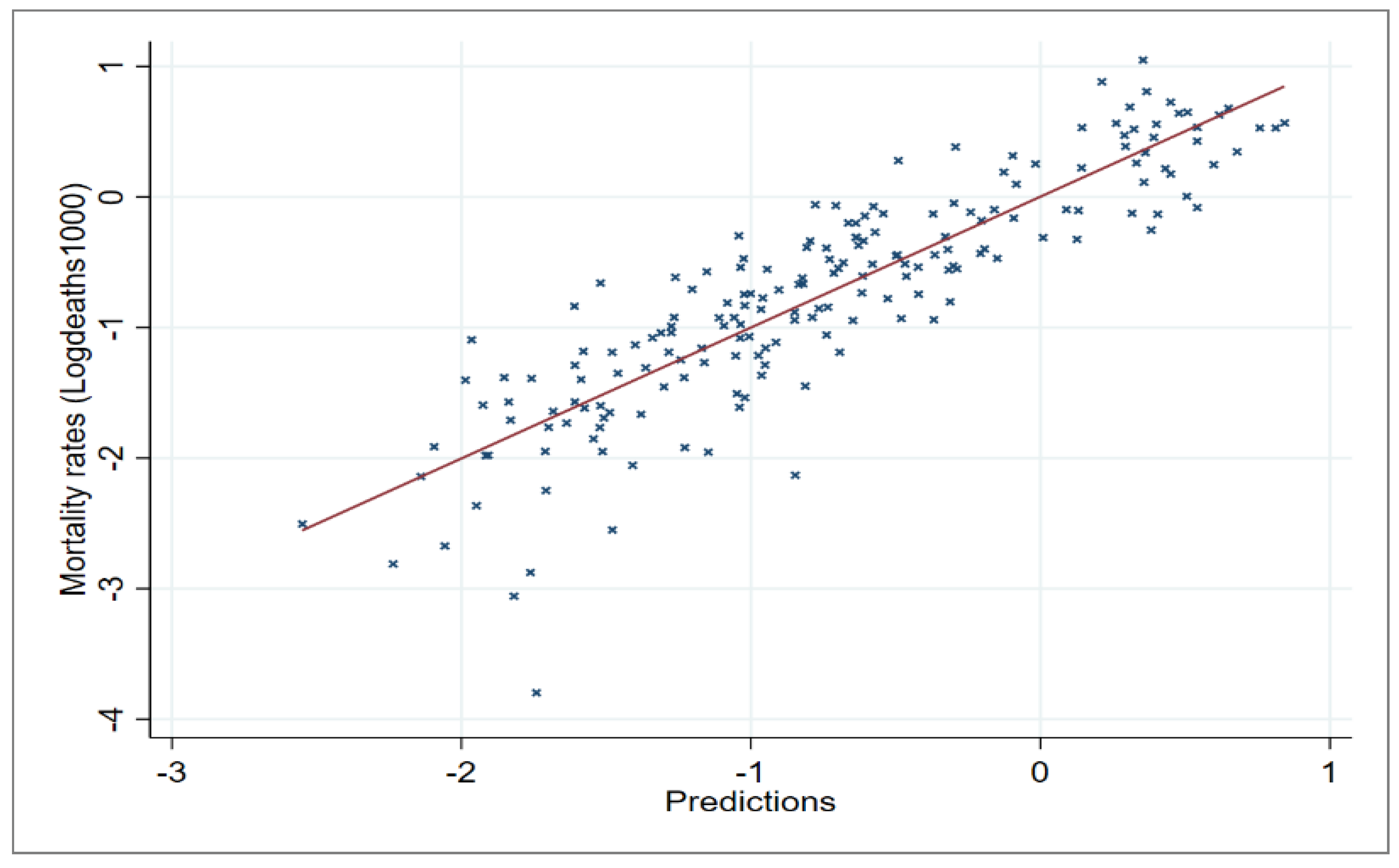{kind=link}
{kind=link}
| Types | Support for Response and Recovery from COVID-19 Pandemic [36] | COVID-19 Diagnosis and Treatment and Disinfection and Sterilization Medical Equipment [37] |
|---|---|---|
| Goods and services | Oxygen, automatic respirators, dexamethasone, prednisone, acetaminophen, antibiotics (azithromycin, levofloxacin), anti-clotting medication, KN95 masks, gloves, intensive care beds, alcohol, other disinfection products. Health care, emergency transport, hospitals, doctors. Funerary protocols (incineration) and transport. | Stethoscope, thermometer, sphygmomanometer, oxygen flowmeter, oxygen saturation monitor, air disinfection machine, crash cart, defibrillator, monitor, micro-injection pump, sputum elimination machine, noninvasive ventilator, invasive ventilator, continuous renal replacement therapy (CRRT), extracorporeal membrane oxygenation (ECMO), designated computed tomography, polymerase chain reaction (PCR) machine, nucleic acid detector, ultraviolet disinfection machine, anesthesia machine, ventilator circuit disinfection machine, infrared thermal imager, and forehead thermometer. |
| Variable | Expected Sign of Effect Regarding Mortality Rates |
|---|---|
| Poverty | − |
| Age | + |
| Sex | + |
| Black skin color | + |
| Chronic diseases | + |
| Overcrowding in cities | + |
| Overcrowding in households | + |
| Health insurance | ? |
| Health system performance | ? |
| Endogenous interaction effects | + |
| Exogenous interaction effects | + |
| Correlated effects | + |
| Name | Description | Source |
|---|---|---|
| Logdeaths1000 | The logarithm of the cumulative number of COVID-19 deaths per 1000 inhabitants until 12 December 2020 | MINSA (2020) |
| Composite_Poverty_Index | The average index of poverty estimated by the Multiple Correspondence Analysis (MCA) methods | Census * (2017) |
| Employed | People employed per 1000 inhabitants | S.A. 1 |
| Secondary_Educ | People having a complete secondary education per 1000 inhabitants. | S.A. |
| Vulnerable_pop | Elderly people (>65 years) per 1000 inhabitants | S.A. |
| LogPD_1000 | The logarithm of the population density measured as 1000 inhabitants per km² (urban area) | S.A. |
