
Application of Combined Models Based on Empirical Mode Decomposition, Deep Learning, and Autoregressive Integrated Moving Average Model for Short-Term Heating Load Predictions


Abstract
:1. Introduction
2. Overview of the Combined Model
2.1. Empirical Model Decomposition
- (1)
- White noise ωi is added into the original signal x; then, the IMFs are obtained via decomposition of the signal using EMD. Thus, the first model is calculated using the following equation:
- (2)
- Calculate the first residual (r1) at the first stage:
- (3)
- The signal () is further decomposed using EMD until IMF1 is obtained. Then, IMF2 can be calculated as follows:
- (4)
- The k-th residual is calculated.
- (5)
- The realization signal () is further decomposed using EMD, and IMFk+1 is calculated:
- (6)
- Repeat the above steps until the residual satisfies the iteration termination condition, i.e., when there is no further decomposition possible. Then, the final residual is:
2.2. Deep Learning Models
2.2.1. Convolutional Neural Networks
2.2.2. Long–Short-Term Memory Networks
- (1)
- Depending on the input xt and the state of the last hidden layers ht−1, the LSTM can determine the information to be thrown away by forget gate ft:
- (2)
- The last output and the current input value are transferred to the input gate. Then, the output it and candidate state are generated.
- (3)
- The current state of cell Ct is updated through the integration of the input of the forget gate with the last state of the cell.
- (4)
- Finally, the output gate ot is calculated using ht−1 and xt. Then, the final output ht is obtained from the output gate.
2.2.3. Gated Recurrent Unit
2.2.4. Bidirectional Long–Short-Term Memory Network (Bi-LSTM)
2.3. ARIMA Model
3. Materials and Methods
3.1. Data Description
3.2. Correlation Analysis
