This experiment selected the eastern region of the American Electric Reliability Council of Texas (ERCOT) power grid as the research object. As shown in
Figure 7, the ERCOT power network covers about 75% of Texas, and the ERCOT power market manages more than 90% of the users in Texas. Because Houston is the main resource node in the eastern region, energy demand accounts for the vast majority of the eastern region. This experiment selects ERCOT’s eastern region’s power report [
39] as the experimental database. This experiment’s data use the hourly data of 1057 days from January 1, 2015 to November 30, 2017 as a sample. The experiment randomly shuffles the input and output into samples, improving the generalization of the model. So, 80% of the total sample was selected as the training set and 20% as the test set. Considering that the geographic range of Texas in the Northern Hemisphere is approximately 25°50′–36°30′ north latitude, 93°31′–106°38′ west longitude, according to the local climate change and local people’s perception, we use the local Texas climate to divide the seasons. The approximate seasons are divided into the following
Table 2.
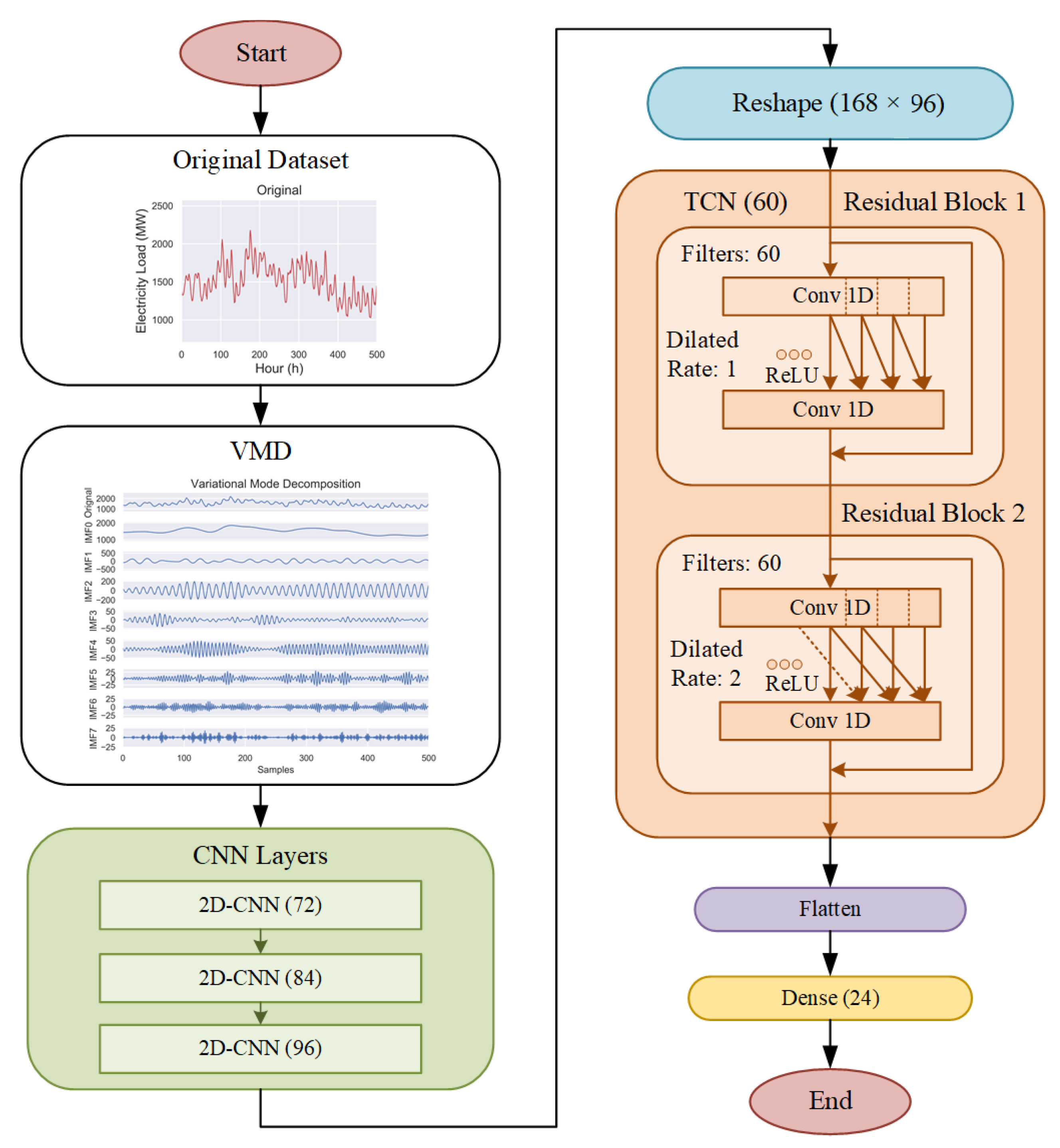
Data Preprocessing
In this experiment, the VMD algorithm is used to decompose the original load data into eight relatively stable IMFs. The number of decomposed modes and the optimal center frequency are obtained through a grid search algorithm. It is verified that the loss value of each mode after decomposition is within the allowable range, among which,
,
the decomposition effect of the original electricity price is shown in
Figure 8, where the decomposition effect is shown for the entire year of 2015. It can be seen from
Figure 8 that the low-frequency signal has a smoother trend than the original signal, and the trend of the low-frequency part is roughly in line with the original signal, indicating that the VMD decomposition can effectively separate noise and is more convenient for prediction. From the figure, the low-frequency part of the four seasons of a complete year fluctuates more smoothly, which is one reason why the experiment chose to forecast regardless of the season.
