3.1. Theoretical Framework
The formal setting of this methodology is based on statistical decision theory (STD). STD is concerned with making optimal decisions in the presence of statistical knowledge (data), which sheds light on some of the uncertainties involved in the decision problem [
75]. STD is an essential mathematical theory used in machine learning and social informatics research fields. The formal definition of STD for a 2 class problem is given by the determination of the joint distribution function:
where:
p is the probability,
X is an input vector that consists series of values (a set of data),
C is a class,
k is a constant that takes values of 1, 2.
Assume y is a correspondent vector of the target variable (1 or 0), and let y = 1 correspond to class C1, and y = 0 correspond to class C2. The theory is concerning with how to make an optimal decision given the reasonable probabilities in a task of assigning an input vector (X) value to a suitable class (C1, C2); SDT has two main objectives in performing this task:
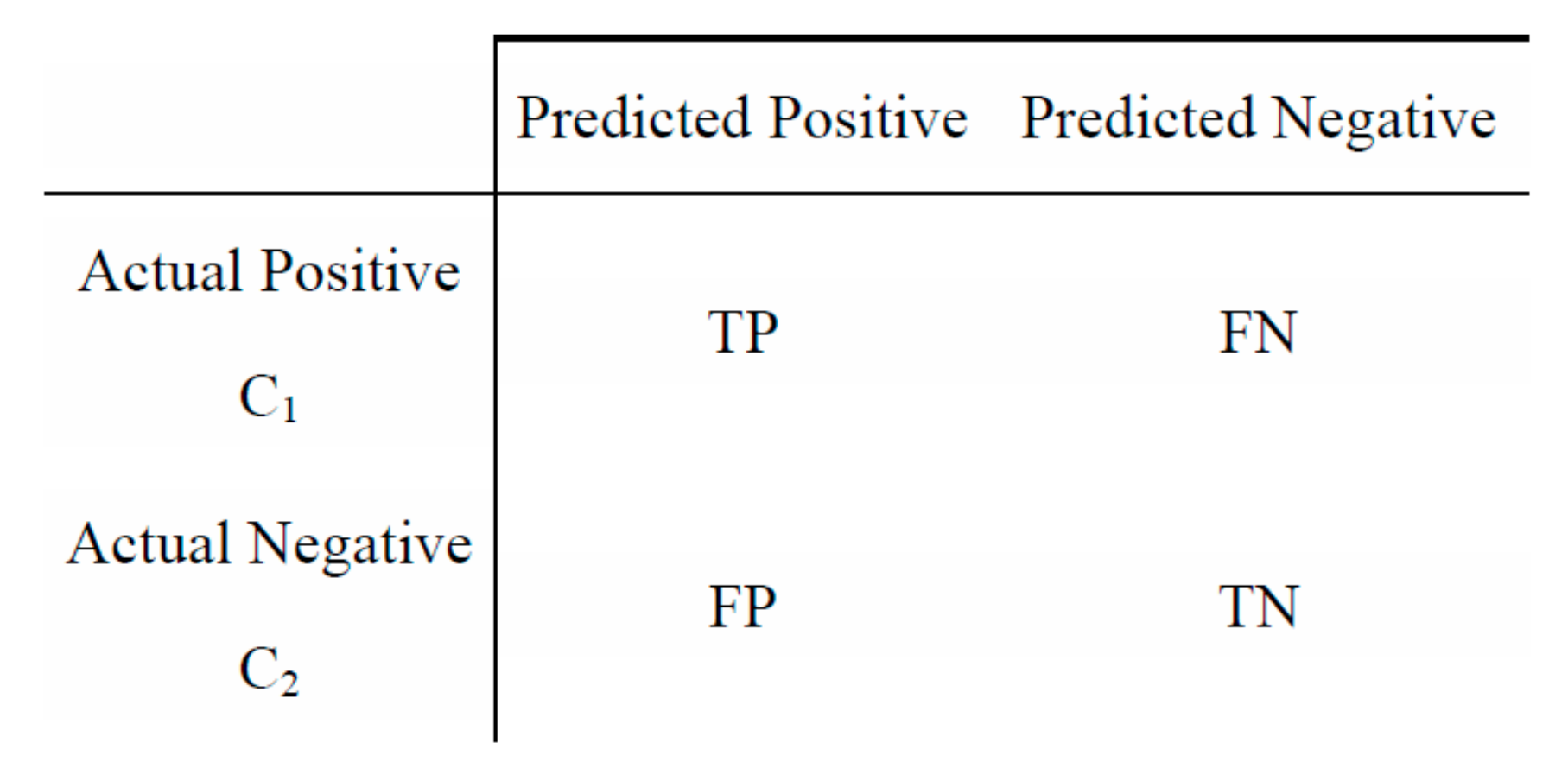
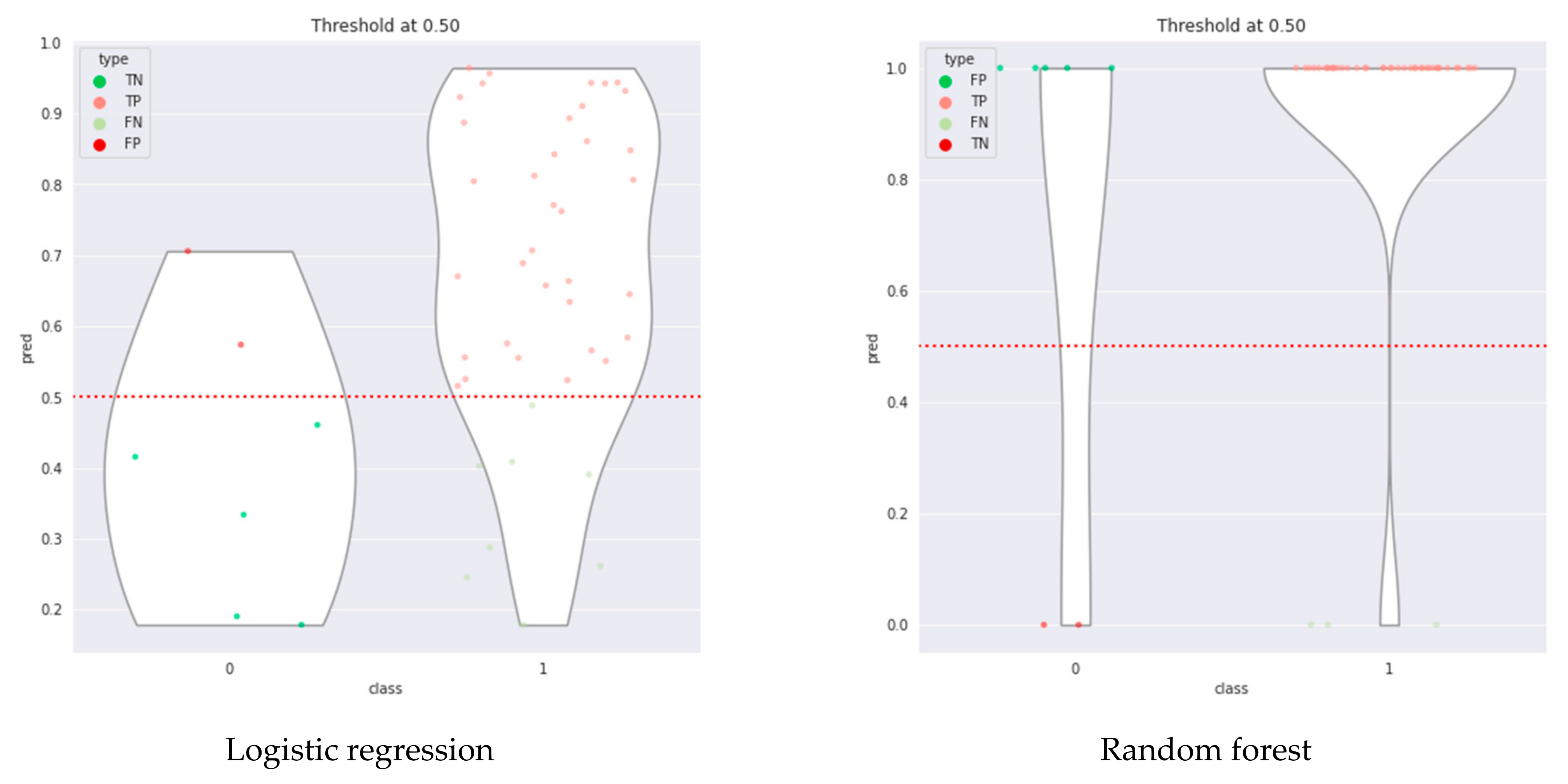
In the case of two-class problems, drawing a confusion matrix (
Figure 2) would help visualize the theory. The performance of machine learning algorithms is also typically evaluated by a confusion matrix.
