


Comparing Four Machine Learning Algorithms for Land Cover Classification in Gold Mining: A Case Study of Kyaukpahto Gold Mine, Northern Myanmar

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
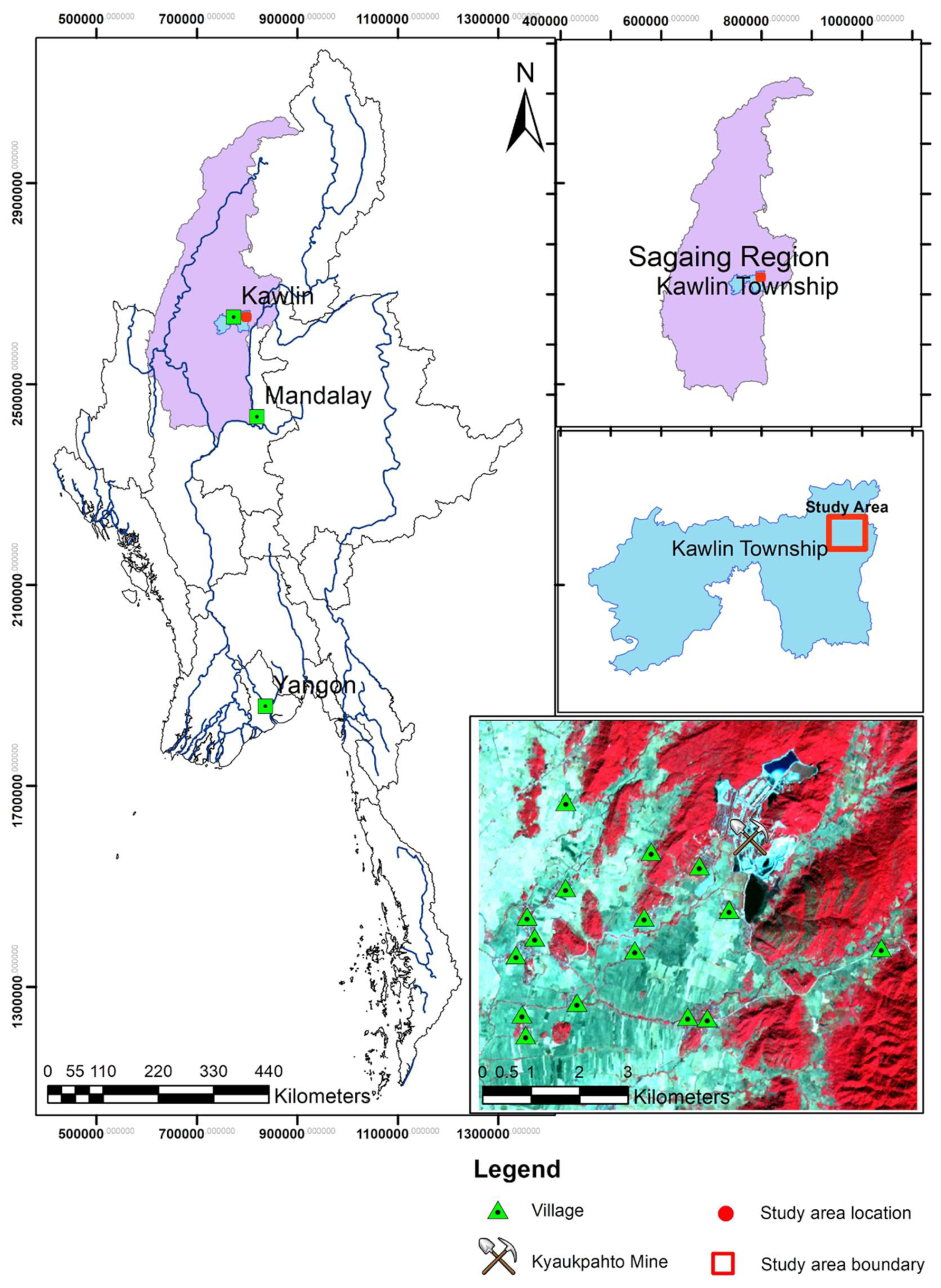
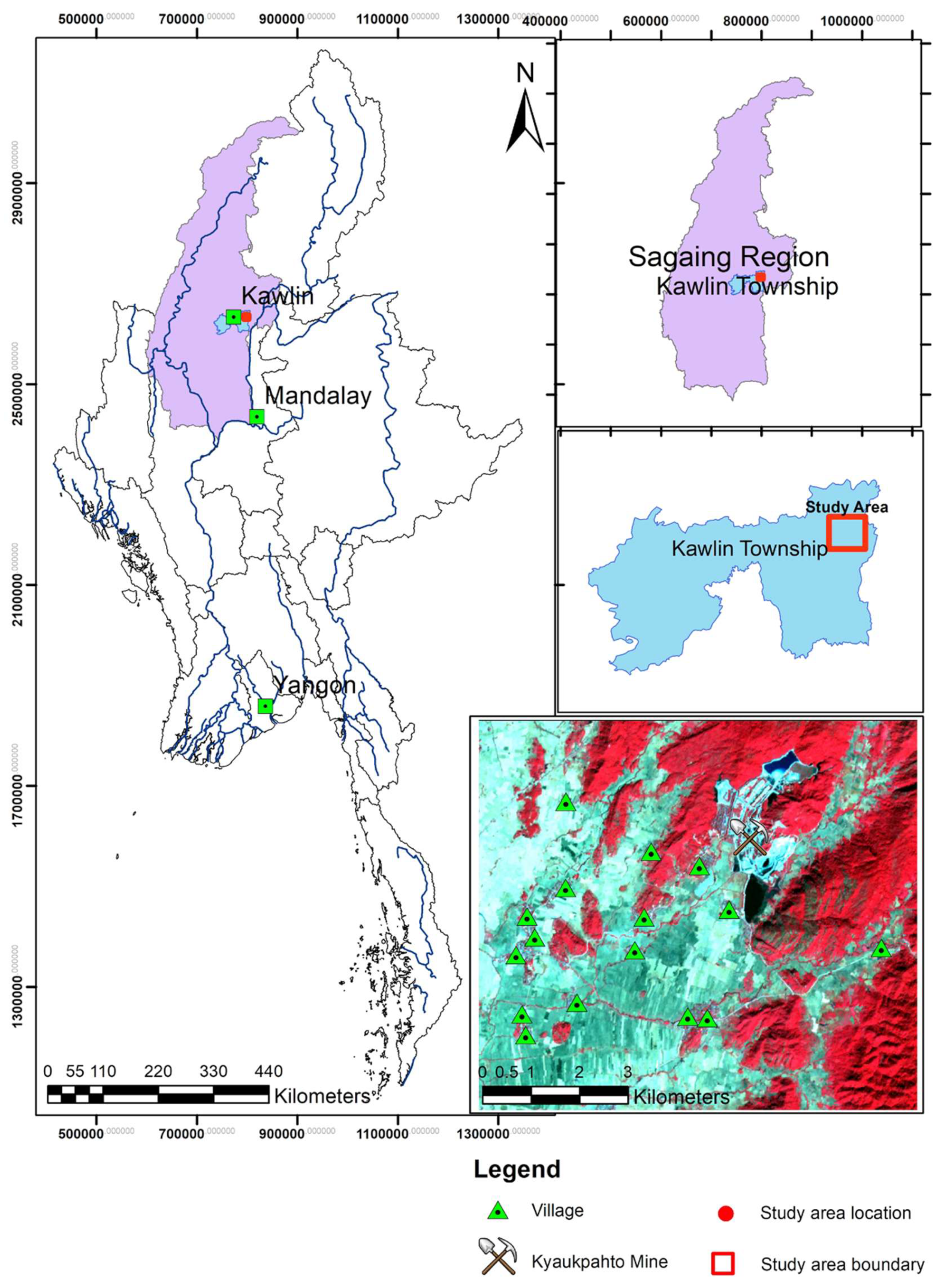
2.1. Study Area
2.2. Data Used
2.3. Training and Testing Sample Datasets
2.4. Classification Algorithms
2.5. Thematic Accuracy Assessment and Comparisons
3. Results
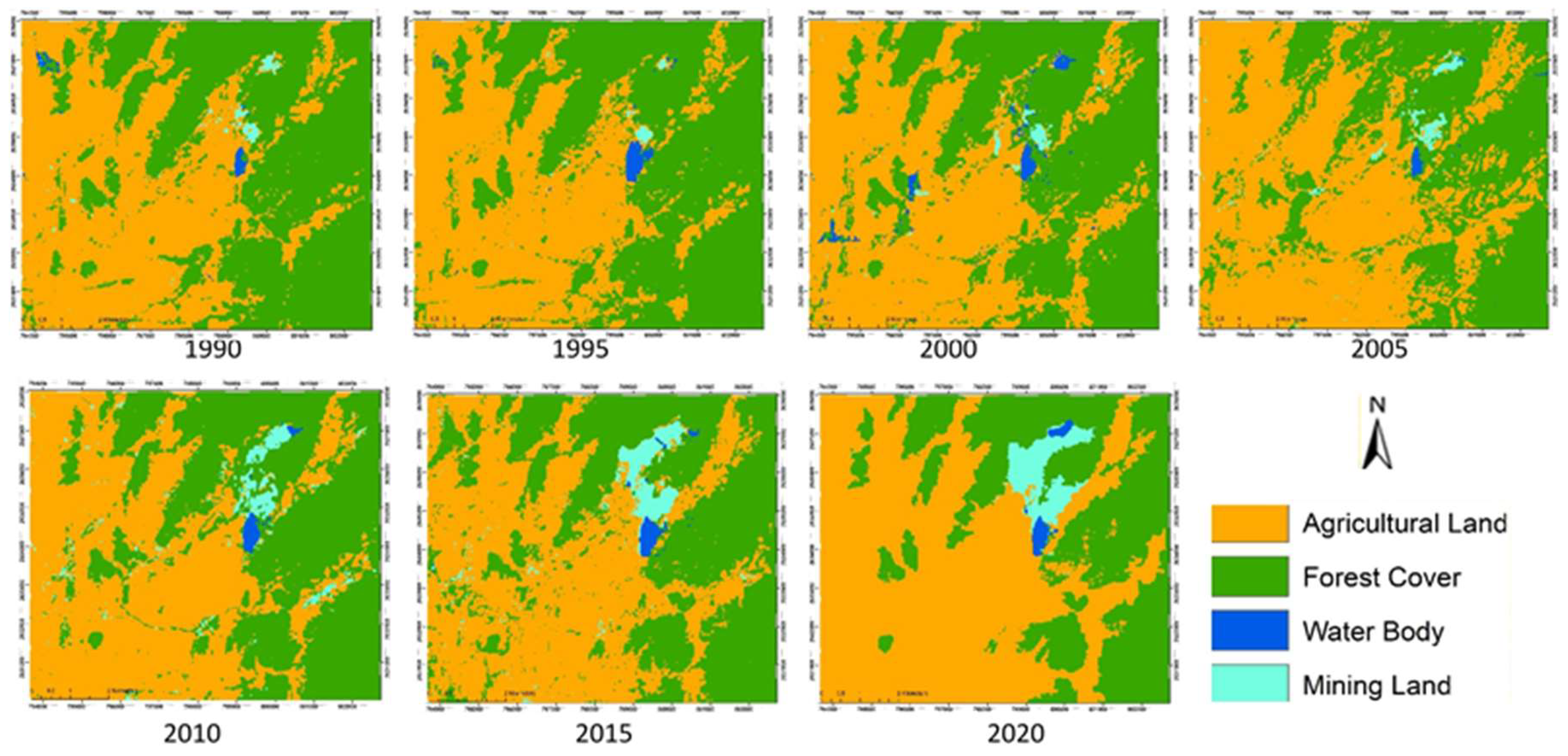
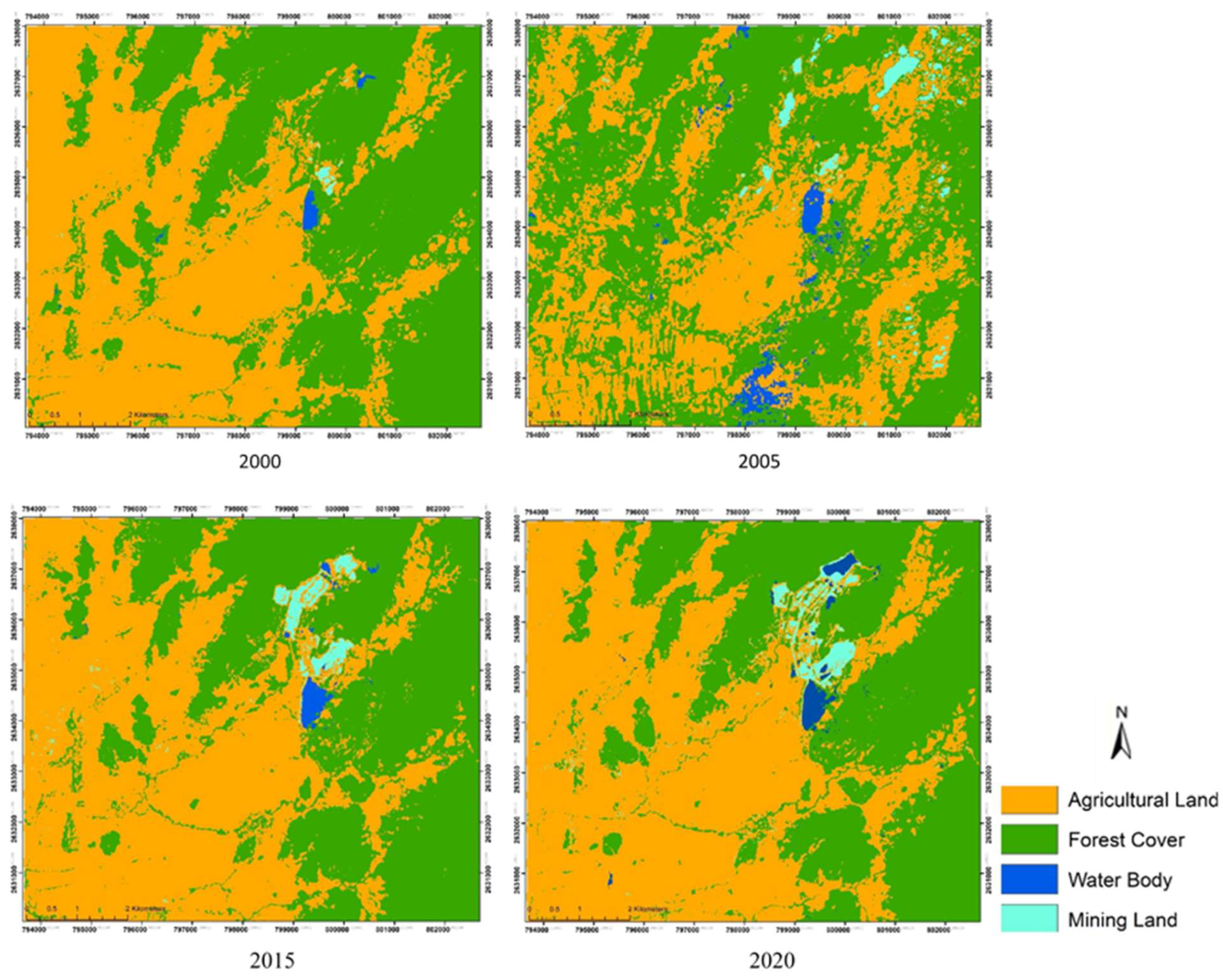
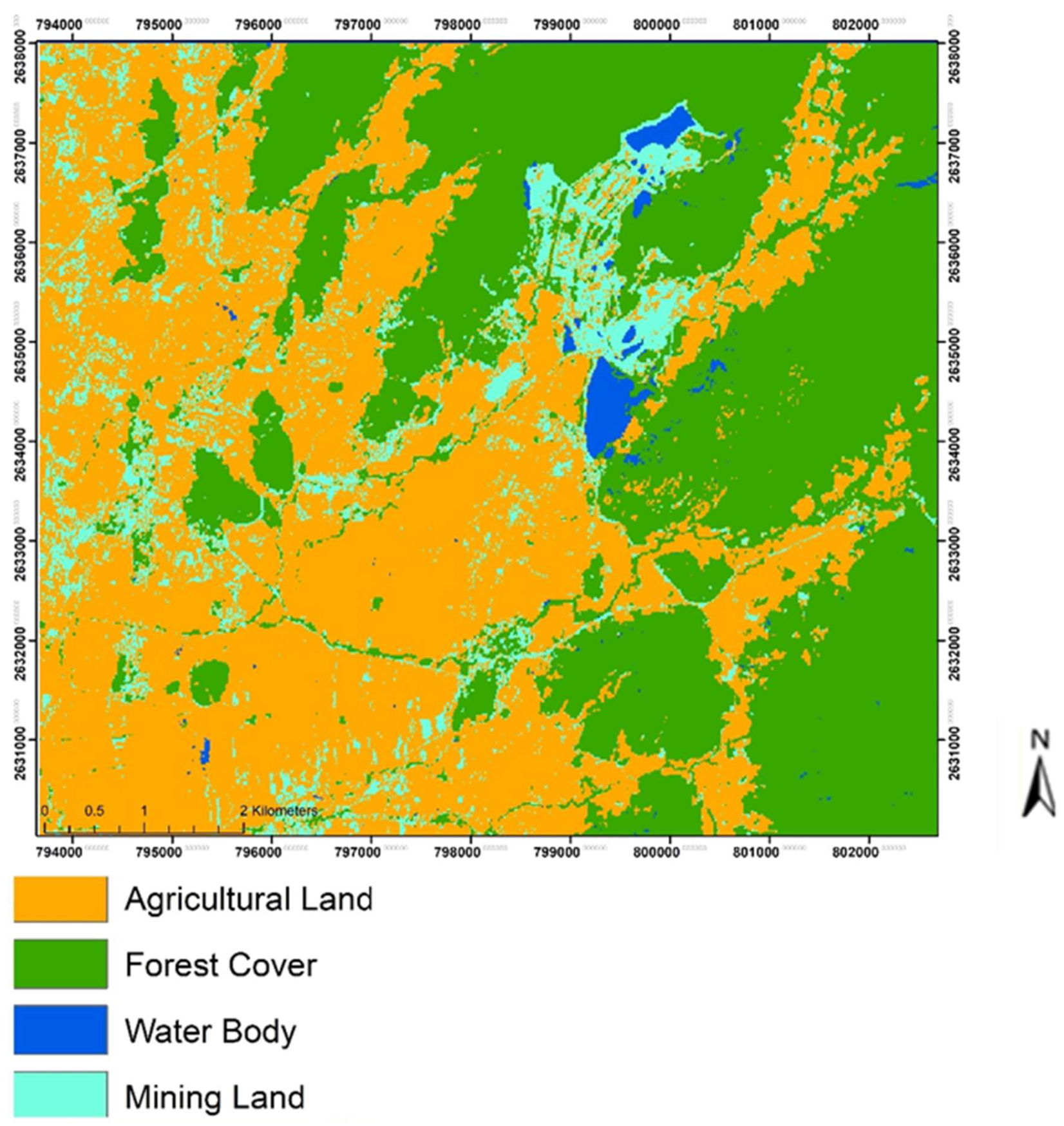
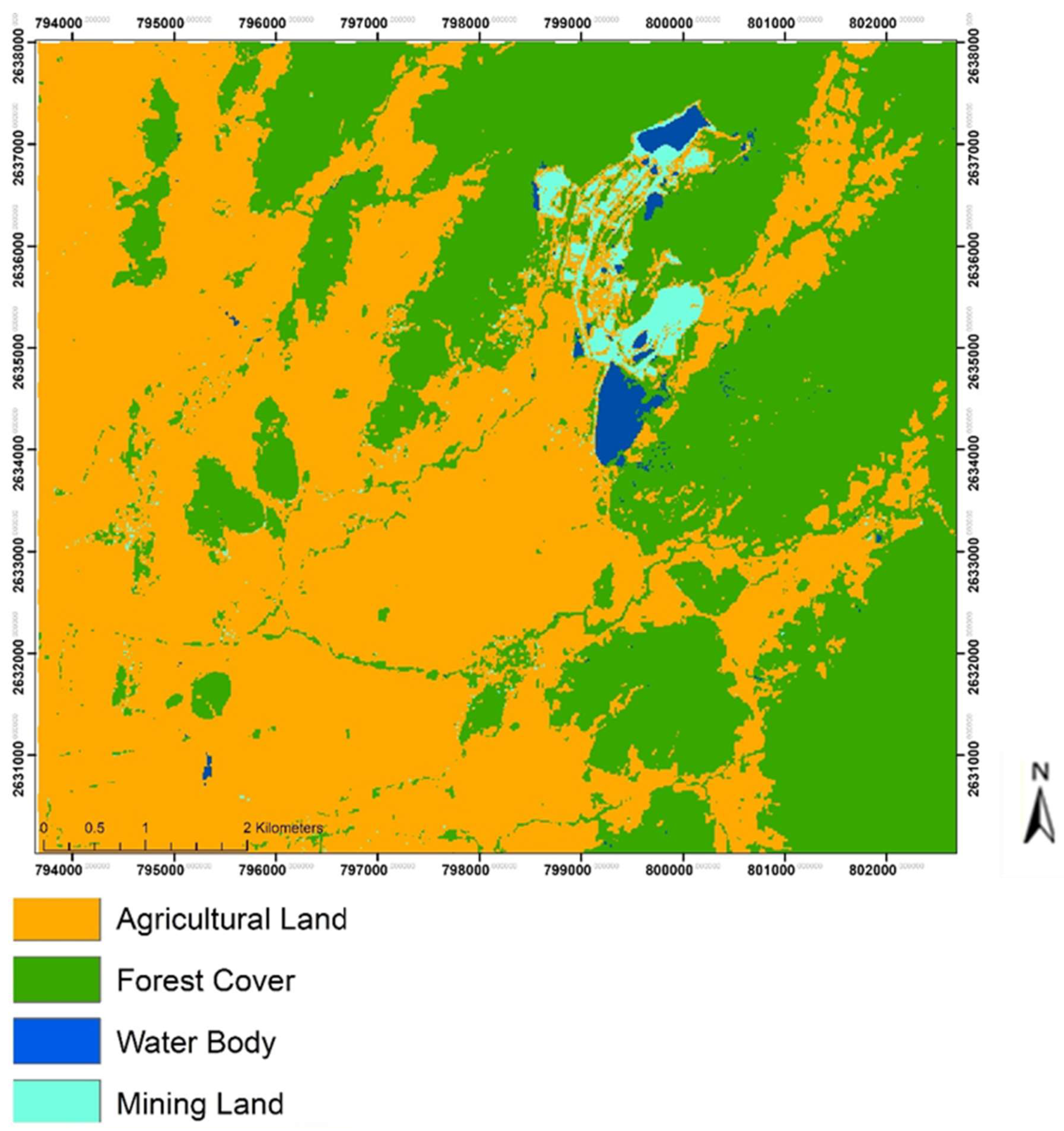
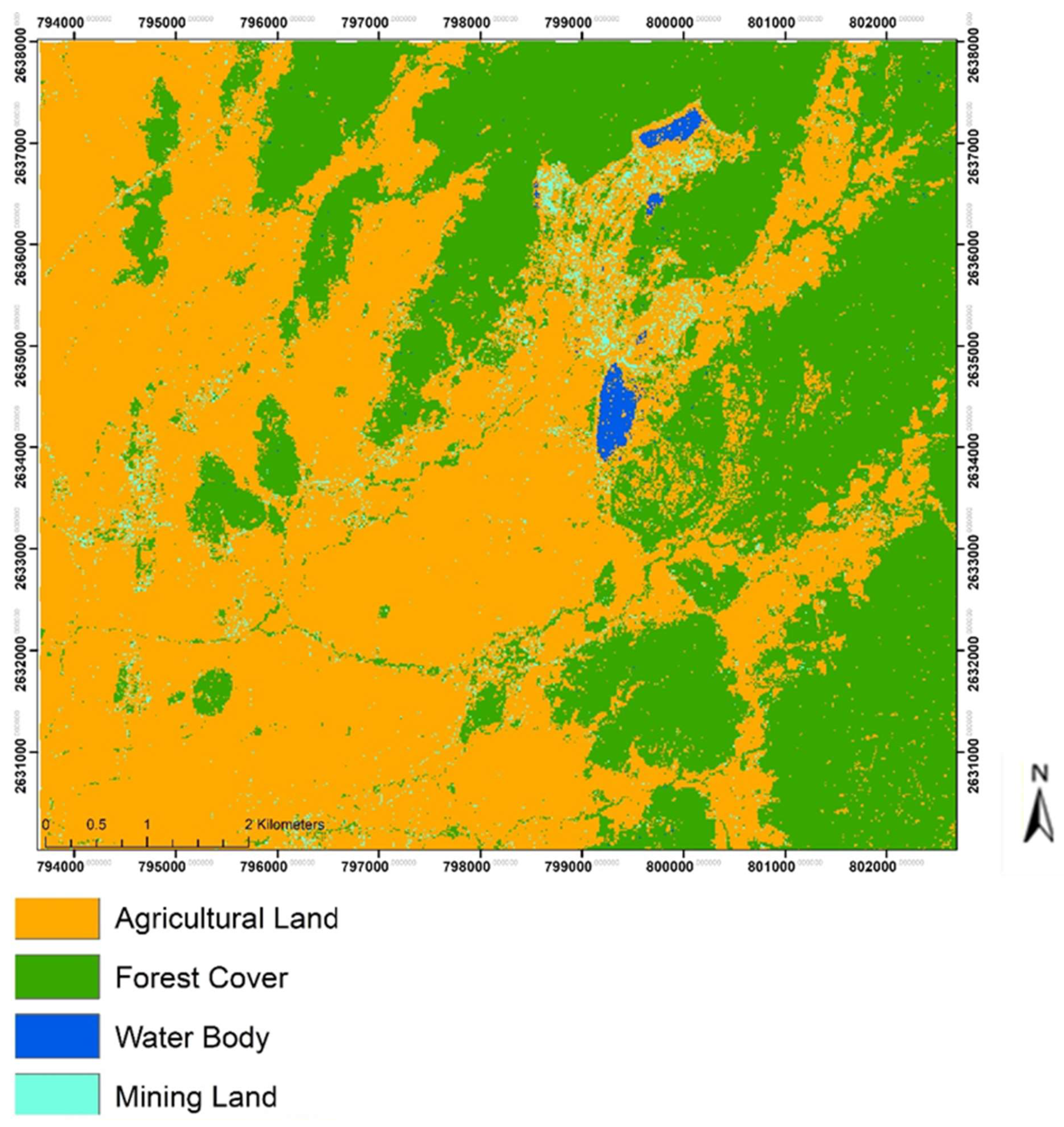
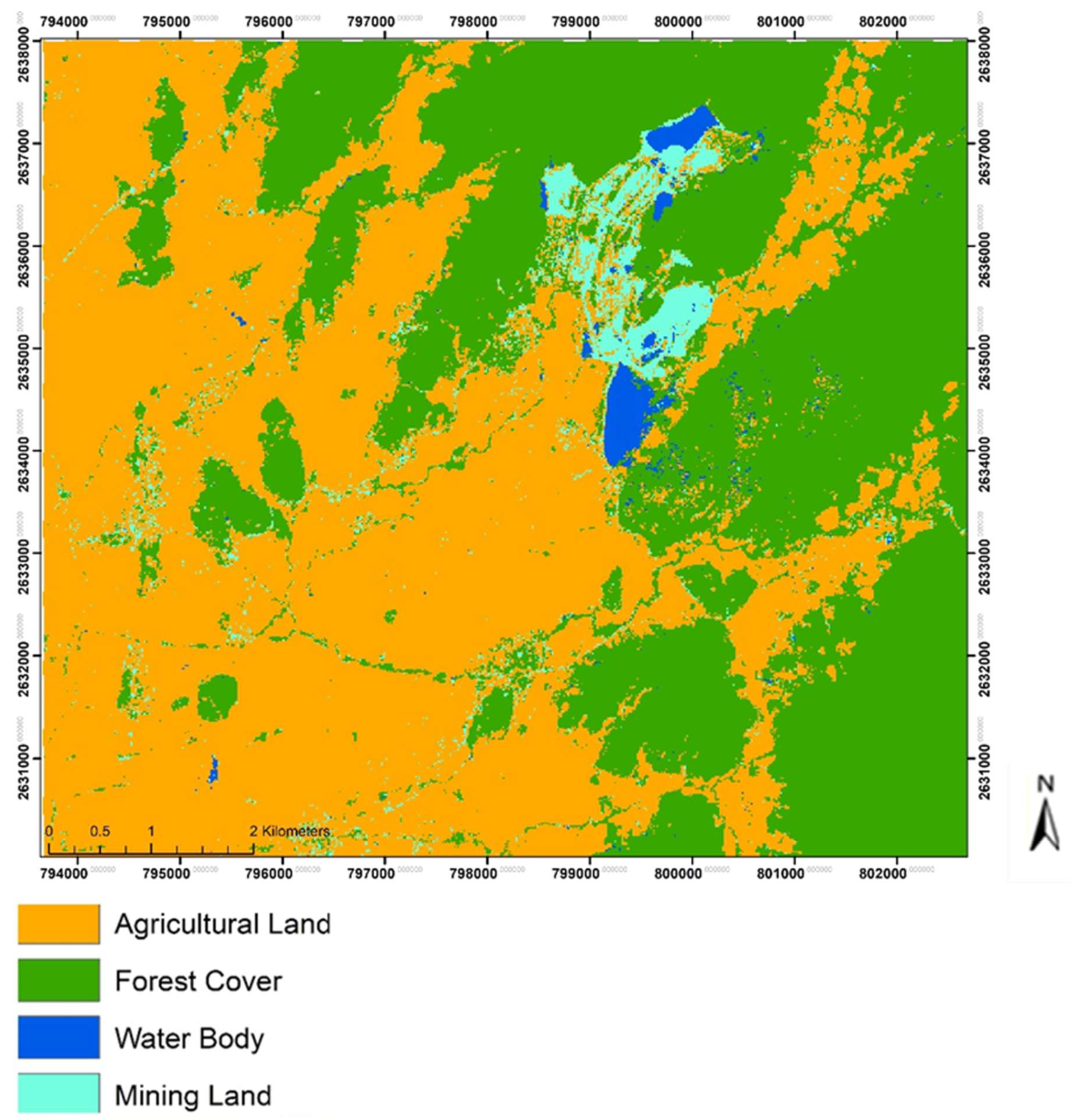
3.1. Land Use/Cover Change Analysis
3.2. Comparison of Machine Learning Algorithms
4. Discussion
4.1. Land Use/Land Cover Change in the Mining District
4.2. Performance of Four Algorithms
4.3. Recommendations for Future Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lam, N.S.N. Methodologies for mapping land cover/land use and its change. In Advances in Land Remote Sensing: System, Modeling, Inversion and Application; Liang, S., Ed.; Springer: Dordrecht, The Netherlands, 2008; pp. 341–367. [Google Scholar]