3.3. Model Evaluation
3.4. Model Development
3.4.1. Sample Entropy Analysis
3.4.2. Model Development and Parameter Setting
- (1)
- Data preprocessing: The CEEMDAN algorithm is applied to decompose the heating load into six IMFs and one RES. Then, the sample entropies are calculated, and the corresponding prediction models of each component are determined.
- (2)
- Model development: The four DL models are integrated with the ARIMA model to develop the combined models. That is, IMF1−IMF4 are used to train the DL models, and IMF5−RES are used to train the ARIMA model.
- (3)
- Model prediction: The prediction of the four DL models and the ARIMA model are summed. Thus, the predictions obtained are from four combined models, namely CEEMDAN-CNN-ARIMA, CEEMDAN-LSTM-ARIMA, CEEMDAN-GRU-ARIMA, and CEEMDAN-bi-LSTM-ARIMA.
4. Results and Discussion
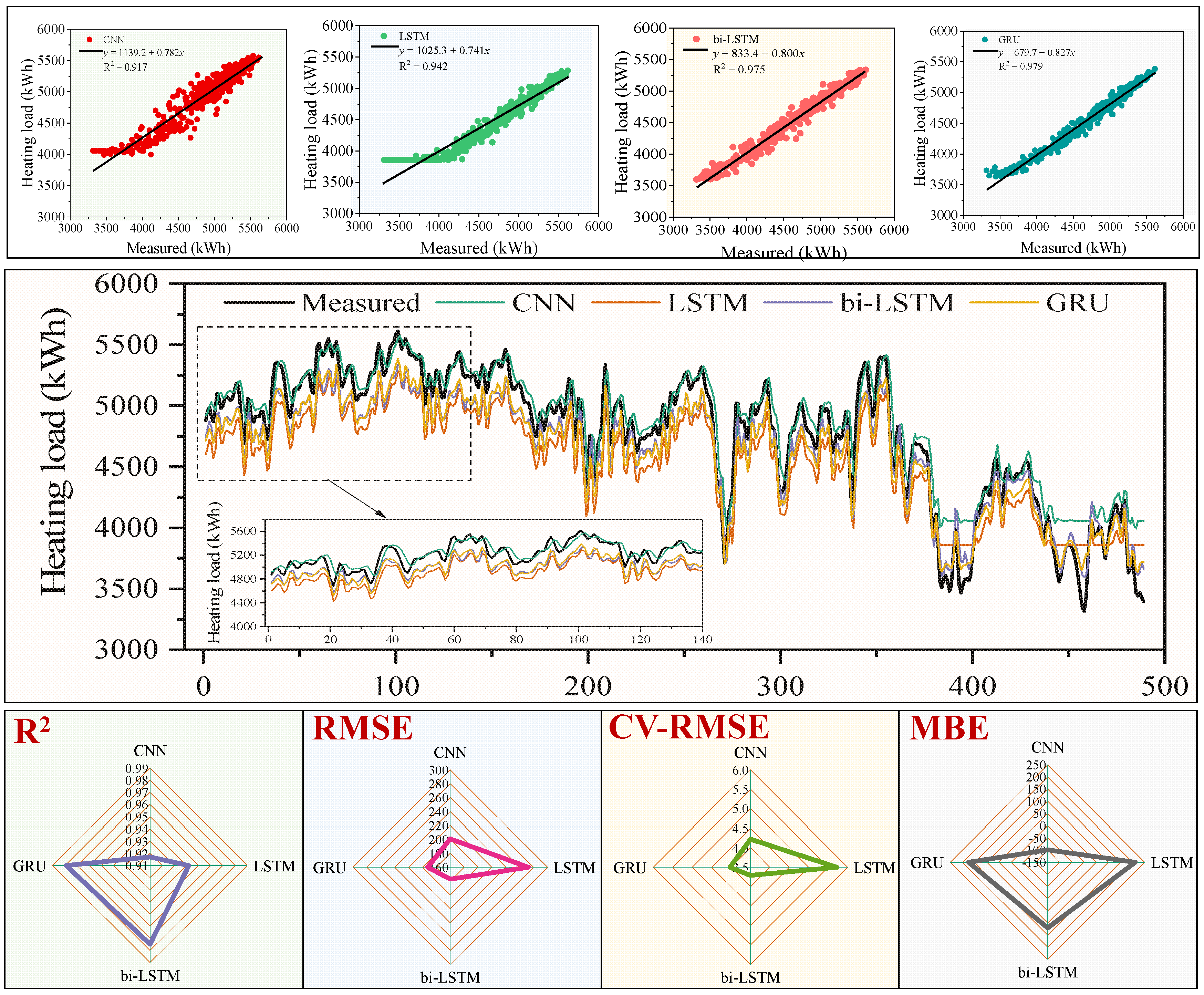