In the confusion matrix, TN is the number of negative examples correctly classified (True Negatives), FP is the number of negative examples incorrectly classified as positive (False Positives), FN is the number of positive examples incorrectly classified as negative (False Negatives), and TP is the number of positive examples correctly classified (True Positives).
To minimize the given wrong assignment approach, we divide the input space into decision regions (
Rk), one region for each class (
Rk is assigned to class
Ck). While doing this operation, a mistake occurs when an input vector value belonging to
R1 is assigned to
C2 or a vector value belonging to
R2 is assigned to
C1. The equation given below used to calculate this mistake:
where:
X is an input vector that consists series of values (a set of data),
C1 and C2 are the two classes,
Rk is decision regions,
k is a constant that takes the value of 1 or 2.
To minimize misclassification, X must be assigned to the classes that have provided a smaller integral value.
To reducing the expected loss, assuming that for a new value of
X, we assign it to class
Cj whereas the real correct class is
Ck. This means we have incurred a loss
Lkj, which is the
k,
j element of the confusion matrix. The following equation gives the average loss function:
where:
Lkj is an occurred loss value,
X is an input vector that consists series of values (a set of data),
Ck is the actual correct class,
Rj is decision regions,
j, and k is the constant of regions that take the value of 1 or 2.
The best solution is one that minimizes the average loss function. For a given input vector X, the uncertainty in the correct class is expressed through the joint probability distribution p(X, Ck).
The interpretation of the method under a short description of the STD presented as follows:
Predictive analysis, especially in machine learning classification, is tried to estimate the future possibility of an event in advance from the historical set of data related to that event. Simply the researcher needs the collection of data features to conduct the analysis. The reason for additional questions in any survey is to collect more information related to the subject issue.
It is common to perform a survey study to measure people’s opinions on a specific topic, and all surveys have a set of questions for different analysis purposes. This case study’s prime concern is to ask a correct set of questions related to the mobility preferences of university students of a rural town in a proper way while respecting their sensitivities. Therefore the structure of the questions did not contain any political or misleading contents.
The initial attempt with direct questioning is intended to test the responder’s reaction to demanding more PBS in daily life and resulted in an outcome below what is typically expected. This situation displays the influence of a status quo that we mentioned earlier. The status quo that the sustainability and availability of PBS in Japan’s rural regions have been in a continuous declining state for a long time. This method is an attempt to discover the consequences of this condition to current-day mobility demands.
The secondary questioning regarding the same problem is intended to discover a concrete development in the responder’s mind. However, it is still not enough to measure other daily life indicators’ impact. Therefore, to collect more information about the PBS demand, three sets of questions, a demographical background, travel behavior, and overall life satisfaction prepared and asked the participant.
Many factors can affect anyone’s daily life mobility needs. In this case, those factors’ weight implications to the overall mobility requirement are intended to reveal. In this way, this method could explain the reasonability of any increase or decrease in predicting a specific issue.