In the feature selection part, because the experiment mainly uses load data for training, in the time series analysis process, the autocorrelation function (ACF) is often used to evaluate the degree of influence between the events before and after the event so that this experiment will be in the database. The hourly lag of 5 weeks and the daily lag of 2 weeks selected for the same time, as evaluated using the ACF, are shown in
Figure 9.
It can be seen from the blue line in
Figure 9a that the autocorrelation coefficient reaches its peak when Lag is one day, which indirectly reflects the high correlation between load changes at the same time, so the input data are expanded to 7 × 24 matrices so that the model can not only extract the relevant features of the change between hourly load in a day but also extract the change characteristics of the same hour in a week. When Lag reaches the first week, the second week, etc., it can be found that the power load has a certain weekly change trend, as shown by the red line in
Figure 9a. Therefore, the power load data of the previous seven days are used as input data, according to which is the most suitable.
Figure 9b selects the autocorrelation coefficient image made by the time series of the power load composition at the same time at 12:00 a.m. in the middle time, and displays it in the two states of Lag, verifying the conclusion from
Figure 9a at the same time the load changes are highly correlated, with weekly trends, etc.
To evaluate the accuracy of the model, the commonly used Mean Absolute Percentage Error (MAPE) and Root Mean Square Error (RMSE) in the field of time series forecasting are used to evaluate the accuracy of the model. The equation is as in the following equations:
where
represents the true value,
represents the predicted value, and
represents the number of samples.
This experiment is for daily power load forecasting. Therefore, MAPE and RMSE can be obtained by comparing the predicted value with real value every day. In order to better show the performance of the proposed model, the MAPE and RMSE of each day in the test set are drawn into quartile Figure, as shown in
Figure 10. It can be found from the figure that the proposed model not only has the smallest MAPE and RMSE compared to each model but also the variation range of MAPE and RMSE is relatively concentrated.
Table 3 shows the minimum MAPE, maximum MAPE, average MAPE of each model.
Table 4 shows the minimum RMSE, maximum RMSE, and average RMSE values of each model. The average MAPE and RMSE are better than the comparison model.