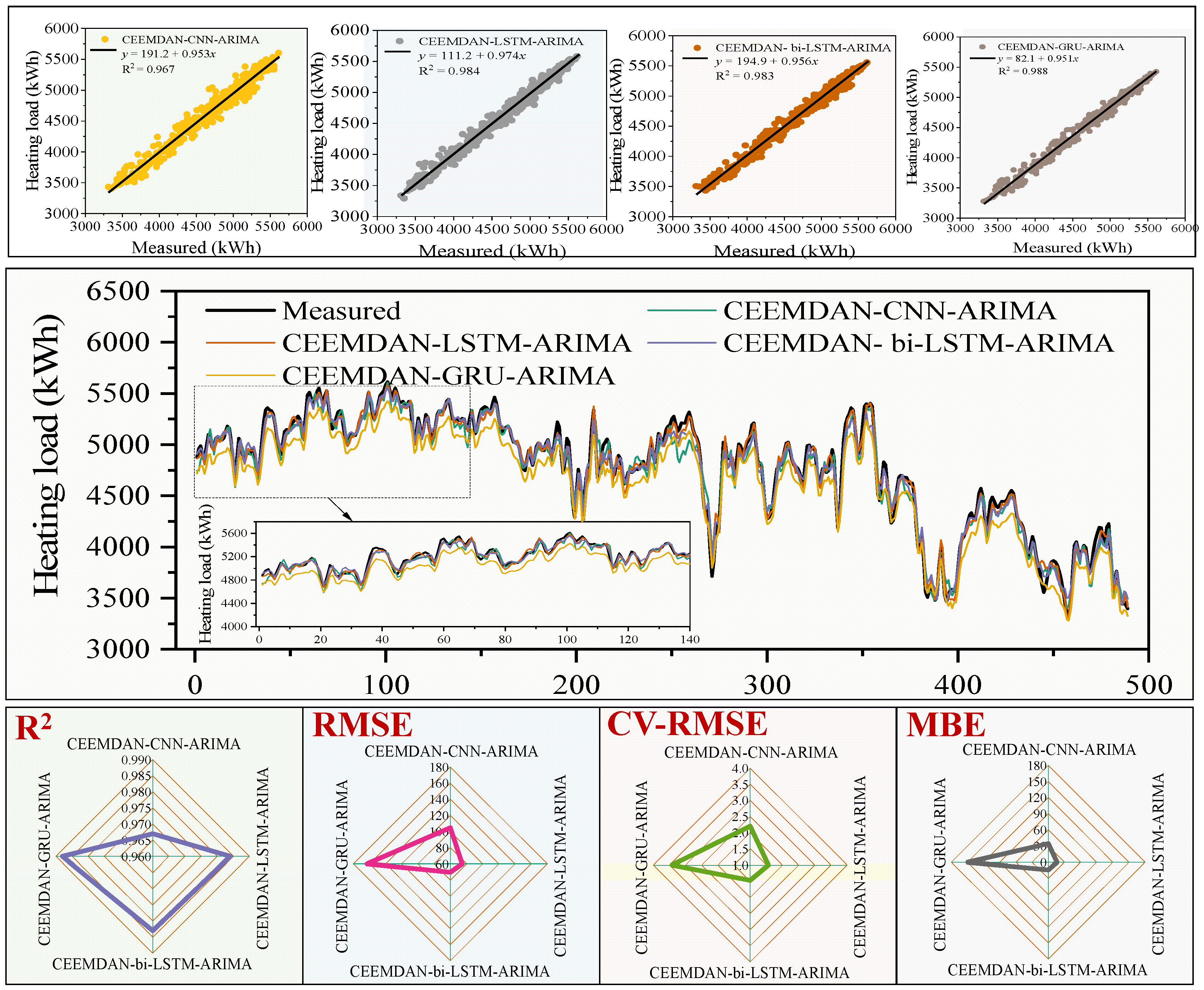
4.1. Model Performance Comparison
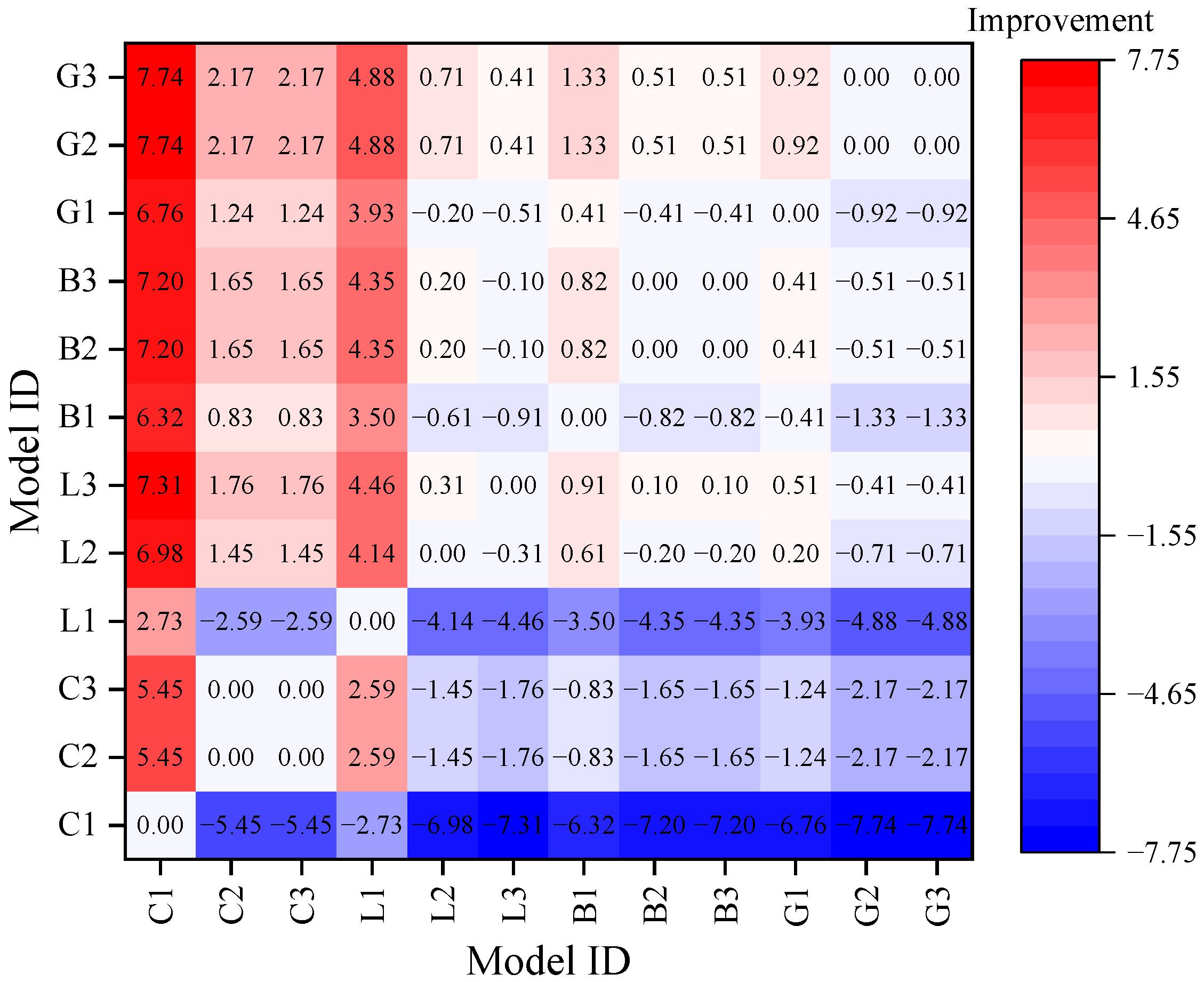
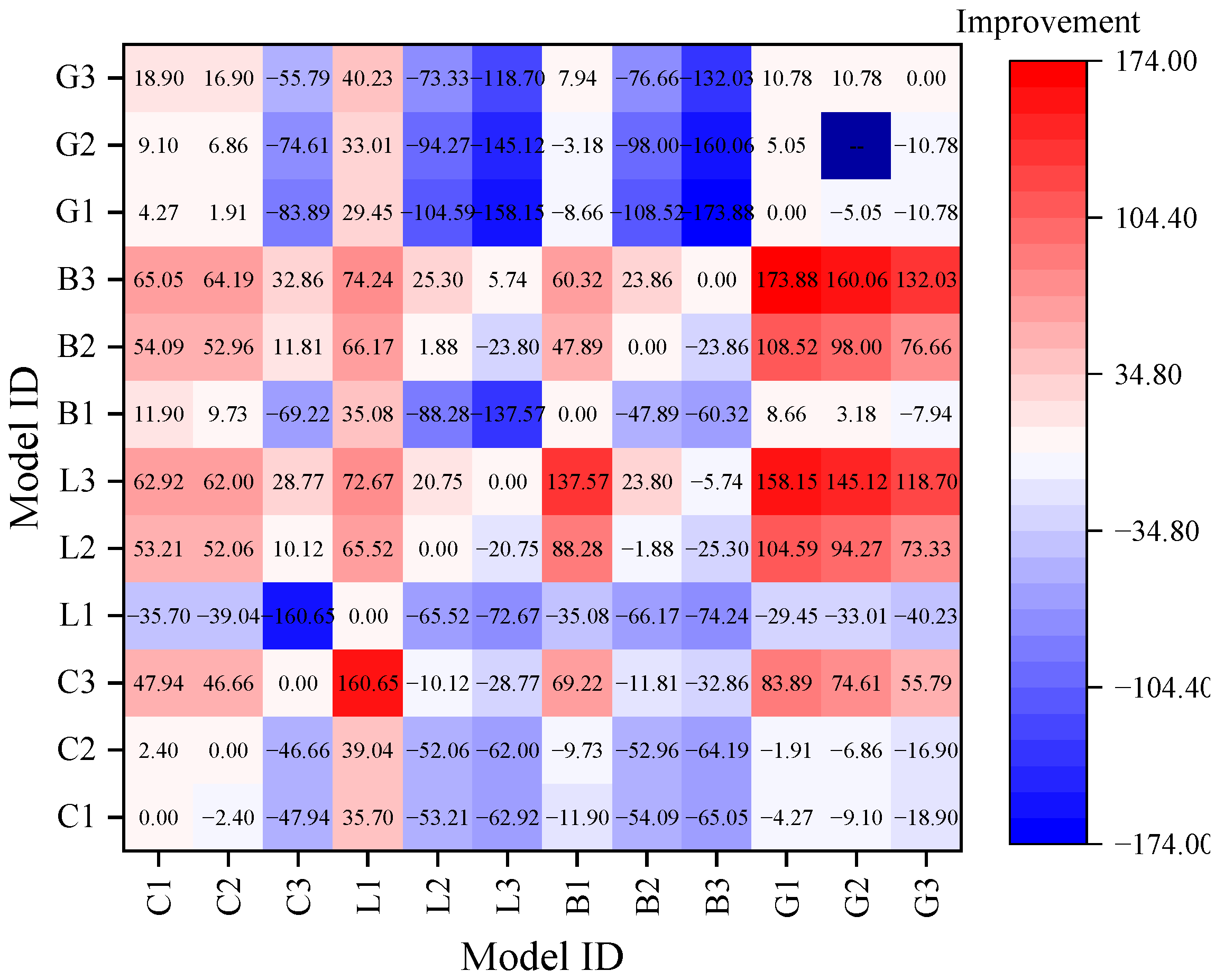
4.2. Improvements of Combined Models
5. Conclusions
- (1)
- At the initial stage of testing, the change trend of the heating load is similar to that observed during training phases, and the CNN model could follow the heating load due to its deep structure. Therefore, at the initial stage of testing, the CNN had the best performance. As time progressed, the heating load gradually decreased, the change trend became less familiar to the model, and the CNN prediction performance decreased. In comparison, the LSTM, bi-LSTM, and GRU have memory functions resulting in their prediction performance improving over time. The Bi-LSTM had the best comprehensive performance because it can integrate information from the previous and the following samples of the time series.
