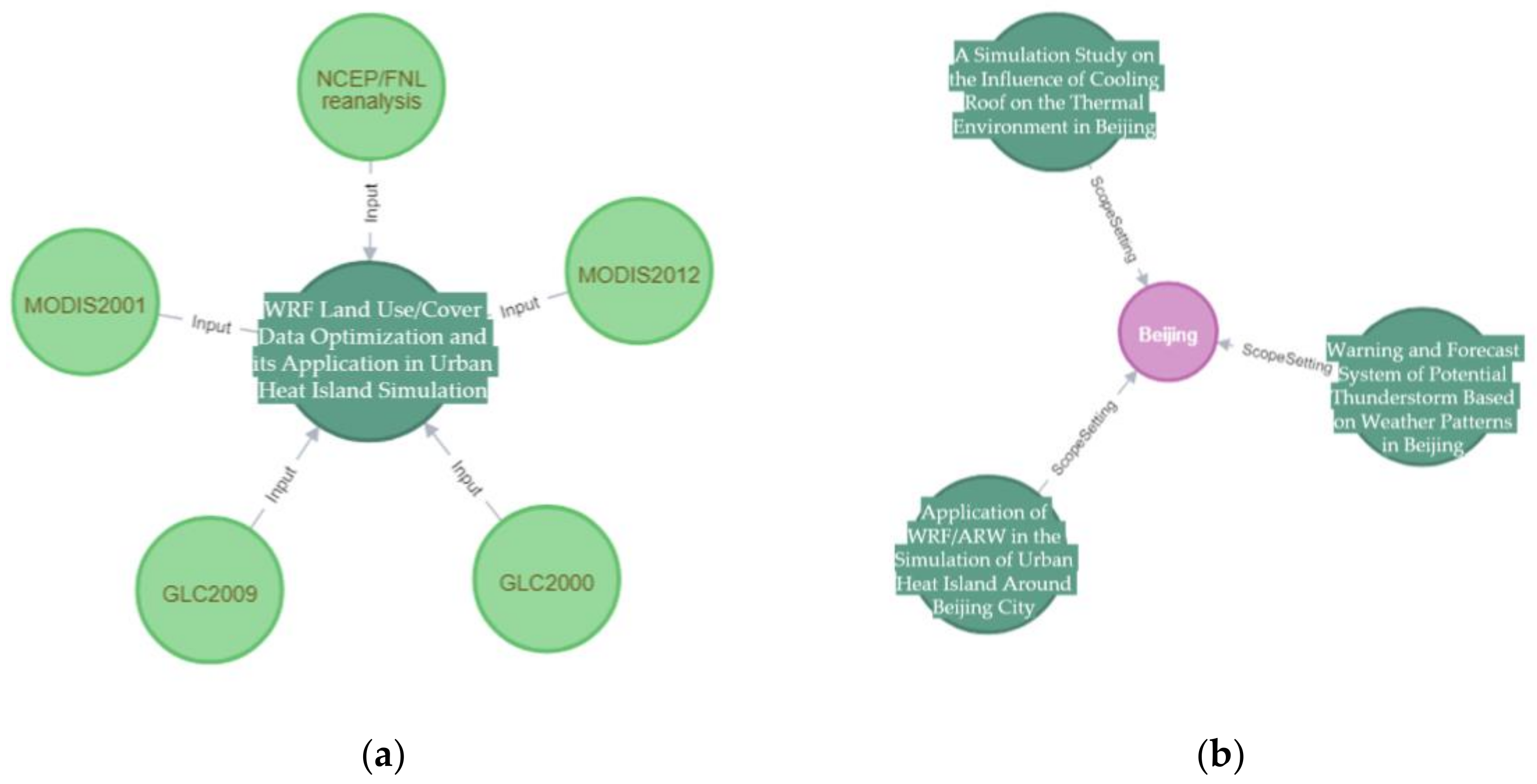
Under the guidance of domain ontology, the data layer of the knowledge graph is constructed. The literature information, such as the author, institutions, and key words are a kind of important knowledge of the meteorological simulation research; they are always displayed in the info box of the literature web pages in a semi-structured form. Hence, in this research, the web crawler was employed to parse the HTML codes of the web pages to obtain the literature information and store them in the structured data sheet for knowledge graph construction.