Although there are numerous other types of classifiers in machine learning, the character of data type and the size of data are of the utmost importance to choose one effective classifier for the desired purposes. For this case, before proceeding any further, the collected data analyzed and processed statistically to better understanding.
Therefore, by the formal definition of the STD, this methodology is divided into three stages to analyze the current PBS situation in Japan’s rural city of Kitami. First, we surveyed university students’ demand rate regarding the current PBS. After completing the survey section, we proceeded with the statistics and hypothesis test to understand the data’s characteristics. Finally, we used the data as input to develop a machine learning prediction model based on STD to discover the potential of the user’s best demand rate for PBS.
3.2. Data
The data was collected through a 2019 questionnaire titled “Student daily life after school hours” conducted at Kitami Institute of Technology, where approximately 1800 undergraduate students are enrolled [
76]. The information bulletin regarding the survey was spread all around the campus, and the data collection period took a month. Responders accessed the web link of an online form by reading the QR code on the notification form with the QR code reading feature of a free application for instant communication on their smartphones. The survey questions collected information about students’ demographics, transport preferences, and overall satisfaction with their academic life. The survey was responded to by 250 students, in other words, 14% of the student population.
Usually, surveys with low response rates and nonresponse bias raise a notable concern. In survey sampling, bias refers to the tendency of a sample statistic to systematically over-or under-estimate a population parameter. In theory, the optimum way to identify bias in the estimates from a sample of respondents would be to compare the estimates to actual population values; however, population values are not always available [
77].
Furthermore, a survey’s response rate reflects the collected data quality and reliability as an essential indicator. Since there is no agreed-upon minimum acceptable response rate, it largely depends on creating, distributing, and managing the surveys [
78].
A conducted study in Japan found evidence of response rate bias for univariate distributions of demographic characteristics, behaviors, and attitudes. Still, during examining relationships between variables in a multivariate analysis, controlling for various background variables, findings do not suggest bias from low response rates for most dependent variables [
79]. Moreover, the survey environment, how questions are asked, and the respondent’s state define problems in measurements. For instance, when we analyze data from another survey study focusing on the health-promoting lifestyle profile of Japanese university students, we see that the response rate decreases as the student year increases [
80]. Nevertheless, in our case, absolute reliability can only be provided by applying the same questionnaire to new students enrolling each year in university and comparing the results obtained. However, at present, the distribution of sex and origin of responders generated by this survey data also matches the current student population characteristics.
There are also statistical formulas available for determining the size of the sample [
81]. The two critical factors for these formulas are the margin of error (in the social research, a 5% margin of error is usually acceptable) and the level of confidence that the survey findings’ results are accurate (the typical confidence levels used are 95 %) [
82].
The size of the collected responses and total student population calculates the margin of error as ±5.76% with a 95% confidence level. A 95 percent confidence level means that 95 out of 100 samples will have the actual population value within the specified margin of error of ±5.76 percent.
The obtained response rate from the student survey still encouraged us to exhibit the differences and similarities in the student community of the university town of Kitami within a given limit.