- Rimal, B.; Keshtkar, H.; Sharma, R.; Stork, N.; Rijal, S.; Kunwar, R. Simulating urban expansion in a rapidly changing landscape in eastern Tarai, Nepal. Environ. Monitor. Assess. 2019, 191, 255. [Google Scholar] [CrossRef] [PubMed]
- Cohen, W.B.; Goward, S.N. Landsat’s role in ecological applications of remote sensing. BioScience 2004, 54, 535–545. [Google Scholar] [CrossRef]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Inter. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Waske, B.; Braun, M. Classifier ensembles for land cover mapping using multitemporal SAR imagery. ISPRS J. Photogramm. Remote Sens. 2009, 64, 450–457. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with Landsat Thematic Mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef]
- Dixon, B.; Candade, N. Multispectral landuse classification using neural networks and support vector machines: One or the other, or both? Inter. J. Remote Sens. 2008, 29, 1185–1206. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Inter. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosc. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Inter. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Inter. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Ghosh, A.; Joshi, P.K. A comparison of selected classification algorithms for mapping bamboo patches in lower Gangetic plains using very high resolution WorldView 2 imagery. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 298–311. [Google Scholar] [CrossRef]
- Pouteaua, R.; Collinb, A.; Stolla, B.A. A Comparison of Machine Learning Algorithms for Classification of Tropical Ecosystems Observed by Multiple Sensors at Multiple Scales. In Proceedings of the 34th International Symposium on Remote Sensing of Environment, Sydney, Australia, 11–15 April 2011; Available online: https://www.isprs.org/proceedings/2011/ISRSE-34/211104015Final00913.pdf (accessed on 16 June 2022).
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Lizarazo, I. SVM-based segmentation and classification of remotely sensed data. Inter. J. Remote Sens. 2008, 29, 7277–7283. [Google Scholar] [CrossRef]
- Tso, B.; Mather, P. Classification Methods for Remotely Sensed Data; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Li, J.; Zipper, C.E.; Donovan, P.F.; Wynne, R.H.; Oliphant, A.J. Reconstructing disturbance history for an intensively mined region by time-series analysis of Landsat imagery. Environ. Monit. Assess. 2015, 187, 557. [Google Scholar] [CrossRef] [PubMed]
