
An Improved Optimization Algorithm Based on Density Grid for Green Storage Monitoring System



Abstract
:1. Introduction
1.1. Status of Research on Corn Storage Monitoring Data
- (1)
- Moisture content is an important indicator of corn quality.
- (2)
- The fatty acid value of corn is also an important indicator for quality testing.
- (3)
- Mold is another quality testing standard.
1.2. Current Status of Research Applications of Data Processing Algorithms
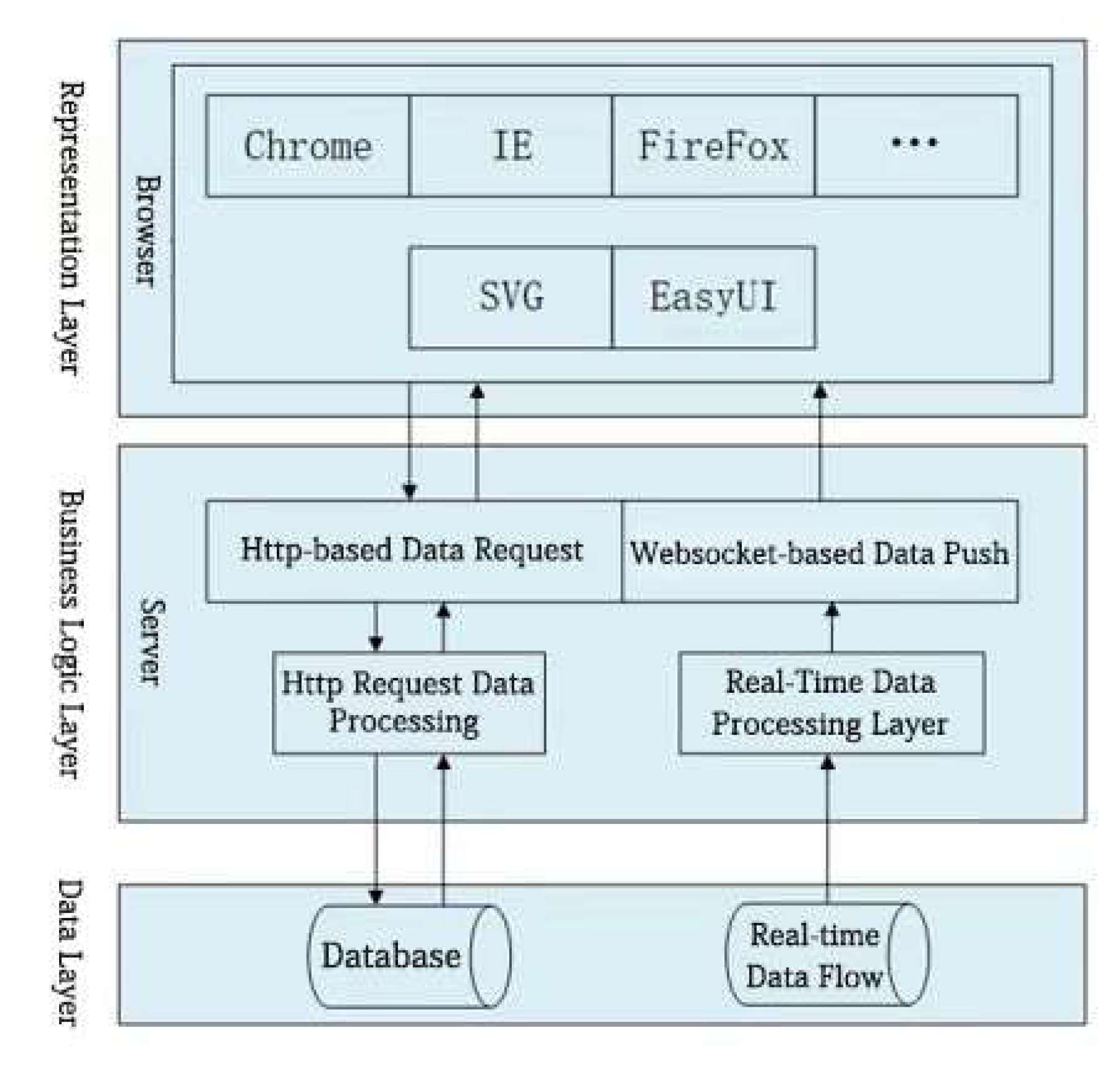
2. Materials and Methods
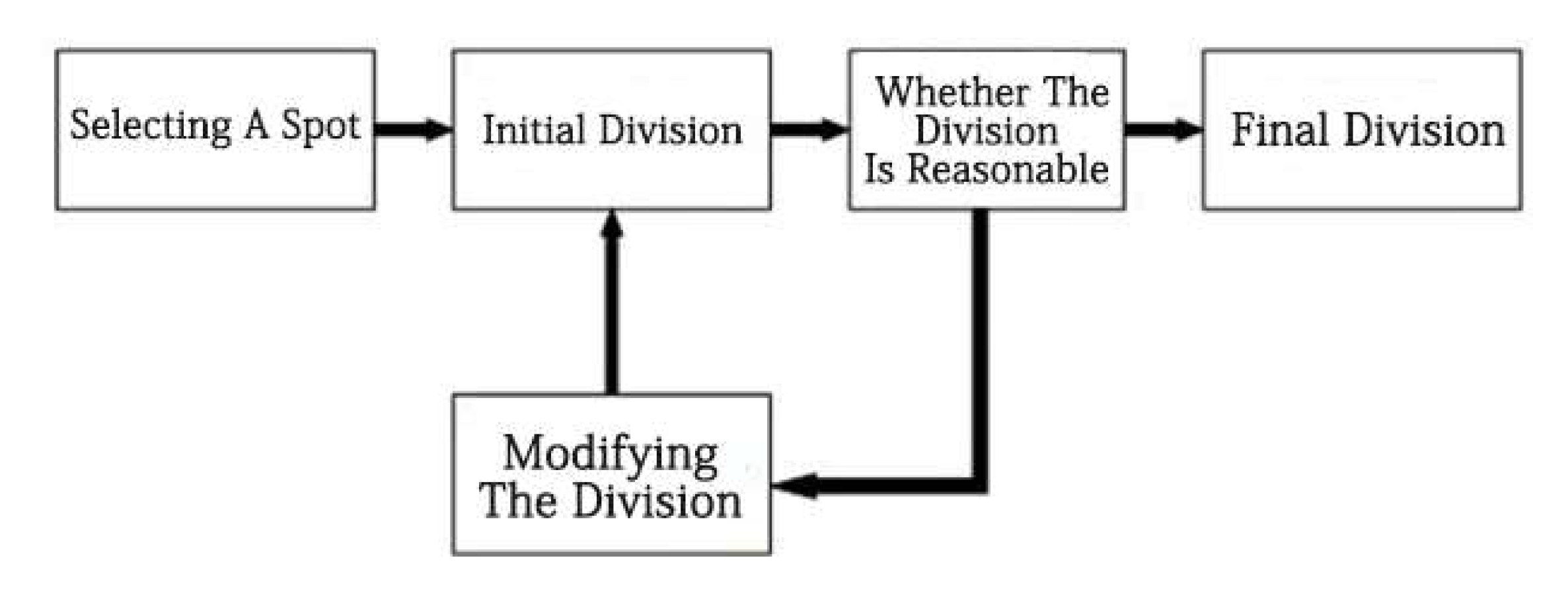
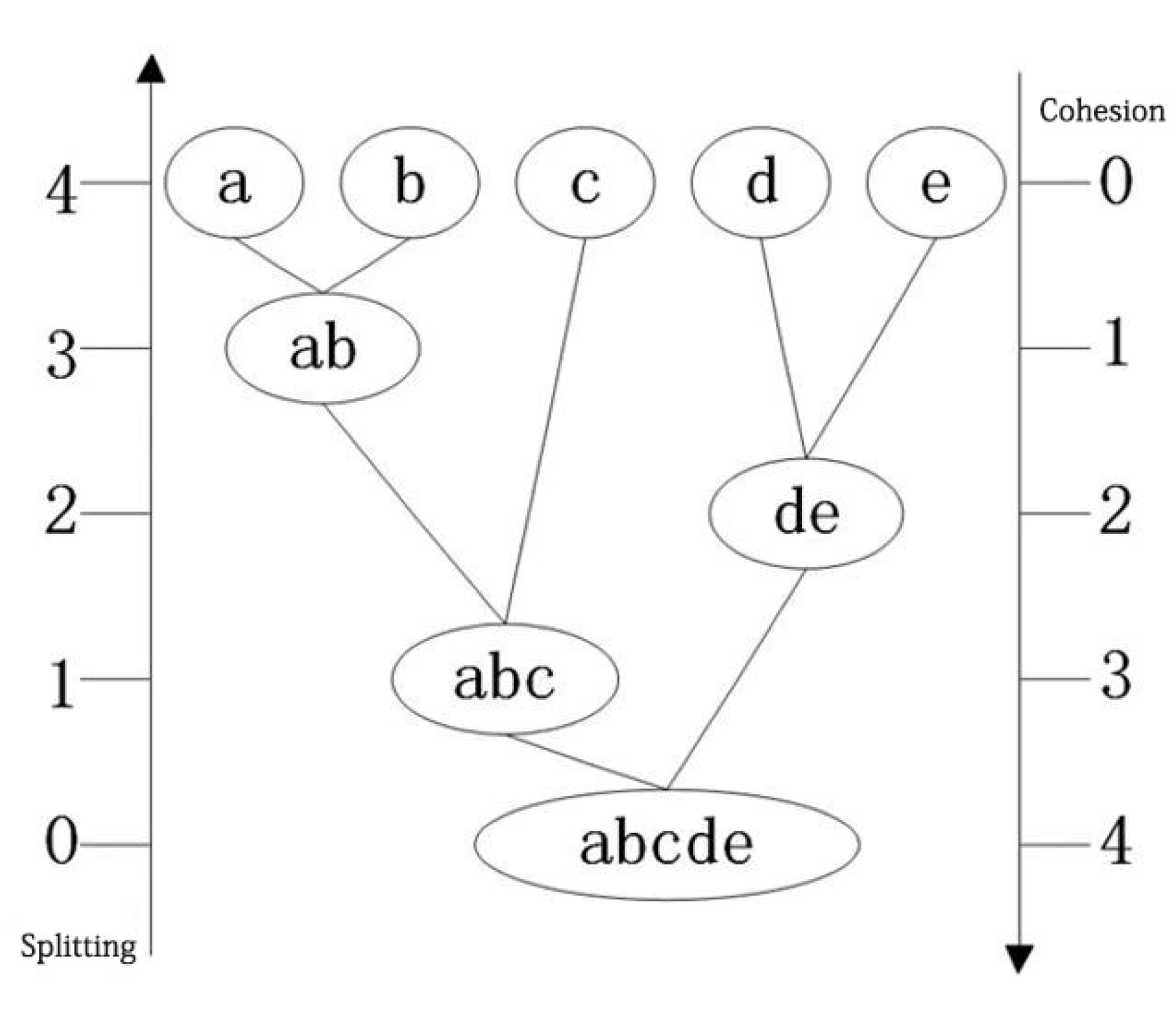
Relevant Definitions of the Improved Algorithm
3. Correlation Modeling of the Improved Algorithm
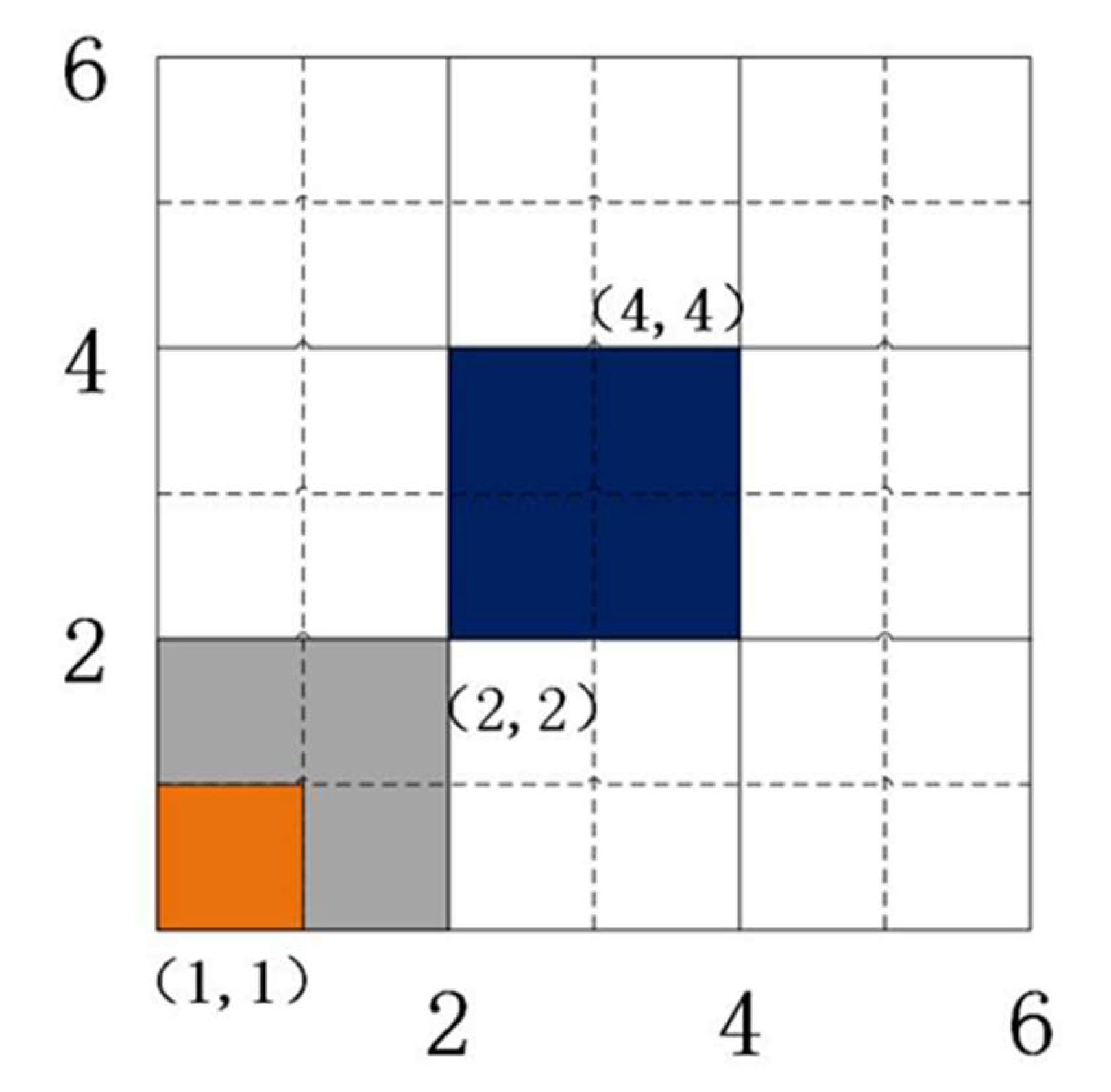
3.1. Adjacent Grid Determination
3.2. Determination of a Boundary Mesh
| Algorithm 1 Steps for determining the boundary grid | |
| Input: Feature vector of the grid to be determined, summary storage mechanism W_List | |
| Output: Bounding mesh identifier Bound | |
| 1: | if (adjacent mesh of input mesh does not exist in W_List) |
| 2: | return the grid is a boundary grid |
| 3: | else if (the density of adjacent grid cells of this grid are above the sparsity threshold Ds or the density of adjacent grid neighboring subgrids is above the subgrid sparsity threshold Ds_little) |
| 4: | return the grid is an interior grid |
