1. Introduction
The impact of COVID-19 has led to discussions in the field of information and communications technology (ICT) about the need for more schools to provide online programs, allowing students to learn in flexible and diversified ways. In addition to existing massive open online courses (MOOCs), many online platforms have begun to appear on the market. In these contexts, instructors may have limited information that can be helpful in detecting student attrition due to the lack of face-to-face interactions [
1]. As a result, distance education has traditionally been associated with high drop-out rates, low completion rates and low success rates [
2,
3]. At the same time, one of the advantages of online learning platforms is that learning analytics can produce a large amount of behavioral information. In many ways, digital data may provide more useful and higher quality information compared to data collected through other, more traditional methods [
4]. Such data from learning analytics could be used to help researchers provide suggestions for improving the learning experience. If the time students spend on the platform is extended, students’ learning outcomes could be improved; thus, the feasibility of the online open-course business model may be promoted [
1]. Therefore, schools and universities have developed private learning platforms (i.e., learning management systems, LMS) which log students’ learning behaviors and instructors have attempted to utilize these data to improve the overall learning efficacy and to strengthen the students’ adherence to the courses both in online and offline settings [
2,
3,
4].
For hybrid learning settings (e.g., a mix of online and face-to-face components), Lu et al. [
5] developed a model that analyzed students’ online and offline behavior and predicted at-risk students one third of the way into the semester. Based on the analysis of the learning data, the use of the early warning system (EWS) served to predict students who were less likely to succeed before the end of the term. While the “hybrid” EWS could successfully alert students who were at risk of completing a course, at some level, the system still required “manual input” by the instructors in identifying vulnerable students.
However, in a fully online learning setting, the lack of asynchronous communication and interactions between the instructor and students can make it difficult for instructors to discern student success. The use of a system such as the EWS in making accurate predictions can be helpful in identifying problems among students early on. Current research suggests that EWS can be effective in both hybrid and fully online learning settings. The system serves to identify at-risk students and intervene in the early stages of the learning processes so that students have a better chance of completing the course [
6].
In recent years, researchers have utilized artificial intelligence (AI) techniques, especially machine learning methods, for automated at-risk student predictions through the EWS [
7]. Machine learning techniques have been used to predict students’ performance; however, most approaches do not consider the temporal relations that exist during learning [
8]. Hence, this study determines whether we can have better prediction accuracy when temporal information is factored in the learning. Then, the aim of this study is to maintain the accuracy of other studies using deep neural networks (i.e., deep learning) to predict whether students would pass the course and to determine how early the prediction can be made while maintaining sufficient accuracy. Teachers can utilize this EWS in their online courses to more easily detect at-risk students. We believe that the EWS will not only assist teachers but will also help students maintain their learning performance.
The contribution of this article is summarized as follows:
We developed an assessment of at-risk students based on their online learning behavior and provided information to teachers for devising early intervention strategies to improve students’ concentration in online courses.
We provide a single, lightweight model that can make weekly predictions by leveraging the characteristics of RNN models, thus contributing to online learning platforms that deploy EWS.
We conducted an experiment to show the effectiveness of the RNN model and we compare the employed RNN models to other machine learning and deep learning models. The employed RNN models demonstrated satisfactory results when there were few learning features.
The remainder of this article is organized as follows:
Section 2 presents a broad review of recent works on EWS, especially the studies that applied machine learning technology. We also discuss their disadvantages.
Section 3 introduces the methodology, feature descriptions and model settings applied in this study, followed by details of the experiments and discussions in
Section 4 and
Section 5, respectively.
2. Literature Review
As one of the mainstreams in the field of educational technology, learning analytics has become an influential method for sustaining students’ online learning [
9]. The lives of the younger generation are filled with information in their daily digital media digest menu (e.g., social media, podcasting) and their real lives (e.g., jobs, student clubs, school activities), thus highlighting the need for and value of continuously keeping students on track through timely learning analytics reports, such as an EWS [
10]. The results of an EWS are formative and can greatly help instructors warn students before they start to fail. Thus, the value of EWS as one type of learning analytics for the current era when nearly all courses occur online is strong. Learning analytics is defined as “an educational application of web analytics aimed at learner profiling, a process of gathering and analyzing details of individual student interactions in online learning activities” [
11]. Many institutions have invested in and customized systems for specific needs. However, the option for investment has not been economic [
12]. EWSs are normally built within the learning management system (LMS), where entire courses can be stored and administered online and are supported by various specific instructional needs.