- Kamga, M.A.; Nguemhe Fils, S.C.; Ayodele, M.O.; Olatubara, C.O.; Nzali, S.; Adenikinju, A.; Khalifa, M. Evaluation of land use/land cover changes due to gold mining activities from 1987 to 2017 using landsat imagery, East Cameroon. GeoJournal 2020, 85, 1097–1114. [Google Scholar] [CrossRef]
- Mi, J.; Yang, Y.; Zhang, S.; An, S.; Hou, H.; Hua, Y.; Chen, F. Tracking the Land Use/Land Cover Change in an Area with Underground Mining and Reforestation via Continuous Landsat Classification. Remote Sens. 2019, 11, 1719. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 2nd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 3rd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Jonathan, M.; Meirelles, M.S.P.; Berroir, J.-P.; Herlin, I. Regional scale land use/landcover classification using temporal series of MODIS data. In Proceedings of the ISPRS Commission VII Mid-Term Symposium “Remote Sensing: From Pixels to Processes”, Enschede, The Netherlands, 8–11 May 2006; pp. 522–527. [Google Scholar]
- Manandhar, R.; Odeh, I.O.A.; Ancev, T. Improving the accuracy of land use and land cover classification of Landsat data using post-classification enhancement. Remote Sens. 2009, 1, 330–344. [Google Scholar] [CrossRef]