| 5: | else{ |
| 6: | return the grid |
| 7: | }//end else if |
3.3. Detection and Processing of Isolated Grid Cells
3.4. Microclustering Algorithm
| Algorithm 2 Steps of microcluster clustering | |
| Input: the set of internal grid cells in the dynamic grid | |
| Output: set of grid clusters | |
| 1: | Detect all internal grid cells and update the grid cell feature vector |
| 2: | While (the class attributes within the set of dynamic internal grid cells no longer change) |
| 3: | { for(dynamic internal grid cell W1) |
| 4: | { if(dynamic internal grid cells of W1 exist adjacent to the internal grid W2) |
| 5: | compute Fac(W1,W2); |
| 6: | if (there exists an adjacent grid cell W2 of W1 such that Fac(W1,W2) is maximum) |
| 7: | group grid W2 and W1 into the same cluster. |
| 8: | else group grid W1 as a separate cluster and update flag Cla. |
| 9: | }//end for |
| 10: | }//end while |
3.5. Clustering Algorithm for Boundary Subgrids
| Algorithm3 Steps of clustering algorithm for boundary subgrid | |
| Input: the boundary grid W1 and its subgrid feature vectors, the set of grid feature vectors | |
| Output: the classes to which the subgrids of grid W1 belong. | |
| 1: | obtain information about the boundary grid and its subgrid feature vectors. |
| 2: | if (grid W1 adjacent grid has internal grid) |
| 3: | { for(internal grid W) |