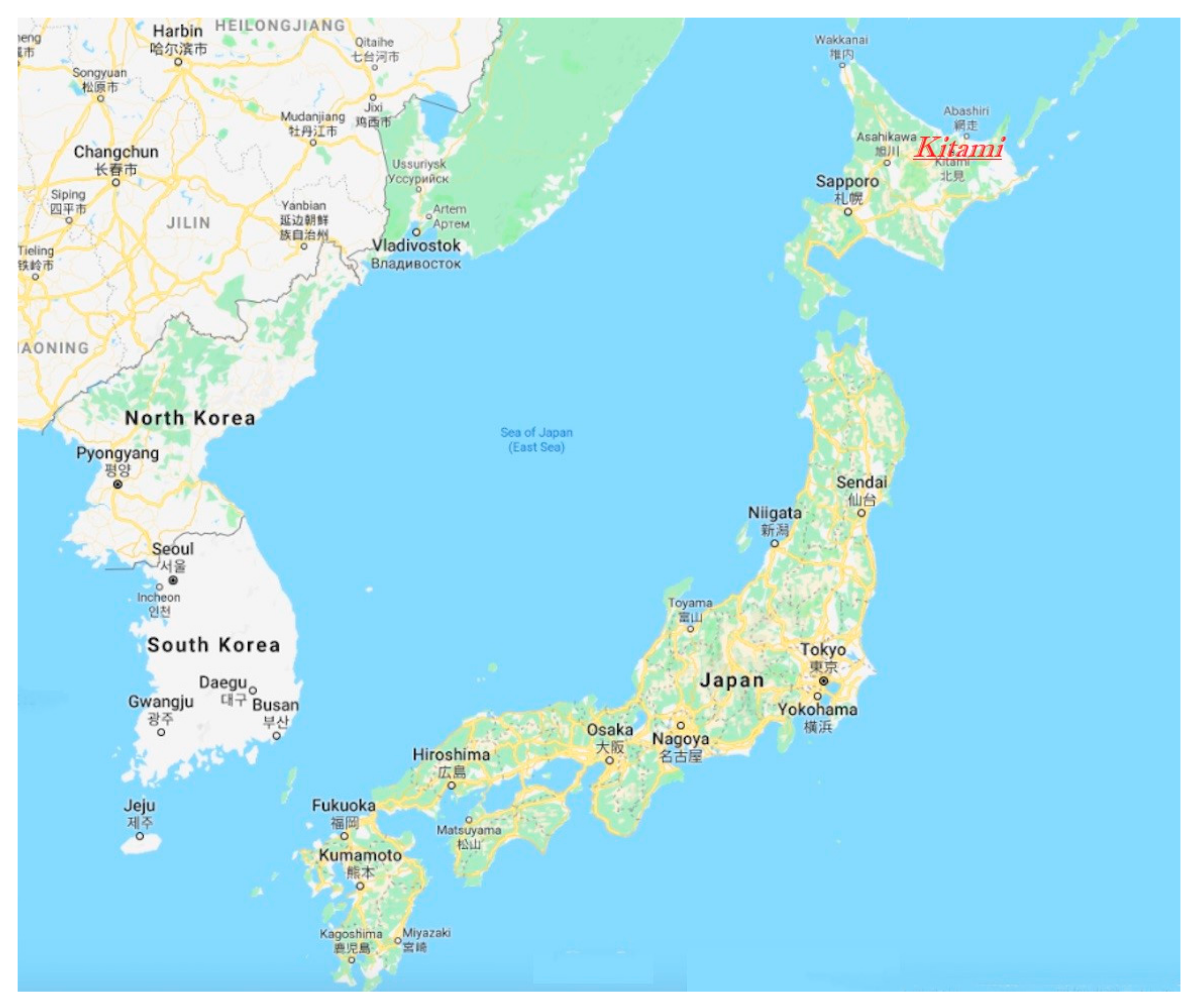
The urban outline of Kitami city is distributed sparsely, with winter periods mainly being cold and snowy compared to the rest of Japan [
83]. The university campus area is 2.5 km from the city center. Transportation in Kitami city is highly automobile-dependent (152.4 automobiles per 100 people) [
84], which is much higher than the average of the whole Hokkaido prefecture (68.67 automobiles per 100 people) [
85]. The offered frequency of PBS is relatively limited due to a lack of passengers’ interest, e.g., some bus lines run only 3 or 4 times per day. The main bus line, running across the city, runs four times per hour and ends around 21:00 on weekdays and 20:00 on weekends [
86].