- Saha, S.K.; Kudrat, M. Selection of spectral band combination for land cover/land use classification using a brightness value overlapping index (BVOI). J. Indian Soc. Remote Sens. 1991, 19, 141–147. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Abdullah, A.Y.M.; Masrur, A.; Adnan, M.S.G.; Baky, M.; Al, A.; Hassan, Q.K.; Dewan, A. Spatio-temporal patterns of land use/land cover change in the heterogeneous coastal region of Bangladesh between 1990 and 2017. Remote Sens. 2019, 11, 790. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. In Theory of Probability and Its Applications; Springer: Cham, Switzerland, 1971; Volume 16, pp. 264–280. [Google Scholar]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth & Brooks: Monterey, CA, USA, 1984. [Google Scholar]
- Kavzoglu, T.; Colkesen, I. A kernel functions analysis for support vector machines for land cover classification. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 352–359. [Google Scholar] [CrossRef]
- Campbell, J.B. Introduction to Remote Sensing; The Guilford Press: New York, NY, USA, 1996. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Land Use/Cover Class | Training Samples | Testing Samples |
|---|---|---|
| Agricultural Land | 258 | 112 |
| Forest Cover | 235 | 101 |
| Water Body | 82 | 35 |
| Mining Land | 150 | 65 |
| Land Use/Cover Type | 1990 | 1995 | 2000 | 2005 | 2010 | 2015 | 2020 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| km2 | % | km2 | % | km2 | % | km2 | % | km2 | % | km2 | % | km2 | % | |
| Agricultural Land | 48.9 | 37.1 | 48.1 | 36.5 | 50.7 | 38.4 | 56.8 | 43.0 | 50.9 | 38.6 | 51.9 | 39.3 | 59.6 | 45.2 |
| Forest Cover | 50.0 | 37.8 | 50.8 | 38.5 | 47.4 | 35.9 | 41.9 | 31.7 | 45.8 | 34.7 | 44.2 | 33.5 | 36.1 | 27.3 |
| Water Body | 0.4 | 0.3 | 0.7 | 0.6 | 1.2 | 0.9 | 0.2 | 0.2 | 0.6 | 0.4 | 0.7 | 0.5 | 0.7 | 0.5 |
| Mining Land | 0.7 | 0.5 | 0.3 | 0.3 | 0.7 | 0.5 | 1.1 | 0.8 | 2.7 | 2.1 | 3.2 | 2.4 | 3.6 | 2.7 |
| Land Use/Cover Type | 1990–1995 | 1995–2000 | 2000–2005 | 2005–2010 | 2010–2015 | 2015–2020 | 1990–2020 |
|---|---|---|---|---|---|---|---|
| Agricultural Land | −0.8 | 2.5 | 6.1 | −5.9 | 1.0 | 7.7 | 10.7 |
| Forest Cover | 0.8 | −3.4 | −5.5 | 4.0 | −1.6 | −8.1 | −13.9 |
| Water Body | 0.3 | 0.5 | −1.0 | 0.3 | 0.1 | 0.0 | 0.2 |
| Mining Land | −0.3 | 0.4 | 0.4 | 1.6 | 0.5 | 0.4 | 2.9 |
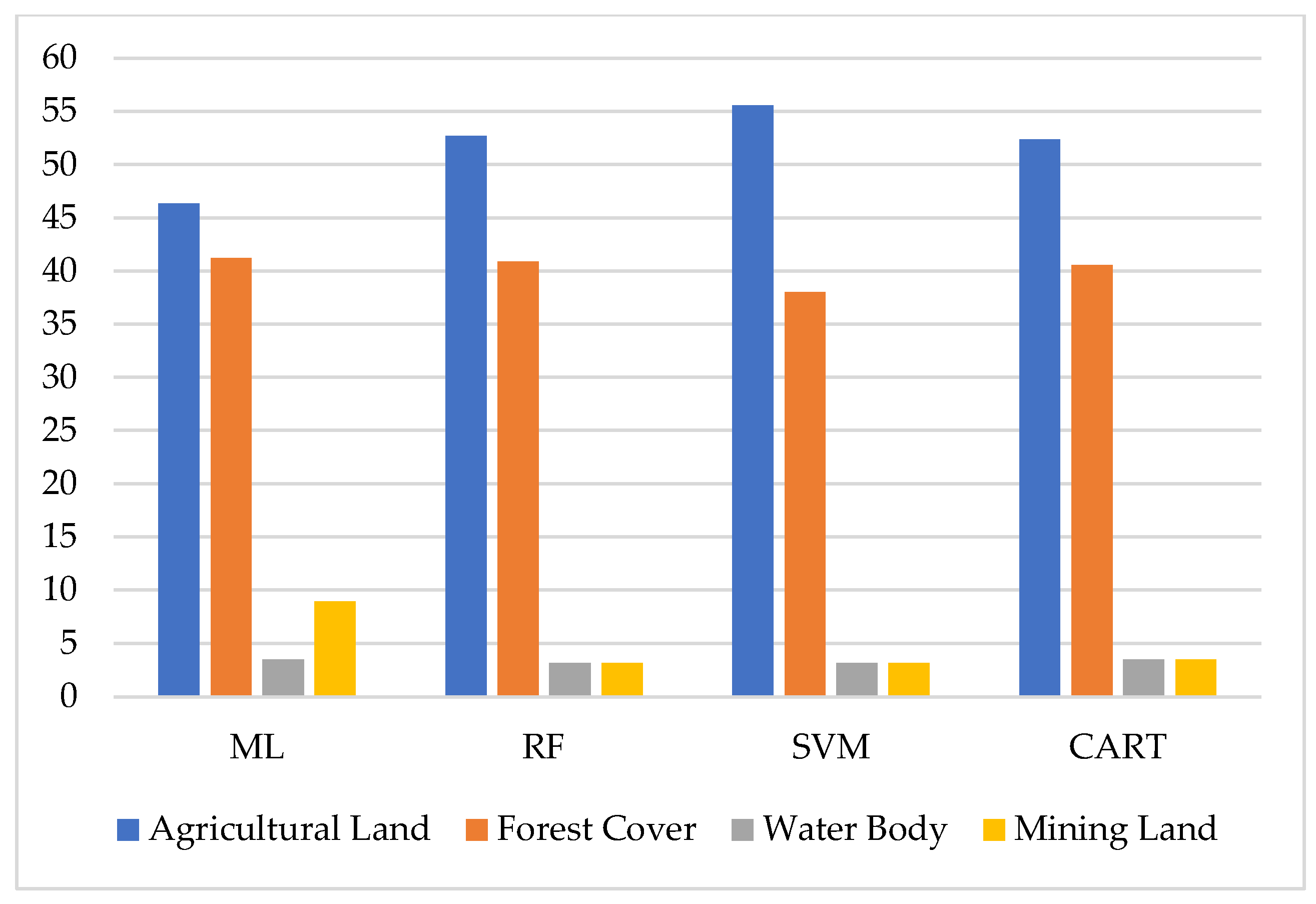