Regarding the simulation knowledge in unstructured literature content, a knowledge extraction model based on BiLSTM-CRF was used to recognize and extract the knowledge. The structure of the model is shown in
Figure 2. It contains 5 layers, including an input layer, embedding layer, BiLSTM layer, CRF layer, and output layer.
3.2.1. Input Layer and Embedding Layer
The corpus was input into the model sentence by sentence. The pure character-level input lacks word-level information; likewise, the pure word-level input is very dependent on the accuracy of text segmentation, and word segmentation errors will cause entity boundary recognition errors. Therefore, in the input layer, the character-level and word-level information was integrated and input into the model, which can make full use of the context information.
The natural language cannot be processed by the BiLSTM directly; the semantic information in the text needs to be digitized for further processing. Hence, in the embedding layer, the input words and characters are transformed into eigenvectors by word embedding. Word embedding is a language processing model trained by corpora, such as the continuous bag-of-words (CBOW) and Skip-Gram (SG) model. Based on the token in the corpus and its context, the word embedding model can map each token into the numeric vector space and generate an eigenvector with semantic information [
48]. Word2vec, a word embedding tool provided by Google, was employed in this study to convert the word and character inputs into eigenvectors, which can be processed by the subsequent BiLSTM-CRF model.
3.2.2. BiLSTM-CRF Model
Since the knowledge in meteorological simulation literature is distributed in plaintext, natural language processing technology is required to process the semantic information and recognize the knowledge entity. The BiLSTM-CRF model is a natural language processing model based on deep learning, which is widely used in knowledge recognition and extraction; it has an excellent performance in unstructured text processing [
49]. Knowledge recognition and extraction is essentially a sequence labeling task, an input sequence of sentence is processed by the BiLSTM-CRF model and it outputs a label sequence, which labels the knowledge entities in the sentences. The BiLSTM-CRF model is composed of two layers of long short-term memory (LSTM) with forward and backward directions, and a layer of conditional random field (CRF).
LSTM is a modification of the recurrent neural network (RNN); it expands the computing unit of the traditional RNN and uses a gating mechanism, which can solve the problem of gradient disappearance or explosion in the processing of long sequence data. The structure of the LSTM unit is shown in
Figure 3.
In sentences processes of LSTM, through the gating mechanism, it is can selectively change the update and retention in the processing of the information data stream [
50]. The formulas of the gating mechanism are expressed as follows:
In the formula,
is the output of the hidden layer at the previous moment,
is the input at the current moment,
and
are the activation functions,
is the weight matrix, and
is the bias vector.
,
, and
are the outputs of the forget gate, input gate, and output gate, respectively.
is the information to be added to the cell state,
is the updated cell state at the current moment, and
is the final output result of the current LSTM unit [
51].
In the text processes, the forget layer can analyze the current input and delete the useless information of the former text. The input layer controls the useful information that can be added into the information stream. Then, the results of the forget layer and input layer are processed and integrated in the output layer, which is the final output of the current token. LSTM can control the long-distance retention of effective information and the rapid forgetting of useless information, which is very suitable for processing long text sequences. BiLSTM is composed of a forward LSTM and a backward LSTM; in text processing, the text can be processed from both front and back directions, and the semantic information of the context can be fully considered.
However, in natural language, there are some syntactic constrains in the sentences, which cannot be captured by BiLSTM precisely; only use of the softmax function in its output layer may lead to prediction errors. Therefore, CRF is used to compensate for the shortcomings of BiLSTM in syntactic feature processing [
52]. CRF is a discriminative probability model, which is a sequence processing algorithm based on hidden Markov model (HMM) promotion. It can receive an input sequence such as
X = {
x1,
x2,
x3,
x4, …,
xn} and output the target sequence
Y = {
y1,
y2,
y3,
y4, …,
yn}, which can predict the conditional probability of output variables by input variables while considering the relationship between the front and back position features of each output [
53]. Hence, in this study, the outputs of the BiLSTM layer are fed into a CRF layer, which is based on the BiLSTM-CRF model, while the semantic information and syntactical constrains in meteorological simulation literature can be fully processed to realize more accurate extraction of meteorological simulation knowledge.