- (2)
- Combined models performed better than single models. Compared with the single model, the average performance improvement percentages of R2, RMSE, and CV-RMSE of the two-step models combining CEEMDAN and DL models were 2.83%, 30.22%, and 30.15%, respectively. The corresponding values of the three-step models, which combined CEEMDAN, DL, and ARIMA, were 2.91%, 47.93%, and 47.92%, respectively.
- (3)
- Among all models, the CEEMDAN-Bi-LSTM-ARIMA model had the best performance. ARIMA model can predict the low-frequency subsequences decomposed by CEEMDAN effectively and reduce the prediction error of the bi-LSTM on these low-frequency subsequences. This resulted in an improvement in the overall prediction accuracy of the hybrid model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Symbols | |
| R2 | Coefficient of determination |
| Abbreviations | |
| Adam | Adaptive moment estimation |
| ANN | Artificial neural network |
| ARIMA | Autoregressive integrated moving average |
| Bi-LSTM | Bi-directional long- and short-term memory |
| BPNN | Back-propagation neural network |
| CEEMDAN | Complete ensemble empirical model decomposition with adaptive noise |
| CNN | Convolutional neural network |
| CV-RMSE | Coefficient of variation of the root mean square error |
| DL | Deep learning |
| EEMD | Ensemble empirical model decomposition |
| EMD | Empirical mode decomposition |
| GRU | Gated recurrent unit |
| IMF | Intrinsic mode function |
| LSSVM | Least square support vector machine |
| LSTM | Long- and short-term memory |
| MBE | Mean bias error |
| RF | Random forest |
| RMSE | Root mean square error |
| RES | Residuals |
| SVM | Support vector machine |
| TLBO | Teaching learning-based optimization algorithm |
| TPE | Tree of Parzen Estimators |
| XGBoost | Extreme gradient boosting |
References
- Lu, C.; Li, S.; Lu, Z. Building energy prediction using artificial neural networks: A literature survey. Energy Build. 2022, 262, 111718. [Google Scholar] [CrossRef]
- Olu-Ajayi, R.; Alaka, H.; Sulaimon, I.; Sunmola, F.; Ajayi, S. Building energy consumption prediction for residential buildings using deep learning and other machine learning techniques. J. Build. Eng. 2022, 45, 103406. [Google Scholar] [CrossRef]
- Li, A.; Xiao, F.; Zhang, C.; Fan, C. Attention-based interpretable neural network for building cooling load prediction. Appl. Energy 2021, 299, 117238. [Google Scholar] [CrossRef]
- Razmjooy, N.; Ramezani, M. Uncertain Method for Optimal Control Problems with Uncertainties Using Chebyshev Inclusion Functions. Asian J. Control 2019, 21, 824–831. [Google Scholar] [CrossRef]
- Razmjooy, N.; Ramezani, M. Interval structure of Runge-Kutta methods for solving optimal control problems with uncertainties. J. Comput. Methods Differ. Equ. 2019, 7, 235–251. [Google Scholar]
- Jang, Y.; Byon, E.; Jahani, E.; Cetin, K. On the long-term density prediction of peak electricity load with demand side management in buildings. Energy Build. 2020, 228, 110450. [Google Scholar] [CrossRef]
- Fang, X.; Gong, G.; Li, G.; Chun, L.; Li, W.; Peng, P. A hybrid deep transfer learning strategy for short term cross-building energy prediction. Energy 2021, 215, 119208. [Google Scholar] [CrossRef]
- Dong, Z.; Liu, J.; Liu, B.; Li, K.; Li, X. Hourly energy consumption prediction of an office building based on ensemble learning and energy consumption pattern classification. Energy Build. 2021, 241, 110929. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, X.; Luo, X.; Zhou, Y.; Wang, D.; Farah, S. Identifying the most significant input parameters for predicting district heating load using an association rule algorithm. J. Clean. Prod. 2020, 275, 122984. [Google Scholar] [CrossRef]