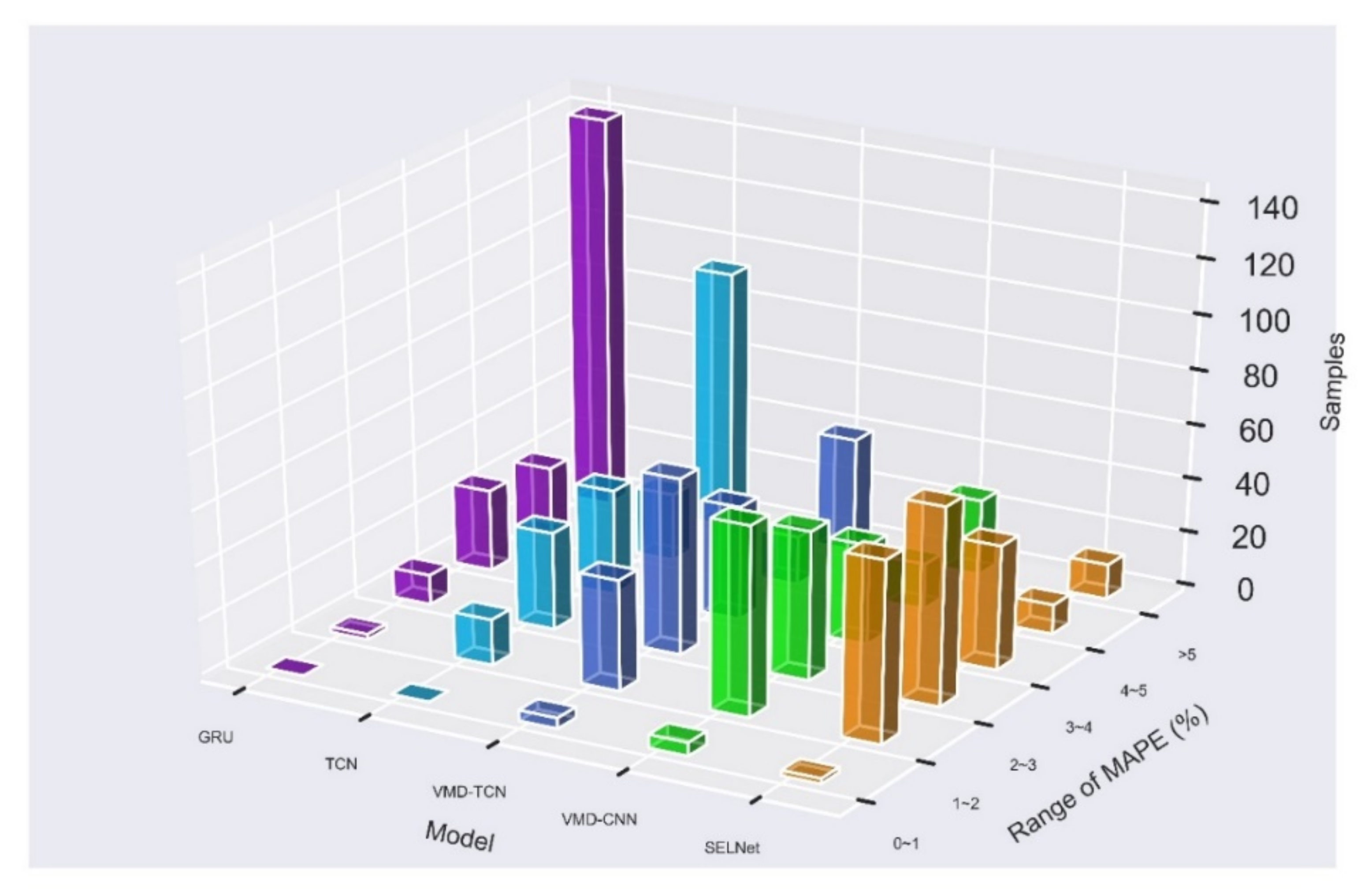
In
Table 5, the prediction results of each model test set MAPE in the range of 0–1%, 1–2%, 2–3%, 3–4%, 4–5%, and days greater than 5% are performed According to statistics, it can be found that 67% of the GRU model has a MAPE value greater than 5%, so the model prediction performance is poor. The TCN model has a MAPE value greater than 5%, accounting for 45%, which is better than GRU, and by combining TCN and VMD algorithms, it can be found that the value of MAPE greater than 5% drops to 20%, which verifies the effectiveness of the VMD algorithm. After the VMD algorithm is decomposed, the data are combined with CNN to extract features from expanded matrices and learn the features through the fully connected layer. The VMD-CNN model has a MAPE greater than 5% and only accounts for 13% of the model performance has been further improved. However, compared with the proposed model whose MAPE is greater than 5%, 6% is still slightly inferior. Moreover, each sample of the proposed model’s MAPE is mainly concentrated in 1–3%, which shows that the model can generally predict the power load of the next day well. Therefore, using a CNN to extract features from the expanded matrices, reshaping them into a time series, and applying a TCN to learn the time series and realize the final forecasting is an effective approach.