University students in Kitami city come from various parts of Japan, with only 35% from Hokkaido prefecture, and the ratio of female students is 14 % [
87]. In other words, students from different prefectures represent an active population of domestic tourists for locals and business owners, at least until they graduate from the university. The broad impact of a society with a declining birthrate, such as Japan, although not noticeable around big cities, significantly influences the local economy in rural towns such as Kitami. Therefore, it is crucial to engage young people living in this city to support the local economy from various perspectives. The idea includes both purely economic aspects such as buying from local stores and economic and environmental aspects, such as choosing PBS in favor of private cars.
We have decided to use a two-step verification process in the survey design under the conditions mentioned above. Because the long-neglected status of PBS in rural Japan has reinforced the belief that there will be no change in the situation, psychologically, people have come to accept this as the status quo.
The first question we asked (first inquiry—FI) was whether a student would like to use PBS more in the current situation with a binary response (yes/no).
The following several questions we asked for linked the daily life activities that need mobility, including joining a part-time job, dinner options, nearby restaurant demand, and supermarket shopping. Next, we asked questions regarding the respondents’ public transport behavior, such as frequency of using PBS, days and times they prefer to go out, the transportation type they choose during these activities. These questions aimed to demonstrate to the responders the essential requirement of PBS in daily life.
The second question we asked (second inquiry—SI) was whether a student would like to use PBS in an alternate situation with a binary response. An alternate PBS that can provide the mobility need of any person during everyday life for various reasons such as going shopping, dining in a restaurant, traveling for sightseeing purposes, or even conveniently commuting to part-time job workplaces.
The difference in responders’ decision distribution between the two groups (Yes/No) did not reveal any visible diversity in the first inquiry (FI); however, the second inquiry (SI) resulted in a meaningful difference. This finding showed that using the two-stage verification probe was the right decision to analyze this specific community.
Furthermore, the variable identified with the second inquiry (SI) became the entire survey study’s target value for the machine learning-based predictions. Finally, regarding the various questions asked, the respondent’s overall satisfaction with academic lives has also been reviewed.
By the end of data collection, we populated 18 different types of categorical variables from the respondents. The conversion of these 18 categorical variables to the continuous type resulted in 47 types of continuous labels.
Once the dataset was formed and prepared for the analysis, chi-square statistical tests were applied to determine the best subset collection while dataset attributes were of the categorical value form. The chi-square test is a nonparametric statistical test that measures the association between two categorical variables [
88]. It is not applicable to analyze parametric or continuous data types [
89].
Additionally, the
p-value calculation was applied while dataset attributes were of the continuous value form. Statistical significance is the probability that the observed difference between two groups is due to chance. If the
p-value is more significant than the statistical significance level (α), any practical difference is assumed to be explained by sampling variability. However, reporting only the significant
p-value for analysis is not adequate to fully understand the effect sizes [
90,
91].
Due to differences in the perception of statistical inference to prevent misinterpretation of evidence from the given data [
92], we set two different criteria to evaluate the participants’ behavior better and simplify the models’ predictive weight. These criteria were chi-square and
p-value.
3.4. Predictive Modeling
The predictive modeling part explains the applicability of an inferential model for data mining algorithm to predict new or future observations. In particular, the goal is to predict the output value (y) for recent statements given their input value sets (X) [
98]. In predictive modeling, we used a group of classifiers trained with the dataset to predict whether a randomly selected student would prefer to use PBS more or not.
Classification is a part of predictive modeling, and it is an integral part of the data science processes. A typical supervised statistical learning problem is defined when the relationship between a response variable and an associated set of predictors (inputs) is of interest while the response variable is categorical. One challenge in classification problems is to use a dataset to construct an accurate classifier that produces a class prediction for any new observation with an unknown response [
99].
