
Traffic Volume Prediction: A Fusion Deep Learning Model Considering Spatial–Temporal Correlation


Abstract
:1. Introduction
2. Related Work
3. Methodologies
3.1. Road Section Similarity Measurement
3.1.1. Reconstruction of Traffic Flow Data Based on Wavelet Transform
3.1.2. Similarity Measurement Based on Dynamic Time Warping
3.2. Stationarity Analysis
3.3. Traffic Flow Prediction Based on CNN-LSTM
3.3.1. Feature Extraction Method of Traffic Flow Parameters Based on CNN
- (1)
- Convolution Layer
- (2)
- Pooling Layer
3.3.2. Prediction Method of Traffic Flow Parameters Based on LSTM
4. Modelling Results
4.1. Road Section Similarity Measurement
4.1.1. Reconstruction of Traffic Flow Time Series Data
4.1.2. Similarity Measurement of Time Series
4.2. Stationarity Analysis
4.3. Traffic Flow Prediction Based on CNN-LSTM
4.3.1. Model Parameter Selection
- (1)
- Number of Iterations
- (2)
- Selection of Time Step
- (3)
- Number of LSTM Layers and Size of Hidden Layers
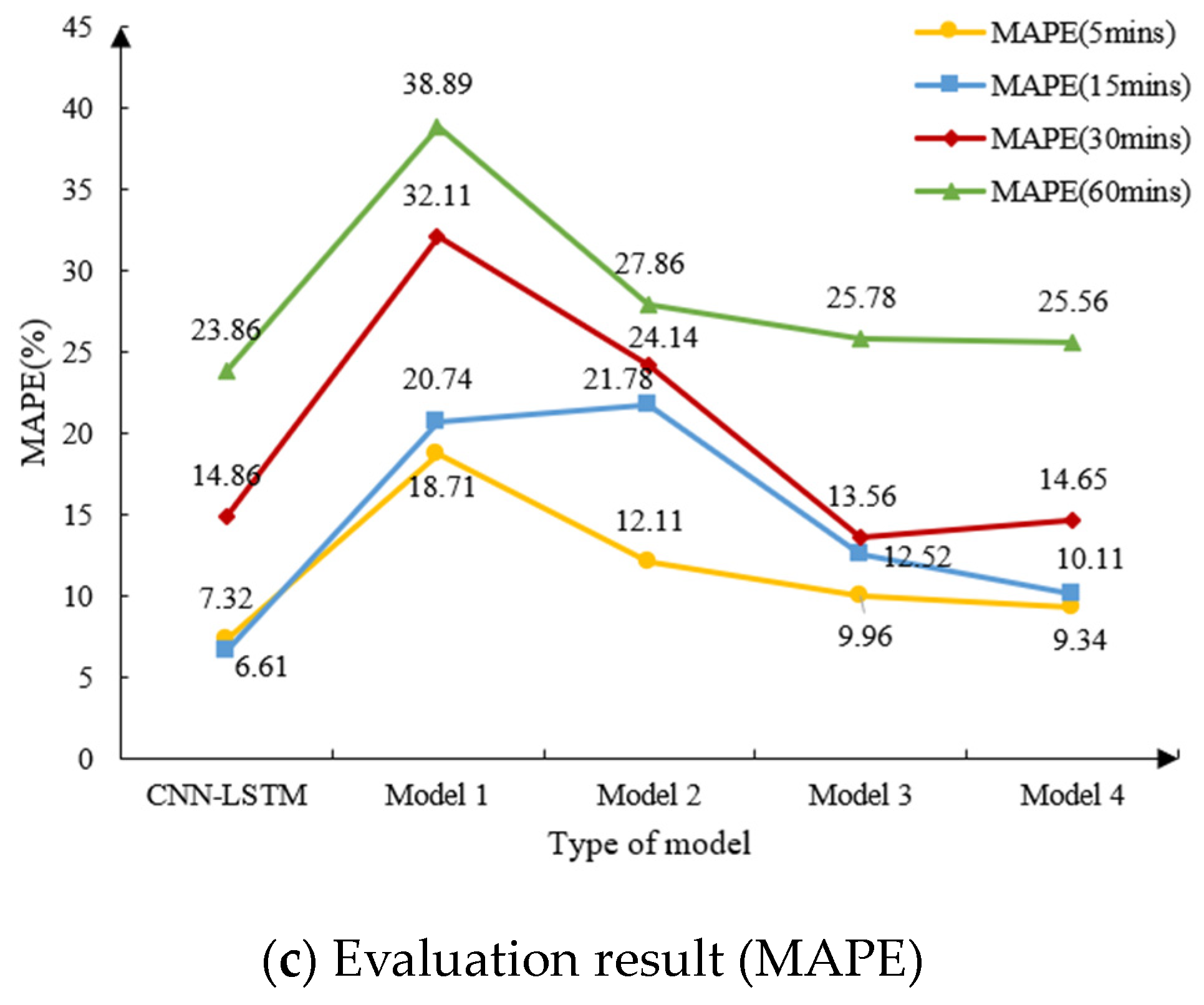
4.3.2. Evaluation of Traffic Flow Prediction Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gu, Y.; Lu, W.; Qin, L.; Li, M.; Shao, Z. Short-term prediction of lane-level traffic speeds: A fusion deep learning model. Transp. Res. Part C Emerg. Technol. 2019, 106, 1–16. [Google Scholar] [CrossRef]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Otoshi, T.; Ohsita, Y.; Murata, M.; Takahashi, Y.; Ishibashi, K.; Shiomoto, K. Traffic prediction for dynamic traffic engineering considering traffic variation. In Proceedings of the Global Communications Conference, Atlanta, GA, USA, 9–13 December 2013; IEEE: Piscataway, NJ, USA, 2014; pp. 1570–1576. [Google Scholar]
- Boto-Giralda, D.; Dfaz-Pernas, F.J.; Gonzalez-Ortega, D.; Díez-Higuera, J.F.; Antón-Rodríguez, M.; Martínez-Zarzuela, M.; Torre-Díez, I. Wavelet-Based Denoising for Traffic Volume Time Series Forecasting with Self-Organizing Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2010, 25, 530–545. [Google Scholar] [CrossRef]
- Chan, K.Y.; Dillon, T.S.; Singh, J.; Chang, E. Neural-Network-Based Models for Short-Term Traffic Flow Forecasting Using a Hybrid Exponential Smoothing and Levenberg-Marquardt Model. IEEE Trans. Intell. Transp. Syst. 2012, 13, 644–654. [Google Scholar] [CrossRef]
- Ch, S.; Anand, N.; Panigrahi, B.K.; Mathur, S. Streamflow forecasting by SVM with quantum behaved particle swarm optimization. Neurocomputing 2013, 101, 18–23. [Google Scholar] [CrossRef]