| 4: | { for(subgrid cell Wlittle) |
| 5: | { if(subgrid cell density reaches subgrid density threshold Df-little) |
| 6: | if the subgrid adjacent grid has a large grid that has been divided into classes, calculate the density factor, group the subgrid into the class where the grid with the largest Fac is located, and update the subgrid cell feature vector. |
| 7: | else ignore this sub-grid, i.e., the clustering grid density requirement is not met. |
| 8: | }//end for |
| 9: | }//end for |
| 10: | }//end if |
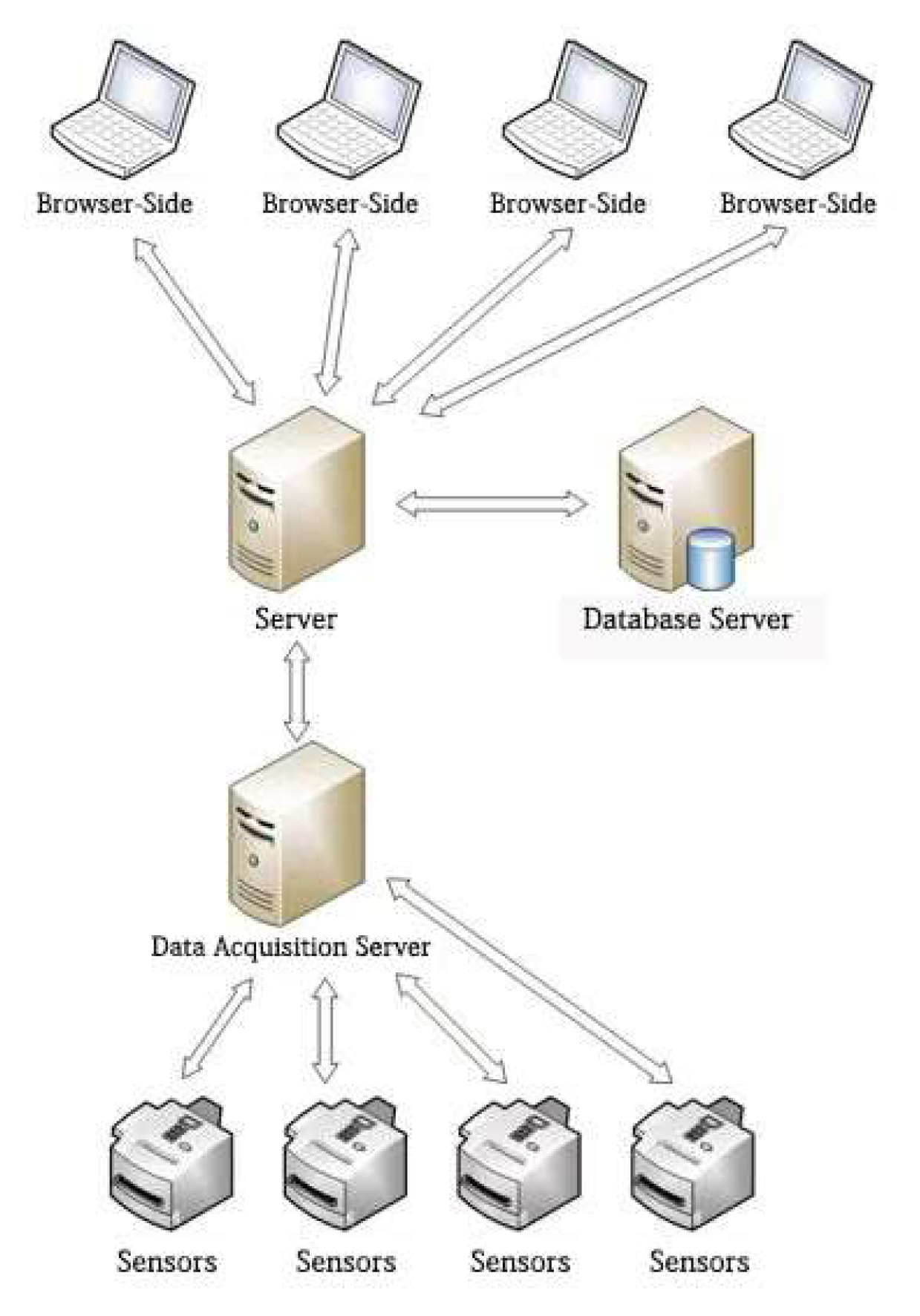
4. Application of the Improved Algorithm in the Corn Storage Monitoring System
| Algorithm4 Steps to improve algorithms in monitoring systems | |
| 1: | Initialize the division grid, initialize the grid maintenance cell W_List, current time t; |
| 2: | While (data flow is not finished) |
| 3: | { read in data item Y, preprocess the data, map to the corresponding grid, update the grid tuple and put it in the data structure information table W_List |
| 4: | if (t = T)//i.e. time reaches the first interval |
| 5: | adjudicate the boundary grid and form the initial grid according to the microcluster clustering algorithm. |
| 6: | if (t > T and t mod T = 0)//that is, the time to reach the second and subsequent intervals |
| 7: | { decay the grid density according to the decay function and update the grid tuple. |