| Males_1000_Inhab | Males per 1000 inhabitants | S.A. |
| White_1000_Inhab | White people per 1000 inhabitants | S.A. |
| Black_1000_Inhab | Black people per 1000 inhabitants | S.A. |
| Assian_1000_Inhab | Asian people per 1000 inhabitants | S.A. |
| Overcrowding | The average proportion of households with more members than rooms | S.A. |
| Natural_Region1 | Province is located in the Coastal region | S.A. |
| Natural_Region2 | Province is located in the Highlands region | S.A. |
| Natural_Region3 | Province is located in the Jungle region | S.A. |
| Hypert1 | People with hypertension measured by results on differential pressure per 1000 inhabitants | S.A. |
| Hypert2 | People with diagnosed hypertension per 1000 inhabitants | S.A. |
| Diabetes | People with diagnosed diabetes per 1000 inhabitants | S.A. |
| Obesity | People with obesity by body mass index per 1000 inhabitants | S.A. |
| Chronic | People with a chronic illness (COPD, diabetes, hypertension, etc.) per 1000 inhabitants | ENAHO * (2019) |
| Health_Insurance | Number of people with health insurance per 100 inhabitants | Census * (2017) |
| Life_Expectancy | The average life between 2017 and 2019 before the COVID-19 pandemic | S.A. |
| Days_Till_Attended | The average days until medical attention | ENAHO * (2019) |
| SD_DTA | The standard deviation of days until medical attention | S.A. |
| Travel_Time | The average hours of travel time to health facility | S.A. |
| SD_TTtHFH | The standard deviation of hours of travel time to health facility | S.A. |
| Waiting_Time | The average hours of waiting time until attention in health facility | S.A. |
| SD_WT4AH | The standard deviation of hours of waiting time until attention at the health facility | S.A. |
| Variable | Mean | S.D. | Min | Max | Median |
|---|---|---|---|---|---|
| Logdeaths1000 | −0.74 | 0.87 | −3.80 | 1.05 | −0.67 |
| Employed_100 | 371.12 | 72.03 | 140.31 | 589.99 | 379.94 |
| Males_1000_Inhab | 501.72 | 19.55 | 471.90 | 604.85 | 498.97 |
| Vulnerable_pop | 199.71 | 40.98 | 83.02 | 350.88 | 197.91 |
| Health_Insurance | 811.87 | 93.86 | 488.04 | 958.34 | 817.18 |
| Secondary_Educ | 313.98 | 52.78 | 186.49 | 436.08 | 314.60 |