- Yang, H.J.; Hu, X. Wavelet neural network with improved genetic model for traffic flow time series prediction. Optik 2016, 127, 8103–8110. [Google Scholar] [CrossRef]
- Wang, K.; Ma, C.; Qiao, Y.; Lu, X.; Hao, W.; Dong, S. A hybrid deep learning model with 1DCNN-LSTM-Attention networks for short-term traffic flow prediction. Phys. A Stat. Mech. Its Appl. 2021, 583, 126293. [Google Scholar] [CrossRef]
- Zhan, F.; Wan, X.; Cheng, Y.; Ran, B. Methods for multi-type sensor allocations along a freeway corridor. IEEE Intell. Transp. Syst. Mag. 2018, 10, 134–149. [Google Scholar] [CrossRef]
- Yu, X.; Prevedouros, P.D. Performance and Challenges in Utilizing Non-Intrusive Sensors for Traffic Data Collection. Adv. Remote Sens. 2013, 2, 45–50. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Liu, L.; Dong, S.; Qian, Z.; Wei, H. A novel work zone short-term vehicle-type specific traffic speed prediction model through the hybrid EMD-ARIMA framework. Transp. B Transp. Dyn. 2015, 4, 159–186. [Google Scholar] [CrossRef]
- Xie, H.H.; Dai, X.H.; Qi, Y. Improved K-nearest neighbor model for short-term traffic flow forecasting. J. Traffic Transp. Eng. 2014, 14, 87–94. [Google Scholar]
- Dong, C.; Stephen, H.R.; Yang, Q.; Shao, C. Combining the statistical model and heuristic model to predict flow rate. J. Transp. Eng. 2014, 140, 06014001. [Google Scholar] [CrossRef]
- Dong, C.; Shao, C.; Richards, S.H.; Han, L.D. Flow rate and time mean speed predictions for the urban freeway network using state space models. Transp. Res. Part C Emerg. Technol. 2014, 43, 20–32. [Google Scholar] [CrossRef]
- Yang, L.H.; Zhang, C.; Qiu, X.Y.; Li, S.; Wang, H. Research progress on car-following models. J. Traffic Transp. Eng. 2019, 19, 125–138. [Google Scholar]
- Zhan, X.; Li, R.; Ukkusuri, S.V. Link-based traffic state estimation and prediction for arterial networks using license-plate recognition data. Transp. Res. Part C Emerg. Technol. 2020, 117, 102660. [Google Scholar] [CrossRef]
- Pan, Y.; Jin, X.; Li, Y.; Chen, D.; Zhou, J. A Study on the Prediction of Book Borrowing Based on ARIMA-SVR Model. Procedia Comput. Sci. 2021, 188, 93–102. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, M.; Lin, X.; Wang, Y.; He, F. Multistep speed prediction on traffic networks: A deep learning approach considering spatio-temporal dependencies. Transp. Res. Part C Emerg. Technol. 2019, 105, 297–322. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based Traffic Flow Prediction with Missing Data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Sun, X.; Munoz, L.; Horowitz, R. Mixture Kalman filter based highway congestion mode and vehicle density estimator and its application. In Proceedings of the American Control Conference, Boston, MA, USA, 30 June–2 July 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 2098–2103. [Google Scholar]