| 8: | detection and processing of isolated meshes. |
| 9: | adjusting the boundary grid and internal grid information to the density grid microclusters. |
| 10: | starting a new thread to invoke the offline algorithm. |
| 11: | Offline clustering. |
| 12: | Matching analysis results. |
| 13: | Snapshot storage of summary information. |
| 14: | WebSocket message pushing. |
| 15: | }//end if |
| 16: | }//end While |
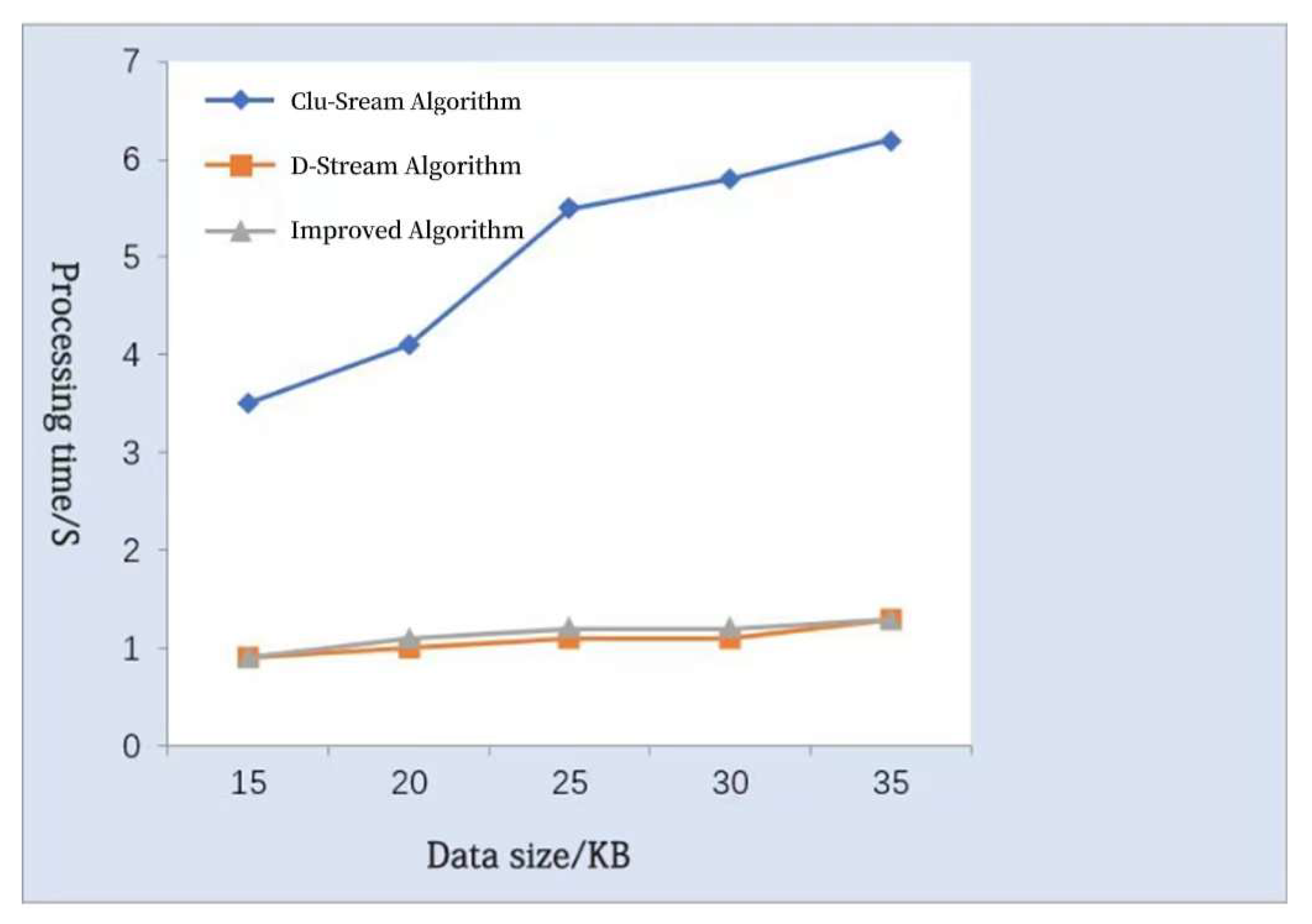
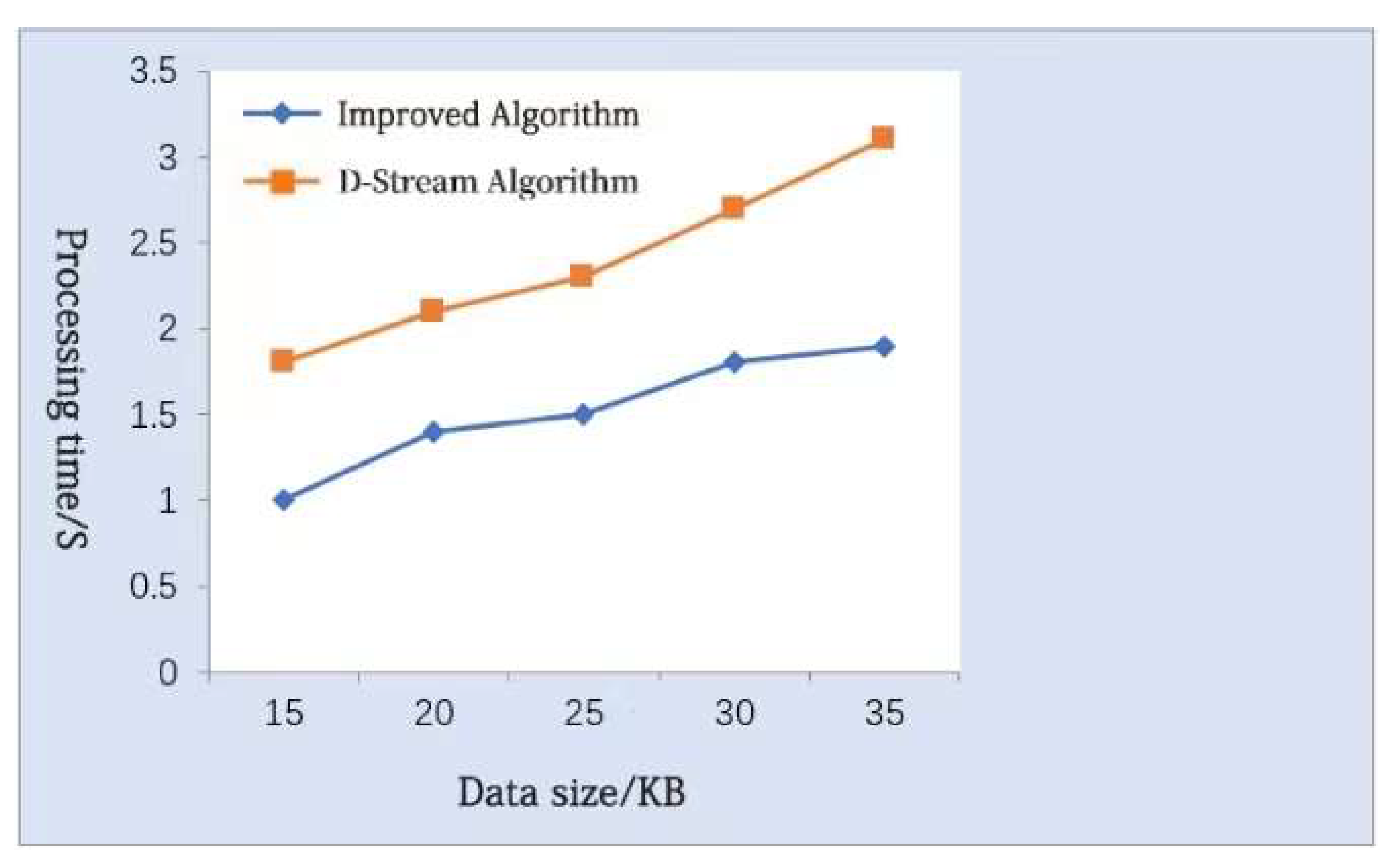
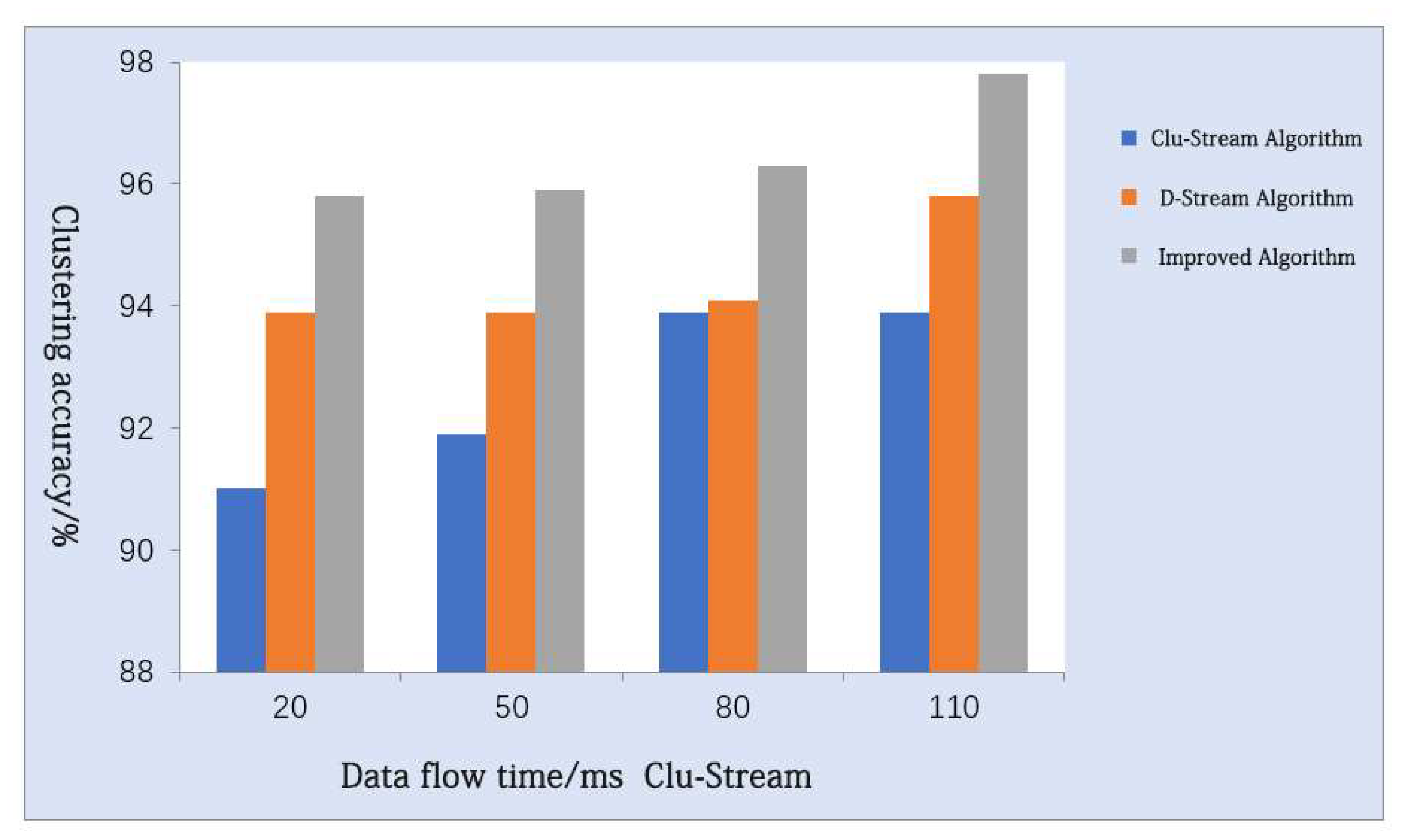
4.1. Analysis of the Operational Effect of the Improved Algorithm
4.1.1. Operation of the Improved Algorithm
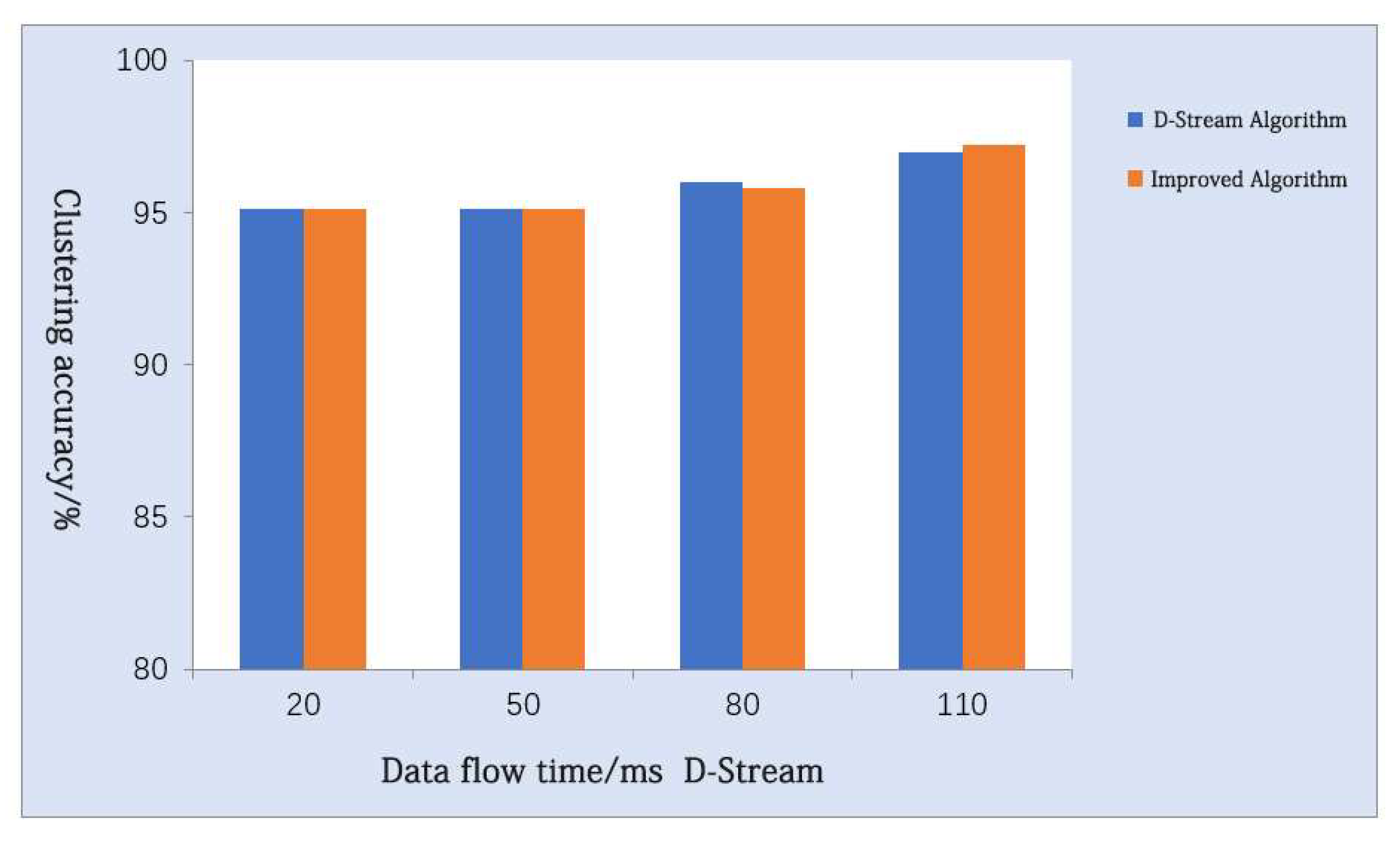
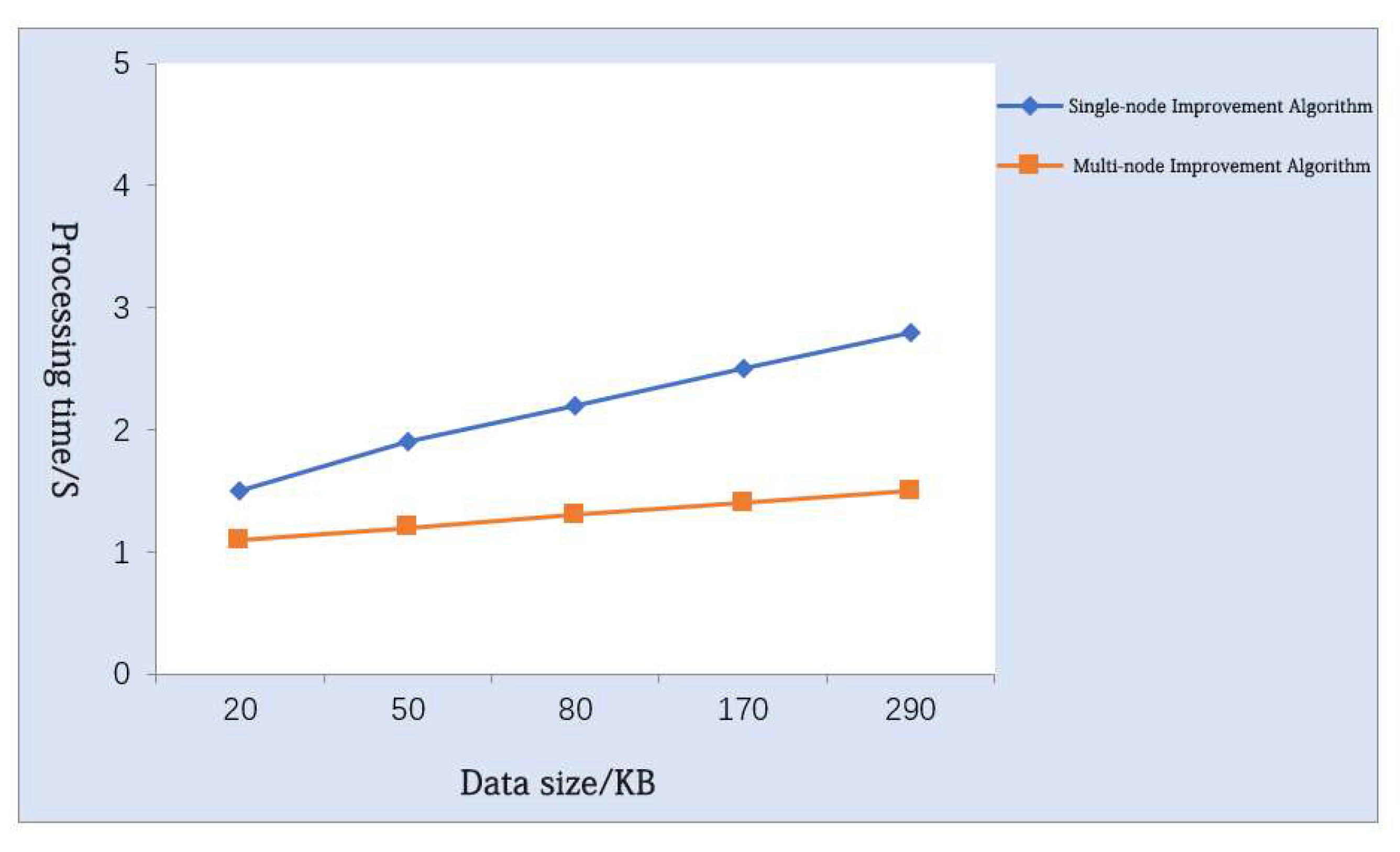
4.1.2. Comparative Analysis of the Improved Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rostamzadeh, R.; Govindan, K.; Esmaeili, A.; Sabaghi, M. Application of fuzzy VIKOR for evaluation of green supply chain management practices. Ecol. Indic. 2015, 49, 188–203. [Google Scholar] [CrossRef]
- Kumar, N.; Agrahari, R.P.; Roy, D. Review of green supply chain processes. Ifac-Pap. 2015, 48, 374–381. [Google Scholar] [CrossRef]
- Mao, J.; Sun, Q.; Ma, C.; Tang, M. Site selection of straw collection and storage facilities considering carbon emission reduction. Environ. Sci Pollut Res. 2021. [Google Scholar] [CrossRef]