| Life_Expectancy | 63.34 | 6.49 | 35.09 | 74.81 | 65.03 |
| Chronic | 364.96 | 96.99 | 117.03 | 630.40 | 362.31 |
| Composite_Poverty_Index | 56.62 | 12.17 | 25.71 | 78.74 | 60.63 |
| White | 32.24 | 25.05 | 0.71 | 119.25 | 27.29 |
| Asian_1000_Inhab | 0.18 | 0.40 | 0.00 | 3.32 | 0.04 |
| Black_1000_Inhab | 21.10 | 24.99 | 0.00 | 102.08 | 12.16 |
| Hypert1 | 434.69 | 80.36 | 96.14 | 724.68 | 430.87 |
| Hypert2 | 89.86 | 44.14 | 0.00 | 277.53 | 84.54 |
| Diabetes | 25.32 | 25.18 | 0.00 | 171.49 | 21.70 |
| Obesity | 184.44 | 94.21 | 0.00 | 514.62 | 173.56 |
| Days_Till_Attended | 1.06 | 1.79 | 0.01 | 12.97 | 0.34 |
| SD_DTA | 3.67 | 5.10 | 0.00 | 35.44 | 1.49 |
| Travel_Time | 0.65 | 0.45 | 0.20 | 4.37 | 0.53 |
| SD_TTtHFH | 1.61 | 2.84 | 0.16 | 30.70 | 0.82 |
| Waiting_Time | 0.11 | 0.05 | 0.02 | 0.28 | 0.11 |
| SD_WT4AH | 0.41 | 0.16 | 0.05 | 1.21 | 0.43 |
| logPD_1000 | −0.31 | 3.33 | −9.85 | 7.70 | −0.15 |
| Overcrowding | 17.24 | 7.85 | 7.54 | 53.62 | 14.71 |
| Natural_Region1 | 0.19 | 0.39 | 0.00 | 1.00 | 0.00 |
| Natural_Region2 | 0.62 | 0.49 | 0.00 | 1.00 | 1.00 |
| Natural_Region3 | 0.19 | 0.39 | 0.00 | 1.00 | 0.00 |
| Spatial Weighting Matrix | Moran’s I Standard Deviate | Significance (p-Value) |
|---|---|---|
| Queen’s contiguity criteria | 5.058 | 4.23 × 10−7 |
| K-nearest neighbors (K = 1) | 2.864 | 4.18 × 10−3 |
| K-nearest neighbors (K = 2) | 3.613 | 3.02 × 10−4 |
| K-nearest neighbors (K = 3) | 3.648 | 2.64 × 10−4 |
| K-nearest neighbors (K = 4) | 3.874 | 1.07 × 10−4 |
| Model | SDM (1,1,1) | SDM (1,0,1) | SDM (1,1,0) | SDM (0,1,1) | SDM (1,0,0) | SDM (0,0,1) | OLS (0,0,0) | ENR |
|---|---|---|---|---|---|---|---|---|
| MF R² | 0.67 | 0.53 | 0.67 | 0.67 | 0.53 | 0.53 | 0.52 | N.E. |
| R² | 0.75 | 0.72 | 0.75 | 0.75 | 0.73 | 0.72 | 0.74 | 0.68 |
| AIC | 443.80 | 283.20 | 267.30 | 266.80 | 281.90 | 281.90 | 287.00 | N.E. |
| BIC | 443.80 | 377.20 | 439.1 | 438.60 | 372.70 | 372.70 | 374.60 | N.E. |
| WT | 98.63 * | 11.95 * | 88.16 * | 99.55 * | 7.138 * | 18.75 * | N.E. | N.E. |
| RMSE | 0.27 | 0.28 | 0.27 | 0.27 | 0.28 | 0.28 | 0.27 | 0.30 |
| ENR | |||||
|---|---|---|---|---|---|
| VARIABLES | Logdeaths1000 | S.E. | W | S.E. | Logdeaths1000 |