- Xu, D.W.; Wang, Y.D.; Jia, L.M.; Qin, Y.; Dong, H.H. Real-time road traffic state prediction based on ARIMA and Kalman filter. Front. Inf. Technol. Electron. Eng. 2017, 18, 287–302. [Google Scholar] [CrossRef]
- Narmadha, S.; Vijayakumar, V. Spatio-Temporal vehicle traffic flow prediction using multivariate CNN and LSTM model. Mater. Today Proc. 2021, SSN, 2214–7853. [Google Scholar]
- Do, L.N.; Vu, H.L.; Vo, B.Q.; Liu, Z.; Phung, D. An effective spatial-temporal attention based neural network for traffic flow prediction-ScienceDirect. Transp. Res. Part C Emerg. Technol. 2019, 108, 12–28. [Google Scholar] [CrossRef]
- Wiseman, Y. Autonomous vehicles. In Encyclopedia of Information Science and Technology, 5th ed.; Bar-Ilan University: Ramat Gan, Israel, 2021. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DF Detection Values for Traffic Flow | −12.628 |
|---|---|
| Confidence | Detection value |
| 1% | −3.434 |
| 5% | −2.863 |
| 10% | −2.568 |
| Time Step | MAE | MSE | MAPE (%) |
|---|---|---|---|
| 1 | 11.77 | 236.15 | 25.34 |
| 2 | 10.60 | 193.53 | 22.03 |
| 3 | 10.56 | 190.74 | 22.84 |
| 4 | 10.58 | 192.46 | 21.32 |
| 5 | 10.34 | 189.34 | 21.57 |
| 6 | 11.29 | 231.08 | 20.40 |
| 12 | 10.54 | 196.33 | 20.30 |
| 24 | 10.05 | 169.26 | 22.42 |
| Layers | Nodes | MAE | RMSE | MAPE |
|---|---|---|---|---|
| 1 | 64 | 11.77 | 15.37 | 25.34 |
| 128 | 11.49 | 15.01 | 24.36 | |
| 256 | 11.57 | 15.08 | 24.53 | |
| 2 | 64 | 11.46 | 14.98 | 24.33 |
| 128 | 11.33 | 14.10 | 23.36 | |
| 256 | 10.99 | 13.94 | 24.11 | |
| 3 | 64 | 12.00 | 15.39 | 22.23 |
| 128 | 11.43 | 14.13 | 22.36 | |
| 256 | 11.57 | 14.40 | 22.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Dong, C.; Dong, D.; Wang, S. Traffic Volume Prediction: A Fusion Deep Learning Model Considering Spatial–Temporal Correlation. Sustainability 2021, 13, 10595. https://doi.org/10.3390/su131910595
Zheng Y, Dong C, Dong D, Wang S. Traffic Volume Prediction: A Fusion Deep Learning Model Considering Spatial–Temporal Correlation. Sustainability. 2021; 13(19):10595. https://doi.org/10.3390/su131910595
Chicago/Turabian StyleZheng, Yan, Chunjiao Dong, Daiyue Dong, and Shengyou Wang. 2021. "Traffic Volume Prediction: A Fusion Deep Learning Model Considering Spatial–Temporal Correlation" Sustainability 13, no. 19: 10595. https://doi.org/10.3390/su131910595