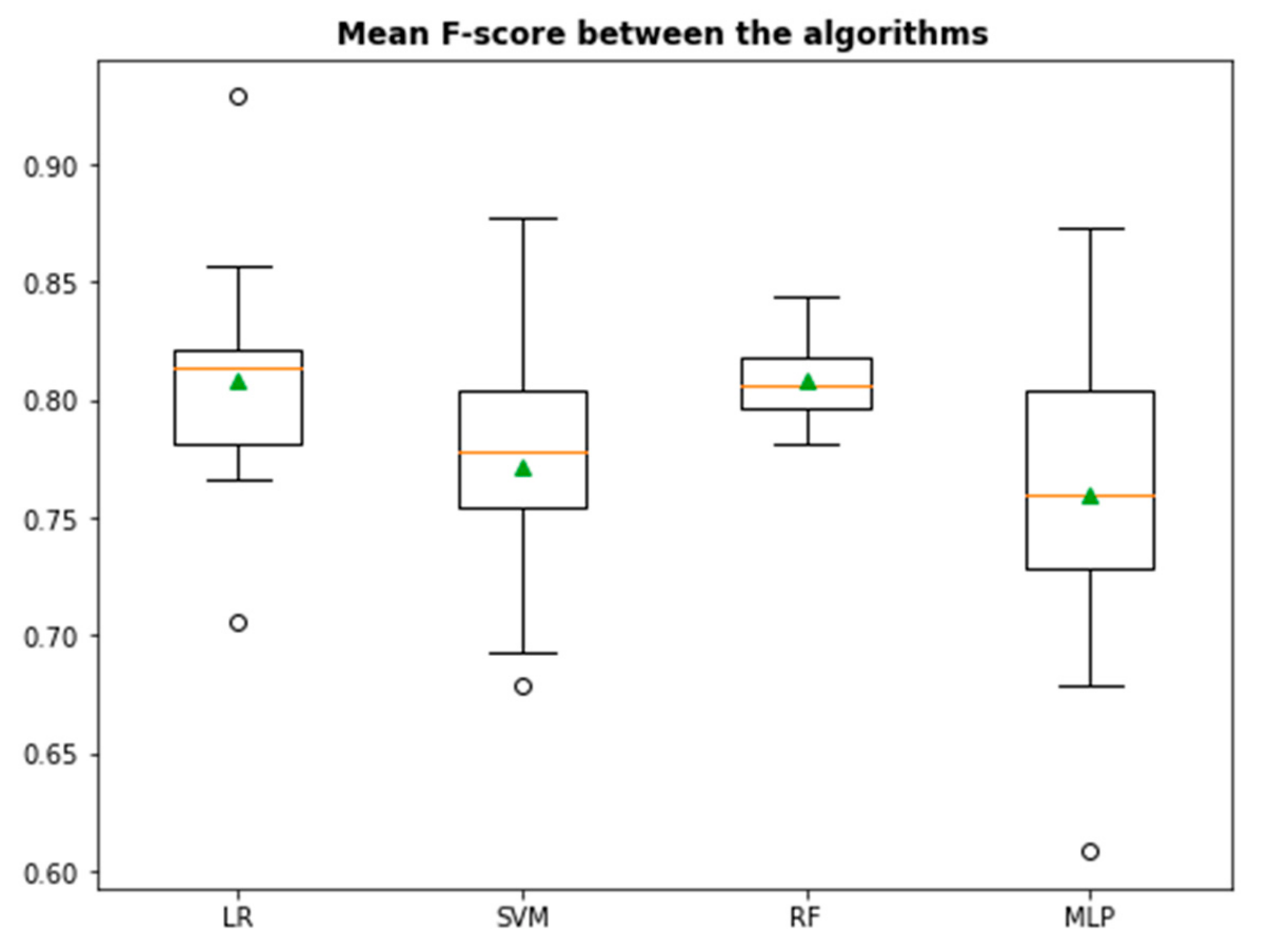
The classifier algorithms used for comparison in our research included a logistic regression (LR), a support vector machine (SVM), a random forest (RF), and a multi-layer perceptron classifier (MLP).