| Employed_100 | 0.001 | (0.001) | −0.005 * | (0.003) | 0.000 |
| Males_1000_Inhab | −0.001 | (0.003) | −0.002 | (0.005) | 0.002 |
| Vulnerable_pop | 0.001 | (0.002) | 0.003 | (0.005) | 0.004 |
| Health_Insurance | −0.001 | (0.001) | 0.001 | (0.002) | 0.001 |
| Secondary_Educ | 0.002 | (0.001) | 0.005 | (0.003) | 0.001 |
| Life_Expectancy | 0.018 | (0.012) | 0.006 | (0.035) | 0.000 |
| Chronic | −0.000 | (0.000) | −0.002 * | (0.001) | 0.000 |
| Composite_Poverty_Index | −0.031 *** | (0.009) | 0.009 | (0.024) | −0.048 |
| White_1000_Inhab | −0.006 * | (0.003) | 0.024 *** | (0.006) | −0.002 |
| Assian_1000_Inhab | −0.076 | (0.122) | −0.430 | (0.387) | 0.000 |
| Black_1000_Inhab | 0.004 | (0.003) | −0.020 ** | (0.008) | 0.007 |
| Hypert1 | −0.000 | (0.000) | 0.000 | (0.001) | 0.000 |
| Hypert2 | 0.000 | (0.001) | 0.002 | (0.003) | −0.001 |
| Diabetes | −0.000 | (0.002) | 0.007 | (0.004) | 0.000 |
| Obesity | 0.000 | (0.001) | 0.002 | (0.002) | 0.001 |
| Days_Till_Attended | −0.021 | (0.061) | −0.117 | (0.186) | 0.000 |
| SD_DTA | 0.008 | (0.020) | 0.059 | (0.066) | −0.003 |
| Travel_Time | −0.244 | (0.162) | −0.083 | (0.528) | 0.000 |
| SD_TTtHFH | 0.051 ** | (0.025) | 0.046 | (0.080) | 0.000 |
| Waiting_Time | 1.498 | (1.450) | −4.008 | (4.174) | 0.000 |
| SD_WT4AH | 0.219 | (0.391) | 1.434 | (1.083) | 0.000 |
| LogPD_1000 | 0.077 *** | (0.012) | 0.131 *** | (0.050) | 0.053 |
| Overcrowding | 0.019 ** | (0.008) | −0.043 *** | (0.015) | 0.019 |
| Natural_Region1 | (base) | (base) | 0.000 | ||
| Natural_Region2 | −0.056 | (0.187) | −0.483 | (0.460) | 0.000 |
| Natural_Region3 | 0.577 ** | (0.259) | −0.238 | (0.525) | 0.000 |
| Logdeaths1000 | 0.109 | (0.100) | N.E. | ||
| e.Logdeaths1000 | 0.305 ** | (0.151) | N.E. | ||
| var(e.Logdeaths1000) | 0.190 *** | (0.027) | N.E. | ||
| Constant | 1.468 | (1.524) | 0.403 | ||
| Logdeaths1000 | Direct | Indirect | Total |
|---|---|---|---|
| Employed_100 | 0.001 | −0.001 | 0.001 |
| Males_1000_Inhab | −0.001 | −0.007 | −0.007 |
| Vulnerable_pop | 0.001 | −0.001 | 0.001 |
| Health_Insurance | −0.001 | 0.003 * | 0.002 |
| Secondary_Educ | 0.000 | 0.003 | 0.003 |
| Life_Expectancy | 0.013 | 0.001 | 0.014 |
| Chronic | 0.000 | −0.001 | 0.000 |