- Baglivo, C.; Congedo, P.M.; Murrone, G.; Lezzi, D. Long-term predictive energy analysis of a high-performance building in a mediterranean climate under climate change. Energy 2022, 238, 121641. [Google Scholar] [CrossRef]
- Gassar, A.A.A.; Cha, S.H. Energy prediction techniques for large-scale buildings towards a sustainable built environment: A review. Energy Build. 2020, 224, 110238. [Google Scholar] [CrossRef]
- Zhang, Q.; Tian, Z.; Ma, Z.; Li, G.; Lu, Y.; Niu, J. Development of the heating load prediction model for the residential building of district heating based on model calibration. Energy 2020, 205, 117949. [Google Scholar] [CrossRef]
- Shabunko, V.; Lim, C.M.; Mathew, S. EnergyPlus models for the benchmarking of residential buildings in Brunei Darussalam. Energy Build. 2018, 169, 507–516. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Sun, Y.; Haghighat, F.; Fung, B.C.M. A review of the-state-of-the-art in data-driven approaches for building energy prediction. Energy Build. 2020, 221, 110022. [Google Scholar] [CrossRef]
- Zhang, L.; Wen, J.; Li, Y.; Chen, J.; Ye, Y.; Fu, Y.; Livingood, W. A review of machine learning in building load prediction. Appl. Energy 2021, 285, 116452. [Google Scholar] [CrossRef]
- Elbeltagi, E.; Wefki, H. Predicting energy consumption for residential buildings using ANN through parametric modeling. Energy Rep. 2021, 7, 2534–2545. [Google Scholar] [CrossRef]
- Ahmad, A.S.; Hassan, M.Y.; Abdullah, M.P.; Rahman, H.A.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Chen, B.; Liu, Q.; Chen, H.; Wang, L.; Deng, T.; Zhang, L.; Wu, X. Multiobjective optimization of building energy consumption based on BIM-DB and LSSVM-NSGA-II. J. Clean. Prod. 2021, 294, 126153. [Google Scholar] [CrossRef]
- Yu, Z.; Haghighat, F.; Fung, B.C.M.; Yoshino, H. A decision tree method for building energy demand modeling. Energy Build. 2010, 42, 1637–1646. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Z.; Gang, W.; Yuan, J.; Zhang, Y.; Fan, C. Cooling load disaggregation using a NILM method based on random forest for smart buildings. Sustain. Cities Soc. 2021, 74, 103202. [Google Scholar] [CrossRef]
- Lu, H.; Cheng, F.; Ma, X.; Hu, G. Short-term prediction of building energy consumption employing an improved extreme gradient boosting model: A case study of an intake tower. Energy 2020, 203, 117756. [Google Scholar] [CrossRef]
- Ling, J.; Dai, N.; Xing, J.; Tong, H. An improved input variable selection method of the data-driven model for building heating load prediction. J. Build. Eng. 2021, 44, 103255. [Google Scholar] [CrossRef]
- Chen, Y.; Guo, M.; Chen, Z.; Chen, Z.; Ji, Y. Physical energy and data-driven models in building energy prediction: A review. Energy Rep. 2022, 8, 2656–2671. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Zhang, L.; Feng, Z. Enhancing building energy efficiency using a random forest model: A hybrid prediction approach. Energy Rep. 2021, 7, 5003–5012. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Q.; Dong, Z.; Li, X.; Li, G.; Xie, Y.; Li, K. Quantitative evaluation of the building energy performance based on short-term energy predictions. Energy 2021, 223, 120065. [Google Scholar] [CrossRef]
- Lei, L.; Chen, W.; Wu, B.; Chen, C.; Liu, W. A building energy consumption prediction model based on rough set theory and deep learning algorithms. Energy Build. 2021, 240, 110886. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, Y.; Wang, D.; Liu, X. Comparison of machine-learning models for predicting short-term building heating load using operational parameters. Energy Build. 2021, 253, 111505. [Google Scholar] [CrossRef]