Logistic regression is considered a standard approach for binary classification in the context of a low-dimensional dataset. This condition usually occurs in scientific fields such as medicine, psychology, and social sciences, where the focus is not only on a prediction but also on explainability [
100]. LR classifier aims to test the relationship between a categorical dependent variable and continuous independent variables by plotting the dependent variables’ probability scores. LR models develop from the statistic that best explains the relationships with yes or no answers (no answer indicates missing data) [
101].
SVMs do separate two classes in the data space by building a decision boundary [
102]. The SVM classifier creates a maximum-margin hyperplane that lies in transformed input space and splits the class samples while maximizing the distance to the nearest dividing samples [
103].
RFs are a machine learning technique that aggregates many decision trees in the ensemble (this is often called “ensemble learning”), resulting in a reduction in the variance compared to single decision trees [
104]. The objective behind an RF classifier is to take a set of high-variance, low-bias decision trees and transform them into a low variance and low-bias model. By aggregating individual decision trees’ various outputs, RF reduces the conflict that can cause errors in decision trees. RF also allows a reliable assessment of the importance (weight) of each variable.
Unlike previous classification algorithms, an MLP relies on an underlying neural network to perform classification. Artificial neural networks try to learn tasks (to solve problems), applying the similarities to the brain’s behavior. Specifically, similarly to how the brain is composed of a large set of specialized cells called neurons that memorize brain activity patterns, neural networks memorize patterns between features to fit as closely as possible to the desired output. MLP is often achieving high performance. However, similarly to how it is difficult to explain the behavior of separate neurons in the brain, neural network-based models are also considered ill-suited for explanatory modeling, especially when the training data size is small [
105,
106].
The performance of machine learning algorithms usually is evaluated by predictive accuracy. However, this is not appropriate when the data is imbalanced, and the costs of different errors vary markedly. Often real-world datasets are predominately composed of “normal” examples with only a tiny percentage of “abnormal” or “relevant” examples [
107].
The dataset was split into the train (80%) and the test set (20%). We used test sets, which the model did not see, during the performance metrics calculation to avoid over-optimistic predictive accuracy. After interpreting the performance metrics, the method that produces the most compatible outcome with the real-life situation was compared.
The performance metrics for evaluating each algorithm in this study were the F-measure (Fβ), accuracy, area under the curve (AUC), Cohen’s kappa, and cross-validation (CV).
F-Measure is a commonly used performance measure and is more informative about the effectiveness of a classifier on its predictive ability than simple accuracy. The β in Fβ sets different weightings for Precision and Recall (β = 1 or 2 or 3). We therefore computed the F1 score, where β was chosen to be equal to 1. Accuracy is not suitable considering a user preference bias toward the minority (positive) class examples because of the least represented impact. However, more actual examples are reduced when compared to that of the majority class. Two other popular measures used, especially in imbalanced class domains, are the receiver operating characteristics (ROC) curve and the corresponding area under the ROC curve (AUC).
Moreover, ROC curves do not provide a single-value performance score, which motivates the use of AUC. The AUC allows the evaluation of the best model on average. Still, it is not biased toward the minority class [
108].
The reliability of data collection is an essential component influencing the overall real-life utility of the proposed machine learning model. Cohen’s kappa statistic is frequently used to test interrater reliability, which shows how reliable the data is. Cohen’s kappa was developed to account for the possibility that raters guess on at least some variables due to uncertainty. A kappa is a form of the correlation coefficient. Correlation coefficients cannot be directly interpreted, but a squared correlation coefficient, called the coefficient of determination (COD), is directly interpretable. The COD is explained as the amount of variation in the dependent variable that can be explained by the independent variable [
109]. Like most correlation statistics, the kappa can range from −1 to +1.
Cross-validation (CV) is a popular strategy for algorithm selection. The main idea behind CV is to split data, once or several times, for estimating the risk of each algorithm. Part of the data (the training sample) is used for training each algorithm, and the remaining part (the test sample) is used for estimating the efficacy of the algorithm. In the process of CV, the algorithm with the highest efficacy is then selected. CV is a widespread strategy because of its simplicity and universality [
110].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}