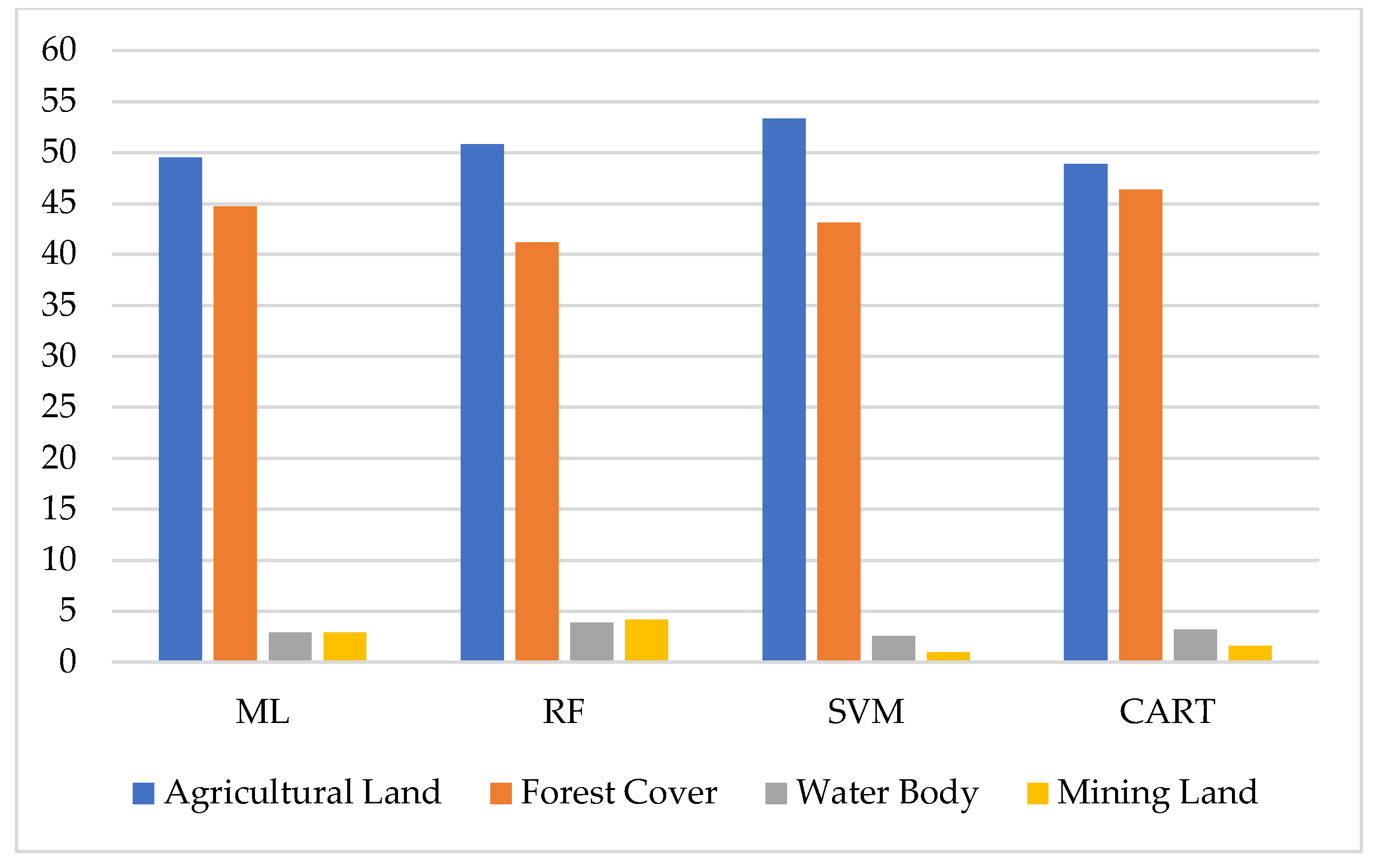
| Machine Learning Algorithms | Agricultural Land | Forest Cover | Water Body | Mining Land | |
|---|---|---|---|---|---|
| Maximum likelihood classification | Agricultural Land | 139 | 5 | 0 | 1 |
| Forest Cover | 0 | 128 | 1 | 0 | |
| Water Body | 2 | 1 | 8 | 0 | |
| Mining Land | 14 | 6 | 0 | 8 | |
| Random forest classification | Agricultural Land | 157 | 5 | 0 | 3 |
| Forest Cover | 1 | 124 | 2 | 1 | |
| Water Body | 0 | 0 | 10 | 0 | |
| Mining Land | 1 | 0 | 0 | 9 | |
| SVM classification | Agricultural Land | 159 | 14 | 0 | 1 |
| Forest Cover | 1 | 118 | 0 | 0 | |
| Water Body | 1 | 1 | 8 | 0 | |
| Mining Land | 6 | 2 | 0 | 2 | |
| CART classification | Agricultural Land | 147 | 17 | 0 | 0 |
| Forest Cover | 2 | 124 | 1 | 0 | |
| Water Body | 0 | 2 | 9 | 0 | |
| Mining Land | 4 | 2 | 0 | 5 |
| Algorithm | Overall Accuracy (%) | Kappa Value |
|---|---|---|
| Maximum Likelihood | 90.42 | 0.84 |
| Random Forest | 95.85 | 0.93 |
| Support Vector Machine | 91.69 | 0.85 |