For a more intuitive comparison,
Figure 11 was drawn. The histogram drawn by the days with MAPE greater than 5% shows that the model performance rankings are GRU, TCN, VMD-TCN, VMD-CNN, and Proposed, respectively. It can also be found in
Figure 11 that the addition of VMD has increased the basic performance of the model, that is, the range of the sample MAPE mode up to 2–3%, and the use of CNN has further improved the basic performance of the model to 1–2%. The combination of VMD, CNN, and TCN increases the number of samples in the MAPE range of 2–3% while ensuring that the number of samples in the MAPE range of 1–2% is basically unchanged; it makes the model performance more stable and concentrated.
Figure 12 shows the comparison of each model’s prediction results on the day when the proposed model predicts the largest and smallest MAPE, and a day is randomly selected within the MAPE interval where the mode is located to represent the general level of the model. The selected MAPE value is 2.42%. It can be found that the general prediction result of the proposed model is very close to the true value, and the worst prediction result can basically show the trend of load change.
To further verify the generalization of the model in each season, the randomized sample database was counted, and it was found that the number of samples in the spring, summer, autumn, and winter in the test set were 55 days, 55 days, 45 days, and 57 days, respectively. It accounts for 25.94%, 25.94%, 21.22%, and 26.89% of the total number of samples in the test set, as shown in
Figure 13a.
It shows that the samples in each season in the test set occupy a certain proportion. Continue to count the number of samples in each season with a MAPE greater than 5% in the test set. The four seasons are 3, 1, 1, and 8, as shown in
Table 6, each accounting for 5.45%, 1.81%, 1.81%, and 14% of the total number of samples in each season in the test set.
Figure 13b shows that the number of samples with a MAPE greater than 5% is minimal compared to the total, especially in the three seasons of spring, summer, and autumn, which can be almost ignored, while the performance of the winter model is relatively poor, considering the large difference in winter temperature, There are many festivals, so there are certain changes in residential electricity consumption, which leads to a relatively large number of winter models predicting MAPE greater than 5%.
To show more clearly the prediction performance of the proposed model in four seasons, the number of days in which the MAPE is in each range in the four seasons was counted, as shown in
Table 6 and shown in
Figure 14. It is not difficult to see that the model performs well in the four seasons. The MAPE is almost completely concentrated in 1–4%, especially 1–3%. The proportion is the largest. Although there are some samples with a MAPE greater than 5% in winter, the proportion is relatively small and does not affect the performance of the model’s overall prediction effect. The overall effect is between 1% and 4% of the MAPE, with 2–3% the most. Therefore, the proposed model can make accurate predictions in each season. The best days and worst days for each season in the test set and examples of one-day prediction results in the range of the MAPE mode used to represent the model’s general prediction level are given in
Figure 15,
Figure 16,
Figure 17 and
Figure 18 as follows.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}