In terms of developing EWS, many studies have applied conventional machine learning models. Bozkurt et al. [
13] developed an extensive survey and summarized the research directions for using AI in education into several categories. One of these directions is applying deep learning and machine learning algorithms to online learning processes. Traditional machine learning focuses on the results of algorithms, with more emphasis on mathematical inferences that can be verified or results that can be interpreted by humans. Such learning usually generates rules based on data and has a wide range of applications in different fields, such as computer-assisted teaching [
14], score prediction [
15], decision systems [
16], educational data mining [
17,
18,
19] and teaching strategies [
20]. Moreno-Marcos et al. [
7] used machine learning models, including random forests (RFs), generalized linear models, support vector machines (SVMs) and decision trees (DTs), to predict which students were at risk. To attain a high accuracy level, selecting discriminative features and providing sufficient learning data are required. However, the selection of features among different courses varies and the prediction accuracy drops to 0.5–0.7 when only partial learning data are used.
Alternatively, many researchers [
21,
22,
23] have used the multi-layer perceptron (MLP) model for automated risk prediction. Zeineddine et al. [
21] compared the performance between the MLP model and conventional machine learning approaches, such as k-means, k-nearest neighbors, naive Bayes, SVMs, DTs and logistic regression (LR). The authors used 13 features in their study, most of which elaborated on the learners’ knowledge level but not their learning behaviors [
21]. The accuracy of their results fell from 56% to 83%. The method proposed by Mutanu et al. [
22] reached about 83% accuracy using parameters such as grade point average (GPA) before enrollment. Lee et al. [
23] used the online learning behaviors of students before different exams to predict their scores on those exams. The accuracy was about 0.73–0.97 under different model settings.
In recent years, the ability of neural networks has greatly improved due to the development of deep learning techniques. Since deep learning has had many achievements in various fields, such as image recognition and natural language processing [
24], some studies have started to adopt deep learning techniques in the educational field. For example, Du et al. [
25] proposed a CNN-based model called Channel Learning Image Recognition (CLIR) and provided visualized results to let teachers observe the difference between the at-risk students and other students. In their study, they arranged the learning features each week as a two-dimensional image and applied CNN to make predictions [