| Classification and Regression Trees | 91.05 | 0.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oo, T.K.; Arunrat, N.; Sereenonchai, S.; Ussawarujikulchai, A.; Chareonwong, U.; Nutmagul, W. Comparing Four Machine Learning Algorithms for Land Cover Classification in Gold Mining: A Case Study of Kyaukpahto Gold Mine, Northern Myanmar. Sustainability 2022, 14, 10754. https://doi.org/10.3390/su141710754
Oo TK, Arunrat N, Sereenonchai S, Ussawarujikulchai A, Chareonwong U, Nutmagul W. Comparing Four Machine Learning Algorithms for Land Cover Classification in Gold Mining: A Case Study of Kyaukpahto Gold Mine, Northern Myanmar. Sustainability. 2022; 14(17):10754. https://doi.org/10.3390/su141710754
Chicago/Turabian StyleOo, Tin Ko, Noppol Arunrat, Sukanya Sereenonchai, Achara Ussawarujikulchai, Uthai Chareonwong, and Winai Nutmagul. 2022. "Comparing Four Machine Learning Algorithms for Land Cover Classification in Gold Mining: A Case Study of Kyaukpahto Gold Mine, Northern Myanmar" Sustainability 14, no. 17: 10754. https://doi.org/10.3390/su141710754
APA StyleOo, T. K., Arunrat, N., Sereenonchai, S., Ussawarujikulchai, A., Chareonwong, U., & Nutmagul, W. (2022). Comparing Four Machine Learning Algorithms for Land Cover Classification in Gold Mining: A Case Study of Kyaukpahto Gold Mine, Northern Myanmar. Sustainability, 14(17), 10754. https://doi.org/10.3390/su141710754