- Mao, J.; Hong, D.; Chen, Z.; Changhai, M.; Weiwen, L.; Wang, J. Disassembly sequence planning of waste auto parts. J. Air Waste Manag. Assoc. 2021, 71, 607–619. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Tian, Z.; Liu, W.; Tian, G.; Gao, Y.; Xing, F.; Suo, Y.; Song, B. An energy-efficient method of laser remanufacturing process. Sustain. Energy Technol. Assess. 2022, 52, 102201. [Google Scholar] [CrossRef]
- Yin, Y.X.; Chen, L.; Meng, Z.; Li, B.; Luo, C.; Fu, W.; Mei, H.; Qin, W. Design and evaluation of a maize monitoring system for precision planting. Int. J. Agric. Biol. Eng. 2018, 11, 166–170. [Google Scholar] [CrossRef]
- Irmak, S.; Haman, D.Z.; Bastug, R. Determination of Crop Water Stress Index for Irrigation Timing and Yield Estimation of Corn. Agron. J. 2000, 92, 1221–1227. [Google Scholar] [CrossRef]
- Holmes, M.; Renk, J.S.; Coaldrake, P.; Kalambur, S.; Schmitz, C.; Anderson, N.; Gusmini, G.; Annor, G.; Hirsch, C.N. Food-Grade Maize Composition, Evaluation, and Genetics for Masa-Based Products. Crop Sci. 2019. [Google Scholar] [CrossRef]
- Pippenger, N.; Segall, R.S.; Berleant, D.; Eversole, K.A.; Mustell, R.A.; Hood, E.E. Extracting Numerical Information about Corn Composition from Texts (Invited Paper). J. Syst. Cybern. Inform. 2015, 13, 68–75. [Google Scholar]