25]. With the data of 5235 students and 576 absolute features, the recall rate of the CLIR models they proposed was over 77.26%.
When facing incomplete learning data, a common practice is to fill zeros in those missing fields. However, if the provided learning data are accumulated during different learning periods, the performance of the model is drastically reduced even with such operations. To avoid filling in zeros, which may alter the distribution of data, previous studies [
21,
22,
25,
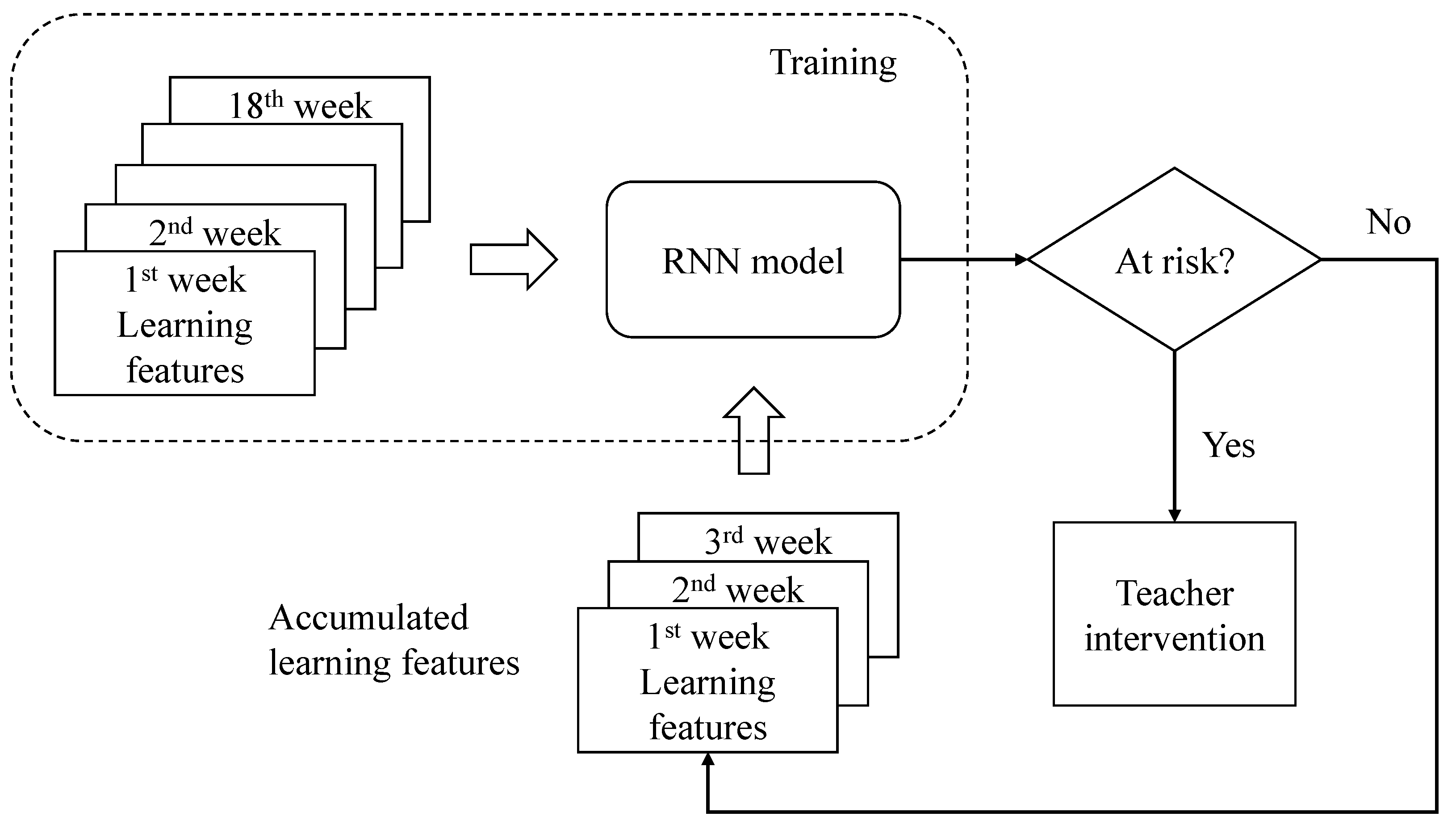
26] used the same length of time as the input when training the model. For example, if we want to predict the outcomes of students in the ninth week, we only provide the model with the cumulative nine weeks of data. However, in our opinion, it is not fair to decide whether a student passes or fails based on partial information. If the model is to be used in a real EWS, it should capture students’ learning patterns in that course across the entire semester and make accurate predictions before the end of the semester to identify and help students while they are still learning. Thus, the model used in this study was trained by providing the complete learning data for the entire semester and tested by only providing learning data over several weeks. By doing so, the model can learn the characteristics of students’ learning behavior throughout the course and make acceptable predictions with partial data.
When applying conventional machine learning, feature engineering (i.e., the selection of effective parameters to be included in the model) may be required to extract important features, while neural networks are much more convenient because they can extract useful features from raw data during the training process. Most studies have used MLP or CNN models for automated at-risk prediction. As the nature of these models tends to ignore the temporal information of raw data, this study chose another classic model: the recurrent neural network (RNN). Thus, this study used RNN in the EWS of online learning courses. RNN was first proposed by Hopfield [
27] and has had tremendous achievements in natural language processing in recent years, benefiting from improvements in computer hardware [
24,
28]. RNN, the neural network we chose, has the characteristic of remembering time sequence variations. Many studies have proven that the RNN model performs better than the CNN model when analyzing sequential data and there have been discussions about applying RNN models to educational data [
26,
29]. However, these methods still require learning features that may not be provided by existing platforms.