The structure of the BiLSTM-CRF model is shown in
Figure 4. The meteorological simulation literature text is segmented into token sequences and fed into the model; when the BiLSTM-CRF model processes the input sequence
X = {
x1,
x2,
x3,
x4,…,
xn}, for the input
xt, the forward LSTM calculates the context eigenvectors
before x
t, and the backward LSTM calculates the context eigenvectors
after x
t. Splicing the calculation results in the forward and backward LSTMs as
, which is the complete semantic eigenvectors representation of the input token
xt. The input eigenvector
is trained by the BiLSTM network to obtain the label prediction probability matrix
in the sequence. Then,
is input into the CRF layer, and the state transition matrix
between the front and back labels is calculated in the CRF layer. After processing by two layers, the final label prediction result is
Y = {
y1,
y2,
y3,
y4, …,
yn}, and the probability of prediction result is:
is all the possible labels of the input
X,
refers to the right label of
X,
s(
X,
Y) represents the probability of the prediction, and
s(
X,
Y) is defined as:
represents the probability that the X in position i is predicted as label
.
represents the probability of transition from
to
in the state transition matrix calculated by the CRF layer. Take the logarithm of both sides of
to obtain the maximum likelihood function of sequence prediction as:
Select the label with the largest prediction score as the final label sequence prediction result.
3.2.4. Construction of Training Dataset
As the BiLSTM-CRF model is a supervised learning method, a large-scale training corpus dataset is required to train the model; however, the meteorological simulation is a professional field, the corpus in open fields is not applicable for meteorological simulation knowledge extraction, and there is no ready training dataset that can be used to train this model. Hence, a training dataset generation method by manual annotation and data augmentation is proposed. First, the corpus annotation scheme was defined based on the study of meteorological simulation theories, ontology, and expert guidance. The entities and attributes defined in the ontology library, including SimulationScope, InputData, ParameterScheme, SimulationTime, and ResultValidation, were annotated by the BIOES annotation scheme (‘B-entity’ refers to the beginning word of an entity, ‘I-entity’ refers to the intermediate word, ‘E-entity’ refers to the end word, ‘S-entity’ refers to a single word as an entity, and ‘O’ refers to other nonentity words). The annotation scheme is shown in
Table 1.
Based on the annotation scheme, the corpus was manually annotated, and each character in the corpus was regarded as a token and matched to a corresponding label.
Figure 5 shows the annotation for a sample sentence: “The center of simulation area is 30° N,100° E. The WSM5 scheme was selected as the microphysical parameterization scheme (in Chinese).” As the exported annotation shows, a complete knowledge entity is composed of a B-entity label in the beginning, several I-entity labels in the middle, and a E-entity label in the end sequentially.
However, the construction of datasets by manual annotation is so dependent on the professional knowledge of annotators that it is time consuming and labor intensive. In this study, a small-scale training dataset was constructed by manual labeling under the guidance of experts, and the dataset was expanded by the data augmentation method to obtain a large-scale dataset that complied with the requirement of model training [
54]. The data augmentation methods proposed in the article include the following:
Choose n words randomly and replace them with their synonyms
Choose n words randomly and insert their synonyms behind them
Choose n words randomly and change their positions
Choose n words randomly and delete them.
According to the recommended parameters in this article, the hand-crafted dataset was augmented and expanded to 10 times the size, which can be used for BiLSTM-CRF model training. The article claimed that the augmentation method above will not cause obvious semantic changes in the corpus. Additionally, some man-made noise was introduced into the dataset, which can improve the generalization ability of the model. In the case of an insufficient corpus, using data augmentation can significantly improve the model training result.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}