- Ni, B.; Paulsen, M.R.; Reid, J.F. Corn Kernel Crown Shape Ientification Using Image Processing. Trans. ASAE 1997, 40, 833–838. [Google Scholar] [CrossRef]
- Wang, W.C.; Wang, L. Design of Moisture Content Detection System. Phys. Procedia 2012, 33, 1408–1411. [Google Scholar] [CrossRef] [Green Version]
- Tan, L.B.; Ji, H.Y. Study on Grain Moisture Detection System Based on the Theory of Dielectric Properties. Appl. Mech. Mater. 2013, 333–335, 1558–1563. [Google Scholar] [CrossRef]
- Zhao, X.; Wei, J.; He, L.; Zhang, Y.; Zhao, Y.; Xu, X.; Wei, Y.; Ge, S.; Ding, D.; Liu, M.; et al. Identification of Fatty Acid Desaturases in Maize and Their Differential Responses to Low and High Temperature. Genes 2019, 10, 445. [Google Scholar] [CrossRef] [PubMed]
- Sanjeev, P.; Chaudhary, D.P.; Sreevastava, P.; Saha, S.; Rajenderan, A.; Sekhar, J.C.; Chikkappa, G.K. Comparison of Fatty Acid Profile of Specialty Maize to Normal Maize. JAOCS. J. Am. Oil Chem. Soc. 2014, 91, 1001–1005. [Google Scholar] [CrossRef]
- Lam, H.S.; Proctor, A. Rapid Methods for Milled Rice Surface Total Lipid and Free Fatty Acid Determination. Cereal Chem. 2001, 78, 498–499. [Google Scholar] [CrossRef]
- Dou, Y.P. Determination of fatty acid values of corn by potentiometric titration. Grain Oil Storage Sci. Technol. Commun. 2004, 3, 47–49. [Google Scholar]