- Li, X.; Liu, S.; Zhao, L.; Meng, X.; Fang, Y. An integrated building energy performance evaluation method: From parametric modeling to GA-NN based energy consumption prediction modeling. J. Build. Eng. 2022, 45, 103571. [Google Scholar] [CrossRef]
- Wang, R.; Lu, S.; Feng, W. A novel improved model for building energy consumption prediction based on model integration. Appl. Energy 2020, 262, 114561. [Google Scholar] [CrossRef]
- Li, G.; Zhao, X.; Fan, C.; Fang, X.; Li, F.; Wu, Y. Assessment of long short-term memory and its modifications for enhanced short-term building energy predictions. J. Build. Eng. 2021, 43, 103182. [Google Scholar] [CrossRef]
- Li, K.; Tian, J.; Xue, W.; Tan, G. Short-term electricity consumption prediction for buildings using data-driven swarm intelligence based ensemble model. Energy Build. 2021, 231, 110558. [Google Scholar] [CrossRef]
- Zhang, C.; Li, J.; Zhao, Y.; Li, T.; Chen, Q.; Zhang, X. A hybrid deep learning-based method for short-term building energy load prediction combined with an interpretation process. Energy Build. 2020, 225, 110301. [Google Scholar] [CrossRef]
- Zhang, Q.; Tian, Z.; Ding, Y.; Lu, Y.; Niu, J. Development and evaluation of cooling load prediction models for a factory workshop. J. Clean. Prod. 2019, 230, 622–633. [Google Scholar] [CrossRef]
- Gao, B.; Huang, X.; Shi, J.; Tai, Y.; Zhang, J. Hourly forecasting of solar irradiance based on CEEMDAN and multi-strategy CNN-LSTM neural networks. Renew. Energy 2020, 162, 1665–1683. [Google Scholar] [CrossRef]
- Gao, Y.; Hang, Y.; Yang, M. A cooling load prediction method using improved CEEMDAN and Markov Chains correction. J. Build. Eng. 2021, 42, 103041. [Google Scholar] [CrossRef]
- Karijadi, I.; Chou, S.-Y. A hybrid RF-LSTM based on CEEMDAN for improving the accuracy of building energy consumption prediction. Energy Build. 2022, 259, 111908. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, Y.; Wang, D.; Liu, X.; Wang, Y. A review on global solar radiation prediction with machine learning models in a comprehensive perspective. Energy Convers. Manag. 2021, 235, 113960. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar]
- Song, J.; Zhang, L.; Xue, G.; Ma, Y.; Gao, S.; Jiang, Q. Predicting hourly heating load in a district heating system based on a hybrid CNN-LSTM model. Energy Build. 2021, 243, 110998. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Long short term memory–convolutional neural network based deep hybrid approach for solar irradiance forecasting. Appl. Energy 2021, 295, 117061. [Google Scholar] [CrossRef]
- Li, X.; Chen, Q. Development of a novel method to detect clothing level and facial skin temperature for controlling HVAC systems. Energy Build. 2021, 239, 110859. [Google Scholar] [CrossRef]
- Liu, M.-D.; Ding, L.; Bai, Y.-L. Application of hybrid model based on empirical mode decomposition, novel recurrent neural networks and the ARIMA to wind speed prediction. Energy Convers. Manag. 2021, 233, 113917. [Google Scholar] [CrossRef]
- Yu, C.; Li, Y.; Bao, Y.; Tang, H.; Zhai, G. A novel framework for wind speed prediction based on recurrent neural networks and support vector machine. Energy Convers. Manag. 2018, 178, 137–145. [Google Scholar] [CrossRef]