| Composite_Poverty_Index | −0.029 *** | 0.008 | −0.021 ** |
| White_1000_Inhab | −0.007 *** | 0.011 * | 0.004 |
| Assian_1000_Inhab | 0.038 | 0.247 | 0.285 |
| Black_1000_Inhab | 0.005 * | −0.009 | −0.004 |
| Hypert1 | 0.000 | 0.001 | 0.001 |
| Hypert2 | 0.000 | −0.001 | 0.000 |
| Diabetes | 0.000 | 0.006 | 0.006 |
| Obesity | 0.000 | 0.003 | 0.003 |
| Days_Till_Attended | −0.048 | 0.104 | 0.055 |
| SD_DTA | 0.017 | −0.047 | −0.031 |
| Travel_Time | −0.218 | −0.693 | −0.911 |
| SD_TTtHFH | 0.045 * | 0.106 | 0.150 * |
| Waiting_Time | −0.108 | −1.800 | −1.908 |
| SD_WT4AH | 0.672 * | 0.511 | 1.183 |
| LogPD_1000 | 0.079 *** | 0.038 | 0.117 *** |
| Overcrowding | 0.019 *** | −0.031 ** | −0.012 |
| Natural_Region1 | −0.100 | −0.290 | −0.391 |
| Natural_Region2 | 0.337 | −0.206 | 0.131 |
| Natural_Region3 | 0.001 | −0.001 | 0.001 |
| Department | Province | ENR COVID-19 Deaths Forecast | Demand Category |
|---|---|---|---|
| Ucayali | Purús | 0.35 | Medium |
| Ancash | Asunción | 0.28 | Medium |
| Ancash | Antonio Raymondi | 0.23 | Low |
| Huánuco | Marañón | 0.20 | Low |
| Lambayeque | Ferreñafe | 0.72 | High |
| Lima | Cañete | 1.28 | Very high |
| Loreto | D.Marañón | 0.31 | Medium |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quiliche, R.; Rentería-Ramos, R.; de Brito Junior, I.; Luna, A.; Chong, M. Using Spatial Patterns of COVID-19 to Build a Framework for Economic Reactivation. Sustainability 2021, 13, 10092. https://doi.org/10.3390/su131810092
Quiliche R, Rentería-Ramos R, de Brito Junior I, Luna A, Chong M. Using Spatial Patterns of COVID-19 to Build a Framework for Economic Reactivation. Sustainability. 2021; 13(18):10092. https://doi.org/10.3390/su131810092
Chicago/Turabian StyleQuiliche, Renato, Rafael Rentería-Ramos, Irineu de Brito Junior, Ana Luna, and Mario Chong. 2021. "Using Spatial Patterns of COVID-19 to Build a Framework for Economic Reactivation" Sustainability 13, no. 18: 10092. https://doi.org/10.3390/su131810092
APA StyleQuiliche, R., Rentería-Ramos, R., de Brito Junior, I., Luna, A., & Chong, M. (2021). Using Spatial Patterns of COVID-19 to Build a Framework for Economic Reactivation. Sustainability, 13(18), 10092. https://doi.org/10.3390/su131810092