- Liu, Y.; Zhai, H.B.; Cai, J.P. Early warning of aflatoxin production in stored maize using monitoring CO2 method. Mod. Food Sci. Technol. 2015, 31, 309–315. [Google Scholar]
- Huichun, Y.U.; Lou, N.; Yin, Y.; Liu, Y. Study on Detection Model of Maize Toxin with Algorithm of SPXY and SPA Based on Hyperspectral Technology. Food Sci. 2018, 39, 328–335. [Google Scholar]
- Techniques for the Discovery of Patterns Hidden in Large Data Sets and Process Flow of Data Mining. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 2480–2483. [CrossRef]
- Tencent Technology (Shenzhen, China) Company Limited. Data Batch Processing Method and System. US Patent 10,803,433, 13 October 2020.
- Victorovich, K.K. A Multilevel Scheduling Model for Data Batches Processing in Conveyor Systems when Forming Sets and in the Presence of Restriction. SPIIRAS Proc. 2016, 4, 65. [Google Scholar] [CrossRef]
- Goudarzi, M. Heterogeneous Architectures for Big Data Batch Processing in MapReduce Paradigm. IEEE Trans. Big Data 2019, 5, 18–33. [Google Scholar] [CrossRef]
- Hensel, C.; Junges, S.; Katoen, J.; Quatmann, T.; Volk, M. The probabilistic model checker Storm. Int. J. Softw. Tools Technol. Transf. 2022, 24, 589–610. [Google Scholar] [CrossRef]
- Research on Real-Time Anomaly Detection of Massive Log Streams Based on DME Cluster Analysis Model; Hangzhou University of Electronic Science and Technology: Hangzhou, China, 2017.