- Yan, X.; Guan, T.; Fan, K.; Sun, Q. Novel double layer BiLSTM minor soft fault detection for sensors in air-conditioning system with KPCA reducing dimensions. J. Build. Eng. 2021, 44, 102950. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. A novel hybridization of artificial neural networks and ARIMA models for time series forecasting. Appl. Soft Comput. 2011, 11, 2664–2675. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, Y.; Wang, D.; Wang, Y.; Li, Y.; Zhu, Y. Classification of solar radiation zones and general models for estimating the daily global solar radiation on horizontal surfaces in China. Energy Convers. Manag. 2017, 154, 168–179. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, Y.; Wang, D.; De, G.; Li, Y.; Liu, X.; Wang, Y. A novel combined multi-task learning and Gaussian process regression model for the prediction of multi-timescale and multi-component of solar radiation. J. Clean. Prod. 2021, 284, 124710. [Google Scholar] [CrossRef]
- Jia, S.; Ma, B.; Guo, W.; Li, Z.S. A sample entropy based prognostics method for lithium-ion batteries using relevance vector machine. J. Manuf. Syst. 2021, 61, 773–781. [Google Scholar] [CrossRef]
- Ma, Z.; Chen, H.; Wang, J.; Yang, X.; Yan, R.; Jia, J.; Xu, W. Application of hybrid model based on double decomposition, error correction and deep learning in short-term wind speed prediction. Energy Convers. Manag. 2020, 205, 112345. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D.D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 115–123. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Parameters | Maximum Values | Minimum Values |
|---|---|---|---|
| CNN | Filters | 1 | 30 |
| Kernels | 1 | 3 | |
| Dropout rate | 0.1 | 0.5 | |
| Pooling size | 1 | 2 | |
| Layers | 1 | 5 | |
| Learning rate | 0.01 | 0.1 | |
| Epochs | 10 | 100 | |
| Batch size | 12 | 72 | |
| LSTM | LSTM layers | 1 | 5 |
| Dense layers | 1 | 3 | |
| LSTM units | 10 | 100 | |
| Dropout rate | 0.1 | 0.5 | |
| Dense units | 10 | 100 | |
| Batch size | 12 | 72 | |
| Epochs | 10 | 100 | |
| Learning rate | 0.01 | 0.1 | |
| GRU | GRU layers | 1 | 5 |
| Dense layer | 1 | 3 | |
| GRU units | 10 | 100 | |
| Dropout rate | 0.1 | 0.5 | |
| Dense units | 10 | 100 | |
| Batch size | 12 | 72 | |
| Epochs | 10 | 100 | |
| Learning rate | 0.01 | 0.1 | |
| Bi-LSTM | Bi-LSTM layers | 1 | 5 |
| Dense layers | 1 | 3 | |
| Dropout rate | 0.1 | 0.5 | |
| Dense units | 10 | 100 | |
| Batch size | 12 | 72 | |
| Epochs | 10 | 100 | |
| Learning rate | 0.01 | 0.1 |
| Models | Model ID | R2 | RMSE (kWh) | CV-RMSE (%) | MBE (kWh) |
|---|---|---|---|---|---|
| CNN | C1 | 0.917 | 200.98 | 4.22 | −99.16 |
| CEEMDAN-CNN | C2 | 0.967 | 196.15 | 4.12 | 158.74 |
| CEEMDAN-CNN-ARIMA | C3 | 0.967 | 104.63 | 2.20 | 34.12 |
| LSTM | L1 | 0.942 | 272.72 | 5.72 | 210.74 |
| CEEMDAN-LSTM | L2 | 0.981 | 94.04 | 1.97 | 44.13 |
| CEEMDAN-LSTM-ARIMA | L3 | 0.984 | 74.53 | 1.56 | 16.32 |
| Bi-LSTM | B1 | 0.975 | 177.06 | 3.71 | 120.60 |
| CEEMDAN- Bi-LSTM | B2 | 0.983 | 92.27 | 1.94 | −22.17 |
| CEEMDAN- Bi-LSTM-ARIMA | B3 | 0.983 | 70.25 | 1.47 | 14.25 |
| GRU | G1 | 0.979 | 192.40 | 4.03 | 174.81 |
| CEEMDAN-GRU | G2 | 0.988 | 182.69 | 3.83 | 142.34 |
| CEEMDAN-GRU-ARIMA | G3 | 0.988 | 163.00 | 3.42 | 149.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, L.; Qian, J. Application of Combined Models Based on Empirical Mode Decomposition, Deep Learning, and Autoregressive Integrated Moving Average Model for Short-Term Heating Load Predictions. Sustainability 2022, 14, 7349. https://doi.org/10.3390/su14127349
Zhou Y, Wang L, Qian J. Application of Combined Models Based on Empirical Mode Decomposition, Deep Learning, and Autoregressive Integrated Moving Average Model for Short-Term Heating Load Predictions. Sustainability. 2022; 14(12):7349. https://doi.org/10.3390/su14127349
Chicago/Turabian StyleZhou, Yong, Lingyu Wang, and Junhao Qian. 2022. "Application of Combined Models Based on Empirical Mode Decomposition, Deep Learning, and Autoregressive Integrated Moving Average Model for Short-Term Heating Load Predictions" Sustainability 14, no. 12: 7349. https://doi.org/10.3390/su14127349