Learning is the accumulation of knowledge. The absorption of previous knowledge impacts the following learning outcomes. However, most conventional machine learning models cannot afford this requirement. Although we can make the model learn from sequential data, these models do not naturally memorize the changes on the timeline. In our opinion, RNNs have the potential to learn students’ learning patterns over time and it is not possible to determine whether students would pass the semester in the first several weeks. Therefore, the model should provide a certain level of confidence of prediction (i.e., probability of failure as the aforementioned) for both the instructors and the students. To achieve this, we trained the network with complete learning data to make it memorize the characteristics of learning behavior at different stages and predict whether students would be at risk at some point in the future. Furthermore, the CLIR experiments were conducted based on numerous subjects and many learning logs. However, for a traditional online platform, it is difficult to collect such a large number of subjects and data. This study found a useful yet effective model that can capture learning patterns in a relatively smaller dataset with fewer learning features. This study also discusses the performance of CLIR on the collected dataset and compares it with RNN models.
In summary, although many researchers have incorporated machine learning or deep learning techniques with the EWS, these methods have some inconveniences. First, some models require many learning samples and features. Second, to make predictions every week, they have to train the individual model each week. This study aims to propose a simple framework that can be more widely applied to most online earning platforms. To achieve this, we use RNNs to explore the following three questions:
Can RNN correctly predict the learning effectiveness of online course students?
Can RNN discover at-risk students with incomplete learning data?
With incomplete learning data, does RNN perform better than other conventional NN and machine learning approaches in terms of predicting at-risk students?
5. Discussion and Conclusions
Nowadays, neural networks have the potential for use in various applications for analyzing educational data. Various systematic analyses of the EWS for online learning are supported by deep learning techniques. However, some drawbacks are observed. This study attempts to find a “slim” approach to solve the previously mentioned concerns and optimize the overall process and user experience. The proposed method has several advantages: (1) it is a single model that can predict learning outcomes for each week, (2) the model used in this study is lightweight and has fewer parameters than other deep learning-based models and (3) we only consider common features that can be acquired by most online learning platforms, but provide convincing prediction results.
This study utilizes the characteristics of the RNN model for discovering at-risk students in the earlier stage of semesters. This study proves that the RNN model can successfully capture students’ learning patterns over time, indicating that it can be used to predict the learning outcomes of students with high accuracy. Furthermore, for the models SRN, LSTM and GRU, the F-scores range from 0.49 to 0.51 at the sixth week. The F-scores demonstrate a steady increment after that time, showing that the proposed method can be used in an EWS. Further, the performance of the model was also better than that of conventional machine learning models, such as DT and SVM. Comparing with another deep learning-based model, the SRN, LSTM and GRU had better recall rate than the CLIR because they are able to memorize the learning pattern thoroughly. Our results show that the RNN models can capture students’ learning behaviors in a short period and provide predictions in the early stages of the semester. The models used in the study first collected a full semester of students’ learning data and provided reliable predictions for another semester dataset after the first third of the period so that teachers can be notified about those who are at high risk and intervene early to remind students that they need to keep up with the learning or seek academic help.
Even though other models may have better precision or recall rates than RNN models, the proposed framework can also have different precision and recall rates by adjusting the threshold of the prediction probability. A high recall rate implies that the system finds more at-risk students, whereas a high precision rate implies that students who are warned by the system are actually at-risk students. By contrast, a high precision rate usually comes up with a low recall rate, indicating that many at-risk students are missed by the system. In our opinion, the choice of focusing on precision or recall rate depends on the target that the EWS is serving. If the EWS is serving teachers, we could have a higher recall rate because teachers tend to find all at-risk students. However, if the system is designed to warn students, it should have a higher precision rate to reduce false alarms, which are bothersome for students.
There are several directions for future discussion. First, the data used for the experiments were imbalanced. However, the performance of the model was not significantly affected. Further experiments could apply such a model to a highly imbalanced dataset to see if the prediction accuracy of the model is affected. Second, the experiments in this study were conducted from a general education curriculum; foundation courses could be considered to evaluate the generalizability of the model. Third, our results showed that the students’ learning activities stabilized after six weeks, which was one-third of the semester. Although this finding echoes the results obtained by Owen et al.’s [
5] study, future researchers can still try to gain prediction results at other prediction periods by testing the model on other platforms or collecting more learning data. Lastly, future research could apply the EWS to the course in the new semester to see if the failure rate decreases.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}