- Chen, F.M.; Han, D.Z.; Bi, K.; Dai, Y.T. Exploration of key technologies for distributed data stream processing in big data environment. Comput. Appl. 2017, 37, 620–627. [Google Scholar] [CrossRef]
- Chen, F. Research and Application of Data Stream Anomaly Detection Technology. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD2011&filename=2010234254.nh&uniplatform=NZKPT&v=SwOVri0cKXGi4psyVacEyw4DekFbZXLvDIkK2-b8EvXAWNNBPcQa8ronLw8XZ7fD (accessed on 22 July 2022).
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-based outliers: Algorithms and applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Knorr, E.M.; Ng, R.T. Algorithms for Mining Distance-Based Outliers in Large Datasets. In Proceedings of the International Conference on Very Large Data Bases, New York, NY, USA, 24–27 August 1998; pp. 392–403. [Google Scholar]
- Kumar, P.K.; Diwakar, S. Maxmin distance sort heuristic-based initial centroid method of partitional clustering for big data mining. Pattern Anal. Appl. 2022, 25, 139–156. [Google Scholar] [CrossRef]
- Kamlesh, P.K.; Diwakar, S. Maxmin Data Range Heuristic-Based Initial Centroid Method of Partitional Clustering for Big Data Mining. Int. J. Inf. Retr. Res. (IJIRR) 2021, 12, 1–22. [Google Scholar] [CrossRef]
- Narjes, V.; Mirzabeigi, M.; Sotudeh, H.; Fakhrahmad, S.M. Application of k-means clustering algorithm to improve effectiveness of the results recommended by journal recommender system. Scientometrics 2022, 127, 3237–3252. [Google Scholar] [CrossRef]
- Awad, F.H.; Hamad, M.M. Improved k-Means Clustering Algorithm for Big Data Based on Distributed SmartphoneNeural Engine Processor. Electronics 2022, 11, 883. [Google Scholar] [CrossRef]
- Bock, F. Hierarchy cost of hierarchical clusterings. J. Comb. Optim. 2022, 44, 617–634. [Google Scholar] [CrossRef]
- Naik, C.; Shetty, P.D. FLAG: Fuzzy logic augmented game theoretic hybrid hierarchical clustering algorithm for wireless sensor networks. Telecommun. Syst. 2022, 79, 559–571. [Google Scholar] [CrossRef]
- Khader, M.; Al-Naymat, G. An overview of various enhancements of DENCLUE algorithm. In Proceedings of the DATA’19: International Conference on Data Science, E-learning and Information Systems 2019, Dubai, United Arab Emirates, 2–5 December 2019. [Google Scholar] [CrossRef]
- Alexander, K.; Peciar, P.; Coffey, K.; Bryan, K.; Lenihan, S. A combination of density-based clustering method and DEM to numerically investigate the breakage of bonded pharmaceutical granules in the ball milling process. Particuology 2021, 58, 153–168. [Google Scholar] [CrossRef]
- Kazemi, U.; Boostani, R. FEM-DBSCAN: An Efficient Density-Based Clustering Approach. Iran. J. Sci. Technol. Trans. Electr. Eng. 2021, 45, 979–992. [Google Scholar] [CrossRef]
- Suo, M.L.; Zhou, D.; Ruoming, A.; Shunli, L. Neighborhood density grid clustering algorithm and application. J. Tsinghua Univ. 2018, 58, 732–739. [Google Scholar] [CrossRef]
- Weber, C.M.; Ray, D.; Valverde, A.A.; Clark, J.A.; Sharma, K.S. Gaussian mixture model clustering algorithms for the analysis of high-precision mass measurements. Nucl. Inst. Methods Phys. Res. 2022, 1027, 166299. [Google Scholar] [CrossRef]
- García-Escudero, L.A.; Mayo-Iscar, A.; Riani, M. Constrained parsimonious model-based clustering. Stat. Comput. 2021, 32, 2. [Google Scholar] [CrossRef] [PubMed]
- Mohammadi, M.; Gheibi, M.; Fathollahi-Fard, A.M.; Eftekhari, M.; Tian, G. A hybrid computational intelligence approach for bioremediation of amoxicillin based on fungus activities from soil resources and aflatoxin b1 controls. J. Environ. Manag. 2021, 299, 113594. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Monitoring Point | Molded Grain % | Moisture Content % | Capacity Weight g/L |
|---|---|---|---|
| 1 | 0.0 | 10.9 | 741 |
| 2 | 0.0 | 11.1 | 738 |
| 3 | 0.1 | 11.0 | 742 |
| 4 | 0.0 | 12.7 | 551 |
| 5 | 0.0 | 12.7 | 756 |
| 6 | 1.2 | 12.2 | 753 |
| 7 | 0.0 | 12.0 | 732 |
| 8 | 0.6 | 15.1 | 743 |
| 9 | 3.0 | 12.8 | 620 |
| 10 | 1.2 | 17.5 | 638 |
| 11 | 0.2 | 13.6 | 560 |
| 12 | 4.0 | 10.9 | 652 |
| 13 | 6.0 | 10.6 | 667 |
| 14 | 5.5 | 10.4 | 785 |
| 15 | 0.0 | 9.4 | 757 |
| 16 | 1.0 | 22.9 | 687 |
| 17 | 1.5 | 21.3 | 705 |
| 18 | 0.2 | 22.0 | 700 |
| 19 | 0.0 | 12.9 | 769 |
| 20 | 0.0 | 13.3 | 746 |
| Grade | Weight Capacity g/L | Mildew Grain Content % | Moisture Content % |
|---|---|---|---|
| 1 | 720 | 2.0 | 14.0 |
| 2 | 690 | ||
| 3 | 660 | ||
| 4 | 630 | ||
| 5 | 600 | ||
| Other | 600 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhu, Z.; Ning, W.; Fathollahi-Fard, A.M. An Improved Optimization Algorithm Based on Density Grid for Green Storage Monitoring System. Sustainability 2022, 14, 10822. https://doi.org/10.3390/su141710822
Zhang Y, Zhu Z, Ning W, Fathollahi-Fard AM. An Improved Optimization Algorithm Based on Density Grid for Green Storage Monitoring System. Sustainability. 2022; 14(17):10822. https://doi.org/10.3390/su141710822
Chicago/Turabian StyleZhang, Yanting, Zhe Zhu, Wei Ning, and Amir M. Fathollahi-Fard. 2022. "An Improved Optimization Algorithm Based on Density Grid for Green Storage Monitoring System" Sustainability 14, no. 17: 10822. https://doi.org/10.3390/su141710822
APA StyleZhang, Y., Zhu, Z., Ning, W., & Fathollahi-Fard, A. M. (2022). An Improved Optimization Algorithm Based on Density Grid for Green Storage Monitoring System. Sustainability, 14(17), 10822. https://doi.org/10.3390/su141710822